设备控制方法及装置
文献发布时间:2023-06-19 10:00:31
技术领域
本申请涉及电子设备控制领域,尤其涉及基于设备控制方法及装置。
背景技术
随着智能手机发展,便携式音频设备越来越多,很多的便携设备都自带麦克风(microphone)。例如手机、平板电脑、耳机等设备通常都具有麦克风,麦克风主要用于采集用户的声音进行通话、录音等。
为了拓展麦克风的应用,现有一种方案中,可利用麦克风实现对设备进行语音控制。用户通过对麦克风说话而发出语音命令,麦克风采集用户的语音命令,使用语音识别技术识别出语义,形成控制命令,进而根据控制命令完成对设备的控制。
然而在一些需要保持安静的场合,用户不适合说话或者不愿意说话,这样的场合就不能采用语音控制的方式来控制设备,给用户造成了困扰。
发明内容
本申请提供了设备控制方法及装置,能够实现在用户不发出声响的情况下利用麦克风来控制设备,解决了用户的痛点,提升用使用户体验。
第一方面,本申请提供一种设备控制方法,该方法应用于具有至少一个麦克风的第一设备,包括:通过所述至少一个麦克风采集音频信号;确定所述音频信号的信号类型和音频特征;所述信号类型至少包括风噪;判断所述信号类型和所述音频特征是否符合预设条件;当所述信号类型和所述音频特征符合预设条件时,触发所述预设条件对应的控制命令。
其中,所述音频信号可以是由用户的无声操作引起的,所述无声操作是由所述用户的手部触发且不被人耳感知到声响的操作。举例来说,人耳能听到的最小的声音强度为1分贝(decibel,db),那么由该用户的无声操作导致的声响可以低于1分贝。所述无声操作例如可以是摩擦至少一个麦克风、点击至少一个麦克风、在至少一个麦克风附近扇风、在至少一个麦克风附近吹气的至少一种。由无声操作引起的音频信号可以是风噪信号或者类似于风噪信号。
其中,所述该信号类型可以是由风躁引起的音频信号的类型。举例来说,一种具体分类中,信号类型例如可划分为:由摩擦麦克风所引起的信号类型、由点击麦克风所引起的信号类型、由向麦克风扇风所引起的信号类型、由向麦克风吹气所引起的信号类型。信号类型直接反应了用户的无声操作的动作类型,所述动作类型例如可划分为:摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等动作类型。
音频特征可以是音频信号中的目标特征,音频特征反映了无声操作的动作特征,例如动作频次、动作力度、动作节奏、动作顺序等。
信号类型和音频特征的组合和控制命令之间具有映射关系,那么当所述信号类型和所述音频特征符合预设条件(例如信号类型和音频特征的组合符合预设组合),则可触发所述预设条件(例如预设组合)对应的控制命令。
可以看到,本申请实施例中,当通过麦克风采集到用户摩擦或点击麦克风的无声操作或者在麦克风附近扇风或吹气的无声操作所引起的音频信号(风噪信号),第一设备可识别出音频信号的信号类型和音频特征,从而实现对该无声操作的识别,进而可以根据信号类型和音频特征的组合对应的控制命令实现对第二设备的控制。这样,实现了在用户不发出声音的情况下也能对第二设备进行控制,拓展了用户对设备控制形式。无声操作的输入方式比较简便,提高了第二设备拨打紧急电话等操作的隐蔽性。此外,由于本申请使用的第一设备本身就具有麦克风,通过复用设备上的麦克风就可以实现控制功能,无须增加额外的传感器设备,且成本较低,设备功耗较低。所以,实施本申请能极大提升用户的使用体验。
基于第一方面,在可能的实施例中,所述第一设备与第二设备通信连接,所述控制命令用于对所述第二设备进行控制。
例如,第一设备可以是耳机、智能眼镜、智能手表、智能手环之类的具有麦克风的可穿戴设备,第二设备可以是智能手机、平板电脑、笔记本电脑之类的具有被控需求的移动终端。在用户不发出声音的情况下,可利用第一设备可利用本申请的方法实现对第二设备的控制,极大提升用户的使用体验。
基于第一方面,在可能的实施例中,所述控制命令用于对所述第一设备进行控制。这样的方案中,第一设备可基于本申请描述的方法来实现自我控制。例如,以第一设备为智能手机为例,该智能手机可包括一个或多个麦克风,例如包括设置于智能手机顶部的顶部麦克风和设置于智能手机底部的底部麦克风。在用户不发出声音的情况下,用户可根据需要对这两个麦克风中的至少一个麦克风进行无声操作,触发对智能手机的控制,拓展了用户对智能手机的控制手段,提升用户的使用体验。
基于第一方面,在可能的实施例中,所述确定所述音频信号的信号类型,包括:通过检测所述音频信号的时域特征、频谱特征中的一种或多种,获得所述信号类型。其中时域特征表示无声操作引起的音频信号的时域脉冲信号,例如可用振幅与时间的变化关系来体现;频谱特征表示无声操作引起的音频信号的频率谱密度,例如可用振幅与频率的变化关系来体现。通过算法方式能快识别信号类型,且成本较低。
举例来说,不同的无声操作引起的音频信号的时域特征各不相同,时域特征表示无声操作引起的音频信号的时域脉冲信号。那么在采集到音频信号后,可根据音频信号的时域特征通过检测算法确定当前信号的信号类型。
又举例来说,由无声操作引起的音频信号可以是风噪信号或者类似于风噪信号,第一设备可以利用风噪检测算法检测麦克风采集到的音频信号中是否包含具有风噪特性的信号。例如,采用基于数字信号处理的方法,计算所采集的音频信号的频谱的功率谱密度,通过功率谱密度的特征识别该音频信号是否具有风噪特性的信号。如是,则说明该音频信号是由无声操作引起的,否则,说明该音频信号不是由无声操作引起的(例如可能是用户说话的声音,背景环境噪音等)。然后,可对不同无声操作对应的信号类型通过检测算法进行区别。例如,对于由摩擦或点击麦克风的采声部位置引起的音频信号,由于是近距离施加在麦克风采声部位置,所产生的音频信号相比起向麦克风扇风/吹气引起的音频信号而言,能量更大。第一设备可通过信号的能量的大小来区分由无声操作所引起的音频信号(噪声信号)的信号类型,能量小于设定的阈值则认为是在麦克风附近扇风/吹气的动作引起的信号类型,否则认为是由摩擦或点击麦克风采声部位置的动作引起的信号类型。从而实现了第一设备区分不同的无声操作的信号类型。
基于第一方面,在可能的实施例中,所述确定所述音频信号的信号类型,包括:根据所述音频信号和神经网络模型,获得所述信号类型;其中,所述神经网络模型表征了音频信号和信号类型之间的映射关系。通过机器学习的方法能够提高信号类型的准确度和识别效率。
例如,可预先采用机器学习的方法,利用大量的训练数据,进行模型训练得到模型。其中,训练数据包括由无声操作引起的音频信号数据(例如摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等无声操作引起的音频信号)和信号类型,即该模型可表征音频信号与信号类型之间的映射关系。第一设备获取并保存该模型。当第一设备采集到音频信号时,可以将音频信号输入到模型,从而获得模型输出的信号类型。
机器学习模型具体可以是下述模型中的一种:神经网络(Neural Network,NN)模型、深度神经网络(Deep Neural Network,DNN)模型、因式分解机支持的神经网络(Factorization-machine supported Neural Networks,FNN)模型、卷积神经网络(Convolutional Neural Networks,CNN)模型、基于内积的神经网络(Inner Product-based Neural Network,IPNN)模型、基于外积的神经网络(Outer Product-based NeuralNetwork,OPNN)模型、神经分解机(Neural Factorization Machines,NFM)模型等等。
基于第一方面,在可能的实施例中,所述确定所述音频信号的信号类型和音频特征,包括:通过对所述音频信号进行特征提取,获得所述音频特征。
其中,所述音频特征例如包括:所述音频信号中风噪脉冲的频次、能量、持续时间、音长特征、音强特征、采集不同信号类型的顺序中的一种或多种。风噪脉冲的频次体现了音频信号中脉冲激发的次数、脉冲激发的快慢等。脉冲的能量体现了音频信号中脉冲激发的能量大小。脉冲的持续时间体现了音频信号中脉冲持续的时长。采集不同的信号类型的顺序可以是单个麦克风采集不同类型(例如摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等动作类型)的无声操作引起的音频信号的先后顺序,还可以是不同麦克风(例如两个麦克风)采集相同或不同类型的无声操作引起的音频信号的先后顺序。
音频特征反映了无声操作的动作特征,也就是说,根据音频特征(例如所述音频信号中脉冲的频次、能量、持续时间、音长特征、音强特征、采集不同信号类型的顺序中的一种或多种)可以识别出无声操作的动作特征(例如动作频次、动作力度、动作节奏、动作顺序等中的一种或多种)。
例如,第一设备的麦克风采集的音频信号可能包括无声操作的多个动作类型产生的音频信号,可通过语音激活检测技术将音频信号进行分段,每个分段表示一种动作类型,通过检测一个分段内与待识别的动作相对应的音频信号的持续时间,以及不同分段内与待识别的动作相对应的音频信号的起始时间的间隔,区分不同动作类型的动作的快慢。通过对不同分段内动作类型进行统计,获得不同动作类型的动作频次。通过统计一段时间内,不同分段内动作类型以及各自连续出现的动作频次,可以进一步获得无声操作的动作节奏或者动作顺序。从而,实现了第一设备获得无声操作的音频信号对应的动作特征。
基于第一方面,在可能的实施例中,所述预设条件为一个或多个包含信号类型和音频特征的预设组合;所述判断所述信号类型和所述音频特征是否符合预设条件,包括:判断所述信号类型和所述风噪脉冲的频次、能量、持续时间、音长特征、音强特征、采集不同信号类型的顺序中的一种或多种所形成的组合是否符合所述预设组合。
其中,每个预设组合与至少一种控制指令具有映射关系。
所述当所述信号类型和所述音频特征符合预设条件时,触发所述预设条件对应的控制命令,包括:当所述信号类型和所述音频特征的组合符合所述预设组合中的目标预设组合时,触发所述目标预设组合对应的控制命令。
本申请实施例中,动作类型和信号类型具有对应关系,动作特征和信号特征具有对应关系。所以,信号类型和音频特征的组合(预设组合)可以用动作类型和动作特征的组合(预设组合)来体现,那么可以预先存储动作类型和动作特征的组合与控制命令之间的映射关系,这样,根据该映射关系即可获得对应的控制命令。所以,实施本申请能够快速地确定信号类型和所述音频特征的组合对应的控制命令,降低控制时延,提升用户体验。
