表情动画的生成方法、装置、设备、存储介质及程序产品
文献发布时间:2024-04-18 20:01:23
技术领域
本申请实施例涉及人工智能技术领域,特别涉及一种表情动画的生成方法、装置、设备、存储介质及程序产品。
背景技术
随着人工智能技术的发展,可以通过虚拟角色代替真实用户,并使得虚拟角色的面部表情跟随真实用户的语音信号变化,以使得虚拟角色与真实用户呈现相同的表情变化。
相关技术中,为使得虚拟角色的表情动画与输入语音信号同步,从而实现自然、逼真的视觉效果。使用预训练的神经网络模型从输入的语音信号中提取特征;再根据提取到的特征计算得到相应的口型参数,如嘴部开合程度、舌头位置等;最后,根据口型参数生成表情动画,从而使虚拟角色的表情动画与输入语音信号同步。
然而,由于不同的虚拟角色的模型之间存在差异,神经网络模型生成的表情动画对于不同的虚拟角色的适应性较差。
发明内容
本申请提供了一种表情动画的生成方法、装置、设备、存储介质及程序产品,所述技术方案如下:
根据本申请的一方面,提供了一种表情动画的生成方法,所述方法包括:
获取语音文件对应的音素序列,所述语音文件用于表示生成所述表情动画的音频文件和文本文件中的至少一种,所述音素序列包括至少一个音素,每个音素与所述表情动画中的一个表情动作相对应,所述音素是用于表示语音信息的基本单位;
根据所述音素序列中的所述至少一个音素生成所述表情动画中的关键帧对应的动画参数,所述动画参数是指虚拟角色的表情动作的参数;
根据所述关键帧对应的所述动画参数生成所述语音文件对应的动画序列,所述动画序列是播放所述虚拟角色的所述表情动画的帧序列。
根据本申请的一方面,提供了一种表情动画的生成装置,所述装置包括:
获取模块,用于获取语音文件对应的音素序列,所述语音文件用于表示生成所述表情动画的音频文件和文本文件中的至少一种,所述音素序列包括至少一个音素,每个音素与所述表情动画中的一个表情动作相对应,所述音素是用于表示语音信息的基本单位;
生成模块,用于根据所述音素序列中的所述至少一个音素生成所述表情动画中的关键帧对应的动画参数,所述动画参数是指虚拟角色的表情动作的参数;
所述生成模块,用于根据所述关键帧对应的所述动画参数生成所述语音文件对应的动画序列,所述动画序列是播放所述虚拟角色的所述表情动画的帧序列。
根据本申请的另一方面,提供了一种计算机设备,该计算机设备包括:处理器和存储器,存储器中存储有至少一条计算机程序,至少一条计算机程序由处理器加载并执行以实现如上方面所述的表情动画的生成方法。
根据本申请的另一方面,提供了一种计算机存储介质,计算机可读存储介质中存储有至少一条计算机程序,至少一条计算机程序由处理器加载并执行以实现如上方面所述的表情动画的生成方法。
根据本申请的另一方面,提供了一种计算机程序产品,上述计算机程序产品包括计算机程序,所述计算机程序存储在计算机可读存储介质中;所述计算机程序由计算机设备的处理器从所述计算机可读存储介质读取并执行,使得所述计算机设备执行如上方面所述的表情动画的生成方法。
本申请提供的技术方案带来的有益效果至少包括:
通过获取语音文件并对语音文件进行解析,得到语音文件对应的音素序列,音素序列包括至少一个音素;根据音素序列中的至少一个音素生成表情动画中的关键帧对应的动画参数;根据关键帧对应的动画参数生成语音文件对应的动画序列。本申请提供了一种新的表情动画生成方法,直接从语音文件出发,通过解析语音文件得到的音素序列中的音素生成关键帧对应的动画参数,基于关键帧对应的动画参数生成播放表情动画的动画序列,通过该方法不仅适应不同的虚拟角色,还大大提高了动画序列的生成效率。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本申请一个示例性实施例提供的一种表情动画的生成方法的示意图;
图2是本申请一个示例性实施例提供的计算机系统的架构示意图;
图3是本申请一个示例性实施例提供的表情动画的生成方法的流程图;
图4是本申请一个示例性实施例提供的表情动画的生成方法的流程图;
图5是本申请一个示例性实施例提供的音频转文本插件的界面示意图;
图6是本申请一个示例性实施例提供的音频转文本插件的配置界面示意图;
图7是本申请一个示例性实施例提供的文本转音频插件的界面示意图;
图8是本申请一个示例性实施例提供的文本转音频插件的配置界面示意图;
图9是本申请一个示例性实施例提供的创建第一动画序列的界面示意图;
图10是本申请一个示例性实施例提供的第一动画序列的配置界面示意图;
图11是本申请一个示例性实施例提供的搜索USound Wave的源文件位置的示意图;
图12是本申请一个示例性实施例提供的构建第二动画序列的示意图;
图13是本申请一个示例性实施例提供的表情动画的生成方法的流程图;
图14是本申请一个示例性实施例提供的表情动画的生成方法的流程图;
图15是本申请一个示例性实施例提供的表情动画的生成装置的框图;
图16是本申请一个示例性实施例提供的计算机设备的结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。
在本公开使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本公开。在本公开和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
应当理解,尽管在本公开可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。
为了便于理解,下面对本申请涉及的几个名词进行解释。
人工智能(Artificial Intelligence,AI)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、预训练模型技术、操作/交互系统、机电一体化等。其中,预训练模型又称大模型、基础模型,经过微调后可以广泛应用于人工智能各大方向下游任务。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
云技术(Cloud technology)是指在广域网或局域网内将硬件、软件、网络等系列资源统一起来,实现数据的计算、储存、处理和共享的一种托管技术。
云技术(Cloud technology)基于云计算商业模式应用的网络技术、信息技术、整合技术、管理平台技术、应用技术等的总称,可以组成资源池,按需所用,灵活便利。云计算技术将变成重要支撑。技术网络系统的后台服务需要大量的计算、存储资源,如视频网站、图片类网站和更多的门户网站。伴随着互联网行业的高度发展和应用,将来每个物品都有可能存在自己的识别标志,都需要传输到后台系统进行逻辑处理,不同程度级别的数据将会分开处理,各类行业数据皆需要强大的系统后盾支撑,只能通过云计算来实现。
云计算(Cloud computing)是一种计算模式,它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。提供资源的网络被称为“云”。“云”中的资源在使用者看来是可以无限扩展的,并且可以随时获取,按需使用,随时扩展,按使用付费。
作为云计算的基础能力提供商,会建立云计算资源池(简称云平台,一般称为IaaS(Infrastructure as a Service,基础设施即服务)平台,在资源池中部署多种类型的虚拟资源,供外部客户选择使用。云计算资源池中主要包括:计算设备(为虚拟化机器,包含操作系统)、存储设备、网络设备。
按照逻辑功能划分,在IaaS(Infrastructure as a Service,基础设施即服务)层上可以部署PaaS(Platform as a Service,平台即服务)层,PaaS层之上再部署SaaS(Software as a Service,软件即服务)层,也可以直接将SaaS部署在IaaS上。PaaS为软件运行的平台,如数据库、Web(World Wide Web,全球广域网)容器等。SaaS为各式各样的业务软件,如web门户网站、短信群发器等。一般来说,SaaS和PaaS相对于IaaS是上层。
