一种构建知识驱动的少样本命名实体识别适配器的方法
文献发布时间:2024-04-18 20:01:30
技术领域
本发明属于自然语言处理技术领域,涉及一种构建知识驱动的少样本命名实体识别适配器的方法。
背景技术
命名实体识别(NER)是自然语言处理(NLP)中的一个基础任务。NER通常被表述为序列分类任务,目标是为输入序列中的每个实体分配一个标签。这些标签基于预定义的类别,例如位置、组织和人物。当前最先进的NER方法使用预训练语言模型(PretrainedLanguage Models,PLMs))并配备了多个NER范式,包括标签特定分类器(LC)、机器阅读理解(MRC)和统一生成模型(BartNER)。然而,这些模型与可见类别高度相关,并且经常显式地记住实体。这是因为这些模型的输出层必须在训练和测试之间具有一个一致的标签集。因此,这些模型必须从头开始重建以适应具有新实体类别的目标域,这使少样本NER成为一个具有挑战性但又实用的研究问题。
少样本NER的一个重要研究方向是使用原型方法。这些方法结合了元学习,作为NER领域的少样本学习方法而广受欢迎。然而,大多数现有方法都依赖于最近邻准则来分配实体类型,该准则基于源域和目标域之间的相似模式。这些方法无法充分利用PLMs的能力,可能无法很好地处理跨域实例。
另一种解决少样本命名实体识别的方法是使用高效微调(Parameter EfficientFine-tuning,PEFT),主要使用提示学习(prompt tuning)。尤其是PromptNER将实体定位和实体类型化统一到提示学习中,并设计了一个包含位置槽和类型槽的双槽多提示模板,分别提示定位和类型化,达到了最先进的性能。
但是,原型方法和提示学习(prompt tuning)方法都没有考虑知识图谱本体的丰富结构类型信息;因此,本发明提出了一种构建知识驱动的少样本命名实体识别适配器的方法。
发明内容
本发明的目的就是提供一种构建知识驱动的少样本命名实体识别适配器的方法,充分利用PLMs中的参数化知识和知识图谱(Knowledge Graph,KG)中的实体知识,从而提升少样本命名实体识别的性能。
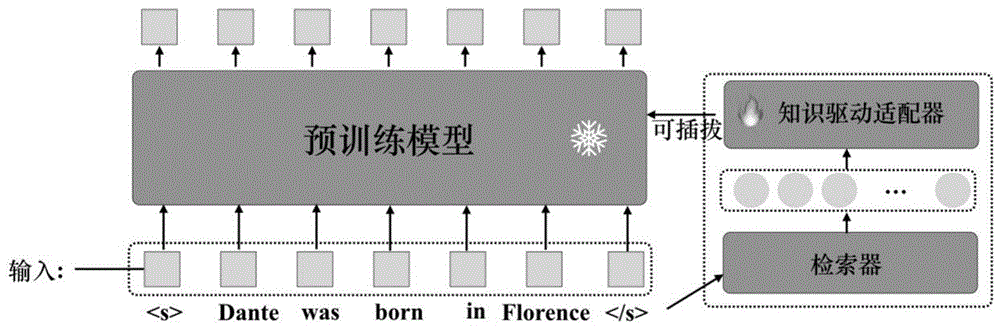
本发明通过知识图谱增强高效微调(PEFT)范式来解决少样本命名实体识别任务。设计的适配器(KG-adapter)遵循通用的Seq2Seq生成框架,并使用指针机制生成实体索引序列。
对于给定的输入句子,构造了一个知识图谱检索器来搜索其对应的知识图谱(KG)实体类型序列。针对每个句子的知识图谱(KG)实体类型序列,利用本体图谱中每个实体类型的对应本体词生成KG实体类型的表示,用以作为适配器的输入,对适配器进行引导。
具体包括如下步骤:
步骤一、文本的相关知识图谱(KG)实体类型序列检索及其表示生成;
具体为:
步骤1、对于句子中的一个命名实体,利用现有检索器,使用以下形式按顺序在现有数据库中中找到其最接近的匹配:i)原始形式;ii)利用spaCy库进行词形还原;iii)词干。检索器最终针对每个句子生成一个向量。
步骤2、将本体知识纳入编码器以协助适配器调优。
步骤二、利用知识图谱(KG)实体类型序列的表示改造现有适配器,使其成为知识驱动的适配器(KG-adapter);
步骤三、冻结Seq2Seq预训练语言模型PLMs的参数,只在数据集上训练知识驱动的适配器。
步骤四、利用训练好的适配器进行少样本的命名实体识别。
采用本发明设计的适配器进行的少样本命名实体识别,相比传统的PEFT少样本命名实体识别方法,针对每一个句子,在知识库中搜索得到对应的背景实体,并通过将背景实体转换为类型序列,不仅扩充了句子的预测类型背景知识,也添加了相应的实体边界分割信息,让适配器能被迫从实体的扩充上下文中收集更多信息以进行正确分类,提高了准确度和召回率;相比以往的知识注入PLMs的命名实体识别算法,增加扩充上下文信息时,并没有引入更多训练参数,减少了计算的复杂度。同时该知识适配器针对命名实体识别(NER)任务,在不同领域的数据集上引入了特定的数据。适用于命名实体识别任务,特定用于扩充命名实体识别中不同领域的知识(比如医疗等领域)。
