基于大模型的视频剪辑方法、装置、设备、介质及产品
文献发布时间:2024-07-23 01:35:21
技术领域
本申请实施例涉及视频处理领域,尤其涉及一种基于大模型的视频剪辑方法、装置、设备、介质及产品。
背景技术
短视频内容生产是短视频行业的重要环节,通过视频剪辑手段将电影、电视剧等长视频切分为多段短视频是一种常见的短视频生成方式。视频切分流程通常包括熟悉长视频的内容(长视频一般定义为时长大于1200秒的视频);确定内容段,其包含一个较为独立的叙事、场景大体一致;确定内容段后裁剪视频作为短视频;为裁剪的短视频添加标题的步骤,往往需要专业的剪辑人员、后期人员依序进行剪辑、适配标题等一系列操作,耗费了大量的人力和时间。
目前,已提出了一些自动化剪辑视频的相关方案,通过识别长视频的高光时刻或者转场等获得切分的候选集。这些方案首先在标注的视频切分数据上训练视频分割模型,然后使用该分割模型预测可能的候选时间作为切分后短视频的边界帧。然而,训练视频分割模型需要依赖大量的长视频标注数据作为训练数据集,该标注数据是由专门人员通过浏览长视频的内容并人工标注边界帧来获得,标注过程仍需要耗费较多的人力和时间,而且在模型推理阶段需要将整个待剪辑的长视频输入模型中,不仅耗时较多、效率较低,而且分割的效果不佳。
发明内容
本申请实施例提供了一种基于大模型的视频剪辑方法、装置、设备、介质及产品,解决了相关技术中视频分割需要耗费大量人力和时间,效率低且分割效果不佳的技术问题。
在第一方面,本申请实施例提供了一种基于大模型的视频剪辑方法,包括:
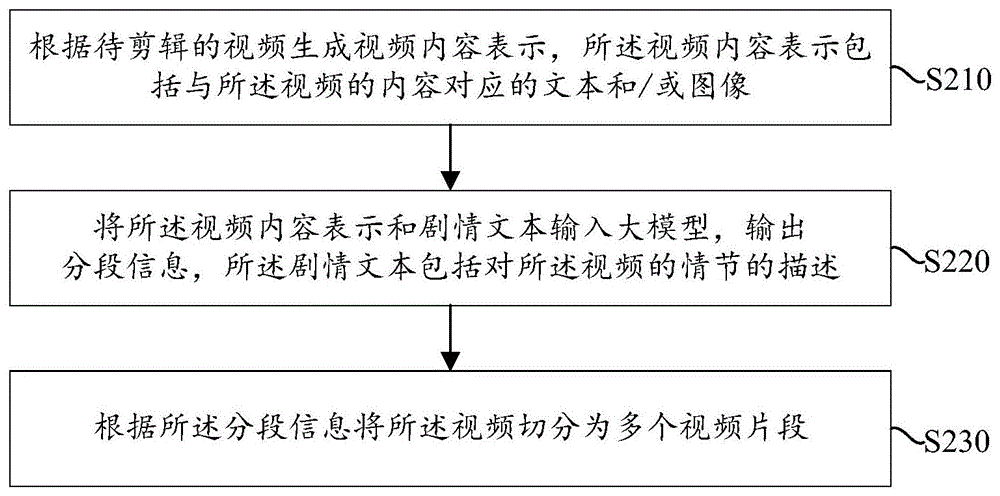
根据待剪辑的视频生成视频内容表示,所述视频内容表示包括与所述视频的内容对应的文本和/或图像;
将所述视频内容表示和剧情文本输入大模型,输出分段信息,所述剧情文本包括对所述视频的情节的描述;
根据所述分段信息将所述视频切分为多个视频片段。
在第二方面,本申请实施例提供了一种基于大模型的视频剪辑装置,包括:
生成模块,配置为根据待剪辑的视频生成视频内容表示,所述视频内容表示包括与所述视频的内容对应的文本和/或图像;
第一处理模块,配置为将所述视频内容表示和剧情文本输入大模型,输出分段信息,所述剧情文本包括对所述视频的情节的描述;
第一切分模块,配置为根据所述分段信息将所述视频切分为多个视频片段。
在第三方面,本申请实施例提供了一种计算机设备,包括:存储器以及一个或多个处理器;
所述存储器,用于存储一个或多个程序;
当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如第一方面所述的视频剪辑方法。
在第四方面,本申请实施例提供了一种存储计算机可执行指令的非易失性存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行如第一方面所述的视频剪辑方法。
在第五方面,本申请实施例提供了一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的视频剪辑方法。
本申请实施例中提供的一个或多个技术方案中,通过根据待剪辑的视频生成与所述视频的内容对应的文本和/或图像作为视频内容表示,将所述视频内容表示和包括视频情节描述的剧情文本输入大模型,得到用于切分视频片段的分段信息,无需使用大规模的标注数据训练分割模型,也不需要以完整长度的视频作为模型的输入,大大降低了人力和时间成本,而且利用视频内容表示和剧情文本作为输入,引入了更加全局和深层次的语义信息,实现了更佳的视频分割效果,从而提升了短视频内容生产的效率和质量。
附图说明
图1是本申请实施例提供的视频剪辑方法的应用场景示意图;
