一种轻量级的单目近红外静默人脸活体判别方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明公开了一种人脸活体判别方法,特别是涉及一种轻量级的单目近红外静默人脸活体判别方法。
背景技术
随着人脸识别技术被广泛应用到如线上支付等网络交易领域,并向着自动化、无人工化的趋势发展,支付方式变得更加便利,但随之而来的安全问题也成了一个需要迫切解决的问题。为了自动地、高效地辨别传感器所捕获的图像的真伪、抵抗欺骗攻击以确保系统安全,活体判别也获得了越来越多的关注。
在实际应用场景中,从传感器角度考虑,近红外图像在活体判别领域具有环境适应性优于可见光、电子屏幕无法成像、近红外传感器成本较低、可穿透墨镜成像等优势。
从硬件设备角度考虑,参数量较大的模型由于内存空间等设备性能限制,难以部署到边缘设备上。以往的活体判别方法大多为基于ResNet模型与VGG模型等参数量较大的模型,难以落地部署,而基于MobileNet的轻量级模型则性能较低,无法满足产品实际使用要求。
在训练模型时,为了获取最好的结果人们通常采用复杂模型来训练,参数冗余严重,导致前向预测时,需要对模型进行复杂的计算,从而使得模型工程落地难。因此需要把复杂模型(Teacher)学到的知识迁移到另一个轻量级模型(Student)上。使模型变轻量的同时(方便部署),尽量不损失性能,这就是知识蒸馏方案(Hinton G,Vinyals O,DeanJ.Distilling the knowledge in a neural network[J].arXiv preprint arXiv:1503.02531,2015,2(7).)。而常规的知识蒸馏方案仅是通过对比两个模型的最终输出,或是对比每一个模块输出的特征(CN114821721A)来进行知识蒸馏,这会导致模型难以学习到更细粒度的有效特征,或是学习到一些冗余的无关特征。
此外,从活体判别常见攻击类型可以发现,打印攻击、重播攻击等二维攻击都不具有深度信息,故可以考虑将深度图作为模型训练时的监督信息。Y.Atoum(Atoum Y,Liu Y,Jourabloo A,et al.Face anti-spoofing using patch and depth-based CNNs[C]//2017IEEE International Joint Conference on Biometrics(IJCB).IEEE,2017:319-328.)等人认为像素级伪深度标签可以指导深度学习模型正确地区分活体与非活体,从而首次提出了利用伪深度标签来指导多级全卷积网络(FCN)训练的方案。该方案先由3D面部模型拟合算法生成真实人脸的深度图并提取特征,再将之与人脸随机抽取区域的特征相融合进行活体判别,因此,DepthNet能够将整体深度图作为决策依据。
此外,Z.Yu等人提出了一种基于中心差分卷积(CDC)的帧级活体判别方法,该卷积可以替代普通卷积,相较普通卷积更注意强度与梯度信息,从而获得更本质的细节信息。本文也使用深度图作为像素级监督信息,且使用了一种对抗深度损失(CDL),该损失函数能够更好地利用细粒度的局部深度信息。
但是,活体判别常被视作二分类任务,而基于二进制损失函数(如交叉熵损失)的深度学习模型很可能无法学习到细粒度的本质欺骗特征,比如背景干扰较大或面部被遮挡时,这种方案会倾向于误判。基于像素级监督的方案能有效改善这一问题,可以更好的提取细粒度信息和上下文相关的活体线索,从而引导模型学习活体判别相关的局部特征。但常规的像素级监督方案主要基于深度图进行像素级监督,需要像素级的深度标签,成本较高。本方案则可由图片标签自行生成像素级标签图,无需另外采集深度图作为标签。
