基于按需抽取和图同构源代码漏洞分析方法、装置、设备
文献发布时间:2024-04-18 20:00:50
技术领域
本发明属于网络安全技术领域,具体涉及基于按需抽取和图同构源代码漏洞分析方法、装置、设备。
背景技术
随着互联网的高速发展,网络攻击手段越来越复杂,其中针对软件漏洞的攻击也越来越多,高危软件漏洞会严重影响到信息系统的业务连续性。漏洞挖掘是发现软件未知漏洞的方法,当前主要是静态分析和动态分析两种主流方式。动态分析仅能发现软件运行态漏洞,代码覆盖率低。静态分析具有分析漏洞覆盖深度和广度的优势。静态分析分为针对源代码和二进制程序两种情况,针对有源代码的场景,静态分析源代码更能全面发现代码存在的漏洞,在软件发布之前解决漏洞问题,降低软件安全维护成本。目前较为流行的源代码漏洞分析主要有两种方法,一种是基于漏洞检测规则,一种是基于深度学习。其中,基于规则的漏洞分析主要使用预定义的规则集来分析源代码,这些规则定义了可能引发问题或漏洞的编程模式。较为典型的基于规则的源代码分析工具主要有Fortify、Checkmarx、Coverity等。然而,这类方法非常依赖于专业安全知识来确定规则集,维护和更新规则集需要消耗大量的时间和精力,基于深度学习的方法,可以极大解决人工定义漏洞特征的繁琐任务,减少规则更新不及时,造成无法实时分析出最新漏洞的问题。
在基于深度学习的图神经网络分析漏洞方法中,虽然基于图的方法能更好地理解程序语义,但分析源代码生成图的过程中,会产生生成图路径爆炸问题,遍历图路径会大量增加时间成本,不太适用于大规模源代码漏洞分析。
发明内容
本发明的目的是提供一种基于按需抽取和图同构的源代码漏洞分析方法。
第一方面,为实现上述目的,本发明提出基于按需抽取和图同构源代码漏洞分析方法,包括有以下方法步骤:
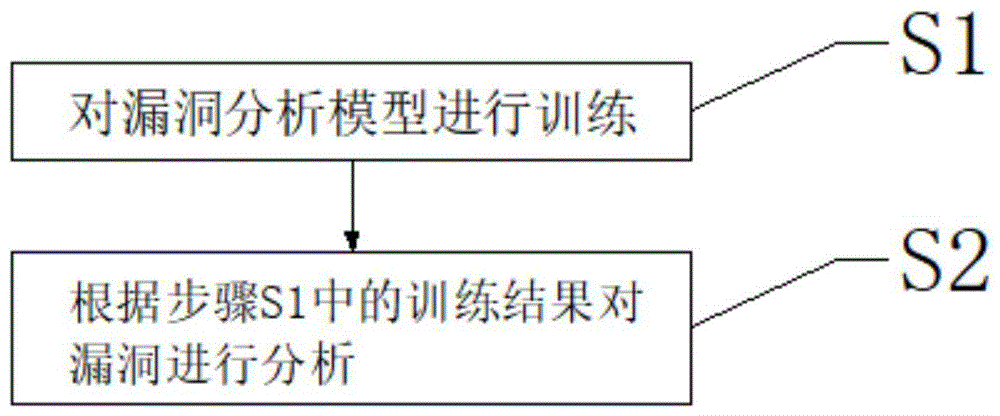
S1、对漏洞分析模型进行训练;
S2、根据步骤S1中的训练结果对漏洞进行分析。
可选的,所述S1中对漏洞分析模型进行训练包括如下步骤:
S11、选取开源数据集以及样本集;
S12、根据开源数据集中相应的函数调用链,生成dot文件;
S13、根据数据集中的函数名对word2vec模型进行预训练,并对函数调用链的各节点向量化;
S14、将从数据表征模块得到的向量送到预先设计的机器学习模型中进行训练;
S15、根据计算得到的特征表达与原始标签的差异构建损失函数;
S16、通过优化方法来最小化损失函数;
S17、设置训练周期以及过程中需要记录输出信息的参数;
S18、对训练数据集样本经过指定次数训练后,得到GIN分类器模型。
可选的,所述S11中选取apache作为开源数据集,选取DiverseVul作为样本集。
可选的,选取开发语言分布在c、c++、java、python。
可选的,所述S12具体为:
使用Doxywizard从数据集中抽取相应的函数调用链,生成dot文件。
可选的,所述S14中预先设计的机器学习模型采用图同构神经网络GIN作为训练模型,将向量化的代码表征输入模型进行训练。
可选的,所述S15中差异构建损失函数采用交叉熵损失函数CrossEntropyLoss作为模型的损失函数;
交叉熵损失函数的公式为:
其中:N为样本数量,y为真实标签的独热编码形式或者类别索引,p为模型的输出概率分布向量。
可选的,所述S16中的优化方法为:AdamW优化算法,所述AdamW优化算法为常用优化算法,其由pytorch框架给出。
可选的,所述S2中对漏洞进行分析的具体步骤如下:
S21、通过源代码文件名后缀判断、源代码特征正则匹配方式分析源代码使用的开发语言;
S22、根据源代码开发语言确定对应的危险函数库;
S23、对源代码进行脆弱点分析,根据所确定的开发语言对应的危险函数来定位脆弱点;
S24、根据危险函数和脆弱点来提取该函数相关联的关键代码和边界代码;
S25、将提取出来的代码转换为中间语言;
S26、对关键代码生产函数内控制流图、对边界代码生成函数间调用关系图。通过结合函数内控制流图和函数间调用关系图,生成函数调用图;
S27、利用深度优先遍历算法得到函数调用图中包含危险函数的分支的函数调用链;
S28、将函数调用图节点信息进行向量化;
S29、使用四层图同构网络,每层的图特征分别通过一个全连接神经网络和一个softmax分类器对进行当前层次的目标函数调用链进行分类;