图2是本申请实施例提供的一种基于大模型的视频剪辑方法的流程图;
图3是本申请实施例提供的另一种基于大模型的视频剪辑方法的流程图;
图4是根据本申请实施例实现的视频剪辑过程的数据流向示意图;
图5是本申请实施例提供的一种基于大模型的视频剪辑装置的结构示意图;
图6是本申请实施例提供的一种计算机设备的结构示意图。
具体实施方式
为了使本申请的目的、技术方案和优点更加清楚,下面结合附图对本申请具体实施例作进一步的详细描述。可以理解的是,此处所描述的具体实施例仅仅用于解释本申请,而非对本申请的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本申请相关的部分而非全部内容。在更加详细地讨论示例性实施例之前应当提到的是,一些示例性实施例被描述成作为流程图描绘的处理或方法。虽然流程图将各项操作(或步骤)描述成顺序的处理,但是其中的许多操作可以被并行地、并发地或者同时实施。此外,各项操作的顺序可以被重新安排。当其操作完成时上述处理可以被终止,但是还可以具有未包括在附图中的附加步骤。上述处理可以对应于方法、函数、规程、子例程、子程序等等。
本申请的说明书和权利要求书中的术语“第一”、“第二”等是用于区别类似的对象,而不用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便本申请的实施例能够以除了在这里图示或描述的那些以外的顺序实施,且“第一”、“第二”等所区分的对象通常为一类,并不限定对象的个数,例如第一对象可以是一个,也可以是多个。此外,说明书以及权利要求中“和/或”表示所连接对象的至少其中之一,字符“/”,一般表示前后关联对象是一种“或”的关系。
图1为本申请实施例提供的视频剪辑方法的应用场景示意图。在该示例性的应用场景中,视频剪辑方法由服务器12执行。服务器12从例如数据库11的数据源中取得一个待剪辑的长视频,例如一集电视剧、一部电影等,然后执行视频剪辑方法对该长视频进行切分,得到多个短视频。所生成的短视频可以被发送到数据库中进行存储或者上传至内容平台的服务器13,以对外进行发布。然后,基于推荐系统或者其他下游分发方式,用户可以使用终端14从内容平台上观看上述短视频。
应理解,本申请实施例提供的视频剪辑方法可以应用于任何具备相应处理能力的电子设备,如终端设备、服务器等。其中,终端设备具体可以为智能手机、计算机、个人数字助理(Personal Digital Assistant,PDA)、平板电脑等;服务器具体可以为应用服务器,也可以为Web服务器,在实际应用部署时,该服务器可以为独立服务器,也可以为集群服务器。
图2为本申请实施例提供的一种基于大模型的视频剪辑方法的流程示意图。如图2所示,该基于大模型的视频剪辑方法包括:
S210:根据待剪辑的视频生成视频内容表示,所述视频内容表示包括与所述视频的内容对应的文本和/或图像;
其中,所述待剪辑的视频包括任何时间长度的视频。
示例性地,所述待剪辑的视频为长视频,即时长大于1200秒的视频,例如电视剧、电影等。
示例性地,所述视频内容表示还包括时间戳信息。
在一个实施例中,所述视频内容表示包括与所述视频的内容对应的文本,例如包括根据视频中的语音内容生成的语音文字,以及每段语音文字对应的时间戳。其中,语音内容包括视频中的人物对话和画外音介绍。具体地,所述根据待剪辑的视频生成视频内容表示,包括:
从所述待剪辑的视频中提取语音音频及其时间戳;
将所述语音音频转换为对应语音内容的文字;
根据所述文字和时间戳生成视频内容表示。
