一种通过头部追踪实现场景切换的耳机实现方法
文献发布时间:2024-07-23 01:35:21
技术领域
本发明涉及耳机控制领域,尤其涉及一种通过头部追踪实现场景切换的耳机实现方法。
背景技术
蓝牙耳机就是将蓝牙技术应用在免持耳机上,让使用者可以免除恼人电线的牵绊,自在地以各种方式轻松通话,其解决了传统有线耳机使用的局限性,增加了使用的便捷性。
例如,经检索,中国专利公开号为CN218473350U的专利,公开了一种智能运动蓝牙耳机,包括智能运动蓝牙耳机连接线,所述智能运动蓝牙耳机连接线的右侧固定连接有智能运动蓝牙耳机耳机头;所述智能运动蓝牙耳机连接线的表面套设有移动套,所述移动套的数量为两个,所述移动套的内壁固定连接有挤压防移位抵紧片,所述挤压防移位抵紧片远离移动套内壁的一侧与智能运动蓝牙耳机连接线的表面接触。
上述专利存在以下不足:其无法实现使用者所处场景的感知,从而无法根据使用者所处场景来切换不同的音乐,具有一定的局限性。
为此,本发明提出一种通过头部追踪实现场景切换的耳机实现方法。
发明内容
本发明的目的是为了解决现有技术中存在的缺点,而提出的一种通过头部追踪实现场景切换的耳机实现方法。
为了实现上述目的,本发明采用了如下技术方案:
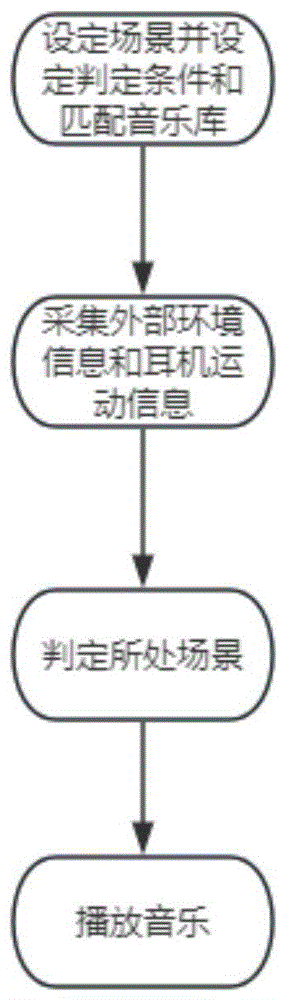
一种通过头部追踪实现场景切换的耳机实现方法,包括以下步骤:
S1:设定场景,并设定每个场景的判定条件以及每个场景的匹配音乐库;
S2:在耳机使用过程中,实时采集外部环境信息以及耳机运动信息;
S3:根据外部环境信息以及耳机运动信息确定使用者所处环境;
S4:根据所处环境确定场景,并播放与场景匹配的音乐。
优选地:所述S1步骤中,音乐库从互联网获取。
优选地:所述S1步骤中,每个场景匹配的音乐库的播放顺序采用基于热度的播放顺序和基于喜爱程度的播放顺序。
优选地:所述基于热度的播放顺序其包括以下步骤:
S11a:获取所有的播放列表音乐信息,并随机排序;
S12a:随机选择一首歌曲,并从互联网获取所有用户对该歌曲的喜爱程度,然后以平均值的形式最为该歌曲的热度;
S13a:将所有歌曲,按照热度降序排列即可。
优选地:所述S12a步骤中,用户对歌曲的喜爱程度为用户对该歌曲的总播放时长。
优选地:所述基于喜爱程度的播放顺序包括以下步骤:
S11b:从互联网获取所有音乐列表,并随机排序;
S12b:用户前期对音乐进行随机播放,且播放时采集每首音乐的播放时长;
S13b:然后将总播放时长作为用户对改歌曲的喜爱程度,然后按照降序排列即可。
优选地:所述S2步骤中,外部环境信息包括外部温度信息、外部声音幅值信息、外部声音内容信息,所述耳机运动信息包括耳机的震动幅度和频率,耳机的运动速度和加速度。
优选地:所述S3步骤中,其具体包括以下步骤:
S31:首先根据大数据确定每个场景下的每个信息阈值范围T
S32:若实际采集的信息完全落入T
S33:若实际采集的信息无法完全落入T
优选地:所述S33步骤中,采用基于投票的形式判断包括以下步骤:
S331:对于每种信息进行实际判断,获取该项目投票得分;
S332:统计一个场景内所有项目的得分总数,并设定最小阈值比较;
S333:若所有场景内存在大于最小阈值的得分,则以最高得分的场景为当前得分;
S334:若所有场景的得分均小于最小阈值的得分,则自动建立新的场景信息。
优选地:所述S331步骤中,其得分计算包括以下情况:
S3311:若实际采集信息落入阈值区间内,则得分为“1”;
S3312:若实际采集信息不落入阈值区间内,且小于阈值区间的下限值,则按照公式
S3313:若实际采集信息不落入阈值区间内,且大于阈值区间的上限值,则按照公式
本发明的有益效果为:
1.本发明通过对场景进行设定,并设定每个场景的判定条件以及每个场景的匹配音乐库,然后再根据实际采集到的外部环境信息以及耳机运动信息判定场景,从而能根据实际场景进行音乐切换,解决了局限性问题。
附图说明
图1为本发明提出的一种通过头部追踪实现场景切换的耳机实现方法的流程示意图。
具体实施方式
下面结合具体实施方式对本发明的技术方案作进一步详细地说明。
