一种基于深度强化学习的天地一体化负载均衡路由方法
文献发布时间:2024-04-18 20:01:55
技术领域
本发明涉及网络负载均衡,尤其涉及一种基于深度强化学习的天地一体化负载均衡路由方法。
背景技术
随着天地一体化网络的发展,关键节点具有计算和存储功能,网络呈现智能化特征,流量特性也随之改变。网络流量描述的变化,导致天地一体化网络中与时间相关和连接相关的流量特征发生了变化,传统的网络流量理论难以对动态变化、链路多样、复杂异构的流量进行负载均衡处理。当前,关于天地一体化网络负载均衡方法主要分为非人工智能方法与人工智能方法。
非人工智能方法主要包括遗传算法、启发式算法、蚁群算法。北京遥测技术研究所的李澎等人(李澎,赵祥,胡剑平等.基于区域划分的LEO卫星星座QoS(Quality ofService,服务质量)路由算法[J].遥测遥控,2022,43(2):17–24)提出了一种基于多目标遗传算法的路由策略,保障了重负载区域不同业务QoS并实现负载均衡,仿真结果表明该方法具有较低的网络平均时延和丢包率。爱尔兰都柏林圣三一学院的Sangita Dhara(S.Dhara, S. Ghose and R. Datta, "MFR—A Max-Flow-Based Routing for FutureInterplanetary Networks," in IEEE Transactions on Aerospace and ElectronicSystems. vol. 58, no. 6, pp. 5334-5350, Dec. 2022)提出了一种基于启发式算法的面向未来星际网络的最大流路由策略,该方法通过可预测性计算大型网络的最优流,仿真结果表明其有较大的网络性能提升。广州大学曾首元(曾首元.基于蚁群优化的低轨卫星网络负载均衡路由算法研究[D].广州大学,2022)提出了一种基于蚁群优化的负载均衡路由算法,该方法根据路径总长度和当前节点的缓存状态优化了信息素更新规则,仿真结果表明其能够在网络负载增加的情况下平衡流量,保持较小的平均延迟和开销。上述非人工智能方法对于简单网络具有良好的负载均衡效果,但是路由约束条件不完善,难以从全局对网络进行规划,因此并不适用于复杂网络的负载均衡。
人工智能方法主要包括机器学习、深度学习、深度强化学习相关的负载均衡路由策略。中国电子科技集团公司第五十四研究所的李新桐等人(李新桐,张亚生.一种适用于低轨卫星的SDN网络人工智能路由方法[J].电子测量技术,2020,43(22):109-114),其提出的机器学习辅助路由策略使卫星网络链路负载降低。哈尔滨工业大学的薛冠昌等人(薛冠昌,王钢,解索非,等.基于流量预测的卫星网络路由算法[J].无线电通信技术,2021,47(5):596-602)提出的基于流量预测的星上路由算法,使用深度学习能够降低数据的端到端时延,并改善丢包率。重庆邮电大学汪昊等人(汪昊.基于图神经网络的低轨卫星网络动态路由算法研究[D].重庆邮电大学,2022)提出一种基于图神经网络的低轨卫星动态路由算法,通过深度强化学习能够对拓扑动态的卫星网络有效提升时延、吞吐量和丢包率方面的性能。此类方法虽然有较高的负载优化,但是由于人工智能方法需要复杂的数学建模及大样本数据支持,这些方法决策有较高的时间成本。
上述方法虽然能较好地实现天地一体化网络的负载均衡,但是大多都只基于天基网络,而未考虑到包括天、地在内完整的复杂异构网络,且一条完整的流量传输路径由链路、队列等多种因素构成,上述方法缺少对网络特征的准确描述,所以难以形成负载均衡的路由约束。
发明内容
