一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于图像处理技术领域,具体涉及一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法。
背景技术
图像分割(像素级分类)是计算机视觉领域的一个重要研究方向,主要得益于其可以完成对图像中不同目标的像素级精准分类,从而成为很多视觉场景任务的基础,例如在无人机自动巡检领域,通过对目标的精准分割及其他技术,可以获取巡检目标的相对姿态,进而去执行自动飞行和巡检任务。
目前,图像分割任务的主要数据来源是使用标注工具进行多边形人工标注,该方法具有以下缺点:(1)传统人工标注对于像素区域较小的目标或形状较为不规则的目标,需要耗费较长的时间逐一进行标注,标注效率较低,标注成本较高;并且对于目标边界像素的划定只能采用多条直线进行分割,会导致部分非直线边界像素的标注错误,标签的分割精度受到客观条件限制。(2)在当前深度学习模型的发展趋势下,模型结构日益复杂及模型参数量也在爆炸式增长,因此,模型训练所需的数据量也在变得非常庞大(目前部分大模型训练数据中掩码数量已为亿级),传统的人工标注方法已经无法满足快速增长的模型训练数据规模的需求。(3)在大多数任务中,需要更新模型时,一般需要在数据采集后预留一定时间来进行数据标注,人工标注周期一般较长,且标注质量不统一,后期需进行人工审核及修改,致使模型更新的周期较长,无法满足快速任务迭代的需求。
因此,本发明的目的是提供一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法,以来解决上述技术问题。
发明内容
发明目的:为了克服以上不足,本发明的目的是提供一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法,设计合理,提供了一种利用计算机视觉大模型和拍摄位姿约束进行图像目标分割的方法,提高了图像分割自动标注效率、质量,成本低,应用前景广泛。
本发明的目的是通过以下技术方案实现的:
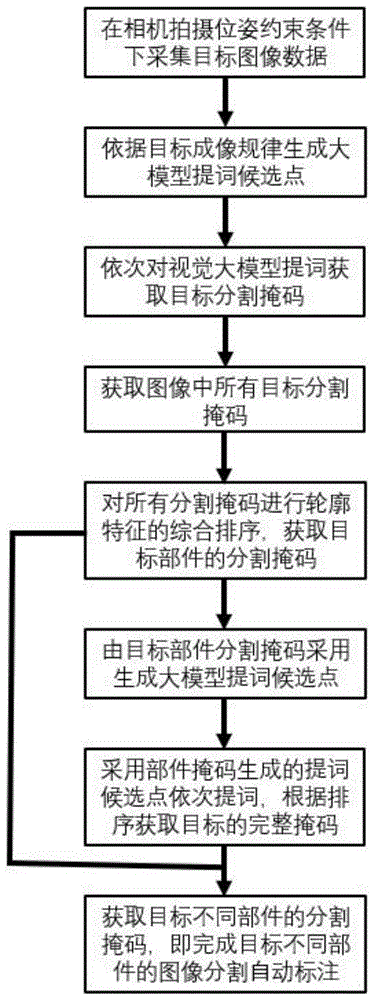
一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法,S1:在相机拍摄位姿约束条件下采集目标图像数据,根据目标的成像规律生成大模型提词候选点;
S2:由步骤S1生成的大模型提词候选点依次进行视觉大模型提词分割,获取相应的目标分割掩码;
S3:不断重复步骤S2,获取每次视觉大模型提词分割输出的目标分割掩码,直至遍历结束;
S4:对步骤S3中获取的所有目标分割掩码进行轮廓特征的综合排序,获取目标部件的分割掩码;
S5:由步骤S4中获取的目标部件的分割掩码生成N个提词候选点;
S6:对步骤S5中目标部件的分割掩码生成的N个提词候选点依次进行视觉大模型提词分割,根据排序获取目标的完整掩码;
S7:由步骤S4中获取的目标不同部件的分割掩码,完成目标不同部件的图像分割自动标注。
本发明提供了一种利用计算机视觉大模型和拍摄位姿约束进行图像目标分割的方法,通过对相机拍摄位姿的约束,使成像画幅中目标可以保持适当大小,根据目标成像的位置规律来制定视觉大模型提词候选点的生成规则,然后采用视觉大模型对单个提词候选点进行提词分割,可以获取高质量的前景目标分割掩码,进而通过排序筛选目标部件的轮廓特征获取目标部件的分割掩码,根据目标部件的分割掩码依据规则生成提词候选点,再次对目标进行提词分割,最终获取目标不同部件的图像自动标注分割掩码。上述方法提高了图像分割自动标注效率、质量,并且成本低。
进一步的,上述的一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法,所述步骤S1,具体包括如下步骤:
S11:目标在进行图像数据采集时,相机拍摄的位姿需满足一定约束,使得成像画幅中目标满足一定相对位置的规律;
S12:在相机拍摄位姿约束条件下采集目标图像数据,根据目标的成像规律制定大模型提词候选点的生成规则,生成一系列大模型提词候选点。
进一步的,上述的一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法,所述步骤S2,所述视觉大模型提词分割采用SAM。
所述SAM为已开源的提词分割模型Segment Anything Model。