计算机视觉技术(Computer Vision,CV)是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取信息的人工智能系统。大模型技术为计算机视觉技术发展带来重要变革,swin-transformer,ViT,V-MOE,MAE等视觉领域的预训练模型经过微调(fine tune)可以快速、广泛适用于下游具体任务。计算机视觉技术通常包括图像处理、图像识别、图像语义理解、图像检索、OCR、视频处理、视频语义理解、视频内容/行为识别、三维物体重建、3D技术、虚拟现实、增强现实、同步定位与地图构建等技术,还包括常见的生物特征识别技术。
机器学习(Machine Learning,ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、示教学习等技术。预训练模型是深度学习的最新发展成果,融合了以上技术。
本申请实施例提供了一种表情动画的生成方法的示意图,如图1所示,该方法应可以由计算机设备执行,计算机设备可以是终端或服务器。
示例性地,计算机设备通过获取语音文件10对应的音素序列20;计算机设备根据音素序列20中的至少一个音素生成表情动画中的关键帧对应的动画参数30,动画参数30是指虚拟角色的表情动作的参数;计算机设备根据关键帧对应的动画参数30生成语音文件10对应的动画序列40。
语音文件10用于表示生成表情动画的信息文件。
可选地,语音文件10包括音频文件101、文本文件102中的至少一种,但不限于此,本申请实施例对此不作具体限定。
音频文件101是指虚拟角色所表达语句的音频信息。
文本文件102是指虚拟角色所表达语句的文字或拼音信息。
在一些实施例中,在语音文件10中存在文本文件102,但不存在音频文件101的情况下,计算机设备通过调用文本转音频插件对文本文件102进行语音合成,得到音频文件101。
在语音文件10中存在音频文件101,但不存在文本文件102的情况下,计算机设备通过调用音频转文本插件对音频文件101进行语音识别,得到文本文件102。
其中,文本转音频插件用于将文本文件102转化为音频文件101;音频转文本插件用于将音频文件101转化为文本文件102。
音素序列20包括至少一个音素,每个音素与表情动画中的一个表情动作相对应,音素是用于表示语音信息的基本单位。
可选地,音素序列20中的内容包括音素名称、音素的时间跨度、权重值中的至少一种,但不限于此,本申请实施例对此不作具体限定。
可选地,音素是根据语音的自然属性划分出来的最小语音单位,一个发音动作对应一个音素。
动画序列40是播放虚拟角色的表情动画的帧序列。
动画序列40包括表情动画在播放过程中对应的关键帧,关键帧定义了虚拟角色的动画参数,通过关键帧中动画参数的变化,从而得到表情动画。
在一些实施例中,计算机设备根据音素序列20中的n个音素生成表情动画中的n个关键帧对应的动画参数30;计算机设备根据关键帧对应的动画参数30生成关键帧;计算机设备基于生成的关键帧组合得到动画序列40。
在一些实施例中,动画参数30包括动画生成参数301和动画控制参数302中的至少一种,但不限于此,本申请实施例对此不作具体限定。
动画生成参数301是指作用于虚拟角色对应的面部骨骼模型上的参数。
动画控制参数302是指作用于面部骨骼模型对应的控制器上的控制参数,即,计算机设备通过控制器间接控制面部骨骼模型。
综上所述,本实施例提供的方法,通过获取语音文件并对语音文件进行解析,得到语音文件对应的音素序列,音素序列包括至少一个音素;根据音素序列中的至少一个音素生成表情动画中的关键帧对应的动画参数;根据关键帧对应的动画参数生成语音文件对应的动画序列。本申请提供了一种新的表情动画生成方法,直接从语音文件出发,通过解析语音文件得到的音素序列中的音素生成关键帧对应的动画参数,基于关键帧对应的动画参数生成播放表情动画的动画序列,通过该方法不仅适应不同的虚拟角色,还大大提高了动画序列的生成效率。
图2示出了本申请一个实施例提供的计算机系统的架构示意图。该计算机系统可以包括:终端100和服务器200。
终端100可以是诸如手机、平板电脑、车载终端(车机)、可穿戴设备、个人计算机(Personal Computer,PC)、车载终端、飞行器、无人售货终端等电子设备。终端100中可以安装运行目标应用程序的客户端,该目标应用程序可以是参考表情动画的生成的应用程序,也可以是提供有表情动画的生成功能的其他应用程序,本申请对此不作限定。另外,本申请对该目标应用程序的形式不作限定,包括但不限于安装在终端100中的应用程序(Application,App)、小程序等,还可以是网页形式。
服务器200可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云计算服务的云服务器、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、内容分发网络(Content DeliveryNetwork,CDN)、以及大数据和人工掌部图像识别平台等基础云计算服务的云服务器。服务器200可以是上述目标应用程序的后台服务器,用于为目标应用程序的客户端提供后台服务。
其中,云技术(Cloud technology)是指在广域网或局域网内将硬件、软件、网络等系列资源统一起来,实现数据的计算、储存、处理和共享的一种托管技术。云技术基于云计算商业模式应用的网络技术、信息技术、整合技术、管理平台技术、应用技术等的总称,可以组成资源池,按需所用,灵活便利。云计算技术将变成重要支撑。技术网络系统的后台服务需要大量的计算、存储资源,如视频网站、图片类网站和更多的门户网站。伴随着互联网行业的高度发展和应用,将来每个物品都有可能存在自己的识别标志,都需要传输到后台系统进行逻辑处理,不同程度级别的数据将会分开处理,各类行业数据皆需要强大的系统后盾支撑,只能通过云计算来实现。
在一些实施例中,上述服务器还可以实现为区块链系统中的节点。区块链(Blockchain)是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链,本质上是一个去中心化的数据库,是一串使用密码学方法相关联产生的数据块,每一个数据块中包含了一批次网络交易的信息,用于验证其信息的有效性(防伪)和生成下一个区块。区块链可以包括区块链底层平台、平台产品服务层以及应用服务层。
终端100和服务器200之间可以通过网络进行通信,如有线或无线网络。
本申请实施例提供的表情动画的生成方法,各步骤的执行主体可以是计算机设备,所述计算机设备是指具备数据计算、处理和存储能力的电子设备。以图2所示的方案实施环境为例,可以由终端100执行表情动画的生成方法(如终端100中安装运行的目标应用程序的客户端执行表情动画的生成方法),也可以由服务器200执行该表情动画的生成方法,或者由终端100和服务器200交互配合执行,本申请对此不作限定。
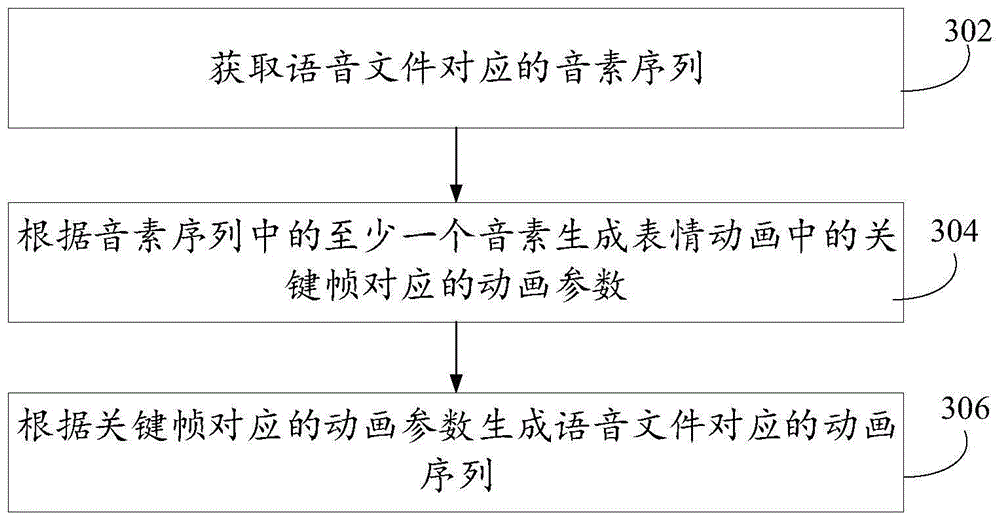
图3是本申请一个示例性实施例提供的表情动画的生成方法的流程图。该方法可以由计算机设备执行,计算机设备可以是终端或服务器。该方法包括:
步骤302:获取语音文件对应的音素序列。
语音文件用于表示生成表情动画的信息文件。
可选地,语音文件包括音频文件、文本文件中的至少一种,但不限于此,本申请实施例对此不作具体限定。
音频文件是指虚拟角色所表达语句的音频信息。
文本文件是指虚拟角色所表达语句的文字或拼音信息。
其中,获取音频文件的方式包括如下情况中的至少一种:
1、计算机设备接收音频文件,例如:终端为发起音频录制的终端,通过终端录制音频,并在录制结束后,得到音频文件。