发明目的:本发明的目的是提供一种能够实现对天地一体化复杂网络性能高精度预测的基于深度强化学习的天地一体化负载均衡路由方法。
技术方案:本发明的天地一体化负载均衡路由方法,包括如下步骤:
S1,将天地一体化网络拓扑转化为流量传递有向图
S2,通过OMnet软件构建需要预测得到的网络拓扑,模拟多种流量情况,生成数据集,并对数据集进行预处理;
S3,将数据集中的流特征进行归一化处理,通过特征嵌入H函数分别对路径、链路、队列的隐藏状态进行初始化;
S4,通过MPNN进行消息传递、聚合更新和生成信息,依次对路径、链路、队列的隐藏状态进行处理;在聚合过程中,采用注意力机制捕捉骨干节点的邻近图结构信息;
S5,重复步骤S4至T次;
S6,将T次传递后的路径、链路和队列的隐藏状态作为读出函数的输入,将图内所有节点的特征聚合,最终得到一个包含整个图信息的隐藏状态
S7,计算流时延、抖动和每个流的丢包率;
S8,以平均绝对百分误差MAPE作为损失函数,对性能预测模型进行训练,迭代得到收敛值,生成源至目标节点的性能预测矩阵;
S9,根据步骤S8生成的性能矩阵参数,结合网络拓扑参数,划分为动态参数与静态参数;
S10,设置强化学习初始策略参数
S11,根据状态
S12,从重放缓冲区D中抽取经验B进行学习,设置计算目标值
S13,使用均方误差MSE作为损失函数更新
S14,重复步骤S12的更新步骤,直至收敛,得到最优负载均衡路径结果。
进一步,步骤S1中,所述流量传递有向图
进一步,步骤S3中,对路径、链路及队列的隐藏状态进行初始化的实现步骤如下:
S31,根据步骤S2数据集中得到的流特征,按照路径特征、链路特征和队列特征进行分类;
S32,对于以数值表示的数据将其的实际值减去平均值,并除以标准差,作归一化处理;
对于以类别表示的数据将其用one_hot形式进行编码;
S33,通过路径、链路和队列的映射关系,依次将流的路径、链路和队列特征通过一个输入层、两个全连接层进行隐藏状态初始化,得到初始路径隐藏状态、初始链路隐藏状态和初始队列隐藏状态。
进一步,步骤S4中,对路径隐藏状态进行处理的步骤如下:
SB1,将链路与路径映射的隐藏状态、队列与路径映射的隐藏状态按索引进行收集,获取与路径对应的状态子集;
SB2,将路径隐藏状态通过GRU门控循环单元进行更新;
SB3,将步骤SB1中保存的先前路径隐藏状态与步骤SB2更新得到的路径隐藏状态沿着axis=1拼接,对路径状态进行更新;在骨干网节点状态的聚合过程中,采用注意力机制,输出每次迭代完整的路径状态;
对队列隐藏状态进行处理的步骤如下:
SC1,从路径状态序列中获取与队列对应的子集;
SC2,将路径状态求和,得到每个队列对应的路径状态总和;
SC3,将步骤SC1中得到的当前队列隐藏状态和步骤SC2的路径状态总和作为作为输入,经过GRU门控循环单元更新得到新的队列状态,输出每次迭代完整的队列状态;
对链路隐藏状态进行处理的步骤如下:
SD1,从队列状态中获取与链路对应的子集;
SD2,将链路状态经过GRU门控循环单元更新得到新的链路状态;
SD3,将步骤SD1中的状态作为输入传递给GRU门控循环单元,并将步骤SD2中的状态作为初始状态,输出每次迭代完整的链路状态。
进一步,步骤S6中,所述读出函数由神经网络实现,将最终的隐藏状态通过一个输入层和三个全连接层,其中最后一个全连接层的输出形状大小为1。
进一步,步骤S7中,流时延
抖动
最后,丢包率
进一步,步骤S9中,所述动态参数包括时延、抖动和丢包;所述静态参数为网络的固有属性。
进一步,步骤S12中,所述经验B包括代理在环境中的状态
本发明与现有技术相比,其显著效果如下:
1、本发明采用的注意力机制能够使节点在消息传递的过程中根据邻接点对任务的重要程度自动对该邻接点的权重进行分配,并且在天地一体化网络中卫星节点与地面节点的“连-断”过程中能够迅速调整聚合权重,有效地提高了模型的预测能力。本发明的性能预测决定系数MAPE,时延预测的MAPE收敛至2.6677%,较于RouteNet-Erlang模型预测效果MAPE=14.3298%预测准确度提升了11.6621个百分点,较于RouteNet-Fermi模型预测效果MAPE=9.2740%预测准确度提升了6.6063个百分点;抖动预测的MAPE收敛至7.2822%,较于RouteNet-Erlang模型预测效果MAPE=13.334%预测准确度提升了6.0525个百分点,较于RouteNet-Fermi模型预测效果MAPE=11.8569%预测准确度提升了4.5747个百分点;
2、本发明在性能预测的基础上采用DDPG强化学习方法对预测的性能指标组合优化,能够实现对下一时间片的最佳路由决策;本发明的多QoS负载效果决定系数为源-目的地平均时延、抖动和丢包率,时延较于其他算法至少提升12.6%,抖动较于其他算法至少提升30.6%,丢包率较于其他算法至少提升19.5%,表明本发明提出的基于图注意力网络的天地一体化负载均衡路由策略,能够实现对天地一体化复杂网络性能的高精度预测,从而实施均衡的路由策略。
附图说明
图1为本发明的算法流程图;
图2为本发明与Routenet-Fermi和Routenet-Erlang时延预测的训练loss对比图;
图3为本发明与Routenet-Fermi和Routenet-Erlang抖动预测的训练loss对比图;
图4为本发明随机抽取50种路径下对时延的真实值与预测值对比的矩形图;
图5为本发明随机抽取50种路径下对时延的真实值与预测值对比的误差散点图;
图6为本发明随机抽取50种路径下对抖动的真实值与预测值对比的矩形图;
图7为本发明方法随机抽取50种路径下对抖动的真实值与预测值对比的误差散点图;
图8为本发明采用的真实网络拓扑图;
图9为本发明抽象后的网络拓扑图;
图10为神经网络隐藏状态初始化的模型图;
图11为基于MPNN和注意力机制的图神经网络模型;
图12为一种路径选择方案示意图。
实施方式
下面结合说明书附图和具体实施方式对本发明做进一步详细描述。
本发明的深度强化学习方法将图神经网络应用到天地一体化网络,图神经网络作为神经网络扩展,可以处理图结构表示的数据格式,旨在利用节点与节点之间的连接关系,通过递归聚合和转换相邻节点的表示向量来计算当前节点的表示向量,进而实现路径、链路和队列的关系约束,实现端到端流量传输时延、抖动和丢包率的准确预测,在此基础上进行组合优化达到负载均衡效果。
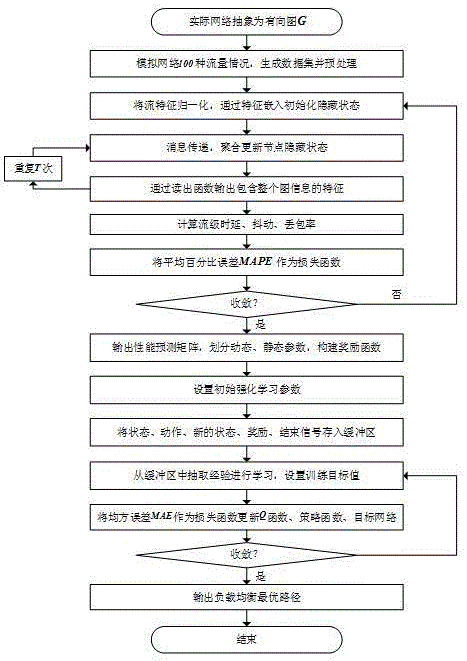
图1为本发明的算法流程图,具体实现步骤如下:
步骤1,将天地一体化网络拓扑转化为流量传递有向图
流量传递有向图
步骤2,通过OMnet软件构建需要预测得到的网络拓扑,模拟100种流量情况,生成数据集,作为神经网络输入,并对数据集进行预处理。
为了验证本发明方法对真实网络有效,模拟了100种随机流量,这些随机流量有不同的流量特性,包括每个节点的队列调度策略,并依次分配权重、ToS(Type of Service,服务类型),以及流的到达时间分布和大小分布,其余如网络拓扑结构、节点间带宽大小等都是真实网络的静态属性。网络流特征如表1所示。
表1 网络流量特征表