进一步的,上述的一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法,所述步骤S2,SAM提词分割包括如下步骤:
(1)输入大模型的提词类型为像素点坐标,将1个坐标点(w, h)进行位置编码,编码为1×256的数组;
(2)将采集的目标图像数据送入预训练过的ViT模型中得到图像编码;
(3)大模型自身学习出的各像素点坐标属于前景或者背景的编码,以下称为分类编码;将分类编码和上述位置编码、图像编码同时送入解码模块,最终获取视觉大模型提词分割输出得分最高的目标分割掩码。
进一步的,上述的一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法, 所述步骤(3),所述解码模块包含多层自注意力模块、交叉注意力模块和全连接网络模块。
进一步的,上述的一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法,所述步骤S4,具体包括如下内容:对步骤S3中所有迭代获取的目标分割掩码进行排序;根据目标部件的轮廓特征,制定了针对分割掩码的规则,所述规则包括但不限于外接矩形框长宽比、掩码面积、外接矩形框填充率,对所有的分割掩码进行由大到小的排序,选取综合排序结果第一名对应的分割掩码作为目标部件的分割掩码。
进一步的,上述的一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法,所述步骤S5,具体包括如下内容:由步骤S4中获取的目标部件的分割掩码,沿成像画幅高度方向在分割掩码的高度范围内均匀设置N个采样高度,每个采样高度下选取分割掩码最左侧和左右侧线段的中心点生成一个提词候选点,最终由目标部件的分割掩码可以生成N个提词候选点。
进一步的,上述的一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法,所述步骤S6,具体包括如下内容:由步骤S5中生成的N个提词候选点依次进行视觉大模型提词分割,设置输出模式为多掩码输出,即由小到大多个层次的目标掩码输出,依次记录每个提词候选点最大层次的目标掩码输出;对所有掩码的前景像素面积进行排序,选取面积最大的掩码作为目标的完整掩码。
进一步的,上述的一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法,所述步骤S7,具体包括如下内容:由步骤S4中获取的的目标不同部件的分割掩码,依据像素坐标对目标的完整掩码进行部件去除,得到目标剩余部件的分割掩码,即完成了目标中不同部件的图像分割自动标注。
与现有技术相比,本发明具有如下的有益效果:本发明所述的一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法,设计合理,提供了一种利用计算机视觉大模型和拍摄位姿约束进行图像目标分割的方法,通过对相机拍摄位姿的约束,使成像画幅中目标满足一定相对位置的规律,根据目标成像的位置规律来制定视觉大模型提词候选点的生成规则,然后采用视觉大模型对单个提词候选点进行提词分割,可以获取高质量的前景目标分割掩码,进而通过排序筛选目标部件的轮廓特征获取目标部件的分割掩码,根据目标部件的分割掩码依据规则生成提词候选点,再次对目标进行提词分割,利用视觉大模型提词分割多掩码输出模式的特点,获取由小到大多个层级的目标分割掩码,最终获取目标不同部件的图像自动标注分割掩码;上述方法提高了图像分割自动标注的效率、质量,同时成本低,应用前景广泛。
附图说明
图1为本发明所述一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法的流程图;
图2为本发明实施例1的步骤S1生成的大模型提词候选点的示意图;
图3为本发明实施例1的步骤S2、S3获取目标分割掩码的示意图;
图4为本发明实施例1的步骤S4筛选目标部件的分割掩码的示意图;
图5为本发明实施例1的步骤S5、S6获取目标的完整掩码的示意图;
图6为本发明实施例1的步骤S7完成目标不同部件的图像分割自动标注的示意图。
具体实施方式
下面将附图1-6、实施例1对本发明的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通的技术人员在没有做出创造性劳动的前提下所获得的所有其它实施例,都属于本发明的保护范围。
