基于层次化策略图的目标分配方法
文献发布时间:2024-04-18 20:02:40
技术领域
本发明属于信号处理领域,具体涉及一种基于层次化策略图的目标分配方法。
背景技术
在当前复杂环境多对多动态博弈的对抗形势下,传统的、简单的单一设备资源分配方案很难满足复杂的防御任务需求。同时在体系场景下,多波次、多威胁目标的状况下,设备资源数量有限,无法针对所有威胁目标使用大量防御资源。因此,需要寻找能够最小化资源损失并且能够最大化防御收益的目标分配方案,将设备资源分配给对应的威胁目标。
传统的目标分配技术主要将目标分配问题抽象为整数规划或混合整数规划问题,分为建模与求解两个过程。针对不同场景建立不同的数学模型,并在该数学模型中确定约束条件以及目标函数,以最小化或最大化目标函数为寻优方向,寻找最终的目标分配方案。其中约束条件与当前态势相关,表示目标分配方案需要满足的条件,例如当前态势需要分配给每个设备资源数目不能超过一定的上限,使用某个设备资源必须满足威胁目标在其范围内等。目标函数为表征目标分配方案好坏的指标,在求最大目标函数的问题中,具有越大的目标函数值的分配方案对我方越有利。目标函数往往由多方面因素共同组成,不同方面的因素就是评价目标分配方案的不同角度,例如成本、收益以及时间等。传统的目标分配技术在数学建模时很难处理设备资源之间的协同关系,一般的解决方法为设定相关的约束条件,在协同关系较为复杂的情况下,构建约束条件的过程也将耗费大量时间,并且在协同关系发生改变时,需要不断调整数学模型,极大地影响目标分配求解的稳定性与可持续性。
传统的目标分配求解技术主要为基于运筹学方法、基于启发式方法以及基于深度强化学习方法。运筹学方法能够在数学层面上对当前构建的数学模型分析,能求得最优解,但仅限简单的模型下,无法应对复杂的场景。启发式方法能够在全部解空间中搜索,逐步逼近最优的目标分配方案,但无法保证得到最优解并且在复杂场景中解空间较大,启发式方法所需要的时间较长,直接使用启发式方法无法满足复杂场景下对决策实时性要求。基于深度强化学习的方法能够通过学习的方式不断优化寻优能力,能够应对复杂情况,但深度强化学习需要大量的训练数据来训练模型,如果在新的场景中缺少训练数据,最终的目标分配的效果就难及预期。因此,本发明希望能够寻找一个可拓展性较强,能够应对复杂多变的场景,并且具有实时性的目标分配方法,即便环境发生较大变化,也不需要改变已经构建的数学模型,只需调整相关参数即可。
发明内容
本发明提出了一种基于层次化策略图的目标分配方法,在传统目标分配方法的基础上,将目标分配问题映射为路径搜索问题,避免了以往目标分配模型拓展性低,无法应对复杂多变的环境态势的难题。
实现本发明的技术解决方案为:一种基于层次化策略图的目标分配方法,步骤如下:
步骤1、对成本与受益进行量化,以确定设备资源执行的成本预估、效果预估以及协同影响;
步骤2、定义层次化策略图;
步骤3、构建层次化策略图;
步骤4、求解策略图,实现目标分配。
本发明与现有技术相比,其显著优点在于:
(1)增强设备资源协作效率层次化策略图模型将设备资源之间的防御抽象为图中的有向边,通过有向边的权值来衡量两种设备资源之间的协同关系。通过协同关系的构建,增强设备资源之间的协作效率,避免了传统单一设备资源没有协作的问题,增强设备资源防御效率。
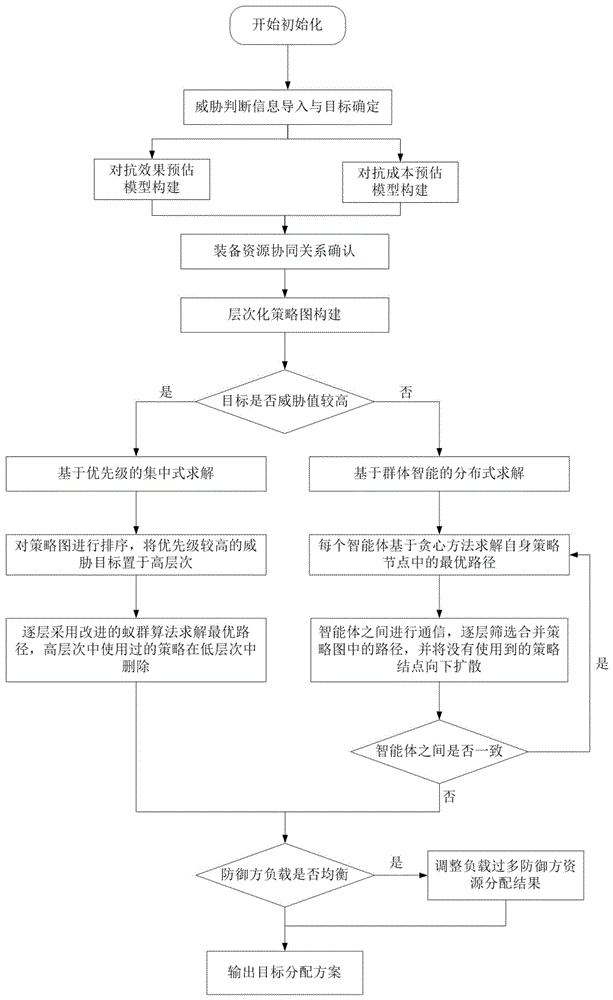
(2)适应环境实时性要求层次化策略图模型针对每个威胁目标构建专门的策略图,包含所有可以使用的策略,排除无效设备资源,减小解空间大小。在威胁目标逼近受保护对象受保护对象时,情况紧急情况下使用集中式方法求解,基于贪心方法思想,优先处理优先级最大的威胁目标,增强模型实时性。在威胁目标处于较远处时使用分布式方法,每个智能体只需要在搜索负责受保护对象上的设备资源,减小每个智能体解空间大小,增强模型实时性。
(3)适应动态性和拓展性以层次化策略图描述当前目标分配模型,可以根据环境动态变化增加策略图中的结点与有向边,用以描述设备资源增减与协同约束条件的变化而不需要改变原本的数学模型,增强模型应对复杂场景动态变化的能力与拓展性。
附图说明