发明内容
为了解决上述问题,本发明提出了一种轻量级的单目近红外静默人脸活体判别方法,其本质上是一种基于深度神经网络的单目人脸活体判别方法,通过结构重参数化方法,在不提高模型复杂度的情况下提高模型所学习到的有效信息;通过无需像素级深度图标签的像素级二值监督辅助模型训练,使模型不仅从整体特征上学习人脸的欺骗信息,还从更全面的像素级别的信息上学习更细粒度更本质人脸的欺骗信息;通过多尺度知识蒸馏,让大模型不仅监督轻量级模型的判别结果,也监督每一层的特征。综上,使得模型可以在非常小的参数量下获得较高的性能,有效抵御各种非活体攻击。本发明将每一层特征提取出来,经过特征融合与欺骗特征提取后再进行对比监督,可以有效学习到更细粒度更本质的欺骗特征,并通过该过程摒弃无关的冗余特征。
本发明至少通过如下技术方案之一实现。
一种轻量级的单目近红外静默人脸活体判别方法,包括以下步骤:
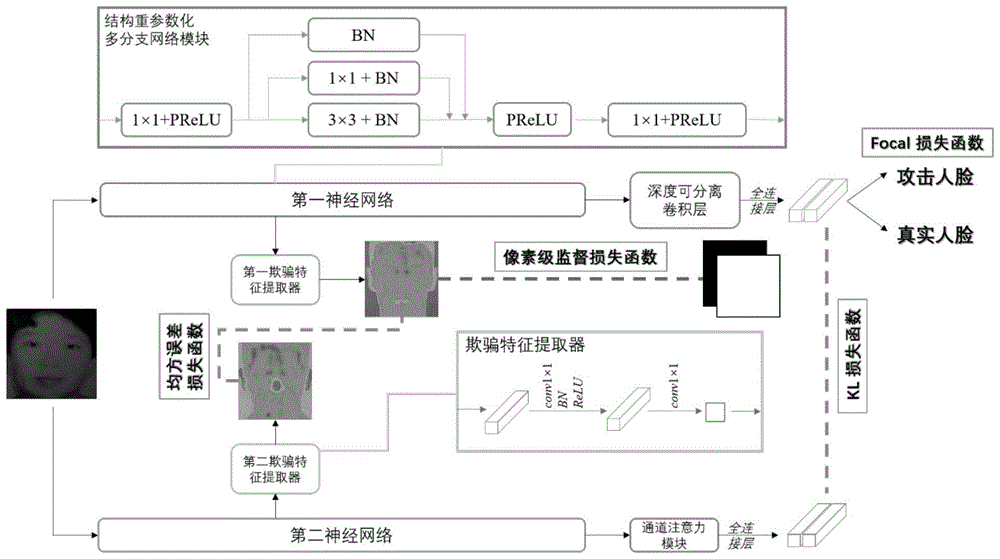
(a)获取单目近红外摄像头的人脸图像作为输入图像,采用结构重参数化的第一神经网络的每一个特征提取模块分别生成一个特征图,并在第一神经网络结尾经全连接层生成第一活体判别结果;所述第一神经网络包括四个特征提取模块;
(b)将第一神经网络的第一特征提取模块-第四特征提取模块输出的特征融合后,通过欺骗特征提取器获得第一像素级特征图,并通过对比该图与根据标签生成的像素级标签图来监督第一神经网络的训练;
(c)预训练第二神经网络,获得第二像素级特征图与第二活体判别结果;
(d)基于多尺度知识蒸馏,分别通过对比第一像素级特征图与第二像素级特征图,以及对比第一活体判别结果、第二活体判别结果监督第一神经网络训练,从而在轻量级模型上实现高精度活体判别。
进一步地,所述第一神经网络是任意带有3x3卷积的网络结构。
进一步地,每个特征提取模块包括数量不同的分支结构;所述在第一神经网络训练阶段,在每个卷积核上平行添加分支结构。
进一步地,每个特征提取模块包括依次连接的卷积核大小为1x1的卷积层、PreLu激活函数层、分支结构、PreLu激活函数层、卷积核大小为1x1的卷积层、PReLU激活函数层。
进一步地,每个分支结构为三分支结构,并在每个分支结尾加上一个批归一化层操作,三个分支为3x3的卷积层、1x1的卷积层和全连通。
进一步地,在推理阶段将三分支结构等价转换为单分支结构;
单分支结构包括依次连接的卷积核大小为1x1的卷积层、PreLu激活函数层、卷积核大小为3x3的卷积层、PreLu激活函数层、卷积核大小为1x1的卷积层、PReLU激活函数层。
进一步地,步骤(b)中,将第一特征提取模块输出的特征图下采样到第二特征提取模块所输出特征图的尺寸,并将第三、四特征提取模块输出的特征图上采样到第二特征提取模块所输出特征图的尺寸,最后将四个特征图按通道进行拼接融合,通过由两个1x1卷积层为核心组成的欺骗特征提取器获得第一像素级特征图,并通过对比该图与根据标签生成的像素级标签图来监督模型训练。
进一步地,步骤(b)中,根据标签生成的像素级标签图包括:根据输入人脸图像的真实标签,构建一张与第二特征提取模块所输出特征图的尺寸相同的像素级标签图,当输入图像为活体人脸时,该像素级标签图内的值全为1,而当输入图像为伪造攻击人脸时,该像素级标签图内的值全为0。
进一步地,步骤(c)预训练一个参数量较大的模型作为第二神经网络,输入人脸图像后,由步骤(a)和步骤(b)的方式获得第二像素级特征图与第二活体判别结果。
进一步地,基于均方误差损失函数,通过对比第一像素级特征图与第二像素级特征图来监督第一神经网络训练;并引入KL散度损失函数,通过对比第一活体判别结果、第二活体判别结果来监督第一神经网络训练;再引入Focal损失函数,通过对比第一活体判别结果与真实标签监督第一神经网络训练。
