一种多音箱声音处理方法及设备
文献发布时间:2024-04-18 20:01:30
技术领域
本发明涉及声音处理领域,具体是一种多音箱声音处理方法及设备。
背景技术
在音频处理中,声道数量是一个重要的因素。单声道音频只有一个声道,与立体声相比缺乏空间感。而立体声有两个声道,可以更好地模拟声音在空间中的位置。但是,立体声的音场也存在一些缺陷,即音源定位不准以及方向感模糊。
现有技术中优化音场的方式除了改善音频设备的环境与硬件外,就是改善音频处理软件,而目前市面上的常用的改善音场的音频处理软件有Adobe Audition与配音工厂,这两款软件的处理方法都是去除噪音,提高音频质量,但二者对于音源定位不准以及方向感模糊的问题不够重视,为此,如何针对多音箱声音的音源定位不准以及方向感模糊问题提出有效的处理方法是目前急需解决的难题。
因此,本领域技术人员提供了一种多音箱声音处理方法及设备,以解决上述背景技术中提出的问题。
发明内容
本发明的目的在于提供一种多音箱声音处理方法及设备,能够有效对多音箱声音的音场进行优化,从而避免音源定位不准以及方向感模糊,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
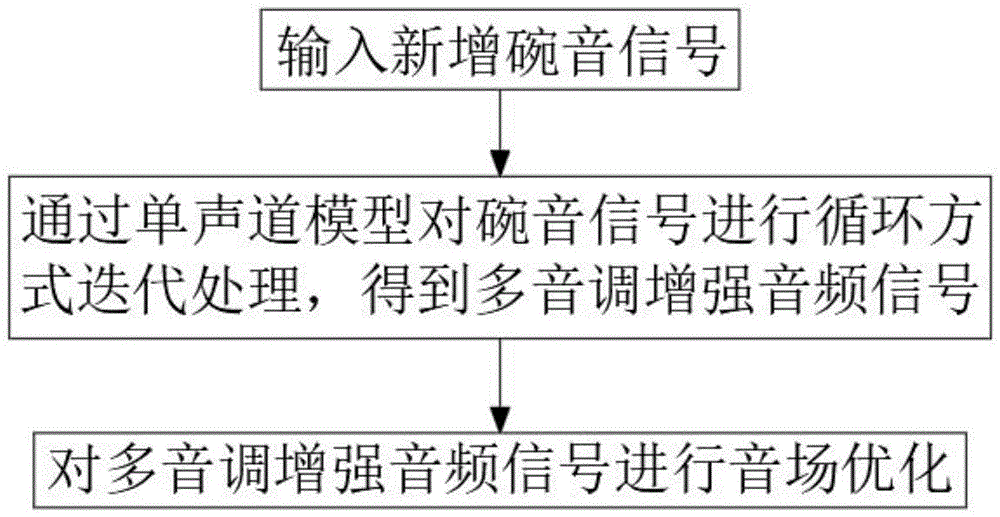
一种多音箱声音处理方法,包括以下步骤:
输入新增碗音信号;
通过单声道模型对碗音信号进行循环方式迭代处理,得到多音调增强音频信号;
对多音调增强音频信号进行音场优化。
作为本发明进一步的方案:所述碗音信号进行循环方式迭代处理的具体过程为:
将新增输入碗音信号输入多重音调估计器,多重音调估计器识别和估计碗音信号中的多个音调;
将碗音信号中的剩余低频信号输入强度估计器,强度估计器测量音频信号的强度;
将多重音调估计器与强度估计器的输出信号输入到音频增强器,音频增强器对音频信号进行优化和增强,得到单音调增强音频信号;
将单音调增强音频信号通过低通滤波器去除高频噪音,再将滤波处理后的单音调增强音频信号返回到音频增强器的;
以循环方式迭代使用音频增强器,得到多个单音调增强音频信号;
将多个单音调增强音频信号相加得到多音调增强音频信号。
作为本发明再进一步的方案:所述音频增强器对音频信号进行优化和增强的具体过程为:
通过强度估计器与音调估计器分别对低频输入碗声信号进行分析,以提取随时间变化的响度与基频;
将低频输入碗声信号输入到编码器,经过编码器的处理后产生潜在向量;
将潜在向量与响度、基频输入到解码器中,经过解码器的处理后输出两个信号分别送给加法合成器与噪声模块;
加法合成器通过音调估计器的输出信号和解码器输出的一个信号生成音频信号,噪声模块对解码器输出的另一个信号进行滤波,得到自然界底噪;
将音频信号与自然界底噪相加得到增强音频信号。
作为本发明再进一步的方案:所述对多音调增强音频信号进行音场优化的具体过程为:
将多音调增强音频信号中的音源位置/方向信息输入编码器中,该编码器包括两个路径,分别为高斯随机处理路径与动态内核建模路径;
高斯随机处理路径对信号进行处理后得到高斯处理音场分布信号;
动态内核建模路径对信号进行处理后得到观测音场分布信号;
将高斯处理音场分布信号、目标音场分布信号与观测音场分布信号输入到解码器中;
解码器对输入信号进行嵌入转换处理,再利用注意力学习机制的神经网络计算出优化后音源位置与方向。