图1是策略图的示意图。
图2是面向多威胁目标的层次化策略图的示意图。
图3是基于群体智能的分布式方法结构的示意图。
图4是本发明方法的原理图。
在图1、图2中的圆形节点都相同,表示防御方编队载有的设备资源,其中标记数字1,2,3,…,9表示设备资源的序号。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围指内。
下面将结合本设计实例对具体实施方式、以及本次发明的技术难点、发明点进行进一步介绍。
结合图1~图4,一种基于层次化策略图的目标分配方法,具体步骤如下:
步骤1、对成本与受益进行量化,以确定设备资源执行的成本预估、效果预估以及协同影响。
S1.1)执行成本预估:设备资源执行成本可用costxy表示,其中x表示当前威胁目标,y表示使用的设备资源。设备资源成本评估模型通过数学建模方式直接建立,主要影响因素为时间成本ctxy,经济成本cexy,安全性能损失成本csxy。在当前态势下确定不同因素的影响权重wxyt,可使用如下方式确定防御成本预估值costij:
因素t=1,2,3……。
S1.2)防御效果预估:由于防御效果由大量因素综合影响,例如天气、距离、威胁目标工作参数以及防御资源工作参数等多种参数组成,很难直接区分多种因素之间的影响权重并且建立对应的物理模型计算防御效果值,因此可以通过构建深度神经网络来预估防御效果。其中深度神经网络输入Input为:
Input=
其中,rtypey表示使用的资源种类,rinfoy表示资源的使用信息,dxy表示设备资源与威胁目标之间的距离,Infox表示威胁目标当前运动状态,Tracex表示威胁目标轨迹预测。将多种不同的影响防御效果的因素组成输入向量,输入构建的深度神经网络中,最终输出结点如下:
Output=
其中,ex表示防御效果评估值。
S1.3)协同影响预估:协同影响预估模型采用基于专家知识的方式构建,协同影响effxy主要通过专家知识库中获取,表示在当前威胁目标下使用某种设备资源能否加强下一个设备资源的使用效果。主要输入使用的资源类型rtypex,rtypey以及威胁目标Targetx,输出协同影响值effxy。
步骤2、定义层次化策略图:
该层次化策略图由结点与有向边组成,如示例图1、2所示。示例图1中的策略图对应的一个威胁目标,策略图中的结点表示该威胁目标可以使用的策略,策略是一个动态的过程,指在满足当前态势情况下,使用该设备资源防御该威胁目标,一个策略对应一个设备资源。因此,一个策略图中策略结点的最大数目为设备资源的最大数目N
步骤3、构建层次化策略图
S3.1)建立目标-设备资源映射:在目标-设备资源映射过程中,使用Resource= S3.2)生成有向边:策略图中有向边的有无主要取决于当前场景中设备资源之间的协同关系以及设备资源之间的约束条件。设备资源之间如果没有协同关系,则两个设备资源之间没有有向边相连,如果在当前态势下某几种设备资源之间相互排斥,只能选择一种执行,则这几种设备资源之间没有有向边相连,并且在算法搜索过程中,如果出现同时使用互斥资源的情况,就应该舍弃当前解。主要考虑设备资源y与y'之间是否具有协同约束关系,若能够满足当前协同约束关系,就构造一条有向边Edeg 步骤4、求解策略图: S4.1)分析层次化策略:通过利用策略图,寻找目标分配最优解的问题可以转化为在当前策略图中寻找一条符合条件的最优路径问题。在构建完成的层次化策略图中求解每个威胁目标的分配方案,采用基于优先级的集中式方法与基于群体智能的分布式方法求解目标分配方案。对于威胁值较大(已锁定设备并能稳定干扰设备正常运行)以及短时间(数秒)内能够干扰设备的威胁目标,采用基于优先级的集中式分配方法。由于在不同策略图之间,不同策略可能对应一个设备资源,因此在不同策略图使用相同的设备资源会产生冲突。将每个威胁目标的策略图以优先级排序,层次高的策略图具有较高的优先级,在设备资源出现冲突时优先使用。集中式方法将层次按照优先级排序,采用自上而下的寻优方法,在每层策略图中可以采取多种不同的方法求解,但由于体系对抗下设备资源多,威胁目标多造成的解空间过大的问题,传统的运筹学方法或最优解方法无法求解,因此寻找尽可能有利的近似解为集中式方法的目标,采用启发式方法能够有效的寻找近似解,而不需要在所有解空间中搜索。 