与现有技术相比,本发明具有以下有益效果:
(1)在像素级监督中,通过融合多尺度特征图,提取更全面的人脸欺骗信息,并通过像素级监督方案有效提取其中的细粒度本质欺骗特征,相对常规二分类监督有效提高欺骗信息提取能力。同时能够部署在仅采用单目近红外摄像头的低内存边缘设备上的轻量级高精度活体判别模型,相对其他方法大大降低了设备成本,并显著提高了判别精度,利于实际落地部署;
(2)在知识蒸馏中,除了通过KL散度损失函数使第一神经网络的活体判别结果接近第二神经网络外,还通过融合多尺度特征在全局层面上使第一网络的特征图提取接近第二神经网络,全面提高第一神经网络的活体攻击信息提取能力;
(3)在结构重参数化中,能够解耦训练时和推理时的架构,即能够在训练阶段训练一个多分支模型,而在推理时将多分支模型等价转换为单路模型。使得模型能够增加连接上的多样性与训练时的非线性,从数据中获得更多信息,并且不额外增加模型负担。
附图说明
图1是本发明提出的轻量级的单目近红外静默人脸活体判别方法示意图;
图2是通过结构重参数化方法将多分支结构转成单路结构示意图;
图3是多尺度知识蒸馏框架示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,以下将结合附图和具体实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示的一种轻量级的单目近红外静默人脸活体判别方法,包括以下步骤:
(a)获取单目近红外摄像头的人脸图像作为输入图像,采用结构重参数化的第一神经网络的每一个特征提取模块分别生成一个特征图,并在第一神经网络结尾经全连接层生成第一活体判别结果;所述第一神经网络包括四个特征提取模块block;
每个特征提取模块包括1、2、6、3数量不同的分支结构;所述在第一神经网络训练阶段,在每个卷积核上平行添加分支结构。每个分支结构为三分支结构,并在每个分支结尾加上一个批归一化层操作,三个分支为3x3的卷积层、1x1的卷积层和全连通。在推理阶段将三分支结构等价转换为单分支结构;单分支结构包括依次连接的卷积核大小为1x1的卷积层、PreLu激活函数层、卷积核大小为3x3的卷积层、PreLu激活函数层、卷积核大小为1x1的卷积层、PReLU激活函数层。
(b)将第一神经网络的第一特征提取模块-第四特征提取模块输出的特征融合后,通过欺骗特征提取器获得第一像素级特征图,并通过对比该图与根据标签生成的像素级标签图来监督第一神经网络的训练;
(c)预训练第二神经网络,获得第二像素级特征图与第二活体判别结果;
(d)基于多尺度知识蒸馏,分别通过对比第一像素级特征图与第二像素级特征图,以及对比第一活体判别结果、第二活体判别结果监督第一神经网络训练,从而在轻量级模型上实现高精度活体判别。
作为一种优选的实施例,本实施例采用像素级二值监督方案、知识蒸馏方案监督模型训练,并采用结构重参数化方案以解耦训练时和推理时的架构,使得模型能在训练时采用多分支架构,从数据中获得更多信息,而后在推理阶段将多分支架构等价转换为单分支架构,让模型能够在参数量较小的单分支架构下获得多分支架构下较高的性能。最终获得一种新的轻量级人脸活体判别模型,能够有效应对近红外传感器下的非活体人脸攻击。
本实施例的一种轻量级的单目近红外静默人脸活体判别方法,包括以下步骤:
(a)获取单目近红外摄像头的人脸图像作为输入图像,由采用了结构重参数化的第一神经网络的每一个模块分别生成一个特征图,并在模型结尾经全连接层生成第一活体判别结果;