基于第一方面,在可能的实施例中,所述第一设备例如为耳机(比如无线耳机),所述第二设备例如为智能设备;第一设备和第二设备通信连接。所述控制命令用于对所述第二设备执行以下至少一种控制:控制所述第二设备执行拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、或开启/关闭指定功能模式。所述指定功能模式例如可以是静音模式、振动模式、飞行模式、省电模式、主动降噪(ANC)功能、监听模式(HearThrough)等等中的一种或多种功能。
基于第一方面,在可能的实施例中,所述第一设备例如为智能设备;所述控制命令用于对所述第一设备执行以下至少一种控制:控制所述第一设备执行拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、或开启/关闭指定功能模式。所述指定功能模式例如可以是静音模式、振动模式、飞行模式、省电模式、主动降噪(ANC)功能、监听模式(HearThrough)等等中的一种或多种功能。
基于第一方面,在可能的实施例中,还可通过以下方法确定与所述信号类型和所述音频特征对应的控制命令:确定与所述信号类型对应的动作类型,所述动作类型表示引起所述噪声信号的用户动作的操作类型;确定与所述音频特征对应的动作特征,所述动作特征包括所述用户动作的动作频次、动作力度、动作节奏、动作顺序中的一种或多种;根据用户预设的动作类型和动作特征与控制命令之间的映射关系(例如映射表),确定与所述动作类型和所述动作特征对应的控制命令。
基于第一方面,在可能的实施例中,所述动作类型包括:向所述至少一个麦克风扇风;
所述动作特征包括如下至少一种:向所述至少一个麦克风扇风的次数为一次或多次、向所述至少一个麦克风扇风的次数大于或等于第一次数阈值、向所述至少一个麦克风扇风的时长大于或等于第一时长阈值、向所述至少一个麦克风扇风的强度大于或等于第一强度阈值、向所述至少一个麦克风扇风的间隔大于或等于第一时长间隔。
基于第一方面,在可能的实施例中,所述动作类型包括:摩擦所述至少一个麦克风;
所述动作特征包括如下至少一种:摩擦所述至少一个麦克风的次数为一次或多次、摩擦所述至少一个麦克风的次数大于或等于第二次数阈值、摩擦所述至少一个麦克风的时长大于或等于第二时长阈值、摩擦所述至少一个麦克风的强度大于或等于第二强度阈值、摩擦所述至少一个麦克风的间隔大于或等于第二时长间隔。
基于第一方面,在可能的实施例中,所述动作类型包括:向所述至少一个麦克风吹气;
所述动作特征包括如下至少一种:向所述至少一个麦克风吹气的次数为一次或多次、向所述至少一个麦克风吹气的次数大于或等于第三次数阈值、向所述至少一个麦克风吹气的时长大于或等于第三时长阈值、向所述至少一个麦克风吹气的强度大于或等于第三强度阈值、向所述至少一个麦克风吹气的间隔大于或等于第三时长间隔。
基于第一方面,在可能的实施例中,所述动作类型包括:点击所述至少一个麦克风;
所述动作特征包括如下至少一种:点击所述至少一个麦克风的次数为一次或多次、点击所述至少一个麦克风的次数大于或等于第四次数阈值、点击所述至少一个麦克风的时长大于或等于第四时长阈值、点击所述至少一个麦克风的强度大于或等于第四强度阈值、点击所述至少一个麦克风的间隔大于或等于第四时长间隔。
基于第一方面,在可能的实施例中,当第一设备中还设置有除麦克风之外的其他传感器时,还可以利用所述其他传感器,辅助第一设备检测麦克风采集的音频信号中是否存在与待识别的无声操作相对应的噪声信号,提高识别的准确率和可靠性,进一步提升用户使用体验,且能节约误识别带来的功耗。
基于第一方面,在可能的实施例中,第一设备还可以利用第二设备或其他终端设备或服务器提供的信息,控制本申请提供的设备控制方法的功能的开启或关闭,从而提升设备可靠性和准确性,提升用户使用体验。
第二方面,本申请提供一种用于设备控制的装置,应用于具有至少一个麦克风的第一设备,包括:采集模块,用于通过所述至少一个麦克风采集音频信号;信号处理模块,用于确定所述音频信号的信号类型和音频特征;所述信号类型至少包括风噪;控制模块,用于判断所述信号类型和所述音频特征是否符合预设条件;当所述信号类型和所述音频特征符合预设条件时,触发所述预设条件对应的控制命令。该装置的各功能模块具体用于实现第一方面所描述的方法。
可以看到,本申请实施例中,当通过麦克风采集到用户摩擦或点击麦克风的无声操作或者在麦克风附近扇风或吹气的无声操作所引起的音频信号(风噪信号),第一设备可识别出音频信号的信号类型和音频特征,从而实现对该无声操作的识别,进而可以根据信号类型和音频特征的组合对应的控制命令实现对第二设备的控制。这样,实现了在用户不发出声音的情况下也能对第二设备进行控制,拓展了用户对设备控制形式。无声操作的输入方式比较简便,提高了第二设备拨打紧急电话等操作的隐蔽性。此外,由于本申请使用的第一设备本身就具有麦克风,通过复用设备上的麦克风就可以实现控制功能,无须增加额外的传感器设备,且成本较低,设备功耗较低。所以,实施本申请能极大提升用户的使用体验。
基于第二方面,在可能的实施例中,所述第一设备与第二设备通信连接,所述控制命令用于对所述第二设备进行控制。
基于第二方面,在可能的实施例中,所述控制命令用于对所述第一设备进行控制。
基于第二方面,在可能的实施例中,所述信号处理模块用于:通过检测所述音频信号的时域特征、频谱特征中的一种或多种,获得所述信号类型;通过对所述音频信号进行特征提取,获得所述音频特征。
基于第二方面,在可能的实施例中,所述信号处理模块用于:根据所述音频信号和神经网络模型,获得所述信号类型;其中,所述神经网络模型表征了音频信号和信号类型之间的映射关系;通过对所述音频信号进行特征提取,获得所述音频特征。
基于第二方面,在可能的实施例中,所述音频特征包括:所述音频信号中风噪脉冲的频次、能量、持续时间、音长特征、音强特征、采集不同信号类型的顺序中的一种或多种。
基于第二方面,在可能的实施例中,所述预设条件为至少一个包含信号类型和音频特征的预设组合;所述控制模块具体用于,判断所述信号类型和所述风噪脉冲的频次、能量、持续时间、音长特征、音强特征、采集不同信号类型的顺序中的一种或多种所形成的组合是否符合所述预设组合。
基于第二方面,在可能的实施例中,每个预设组合与至少一种控制指令具有映射关系;
所述控制模块具体用于,当所述信号类型和所述音频特征的组合符合所述预设组合中的目标预设组合时,触发所述目标预设组合对应的控制命令。
基于第二方面,在可能的实施例中,所述第一设备例如为耳机(比如无线耳机),所述第二设备例如为智能设备;第一设备和第二设备通信连接。所述控制命令用于对所述第二设备执行以下至少一种控制:控制所述第二设备执行拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、或开启/关闭指定功能模式。所述指定功能模式例如可以是静音模式、振动模式、飞行模式、省电模式、主动降噪(ANC)功能、监听模式(HearThrough)等等中的一种或多种功能。
基于第二方面,在可能的实施例中,所述第一设备例如为智能设备;所述控制命令用于对所述第一设备执行以下至少一种控制:控制所述第一设备执行拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、或开启/关闭指定功能模式。所述指定功能模式例如可以是静音模式、振动模式、飞行模式、省电模式、主动降噪(ANC)功能、监听模式(HearThrough)等等中的一种或多种功能。
第三方面,本申请实施例提供一种设备,所述设备为第一设备,包括:至少一个麦克风;一个或多个处理器;存储器;以及一个或多个计算机程序;其中所述一个或多个计算机程序被存储在所述存储器中,所述一个或多个计算机程序包括指令,当所述指令被所述第一设备执行时,使得所述第一设备执行如第一方面所描述的方法。
第四方面,本申请实施例提供一种芯片,所述芯片包括处理器与数据接口,所述处理器通过所述数据接口读取存储器上存储的指令,执行第一方面或第一方面的任一可能的实施方式中的方法。
可选地,作为一种实施方式,所述芯片还可以包括存储器,所述存储器中存储有指令,所述处理器用于执行所述存储器上存储的指令,当所述指令被执行时,所述处理器用于执行第一方面或第一方面的任一可能的实施方式中的方法。
第五方面,本申请实施例提供一种计算机可读存储介质,所述计算机可读介质存储用于设备执行的程序代码,所述程序代码包括用于执行第一方面或者第一方面的任一可能的实施方式中的方法的指令。
第六方面,本发明实施例提供了一种计算机程序产品,该计算机程序产品可以为一个软件安装包,该计算机程序产品包括程序指令,当该计算机程序产品被电子设备执行时,该电子设备的处理器执行前述第一方面任一实施例中的方法。
可以看到,本申请实施例中,当通过麦克风采集到用户摩擦或点击麦克风的无声操作或者在麦克风附近扇风或吹气的无声操作所引起的音频信号,第一设备可识别出音频信号的信号类型和音频特征,进一步确定信号类型和音频特征分别对应的动作类型和动作特征,从而实现对该无声操作的识别,进而可以根据动作类型和动作特征的组合对应的控制命令实现对第二设备的控制。这样,实现了在用户不发出声音的情况下也能对第二设备进行控制,拓展了用户对设备控制形式。无声操作的输入方式比较简便,提高了第二设备拨打紧急电话等操作的隐蔽性。此外,由于本申请使用的第一设备本身就具有麦克风,通过复用设备上的麦克风就可以实现控制功能,无须增加额外的传感器设备,且成本较低,设备功耗较低。所以,实施本申请能极大提升用户的使用体验。
附图说明
图1为本申请实施例提供的一种系统架构示意图;
图2为本申请实施例提供的一种无线通信的头戴式耳机的示例性示意图;
图3为本申请实施例提供的一种无线通信的入耳式耳机的示例性示意图;
图4为本申请实施例提供的一种无线通信的颈挂式耳机的示例性示意图;
图5为本申请实施例提供的一种智能手机的的示例性示意图;
图6为本申请实施例提供的一种示例性的设备的结构示意图;
图7为本申请实施例提供的一种设备控制方法的流程示意图;
图8为本申请实施例提供的一种摩擦麦克风的无声操作的场景的示意图;
图9为本申请实施例提供的一种点击擦麦克风的无声操作的场景的示意图;
图10为本申请实施例提供的一种向麦克风扇风的无声操作的场景的示意图;
图11为本申请实施例提供的一种向麦克风吹气的无声操作的场景的示意图;
