一种用于智能面试的表达能力维度评价方法及装置
文献发布时间:2023-06-19 11:02:01
技术领域
本发明属于人工智能技术领域,涉及对图像、音频信息的特征抽取和深层维度的机器学习,用于对面试者进行特征画像的建模分析,为一种用于智能面试的表达能力维度评价方法及装置。
背景技术
随着技术发展和经济发展需求,大部分企业都有降本增效需求,减少在招聘中的人力投入,提升效率是其中重要一环。对于标准明确、对面试者要求偏低的岗位,AI面试技术通过设定标准化问题就可以自动判断面试者是否满足要求,而对于高要求岗位,通过AI面试可以用于对面试者进行初筛,从而减轻面试官后续的面试量,大大降低人工成本。
在提高面试效率的同时,如何保障面试质量成为核心。面对海量面试者,面试需要花费大量时间进行评估,而且即便是经验丰富的面试官也难免会因为疲劳、情绪等主观因素造成评估偏差。而“招错人”一旦既成事实,可能对企业组织管理、业务发展和人力成本等各方面带来不小的负面影响。
一般的线上面试系统仅仅提供了最基础的判断能力,只能从地区、职位、学历等简单、浅层的维度用基于规则的方法呈现面试者的情况,智能性较差,难以替代面试官的工作,无法全面多维地呈现面试者的胜任能力,进而无法科学、精准地解决目前招聘流程所存在的问题和需求。而基于自然语言处理和计算机视觉技术的自动化、智能化的分析面试者在面试中的表现,进行面试者表达能力的评估,能够深度评估面试者的潜在能力,对人才审核和选拔具有积极的意义。将先进的AI技术引入科学的面试内容分析能够有效地助力于招聘工具的升级、招聘资源的节省和招聘效率及质量的提升。
发明内容
本发明要解决的问题是:解决现有线上面试系统在表达能力方面的评估缺口和分析不够精准合理的问题,目的是通过自动化流程和智能化工具对人才表达能力进行快速、精准的评估,提升面试效率和评估质量。
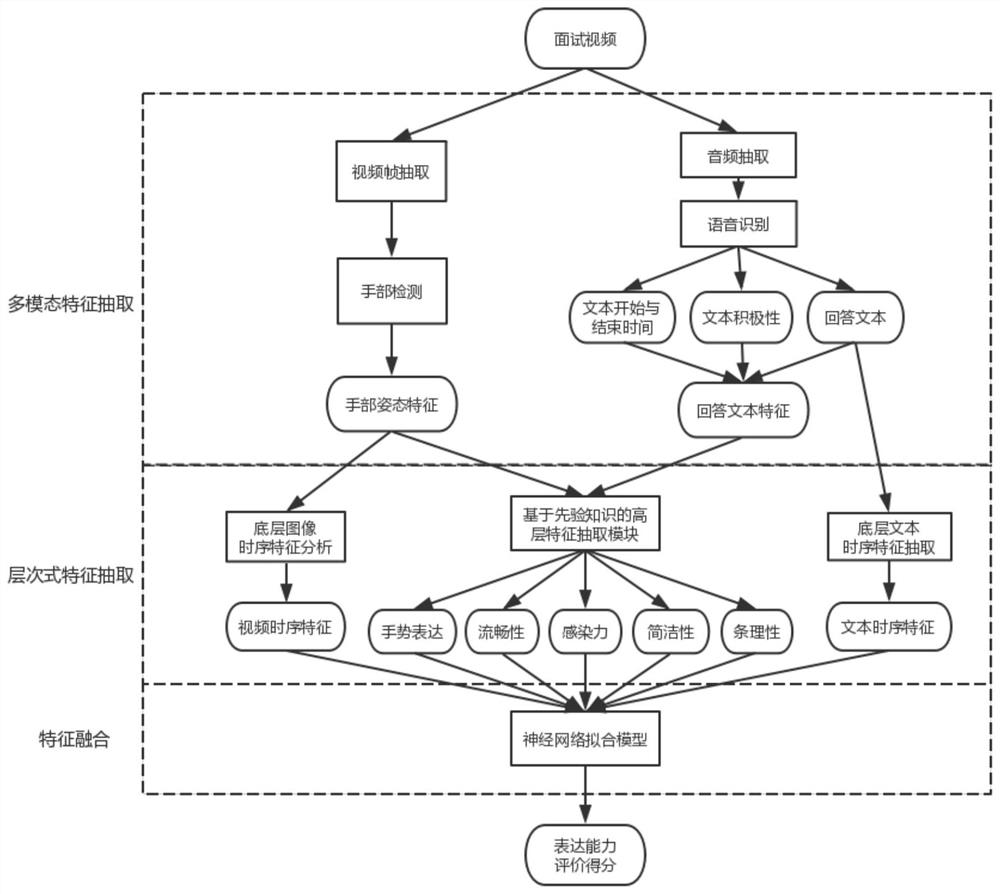
本发明的技术方案为:一种用于智能面试的表达能力维度评价方法,采集面试者面试视频,抽取视频帧图像序列和视频的音频数据,使用分布式函数计算服务搭建基于深度神经网络的多阶段特征提取模型,获得多模态、层次式特征表示,用于产生面试者表达能力维度的综合评价;首先将抽取到的视频帧输入基于CNN的手部检测模型进行特征提取,得到底层手部姿态特征,将音频数据输入基于自然语言处理的音频处理模块,获取底层回答文本特征,底层手部姿态特征和底层回答文本特征构成多模态特征;将两种底层特征分别输入两个LSTM编码为时序特征,得到视频时序特征和文本时序特征;再通过一组基于先验知识的规则从多模态特征中抽取抽象的高层语义特征,包括手势表达、流畅性、感染力、条理性、简洁性特征,视频时序特征、文本时序特征及高层语义特征构成层次式特征;最后,将层次式特征标准化后输入全连接神经网络,进行特征融合,得到表达能力等级分类器,用于预测表达能力等级。
本发明还提供一种用于智能面试的表达能力维度评价装置,配置有数据处理模块,数据处理模块的输入为候选者面试视频,输出为表达能力维度评价信息,数据处理模块中配置有表达能力评估模型,使用分布式函数计算服务搭建,表达能力评估模型由上述的方法训练得到,并执行所述评价方法。形成弹性高效的适用于智能面试的表达能力评价系统。