依次连接卷积核大小为1x1的卷积层、PreLu激活函数层、卷积核大小为3x3的卷积层、PreLu激活函数层、卷积核大小为1x1的卷积层、PReLU激活函数层作为特征提取模块,基于该结构,在卷积核大小为3x3的卷积层上平行添加一个卷积核大小为1x1的卷积层和一个恒等映射分支,并在每个分支结尾加上一个批归一化层,构成基础多分支模块。通过堆叠多个该多分支结构为基础构成四个网络模块组成的神经网络,称为第一神经网络,该模型可由结构重参数化方法等价转换为参数量更少的单分支模型。
在模型推理阶段,基于以上多分支结构的特征提取模块组成的第一神经网络由结构重参数化方法等价转换为参数量更少的由单分支特征提取模块组成的模型。通过结构重参数化方法将多分支结构转化为基于单分支结构组成的模型的具体做法为:
a)将全连通分支等价转换为1x1卷积层,该卷积层以单位矩阵为卷积核,从而确保恒等映射。
b)将1x1卷积等价转化为3x3卷积层,该卷积层的卷积核以1x1卷积层为基础,在周围填充0。
c)将批归一化层的均值μ
d)将三个3x3卷积层的权重和偏置值相加,即可得到最终转换后的一个3x3卷积层。
通过在训练时使用一个多分支模型,该模型由四个特征提取模块组成,四个特征提取模块分别由1、2、6、3个上述多分支结构堆叠而成。再通过上述步骤将该多分支模型等价转换为单路架构模型,从而成功解耦训练时和推理时的架构,可以同时利用多分支模型和单路架构模型的优势,在不提高模型复杂度的情况下,提高模型所学习到的信息。
(b)将第1-4特征提取模块输出特征融合后,通过欺骗特征提取器获得第一像素级特征图,并通过对比该图与根据标签生成的像素级标签图来监督模型训练。
将第一网络模块输出特征图下采样到第二网络模块输出特征图特效,并将第三、四网络模块输出特征图上采样到第二网络模块输出特征图大小,最后将四个特征图按通道进行拼接融合,获得第一融合特征图。
依次连接卷积核大小为1x1的卷积层、批归一化层、ReLU激活函数层、卷积核大小为1x1的卷积层构成第一欺骗特征提取器,将第一融合特征图输入该欺骗特征提取器后获得第一像素级特征图。
同时,根据输入人脸图像的真实标签,构建一张与该欺骗特征图大小相同的像素级标签图,当输入图像为活体人脸时,该像素级标签图内的值全为1,而当输入图像为伪造攻击人脸时,该像素级标签图内的值全为0。
最后,通过像素级监督损失函数
(c)预训练一个大模型作为第二神经网络,获得第二像素级特征图与第二活体判别结果。
预训练一个较大模型(如ResNet34)作为第二神经网络,将输入第一神经网络的人脸图像同时输入第二神经网络,经由类同第一神经网络的多尺度特征融合方式获得第二融合特征图。并构造与第一欺骗特征提取器结构相同的第二欺骗特征提取器,将第二融合特征图输入第二欺骗特征提取器获得第二像素级特征图。最后在该较大模型结尾加上一个全连接层,将网络输出的最末特征图转换为第二活体判别结果。
作为另一种实施例,是第二神经网络为ResNet34。
(d)基于多尺度知识蒸馏,分别通过对比第一像素级特征图与第二像素级特征图,以及对比第一、第二活体判别结果来监督模型训练。
为了进一步利用像素级监督方案有效提取更细粒度本质欺骗特征,并基于均方误差损失函数
此外,基于KL散度损失函数
最终引入Focal损失函数
其中,α、β、γ分别为像素级监督损失函数、均方误差损失函数
上述技术方案仅体现了本发明技术方案的优选技术方案,本技术领域的技术人员对其中某些部分所可能做出的一些变动均体现了本发明的原理,属于发明的保护范围之内。
- 具有提高的开口率的有机发光二极管显示器
- 一种有机发光二极管显示器的制作方法
- 有机发光二极管显示器及其制造方法
- 具有减少的侧向泄漏的有机发光二极管显示器
- 具有减少的侧向泄漏的有机发光二极管显示器