图12为本申请实施例提供的一种采用本申请方法实现的场景的示意图;
图13为本申请实施例提供的一种采用本申请方法实现的场景的示意图;
图14为本申请实施例提供的一种设备控制方法的流程示意图;
图15为本申请实施例提供的一种摩擦麦克风的时域脉冲信号示意图;
图16为本申请实施例提供的一种向麦克风扇风的时域脉冲信号示意图;
图17为本申请实施例涉及的一种人声的时域脉冲信号示意图;
图18为本申请实施例提供的一种设备控制方法的流程示意图;
图19为本申请实施例提供的一种用户界面的示意图;
图20为本申请实施例提供的一种第一设备的结构示意图,以及由第一设备和第二设备组成的系统的结构示意图。
具体实施方式
下面结合本申请实施例中的附图对本申请实施例进行描述。本申请的实施方式部分使用的术语仅用于对本申请的具体实施例进行解释,而非旨在限定本申请。本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”等是用于区别不同对象,而不是用于限定特定顺序。在本申请实施例中,“示例性的”或者“例如”等词用于表示作例子、例证或说明。本申请实施例中被描述为“示例性的”或者“例如”的任何实施例或设计方案不应被解释为比其它实施例或设计方案更优选或更具优势。确切而言,使用“示例性的”或者“例如”等词旨在以具体方式呈现相关概念。
在本申请实施例或所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。如本文所使用的,单数形式的“一”、“某”和“该”旨在也包括复数形式,除非上下文另有明确指示。还将理解,术语“包括”、“具有”、“包含”和/或“含有”在本文中使用时指定所陈述的特征、整数、步骤、操作、要素、和/或组件的存在,但并不排除一个或多个其他特征、整数、步骤、操作、要素、组件和/或其群组的存在或添加。
需要说明的是,在本申请实施例中使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本申请。
本申请提供了基于麦克风的设备控制方法,该方法能够应用于具有麦克风(microphone)的设备。本文中所称的麦克风是一种用于声音信号采集的装置。麦克风也可能被称为话筒、耳麦、拾音器、收音器、传音器、声音传感器、声敏传感器、音频采集装置或其他某个合适的术语。本文主要以麦克风为例进行技术方案的描述。
本文中,应用本申请所描述的设备控制方法的设备又可称为第一设备,受该第一设备控制的设备可称为第二设备。
在一些方案中,第一设备和第二设备是不同的设备,也就是说,第一设备可基于本申请描述的方法来控制第二设备。第一设备和第二设备之间可进行通信,例如第一设备可通过比如无线保真(wireless-fidelity,Wifi)通信、蓝牙通信、红外通信、或蜂窝2/3/4/5代(2/3/4/5generation,2G/3G/4G/5G)通信等通信方式实现对第二设备的控制。
其中,第一设备和第二设备中的至少一者也可能被称为用户装备(UE)、可穿戴设备、移动单元、订户单元、无线单元、远程单元、移动设备、无线设备、无线通信设备、远程设备、移动订户站、终端设备、接入终端、移动终端、无线终端、智能终端、远程终端、手持机、用户代理、移动客户端、客户端、或其他某个合适的术语。
例如,第一设备可以是耳机、智能眼镜、智能手表、智能手环之类的具有麦克风的可穿戴设备,也可以是智能手机、平板电脑、笔记本电脑之类的具有麦克风的移动终端,也可以是音响设备、智能电视机、智能空调以及智能冰箱之类的具有麦克风的智能家居设备,还可以是电单车设备、汽车设备之类的具有麦克风的车载设备。本申请实施例对第一设备的具体形式不做特殊限制。
例如,第二设备可以是智能手机、平板电脑、笔记本电脑之类的具有被控需求的移动终端,也可以是音响设备、智能电视机、智能空调以及智能冰箱之类的具有被控需求的智能家居设备,还可以是电单车设备、汽车设备之类的具有被控需求的车载设备。本申请实施例对第二设备的具体形式不做特殊限制。
为了便于方案的理解,本文后续主要以第一设备为耳机,第二设备为移动终端(例如手机)为例进行技术方案的描述。
参见图1,图1为本申请实施例提供的一种系统架构示意图,该系统架构包括移动终端(图示中的移动终端以智能手机为例)和具有麦克风的耳机,耳机和移动终端之间可建立通信连接。
从耳机的通信方式上看,应用本申请的耳机可以是无线耳机或有线耳机。无线耳机即可以与移动终端进行无线连接的耳机,根据无线耳机使用的电磁波频率,还可以将它们进一步区分为:红外线无线耳机、米波无线耳机(例如FM调频耳机)、分米波无线耳机(例如蓝牙耳机)等等。有线耳机即可以与移动终端通过导线(例如线缆)连接的耳机,根据线缆形状还可以区分为圆柱形线缆耳机、面条线耳机等等。
从耳机的佩戴方式上看,应用本申请的耳机可以是入耳式耳机、半入耳式耳机、耳挂式耳机、颈挂式耳机、头戴式耳机(贴耳式耳机、包耳式耳机)、骨传导耳机等等。
从耳机的结构功能方式上看,应用本申请的耳机可以是封闭式耳机、开放式耳机、半开放式耳机、半开放式耳机等等。
从耳机的降噪方式上看,应用本申请的耳机可以是主动降噪(Active NoiseCancellation,ANC)功能的耳机、被动降噪功能的耳机、非降噪的耳机。
本文中,主要以具有麦克风的无线耳机(例如蓝牙耳机)为例进行方案的描述,麦克风的数量可以是一个,也可以是多个。
例如,在图2示出了一种无线通信(例如蓝牙耳机)的头戴式耳机,该头戴式耳机包括一个麦克风,该麦克风可伸出该头戴式耳机的听筒装置之外,以方便用户根据需要对麦克风进行操作。
又例如,在图3示出了一种无线通信(例如蓝牙耳机)的入耳式耳机,该入耳式耳机的麦克风可内置于该入耳式耳机的耳机听筒装置,从而使得该入耳式耳机更加便携、轻便易带。每个入耳式耳机例如包括一个麦克风,那么可以理解的,一对入耳式耳机(即包括用在左耳的入耳式耳机和用在右耳的入耳式耳机)则包括两个麦克风,用在左耳的入耳式耳机的麦克风可称为左麦克风,用在右耳的入耳式耳机的麦克风可称为右麦克风。
又例如,在图4示出了一种无线通信的颈挂式耳机,该颈挂式耳机包括两个麦克风,分别为连接左侧耳机的左麦克风和连接右侧耳机的右麦克风,用户可根据需要对这两个麦克风中的至少一个麦克风进行操作,从而使得用户对麦克风的操作方式得到扩展。
需要说明的是,本申请的又一些方案中,第一设备和第二设备也可能是同一设备,也就是说,这样的方案中,第一设备可基于本申请描述的方法来实现自我控制。例如,如图5所示,图5以第一设备为智能手机为例,该智能手机可包括一个或多个麦克风,例如包括设置于智能手机顶部的顶部麦克风和设置于智能手机底部的底部麦克风。用户可根据需要对这两个麦克风中的至少一个麦克风进行操作。这些方案的具体实现过程可参考第一设备和第二设备为不同设备时的方案的实施方式,本文将不再展开详述。
参见图6,图6为本申请实施例提供的一种示例性的设备100的结构示意图。在一些实施例中,设备100可以是本申请实施例描述的第一设备。如图6所示,设备100包括一个或者多个处理器110、一个或多个存储器120、通信接口130、音频采集电路和音频播放电路。其中音频采集电路进一步可包括麦克风140和模拟数字转换器(Analog-to-DigitalConverter,ADC)150。音频播放电路进一步可包括扬声器160和数字模拟转换器(Digital-to-Analog Converter,DAC)。上述这些部件可在一个或多个通信总线上通信。分别描述如下:
处理器110是设备100的控制中心,处理器还可能被称为控制单元、控制器、微控制器或其他某个合适的术语。处理器110利用各种接口和线路连接设备100的各个部件,在可能实施例中,处理器110还可包括一个或多个处理核心。
存储器120可以与处理器110耦合,或者与处理器110通过总线连接,用于存储各种软件程序和/或多组指令以及数据。具体实现中,存储器120可包括高速随机存取的存储器,并且也可包括非易失性存储器,例如一个或多个磁盘存储设备、闪存设备或其他非易失性固态存储设备。存储器120还可以存储一个或多个计算机程序,所述一个或多个计算机程序包括本申请所描述方法的程序指令。存储器120还可以存储通信程序,该通信程序可用于与至少一个第二设备进行通信。存储器120还可以存储执行如图20实施例中的第一设备的各种功能模块的相关数据/代码。
本申请具体实施例中,处理器110可用于调用存储器120中的程序指令,以执行如图7、图14、或图18实施例中第一设备侧的功能。或者,处理器110可通过运行存储在存储器120内的各种功能模块,以及调用存储在存储器120内的数据(例如采集的音频信号)来执行对第二设备的控制。
通信接口130用于与第二设备进行通信,该通信方式可以是有线方式,也可以是无线方式。当通信方式是有线通信时,通信接口130可通过线缆接入到第二设备。当通信方式是无线通信时,通信接口130用于接收和发送射频信号,其所支持的无线通信方式例如可以是蓝牙(Bluetooth)通信、无线保真(wireless-fidelity,Wifi)通信、红外通信、或蜂窝2/3/4/5代(2/3/4/5generation,2G/3G/4G/5G)通信等通信方式中的至少一种。具体实现中,通信接口130可包括但不限于:天线系统、RF收发器、一个或多个放大器、调谐器、一个或多个振荡器、数字信号处理器、CODEC芯片、SIM卡和存储介质等。在一些实施例中,可在单独的芯片上实现通信接口130。
麦克风140可用于采集音频信号(或称声音信号,该音频信号是模拟信号),模拟数字转换器150用于将麦克风140采集到的模拟信号转换成为数字信号,并将该数字信号送到处理器110进行处理。
本申请实施例中,麦克风140可采集音频信号,该音频信号可以是现实生活环境中不被人耳所识别的。例如,用户在麦克风140的周围进行无声操作,所述无声操作表示由所述用户的手部触发且不被人耳感知到声响的操作,例如用户在麦克风140的采声部附近扇动空气,或者触摸/摩擦/轻微点击麦克风140的采声部,麦克风140的采声部即为麦克风140用来采集音频信号的部位。麦克风140可采集用户的无声操作引起的音频信号,并通过模拟数字转换器150最终传输到处理器110。处理器110可对麦克风140采集到的信号进行识别,根据识别信号特征,进而根据预先设定的规则,通过通信接口130向第二设备发送控制命令,完成对第二设备的控制。例如,控制所述第二设备执行拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、开启/关闭指定功能模式中至少一种。