2、计算机设备从已存储的数据库中获取音频文件,如:在音频数据库中,获取至少一个音频文件。
值得注意的是,上述获取音频文件的方式仅为示意性的举例,本申请实施例对此不加以限定。
音素序列包括至少一个音素,每个音素与表情动画中的一个表情动作相对应,音素是用于表示语音信息的基本单位。
可选地,音素序列中的内容包括音素名称、音素的时间跨度、权重值中的至少一种,但不限于此,本申请实施例对此不作具体限定。
可选地,音素是根据语音的自然属性划分出来的最小语音单位,一个发音动作对应一个音素。
步骤304:根据音素序列中的至少一个音素生成表情动画中的关键帧对应的动画参数。
表情动画是指在虚拟角色表达时具有动态变化的表情,从而更加生动真实地模拟真实人的表情。
动画参数是指虚拟角色的表情动作的参数。
例如,动画参数包括虚拟角色在表达时嘴巴的张开程度、眼睛的眨动速度、眼睛的眨动幅度等等。
关键帧用于决定动画的起始状态和结束状态,从而控制动画的节奏,也即以控制动作的节奏。
例如,确定第一关键帧的动画参数为嘴巴张开3度,第二关键帧的动画参数为嘴巴张开5度,则,通过播放第一关键帧及第二关键帧之间的帧可实现嘴巴的动态张开。
在一些实施例中,动画参数包括动画生成参数和动画控制参数中的至少一种,但不限于此,本申请实施例对此不作具体限定。
动画生成参数是指作用于虚拟角色对应的面部骨骼模型上的参数。
动画控制参数是指作用于面部骨骼模型对应的控制器上的控制参数,即,计算机设备通过控制器间接控制面部骨骼模型。
需要说明的是,本申请实施例实现了一套完整、独立的表情动画生成插件,表情动画生成插件与虚幻引擎连接,对于语音文件的音素识别步骤可以离线在表情动画生成插件中完成。
步骤306:根据关键帧对应的动画参数生成语音文件对应的动画序列。
动画序列是播放虚拟角色的表情动画的帧序列。
可选地,动画序列包括一系列关键帧,这些关键帧定义了虚拟角色在动画过程中的变化。通过播放动画序列中的帧,从而实现表情动画的播放。
示例性的,计算机设备根据动画参数调整虚拟角色的表情动作的参数,生成关键帧;计算机设备将生成的关键帧进行组合得到动画序列。
例如,在确定关键帧对应的动画参数后,根据关键帧对应的动画参数生成关键帧,或,根据关键帧对应的动画参数调整关键帧中的参数;在生成关键帧后,将生成的关键帧按照时间顺序排列生成动画序列。
综上所述,本实施例提供的方法,通过获取语音文件并对语音文件进行解析,得到语音文件对应的音素序列,音素序列包括至少一个音素;根据音素序列中的至少一个音素生成表情动画中的关键帧对应的动画参数;根据关键帧对应的动画参数生成语音文件对应的动画序列。本申请提供了一种新的表情动画生成方法,直接从语音文件出发,通过解析语音文件得到的音素序列中的音素生成关键帧对应的动画参数,基于关键帧对应的动画参数生成播放表情动画的动画序列,通过该方法不仅适应不同的虚拟角色,还大大提高了动画序列的生成效率。
图4是本申请一个示例性实施例提供的表情动画的生成方法的流程图。该方法可以由计算机设备执行,计算机设备可以是终端或服务器。该方法包括:
步骤402:获取语音文件对应的音素序列。
语音文件用于表示生成表情动画的信息文件。
可选地,语音文件包括音频文件、文本文件中的至少一种,但不限于此,本申请实施例对此不作具体限定。
音频文件是指虚拟角色所表达语句的音频信息。
文本文件是指虚拟角色所表达语句的文字或拼音信息。
音素序列包括至少一个音素,每个音素与表情动画中的一个表情动作相对应,音素是用于表示语音信息的基本单位。
可选地,音素序列中的内容包括音素名称、音素的时间跨度、权重值中的至少一种,但不限于此,本申请实施例对此不作具体限定。
可选地,音素是根据语音的自然属性划分出来的最小语音单位,一个发音动作对应一个音素。
在一些实施例中,计算机设备获取语音文件;计算机设备对音频文件和文本文件进行音素识别,得到音素序列。
可选地,在语音文件中存在音频文件,但不存在文本文件的情况下,计算机设备通过调用音频转文本插件对音频文件进行语音识别,得到文本文件。
音频转文本插件用于将音频文件转化为文本文件。
例如,如图5所示出的音频转文本插件的界面示意图,音频转文本插件可通过菜单栏中的工具(Tools)501进入,在触发菜单栏中的工具(Tools)501后,显示转化插件入口(TFCinmeatic)502;通过触发转化插件入口(TF Cinmeatic)502后显示音频转文本插件503。在触发音频转文本插件503后,显示如图6所示出的音频转文本插件的配置界面示意图,在界面中显示包括输入文件目录(Input Directory)601、输出文件目录(Output Directory)602和表情动画生成对应的骨骼模型(Skeleton)603,通过触发输入文件目录601可选择对应的音频文件,通过触发输出文件目录602可查看输出的文件。
可选地,在语音文件中存在文本文件,但不存在音频文件的情况下,计算机设备通过调用文本转音频插件对文本文件进行语音合成,得到音频文件。
文本转音频插件用于将文本文件转化为音频文件。
例如,如图7所示出的文本转音频插件的界面示意图,文本转音频插件可通过菜单栏中的工具(Tools)701进入,在触发菜单栏中的工具(Tools)701后,显示转化插件入口(TFCinmeatic)702;通过触发转化插件入口(TFCinmeatic)702后显示文本转音频插件703。在触发文本转音频插件703后,显示如图8所示出的文本转音频插件的配置界面示意图,在界面中显示包括语音合成使用的语言801、语音合成使用的音色802、输入文本文件路径(Input Text Path)803、输入文本文件(Input Text)804、默认后缀805、输出路径806中的至少一种,但不限于此。通过触发语音合成使用的语言801可选择语音合成所使用的语言;在选择好所使用的语言后,可选择语音合成所使用的音色。在选择好输入文本文件路径后,可自动读取文本文件中的内容,并可修改。
在一些实施例中,音素识别的过程包括:计算机设备对音频文件进行特征提取,得到音频文件对应的频谱信息;计算机设备将文本文件进行拆分,得到文本文件对应的音素列表;计算机设备将频谱信息和音素列表进行对齐,得到音素在音频文件中的位置信息;计算机设备基于音素及位置信息构成音素序列。
在一些实施例中,在生成作用于控制器上的动画控制参数的情况下,所使用的语音文件的获取步骤包括:计算机设备获取虚拟角色对应的音频轨道;计算机设备对虚拟角色对应的音频轨道进行音频读取,得到音频文件;计算机设备通过调用音频转文本插件对音频文件进行语音识别,得到文本文件;通过读取的音频文件和语音识别得到的文本文件,组成语音文件。基于文本文件和音频文件进行音素识别得到语音文件对应的音素序列,该方法直接从语音文件出发,通过语音信息中最小的语音单位“音素”来对虚拟角色的表情进行调整,提升了表情动画的生成质量。
可选地,音频轨道包括主音频轨道和子音频轨道。
主音频轨道与虚拟角色列表中的至少一个虚拟角色相对应,或,主音频轨道与虚拟角色列表中的所有虚拟角色相对应,也即,主音频轨道能够对应多个虚拟角色。
子音频轨道与虚拟角色列表中的单个虚拟角色一一对应,也即,子音频轨道仅对应一个虚拟角色。
在一些实施例中,计算机设备将虚拟角色对应的主音频轨道和子音频轨道进行合并,得到虚拟角色对应的音频轨道。
步骤404:根据音素序列中的至少一个音素生成表情动画中的关键帧对应的作用于面部骨骼模型上的动画生成参数。
表情动画是指在虚拟角色表达时具有动态变化的表情,从而更加生动真实地模拟真实人的表情。
关键帧用于决定动画的起始状态和结束状态,从而控制动画的节奏,也即以控制动作的节奏。
动画生成参数是指作用于虚拟角色对应的面部骨骼模型上的参数。