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“设置”应做广义理解,例如,可以是固定相连、设置,也可以是可拆卸连接、设置,或一体地连接、设置。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
实施例1:
一种通过头部追踪实现场景切换的耳机实现方法,包括以下步骤:
S1:设定场景,并设定每个场景的判定条件以及每个场景的匹配音乐库;
S2:在耳机使用过程中,实时采集外部环境信息以及耳机运动信息;
S3:根据外部环境信息以及耳机运动信息确定使用者所处环境;
S4:根据所处环境确定场景,并播放与场景匹配的音乐。
所述S2步骤中,外部环境信息包括外部温度信息、外部声音幅值信息、外部声音内容信息,所述耳机运动信息包括耳机的震动幅度和频率,耳机的运动速度和加速度。
实施例2:
一种通过头部追踪实现场景切换的耳机实现方法,包括以下步骤:
S1:设定场景,并设定每个场景的判定条件以及每个场景的匹配音乐库;
S2:在耳机使用过程中,实时采集外部环境信息以及耳机运动信息;
S3:根据外部环境信息以及耳机运动信息确定使用者所处环境;
S4:根据所处环境确定场景,并播放与场景匹配的音乐。
所述S2步骤中,外部环境信息包括外部温度信息、外部声音幅值信息、外部声音内容信息,所述耳机运动信息包括耳机的震动幅度和频率,耳机的运动速度和加速度。
所述S3步骤中,其具体包括以下步骤:
S31:首先根据大数据确定每个场景下的每个信息阈值范围T
S32:若实际采集的信息完全落入T
S33:若实际采集的信息无法完全落入T
实施例3:
一种通过头部追踪实现场景切换的耳机实现方法,包括以下步骤:
S1:设定场景,并设定每个场景的判定条件以及每个场景的匹配音乐库;
S2:在耳机使用过程中,实时采集外部环境信息以及耳机运动信息;
S3:根据外部环境信息以及耳机运动信息确定使用者所处环境;
S4:根据所处环境确定场景,并播放与场景匹配的音乐。
所述S2步骤中,外部环境信息包括外部温度信息、外部声音幅值信息、外部声音内容信息,所述耳机运动信息包括耳机的震动幅度和频率,耳机的运动速度和加速度。
所述S3步骤中,其具体包括以下步骤:
S31:首先根据大数据确定每个场景下的每个信息阈值范围T
S32:若实际采集的信息完全落入T
S33:若实际采集的信息无法完全落入T
所述S33步骤中,采用基于投票的形式判断包括以下步骤:
S331:对于每种信息进行实际判断,获取该项目投票得分;
S332:统计一个场景内所有项目的得分总数,并设定最小阈值比较;
S333:若所有场景内存在大于最小阈值的得分,则以最高得分的场景为当前得分;
S334:若所有场景的得分均小于最小阈值的得分,则自动建立新的场景信息。
实施例4:
一种通过头部追踪实现场景切换的耳机实现方法,包括以下步骤:
S1:设定场景,并设定每个场景的判定条件以及每个场景的匹配音乐库;
S2:在耳机使用过程中,实时采集外部环境信息以及耳机运动信息;
S3:根据外部环境信息以及耳机运动信息确定使用者所处环境;
S4:根据所处环境确定场景,并播放与场景匹配的音乐。
所述S2步骤中,外部环境信息包括外部温度信息、外部声音幅值信息、外部声音内容信息,所述耳机运动信息包括耳机的震动幅度和频率,耳机的运动速度和加速度。
所述S3步骤中,其具体包括以下步骤:
S31:首先根据大数据确定每个场景下的每个信息阈值范围T
S32:若实际采集的信息完全落入T
S33:若实际采集的信息无法完全落入T
所述S33步骤中,采用基于投票的形式判断包括以下步骤:
S331:对于每种信息进行实际判断,获取该项目投票得分;
S332:统计一个场景内所有项目的得分总数,并设定最小阈值比较;
S333:若所有场景内存在大于最小阈值的得分,则以最高得分的场景为当前得分;
S334:若所有场景的得分均小于最小阈值的得分,则自动建立新的场景信息。
所述S331步骤中,其得分计算包括以下情况:
S3311:若实际采集信息落入阈值区间内,则得分为“1”;
S3312:若实际采集信息不落入阈值区间内,且小于阈值区间的下限值,则按照公式
S3313:若实际采集信息不落入阈值区间内,且大于阈值区间的上限值,则按照公式
实施例5:
一种通过头部追踪实现场景切换的耳机实现方法,包括以下步骤:
S1:设定场景,并设定每个场景的判定条件以及每个场景的匹配音乐库;
S2:在耳机使用过程中,实时采集外部环境信息以及耳机运动信息;
S3:根据外部环境信息以及耳机运动信息确定使用者所处环境;
S4:根据所处环境确定场景,并播放与场景匹配的音乐。
所述S2步骤中,外部环境信息包括外部温度信息、外部声音幅值信息、外部声音内容信息,所述耳机运动信息包括耳机的震动幅度和频率,耳机的运动速度和加速度。
所述S3步骤中,其具体包括以下步骤:
S31:首先根据大数据确定每个场景下的每个信息阈值范围T
S32:若实际采集的信息完全落入
T
S33:若实际采集的信息无法完全落入T
所述S33步骤中,采用基于投票的形式判断包括以下步骤:
S331:对于每种信息进行实际判断,获取该项目投票得分;
S332:统计一个场景内所有项目的得分总数,并设定最小阈值比较;
S333:若所有场景内存在大于最小阈值的得分,则以最高得分的场景为当前得分;
S334:若所有场景的得分均小于最小阈值的得分,则自动建立新的场景信息。
所述S331步骤中,其得分计算包括以下情况:
S3311:若实际采集信息落入阈值区间内,则得分为“1”;
S3312:若实际采集信息不落入阈值区间内,且小于阈值区间的下限值,则按照公式
S3313:若实际采集信息不落入阈值区间内,且大于阈值区间的上限值,则按照公式
所述S1步骤中,音乐库从互联网获取。
所述S1步骤中,每个场景匹配的音乐库的播放顺序采用基于热度的播放顺序。
述基于热度的播放顺序其包括以下步骤:
S11a:获取所有的播放列表音乐信息,并随机排序;
S12a:随机选择一首歌曲,并从互联网获取所有用户对该歌曲的喜爱程度,然后以平均值的形式最为该歌曲的热度;
S13a:将所有歌曲,按照热度降序排列即可。
实施例6
一种通过头部追踪实现场景切换的耳机实现方法,包括以下步骤:
S1:设定场景,并设定每个场景的判定条件以及每个场景的匹配音乐库;
S2:在耳机使用过程中,实时采集外部环境信息以及耳机运动信息;
S3:根据外部环境信息以及耳机运动信息确定使用者所处环境;
S4:根据所处环境确定场景,并播放与场景匹配的音乐。
所述S2步骤中,外部环境信息包括外部温度信息、外部声音幅值信息、外部声音内容信息,所述耳机运动信息包括耳机的震动幅度和频率,耳机的运动速度和加速度。
所述S3步骤中,其具体包括以下步骤:
S31:首先根据大数据确定每个场景下的每个信息阈值范围T
S32:若实际采集的信息完全落入T
S33:若实际采集的信息无法完全落入T
所述S33步骤中,采用基于投票的形式判断包括以下步骤:
S331:对于每种信息进行实际判断,获取该项目投票得分;
S332:统计一个场景内所有项目的得分总数,并设定最小阈值比较;
S333:若所有场景内存在大于最小阈值的得分,则以最高得分的场景为当前得分;
S334:若所有场景的得分均小于最小阈值的得分,则自动建立新的场景信息。
所述S331步骤中,其得分计算包括以下情况:
S3311:若实际采集信息落入阈值区间内,则得分为“1”;
S3312:若实际采集信息不落入阈值区间内,且小于阈值区间的下限值,则按照公式
S3313:若实际采集信息不落入阈值区间内,且大于阈值区间的上限值,则按照公式
所述S1步骤中,音乐库从互联网获取。
所述S1步骤中,每个场景匹配的音乐库的播放顺序采用基于喜爱程度的播放顺序。
所述基于热度的播放顺序其包括以下步骤:
S11a:获取所有的播放列表音乐信息,并随机排序;
S12a:随机选择一首歌曲,并从互联网获取所有用户对该歌曲的喜爱程度,然后以平均值的形式最为该歌曲的热度;
S13a:将所有歌曲,按照热度降序排列即可。
本发明,通过对场景进行设定,并设定每个场景的判定条件以及每个场景的匹配音乐库,然后再根据实际采集到的外部环境信息以及耳机运动信息判定场景,从而能根据实际场景进行音乐切换,解决了局限性问题。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 一种实现医药行业批次级的逆向追踪方法
- 用于实现头部跟踪耳机的方法和装置
- 基于头部运动实现超视距视觉追踪的无人机系统