一种基于高光谱成像技术的喷墨打印墨水种类鉴定方法
文献发布时间:2024-04-18 20:01:30
技术领域
本发明属于高光谱鉴别技术领域,具体涉及一种基于高光谱成像技术的喷墨打印墨水种类鉴定方法。
背景技术
随着喷墨打印技术的快速发展和普及,伪造文件已经成为各类犯罪案件中的常见手段,涉及合同诈骗、贪污、逃税和制作假币等领域。这些犯罪活动给社会秩序和经济秩序带来严重威胁。在文件检验领域中,喷墨打印文件的鉴定已成为工作中的重点内容。
喷墨打印墨水通常包含染料、溶剂、添加剂和pH调节剂。色素或染料提供颜色,溶剂稀释和溶解色素,添加剂改善墨水性能,pH调节剂调整酸碱性。不同品牌、型号的打印墨水的成分不同。目前,喷墨打印文件的鉴定方法已经十分成熟,如薄层色谱法(TLC)、气相色谱法(GC)和气质联用(GC-MS)等理化检验法,国内外学者广泛使用的色差法和吸收光谱分析法,以及利用傅里叶变换红外光谱(FIR)和拉曼光谱等仪器进行检验。这些方法都有各自的优势,但大部分是破坏性检验,且局限性较大。考虑到喷墨打印文件的特性,最理想的方法应具有非破坏性,稳定性以及准确性等特点。
发明内容
鉴于现有技术存在的问题,本发明的目的在于提供一种基于高光谱成像技术的喷墨打印墨水种类鉴定方法。本发明采用UMAP降维算法处理高光谱墨水数据,然后使用SVM分类器构建分类模型,通过准确率(Accuracy)评估模型性能,经调试参数后得到最优的喷墨打印墨水种类鉴别模型,实现对喷墨打印墨水的精确分类。
为实现上述目的,本发明采取下述技术方案。
一种基于高光谱成像技术的喷墨打印墨水种类鉴定方法,包括以下步骤:
步骤1、通过高光谱成像仪采集N组不同品牌、型号的喷墨打印文件高光谱图像;
步骤2、对N组所述高光谱图像进行去噪和校正,采集得到N组高光谱样品数据;
步骤3、采用UMAP非线性降维算法处理N组高光谱样品数据;
步骤4、将降维后的数据输入SVM分类器训练,经数据验证优化模型后得到最佳的喷墨打印墨水分类模型;
步骤5、根据公式计算分类模型的准确率;
步骤6、使用所述喷墨打印墨水分类模型对喷墨打印墨水进行种类鉴别。
进一步地,所述步骤1中,每组的高光谱数据包含400~1000nm,波段间隔为5nm的120个波段的反射率。
进一步地,所述步骤2中,图像去噪和校正过程包括:去除仪器本身暗噪声;解决多个图像之间的错位、畸变或变换等问题;校正高光谱图像中不同波长下的像素值;去除由于不同数据采集条件或设备参数引起的光谱强度差异。
进一步地,所述步骤3中,UMAP非线性降维算法处理数据包括:计算每对数据点之间的局部相似性度量来构建一个高维空间的邻接图,其利用相似性度量构建高维空间中的邻接图,保留了数据点之间的局部拓扑结构的同时将高维空间中的数据映射到低维空间,达到高光谱数据降维的目的。
进一步地,所述步骤5中,准确率的公式如下:
Acc:准确率;TP:预测为正,实际也为正的样本数量;FN为预测为负,实际为正的样本数量;TN为预测为负,实际也为负的样本数量;FP为预测为正,实际为负的样本数量。
与现有技术相比,本发明的有益效果是。
本发明的优点在于利用高光谱成像技术结合UMAP和SVM方法,能够方便快速的获取喷墨打印墨水的光谱信息,准确的鉴别其墨水种类;使用机器学习方法分析喷墨打印墨水特征规律,打破了传统检验方法依靠谱图进行肉眼分类的局限;学者们常用的理化检验方法会破坏检材的完整性,而本发明可以实现对喷墨打印墨水的无损检验。
附图说明
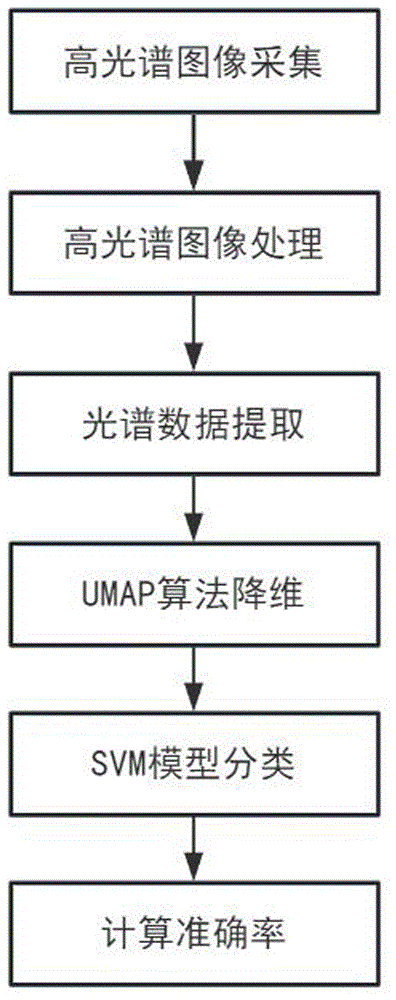
图1是本发明鉴定方法流程图。
图2是本发明实施例1中采集的实验用56种墨水的高光谱谱图(a、黑色墨水,b、青色墨水,c、品红色墨水和d、黄色墨水样品的原始谱图)。