在一些实施例中,计算机设备基于至少一个音素与骨骼参数变化幅值之间的对应关系,确定关键帧对应的动画生成参数。通过音素序列中的至少一个音素生成作用于虚拟角色对应的面部骨骼模型上的动画生成参数,基于直接作用于面部骨骼模型上的动画生成参数调整虚拟角色的表情,该方法直接从语音文件出发,调整虚拟角色的面部骨骼参数,不仅适应不同的虚拟角色,还大大提高了动画序列的生成效率、降低了表情动画的生成成本。
动画生成参数用于直接调整面部骨骼模型。
可选地,动画生成参数包括嘴巴幅值参数和眼睛幅值参数中的至少一种,但不限于此,本申请实施例对此不作具体限定。
嘴巴幅值参数用于表示面部骨骼模型上的嘴巴的张开幅值。
计算机设备基于音素与嘴巴参数变化幅值列表之间的对应关系,确定关键帧对应的嘴巴幅值参数。
嘴巴幅值参数用于直接调整面部骨骼模型上的嘴巴。
嘴巴参数变化幅值列表中包括音素与嘴巴参数变化幅值之间的对应关系,通过确定音素便可查询对比确定嘴巴参数变化幅值。
眼睛幅值参数用于表示面部骨骼模型上的眼睛的张开幅值。
计算机设备基于音素与眼睛参数变化幅值列表之间的对应关系,确定关键帧对应的眼睛幅值参数。
眼睛幅值参数用于直接调整面部骨骼模型上的眼睛。
眼睛参数变化幅值列表中包括音素与眼睛参数变化幅值之间的对应关系,通过确定音素便可查询对比确定眼睛参数变化幅值。
步骤406:根据关键帧对应的动画生成参数生成语音文件对应的第一动画序列。
第一动画序列(也可称为动画生成序列AnimSequence)是指包括由动画生成参数生成的关键帧的帧序列,即,第一动画序列中的表情动画都是动画生成参数直接作用于虚拟角色对应的面部骨骼模型得到的。
比如,在调整眼睛时,计算机设备直接调整面部骨骼模型上的眼睛的参数,通过直接调整面部骨骼模型上的眼睛的参数实现对眼睛的调整。
示例性地,计算机设备根据关键帧对应的动画生成参数调整虚拟角色的表情动作的参数,生成动画生成关键帧;计算机设备将生成的动画生成关键帧进行组合得到第一动画序列。
示例性地,如图9所示出的创建第一动画序列的界面示意图,图中显示了第一动画序列的创建入口,响应于触发音频工具控件(TF Sound Wave Tools)901显示第一动画序列的创建对话框(Generate Anim Sequence)902;响应于创建对话框(Generate AnimSequence)902的触发操作,显示如图10所示出的第一动画序列的配置界面示意图,图中包括音频文件的路径、音频文本、骨骼模型、动画曲线生成配置等等。
如图10所示,动画曲线包括了关键帧对应的动画生成参数,即,动画曲线的横坐标为关键帧,动画曲线的纵坐标为动画生成参数。动画曲线生成配置包括选择的骨骼模型(Skeleton)。是否选择调试版的第三方曲线生成工具(Third Party Curve GeneratorEnabled),在选中第三方曲线生成工具的情况下,插件将根据配置调用指定的python脚本来生成动画曲线,方便快速修改算法,调试效果。强制重新加载面部动画生成配置表格(Force Reload Facial Configs),该功能在外部参数表格发生变化时使用。选择支持的骨骼模型的名称(Model Name)。在同一绑定方案之下,可以根据寻角色的不同进行单独配置参数,通过子模型名称(Sub Model Name)进行虚拟角色的区别。
动画曲线生成过程中的可动态调整的参数包括以下参数中的至少一种,但不限于此:
嘴巴张开幅度缩放值(Jaw Open Scale)、头部运动幅度缩放值(Head MoveScale)、眨眼幅度缩放值(Blink Scale)、眨眼速度缩放值(Blink Speed Scale)、情绪标签(Emotion Tag),从预设的列表里选择,供测试情绪叠加效果、用于混合的情绪资源(Emotion Pose Asset),从表情库中选择,供测试情绪叠加效果、优先级比Emotion Tag高、情绪幅度(Emotion Scale)、单一视素最长时间跨度(Max Viseme Duration),超过后进行拆分,视素是指音素的可视化表示、视素时间偏移(Prediction Delay)、开启AU移动速度限制优化(Enable Speed Limit Optimize),默认开启,测试时可以关闭用于对比效果、开启曲线抖动优化(Enable Tremble Optimize),默认开启,测试时可以关闭用于对比效果。
本申请实施例实现了一套完整、独立的表情动画生成插件,表情动画生成插件与虚幻引擎连接,表情动画生成插件在读取虚幻引擎中的第一格式下的音频文件(USoundWave)后,会自动搜索同名的第二格式下的音频文件(Wav文件),其中,第一格式为虚幻引擎对应的格式,第二格式为通用格式,U为虚幻引擎的命名规则,在文件名前加一个U。在搜索同名的Wav文件时会优先搜索USound Wave的源文件位置,如图11所示出的搜索USoundWave的源文件位置的示意图,在图中显示USound Wave对应的源文件位置1101。在USoundWave对应的源文件位置中不存在的情况下,则搜索USound Wave所在的目录;若USoundWave所在的目录还不存在Wav文件的情况下,则将USound Wave导出至临时文件夹中进行格式转换得到Wav文件。
步骤408:根据音素序列中的至少一个音素生成表情动画中的关键帧对应的作用于控制器上的动画控制参数。
动画控制参数是指作用于面部骨骼模型对应的控制器上的控制参数,即,计算机设备通过控制器间接控制面部骨骼模型。
控制器是用于控制虚拟角色的外观、动作和表情中的至少一种工具。
可选地,控制器包括面部表情控制器、身体动作控制器、嘴巴控制器、眼睛控制器、皮肤纹理和颜色控制器、发型和服装控制器中的至少一种,但不限于此,本申请实施例对此不作具体限定。
面部表情控制器用于调整虚拟角色的面部表情,如鼻子、眉毛等部位的形状和位置,以表达不同的情绪和反应。
身体动作控制器用于控制虚拟角色的身体动作,如行走、跑步、跳跃等。身体动作控制器通常使用预设的动画控制参数或实时捕捉的动画控制参数来驱动虚拟角色的动作。
嘴巴控制器用于根据虚拟角色的语音来调整其口型,使其与语音同步。
皮肤纹理和颜色控制器用于调整虚拟角色的皮肤纹理和颜色,以实现不同的纹理和细节效果。
发型和服装控制器用于调整虚拟角色的发型、服装和配饰,以实现不同的外观风格和个性特征。
通过控制上述控制器,设计师或用户可以轻松地创建和操纵逼真的虚拟角色,以满足各种应用场景的需求。
在一些实施例中,计算机设备基于至少一个音素与控制器参数变化幅值之间的对应关系,确定关键帧对应的动画控制参数。通过音素序列中的至少一个音素生成作用于面部骨骼模型对应的控制器上的动画控制参数,通过调节面部骨骼模型对应的控制器的参数间接调整虚拟角色的表情,该方法不仅适应不同的虚拟角色,还大大提高了动画序列的生成效率、降低了表情动画的生成成本。
动画控制参数用于直接调整控制器。
可选地,动画控制参数包括嘴巴控制器参数和眼睛控制器参数中的至少一种,但不限于此,本申请实施例对此不作具体限定。
嘴巴控制器参数用于表示面部骨骼模型上的嘴巴对应的嘴巴控制器的参数。
计算机设备基于音素与嘴巴控制器参数变化幅值列表之间的对应关系,确定关键帧对应的嘴巴控制器参数。
嘴巴控制器参数用于调整嘴巴控制器。
嘴巴控制器参数变化幅值列表中包括音素与嘴巴参数变化幅值之间的对应关系,通过确定音素便可查询对比确定嘴巴控制器的参数变化。
眼睛控制器参数用于表示面部骨骼模型上的眼睛对应的眼睛控制器的参数。
计算机设备基于音素与眼睛控制器参数变化幅值列表之间的对应关系,确定关键帧对应的眼睛控制器参数。
眼睛控制器参数用于调整眼睛控制器。
眼睛控制器参数变化幅值列表中包括音素与眼睛参数变化幅值之间的对应关系,通过确定音素便可查询对比确定眼睛控制器的参数变化。
步骤410:根据关键帧对应的动画控制参数生成语音文件对应的第二动画序列。
第二动画序列(也可称为关卡序列LevelSequence)是指包括由动画控制参数生成的关键帧的帧序列,即,第二动画序列中的表情动画都是动画控制参数作用于面部骨骼模型对应的控制器上得到的。