通信接口130还可用于,接收来自第二设备的数据(该数据为数字信号)并传输至处理器110进行处理,处理器110将处理的数据传输至数字模拟转换器170,数字模拟转换器170可将接收到的数据转换为模拟信号,进而传输到扬声器160,扬声器用于根据该模拟信号进行播放,从而使用户能够听到播放的声音。示例性的,该模拟信号可以是音乐或者语音信号。
本领域技术人员可以理解,设备100仅为本申请实施例提供的一种示例。在本申请的具体实现中,设备100可具有比示出的部件更多或更少的部件,可以组合两个或更多个部件,或者可具有部件的不同配置实现。
举例来说,在一种实现中,设备100为主动降噪耳机时,还包括降噪处理电路(ANCcircuit),降噪处理电路(图未示)用于实现设备100的主动降噪功能。处理器110和降噪处理电路可以集成在一个处理器芯片上,也可以在两个彼此独立的处理器芯片上实现。
需要说明的是,在一种可选的情况中,设备100的上述各个部件也可以耦合在一起设置。
应当理解,本申请的各个实施例中,术语“耦合”是指通过特定方式的相互联系,包括直接相连或者通过其他设备间接相连,例如可以通过各类接口、传输线或总线等相连,这些接口通常是电性通信接口,但是也不排除可能是机械接口或其它形式的接口,本申请实施例对此不做限定。
基于上文的描述,下面给出本申请实施例提供的一些设备控制方法。
对于下文描述的各方法实施例,为了方便起见,将其都表述为一系列的动作步骤的组合,但是本邻域技术人员应该知悉,本申请技术方案的具体实现并不受所描述的一系列的动作步骤的顺序的限制。
参见图7,图7是本申请实施例提供的一种设备控制方法的流程示意图,在一些实现中,该方法可应用于具有至少一个麦克风的第一设备。该方法包括但不限于以下步骤:
S101、检测到用户在第一设备的至少一个麦克风周围(或附近)的无声操作。
本申请中,所谓“无声操作”是指由所述用户的手部触发且不被人耳感知到声响的操作。举例来说,人耳能听到的最小的声音强度为1分贝(decibel,db),那么由该用户的操作导致的声响可以低于1分贝。
在一些具体实施例中,用户可在接触第一设备的情况下触发无声操作。比如,用户可使用手指在第一设备的至少一个麦克风的采声部上触发无声操作,麦克风的采声部即为麦克风用来采集音频信号的部位。该无声操作例如可包括如下至少一种:摩擦麦克风、点击(或称触摸、触碰、撞击、敲打)麦克风。
以用户对入耳式耳机的无声操作为例,入耳式耳机可包括至少一个麦克风。参见图8和图9,图8和图9示例性示出了用户对入耳式耳机的几种无声操作的场景示意图。
其中,图8示出的无声操作为摩擦麦克风,用户可使用手指摩擦麦克风的采声部,例如用户在麦克风的采声部(透声孔)上摩擦,又例如用户的手指触摸麦克风并沿麦克风移动一小段距离,又例如用户的手指来回移动摩擦麦克风,又例如用户的手指在麦克风上打圈、划曲线等等。这样,第一设备可以检测到用户触发的无声操作。图8中的(1)示出了用户沿麦克风的采声部的纵向方向摩擦麦克风的场景示意图,图8中的(2)示出了用户沿麦克风的采声部的横向方向摩擦麦克风的场景示意图。图示中的箭头表示一次摩擦操作,图8中的(1)(2)分别以3次摩擦为示例,每次摩擦的方向可以是相同的也可以是不同的。本申请实施例中,所谓“摩擦麦克风”具体可以为以下实现形式中的一种或多种的组合:
单次摩擦所述至少一个麦克风。例如每当摩擦麦克风的采声部一次,第一设备都可以检测到该操作。
以大于或等于第二次数阈值的次数摩擦所述至少一个麦克风,每次摩擦的方向可以是相同的也可以是不同的,第二次数阈值表示触发第一设备检测到该无声操作的次数值。例如一种实现中,第二次数阈值为2次,当摩擦麦克风的采声部的次数等于2次,第一设备可以检测到该操作,又例如一种实现中,第二次数阈值为2次,摩擦麦克风的采声部的次数超过2次时,第一设备都可以检测到该操作。
以大于或等于第二时长阈值的时长持续摩擦所述至少一个麦克风,每次摩擦的方向可以是相同的也可以是不同的,第二时长阈值表示触发第一设备检测到该无声操作的操作时长。例如一种实现中,第二时长阈值为2秒,每当摩擦麦克风的采声部的时长等于2秒,第一设备就可以检测到该操作。又例如一种实现中,第二时长阈值为2秒,当摩擦麦克风的采声部的时长超过2秒,第一设备就可以检测到该操作。
以大于或等于第二强度阈值的强度摩擦所述至少一个麦克风。每次摩擦的位置可以是相同的也可以是有所差异的,第二强度阈值表示触发第一设备检测到摩擦所述至少一个麦克风来控制第二设备的摩擦动作的摩擦强度值,所述点击强度值例如可用摩擦动作所引起的音频信号的音强特征或振幅或能量来表征。例如在一种实现中,当摩擦所述至少一个麦克风的摩擦强度值等于第二强度阈值,第一设备就可以检测到该操作。又例如一种实现中,当摩擦所述至少一个麦克风的摩擦强度值超过第二强度阈值,第一设备就可以检测到该操作。
以大于或等于第二时长间隔的间隔摩擦所述至少一个麦克风。每次摩擦的位置可以是相同的也可以是有所差异的,第二时长间隔表示触发第一设备检测到摩擦所述至少一个麦克风来控制第二设备的摩擦动作的时长间隔。例如在一种实现中,第二时长间隔为1秒,当用户以1秒的间隔摩擦所述至少一个麦克风,第一设备就可以检测到该操作。又例如一种实现中,第二时长间隔为1秒,当用户以超过1秒的间隔摩擦所述至少一个麦克风,第一设备就可以检测到该操作。
需要说明的是,上述示例以用户手指摩擦麦克风为例进行说明,应理解的是,在可能的实现中,也可以用其他的人体部分(例如手掌)或者其他工具(例如手套、笔等)来摩擦麦克风以实现所述无声操作。
还需要说明的是,上述示例仅仅用于解释本申请实施例,上述第二次数阈值、第二时长阈值、第二强度阈值、第二时长间隔还可以是其他的取值,本申请不做限定。
图9示出的无声操作为点击麦克风,即用户可使用手指触摸、触碰、轻轻撞击、或轻轻敲打麦克风的采声部。这样,第一设备可以检测到用户触发的无声操作。图示中的圆圈表示一次点击操作(图中以一次点击为例)。本申请实施例中,所谓“点击麦克风”具体可以为以下实现形式中的一种或多种的组合:
单次点击所述至少一个麦克风。例如每当点击麦克风的采声部一次,第一设备都可以检测到该操作。
以大于或等于第四次数阈值的次数点击所述至少一个麦克风,每次点击的位置可以是相同的也可以是有所差异的,第四次数阈值表示触发第一设备检测到该无声操作的次数值。例如一种实现中,第四次数阈值为3次,每当点击麦克风的采声部的次数等于3次,第一设备就可以检测到该操作。又例如一种实现中,第四次数阈值为3次,当点击麦克风的采声部的次数超过3次,第一设备就可以检测到该操作。
在大于或等于第四时长阈值的时长内持续点击所述至少一个麦克风,每次点击的位置可以是相同的也可以是有所差异的,第四时长阈值表示触发第一设备检测到该无声操作的操作时长。例如一种实现中,第四时长阈值为2秒,每当点击麦克风的采声部的时长等于2秒,第一设备就可以检测到该操作。又例如一种实现中,第四时长阈值为2秒,每当点击麦克风的采声部的时长超过2秒,第一设备就可以检测到该操作。
以大于或等于第四强度阈值的强度点击所述至少一个麦克风。每次点击的位置可以是相同的也可以是有所差异的,第四强度阈值表示触发第一设备检测到点击所述至少一个麦克风来控制第二设备的点击动作的点击强度值,所述点击强度值例如可用点击动作所引起的音频信号的音强特征或振幅或能量来表征。例如在一种实现中,当点击所述至少一个麦克风的点击强度值等于第四强度阈值,第一设备就可以检测到该操作。又例如一种实现中,当点击所述至少一个麦克风的点击强度值超过第四强度阈值,第一设备就可以检测到该操作。
以大于或等于第四时长间隔的间隔点击所述至少一个麦克风。每次点击的位置可以是相同的也可以是有所差异的,第四时长间隔表示触发第一设备检测到该无声操作(即点击)的两次点击之间的时长间隔。例如在一种实现中,第四时长间隔为1秒,当用户以1秒的间隔点击所述至少一个麦克风,第一设备就可以检测到该操作。又例如一种实现中,第四时长间隔为1秒,当用户以超过1秒的间隔点击所述至少一个麦克风,第一设备就可以检测到该操作。
需要说明的是,上述示例以用户手指点击麦克风为例进行说明,应理解的是,在可能的实现中,也可以用其他的人体部分(例如指关节)或者其他工具(例如笔、树枝等)来点击麦克风以实现所述无声操作。
还需要说明的是,上述示例仅仅用于解释本申请实施例,上述第四次数阈值、第四时长阈值、第四强度阈值、第四时长间隔还可以是其他的取值,本申请不做限定。
在又一些具体实施例中,用户可在不接触第一设备的情况下触发无声操作。比如,用户可在距第一设备较近距离的位置(即第一设备的附近)触发无声操作,该无声操作例如可包括如下至少一种:在第一设备的至少一个麦克风的附近扇风、向第一设备的至少一个麦克风吹气。
同样以用户对入耳式耳机的无声操作为例,入耳式耳机可包括至少一个麦克风。参见图10和图11,图10和图11示例性示出了用户对入耳式耳机的又几种无声操作的场景示意图。
图10示出的无声操作为向麦克风扇风,即用户可使用手掌在麦克风附近向麦克风的采声部扇风。这样,第一设备可以检测到用户触发的无声操作。图示中的箭头表示一次扇风操作(图中以三次扇风为例)。本申请实施例中,所谓“向麦克风扇风”具体可以为以下实现形式中的一种或多种的组合:
单次向所述至少一个麦克风扇风。例如每当向麦克风的采声部扇风一次,第一设备都可以检测到该操作。
以大于或等于第一次数阈值的次数向所述至少一个麦克风扇风。每次扇风的位置可以是相同的也可以是有所差异的,第一次数阈值表示触发第一设备检测到该无声操作的次数值。例如一种实现中,第一次数阈值为3次,每当向麦克风的采声部扇风的次数等于3次,第一设备就可以检测到该操作。又例如一种实现中,第一次数阈值为3次,当向麦克风的采声部扇风的次数超过3次,第一设备就可以检测到该操作。
以大于或等于第一时长阈值的时长持续向所述至少一个麦克风扇风。每次扇风的位置可以是相同的也可以是有所差异的,第一时长阈值表示触发第一设备检测到该无声操作的操作时长。例如一种实现中第一时长阈值为2秒,每当向麦克风的采声部扇风的时长等于2秒,第一设备就可以检测到该操作。又例如一种实现中,第一时长阈值为2秒,每当向麦克风的采声部扇风的时长超过2秒,第一设备就可以检测到该操作。