本发明的有益效果是:提出了一种用于智能面试的表达能力维度评价方法及装置,通过自动化流程和深度学习技术,对面试视频提取多模态、层次式特征来产生面试者表达能力的综合评价。第一,现有的智能评价方法大多仅依赖底层感知特征,本发明所提出的层次式特征综合了底层感知特征和高层认知特征,能够为面试者表达能力形成更加完整的表征;第二,现有智能评价方法大多仅依赖与对静态视频帧的分析,本发明利用LSTM网络进一步抽取时序特征,以此捕捉面试者在面试过程中的动态行为信息;第三,现有智能评价方法大多仅利用图像或语音一种模态的信息进行分析,本发明通过对图像、音频双通道特征提取,产生多模态特征表示,使其能够具备理解多源信息的能力;第四,现有智能评价方法大多仅使用单个深度学习模型进行特征提取,本发明使用分布式函数计算服务搭建系统,使本发明能够使用多个深度学习模型进行多种特征提取,使系统具备良好的性能和可扩展性。本发明实现的基于层次式特征表示、多模态特征融合的表达能力评价方法能够捕捉到面试者更全面的信息,有助于产生更客观的评价供面试官进行进一步判断,有效降低面试的时间成本,减少主观因素对面试的影响,同时提升了评估效率和质量,具有良好的实用性。
附图说明
图1为本发明的实施流程图。
图2为本发明的手势时序特征训练的结构图。
图3为本发明的回答文本时序特征训练的结构图。
图4为本发明的最终评分分类神经网络结构图。
具体实施方式
本发明提出了一种用于智能面试的表达能力维度评价方法及装置,如图1所示,采集面试者面试视频,抽取视频帧图像序列和视频的音频数据,通过基于深度神经网络的多阶段特征提取模型获得具备良好可解释性的多模态、层次式特征表示,用于产生面试者表达能力维度的综合评价。首先将抽取到的视频帧输入基于CNN的手部检测模型进行特征提取,得到底层静态手部姿态特征;将音频数据输入基于自然语言处理的音频处理模块,获取底层语音表达特征;再将上述两种底层特征分别输入两个LSTM进一步编码为时序特征,得到包含丰富表达能力信息的视频级底层时序特征;再通过一组基于先验知识的规则从底层手部姿态特征、语音表达特征中抽取抽象的高层语义特征,包括手部表达、表达流畅度、感染力、条理性、简洁度信息;最后,将上述底层时序特征和高层语义特征标准化后输入全连接神经网络,进行多模态融合,预测表达能力等级,系统使用分布式函数计算服务搭建,形成弹性高效的适用于智能面试的表达能力评价系统。
下面结合本发明实施例及附图,对本发明实例中的技术方案进行清楚、完整地描述,所描述的实例仅仅是本发明的一部分实例,而不是全部的实例。基于本发明的实例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实例,都属于本发明的保护范围。本发明的具体实施包括以下步骤。
1.对输入的面试视频进行预处理,每隔k帧采集一帧,进而为一个视频生成一个图像序列;本实施例优选k=10;
2.通过手部检测技术获得面试者手部位置框和手腕位置信息,得到手部姿态特征:对于输入的每一帧图像,输入我们的手部检测模型中,得到双手的位置和手腕的位置,每一只手的输出格式为(x1,y1,x2,y2,xw,yw),其中x1,y1是手部左上角坐标,x2,y2是右下角坐标,xw,yw是手腕的坐标,当无法检测到手部时,输出6个空值;
3.使用ffmpeg从面试视频提取音频,调用Vosk Api对面试音频进行语音识别,用于生成语音转文本、分词起始时间、分词结束时间和分词文本积极性等底层特征。文本积极性用范围在[0,1]的浮点数表示分词的积极度数值,文本积极性属于文本情感分析技术,不再详述。