比如,在调整眼睛时,计算机设备需要调整面部骨骼模型上的眼睛对应的眼睛控制器参数,通过调整眼睛控制器的参数的方式实现对眼睛的调整。
示例性地,计算机设备根据关键帧对应的动画控制参数调整虚拟角色的表情动作的参数,生成动画控制关键帧;计算机设备将生成的动画控制关键帧进行组合得到第二动画序列。
例如,如图12所示出的构建第二动画序列的示意图,构建第二动画序列的可视化流程为:创建第二动画序列、添加虚拟角色、添加音频轨道、点击工具栏打开生成界面、调整参数后生成第二动画序列。如图12所示,最上面的音频轨道是全局的主音频轨道(MasterTrack)1201,对所有的虚拟角色有效;下面的音频轨道(子音频轨道)分别是虚拟角色1和虚拟角色2这两个角色各自对应的音频轨道。
在一些实施例中,计算机设备对语音文件进行解析,得到头部运动信息;计算机设备根据头部运动信息生成表情动画中的关键帧对应的头部位置参数;计算机设备根据动画参数(动画生成参数或动画控制参数)调整面部骨骼模型,以及根据头部位置参数调整头部骨骼模型,生成关键帧。通过获取头部运动信息,根据动画参数调整面部骨骼模型,以及根据头部位置参数调整头部骨骼模型,实现了对面部表情和头部运动信息的共同调节,使得生成的动画表情更加地逼真、动人。
头部运动信息用于表示虚拟角色的头部在表情动画中的头部位置变化信息。
头部位置参数是指作用于虚拟角色对应的头部骨骼模型上的参数。
示例性地,计算机设备将关键帧对应的动画参数及头部位置参数进行组合后调整虚拟角色的表情动作的参数,生成关键帧。
综上所述,本实施例提供的方法,通过获取语音文件并对语音文件进行解析,得到语音文件对应的音素序列,音素序列包括至少一个音素;根据音素序列中的至少一个音素生成表情动画中的关键帧对应的动画参数;根据关键帧对应的动画参数生成语音文件对应的动画序列。本申请提供了一种新的表情动画生成方法,直接从语音文件出发,通过解析语音文件得到的音素序列中的音素生成关键帧对应的动画参数,基于关键帧对应的动画参数生成播放表情动画的动画序列,通过该方法不仅适应不同的虚拟角色,还大大提高了动画序列的生成效率、降低了表情动画的生成成本。
此外,本实施例提供的方法实现了完整的表情动画生成、调试的工具链,可以帮助美术、策划等快速、低成本、高质量的生成虚拟角色的表情动画资源。同时,支持从音频文件或者文本文件出发,填充替代参数,能够将原本需要一个一天的表情动画制作工作量,降低到几分钟,帮助游戏剧情得到快速地制作、迭代。
图13是本申请一个示例性实施例提供的表情动画的生成方法的流程图。该方法可以由计算机设备执行,计算机设备可以是终端或服务器。计算机设备中包括虚幻引擎,本申请实施例实现了一套完整、独立的表情动画生成插件,表情动画生成插件与虚幻引擎连接。该方法包括:
步骤1301:在虚幻引擎中查找UsoundWave。
示例性地,图中的圆形用以表示用户操作入口,不同的入口应对不同的需求。通过USound Wave右键菜单入口,表情动画生成插件可在读取虚幻引擎中的第一格式下的音频文件(USound Wave)。
其中,第一格式为虚幻引擎对应的格式,第二格式为通用格式,U为虚幻引擎的命名规则,在文件名前加一个U。
步骤1302:查找对应的Wav文件。
示例性地,表情动画生成插件在读取虚幻引擎中的第一格式下的音频文件(USound Wave)后,会自动搜索同名的第二格式下的音频文件(Wav文件),第二格式为通用格式。
可选地,在搜索同名的Wav文件时会优先搜索USound Wave的源文件位置,在USound Wave对应的源文件位置中不存在的情况下,则搜索USound Wave所在的目录。
步骤1303:是否存在Wav文件。
示例性地,判断是否存在第二格式下的音频文件(Wave文件),在存在Wav文件的情况下,执行步骤1305;在不存在Wav文件的情况下,执行步骤1304。
步骤1304:在临时文件夹中将USoundWave进行格式转化。
示例性地,在搜索同名的Wav时会优先搜索USound Wave的源文件位置;在USoundWave对应的源文件位置中不存在的情况下,则搜索USound Wave所在的目录;若USoundWave所在的目录还不存在Wav的情况下,则将USound Wave导出至临时文件夹中进行格式转换。
步骤1305:得到Wav文件。
示例性地,将USound Wave导出至临时文件夹中进行格式转换得到Wav文件。
步骤1306:将Wav文件转化格式后导入至虚幻引擎中。
示例性地,在得到Wav文件后,将Wav文件进行格式转化后导入至虚幻引擎中。
步骤1307:查找对应的文本文件。
示例性地,在得到Wav文件后,查找与Wav文件对应的文本文件。
步骤1308:是否存在文本文件。
示例性地,判断是否存在文本文件,在不存在文本文件的情况下,执行步骤1309;在存在文本文件的情况下,执行步骤1310。
步骤1309:语音识别。
示例性地,在不存在Wav文件对应的文本文件的情况下,对Wav文件进行语音识别处理。
步骤1310:得到文本文件。
示例性地,在不存在Wav文件对应的文本文件的情况下,对Wav文件进行语音识别处理,得到文本文件。
步骤1311:语音合成。
示例性地,在存在文本文件,但存在Wav文件的情况下,对文本文件进行语音合成处理,得到Wav文件;在得到语音合成的Wav文件后,执行步骤1306。
步骤1312:音素识别。
示例性地,在同时得到Wav文件和文本文件后,对音频文件和文本文件进行音素识别,得到音素序列。
音素序列包括至少一个音素,每个音素与表情动画中的一个表情动作相对应,音素是用于表示语音信息的基本单位。
在一些实施例中,通过对音频文件进行特征提取,得到音频文件对应的频谱信息;计算机设备将文本文件进行拆分,得到文本文件对应的音素列表;计算机设备将频谱信息和音素列表进行对齐,得到音素在音频文件中的位置信息;计算机设备基于音素及位置信息构成音素序列。
步骤1313:文本格式中间文件。
示例性地,在得到音素序列的情况下,将音素序列进行格式转化,得到文本格式中间文件。
步骤1314:导入用户设备。
示例性地,将格式转化后的文本格式中间文件导入用户设备。
步骤1315:音频生成数据资产文件。
示例性地,将格式转化后的文本格式中间文件导入用户设备中保存至音频生成数据资产文件(UTFAudioGeneratedDataAsset)中。
在得到音频生成数据资产文件(UTFAudioGeneratedDataAsset)后,既可通过弹出窗口,指定骨骼模型的名称,调整参数,生成第一动画序列。
在一些实施例中,针对音频生成数据资产文件(UTFAudioGeneratedDataAsset)的格式设计,UTFAudioGeneratedDataAsset中的数据结构包括以下中的至少一种:
数据时间跨度(Fnameed Time Span)。数据时间跨度中包括数据名称、数据起始时间、数据结束时间和权重,可用于表示音素、视素的时间跨度。
可选地,数据时间跨度(Fnameed Time Span)的代码可表示为:
头部运动信息(FAudioHeadMovementInfo),用于存储从音频文件中生成的头部运动信息,包括起始时间,头部的偏航角Yaw、头部的翻滚角Roll、头部的俯仰角Pitch。
头部的偏航角Yaw是指头部围绕Y轴旋转的角。
头部的翻滚角Roll是指头部围绕Z轴旋转的角。
头部的俯仰角Pitch是指头部围绕X轴旋转的角。
可选地,头部运动信息(FAudioHeadMovementInfo)的代码可表示为:
音频生成数据(FTFAudioGeneratedData),用于存储了音素序列、情绪标签列表、头部运动信息等。
可选地,音频生成数据(FTFAudioGeneratedData)的代码可表示为:
/>
音频生成数据文件(UTFAudioGeneratedDataAsset),用于存储以上信息的UAsset类型。