作为本发明再进一步的方案:所述高斯随机处理路径对信号进行处理的具体过程为:将信号进行嵌入转换处理,再经过注意力学习机制的神经网络处理后进行声场建模,通过均值聚合器对所建模型的输出进行数据聚合,将聚合的数据进行全局单一表示,再通过多层感知机生成单个全局表示,最后通过对平均值与标准差的随机采样进行处理生成高斯处理音场分布信号。
作为本发明再进一步的方案:所述高斯随机处理路径对信号进行处理的具体过程为:将信号进行嵌入转换处理,再经过注意力学习机制的神经网络处理后,通过音场键值对的对应关系生成值,再通过动态内核机构对反馈的目标音场分布信号、值与音场键值对的键进行处理,得到观测音场分布信号。
本申请还公开一种多音箱声音处理设备,用于执行多音箱声音处理方法。
作为本发明再进一步的方案:所述多音箱声音处理设备包括两个音箱,其中,一个音箱中存放10种自然界的声音,另外一个音箱中存放20种尼泊尔碗声。
与现有技术相比,本发明的有益效果是:
本申请先通过单声道模型对碗音信号进行循环方式迭代处理,得到多音调增强音频信号,而在对多音调增强音频信号进行音场优化的过程中,通过高斯随机处理路径与动态内核建模路径能够有效对现有音源位置与方向进行优化,从而提高音场优化效果。
附图说明
图1为一种多音箱声音处理方法的流程图;
图2为一种多音箱声音处理方法中碗音信号进行循环方式迭代处理的流程图;
图3为一种多音箱声音处理方法及设备中音频增强器对音频信号进行优化和增强的流程图;
图4为一种多音箱声音处理方法及设备中音场优化的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
正如本申请的背景技术中提及的,发明人经研究发现,现有优化音场的方式针对音源定位不准以及方向感模糊的问题不够重视,最终影响了音场的真实感和沉浸感,存在一定的缺陷。
为了解决上述缺陷,本申请公开了一种多音箱声音处理方法及设备,先通过单声道模型对碗音信号进行循环方式迭代处理,得到多音调增强音频信号,而在对多音调增强音频信号进行音场优化的过程中,通过高斯随机处理路径与动态内核建模路径能够有效对现有音源位置与方向进行优化,从而提高音场优化效果。
以下将结合附图对本申请的方案如何解决上述技术问题详细介绍。
请参阅图1,本发明实施例中,一种多音箱声音处理方法,包括以下步骤:输入新增碗音信号;通过单声道模型对碗音信号进行循环方式迭代处理,得到多音调增强音频信号;对多音调增强音频信号进行音场优化。本申请能够有效对多音箱声音的音场进行优化,从而避免音源定位不准以及方向感模糊。
在本实施例中:如图2所示,所述碗音信号进行循环方式迭代处理的具体过程为:将新增输入碗音信号输入多重音调估计器,多重音调估计器识别和估计碗音信号中的多个音调;将碗音信号中的剩余低频信号输入强度估计器,强度估计器测量音频信号的强度;将多重音调估计器与强度估计器的输出信号输入到音频增强器,音频增强器对音频信号进行优化和增强,得到单音调增强音频信号;将单音调增强音频信号通过低通滤波器去除高频噪音,再将滤波处理后的单音调增强音频信号返回到音频增强器的;以循环方式迭代使用音频增强器,得到多个单音调增强音频信号;将多个单音调增强音频信号相加得到多音调增强音频信号。其中,多重音调估计器是一种用于估计音频信号中多个音调的频率的工具。它通常被用于音频处理、音乐分析和语音识别等领域。多重音调估计器的基本原理是通过对音频信号进行频谱分析,检测出其中存在的多个音调,并估计它们的频率。这通常需要使用一些算法和技术,如短时傅里叶变换(STFT)、频谱图分析、聚类算法等。多重音调估计器的实现方法有多种,其中一种常见的方法是基于聚类算法的。