图3是本发明实施例1中UMAP对高光谱数据降维的散点图(a、黑色墨水,b、青色墨水,c、品红色墨水和d、黄色墨水样品高光谱数据降维后的散点图)。
图4是本发明实施例1中SVM分类器对黑色样品分类的混淆矩阵图。
具体实施方式
下面将结合附图和具体实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明所述的基于高光谱成像技术的喷墨打印墨水种类鉴定方法,包括以下步骤:步骤1、通过高光谱成像设备采集N组不同品牌、型号的喷墨打印文件高光谱图像;采集时保证室内处于黑暗环境,防止外界光线对实验的影响;首先,调整载物台高度,使物镜下的样品呈现面积为20×20mm。然后将样品放置在载物台上,在样品下方放置产商提供的黑白方格纸,用于后续的配准矫正;调整相机曝光时间至0.5s;从系统控制面板的“Filter”选项卡中,选择宽带过滤(Broadband filtering)模式,从Camera窗口的工具栏中启动Camera Live Preview,移动样品直到图像进入焦点;创建一个高光谱图像采集任务(Hyperspectral acquisition),设置光谱波长范围为400~1000nm,间隔为5nm,点击执行,等待数分钟后采集成功。
步骤2、对N组所述高光谱图像进行去噪和校正,采集得到N组高光谱样品数据;去噪和矫正能够去除仪器本身暗噪声,解决多个图像之间的错位、畸变或变换等问题,校正高光谱图像中不同波长下的像素值,去除由于不同数据采集条件或设备参数引起的光谱强度差异。
其中,图像处理依次采用去暗噪法(Dark Subtraction)、配准矫正(RegistrationCorrection)、波长矫正(Wavelength Rectification)和强度归一化(IntensityNormalization)。
其中,去暗噪法涉及将一个图像中的像素值减去另一个图像相应位置上的像素值,其计算公式如下:
I=I
I为校正后的新图像的像素值;I
步骤3、采用UMAP非线性降维算法处理N组高光谱样品数据;UMAP降维算法处理数据包括计算每对数据点之间的局部相似性度量来构建一个高维空间的邻接图,其利用相似性度量构建高维空间中的邻接图,保留了数据点之间的局部拓扑结构,再使用优化技术将高维空间中的数据映射到低维空间,达到高光谱数据降维的目的。
具体包括计算N*120维光谱数据矩阵中每对数据点之间的局部相似性度量来构建一个高维空间的邻接图,这个相似性度量通常使用高斯核距离或T分布相似性来度量,计算公式如下:
s(i,j)=exp(-k||x
s(i,j)=(1+α||x
其中,s(i,j)表示相似性度量;x
最小化了在低维嵌入中的点对之间的T分布相似性和在高维空间中的相似性之间的差异。通过最小化KL散度来实现,计算公式如下:
其中,p(i,j)是高维空间中的相似性度量;q(i,j)是低维嵌入中的T分布相似性。
影响UMAP降维结果的主要参数包括维度数量(n_components)、近邻数量(n_neighbors)和距离度量(metric)等,使用网格搜索(GridSearch)寻找最佳超参数配置,KL散度作为评估指标。KL值越小表示t-SNE降维后的数据与原始数据之间的差异越小。寻找到最佳参数配置后对数据进行降维。
步骤4、将降维后的数据输入SVM分类器训练,经验证优化后得到最佳的喷墨打印墨水分类模型;对UMAP降维后数据进行分类,1:4的比例确定测试集和训练集,将训练集输入SVM分类器进行训练,获得初步的喷墨打印墨水分类模型,然后将该初步的喷墨打印墨水分类模型在验证集上验证。为了达到最佳的分类效果,利用网格搜索来调试模型的参数,尝试不同的参数组合,并使用5折交叉验证来评估每个组合的性能。影响SVM分类效果的参数主要为惩罚系数(C)和内核架构(kernel)。
