基于迁移学习的不可见声波数据的信号级扩充方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明属于深度学习技术领域,具体涉及一种基于迁移学习的不可见声波数据的信号级扩充方法。
背景技术
声波信号是人类感知世界的重要组成部分。随着现代工业和科学研究的发展,声波信号的应用越来越广泛,为人们带来巨大的便利和效益。然而,某些领域却存在着数据稀缺的问题。例如,在监测、水下通信等领域,复杂环境和资源限制等因素不仅影响了数据的数量和多样性,还增加了获取大规模高质量数据的时间、成本和资源投入。因此,为了弥补声波信号数据的稀缺和限制等问题,扩充技术变得至关重要。
近年来,声波信号扩充技术在不同领域和应用中具有广泛的潜力和前景。在经典方法中,例如,通过插值、外推等方式对已有数据进行处理来生成新的样本的传统信号处理方法,以及利用声学原理和物理模型来生成高度真实的声波信号数据的物理模型扩充方法。尽管上述方法可以实现声波信号扩充,但先前的研究表明,这些方法都依赖于具体的参数信息,需要对信号特性或场景进行深入的了解和分析,以获得准确的参数设置,限制了生成高质量和多样性的声波信号数据方法的能力。
目前,基于生成式对抗网络的模型在信号扩充方面表现出较好的性能。一种方法是,在训练阶段使用大量真实可见数据,生成器能够产生高质量的样本数据。另一种方法是模型迁移,其中微调是常见的技术,通过使用目标域数据更新已训练好的源域模型参数进行目标域的扩充。上述方法的前提为所需扩充的目标域数据是已知可用的情况。
然而,在实际场景中源域相对具有较好获取数据的条件,而目标域可能受各种因素限制导致数据获取困难。这种情况并不少见,例如,在一些工业领域或科学研究中,需要采集特定条件下的声波信号数据,但由于设备和实验成本高昂,很难获得大量目标域数据。先前的研究表明,域之间共享的类越少,数据扩充的任务就越难。其中源域可能仅覆盖目标域中类别的一个子集,而目标域中缺乏其它类别的声波信号数据。
对于上述情况,在源域和目标域之间建立联系和共享知识,利用源域数据的信息来扩充目标域中的不可见数据。其中一种常用的方法是利用域不变特征。通过提取和学习域间的域不变特征,再将这些特征与领域特征相结合,通过线性变换实现数据扩充,然而,确保领域特征和域不变特征的变换能够在维度上恢复至原始信号,这一点需要进一步的深入研究和讨论。另一种方法是利用指定特征进行迁移,这种方法将源域中已有的特征知识应用到目标域中,得到逼近目标域的扩充特征。然而,方法需要选择和提取具有代表性的特征,忽略了数据的其它维度信息,因此无法保证数据的整体完整性。
发明内容
本发明要提供一种基于迁移学习的不可见声波数据的信号级扩充方法,以克服现有技术存在的无法保证数据的整体完整性的问题。
为了实现上述目的,本发明的技术方案是:一种基于迁移学习的不可见声波数据的信号级扩充方法,包括以下步骤:
步骤一、数据预处理:采取数据截取策略,确保信号长度的一致性,同时引入定长滑动窗口对截取后的信号数据进行分割;
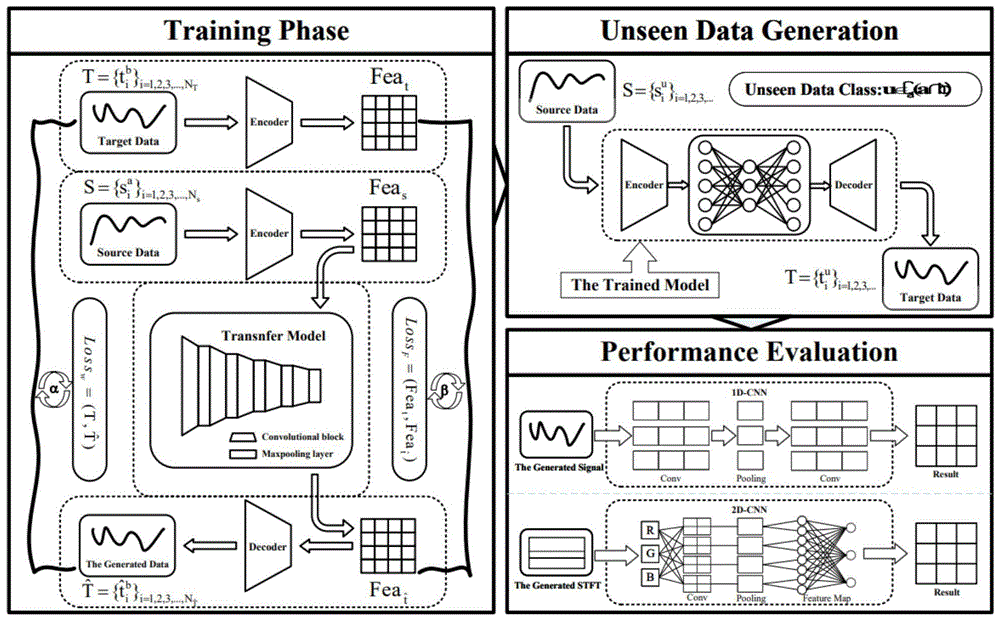
步骤二、使用网络进行训练,所述网络整体结构由特征提取和迁移生成两个模块组成:
特征提取模块:采用时间递归自动编码器,在编码器网络中,引入了重构损失函数;
迁移生成模块:通过迁移网络从源域的特征表示层面出发,引入空间结构一致性损失,同时,采用时间递归自动解码器进行复原;
步骤三、不可见数据的生成:
首先,将来自源域的一批样本输入编码器以获得源域特征;
其次,将源域特征输入到固定设置的迁移网络,得到对应的目标域扩充特征;
最后,通过解码器将扩充特征转换为扩充数据,生成接近目标域中不可见类别的声波信号数据。
进一步的,上述步骤二中,重构损失函数表示为:
其中:X是输入样本,
进一步的,上述步骤二中,一致性损失表示为:
Loss=αLoss
其中:
与现有技术相比,本发明的有益效果是:
1、本方法通过建立源域和目标域之间的联系并共享知识,消除域间差异,实现对目标域不可见数据的扩充。这种方法克服了目标域数据不可用的限制,同时有效利用源域数据的丰富信息,提高了扩充数据的质量和准确性。