这种方法首先对音频信号进行频谱分析,得到频谱图,然后将频谱图中的频率点聚类成多个簇,每个簇代表一个音调。最后,通过对每个簇的质心进行计算,得到每个音调的频率。强度估计器是一种用于估计音频信号强度的工具。它通常被用于音频处理、音乐分析和语音识别等领域,以提取音频信号中的强度信息,从而进行音频分类、识别、合成等操作。强度估计器的基本原理是通过对音频信号进行时域或频域分析,检测出音频信号的强度或能量。这通常需要使用一些算法和技术,如短时能量分析(Short-Time Energy,STE)、短时过零率分析(Short-Time ZeroCrossing Rate,STZCR)、梅尔频率倒谱系数(Mel-frequency cepstral coefficients,MFCC)等。强度估计器的实现方法有多种,其中一种常见的方法是基于短时能量分析的。这种方法首先将音频信号切割成多个短时帧,然后计算每一帧的能量或幅度,从而得到一个强度序列。这个序列可以用于音频分类、识别等任务。低通滤波器是一种能通过频率低于选定截止频率的信号,并衰减频率高于截止频率的信号的滤波器。它常被用于信号处理中,主要目的是去除信号中的高频噪声,保留低频部分,让信号变得更为平滑。低通滤波器有许多不同的形式,包括电子电路,如音频中使用的嘶声滤波器,模数转换前调节信号的抗混叠滤波器,平滑数据集的数字滤波器,声屏障,图像的模糊等等。在移动平均操作中,低通滤波器也被用作特殊的形式,可以用用于其他低通滤波器的相同信号处理技术进行分析。需要说明的是,在每次迭代时,在频谱域中从残余低带输入信号中去除前一步生成的谐波含量,从而使得残留的低频带信号包含越来越少的谐波。
在本实施例中:如图3所示,所述音频增强器对音频信号进行优化和增强的具体过程为:通过强度估计器与音调估计器分别对低频输入碗声信号进行分析,以提取随时间变化的响度与基频;将低频输入碗声信号输入到编码器,经过编码器的处理后产生潜在向量;将潜在向量与响度、基频输入到解码器中,经过解码器的处理后输出两个信号分别送给加法合成器与噪声模块;加法合成器通过音调估计器的输出信号和解码器输出的一个信号生成音频信号,噪声模块对解码器输出的另一个信号进行滤波,得到自然界底噪;将音频信号与自然界底噪相加得到增强音频信号。其中,编码器与解码器是两个相对的概念,主要用于数据的转换和处理。编码器是一种设备、传感器或系统,用于将信号(如比特流)或数据进行编制、转换为可用以通讯、传输和存储的信号形式。例如,在机械领域中,编码器常用来测量机械旋转或位移,将机械部件在运动时的位移位置或速度等信息转换成电信号,并发送反馈信号,可用于确定位置,计数,速度或方向。编码器根据不同的检测原理、机械结构运动方式、刻度实现方法及信号输出形式等可以分为多种类型。而解码器则是执行编码器电路相反操作的组合电路。它将来自编码器的编码信息解码或简化为原始信号。例如,音频处理中的解码器可以将编码的音频信息解码为可听的音频信号。解码器也需要根据具体的编码方式和应用需求来选择和设计。加法合成器是一种通过叠加多个正弦波来生成声音的电子合成器。加法合成基于正弦波叠加的原理来制造更为复杂的波形,从而制造更丰富的听感。在加法合成器中,用户可以调节基波与谐波之间的音量关系,获得比正弦波复杂的波形。这种合成器可以用于创造各种音色和声音效果,广泛应用于音乐、电影、游戏等领域中。加法合成器的实现方式可以是通过硬件电路实现,也可以通过软件算法实现。其中,硬件实现方式通常使用振荡器和滤波器来生成和调节正弦波,通过控制振荡器的频率、幅度和相位等参数来生成不同的声音。而软件实现方式则使用数字信号处理技术来模拟正弦波叠加的过程,通过算法计算来生成声音。
