一种基于大模型的金融指标精准问答方法
文献发布时间:2024-04-18 20:01:30
技术领域
本申请涉及大模型技术领域,具体为一种基于大模型的金融指标精准问答方法。
背景技术
大模型:大规模语言模型,比如chatGPT、chatGLM等;
大模型幻觉:hallucination,当模型生成的文本不遵循原文或者不符合事实时,可以认为模型出现了幻觉问题,通常描述为“一本正经胡说八道”;
prompt:提示词,用于让大模型按照提示词的要求进行文本的提取和生成;
chatGLM2:当前最优秀的中文开源大模型;
Turbo大模型:OpenAI公司开放的GPT大模型编号;
Langchain:一种基于大模型和向量检索的知识库检索方式,通常用于缓解大模型的幻觉问题;
SQL是用于访问和处理数据库的标准的计算机语言;
对于金融领域的公司来说,每年的年报分析会涉及很多和金融相关的指标,比如拨备覆盖率、不良率、利润增速、息差收窄、归母净利润等,通常需要专业人士才能从报告中通过阅读理解到企业在各个指标上的表现,但占大多数的非专业人士就没办法获得自己想得到的信息,存在很大的信息差,在大模型的技术出现后,有很多金融公司对这个问题进行了尝试的解决,包括训练垂直领域的金融大模型去提高效果,但得到的指标数据都不能保证正确率,虽然基于Langchain的向量搜索和垂直的金融大模型都可以有效改善这种情况,但还是不能保证100%准确,这些已有的方法对于金融行业这种对准确率要求极高的场景是无法落地应用的。
发明内容
本申请的目的在于提供一种基于大模型的金融指标精准问答方法,以解决上述背景技术中提出的问题。
为实现上述目的,本申请提供如下技术方案:一种基于大模型的金融指标精准问答方法,包括以下步骤:
步骤1、指标提取,基于大量历史用户提出的问题数据,通过编写prompt“请帮我从这个问题中提取专业的金融行业指标”,让大模型从单个问题中提取年报中所涉及到的金融行业指标;
步骤2、数据提取,基于步骤1中提取到的金融行业指标采用大模型对年报数据进行分词,将对应的指标和指标数值提取出来,并存储到指标数据库中,并使用一个字段关联表,记录指标和指标在数据库字段的关联关系;同时也将计算具体指标的公式也存储到数据库中;
步骤3、查询指标,当用户提出要分析的问题时,由大模型对这个问题进行分词,找到用户想查询的金融指标,再在步骤2中的字段关联表中找到指标和指标字段的关联关系,把这些相关内容一并交给大模型,生成对应的数据库查询语句,找到和这个问题相关的指标和公式;
步骤4、指标结果融合,将步骤3中查询数据库返回的指标和公式,交给chatGLM2大模型进行计算和融合,基于大模型逻辑推理能力综合回答用户的问题。
优选的,所述步骤1中的数据源包括多种语言。
优选的,所述步骤1中的大模型采用了chatGLM2作为底座大模型。
优选的,所述步骤3采用了Turbo作为生成SQL的底座大模型。
优选的,所述步骤4中chatGLM2大模型在计算时首先输出每个指标的具体数值,其次要基于这些指标和公式输出计算后的指标值,最后把这些指标值和计算过程交给大模型。
与现有技术相比,本申请的有益效果是:
本发明通过把问答场景间接转换成数据库检索的方式,通过大模型提前处理并提取年报数据中的指标数据,在回答用户问题时返回数据库中真实的指标数值,让大模型回答数据库中真实的指标数值,避免大模型在数值上的“幻觉”问题导致大模型回答虚假指标数据,从而保证回答的准确性。
附图说明
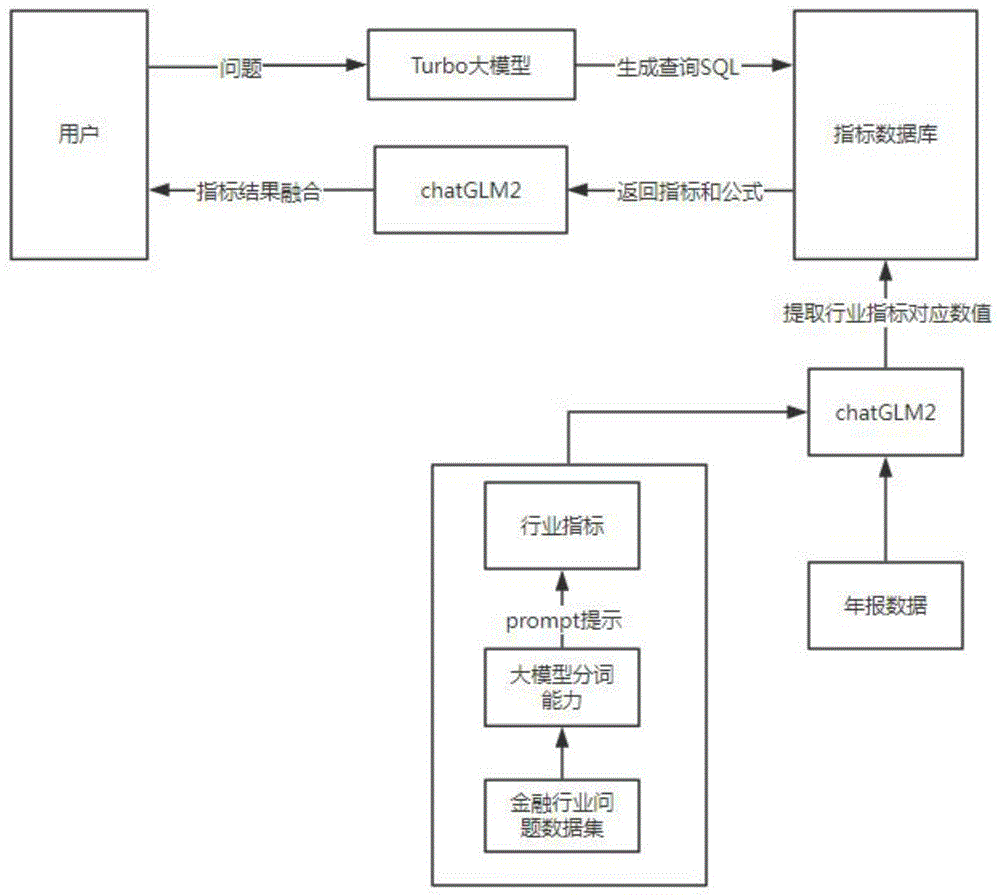
图1为本申请流程示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
实施例:
请参阅图1,本申请提供一种技术方案:一种基于大模型的金融指标精准问答方法,包括以下步骤:
步骤1、指标提取,基于大量历史用户提出的问题数据,数据源包括多种语言,通过编写prompt“请帮我从这个问题中提取专业的金融行业指标”,让大模型从单个问题中提取年报中所涉及到的金融行业指标;(通过把问答场景间接转换成数据库检索的方式,通过大模型提前处理并提取年报数据中的指标数据)通过对标分析,选择当前在中文领域表现最为优秀的chatGLM2作为指标提取阶段的底座大模型;
步骤2、数据提取,基于步骤1中提取到的金融行业指标采用大模型对年报数据进行分词,将对应的指标和指标数值提取出来,并存储到指标数据库中,并使用一个字段关联表,记录指标和指标在数据库字段的关联关系(由于只是使用了大模型的分词能力,所以存储到数据库中的指标数值是真实可信的);基于金融行业的特点,同时也将计算具体指标的公式也存储到数据库中(这样结合步骤1,在数据库中就存储了基本的指标数据,以及基于这些基本指标数据可以去计算其他指标的计算公式);
步骤3、查询指标,当用户提出要分析的问题时,由大模型对这个问题进行分词,找到用户想查询的金融指标,再在步骤2中的字段关联表中找到指标和指标字段的关联关系,把这些相关内容一并交给大模型,生成对应的数据库查询语句,找到和这个问题相关的指标和公式(在回答用户问题时返回数据库中真实的指标数值,让大模型回答数据库中真实的指标数值,从而保证回答的准确性);基于用户的文本输入生成对应的SQL语句需要大模型在编程领域具有较强的能力,通过横向对比,挑选Turbo作为S3生成SQL的底座大模型;
步骤4、指标结果融合,将步骤3中查询数据库返回的指标和公式,交给chatGLM2大模型进行计算和融合,首先输出每个指标的具体数值,这个是存在数据库的真实数值;其次要基于这些指标和公式输出计算后的指标值;最后把这些指标值和计算过程交给大模型,基于大模型逻辑推理能力综合回答用户的问题。
以上显示和描述了本申请的基本原理和主要特征和本申请的优点,对于本领域技术人员而言,显然本申请不限于上述示范性实施例的细节,而且在不背离本申请的精神或基本特征的情况下,能够以其他的具体形式实现本申请;因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本申请的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本申请内。
尽管已经示出和描述了本申请的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本申请的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本申请的范围由所附权利要求及其等同物限定。