以下实施例1提供了一种通过大模型和拍摄姿态约束进行图像分割自动标注的方法。
实施例1
实施例1提供了一种利用计算机视觉大模型和拍摄位姿约束进行图像目标分割的方法。如图1所示,该方法包括如下步骤:
S1:在相机拍摄位姿约束条件下采集目标图像数据,根据目标的成像规律生成大模型提词候选点,如图2所示。
S11:目标在进行图像数据采集时(以下均以风机为例),相机拍摄的位姿需满足一定约束,例如无人机在同一飞行高度下,以固定半径环绕风机进行云台拍摄(默认放大倍数等其他相机参数保持一致),使得成像画幅中目标满足一定相对位置的规律,即可以保持适当大小;
S12:在相机拍摄位姿约束条件下采集目标图像数据,成像画幅中风机的塔筒部件主要处于成像画幅中的下半区域,并且塔筒的长轴方向基本平行于成像画幅中高度方向,根据此成像规律,可以设定在成像画幅一定高度处(例如距离成像画幅底部100个像素),等间距(例如50个像素)生成一系列大模型提词候选点。图2中距离成像画幅底部固定距离的一排点,即为按目标部件(风机塔筒)成像规律生成的大模型提词候选点。
S2:由步骤S1生成的大模型提词候选点依次进行视觉大模型提词分割(采用已开源的提词分割模型:SAM(Segment Anything Model),获取相应的目标分割掩码,如图3所示。
其中,SAM提词分割包括如下步骤:
(1)输入大模型的提词(token)类型为像素点坐标,将1个坐标点(w, h)进行位置编码,编码为1×256的数组(prompt toekn);
(2)将采集的目标图像数据送入预训练过的ViT模型中得到图像编码(256×64×64);
(3)大模型自身学习出的各像素点坐标属于前景或者背景的编码(output token,1×256的数组),以下称为分类编码;将分类编码和上述位置编码、图像编码同时送入解码模块(包含多层自注意力模块、交叉注意力模块和全连接网络模块),最终获取视觉大模型提词分割输出得分最高的目标分割掩码。
S3:不断重复步骤S2,获取每次视觉大模型提词分割输出的目标分割掩码,直至遍历结束,如图3所示,图3中左侧的点示意为当前提词候选点,右侧掩码即为其对应的提词分割掩码。
S4:对步骤S3中获取的所有目标分割掩码进行轮廓特征的综合排序,获取目标部件的分割掩码,如图4所示,图4中筛选目标部件为风机塔筒。
对步骤S3中所有迭代获取的目标分割掩码进行排序;根据目标部件(例如风机塔筒)的轮廓特征(例如竖直长条形),制定了针对分割掩码的规则,所述规则包括但不限于外接矩形框长宽比、掩码面积、外接矩形框填充率,对所有的分割掩码进行由大到小的排序,选取综合排序结果第一名对应的分割掩码作为目标部件的分割掩码。
S5:由步骤S4中获取的目标部件的分割掩码生成N个提词候选点。
由步骤S4中获取的目标部件的分割掩码,沿成像画幅高度方向在分割掩码的高度范围内均匀设置N个采样高度,每个采样高度下选取分割掩码最左侧和左右侧线段的中心点生成一个提词候选点,最终由目标部件的分割掩码可以生成N个提词候选点。
S6:对步骤S5中目标部件的分割掩码生成的N个提词候选点依次进行视觉大模型提词分割,根据排序获取目标的完整掩码,如图5所示,图5中星型标记为提词点,输出由小到大多个层次的目标分割掩码(部分风机塔筒 ->风机塔筒 ->风机塔筒+风机叶片),其中最大层次(图5的子图3)为风机的完整掩码。
由步骤S5中生成的N个提词候选点依次进行视觉大模型提词分割,设置输出模式为多掩码输出,即由小到大多个层次的目标掩码输出,依次记录每个提词候选点最大层次的目标掩码输出;对所有掩码的前景像素面积进行排序,选取面积最大的掩码作为目标的完整掩码。
S7:由步骤S4中获取的目标不同部件的分割掩码,完成目标不同部件的图像分割自动标注。
如图6所示,由步骤S4中获取的已获取的目标部件(风机塔筒)的分割掩码,依据像素坐标对目标的完整掩码(整个风机掩码)进行目标部件(风机塔筒)去除,得到目标剩余部件(风机叶片)的分割掩码,即完成了目标中不同部件的图像分割自动标注。
本发明具体应用途径很多,以上所述仅是本发明的优选实施方式。应当指出,以上实施例仅用于说明本发明,而并不用于限制本发明的保护范围。对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进,这些改进也应视为本发明的保护范围。
- 一种多视角转换的心电信号数据增强方法
- 一种心电、肌电信号测试设备提高数据传输率的方法
- 一种基于脑电信号、肌电信号和心电信号手指康复训练系统