附图说明
图1为知识驱动的少样本命名实体识别的结构图;
图2为知识驱动的适配器的结构图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
如图1所示,一种构建知识驱动的少样本命名实体识别适配器的方法,具体包括如下步骤:
步骤一、文本的相关知识图谱(KG)实体类型序列搜索及其表示生成:
步骤1、对于句子中的一个命名实体,利用现有检索器(如BM25算法),使用以下形式按顺序在现有数据库中(本实施例中选用维基数据(Wikidata))中找到其最接近的匹配:i)原始形式;ii)利用spaCy库进行词形还原;iii)词干(最后一个词)。
检索器最终针对每个句子生成一个向量
具体地:如果文本是
步骤2、将本体知识纳入编码器以协助适配器调优,以提高实体类型编码器的覆盖率和减少偏差:
首先,扫描本体图(ontology graph)中的所有条目,并提取其关联文本以创建大规模语料库。然后,对于集合
本实施例中,m被限制为最多跳数为3。以标签类别c是"Loc"为例,根据c的分解获得集合
具体为:建立了一个映射
文本相关的知识图谱(KG)实体类型的最终表示是通过将实体的稀疏矩阵
步骤二、如图2所示,利用步骤一得到的知识图谱(KG)实体类型序列的表示改造现有普通适配器,使其成为知识驱动的适配器;
具体为:
步骤1)、在基于注意力机制的序列模型(Transformer模型)中,每一层都由两个主要的子层组成:注意力层(深度学习注意力机制MHA)和前馈层(前馈神经网络(FeedForward Networks,FFN))。在每个子层之后,都有一个将特征大小映射回该层输入大小的投影。此外,在每个子层之间应用跳跃连接。然后将每个子层的输出通过层归一化。给定句子
将它们分成N
其中,Q
然后,将所有头的输出通过线性投影变换参数
MHA(X)=Concat(head
其中head
前馈神经网络(Feed Forward Networks,FFN)由两层线性层组成,并带有ReLU非线性激活函数;将句子X作为输入:
适配器在基于注意力机制的序列模型(Transformer)的编码器中插入两个紧凑的模块。
具体为:一个适配器块由降维变换W
X′表示X降维又升维之后的还原值;
步骤2)、为了将知识图谱嵌入整合到适配器中,知识图谱自适应器在每个子层之后插入KG实体类型表示到适配器的输入当中。适配器的输出随后会被直接传递到后续的归一化层中:X″=X+σ(GXW
X″表示transfomer层的输出再加入知识图谱中实体类型知识后,通过降维再升维之后的还原值,即下一层transformer的输入;G表示知识图谱中领域相关(domainspecific)的类型本体知识;
步骤三、冻结住Seq2Seq预训练语言模型PLMs模型在去噪自编码器(BART)上的预训练参数,只在数据集上训练知识驱动的适配器。
步骤四、利用训练好的适配器进行少样本的命名实体识别。
为本申请技术方案进行论证,分别在3个公共数据集上进行对比,对比结果见表1;
表1
如表1所示,采用本发明设计的适配器,在每个数据集中少样本的命名实体识别中,识别率均是最高的。
以上所述,仅为本发明的具体实施方式,本说明中所公开的任一特征,除非特别叙述,均可被其他等效或者具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征或/和步骤外,均可以任何方式组合。
- 一种S型扭转叶片式叶轮结构及使用该叶轮结构对流体介质的加压方法
- 一种通过混合介质加压提高成形效率的热胀型工艺
- 一种用于混凝土制备过程中提高混凝土混合效率的工艺