以大于或等于第一强度阈值的强度向所述至少一个麦克风扇风。每次扇风的位置可以是相同的也可以是有所差异的,第一强度阈值表示触发第一设备检测到向麦克风扇风来控制第二设备的扇风动作的扇风强度值,所述扇风强度值例如可用扇风所引起的音频信号的音强特征或振幅或能量来表征。例如在一种实现中,当向麦克风的采声部扇风的扇风强度值等于第一强度阈值,第一设备就可以检测到该操作。又例如一种实现中,当向麦克风的采声部扇风的扇风强度值超过第一强度阈值,第一设备就可以检测到该操作。
以大于或等于第一时长间隔的间隔向所述至少一个麦克风扇风。每次扇风的位置可以是相同的也可以是有所差异的,第一时长间隔表示触发第一设备检测到该无声操作(即扇风)的两次扇风之间的时长间隔。例如在一种实现中,第一时长间隔为1秒,当用户以1秒的间隔向麦克风的采声部扇风,第一设备就可以检测到该操作。又例如一种实现中,第一时长间隔为1秒,当用户以超过1秒的间隔向麦克风的采声部扇风,第一设备就可以检测到该操作。
需要说明的是,上述示例以用户手掌扇风为例进行说明,应理解的是,在可能的实现中,也可以用其他工具(例如纸片,小扇子等)来向麦克风扇风以实现所述无声操作。
还需要说明的是,上述示例仅仅用于解释本申请实施例,上述第一次数阈值、第一时长阈值、第一强度阈值、第一时长间隔还可以是其他的取值,本申请不做限定。
图11示出的无声操作为向麦克风吹气,即用户可用嘴在麦克风附近向麦克风的采声部吹气/吹风/哈气/吐气。这样,第一设备可以检测到用户触发的无声操作。本申请实施例中,所谓“向麦克风吹气”具体可以为以下实现形式中的一种或多种的组合:
单次向所述至少一个麦克风吹气。例如每当向麦克风的采声部吹气一次,第一设备都可以检测到该操作。
以大于或等于第三次数阈值的次数向所述至少一个麦克风吹气。每次吹气的位置可以是相同的也可以是有所差异的,第三次数阈值表示触发第一设备检测到该无声操作的次数值。例如一种实现中,第三次数阈值为2次,每当向麦克风的采声部吹气的次数等于2次,第一设备就可以检测到该操作。又例如一种实现中,第三次数阈值为2次,当向麦克风的采声部吹气的次数超过2次,第一设备就可以检测到该操作。
以大于或等于第三时长阈值的时长持续向所述至少一个麦克风吹气。每次吹气的位置可以是相同的也可以是有所差异的,第三时长阈值表示触发第一设备检测到该无声操作的操作时长。例如一种实现中,第三时长阈值为1秒,当向麦克风的采声部吹气的时长等于1秒,第一设备就可以检测到该操作。又例如一种实现中,第三时长阈值为1秒,当向麦克风的采声部吹气的时长超过1秒,第一设备就可以检测到该操作。
以大于或等于第三强度阈值的强度向所述至少一个麦克风扇风。每次扇风的位置可以是相同的也可以是有所差异的,第三强度阈值表示触发第一设备检测到向麦克风吹气来控制第二设备的吹气动作的吹气强度值,所述吹气强度值例如可用吹气所引起的音频信号的音强特征或振幅或能量来表征。例如在一种实现中,当向麦克风的采声部吹气的吹气强度值等于第三强度阈值,第一设备就可以检测到该操作。又例如一种实现中,当向麦克风的采声部扇风的吹气强度值超过第三强度阈值,第一设备就可以检测到该操作。
以大于或等于第三时长间隔的间隔向所述至少一个麦克风吹气。每次吹气的位置可以是相同的也可以是有所差异的,第三时长间隔表示触发第一设备检测到该无声操作(即吹气)的两次吹气之间的时长间隔。例如在一种实现中,第三时长间隔为1秒,当用户以1秒的间隔向麦克风的采声部吹气,第一设备就可以检测到该操作。又例如一种实现中,第三时长间隔为1秒,当用户以超过1秒的间隔向麦克风的采声部吹气,第一设备就可以检测到该操作。
需要说明的是,上述示例仅仅用于解释本申请实施例,上述第三次数阈值、第三时长阈值、第三强度阈值、第三时长间隔还可以是其他的取值,本申请不做限定。
还需要说明的是,上述第二次数阈值、第一次数阈值、第三次数阈值、第四次数阈值各自的取值可以是各有差异的,也可以是相同的,本申请不做限定;上述第二时长阈值、第一时长阈值、第三时长阈值、第四时长阈值各自的取值可以是各有差异的,也可以是相同的,本申请不做限定。上述第二强度阈值、第一强度阈值、第三强度阈值、第四强度阈值各自的取值可以是各有差异的,也可以是相同的,本申请不做限定;上述第二时长间隔、第一时长间隔、第三时长间隔、第四时长间隔各自的取值可以是各有差异的,也可以是相同的,本申请不做限定。
还需要说明的是,本申请除了上述所举例的无声操作,还可以对上述无声操作进行变形,或者对上述两种或两种以上的无声操作进行整合,例如当第一设备包括两个以上麦克风时,还可以结合对不同麦克风的操作顺序来形成所述无声操作。此外,基于本申请的技术思想,还可以衍生出其他实现形式的无声操作。
S102、响应于所述无声操作,对第二设备进行控制。
具体的,响应于S101所检测的无声操作,第一设备生成对应的控制命令(或称控制命令),控制命令用于指示第二设备执行某种功能。第一设备将控制命令发送第二设备,第二设备即可根据该控制命令执行相关的功能操作。
举例来说,以第二设备为智能手机例,第一设备可通过控制命令控制所述第二设备执行拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、开启/关闭指定功能模式中至少一种。其中,所述指定功能模式例如可以是静音模式、振动模式、飞行模式、省电模式、主动降噪(ANC)功能、监听模式(HearThrough)等等功能,本申请不做限定。
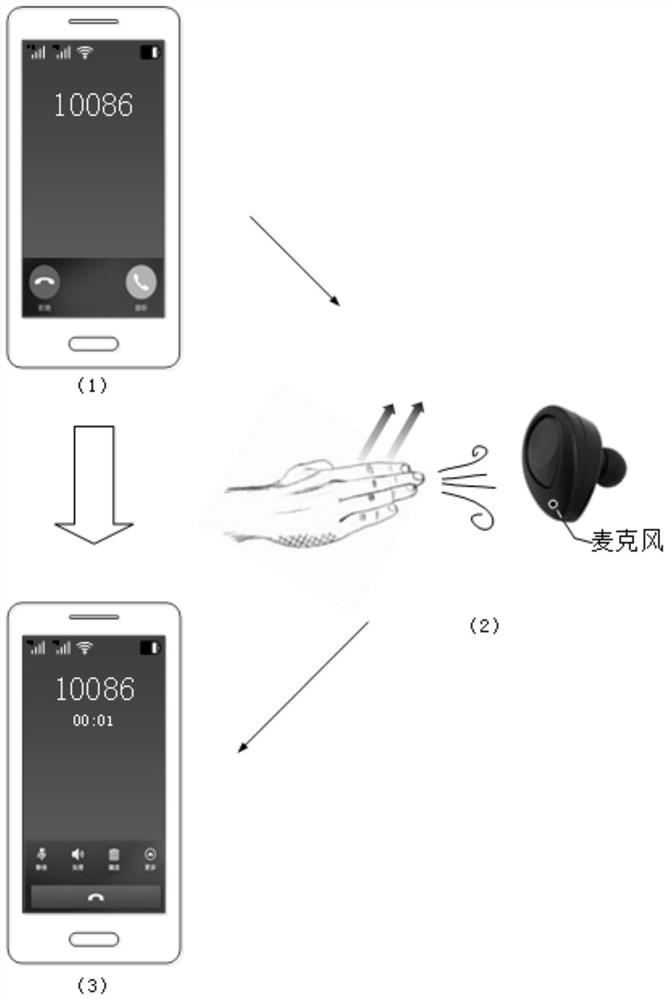
为了更好理解本申请的方案,下面以图12和图13所示场景为例进行描述。
参见图12,在一种可能的应用场景中,以第一设备为入耳式耳机,第二设备为智能手机为例,入耳式耳机可包括至少一个麦克风,该耳机与智能手机建立通信连接,用户可通过该入耳式耳机收听智能手机中的音乐,如图12中的(1)所示,智能手机中呈现音乐播放界面,此时耳机的扬声器将播放音乐。当用户想调大耳机音量时,由于用户可能不方便或者不喜欢直接在智能手机上进行操作,那么用户可以选择用手指摩擦入耳式耳机的麦克风的采声部,如图12中的(2)所示为摩擦麦克风的采声部。这样,入耳式耳机检测到用户的无声操作后,触发入耳式耳机生成“增大音量”的控制命令,并基于该控制命令控制智能手机增大音量,如图12中的(3)中呈现音乐播放音量增加的界面。例如,在具体实现中,可以设计成音乐播放音量随着摩擦麦克风的时间的增加而增加,也可以设计成每摩擦麦克风一次相应增加一段预设程度的音量,本申请不做限定。这样,实现了在用户不发出声响的情况下利用麦克风来控制智能手机调整音乐播放音量的目的,操作简便,提升了用户体验。
参见图13,在又一种可能的应用场景中,同样以第一设备为入耳式耳机,第二设备为智能手机为例,入耳式耳机可包括至少一个麦克风,该耳机与智能手机建立通信连接,例如用户可通过该耳机收听智能手机中的音乐(图未示)。在图12中的(1),智能手机接收到来电如图示中呈现来电界面。用户可能不方便或者不喜欢直接在智能手机上进行操作,那么用户可以选择用手掌向入耳式耳机的麦克风扇风,如图12中的(2)所示为向麦克风扇风两次。这样,入耳式耳机检测到用户的无声操作后,触发入耳式耳机生成“接听电话”的控制命令,并基于该控制命令控制智能手机接通电话,如图12中的(3)中呈现通话界面。后续,用户可以继续利用麦克风实现语音通话。这样,实现了在用户不发出声响的情况下利用麦克风来控制智能手机接通电话的目的,操作简便,提升了用户体验。
可以看到,本申请实施例中,第一设备通过检测用户摩擦或点击麦克风的无声操作或者在麦克风附近扇风或吹气的无声操作,就可以实现对第二设备的控制。这样,实现了在用户不发出声音的情况下也能对第二设备进行控制,拓展了用户对设备控制形式。无声操作的输入方式比较简便,提高了第二设备拨打紧急电话等操作的隐蔽性。此外,由于本申请使用的第一设备本身就具有麦克风,通过复用设备上的麦克风就可以实现控制功能,无须增加额外的传感器设备,且成本较低,设备功耗较低。所以,实施本申请能极大提升用户的使用体验。
参见图14,图14是本申请实施例提供的一种设备控制方法的具体流程示意图,在一些实现中,该方法可应用于具有至少一个麦克风的第一设备。该方法包括但不限于以下步骤:
S201、通过至少一个麦克风采集音频信号。
本文中,所述音频信号可包括由用户的无声操作引起的风噪信号。
在本申请的具体实施例中,当用户对所述至少一个麦克风进行摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等等的无声操作时,所述第一设备所采集的音频信号可以是由用户的无声操作引起的风躁信号,即该音频信号可以是类似风噪特性的信号。
例如,用户用手指通过摩擦或点击麦克风的采声部位置,引发采声部的振动和/或产生气流扰动,进而带动麦克风膜片振动产生音频信号。
又例如,用户用手掌在麦克风附近扇风的动作,产生气流的运动,进而带动麦克风膜片振动产生音频信号。
又例如,用户用嘴在麦克风附近吹气的动作,产生气流的运动,进而带动麦克风膜片振动产生音频信号。
S202、确定是否存在与所述音频信号对应的控制命令。若存在与所述音频信号对应的控制命令,则后续继续执行S204;若不存在与所述音频信号对应的控制命令,则结束本流程。
举例来说,控制命令包括以下控制命令中的至少一种:拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、开启/关闭指定功能模式中至少一种。所述指定功能模式例如可以是静音模式、振动模式、飞行模式、省电模式、主动降噪(ANC)功能、监听模式(HearThrough)等等功能,本申请不做限定。
在本申请又一种可能的实现中,采用机器学习的方法进行模型训练时,所采用的训练数据包括由无声操作引起的音频信号数据(例如摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等无声操作引起的音频信号)和控制标签(用于指示该音频信号数据对应的控制命令),即该模型可表征音频信号与控制命令之间的映射关系。第一设备获取并保存该模型。当第一设备采集到音频信号时,可以将音频信号输入到模型,从而获得模型输出的控制命令。
在本申请又一种可能的实现中,可预先配置由用户的无声操作引起的音频信号的信号类型和音频特征的组合与控制命令之间的映射关系,那么根据映射关系可确定与所述音频信号对应的控制命令。