在本实施例中:如图4所示,所述对多音调增强音频信号进行音场优化的具体过程为:将多音调增强音频信号中的音源位置/方向信息输入编码器中,该编码器包括两个路径,分别为高斯随机处理路径与动态内核建模路径;高斯随机处理路径对信号进行处理后得到高斯处理音场分布信号;动态内核建模路径对信号进行处理后得到观测音场分布信号;将高斯处理音场分布信号、目标音场分布信号与观测音场分布信号输入到解码器中;解码器对输入信号进行嵌入转换处理,再利用注意力学习机制的神经网络计算出优化后音源位置与方向。高斯随机处理路径是一种常用的随机处理方法,其基本思想是通过高斯随机数生成器生成一系列随机数,然后根据这些随机数对处理路径进行随机化处理。高斯随机处理路径的优点是可以增加处理的多样性和随机性,减少对特定路径的依赖,从而增强处理的鲁棒性和适应性。同时,高斯随机处理路径也具有易于实现、处理效果好等优点。动态内核建模路径是一种针对动态内核的建模方法,其基本思想是通过建立模型来描述动态内核的行为和特征。动态内核建模路径具有以下优点:(1)、准确性:动态内核建模路径可以准确地描述动态内核的行为和特征,从而提供更精确的模型预测结果。(2)、灵活性:动态内核建模路径可以灵活地适应不同的数据集和模型需求,从而可以根据实际需求进行模型调整和优化。(3)、可解释性:动态内核建模路径可以提供更清晰、更易于理解的模型解释,从而有助于用户更好地理解模型和数据之间的关系。(4)、鲁棒性:动态内核建模路径可以更好地处理异常值和噪声数据,从而提供更鲁棒的模型性能。(5)、高效性:动态内核建模路径可以利用先进的计算技术和优化算法,从而提供更高效的模型训练和推理性能。
在本实施例中:如图4所示,所述高斯随机处理路径对信号进行处理的具体过程为:将信号进行嵌入转换处理,再经过注意力学习机制的神经网络处理后进行声场建模,通过均值聚合器对所建模型的输出进行数据聚合,将聚合的数据进行全局单一表示,再通过多层感知机生成单个全局表示,最后通过对平均值与标准差的随机采样进行处理生成高斯处理音场分布信号。嵌入转换处理主要是通过转换算法将一种数据格式嵌入到另一种数据格式中,以实现数据的隐藏、保护或转换。这种处理方法可以应用于多种领域,如数字水印、数据加密、图像处理等。注意力学习机制的神经网络是一种模拟人脑注意力机制的神经网络模型,它可以让模型在处理信息时更加聚焦和高效。注意力机制的基本原理是,当处理大量信息时,人脑会选择性地关注其中的一部分信息,而忽略其他不相关的信息。类似地,注意力学习机制的神经网络也会根据输入信息的重要性,动态地分配不同的权重给不同的信息,以便更好地处理和利用这些信息。均值聚合器是一种聚合函数,用于计算一组数值的平均值。在神经网络和机器学习中,均值聚合器通常被用于聚合节点或特征的信息,以便更好地表示和处理数据。在GraphSAGE算法中,均值聚合器被用作一种重要的邻域聚合函数,用于聚合节点及其邻域的本征向量的平均值。具体来说,对于每个节点,均值聚合器会计算其邻域内所有节点的特征向量的平均值,并将该平均值与该节点自身的特征向量进行拼接,以得到该节点的更新后的特征向量。均值聚合器具有简单、高效和易于实现的特点,并且在许多任务中都表现出了较好的性能。但是,它也有一些局限性,例如无法处理节点顺序的问题,以及可能会受到邻域内噪声节点的影响等。因此,在实际应用中,需要根据具体的任务和数据特点来选择合适的聚合函数。总之,均值聚合器是一种重要的聚合函数,在神经网络和机器学习中有着广泛的应用。