可选地,音频生成数据文件(UTFAudioGeneratedDataAsset)的代码可表示为:
将UTFAudioGeneratedDataAsset注册到虚幻引擎,需要派生出资产类型操作库(FAssetTypeActions_Base)。
可选地,派生资产类型操作库(FAssetTypeActions_Base)的代码可表示为:
/>
在派生资产类型操作库(FAssetTypeActions_Base)后,并在表情动画生成插件中国进行注册。
可选地,在表情动画生成插件中进行注册的代码可表示为:
在表情动画生成插件中注册完成后,既可完成对UTF Audio Generated DataAsset的创建、编辑支持。
步骤1316:调整动画生成曲线的参数。
动画曲线包括了关键帧对应的动画生成参数,即,动画曲线的横坐标为关键帧,动画曲线的纵坐标为动画生成参数。
示例性地,在确定语音文件对应的音素序列并保存至音频生成数据资产文件后,根据音素序列中的至少一个音素生成表情动画中的关键帧对应的动画参数,根据关键帧对应的动画参数调整动画生成曲线中各个关键帧的参数。
步骤1317:生成动画生成曲线。
示例性地,在根据关键帧对应的动画参数调整动画生成曲线中各个关键帧的参数后,生成动画生成曲线。
步骤1318:生成第一动画序列。
示例性地,基于动画生成曲线中的关键帧得到第一动画序列。
图14是本申请一个示例性实施例提供的表情动画的生成方法的流程图。该方法可以由计算机设备执行,计算机设备可以是终端或服务器。计算机设备中包括虚幻引擎,本申请实施例实现了一套完整、独立的表情动画生成插件,表情动画生成插件与虚幻引擎连接。该方法包括:
步骤1401:第二动画序列。
示例性地,图中的圆形用以表示用户操作入口,通过点击序列工具栏扩展按钮,可以打开第二动画序列的生成对话框。
可选地,在打开第二动画序列的生成对话框后,将自动读取已有的第二动画序列中的信息。
步骤1402:读取主音频轨道。
主音频轨道与虚拟角色列表中的至少一个虚拟角色相对应,或,主音频轨道与虚拟角色列表中的所有虚拟角色相对应,也即,主音频轨道能够对应多个虚拟角色。
示例性地,计算机设备对虚拟角色列表中的所有虚拟角色有效的主音频轨道。
步骤1403:读取虚拟角色。
示例性地,在计算机设备读取主音频轨道后,接着读取虚拟角色列表中的虚拟角色,从而确定虚拟角色。
可选地,读取虚拟角色列表中的虚拟角色包括读取骨骼模型(USkeletalMeshComponent)、场景配置参数(UMovieSceneControlRigParameterTrack)、音频文件参数(UMovieSceneAudioSection)。
步骤1404:读取子音频轨道。
子音频轨道与虚拟角色列表中的单个虚拟角色一一对应,也即,子音频轨道仅对应一个虚拟角色。
示例性地,在读取确定虚拟角色后,读取各个虚拟角色对应的子音频轨道。
步骤1405:生成第二动画序列的配置文件。
示例性地,在读取主音频轨道、虚拟角色、子音频轨道后,对所读取的信息进行吹,生成第二动画序列的配置文件。
步骤1406:对音频文件进行解析。
示例性地,计算机设备获取虚拟角色对应的音频轨道;计算机设备对虚拟角色对应的音频轨道进行音频读取,得到音频文件;计算机设备通过调用音频转文本插件对音频文件进行语音识别,得到文本文件;通过读取的音频文件和语音识别得到的文本文件,组成语音文件。计算机设备对语音文件进行音素识别,得到语音文件对应的音素序列。
步骤1407:调整控制器参数。
示例性地,计算机设备根据音素序列中的至少一个音素,生成表情动画中的关键帧对应的动画控制参数。
其中,动画控制参数用于直接调整控制器的参数。
步骤1408:重新填充第二动画序列中的参数。
示例性地,计算机设备基于动画控制参数重新填充第二动画序列中的参数。
步骤1409:清除旧数据。
示例性地,计算机设备在基于动画控制参数重新填充第二动画序列中的参数前,清除原第二动画序列中的参数。
步骤1410:填充音素序列。
步骤1411:为虚拟角色重新生成控制器的控制曲线。
控制曲线包括了关键帧对应的动画控制参数,即,动画曲线的横坐标为关键帧,动画曲线的纵坐标为动画控制参数。
示例性地,计算机设备基于动画控制参数调整动画控制曲线中各个关键帧的参数,从而生成动画生成曲线。在得到虚拟角色对应的控制曲线后,基于动画生成曲线中的关键帧得到第二动画序列。
本申请一个示例性实施例提供的表情动画的生成方法。该方法可以由计算机设备执行,计算机设备可以是终端或服务器。计算机设备中包括虚幻引擎,本申请实施例实现了一套完整、独立的表情动画生成插件,表情动画生成插件与虚幻引擎连接。该方法包括:
本申请示例性实施例基于虚幻引擎,实现了一套完整、独立的表情动画生成插件。支持在插件内从音频文件和文本文件中的至少一种生成第一动画序列也称为动画序列AnimSequence,或者第二动画序列也称为关卡序列LevelSequence。并提供了文本转语音、语音转文本服务,表情动画生成参数调整等一系列工具,帮助美术和策划能够快速生成和调整面部表情动画。
本申请示例性实施例集成了离线的音素识别工具,以及自研头部运动生成工具,提供自定义UAsset格式导入成虚幻引擎的资产,再在资产基础上,提供工具方便的调整参数,快速生成动画序列,预览结果。我们也对LevelSequence进行扩展,支持在Sequencer中显示音素及时间跨度;支持添加多个角色,多个对话,单独或者共同生成口型动画;并且LevelSequence中直接生成控制器曲线,实时驱动虚拟角色对应的面部控制器。
本申请所用方法大大提升了表情动画生成的参数可调范围,以及参数调整的直观性,加快了迭代速度,提升了效果表现。
在一些实施例中,AnimSequence生成流程的入口有四个,分别是USoundWave文件的右键菜单,Audio2Face插件面板,Text2Face插件面板,以及UTFAudioGeneratedDataAsset文件的右键菜单。
示例性的,点击USoundWave文件的右键菜单后,弹出AnimSequence创建对话框,并开始识别音频,Sound为选中的USoundWave文件,Wav File Path为自动搜索同名wav文件后的结果,其优先级为先搜索为:先搜索USoundWave文件的Source File,若Source File不存在,则搜索USoundWave所在目录,若还不存在,则将USoundWave导出为临时文件夹下的wav文件。
搜索或者导出的wav文件路径被显示在Wav File Path项,并支持重新指定。
Sound Text为wav文件同目录下对应的txt文本读取结果。若不存在,则为空,支持手工输入。
从wav和txt文件识别出来的音素以及头部运行信息被导入为UTFAudioGeneratedDataAsset文件,Audio Generated Data Asset显示了这一文件的引用,支持手工指定。
在一些实施例中,动画曲线生成相关配置包括:选择的骨骼模型(Skeleton)。是否选择调试版的第三方曲线生成工具(Third Party Curve Generator Enabled),在选中第三方曲线生成工具的情况下,插件将根据配置调用指定的python脚本来生成动画曲线,方便快速修改算法,调试效果。强制重新加载面部动画生成配置表格(Force Reload FacialConfigs),该功能在外部参数表格发生变化时使用。选择支持的骨骼模型的名称(ModelName)。在同一绑定方案之下,可以根据寻角色的不同进行单独配置参数,通过子模型名称(Sub Model Name)进行虚拟角色的区别。
动画曲线生成过程中的可动态调整的参数包括以下参数中的至少一种,但不限于此:
嘴巴张开幅度缩放值(Jaw Open Scale)、头部运动幅度缩放值(Head MoveScale)、眨眼幅度缩放值(Blink Scale)、眨眼速度缩放值(Blink Speed Scale)、情绪标签(Emotion Tag),从预设的列表里选择,供测试情绪叠加效果、用于混合的情绪资源(Emotion Pose Asset),从表情库中选择,供测试情绪叠加效果、优先级比Emotion Tag高、情绪幅度(Emotion Scale)、单一视素最长时间跨度(Max Viseme Duration),超过后进行拆分,视素是指音素的可视化表示、视素时间偏移(Prediction Delay)、开启AU移动速度限制优化(Enable Speed Limit Optimize),默认开启,测试时可以关闭用于对比效果、开启曲线抖动优化(Enable Tremble Optimize),默认开启,测试时可以关闭用于对比效果。
在一些实施例中,通过点击Audio2Face插件的入口,显示UI界面,UI界面中包括:音频文件目录(Input Directory)、输入AnimSequence文件目录(Output Directory)、骨骼模型(Skeleton)、动画曲线生成参数(Curve Generation Config)。
在一些实施例中,通过点击Audio2Face插件的入口,显示UI界面,UI界面中包括:Locale:TTS使用的语言,从下拉列表中选择;Voice:TTS使用的音色,选择好语言后,自动从网络同步可选列表;Input Text Path:输入文本文件路径;Input Text:选择输入文本文件路径后,自动读取,可修改;Default Suffix:生成的动画文件默认后缀;OutputDirectory:输出路径。
在一些实施例中,LevelSequence填充流程包括:新建LevelSequence,添加角色,添加音频轨道(可以是全局的MasterTrack(主音频轨道),或者是单个虚拟角色对应的子音频轨道LocalTrack),点击工具栏按钮打开生成界面,调整参数后,填充LevelSequence。
点击扩展后的工具栏按钮,可以打开LevelSequence生成对话框。打开后的生成对话框,将自动读取LevelSequence中的信息。LevelSequence中的信息包括:Mark Type:Sequencer中的标签类型,Phoneme是音素,Viseme是视素,根据这一配置,插件将自动在TimeLine上插入标签,以方便调试口型生成结果与实际音素是否匹配;Master AudioProcessing Configs:全局音频文件处理配置;Binding Actor Configs:自动读取的角色配置;Local Audio Generate Contents:局部音频文件的处理配置;Curve GenerationConfig:动画曲线生成参数配置。
在一些实施例中,关于UTFAudioGeneratedDataAsset格式设计。关键数据结构有:FNameedTimeSpan,成员包含名称、起始时间、结束时间和权重,可用于表示音素、视素的时间跨度;FAudioHeadMovementInfo,存储从音频文件中生成的头部运动信息,成员包含起始时间,头部的Yaw、Roll、Pitch值,眉毛的幅度值;FTFAudioGeneratedData,存储了音素列表、情绪标签列表、头部运动信息;UTFAudioGeneratedDataAsset,用于存储以上信息的UAsset类型。
在一些实施例中,AnimSequence的生成流程可以被分为音频解析和动画曲线生成两部分,音频解析阶段关注于资源文件的准备,曲线生成部分关注生成参数的调整。
在音频解析阶段,触发USoundWave右键菜单,在USoundWave文件已经存在的情况下,插件会自动查找对应的wav文件是否存在,若部存在,则自动导出wav文件到临时目录。Audio2Face插件从已有的wav文件触发,导入USoundWave文件,查找对应的文本文件是否存在,若不存在,则调用语音识别工具,识别文本,并支持手工修改。Text2Face插件从已有的文本文件触发,调用TTS服务,生成wav文件,导入成USoundWave。在音频和文本都准备齐全之后,调用音素识别工具,结果导入UE生成UTFAudioGeneratedDataAsset。
在曲线生成阶段,在得到UTFAudioGeneratedDataAsset后,既可通过弹出窗口,指定骨骼模型和模型名称,调整参数,生成AnimSequence。
在一些实施例中,LevelSequence填充的核心逻辑与AnimSequence的创建一致,代码也能够共用。其区别在于,AnimSequence的创建参数以手工配置为主,LevelSequence的填充参数则需要首先从LevelSequence中提取,再分别修改参数。
在一些实施例中,LevelSequence填充的流程包括:信息收集阶段。读取全局音频轨道,该音频对所有角色有效;读取绑定角色列表,读取USkeletalMeshComponent、读取UMovieSceneControlRigParameterTrack、读取UMovieSceneAudioSection。音频解析阶段。针对每个角色合并全局音频轨道和局部音频轨道,调用音频解析工具,生成音素列表和头部运动曲线,可使用缓存数据,不用每次都重新生成,支持强制重新生成。控制器曲线生成阶段,包括调整参数、曲线生成、曲线填充。
综上所述,本实施例提供的方法实现了完整的表情动画生成、调试的工具链,可以帮助美术、策划等快速、低成本、高质量的生成虚拟角色的表情动画资源。支持从音频文件或者文本文件出发,填充替代参数。能够将原本需要一个一天的表情动画制作工作量,降低到几分钟,帮助游戏剧情得到快速地制作、迭代。
图15示出了本申请一个示例性实施例提供的表情动画的生成装置的结构示意图。该装置可以通过软件、硬件或者两者的结合实现成为计算机设备的全部或一部分,该装置包括:
获取模块1501,用于获取语音文件对应的音素序列,所述语音文件用于表示生成所述表情动画的音频文件和文本文件中的至少一种,所述音素序列包括至少一个音素,每个音素与所述表情动画中的一个表情动作相对应,所述音素是用于表示语音信息的基本单位;
生成模块1502,用于根据所述音素序列中的所述至少一个音素生成所述表情动画中的关键帧对应的动画参数,所述动画参数是指虚拟角色的表情动作的参数;
生成模块1502,用于根据所述关键帧对应的所述动画参数生成所述语音文件对应的动画序列,所述动画序列是播放所述虚拟角色的所述表情动画的帧序列。
在一些实施例中,所述动画参数包括动画生成参数,所述动画生成参数是指作用于所述虚拟角色对应的面部骨骼模型上的参数。生成模块1502,用于根据所述音素序列中的所述至少一个音素,生成所述表情动画中的所述关键帧对应的所述动画生成参数。
在一些实施例中,生成模块1502,用于基于所述至少一个音素与骨骼参数变化幅值之间的对应关系,确定所述关键帧对应的所述动画生成参数,所述动画生成参数用于直接调整所述面部骨骼模型。
在一些实施例中,所述动画生成参数包括嘴巴幅值参数和眼睛幅值参数中的至少一种,所述嘴巴幅值参数用于表示所述面部骨骼模型上的嘴巴的张开幅值,所述眼睛幅值参数用于表示所述面部骨骼模型上的眼睛的张开幅值。生成模块1502,用于基于所述音素与嘴巴参数变化幅值列表之间的对应关系,确定所述关键帧对应的所述嘴巴幅值参数,所述嘴巴幅值参数用于直接调整所述面部骨骼模型上的嘴巴;
基于所述音素与眼睛参数变化幅值列表之间的对应关系,确定所述关键帧对应的所述眼睛幅值参数,所述眼睛幅值参数用于直接调整所述面部骨骼模型上的眼睛。
在一些实施例中,所述动画参数包括动画控制参数,所述动画控制参数是指作用于面部骨骼模型对应的控制器上的控制参数;生成模块1502,用于根据所述音素序列中的所述至少一个音素,生成所述表情动画中的所述关键帧对应的所述动画控制参数。
在一些实施例中,生成模块1502,用于基于所述至少一个音素与控制器参数变化幅值之间的对应关系,确定所述关键帧对应的所述动画控制参数,所述动画控制参数用于直接调整所述控制器。