表1中,FIFO(First in, First out)表示先入先出队列,SP(Strict Priority )表示严格优先级队列,WFQ(Weighted Fair Queuing)表示加权公平排队,DRR(DeficitRound Robin)表示差分轮询;possion表示泊松流;cbr表示恒定流;on_off表示开/关流。
生成数据集后需要对数据集进行清洗,以保证数据集的高质量和结果的有效性。本实施例中数据集验证的网络拓扑为47节点结构,通过实验证明,除了对数据集正常的处理流程外,去除源-目的节点长度小于4的路径集,能够进一步提升性能预测模型的训练效果。
步骤3,将数据集中的流特征数据进行归一化处理,通过特征嵌入H函数初始化路径、链路及队列的隐藏状态
根据步骤2中迭代生成的数据集中得到的流特征,首先按照路径特征、链路特征和队列特征进行分类。其中路径特征包括源-目的节点的平均带宽traffic、单位时间数据包packets、以及生成流的数据包到达时间分布,如在on_off流的情况下,数据包的on周期平均持续时间AvgTOn的指数分布等。链路特征包括链路负载Load、调度策略SchedulingPolicy等。队列特征包括每个队列的统计信息。
其次,对于以数值表示的数据将其的实际值减去平均值,并除以标准差,作归一化处理。以平均带宽traffic为例,其归一化可表示为:
其中,/>
对于以类别表示的数据将其用one_hot形式进行编码,例如队列调度策略共有四种,则将FIFO(First Input First Output)类型编码为[1,0,0,0],以此类推,方便后续的矩阵运算。
最后,通过路径、链路和队列的映射关系,依次将流的路径、链路和队列特征通过一个输入层、两个全连接层进行隐藏状态初始化,得到初始路径隐藏状态
步骤4,通过MPNN(Message Passing Neural Network,消息传递神经网络)进行消息传递、聚合更新和生成信息依次对路径隐藏状态
表2 通过进行消息传递、聚合更新和生成信息的流程伪代码表
具体来说,首先,对路径隐藏状态
B1)将链路与路径映射的隐藏状态、队列与路径映射的隐藏状态按索引进行收集,获取与路径对应的状态子集;
B2)将路径隐藏状态通过GRU门控循环单元进行更新,用来解决传统RNN(Recurrent Neural Network,循环神经网络)存在的梯度消失和梯度爆炸问题,以更好地捕捉序列数据中的长期依赖关系;
B3)将B1)中保存的先前路径隐藏状态与B2)更新得到的路径隐藏状态沿着axis=1拼接,对路径状态进行更新,在骨干网节点状态的聚合过程中,采用注意力机制,输出每次迭代完整的路径状态。
其次,对队列隐藏状态
C1)从路径状态序列中获取与队列对应的子集;
C2)将路径状态求和,得到每个队列对应的路径状态总和;
C3)将C1)中得到的当前队列隐藏状态和C2)的路径状态总和作为输入,经过GRU门控循环单元更新得到新的队列状态,输出每次迭代完整的队列状态。
最后,对链路状态
D1)从队列状态中获取与链路对应的子集;
D2)将链路状态经过GRU门控循环单元更新得到新的链路状态;
D3)将D1)中的状态作为输入传递给GRU门控循环单元,并将D2)中的状态作为初始状态,输出每次迭代完整的链路状态。
步骤5,重复步骤4至T次,以实现在更远的节点中进行消息传递,基于更广泛的图形结构进行更新;
在图神经网络中,节点需要通过其邻居节点来更新其特征,每一次迭代,每个节点都会从其邻居节点接收信息,然后更新自己的特征。传递次数T决定了信息在图结构中传递的深度,增加迭代次数,消息可以在图中流动得更远,从而使节点能够接收到更广泛的特征数据,T的具体取值由网络拓扑的深度决定。