其中,信号类型可包括风躁,也就是说,该信号类型可以是由风躁引起的音频信号的类型。举例来说,一种具体分类中,信号类型例如可划分为:由摩擦麦克风所引起的信号类型,例如用户用手指通过摩擦麦克风的采声部位置,引发采声部的振动和/或产生气流扰动,进而带动麦克风膜片振动产生该音频信号;由点击麦克风所引起的信号类型,例如用户用手指通过点击麦克风的采声部位置,引发采声部的振动和/或产生气流扰动,进而带动麦克风膜片振动产生该音频信号;由向麦克风扇风所引起的信号类型,例如,用户用手掌在麦克风附近扇风的动作产生气流的运动,进而带动麦克风膜片振动产生该音频信号;由向麦克风吹气所引起的信号类型,例如用户用嘴在麦克风附近吹气的动作,产生气流的运动,进而带动麦克风膜片振动产生该音频信号。当然,在其他实施例中,还可以比示例更多或更少的分类,或者包括由其他无声操作所引起的信号类型,这里不做限定。
音频特征包括但不限于:脉冲信号触发的频次、脉冲信号的持续时间、脉冲信号的能量大小、采集不同信号类型的顺序、音长特征、音强特征等等一种或多种。音频信号的音频特征能够反映出用户的无声操作的动作特征,无声操作的动作特征例如包括动作频次、动作力度、动作节奏、动作顺序中的一种或多种。其中,动作频次表示所述无声操作中的动作的实施次数,动作频次体现了动作的次数、动作的快慢等。动作力度表示所述无声操作中的动作的实施强度。动作力度表示所述无声操作中的动作的实施强度。动作节奏可以表示两个动作之前的时间间隔,例如两次扇风动作之间的时间间隔;动作节奏还可以是通过结合动作频次、动作力度而形成的。动作顺序表示当无声操作的动作类型有多个时,不同的动作类型的动作的先后实施顺序,和/或,当麦克风的数量有两个或两个以上时,针对不同麦克风的无声操作的先后实施顺序。
在本申请又一种可能的实现中,可预先采用机器学习的方法,利用大量的训练数据,进行模型训练得到模型。其中,训练数据包括由无声操作引起的音频信号数据(例如摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等无声操作引起的音频信号)和信号类型标签(用于指示对应的无声操作的信号类型),即该模型可表征音频信号与信号类型之间的映射关系。第一设备获取并保存该模型。当第一设备采集到音频信号时,可以将音频信号输入到模型,从而获得模型输出的信号类型。此外,第一设备还可以通过算法对该信号类型的音频信号进行特征提取,获得音频特征。那么根据预设的信号类型和音频特征的组合与控制命令之间的映射关系,可确定与所述音频信号对应的控制命令。
具体实现中,本文实施例涉及的模型可以是下述模型中的一种:神经网络(NeuralNetwork,NN)模型、深度神经网络(Deep Neural Network,DNN)模型、因式分解机支持的神经网络(Factorization-machine supported Neural Networks,FNN)模型、卷积神经网络(Convolutional Neural Networks,CNN)模型、基于内积的神经网络(Inner Product-based Neural Network,IPNN)模型、基于外积的神经网络(Outer Product-based NeuralNetwork,OPNN)模型、神经分解机(Neural Factorization Machines,NFM)模型等等。
S203、根据控制命令对第二设备进行控制。
具体实施例中,控制命令用于指示第二设备执行某种功能。第一设备将控制命令发送第二设备,第二设备即可根据该控制命令执行相关的功能操作。举例来说,以第二设备为智能手机例,第一设备可通过控制命令控制所述第二设备执行拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、开启/关闭指定功能模式中至少一种。其中,所述指定功能模式例如可以是静音模式、振动模式、飞行模式、省电模式、主动降噪(ANC)功能、监听模式(HearThrough)等等功能,本申请不做限定。
需要说明的是,在可能的实施例中,控制命令也可能用于指示第一设备自己执行某种功能。例如在第一设备为手机的场景中,第一设备可根据该控制命令执行拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、开启/关闭指定功能模式中至少一种。其中,所述指定功能模式例如可以是静音模式、振动模式、飞行模式、省电模式、主动降噪(ANC)功能、监听模式(HearThrough)等等功能,本申请不做限定。
可以看到,本申请实施例中,第一设备通过麦克风采集用户摩擦或点击麦克风的无声操作或者在麦克风附近扇风或吹气的无声操作所引起的音频信号,通过音频信号可确定无声操作所需要触发的控制命令,进而可以根据无声操作对应的控制命令实现对第二设备的控制。这样,实现了在用户不发出声音的情况下也能对第二设备进行控制,拓展了用户对设备控制形式。无声操作的输入方式比较简便,提高了第二设备拨打紧急电话等操作的隐蔽性。此外,由于本申请使用的第一设备本身就具有麦克风,通过复用设备上的麦克风就可以实现控制功能,无须增加额外的传感器设备,且成本较低,设备功耗较低。所以,实施本申请能极大提升用户的使用体验。
参见图18,图18是本申请实施例提供的又一种设备控制方法的具体流程示意图,在一些实现中,该方法可应用于具有至少一个麦克风的第一设备。该方法包括但不限于以下步骤:
S301、第一设备预先在本地保存无声操作的动作类型和动作特征与控制命令之间的映射关系。
也就是说,当动作类型和动作特征符合预设条件(即预设组合)时,该预设条件(即预设组合)与控制命令之间具有映射关系。
无声操作的动作类型表示所述无声操作中的动作的操作类型,例如动作类型可以是摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等等。
无声操作的动作特征例如包括动作频次、动作力度、动作节奏、动作顺序中的一种或多种。其中:动作类型表示所述无声操作中的动作的实施形态;动作频次表示所述无声操作中的动作的实施频次,动作频次体现了动作的次数、动作的快慢等;动作力度表示所述无声操作中的动作的实施强度;动作节奏可以表示两个动作之间的时间间隔,也可以是通过结合动作频次、动作力度而形成的;动作顺序表示当无声操作的动作类型有多个时,不同的动作类型的动作的先后实施顺序,和/或,当麦克风的数量有两个或两个以上时,针对不同麦克风的无声操作的先后实施顺序。
控制命令用于实现对第二设备进行控制,控制命令例如包括以下命令的至少一种:控制第二设备拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、开启/关闭指定功能模式中至少一种。所述指定功能模式例如可以是静音模式、振动模式、飞行模式、省电模式、主动降噪(ANC)功能、监听模式(HearThrough)等等功能。
举例来说,在一种可能的实现场景中,以第一设备为耳机,第二设备为智能手机例,当第一设备只包括单个麦克风,或者只配置第一设备中的某个麦克风来进行无声操作时,可配置动作类型和动作特征的组合与控制命令之间的映射关系信息如下表1所示。其中,该映射关系信息可以是第一设备预先从其他设备(例如第二设备或其他终端设备)或者服务器获取的,也可以是出厂默认设置的。
表1
需要说明的是,表1仅用于解释本申请的方案,不对本申请构成限定。
又举例来说,在一种可能的实现场景中,以第一设备为耳机,第二设备为智能手机例,当第一设备包括两个麦克风(包括左麦克风或右麦克风),或者只配置第一设备中的两个麦克风来进行无声操作时,可配置动作类型和动作特征的组合与控制命令之间的映射关系信息如下表2所示。其中,该映射关系信息可以是第一设备预先从其他设备(例如第二设备或其他终端设备)或者服务器获取的,也可以是出厂默认设置的。
表2
需要说明的是,表2仅用于解释本申请的方案,不对本申请构成限定。
又举例来说,在一种可能的实现场景中,以第一设备为耳机,第二设备为智能手机例,第一设备包括两个麦克风(包括左麦克风或右麦克风),或者只配置第一设备中的两个麦克风来进行无声操作。用户可以通过智能手机对映射关系的规则进行自定义。例如,耳机与智能手机相连接,智能手机显示对映射关系的规则进行自定义的用户界面(UI),如图19所示。用户可通过智能手机的UI界面,对动作类型和动作特征的组合与控制命令之间的映射关系进行重新设定、增加、删减、或修改部分规则。用户设置完成后,智能手机可将该映射关系信息发送给耳机保存。本实施例中用户可以通过UI界面自定义规则,让操作更灵活便捷,更加符合用户的个人习惯,提升用户使用体验。
需要说明的是,本申请实施例中,动作类型和信号类型具有对应关系,动作特征和信号特征具有对应关系。所以,上述映射关系中,动作类型和动作特征的组合(预设组合)直接反映了信号类型和音频特征的组合(预设组合),动作类型和动作特征的组合与控制命令的映射关系直接反映了信号类型和音频特征的组合与控制命令的映射关系。
需要说明的是,图19实施例仅用于解释本申请的方案,不对本申请构成限定。
S302、通过至少一个麦克风采集音频信号。
所述音频信号可包括由用户的无声操作引起的风躁信号(或称噪声信号)。
在本申请的具体实施例中,当用户对所述至少一个麦克风进行摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等等的无声操作时,所述第一设备所采集的音频信号可以是由用户的无声操作引起的风躁信号,即该音频信号可以是类似风噪特性的信号。
例如,用户用手指通过摩擦或点击麦克风的采声部位置,引发采声部的振动和/或产生气流扰动,进而带动麦克风膜片振动产生音频信号。
又例如,用户用手掌在麦克风附近扇风的动作,产生气流的运动,进而带动麦克风膜片振动产生音频信号。
又例如,用户用嘴在麦克风附近吹气的动作,产生气流的运动,进而带动麦克风膜片振动产生音频信号。
S303、确定音频信号的信号类型和音频特征。
其中,信号类型可包括风躁,也就是说,该信号类型可以是由风躁引起的音频信号的类型。举例来说,一种具体分类中,信号类型例如可划分为:由摩擦麦克风所引起的信号类型、由点击麦克风所引起的信号类型、由向麦克风扇风所引起的信号类型、由向麦克风吹气所引起的信号类型。当然,在其他实施例中,还可以比示例更多或更少的分类,或者包括由其他无声操作所引起的信号类型,这里不做限定。
具体实施例中,第一设备可以通过检测所述音频信号获得所采集的音频信号的信号类型。具体的,可通过检测所述音频信号的时域特征、频谱特征中的一种或多种,获得所述信号类型。其中时域特征表示无声操作引起的音频信号的时域脉冲信号,例如可用振幅与时间的变化关系来体现;频谱特征表示无声操作引起的音频信号的频率谱密度,例如可用振幅与频率的变化关系来体现。