步骤5、根据公式计算分类模型的准确率。
公式如下:
Acc:准确率;TP:预测为正,实际也为正的样本数量;FN为预测为负,实际为正的样本数量;TN为预测为负,实际也为负的样本数量;FP为预测为正,实际为负的样本数量。
步骤6、使用所述喷墨打印墨水分类模型对喷墨打印墨水进行种类鉴别。对需要鉴别的喷墨打印文件,首先将文件平铺在高光谱采集装置的传送平台上,调整镜头与样品间距离,设定合适的参数后经镜头扫描获得该待鉴别文件高光谱图像。对图像进行去噪和校正后,在色料饱满的区域采集得到墨水的高光谱数据。在采用UMAP非线性降维算法处理样品的高光谱数据;将降维后的数据输入喷墨打印墨水分类模型,判断墨水型号。
实施例1。
随机选取3种品牌(惠普、佳能、爱普生)不同型号的14台喷墨打印机,共计56种原装墨水。打印机型号和原装墨水型号如表1所示。采集每台打印机PGBK/BK、C、M、Y四种纯色料的样品,打印模式选择打印测试页;每台打印机打印5份样品,共计280份样品。
样品制备完成后进行高光谱图像采集。本实例使用的是GRAND-EOS高光谱仪,采集每份样品在光谱波长范围为400~1000nm,间隔为5nm的120个波段的高光谱图像。
由于图像采集时,仪器噪声、暗电流和背景等因素会对图像产生干扰。因此,对高光谱图像依次采用去暗噪(Dark Subtraction)、配准矫正(Registration Correction)、波长矫正(Wavelength Rectification)和强度归一化(Intensity Normalization)四种方法进行图像处理。处理后的图像包含了样品的空间和光谱信息,每个高光谱图像代表一个波长的强度图。运用区域选择工具对样品中感兴趣区域(ROI)提取相应的光谱信息。在每种样品色料饱满的区域提取6个ROI点位,每种颜色各420条数据,共1680条高光谱数据。提取完毕后记录并保存。
将56种墨水的原始高光谱数据列出,按颜色分为4组进行分析。发现每组的高光谱数据均存在差异,如图2所示实验用56种墨水的高光谱谱图。
用UMAP算法将样品的高光谱数据进行降维处理,调试为最佳参数的降维效果用散点图来进行可视化。调试的最佳参数组合为:黑色墨水:维度数量为8,近邻数量为8,距离度量为欧氏距离(euclidean),学习率为0.8;青色墨水:维度数量为8,近邻数量为8,距离度量为欧氏距离(euclidean),学习率为0.6;品红色墨水:维度数量为7,近邻数量为7,距离度量为欧氏距离(euclidean),学习率为0.2;黄色墨水:维度数量为7,近邻数量为7,距离度量为欧氏距离(euclidean),学习率为0.5。如图3所示UMAP对数据降维的散点图,可以直观地看出降维可视化效果较好。
将降维后的数据输入到SVM分类器中,本实施例将1680组数据按照1:4的比例划分为测试集和训练集,每种颜色的测试集84组数据,训练集336组数据。经网格搜索调试模型的最佳参数组合为:黑色墨水:惩罚系数为0.8,内核架构为径向核函数(rbf);青色、品红色和黄色墨水:惩罚系数为0.1,内核架构为线性核函数(linear)。经SVM分类的青色、品红色和黄色墨水的分类准确率为100%,黑色墨水的准确率为90%左右。
为了探究黑色墨水的分类准确率偏低的原因,列出了对黑色墨水数据进行分类的混淆矩阵图,如图4所示。由图4可知,9号和10号黑色墨水样品错分情况严重,10号样品常常被错分为9号,导致分类准确率较低。说明9号和10号样品的成分相近,难以区分,其余型号的黑色墨水分类准确率较高。
因此,UMAP降维算法搭配SVM分类模型能够有效区分不同品牌、型号的喷墨打印墨水,方法有效可行。
表1实验用喷墨打印机型号和原装墨水型号。