2、本发明引入编解码框架,使用编码器提取源域和目标域之间的特征表示,捕捉域间的细粒度信息,结合迁移网络的特性,全面学习域间差异,最后通过解码器进行特征到信号的复原,从而实现信号级的声波信号扩充。
3、本发明采用卷积神经网络作为迁移基础,结合所提出的空间结构一致性损失,以减少迁移前后域间差异。本发明损失函数的设计使得源域样本能够在无需目标扩充数据辅助的基础上更好地迁移到目标域样本上。在此基础上,结合解码器对特征进行复原,保证了特征的可逆性。本方法不仅考虑了特征层面上的迁移,还考虑了信号本身的特性。
4、本发明通过只使用源域和目标域中同类别样本,生成目标域中不可见类别的扩充样本。大量实验验证,本发明方法在数据扩充上表现出良好的效率和泛化能力,并且在分类准确率上的精度基本可以与真实数据保持一致。
附图说明
图1为目前数据扩充任务中的两种基本情况;
图2为本发明整体方法框架;
图3为本发明实施例中使用到的编解码网络;
图4为本发明实施例中使用到的迁移生成网络;
图5为三个数据集扩充数据分类有效性验证的实验结果。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合实施例对本发明作进一步地详细描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
基于生成式对抗网络的模型包括两种方法,一种方法是在训练阶段使用大量真实可见数据,生成器能够产生高质量的样本数据。另一种方法是模型迁移,模型迁移中微调是常见的技术,通过使用目标域数据更新已训练好的源域模型参数进行目标域的扩充。
本发明的设计思想为,具体参见图1:首先在训练阶段存在部分已知且与源域同类别的目标域数据,通过所提出的模型学习源域和目标域中已有类别数据的域间映射关系,得到已知类别的目标域扩充数据。在此基础上,通过在训练阶段学习到的域间映射关系,可以利用源域中其余类别的数据扩充目标域中的不可见类别数据,在可见和不可见的条件下,对不同声波信号数据设计实验进行探索。
参加图2,本发明提供的一种结合基于迁移学习的不可见声波数据的信号级扩充方法,包括如下步骤:
步骤一、数据预处理操作:为了应对采集数据时间长度不统一以及采集过程中可能存在的冗余时段干扰信息,根据不同的数据集,本发明采取了数据截取的策略,确保信号长度的一致性。同时,引入定长滑动窗口对截取后的信号数据进行分割,以获得丰富的信号片段,进一步拓展训练数据集的基础。这样做不仅可以去除冗余信息,还为后续的处理提供了可用的声波信号数据。
本发明所采用的数据集包括不同参数、不同环境、不同设备的三种数据集,本发明实施例所采用的包括:
数据集一:不同参数的数据集是收集的水下声波信号,主要为水下目标检测、定位跟踪、远程指挥等提供信息支持。在原始数据集中,采集设备以240KHZ的采样频率记录水下声波信号,实测数据以脉宽和中心频率相结合分为6类。将原始高维信号截取为长度150000的数据,通过滑动窗口对信号数据以窗口长度为1500不重叠进行分割。
数据集二:不同环境的数据集是采用同一智能手机收集的水污染声波信号,主要用于水体污染检测的领域。所使用数据为采集设备以48KHZ的采样频率收集来自两种不同环境下的水污染信号:(1)弱多径环境下的水和农药的污染信号;(2)强多径环境下的水和农药的污染信号。需要注意的是,在声波信号的采集过程中,信号的采集环境会不断发生变化,多径环境时强时弱,导致不同的CIR测量值,从而所绘制的CI R频域特征图存在显著差异。
数据集三:不同设备的数据集是在同一材料下收集的声波信号数据,主要用于安检、垃圾分类等物料识别的领域中。所使用数据为两种不同型号的智能手机以48KHZ的采样频率收集在同一材料下的声波信号:(1)陶瓷材料下的K30手机和Mi6x手机;(2)铁片材料下的K30手机和Mi6x手机;(3)玻璃材料下的K30手机和M i6x手机。需要注意,不同手机的扬声器和麦克风的位置和型号可能不同,导致最终的CIR测量结果不同,从而所绘制的CIR频域特征图存在显著差异。将原始高维信号截取为时长9s的信号数据,通过滑动窗口对信号数据以窗口长度为120不重叠进行分割。