在一些实施例中,所述动画控制参数包括嘴巴控制器参数和眼睛控制器参数中的至少一种,所述嘴巴控制器参数用于表示所述面部骨骼模型上的嘴巴对应的嘴巴控制器的参数,所述眼睛控制器参数用于表示所述面部骨骼模型上的眼睛对应的眼睛控制器的参数;生成模块1502,用于基于所述音素与嘴巴控制器参数变化幅值列表之间的对应关系,确定所述关键帧对应的所述嘴巴控制器参数,所述嘴巴控制器参数用于调整所述嘴巴控制器。
在一些实施例中,生成模块1502,用于基于所述音素与眼睛控制器参数变化幅值列表之间的对应关系,确定所述关键帧对应的所述眼睛控制器参数,所述眼睛控制器参数用于调整所述眼睛控制器。
在一些实施例中,获取模块1501,用于获取所述语音文件。
在一些实施例中,所述装置还包括音素处理模块1503,音素处理模块1503,用于对所述音频文件和所述文本文件进行音素识别,得到所述音素序列。
在一些实施例中,音素处理模块1503,用于对所述音频文件进行特征提取,得到所述音频文件对应的频谱信息;将所述文本文件进行拆分,得到所述文本文件对应的音素列表;将所述频谱信息和所述音素列表进行对齐,得到所述音素在所述音频文件中的位置信息;基于所述音素及所述位置信息构成所述音素序列。
在一些实施例中,音素处理模块1503,用于在所述语音文件中存在所述文本文件,但不存在所述音频文件的情况下,通过调用文本转音频插件对所述文本文件进行语音合成,得到所述音频文件;或,在所述语音文件中存在所述音频文件,但不存在所述文本文件的情况下,通过调用音频转文本插件对所述音频文件进行语音识别,得到所述文本文件。
其中,所述文本转音频插件用于将所述文本文件转化为所述音频文件;所述音频转文本插件用于将所述音频文件转化为所述文本文件。
在一些实施例中,获取模块1501,用于获取所述虚拟角色对应的音频轨道;对所述虚拟角色对应的所述音频轨道进行音频读取,得到所述音频文件;通过调用音频转文本插件对所述音频文件进行语音识别,得到所述文本文件。
在一些实施例中,所述音频轨道包括主音频轨道和子音频轨道,所述主音频轨道与虚拟角色列表中的至少一个所述虚拟角色相对应,所述子音频轨道与所述虚拟角色列表中的单个所述虚拟角色一一对应。获取模块1501,还用于将所述虚拟角色对应的所述主音频轨道和所述子音频轨道进行合并,得到所述音频轨道。
在一些实施例中,生成模块1502,用于根据所述动画参数调整所述虚拟角色的表情动作的参数,生成所述关键帧;将生成的所述关键帧进行组合得到所述动画序列。
在一些实施例中,所述装置还包括解析模块1504,解析模块1504,用于对所述语音文件进行解析,得到头部运动信息,所述头部运动信息用于表示所述虚拟角色的头部在所述表情动画中的头部位置变化信息;根据所述头部运动信息生成所述表情动画中的所述关键帧对应的头部位置参数,所述头部位置参数是指作用于所述虚拟角色对应的头部骨骼模型上的参数。
在一些实施例中,生成模块1502,用于根据所述动画参数调整所述面部骨骼模型,以及根据所述头部位置参数调整头部骨骼模型,生成所述关键帧。
在一些实施例中,生成模块1502,用于将所述关键帧对应的所述动画参数及所述头部位置参数进行组合后调整所述虚拟角色的所述表情动作的参数,生成所述关键帧。
图16示出了本申请一示例性实施例示出的计算机设备1600的结构框图。该计算机设备可以实现为本申请上述方案中的服务器。所述计算机设备1600包括中央处理单元(Central Processing Unit,CPU)1601、包括随机存取存储器(Random Access Memory,RAM)1602和只读存储器(Read-Only Memory,ROM)1603的系统存储器1604,以及连接系统存储器1604和中央处理单元1601的系统总线1605。所述计算机设备1600还包括用于存储操作系统1609、应用程序1610和其他程序模块1611的大容量存储设备1606。
所述大容量存储设备1606通过连接到系统总线1605的大容量存储控制器(未示出)连接到中央处理单元1601。所述大容量存储设备1606及其相关联的计算机可读介质为计算机设备1600提供非易失性存储。也就是说,所述大容量存储设备1606可以包括诸如硬盘或者只读光盘(Compact Disc Read-Only Memory,CD-ROM)驱动器之类的计算机可读介质(未示出)。
不失一般性,所述计算机可读介质可以包括计算机存储介质和通信介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质包括RAM、可擦除可编程只读寄存器(Erasable Programmable Read Only Memory,EPROM)、电子抹除式可复写只读存储器(Electrically-Erasable Programmable Read-Only Memory,EEPROM)闪存或其他固态存储其技术,CD-ROM、数字多功能光盘(Digital Versatile Disc,DVD)或其他光学存储、磁带盒、磁带、磁盘存储或其他磁性存储设备。当然,本领域技术人员可知所述计算机存储介质不局限于上述几种。上述的系统存储器1604和大容量存储设备1606可以统称为存储器。
根据本公开的各种实施例,所述计算机设备1600还可以通过诸如因特网等网络连接到网络上的远程计算机运行。也即计算机设备1600可以通过连接在所述系统总线1605上的网络接口单元1607连接到网络1608,或者说,也可以使用网络接口单元1607来连接到其他类型的网络或远程计算机系统(未示出)。
所述存储器还包括至少一段计算机程序,所述至少一段计算机程序存储于存储器中,中央处理器1601通过执行该至少一段程序来实现上述各个实施例所示的表情动画的生成方法中的全部或部分步骤。
本申请实施例还提供一种计算机设备,该计算机设备包括处理器和存储器,该存储器中存储有至少一条程序,该至少一条程序由处理器加载并执行以实现上述各方法实施例提供的表情动画的生成方法。
本申请实施例还提供一种计算机可读存储介质,该存储介质中存储有至少一条计算机程序,该至少一条计算机程序由处理器加载并执行以实现上述各方法实施例提供的表情动画的生成方法。
本申请实施例还提供一种计算机程序产品,所述计算机程序产品包括计算机程序,所述计算机程序存储在计算机可读存储介质中;所述计算机程序由计算机设备的处理器从所述计算机可读存储介质读取并执行,使得所述计算机设备执行以实现上述各方法实施例提供的表情动画的生成方法。
可以理解的是,在本申请的具体实施方式中,涉及到的数据,历史数据,以及画像等与用户身份或特性相关的用户数据处理等相关的数据,当本申请以上实施例运用到具体产品或技术中时,需要获得用户许可或者同意,且相关数据的收集、使用和处理需要遵守相关国家和地区的相关法律法规和标准。
需要说明的是,除非本文中另外明确定义,否则用于权利要求中的所有术语根据它们在技术领域中的普通含义来解释。除非另外明确叙述,否则对“一个元件、装置、部件、设备、步骤等”的所有参考将被开放地解释为指代元件、装置、部件、设备、步骤等的至少一个实例。除非明确叙述,否则本文所公开的任意方法的步骤不是必须以所公开的确切顺序来执行。
应当理解的是,在本文中提及的“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上所述仅为本申请的可选实施例,并不用以限制本申请,凡在本申请的精神和原则之内,所作的任何修改、等同切换、改进等,均应包含在本申请的保护范围之内。
- 一种具有吸附功效的纤维板及其制作方法
- 一种免喷涂的、具有银色金属效果的车用外饰板聚丙烯复合材料及其制备方法
- 一种具有分解甲醛作用的硅纤板及其制备方法
- 一种具有热传导结构的线路板及其制作方法
- 一种具有保护措施的交换机风扇板及保护方法
- 一种具有扇叶保护措施的吊式工业大风扇