本申请具体实施例中,根据音频信号确定音频信号对应的信号类型,可以采用很多不同的方法。可以采用传统的基于音频信号提取的模式识别的方法,也可以采用基于神经网络或者基于深度学习的方法进行信号类型判断。例如采集到的音频信号是由向麦克风扇风的动作所引起的,可以称这种信号的类型为风噪信号。无论采用传统模式识别的方法,还是基于神经网络或者基于深度学习的方法,首先要采集大量的由向麦克风扇风的动作所引起的风噪信号。扇风的动作距离麦克风的远近不同、扇风动作的力度不同、扇风动作的频率等都会影响到采集到的音频信号的时频特征。如果是采用传统的基于模式识别的方法,需要先采集大量的由向麦克风扇风的动作所引起的风噪信号构成训练数据集,对训练数据集中的风噪信号进行特征提取构成特征向量,根据训练数据集的特征向量训练获得各个特征对应的判决阈值,用于判断信号类型是否属于风噪信号。在信号类型判决的过程作中,对采集到的音频信号进行特征提取获得音频信号的特征向量,根据该特征向量和各个特征对应的判决阈值,判断采集到的音频信号是否为风噪信号。如果是采用基于神经网络或深度学习的方法,也需要采集大量的由向麦克风扇风的动作所引起的风噪信号构成训练数据集,根据训练数据集训练用于判决输入信号是否为风噪信号的网络。在信号类型判决的过程作中,将采集到的音频信号作为网络的输入,获得信号类型的判决结果,以确定采集到的音频信号是否属于风噪信号。
当采集到的音频信号是摩擦麦克风的动作所引起的,可以称这种信号的类型为摩擦信号。可以采用类似上述的方法进行训练和信号类型判决,提取的信号特征与判决是否为风噪信号可以不相同。
在本申请一种可能的实现中,由无声操作引起的音频信号可以是风噪信号或者类似于风噪信号,第一设备可以利用风噪检测算法检测麦克风采集到的音频信号中是否包含具有风噪特性的信号。例如,采用基于数字信号处理的方法,计算所采集的音频信号的频谱的功率谱密度,通过功率谱密度的特征识别该音频信号是否具有风噪特性的信号。如是,则说明该音频信号是由无声操作引起的,否则,说明该音频信号不是由无声操作引起的(例如可能是用户说话的声音,背景环境噪音等)。从而实现了第一设备区分无声操作的音频信号和其他操作的音频信号。
然后,可对不同无声操作对应的信号类型通过检测算法进行区别。例如,对于由摩擦或点击麦克风的采声部位置引起的音频信号,由于是近距离施加在麦克风采声部位置,所产生的音频信号相比起向麦克风扇风/吹气引起的音频信号而言,能量更大。为了区别出无声操作的动作类型,第一设备可以进一步对具有风噪特性的信号的能量进行检测,从而判断该信号是在麦克风附近或吹气的动作引起的,还是由摩擦或点击麦克风采声部位置的动作引起的。例如,第一设备可通过信号的能量的大小来区分由无声操作所引起的音频信号(噪声信号)的信号类型,能量小于设定的阈值则认为是在麦克风附近扇风/吹气的动作引起的信号类型,否则认为是由摩擦或点击麦克风采声部位置的动作引起的信号类型。从而实现了第一设备区分不同的无声操作的信号类型。
在本申请又一种可能的实现中,可预先采用机器学习的方法,利用大量的训练数据,进行模型训练得到模型。其中,训练数据包括由无声操作引起的音频信号数据(例如摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等无声操作引起的音频信号)和信号类型,即该模型可表征音频信号与信号类型之间的映射关系。第一设备获取并保存该模型。当第一设备采集到音频信号时,可以将音频信号输入到模型,从而获得模型输出的信号类型。
下面以一个示例进行方案解释说明,在一种场景中,用户在第一设备的麦克风附近扇动手的动作,产生气流的运动,带动麦克风膜片振动产生音频信号,该音频信号类似于风噪信号,即音频信号的音频特征能够体现风噪特性。在一种实现中,第一设备可以利用风噪检测算法检测麦克风采集到的音频信号中是否包含具有风噪特性的信号。例如,第一设备采用基于数字信号处理的方法,计算该音频信号的频谱的功率谱密度,通过功率谱密度的特征识别该音频信号是否具有风噪特性的信号。又一种实现中,可预先采用深度学习的方法,利用大量的训练数据,经过训练得到模型。其中,训练数据为麦克风采集的由在麦克风附近扇风产生的音频信号以及风燥标签(用于指示对应的音频特征是否具有风噪特性)。那么,第一设备可利用该模型,识别麦克风采集的音频信号是否为具有风噪特性的信号。如果具有风噪特性的信号,第一设备还可以对具有风噪特性的音频信号的能量进行检测,判断音频信号是由哪种无声操作的动作引起的。例如,第一设备可通过信号的能量区分音频信号的类型。能量小于设定的阈值则属于在麦克风附近扇风的动作引起的,否则属于摩擦麦克风采声部位置的动作引起的。那么,本示例中若检测到能量小于设定的阈值,则确定该音频信号的信号类型为由麦克风附近扇风的动作所引起的类型。
音频特征可以是音频信号中的目标特征。具体实施例中,第一设备可通过对所述音频信号进行特征提取,获得所述音频特征。
所述音频特征例如包括:所述音频信号中脉冲的频次、能量、持续时间、音长特征、音强特征、采集不同信号类型的顺序中的一种或多种。其中脉冲的频次体现了音频信号中脉冲激发的次数、脉冲激发的快慢等。脉冲的能量体现了音频信号中脉冲激发的能量大小。脉冲的持续时间体现了音频信号中脉冲持续的时长。采集不同的信号类型的顺序可以是单个麦克风采集不同类型(例如摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等动作类型)的无声操作引起的音频信号的先后顺序,还可以是不同麦克风(例如两个麦克风)采集相同或不同类型的无声操作引起的音频信号的先后顺序。音长特征表示无声操作引起的音频信号的时长,音强特征表示无声操作引起的音频信号的能量。
音频特征反映了无声操作的动作特征,也就是说,根据音频特征(例如所述音频信号中脉冲的频次、能量、持续时间、音长特征、音强特征、采集不同信号类型的顺序中的一种或多种)可以识别出无声操作的动作特征(例如动作频次、动作力度、动作节奏、动作顺序等中的一种或多种)。
S304、确定与信号类型对应的动作类型,以及确定与音频特征对应的动作特征。
本申请实施例中,音频信号可以是用户对所述至少一个麦克风进行摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等等的动作类型所引起的,所以音频信号的信号类型与动作类型具有一一对应的关系,那么可以根据信号类型确定无声操作的动作类型。动作类型表示所述无声操作中的动作的操作类型,例如动作类型对应的动作可以是摩擦麦克风、点击麦克风、向麦克风扇风、或向麦克风吹气等等。
同理,音频信号的音频特征反映了无声操作的动作特征,即音频信号的音频特征与动作特征也具有对应的关系,所以可以根据音频特征确定无声操作的动作特征。无声操作的动作特征例如包括动作频次、动作力度、动作节奏、动作顺序中的一种或多种。其中:
动作频次表示所述无声操作中的动作的实施次数,动作频次体现了动作的次数、动作的快慢等。例如,用手快速地摩擦麦克风的采声部一次、两次、三次(即动作频次相应为一次、两次、三次)等等;又例如,用手快速地点击麦克风的采声部一次、两次、三次(即动作频次相应为一次、两次、三次)等等;又例如,在麦克风附近扇风一次、两次、三次(即动作频次相应为一次、两次、三次)等等;又例如,在麦克风附近吹气风一次、两次、三次(即动作频次相应为一次、两次、三次)等等,本申请对动作频次不做具体限定。
动作力度表示所述无声操作中的动作的实施强度。例如可以是轻微摩擦麦克风、用力摩擦耐克风、轻微触摸麦克风、用力按压麦克风、小幅度向麦克风扇风、大幅度向麦克风扇风、轻微向麦克风吹气、急剧向麦克风吹气等等,本申请对动作力度不做具体限定。
动作节奏可以表示两个动作之前的时间间隔,例如两次扇风动作之间的时间间隔;动作节奏还可以是通过结合动作频次、动作力度而形成的。例如,一种动作节奏可以是“轻微摩擦麦克风-用力摩擦耐克风-轻微摩擦麦克风-用力摩擦耐克风…”,又例如,一种动作节奏可以是“小幅度向麦克风扇风-小幅度向麦克风扇风-大幅度向麦克风扇风-大幅度向麦克风扇风…”,本申请对动作节奏不做具体限定。
动作顺序表示当无声操作的动作类型有多个时,不同的动作类型的动作的先后实施顺序,和/或,当麦克风的数量有两个或两个以上时,针对不同麦克风的无声操作的先后实施顺序。例如,一种动作顺序为先在麦克风附近扇了一次,然后用手摩擦麦克风的采声部。又例如,当麦克风包括左麦克风和右麦克风时,一种动作顺序为左麦克风的采声部摩擦了一下,然后在右麦克风的采声部摩擦了一下,本申请对动作顺序不做具体限定。
这样,由于无声操作的动作特征和音频特征之间有一一对应的关系,所以,结合基于时间轴的规律的动作特征,可以产生基于时间轴的音频特征,进而确定所对应的动作特征。在一种示例中,可以根据音频信号中脉冲的频次确定动作频次,根据脉冲的能量大小确定动作力度,根据脉冲信号的持续时间确定动作节奏,根据采集不同信号类型的顺序确定动作顺序。
本申请一种可能的实现中,以音频特征的时域特征为例,时域特征表示无声操作引起的音频信号的时域脉冲信号。共同参见图15、图16和图17,图15示例性地表示由“摩擦麦克风扇风”的无声操作所引起的时域脉冲信号(音频信号)示意图,图16示例性地表示由“向麦克风扇风”的无声操作所引起的时域脉冲信号(音频信号)示意图,图17示例性地表示由用户说话(即不是无声操作)所引起的时域脉冲信号(音频信号)示意图。第一设备基于不同脉冲信号的波形特征(例如波形的振幅、频率、能量等参数),可以识别出当前的音频信号是由无声操作引起的,还是由其他操作(如说话声)引起的。若识别出当前的音频信号是由无声操作引起的,则还可以进一步识别出音频信号中的音频特征,如脉冲信号触发的频次、脉冲信号的持续时间、脉冲信号的能量大小等。
例如,第一设备识别如图15所示的音频信号的脉冲是由摩擦麦克风的动作所引起的,进一步识别出脉冲信号触发的频次(如图示中用摩擦频次标示出了两次摩擦动作之间的不同时间间隔,也对应于动作频次)、脉冲信号的持续时间(如图示中用摩擦时长标示出了多次摩擦动作的总时长)、脉冲信号的能量大小(如图示中用幅度标示出了摩擦动作的强度,也对应于动作力度),即识别出了音频信号的音频特征对应的动作特征。
又例如,第一设备识别如图16所示的音频信号的脉冲是由向麦克风扇风的动作所引起的,进一步识别出脉冲信号触发的频次(如图示中用扇风频次标示出了两次扇风动作之间的不同时间间隔,也对应于动作频次)、脉冲信号的持续时间(如图示中用扇风时长标示出了多次扇风动作的总时长)、脉冲信号的能量大小(如图示中用幅度标示出了扇风动作的强度,也对应于动作力度),即识别出了音频信号的音频特征对应的动作特征。