在本实施例中:如图4所示,所述高斯随机处理路径对信号进行处理的具体过程为:将信号进行嵌入转换处理,再经过注意力学习机制的神经网络处理后,通过音场键值对的对应关系生成值,再通过动态内核机构对反馈的目标音场分布信号、值与音场键值对的键进行处理,得到观测音场分布信号。音场键值对是一种将音场数据保存为键值对形式的数据结构。它通常用于描述音乐或声音的来源位置和声音的属性,例如音调、音色、音量等。在音频处理中,音场键值对可以用于实现环绕声效果、立体声效果等。音场键值对的格式通常为:“键名:键值”。其中,键名表示音场数据的名称,例如“left”(左)、“right”(右)、“front”(前)、“back”(后)等。而键值则表示音场数据具体的数值,例如音量大小、音调高低等。例如,一个简单的音场键值对可能是:“left:0.5,right:0.5,front:1.0,back:0.0”。这个键值对表示左右两个声道都有相同的音量,而前方的音量是1.0,后方的音量是0.0。需要注意的是,音场键值对的具体格式和内容可能会因不同的应用场景和需求而有所不同。在实际应用中,需要根据具体的需求和数据特点来选择合适的音场键值对。动态内核机构是指一种能够在运行时动态调整其内核功能和行为的操作系统机构。与传统的静态内核机构相比,动态内核机构具有更高的灵活性和适应性,可以根据不同的应用场景和需求进行动态调整和优化。动态内核机构的实现需要考虑到多个方面的因素,包括内核的结构、功能、性能、安全性等。其中,内核的结构是动态内核机构设计的基础,需要支持动态扩展和裁剪,以便根据不同的需求进行定制。同时,内核的功能也需要支持动态调整,可以根据不同的应用场景进行添加或删除。在性能方面,动态内核机构需要考虑到资源的利用效率和系统的响应速度等因素,以确保系统的实时性和高效性。在安全性方面,动态内核机构需要采取多种措施,包括访问控制、加密、隔离等,以确保系统的安全性和可靠性。动态内核机构的优势在于可以根据不同的应用场景和需求进行动态调整和优化,从而提高系统的效率和性能。例如,在云计算环境中,动态内核机构可以根据不同的负载情况进行动态调整,以确保系统的高效性和稳定性。在物联网应用中,动态内核机构可以根据不同的设备类型和需求进行定制和优化,以提高系统的适应性和效率。总之,动态内核机构是一种高度灵活和可适应的操作系统机构,可以根据不同的应用场景和需求进行动态调整和优化,从而提高系统的效率和性能。
本申请还公开一种多音箱声音处理设备,用于执行多音箱声音处理方法。
在本实施例中:所述多音箱声音处理设备包括两个音箱,其中,一个音箱中存放10种自然界的声音,另外一个音箱中存放20种尼泊尔碗声。这样两个音箱可同时发声200种混声音。
本发明先通过单声道模型对碗音信号进行循环方式迭代处理,得到多音调增强音频信号,而在对多音调增强音频信号进行音场优化的过程中,通过高斯随机处理路径与动态内核建模路径能够有效对现有音源位置与方向进行优化,从而提高音场优化效果。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
以上所述的,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 一种杂环偶氮苯/石墨烯太阳能储热材料及制备方法
- 一种吲哚偶氮苯/石墨烯复合太阳能储热材料及其制备方法
- 低取向度储热石墨、制备低取向度储热石墨的组合物及其制备方法
- 一种低取向度储热材料、制备储热材料用组合物及储热材料制备方法