其中,可使用自动语音识别(Automatic Speech Recognition,ASR)模型将所述语音音频转换为对应语音内容的文字。示例性地,ASR模型具有去噪能力,可去除语音音频中背景音、配乐、插曲等干扰,对人物对话和画外音介绍进行识别。由此,生成了包括语音文字和时间戳的文本形式的视频内容表示。示例性地,该视频内容表示具有JSON(JavaScriptObject Notation,JS对象简谱)格式。
在另一个实施例中,所述视频内容表示包括与所述视频的内容对应的图像,例如从视频中提取的多个视频帧,以及每个视频帧对应的时间戳。具体地,所述根据待剪辑的视频生成视频内容表示,包括:
从所述待剪辑的视频中提取视频帧及其时间戳,
根据所述视频帧的图像和时间戳生成视频内容表示。
其中,在一个实施例中,所提取的视频帧为视频的全部视频帧。由于很多的相邻视频帧具有近似的画面内容,在另一实施例中,所提取的视频帧为视频的部分视频帧,例如仅提取其中的关键帧,从而减少大模型所处理的图像数量,且不会影响分割效果。由此,生成了包括视频帧的图像和时间戳的视频内容表示。示例性地,所述视频帧的图像为RGB图像。
S220:将所述视频内容表示和剧情文本输入大模型,输出分段信息,所述剧情文本包括对所述视频的情节的描述;
其中,剧情文本是预先生成的,其作为外部知识,描述了视频中的主要人物、故事情节发展等基础信息,体现了视频的全局信息。示例性地,剧情文本为500字左右的分段文本。一般地,视频制作方在制作视频时已经生成了相应的剧情文本。
在一个实施例中,在该步骤之前,根据所述视频获取对应的剧情文本。例如根据所述视频的标题从互联网上搜索得到该视频的剧情文本,或者根据所述视频的标题从互联网上搜索得到该视频的剧情信息,再对搜索到的剧情信息采用自动化工具进行汇总、去重等处理生成剧情文本。获取剧情文本的操作可以在步骤S210之前、之后或与步骤S210并行地执行。
其中,大模型(Large Model,也称为基础模型,即Foundation Model)是指包含超大规模参数(通常在十亿个以上)的神经网络模型,例如GPT-4、GLM-4、文心一言、BLIP-2等。大模型已经在大规模的通用数据集上进行了预训练,在应用时无需训练即可完成实体识别、文本分类、阅读理解等多种任务。大模型示例性地基于Transformer网络结构,或者基于RNN(Recurrent Neural Network,循环神经网络)或CNN(Convolutional Neural Network,卷积神经网络)的视觉网络结构。
在一个实施例中,上述大模型为大语言模型,该类大模型能够接收文字形式的输入,并且按照要求输出分段信息。
在一个实施例中,上述大模型为多模态大模型,该类大模型能够接收图像帧、文字等多种形式的输入,并且按照要求输出分段信息。
示例性地,当视频内容表示仅包括文本时,使用大语言模型具有较好的效果;当视频内容表示包括图像时,大语言模型无法进行处理该类输入,需要使用多模态大模型。
其中,通过提示(prompt)指令的方式实现大模型的输入,在提示指令中嵌入所输入的内容的链接,并包括对输出内容的要求以及其它要求,大模型基于提示指令可以得知有哪些输入信息并明确所要执行的具体任务。
在一个实施例中,所述将所述视频内容表示和剧情文本输入大模型,包括:
将所述视频内容表示和所述剧情文本的链接嵌入第一提示指令中,将所述视频内容表示、剧情文本和第一提示指令输入所述大模型;
在一个实施例中,所述第一提示指令还包括关于输出分段信息的指示。
示例性地,关于输出分段信息的指示包括分段信息的输出格式,例如结构化的JSON格式,并定义其中的具体字段;关于输出分段信息的指示还可以包括分割得到的视频片段的数量范围、视频片段的时长限制等,从而使得生成的视频片段更加便于发布和观看。
大模型接收第一提示指令后,根据其中嵌入的链接获取视频内容表示和剧情文本,并按照其中所指示的输出对象和输出格式输出多个分段信息。示例性地,所述分段信息包括视频片段的时间信息,例如视频片段的开始时间和结束时间。