步骤二、使用网络进行训练,所述网络整体结构由特征提取和迁移生成两个模块组成:
步骤201:特征提取模块:为了有效地对声波数据进行信号到特征表示层面的转换,本发明采用时间递归自动编码器。在编码器网络中,引入了重构损失函数,以确保所提取特征能够准确表示信号数据。这样的设计能够有效地提取并表征声波信号中的关键信息,为后续的扩充任务奠定了基础。
本发明设计了一个时间递归自动编码器,旨在有效地将声波信号转换为时序特征。其基本思想是,编码器引导网络专注于提取输入数据的特征,而解码器则将潜在表示重新构造为输入信号数据。整体网络结构如图3所示,由两个模块组成:编码器模块和解码器模块。重构损失函数如式1所示。
其中:X是输入样本,
步骤202:迁移生成模块:为了实现源域向目标域的迁移,并实现目标域数据的信号级扩充,本发明提出了一种全新的迁移生成方法。具体而言,通过迁移网络从源域的特征表示层面出发,引入空间结构一致性损失,以减少域间差距。同时,为了有效还原特征至信号的原始维度,采用时间递归自动解码器进行复原。通过这种方式,能够高效地实现声波数据的信号级扩充。
本发明在直接采用卷积神经网络的基础上,设计了一个空间结构一致性损失以减少域间差异并实现从源域向目标域的特征迁移,并生成扩充的目标域特征表示。在迁移后目标域特征的基础上,引入解码器模块进行特征级向信号级的维度复原。该模块的结构如图4所示,由一个域迁移模块和解码器模块串联组成,这种设计允许在训练数据集有限的情况下,实现有效的域间迁移和数据扩充。空间结构一致性损失如式2,3,4所示。
Loss=αLoss
其中:
步骤三、不可见数据生成阶段:在此阶段,模型通过在训练阶段学习源域和目标域之间的域间映射关系,成功地将源域数据的知识迁移到目标域中。在此基础上,将所需的源域样本送入已训练好的模型中,从而扩充相应目标域中相应类别的数据。简言之,仅使用源域数据输入模型,就能够生成接近目标域的样本数据。通过这种迁移生成的方法,有效地实现了对不可见数据的扩充,为信号处理领域的研究和应用提供了新的可能性。使用源域数据输入模型,生成接近目标域中不可见类别的声波信号数据。具体为:
此阶段是在没有目标域数据的情况下实现源域到目标域的数据扩充。此时迁移网络的设置固定,训练基本的编码器。此部分整体包含三个步骤:首先,将来自源域的一批样本输入编码器以获得源域特征。其次,将源域特征输入到固定设置的迁移网络,得到对应的目标域扩充特征。最后,通过解码器将扩充特征转换为扩充数据。以上三个步骤构成了在没有目标域数据的情况下实现数据扩充。
为了验证本发明,下面对性能进行评估:
参见图5,通过信号和频谱图两个方面,验证了所提出的模型对数据扩充的有效性。在信号层面,采用了现阶段的一维卷积神经网络进行训练和验证。而在频谱图层面,使用了现阶段的二维卷积神经网络进行训练和验证。验证过程涵盖了两个不同的角度:首先,在训练阶段,所有信号数据都来自扩充模型,而测试阶段使用真实的声波信号样本。其次,在另一个角度,训练和测试阶段的信号数据都是真实的样本,但在训练阶段逐步添加等比例的扩充样本。
本发明从信号相似性、物理特征相似性和中心频率相似性三方面设计多个实验来评估方法的有效性和鲁棒性。实验结果参见表1、表2和表3:
表1:数据集Ⅰ的分类结果
表2:数据集Ⅱ的分类结果
表3:数据集Ⅲ的分类结果
通过表1-表3,可以看到该方法在信号级声波数据的扩充任务中有较好的性能。此外在分类有效性验证中,准确率基本可与原始数据准确率持平。
以上所述,仅是本发明的较佳实施例,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属本发明技术方案的保护范围。
- 一种具有防潮功能的互联网社会化投资系统主机
- 一种互联网社会化投资系统主机的保护装置
- 一种基于主机关系的互联网主机扫描方法及系统
- 一种基于主机关系的互联网主机扫描方法及系统