步骤6,将T次传递后的路径、链路和队列的隐藏状态
读出函数
步骤7,计算流时延
原理基于排队理论,首先,计算流时延
1)
2)从链路容量列表中获取与路径对应的子集,表示每条链路的容量,神经网络可以根据读出函数输出的路径状态得到队列占有率,进而得到排队时延
其中,/>
3)将平均数据包大小除以链路容量得到传输时延:
其中,/>
其次,计算抖动
其中,/>
最后,丢包率
步骤8,以平均绝对百分误差MAPE作为损失函数,对性能预测模型进行训练,迭代得到收敛值,生成源至目标节点的性能预测矩阵;
平均绝对百分误差MAPE的数学定义式为:
其中,/>
步骤9,根据步骤生成的性能矩阵参数,结合网络拓扑参数,划分为动态参数与静态参数;
动态参数包括时延、抖动和丢包等随网络情况变化的网络性能特征,静态参数为网络的固有属性,如链路容量和节点缓存区大小等。
步骤10,设置强化学习初始策略参数
初始策略函数
步骤11,根据状态
是对已预测网络性能的奖励函数,通过代理找到具有最大QoS奖励的路由路径,以最小化时延、抖动和丢包率,并保持较低的链路负载率。具体来说,感知奖励函数为/>
其中,src和dst分别表示源节点和目的节点,/>
步骤12,从重放缓冲区D中抽取经验Z进行学习,设置计算目标值
重放缓冲区是一种数据结构,通常用于存储和抽取经验。这些经验包括代理在环境中的状态
步骤13,使用均方误差MES作为损失函数更新
MSE的数学定义式为:
其中,/>
首先定义计算目标值:
其中,/>
其次,更新
其中,通过计算/>
更新策略:
其中,/>
更新目标网络:
其中,/>
步骤14,重复步骤12的更新步骤,直至收敛,得到最优负载均衡路径结果。
根据奖励的多约束条件,在基于动态、静态参数的基础上得到最优的路由路径。
图2是本发明与Routenet-Fermi和Routenet-Erlang时延预测对比的训练loss对比图,可以看出本发明的时延预测效果相对于其他两类模型均有提升。
图3是本发明与Routenet-Fermi和Routenet-Erlang抖动预测对比的训练loss结果图,可以看出本发明的抖动预测效果相对于其他两类模型均有提升。
图4是本发明随机抽取50种路径下对时延的真实值与预测值对比的矩形图,由于不同的路径和流量配置有指数级的时延情况,因此抽取了50种时延情况作真实值与预测值对比。
图5是本发明随机抽取50种路径下对时延的真实值与预测值对比的误差散点图,由于不同的路径和流量配置有指数级的时延情况,因此抽取了50种时延情况作真实值与预测值对比。
图6是本发明随机抽取50种路径下对抖动的真实值与预测值对比的矩形图,由于不同的路径和流量配置有指数级的时延情况,因此抽取了50种抖动情况作真实值与预测值对比。
图7是本发明随机抽取50种路径下对抖动的真实值与预测值对比的误差散点图,由于不同的路径和流量配置有指数级的时延情况,因此抽取了50种抖动情况作真实值与预测值对比。
图8是本发明采用的真实网络拓扑图,是由微波、光线、区宽、U/V链和卫星组成的复杂天地一体化网络。
图9是本发明抽象后的网络拓扑图,是图神经网络抽象而成的由节点集
图10是神经网络隐藏状态初始化的模型图,具体步骤如下:
步骤101,通过一个Input层,对于路径状态而言,输出17维,链路状态输出5维,队列状态输出5维;
步骤102,通过一个Dense层,输出均为32维,激活函数采用relu;
步骤103,重复步骤102。
图11是基于MPNN和注意力机制的图神经网络模型,同图1的步骤4、步骤5说明。
图12是一种路径选择方案,是基于当前网络内时延、抖动等多约束进行选择的一条路由方案。