S30、经过四层图同构网络分析,使用求和函数对每层的分类结果进行汇总,得到最终的分类结果,分类结果0表示:无漏洞1表示存在漏洞。
可选的,所述S25中中间语言的转换过程如下:使用Doxywizard工具中的编译器将源代码转换IR(Intermediate Representation,中间表示语言),如果源代码开发语言为C/C++/Python,则转为LLVM IR,如果开发语言为java,则转换为jimple。
可选的,所述S26具体为:对源代码转换后的中间表示语言生成函数控制流图(Control Flow Graph,CFG),针对得到的这些函数控制流图进行函数调用处理,生成函数调用图(Call Graph,CG),通过合并函数控制流图和函数调用图,形成过程间控制流图(Inter-procedural Control Flow Graph,ICFG)。
可选的,所述S28中将函数调用图节点信息进行向量化具体方法步骤如下:
数据预处理:从DiverseVul数据集中提取函数名称作为文本语料库;
构建词汇表:基于预处理的文本数据,构建一个词汇表;
初始化词向量:为词汇表中的每个词随机初始化一个词向量;
选择模型类型:选择Word2Vec工具的模型类型;
定义模型结构:默认使用Skip-gram模型,通常包括一个输入层和一个输出层;
训练模型:使用预处理的文本数据训练Word2Vec模型。在训练过程中,模型会调整词向量以最大化上下文和中心词的相关性,得到Word2Vec.model。
第二方面,基于按需抽取和图同构源代码漏洞分析的装置,应用于上述的方法。
第三方面,基于按需抽取和图同构源代码漏洞分析的设备,应用于上述的方法。
与现有技术相比,本发明的有益效果是:
1、本发明基于危险函数,减少遍历全部函数的时间开销,提升源漏洞分析执行效率。
2、本发明使用图同构网络对仅包含脆弱点和边界代码的函数间控制流图进行图分类,减少函数调用链数量级。
3、本发明使用内置函数列表和自定义函数列表,根据需求可自定义抽取函数调用链。
附图说明
图1是本发明的方法原理示意图。
图2是本发明中步骤S1的步骤流程示意图。
图3是本发明中步骤S2的步骤流程示意图。
图4是本发明中源代码分析整体流程图。
图5是本发明中图同构网络分类分析漏洞的实现原理图。
图6是本发明中源代码转换为中间表示语言生成过程间控制流图。
图7是本发明中函数调用图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-图7,本实施例中基于按需抽取和图同构源代码漏洞分析方法,包括有以下方法步骤:
S1、对漏洞分析模型进行训练;
S11、选取开源数据集以及样本集;
选取apache作为开源数据集,选取DiverseVul作为样本集,选取开发语言分布在c、c++、java、python
S12、使用Doxywizard从数据集中抽取相应的函数调用链,生成dot文件;
S13、根据数据集中的函数名对word2vec模型进行预训练,并对函数调用链的各节点向量化;
S14、将从数据表征模块得到的向量送到预先设计的机器学习模型中进行训练;
预先设计的机器学习模型采用图同构神经网络GIN作为训练模型,将向量化的代码表征输入模型进行训练;
S15、根据计算得到的特征表达与原始标签的差异构建损失函数;
差异构建损失函数采用交叉熵损失函数CrossEntropyLoss作为模型的损失函数;
交叉熵损失函数的公式为:
其中:N为样本数量,y为真实标签的独热编码形式或者类别索引,p为模型的输出概率分布向量;
S16、通过优化方法来最小化损失函数;
优化方法为:AdamW优化算法,所述AdamW优化算法为常用优化算法,其由pytorch框架给出;
S17、设置训练周期以及过程中需要记录输出信息的参数;
S18、对训练数据集样本经过指定次数训练后,得到GIN分类器模型
S2、根据步骤S1中的训练结果对漏洞进行分析;
S21、通过源代码文件名后缀判断、源代码特征正则匹配方式分析源代码使用的开发语言;
S22、根据源代码开发语言确定对应的危险函数库;
源代码开发语言确定对应的危险函数如下:
C_DANGEROUS_FUNCS=['strcpy','strncpy','strlcpy','memcpy','memmove','snprintf','vsnprintf','strcat','sscanf','strdup','strstr','strchr','strrchr','strpbrk','stristr','strtok','strtok_r','strsep','atoi','atoll','strtol','strtoll','strtoul','system','exec','popen','execvp','execl','hsearch_r','index','strlen','recv','recvfrom','read','fgets'];
JAVA_DANGEROUS_FUNC=['Runtime.exec','String.getBytes','ObjectInputStream.readObject','System.setSecurityManager','File.delete','File.renameTo','URL Decoder.decode','BufferedReader'];
PYTHON_DANGEROUS_FUNC=['eval','exec','os.system','subprocess.call','pickle','file.write','PyYAML','open','read'];
S23、对源代码进行脆弱点分析,根据所确定的开发语言对应的危险函数来定位脆弱点;
进一步的:危险函数可为strcpy或者system中的一种
S24、根据危险函数和脆弱点来提取该函数相关联的关键代码和边界代码;
S25、将提取出来的代码转换为中间语言;
使用Doxywizard工具中的编译器将源代码转换IR(IntermediateRepresentation,中间表示语言),如果源代码开发语言为C/C++/Python,则转为LLVM IR,如果开发语言为java,则转换为jimple。
S26、对关键代码生产函数内控制流图、对边界代码生成函数间调用关系图;通过结合函数内控制流图和函数间调用关系图,生成函数调用图;
对源代码转换后的中间表示语言生成函数控制流图(Control Flow Graph,CFG),针对得到的这些函数控制流图进行函数调用处理,生成函数调用图(Call Graph,CG),通过合并函数控制流图和函数调用图,形成过程间控制流图(Inter-procedural Control FlowGraph,ICFG)。
S27、利用深度优先遍历算法得到函数调用图中包含危险函数的分支的函数调用链;
S28、将函数调用图节点信息进行向量化;
数据预处理:从DiverseVul数据集中提取函数名称作为文本语料库;
构建词汇表:基于预处理的文本数据,构建一个词汇表;
初始化词向量:为词汇表中的每个词随机初始化一个词向量;
选择模型类型:选择Word2Vec工具的模型类型;
定义模型结构:默认使用Skip-gram模型,通常包括一个输入层和一个输出层;
训练模型:使用预处理的文本数据训练Word2Vec模型。在训练过程中,模型会调整词向量以最大化上下文和中心词的相关性,得到Word2Vec.model。
S29、使用四层图同构网络,每层的图特征分别通过一个全连接神经网络和一个softmax分类器对进行当前层次的目标函数调用链进行分类;
S30、经过四层图同构网络分析,使用求和函数对每层的分类结果进行汇总,得到最终的分类结果,分类结果0表示:无漏洞1表示存在漏洞。
综上可知:
1、本发明基于危险函数,减少遍历全部函数的时间开销,提升源漏洞分析执行效率。
2、本发明使用图同构网络对仅包含脆弱点和边界代码的函数间控制流图进行图分类,减少函数调用链数量级。
3、本发明使用内置函数列表和自定义函数列表,根据需求可自定义抽取函数调用链。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种用于五金配件生产的圆磨装置
- 一种用于工业生产五金打磨设备的降噪除尘装置
- 一种用于五金轴承生产的检测排出装置
- 一种用于电子产品的热辐射型散热五金件及其制备方法
- 一种用于果物生产的一体采摘收集装置
- 一种用于五金生产的碎屑可收集型数控车床
- 一种用于五金零件生产制造用碎屑收集装置