S230:根据所述分段信息将所述视频切分为多个视频片段。
其中,根据每个分段信息中视频片段的开始时间和结束时间,从长视频中切分出对应的视频片段,得到多个短视频。
在本申请实施例提供的基于大模型的视频剪辑方法中,使用大模型生成视频的分段信息,利用了大模型的强泛化性和少样本学习能力,无需使用大规模的标注数据训练分割模型,大大降低了人力和时间成本;通过采用视频内容表示和剧情文本作为模型输入,不需要输入完整长度的长视频,进一步降低了花费的时间,即使输入规模增加也不会显著地增加时间成本;通过输入视频内容表示和剧情文本能够引入全局和深层的语义信息,从而实现了更佳的分割效果;结合提示指令的使用,可以对输出结果提出具体的要求,进一步保障了生成的短视频的质量。采用本申请实施例的方法,可以大大提升短视频内容生产的效率和质量。
通常,按照内容平台规范的要求,提供短视频的同时还需要提供视频标题等额外信息。因此,在切分得到多个视频片段后,还需要为每个视频片段生成标题。在相关技术中,需要先使用视频标签模型对视频打明码标签,再通过固定模版对标签进行处理以生成视频标题。然而,这就需要使用标注数据训练出视频标签模型,同样耗费了较多的人力和时间,且视频标签模型的预测结果为有限或者预定义的闭集,其所能描述的标签是有限的,而且视频标签模型只能学习到视频中浅层的物体、人物等信息,导致生成的标题无法满足和目标短视频语义上连贯、自然等要求,标题质量不高。
为此,在图2所示的视频剪辑方法的基础上,本申请实施例提供了另一种基于大模型的视频剪辑方法,基于大模型实现视频切分的同时,还为切分得到的每个视频片段生成高质量的标题。
图3为本申请实施例提供的另一种基于大模型的视频剪辑方法的流程示意图。其中的步骤S310~S330与图2中的步骤S210~S230相同。
如图3所示,该视频剪辑方法包括:
S310:根据待剪辑的视频生成视频内容表示,所述视频内容表示包括与所述视频的内容对应的文本和/或图像;
S320:将所述视频内容表示和剧情文本输入大模型,输出分段信息,所述剧情文本包括对所述视频的情节的描述;
S330:根据所述分段信息将所述视频切分为多个视频片段;
S340:根据所述分段信息将所述视频内容表示切分为多个片段内容表示;
示例性地,根据视频内容表示中的时间戳信息和分段信息中视频片段的时间信息,将视频内容表示切分为多个片段内容表示,每个片段内容表示与一个视频片段相对应。
在视频内容表示包括与所述视频的内容对应的文本的实施例中,片段内容表示包括与视频片段的内容对应的文本,例如包括与该视频片段中的语音内容对应的文字,以及每段语音内容对应的时间戳。
在视频内容表示包括与所述视频的内容对应的图像的实施例中,片段内容表示包括与所述视频片段的内容对应的图像,例如包括与视频片段的内容对应的多个视频帧,以及每个视频帧对应的时间戳。
S350:将所述多个片段内容表示和所述剧情文本输入大模型,输出多个片段标题。
其中,通过提示(prompt)指令的方式实现大模型的输入。
在一个实施例中,所述将所述多个片段内容表示和剧情文本输入大模型,包括:
将所述多个片段内容表示和所述剧情文本的链接嵌入第二提示指令中,将所述片段内容表示、剧情文本和第二提示指令输入所述大模型;
在一个实施例中,所述第二提示指令还包括关于输出片段标题的指示。示例性地,关于输出片段标题的指示包括片段标题的风格,例如幽默或悬疑等,和/或片段标题的样式,例如对仗式、字数限制等。
大模型接收第二提示指令后,根据其中嵌入的链接获取片段内容表示和剧情文本,并按照其中所指示的输出对象输出与该片段内容表示对应的标题,该标题具有第二提示指令中要求的输出风格和/或输出样式等。