需要说明的是,图15、图16和图17所示的音频信号仅用于解释本申请的方案,不对本申请构成限定。
本申请一种可能的实现中,第一设备的麦克风采集的音频信号可能包括无声操作的多个动作类型产生的音频信号,可通过语音激活检测技术将音频信号进行分段,每个分段表示一种动作类型,通过检测一个分段内与待识别的动作相对应的音频信号的持续时间,以及不同分段内与待识别的动作相对应的音频信号的起始时间的间隔,区分不同动作类型的动作的快慢。通过对不同分段内动作类型进行统计,获得不同动作类型的动作频次。通过统计一段时间内,不同分段内动作类型以及各自连续出现的动作频次,可以进一步获得无声操作的动作节奏或者动作顺序。从而,实现了第一设备获得无声操作的音频信号对应的动作特征。
在本申请又一种可能的实现中,可预先采用机器学习的方法,利用大量的训练数据,进行模型训练得到模型。其中,训练数据包括由无声操作引起的音频信号的音频特征和动作特征标签(标签用于指示对应的无声操作的动作特征),即该模型可表征音频特征与动作特征之间的映射关系。第一设备获取并保存该模型。当第一设备采集到音频信号时,提取音频特征输入到模型,从而获得模型输出的动作特征。
具体实现中,本文实施例涉及的模型可以是下述模型中的一种:神经网络(NeuralNetwork,NN)模型、深度神经网络(Deep Neural Network,DNN)模型、因式分解机支持的神经网络(Factorization-machine supported Neural Networks,FNN)模型、卷积神经网络(Convolutional Neural Networks,CNN)模型、基于内积的神经网络(InnerProduct-basedNeural Network,IPNN)模型、基于外积的神经网络(Outer Product-basedNeural Network,OPNN)模型、神经分解机(Neural Factorization Machines,NFM)模型等等。
S305、确定是否存在与所述音频信号对应的控制命令。
通过S304,第一设备已确定了音频信号对应的动作类型和动作特征,那么第一设备可判断该动作类型和动作特征的组合是否满足预设条件,所述预设条件例如为一个或多个包含动作类型和动作特征的预设组合。比如,通过查询S301中所保存的预设组合(动作类型和动作特征形成的组合)与控制命令之间的映射关系,从而确定该动作类型和动作特征的组合是否符合预设组合中的目标预设组合,也就是说,确定该组合是否存在于在S301所预设的映射表中,如果存在,则说明符合目标预设组合,此时该组合在映射表中具有对应的控制命令,则后续可继续执行S306。否则,说明不符合预设组合,该组合没有对应的控制命令,则可结束本流程。
举例来说,第一设备预设的映射表如图19所示,那么,如果第一设备根据音频信号所确定的动作类型是摩擦左侧麦克风,所确定的动作特征是摩擦1次,即该动作类型和动作特征的组合存在于映射表,所以后续将触发“降低音量”的控制命令。如果第一设备根据音频信号所确定的动作类型是摩擦右侧麦克风,所确定的动作特征是摩擦2次,即该动作类型和动作特征的组合不存在于映射表,那么可结束流程。
需要说明的是,本申请中,由于动作类型和信号类型具有对应关系,动作特征和信号特征具有对应关系,所以本申请实施例也可以描述为:通过S303,第一设备已确定了音频信号对应的信号类型和音频特征,那么第一设备可判断该信号类型和音频特征的组合是否满足预设条件,所述预设条件例如为一个或多个包含信号类型和音频特征的预设组合。比如,通过查询S301中所保存的预设组合(信号类型和音频特征形成的组合)与控制命令之间的映射关系,从而确定该信号类型和音频特征的组合是否符合预设组合中的目标预设组合,也就是说,确定该组合是否存在于在S301所预设的映射表中,如果存在,则说明符合目标预设组合,此时该组合在映射表中具有对应的控制命令,则后续可继续执行S306。否则,说明不符合预设组合,该组合没有对应的控制命令,则可结束本流程。
S306、触发根据控制命令对第二设备进行控制。
具体实施例中,控制命令用于指示第二设备执行某种功能。第一设备将控制命令发送第二设备,第二设备即可根据该控制命令执行相关的功能操作。举例来说,以第二设备为智能手机例,第一设备可通过控制命令控制所述第二设备执行拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、开启/关闭指定功能模式中至少一种。其中,所述指定功能模式例如可以是静音模式、振动模式、飞行模式、省电模式、主动降噪(ANC)功能、监听模式(HearThrough)等等功能,本申请不做限定。
需要说明的是,在可能的实施例中,控制命令也可能用于指示第一设备自己执行某种功能。例如在第一设备为手机的场景中,第一设备可根据该控制命令执行拨打电话、接听/挂断电话、发送信息、播放/暂停音乐、播放/暂停视频、调整曲目、调整音量、锁屏/解锁屏、开启/关闭指定功能模式中至少一种。其中,所述指定功能模式例如可以是静音模式、振动模式、飞行模式、省电模式、主动降噪(ANC)功能、监听模式(HearThrough)等等功能,本申请不做限定。
可以看到,本申请实施例中,第一设备预存有无声操作的动作类型和动作特征与控制命令之间的映射关系,当通过麦克风采集到用户摩擦或点击麦克风的无声操作或者在麦克风附近扇风或吹气的无声操作所引起的音频信号,第一设备可识别出音频信号的信号类型和音频特征,并进一步确定信号类型和音频特征分别对应的动作类型和动作特征,从而实现对该无声操作的识别,进而可以根据动作类型和动作特征的组合对应的控制命令实现对第二设备的控制。这样,实现了在用户不发出声音的情况下也能对第二设备进行控制,拓展了用户对设备控制形式。无声操作的输入方式比较简便,提高了第二设备拨打紧急电话等操作的隐蔽性。此外,由于本申请使用的第一设备本身就具有麦克风,通过复用设备上的麦克风就可以实现控制功能,无须增加额外的传感器设备,且成本较低,设备功耗较低。所以,实施本申请能极大提升用户的使用体验。
需要说明的是,上述实施例用于阐述本申请的一些实施方案。在实际应用中,还可以根据上述实施例的技术内容进行进一步的拓展/变形/细化。
举例来说,在本申请可能的实施例中,当第一设备中还设置有除麦克风之外的其他传感器时,还可以利用所述其他传感器,辅助第一设备检测麦克风采集的音频信号中是否存在与待识别的无声操作相对应的噪声信号,提高识别的准确率。例如,如果第一设备具有运动传感器和两个麦克风,且配置第一设备通过一个麦克风来检测无声操作。那么,第一设备可根据运动传感器的检测结果,可以确定用户是处于静止状态还是处于运动状态。假设检测到用户处于静止状态,通过一个麦克风检测到无声操作相对应的音频信号,同一时刻另一个的麦克风没有检测到无声操作相对应的音频信号,则第一设备可确定是用户在进行无声操作以便于控制第二设备。否则,如果两个麦克风都检测到音频信号,可能存在误识别的情况,则第一设备可以不执行后续控制操作。这样,利用第一设备中已有的其他传感器,配合不同类型传感器,既能够实现对第二设备的控制操作,还有利于提升识别的可靠性,进一步提升用户使用体验,且能节约误识别带来的功耗。
又举例来说,在本申请可能的实施例中,第一设备还可以利用第二设备或其他终端设备或服务器提供的信息,控制本申请提供的设备控制方法的功能的开启或关闭,从而提升设备可靠性。例如,第一设备可以获取第二设备提供的天气预报信息,如果天气预报信息指示了当前环境中的风力超过预设的大小,则可提醒用户关闭本申请提供的设备控制方法的功能,从而避免因大风影响本申请方案中对音频信号识别的准确性,进一步提升了方案可靠性,提升用户使用体验。
参见图20,图20是本申请实施例提供的一种第一设备40的结构示意图,以及由第一设备40和第二设备50组成的系统的示意图,其中所述第一设备和第二设备可进行通信连接,所述通信连接为无线连接或者有线连接。其中,所述第一设备40包括采集模块401、信号处理模块402和控制模块403,在一些实施例中,采集模块401、信号处理模块402和控制模块403可以以软件代码的形式存在,在一具体实现中,采集模块401、信号处理模块402和控制模块403的数据/代码可被存储于如图6所示的存储器120,并可运行于如图6所示的处理器110。其中:
采集模块401,用于通过所述至少一个麦克风采集音频信号;
信号处理模块402,用于确定所述音频信号的信号类型和音频特征;所述信号类型至少包括风噪;
控制模块403,用于判断所述信号类型和所述音频特征是否符合预设条件;当所述信号类型和所述音频特征符合预设条件时,触发所述预设条件对应的控制命令,所述控制命令用于对第二设备进行控制。
具体实施例中,采集模块401、信号处理模块402和控制模块403可相互配合,以执行如图7、图14、或图18实施例中第一设备侧的功能,各功能模块的具体实现内容可参考上述方法实施例的相关步骤描述,为了说明书的简洁,这里不再赘述。
本申请实施例还提供了一种计算机可读存储介质,该计算机可读存储介质中存储有指令,当其在计算机或处理器上运行时,使得计算机或处理器执行上述任一个方法中的一个或多个步骤。上述信号处理装置的各组成模块如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在所述计算机可读取存储介质中。
基于这样的理解,本申请实施例还提供一种包含指令的计算机程序产品,当其在计算机或处理器上运行时,使得计算机或处理器执行本申请实施例提供的任一个方法。本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备或其中的处理器执行本申请各个实施例所述方法的全部或部分步骤。
以上所述实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的范围。例如,装置实施例中的一些具体操作可以参考之前的方法实施例。
- 设备控制装置、声音识别装置、代理装置、车载设备控制装置、导航装置、音响装置、设备控制方法、声音识别方法、代理处理方法、车载设备控制方法、导航方法、音响装置控制方法和程序
- 通信系统、用户设备、控制装置、通信系统控制方法、用户设备控制方法、以及控制装置控制方法