S4.2)求解近区问题:采用改进蚁群的启发式方法在基于优先级的集中式方法中搜索每个层次策略图中的次优解。蚁群算法模拟蚂蚁寻路的过程,通过信息素来控制搜索算法的搜寻方向,越高信息素的道路将会有更多种群进行探索,其中信息素的定义如下: 其中 为了提升在多次迭代之后的种群的多样性,防止算法收敛于局部最优解,使用贪婪策略优化传统蚁群算法。随着迭代次数的增加,信息素的浓度和启发式信息的相对重要性不断调整,种群的多样性也在动态变化,使得算法不容易陷入局部最优解,提高算法的搜索能力。其中α和β的更新定义为如下公式: 其中xmax和xmin分别表示残差信息的相对重要程度的最小和最大值。ymax和ymin分别表示预测值的相对重要程度的最大和最小值。n表示当前迭代次数,Max表示最大迭代次数。在算法初始化时,需要设置有限范围的α和β。其中残差信息相对重要程度α和启发式信息相对重要程度β将随着迭代次数的增加以非线性变化的形式改变。随着蚁群探索过程中信息素浓度的增加,α的值将会不断增加,残差信息的重要性不断增加。相反,β不断减少,启发式信息的重要性不断下降。在这种动态调整的算法中,启发式信息重要性逐步下降,从而确保蚁群在搜索过程中得到充分探索,增强种群的多样性,确保算法不容易陷入局部最优解。 在当前场景下使用的启发式函数定义为:ηij=wij,其中wij表示策略图中有向边的权值,代表了当前场景中设备资源的收益评估模型。在迭代过程中信息素挥发的速度可以定义为: 其中,θ为信息素衰减参数,Δτijk表示种群中个体k释放的信息素强度,ρ(t)是蚂蚁遗忘程度参数,在迭代过程中θ的值不断减小,减少信息素挥发程度,m表示种群中个体总数。 S4.3)求解远区问题:采用基于群体智能的分布式求解方法寻找次优解,结构如图3所示,将场景中的每个受保护对象抽象为一个智能体,每个受保护对象所对应的智能体只能够基于当前受保护对象中的设备资源进行分配,并与其他智能体通信,最终将整个系统趋于一致。分布式求解方法将场景中的每个受保护对象抽象为智能体Agenti,智能体可用三元组Agenti= 内部共识阶段主要包括捆绑包构建过程与冲突处理过程。捆绑包构建过程中每个Agent通过构建can-do列表,can-do列表表示当前Agent可以处理的目标集合。在求解初始阶段,can-do列表为策略图中具有该受保护对象资源的设备资源的威胁目标,在不断迭代并逐步确定每层策略图中的次优路径之后,删除已经分配的策略结点,重新确定can-do列表。接着采用贪心方法搜索路径,得到每个策略图从自身利益出发的较优路径。在Agent贪心求解完成之后,与其他Agent通信,每次迭代中逐层确定策略图的次优路径。若某层策略图中若某个Agent能够单独执行该防御任务,且当前Agent求得的路径优于其他路径,则直接使用该路径作为该层策略图中的最终路径。若不存在Agent单独完成任务,则择优连接不同Agent间的路径,得出该层策略图的最终路径。在迭代中确定某层策略图中的最终路径之后,Agent需要将没有使用到的策略结点添加到其他层次中,以此更新下一次迭代中贪心方法求得的路径。在通信阶段Agent执行三种操作:更新(update)cij=ckj,zij=zkj;重置(reset)cij=0, 在外部共识阶段主要处理不同Agent之间的约束条件,并在当前策略层中初步进行负载均衡。根据场景输入的约束条件,调整路径中的某些结点选择,对不满足约束的结点采用跳过、绕路或相近资源替换的方法连接路径。在负载均衡阶段,若某个受保护对象的资源使用率ratei已经超过一定阈值Th,则需要尝试将周围负载低于一定阈值Tl中的策略结点进行替换。其中资源替换选择就近智能体中相同类型的设备资源,减少负载过多受保护对象的资源使用率。外部共识阶段不考虑当前状况下的最优解,而是着眼于全局约束条件与负载状况,调整负载以避免某些受保护对象在复杂场景前期过度使用资源而无法应对突发状况的问题。
- 基于多尺度层次化特征表示的目标跟踪方法与系统
- 基于多尺度层次化特征表示的目标跟踪方法与系统