在本申请实施例提供的基于大模型的视频剪辑方法中,通过使用大模型进行视频切分和标题生成,可以一次性地得到带有标题的短视频,而无需训练不同的模型,具有较高的生成效率,大大节省了人力和时间;大模型输出的标题不受有限集合的限制,通过以片段内容表示和剧情文本作为模型输入,同时引入了片段信息和全局信息,从而保证了视频片段和标题的语义一致性和连贯性,且能够输出具有知识结构的高质量标题,例如能够体现视频中角色之间的关系;而且,通过提示指令可以灵活调整大模型输出的风格、样式等属性,可以生成风格多样化的标题,满足不同目标客户、不同场景的需求。
而且,图2和图3所示的本申请实施例具有规模效应,输出量级、计算资源量、时间成本与输入量级成线性正比关系,确保本申请实施例可以大规模应用于自动内容生产业务。
需要说明的是,图2和图3示出的视频编辑方法是无训练的,也即直接应用已有的大模型,无需执行基于大量标注数据的训练过程。可选地,也可以预先地使用少量的标注数据集对大模型进行微调,应用微调后的大模型以实现特定偏好的输出。
为了更清楚地阐释本申请上述实施例提供的视频剪辑方法,图4示出了根据本申请实施例实现的视频剪辑过程的数据流向示意图。视频剪辑过程由两个部分组成,第一部分是视频切分过程,如图4(a)所示,该部分过程将一个完整的长视频切分成多个无标题的短视频,第二部分是标题生成过程,如图4(b)所示,该部分过程为多个无标题的短视频生成符合短视频实际内容的标题。
如图4(a)所示,首先,获取待剪辑的长视频,例如是以mp4等格式预先存储在数据库中的一集电视剧。然后,对该长视频进行解码,得到具有时间戳信息的RGB视频帧图像和音频文件,该音频文件中包含了视频中的语音音频。在本实施例中,基于视频中的语音生成视频内容表示,利用例如ASR模型等手段将音频文件中的语音转化为文字,并且提取每段语音的时间戳信息,得到包含对应语音内容的文字和时间戳的语音文本作为视频内容表示,该文本例如为JSON格式,表示为x
{“01:30”:“引子:1992年的大上海霓虹养眼,……故事就从这里开始了”,
“02:18”:“你不买我买,……”,
“02:43”:“宝总今天要重出江湖,……”,
…
…
“38:18”:“我们两个人……”
}
此外,还需要获取预先生成的剧情文本作为外部知识引入,其表示为x
“引子:1992年的大上海霓虹养眼,万花如海,街上车水马龙,人们行色匆匆。阿宝拎着礼品来看望退休在家的老作家。老作家笔耕不辍,最近在写一部小说,阿宝好奇地打听小说的内容,他还没有想好,只是开了一个头,故事就从这里开始了。
中国改革开放的总设计师邓小平南巡讲话,加快了中国股份制改革的步伐,举世瞩目。股票是最新的热点,同样是以一百点为起点,美国道琼斯指数到今天才不过3300点,刚满一岁的上证指数已经接近1000点。机会面前人人平等,抓住了机会就有可能改变人生。有人乘风而起,有人半日归零。
阿宝正值青春,他像每个上海人一样每天在这滚滚红尘里钻门路,撑市面。阿宝雄心万丈,却不知道这不是梦,而是醒不过来的现实。今天是12月31日,和平饭店里人声鼎沸,上海滩的各界名流齐聚于此迎接新年,时钟马上就到12点,人们开始倒计时。阿宝拎着三十万现金从饭店出来,他刚想上车离开,就被一辆疾驰而来的出租车撞飞,箱子里的钱散落一地,肇事车辆掉头逃走。
……”
然后,通过提示(prompt)指令的方式将上述语音文本和剧情文本输入大模型,此处使用的大模型为大语言模型,例如GPT系列。该提示指令表示为x
clip_num,表示切分后的视频片段的编号;
start_time,表示该视频片段起始时在长视频中所处的时间戳;
end_time,表示该视频片段结束时在长视频中所处的时间戳。
一个提示指令的示例如下:
“你是一个专业的剪辑师,你能够将一段长视频剪辑成短视频,但是遗憾的是你无法获得原始视频,不过你可以获得视频中人物交谈,在人物交谈中,包含对应的时间戳,以及剧情介绍等;这些信息都是互补的,能帮助你判断如何剪辑一个完整故事的clip;
其中的语音文字为:{语音文本},剧情介绍为{剧情文本};
要求你输出若干个不等的片段,输出格式为:
{“clip_num”:1,“start_time”:01:30,“end_time”:08:24}”
大语言模型接收上述语音文本x
y
其中,θ
{“clip_num”:1,“start_time”:01:30,“end_time”:08:24}
{“clip_num”:2,“start_time”:08:25,“end_time”:11:23}
……
{“clip_num”:n,“start_time”:29:15,“end_time”:38:18}
然后,根据上述分段信息对待剪辑的长视频进行切分,得到多个视频片段video1、video2、……video n,也即生成了无标题的短视频。当然,也可以按照需求对片段数量n的数值进行预先设定,例如通过在提示指令中明确所要分割的片段数量,或者每个片段的时长限制。
如图4(b)所示,接下来要利用所得到的分段信息对初始得到的视频内容表示文本进行处理,即将ASR识别得到的语音文本x
{“01:30”:“引子:1992年的大上海霓虹养眼,……故事就从这里开始了”,
“02:18”:“你不买我买,……”,
“02:43”:“……”,
…
“08:24”:“这件事就这样了,你也别指望还能怎么样”
}
和第一部分的过程类似,第二部分中大模型的输入还包括对应的剧情文本x
“你是一个专业的剪辑师,你能够将一段长视频剪辑成短视频,但是遗憾的是你无法获得原始视频,不过你可以获得视频中人物交谈,在人物交谈中,包含对应的时间戳,以及剧情介绍等;这些信息都是互补的,能帮助你判断如何剪辑一个完整故事的clip;
其中的语音文字为:{片段文本},剧情介绍为{剧情文本};
要求你输出一个标题,标题切合这一段语音文字,也符合剧情介绍;标题的字数不超过20个字。”
然后,将片段文本x
y
其中,θ
例如对应视频片段vedio 1的标题1为:“霓虹灯下的上海:阿宝的梦开始的地方”,对应视频片段video 2的标题2为:“青春的迷惘:阿宝的上海梦”,等等。
最后,将第一部分得到的视频片段重命名为对应的第二部分输出的标题,得到符合内容平台规范要求的短视频集合,完成对长视频的自动剪辑处理。
所属领域的技术人员可以理解,本申请实施例的视频剪辑过程也可以基于RGB视频帧图像生成视频内容表示,由于例如BLIP-2的多模态大模型具有描述图像所呈现的信息的能力,可以直接将长视频解码得到的图像集合或者从中选取部分关键帧的图像集合作为多模态大模型的一类输入,在得到分段信息后将RGB图像分为与视频片段对应的多个图像子集,再次输入大模型得到短视频的标题。其中所使用的提示指令与图4所示过程中的示例相比仅嵌入的输入内容不同。
本申请实施例的上述过程利用了大模型的强泛化性和少样本学习能力,使用表示视频内容的文本或图像,结合外部的剧集描述等知识数据和一些提示指令,就可以快速、大量地生产质量较高的短视频。
图5为本申请实施例提供的一种基于大模型的视频剪辑装置的结构示意图。该装置实施例与图2和图3所示的视频剪辑方法的实施例相对应,可以具体应用于终端设备、服务器、服务器集群等各种计算机设备中。
如图5所示,本实施例的视频剪辑装置500包括:
生成模块501,配置为根据待剪辑的视频生成视频内容表示,所述视频内容表示包括与所述视频的内容对应的文本和/或图像;
第一处理模块502,配置为将所述视频内容表示和剧情文本输入大模型,输出分段信息,所述剧情文本包括对所述视频的情节的描述;
第一切分模块503,配置为根据所述分段信息将所述视频切分为多个视频片段。
在一个实施例中,生成模块501配置为从所述待剪辑的视频中提取语音音频及其时间戳;将所述语音音频转换为对应语音内容的文字;根据所述文字和时间戳生成视频内容表示。
在一个实施例中,生成模块501配置为从所述待剪辑的视频中提取视频帧及其时间戳,根据所述视频帧和时间戳生成视频内容表示。
在一个实施例中,装置500还包括第二切分模块504和第二处理模块505,第二切分模块504配置为根据所述分段信息将所述视频内容表示切分为多个片段内容表示,第二处理模块505配置为将所述多个片段内容表示和所述剧情文本输入大模型,输出多个片段标题。
本申请实施例所提供的视频剪辑装置可执行本申请任意实施例所提供的视频剪辑方法,具备执行方法相应的功能模块和有益效果。所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的装置实施例的具体工作过程和有益效果,可以参考图2和图3示出的方法实施例中的对应内容,在此不再赘述。
在上述实际例的基础上,本申请实施例还提供了一种计算机设备,参照图6,该计算机设备包括:处理器61、存储器62、通信模块63、输入装置64及输出装置65。存储器作为一种计算机可读存储介质,可配置为存储软件程序、计算机可执行程序以及模块,如本申请任意实施例所述的视频剪辑方法对应的程序指令/模块。通信模块63配置为进行数据传输。处理器61通过运行存储在存储器中的软件程序、指令以及模块,从而执行设备的各种功能应用以及数据处理,即实现上述的视频剪辑方法。输入装置64可配置为接收输入的数字或字符信息,以及产生与设备的用户设置以及功能控制有关的键信号输入。输出装置65可包括显示屏等显示设备。上述提供的计算机设备可配置为执行上述实施例提供的视频剪辑方法,具备相应的功能和有益效果。
在上述实施例的基础上,本申请实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令在由计算机处理器执行时配置为执行一种基于大模型的视频剪辑方法,存储介质可以是任何的各种类型的存储器设备或存储设备。当然,本申请实施例所提供的一种计算机可读存储介质,其计算机可执行指令不限于如上所述的方法,还可以执行本申请任意实施例所提供的视频剪辑方法中的相关操作。
在上述实施例的基础上,本申请实施例还提供一种计算机程序产品,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机程序产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备、移动终端或其中的处理器执行本申请各个实施例所述视频剪辑方法的全部或部分步骤。
注意,上述仅为本申请实施例的较佳实施例及所运用技术原理。所属领域的技术人员会理解,本申请实施例不限于这里所述的特定实施例,对所属领域的技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本申请实施例的保护范围。因此,虽然通过以上实施例对本申请实施例进行了较为详细的说明,但是本申请实施例不仅仅限于以上实施例,在不脱离本申请实施例构思的情况下,还可以包括更多其他等效实施例,而本申请实施例的范围由所附的权利要求范围决定。
- 基于模型的产品构建方法、装置、计算机设备及存储介质
- 基于网页标签的产品数据推送方法、装置、设备及介质
- 基于区块链的理财产品推荐方法、装置、介质及电子设备
- 基于模板的产品构建方法、装置、计算机设备及存储介质
- 基于图表的产品构建方法、装置、计算机设备及存储介质
- 基于大模型的信息处理方法、装置、设备、介质和产品
- 基于大语言模型的信息获取方法、装置、设备及介质