4.解析Vosk Api返回的文本信息字段,获取回答文本的分词列表,进一步计算得到其他能支持表达能力分析的底层特征,包括:
1)问候语:分析分词列表查看是否出现问候语,对诸如“你好”、“您好”、“老师好”、“你们好”这样的问候词,如果出现则返回结果1,否则返回0;
2)感谢语:分析分词列表查看是否出现感谢语,对诸如“谢谢”、“感谢”这样感谢词,如果出现则返回结果1,否则返回0;
3)思考时间:获取回答文本的第一个字的开始时间作为特征的结果;
4)回答时间:获取每一个句子的开始时间和结束时间并求差作为该语句的时长,统计所有语句的时长作为特征的结果;
5)语速:获得回答文本长度特征,根据文本相对应的开始和结束时间,计算回答总时长。最后求比值作为特征返回结果;
6)回答文本长度:获取每个分词的字数之和作为回答的文本;
7)文本积极性:对每一个分词的积极性取平均数作为整个视频的篇章级文本积极性结果;
8)停顿时长:解析语音转文本结果,根据每一个词汇的开始和结束时间,获取上下词汇之间的停顿时间列表,设定阈值Pause_threshold=0.8秒。对停顿时间超过0.8秒的停顿进行求和,求和结果作为特征的结果;
9)短停次数:对上下词汇之间的停顿时间列表设定两个阈值,短时停顿Short_pause=0.8秒,长时停顿Long_pause=1.5秒,对停顿时间在两个阈值间的停顿判定为短停,对短停次数求和作为短停次数特征;
10)长停次数:在短停次数的数据基础上,将超过1.5秒的停顿判定为长停,对长停的次数求和记为长停次数特征;
11)语气词数:分析分词列表,对诸如“吧”、“罢”、“呗”这样的语气词建立一张表,统计表中所有语气词出现的总次数,作为语气词数特征的结果;
12)关联词数:分析分词列表,对诸如“首先”“其次”“因为”“所以”这样体现逻辑性的关联词建立一张表,统计表中所有关联词出现的总次数,作为关联词数特征的结果;
13)停顿词数:分析分词列表,对诸如“嗯”、“啊”、“呃”、“那个”这样通常用于表示思考或停顿的停顿词建立一张表,统计表中所有停顿词出现的总次数,作为停顿词数特征的结果;
14)词汇数:计算分词列表的词汇的总数量作为特征返回结果。
5.根据先验知识对从图像、音频提取的多模态底层特征值进一步加权计算得到多维的高层特征,具体如下:
1)流畅性:对短停次数F
其中atan为Arctangent函数,std为特征的标准差函数,W
2)感染力:对文本积极性F
优选设置W
3)条理性:对短停次数F
优选设置W
4)简洁性:对文本长度F
5)手势表达:先排除视频帧中手部检测置信度低于设定值的图像,然后根据手腕位置相对于手部区域范围的位置,若手腕在相对手部中心位置的下部则判断为有手势,对手势次数做非线性归一化,得到手势表达特征。
6.将视频特征输入到LSTM时序分析模块,其结构见图2,说明如下:
1)网络输入:输入层为前述帧级原始特征,包括手部的6个坐标位置,共12维相连接而得。所有特征列都要进行标准化,公式为
norm(x)=(x-mean(x))/std(x)
其中x为一类特征的具体实例值,mean(x)表示该类特征在所有训练样本上的均值,std(x)表示该类特征在所有训练样本上的方差。
2)网络设置:LSTM隐藏层设置64个长期状态单元64个输出单元,最长限制为256个时序数据。
3)训练方案:将最后一个时序输出单元的64维向量并入第8步中的神经网络进行端对端的训练。
7.将音频回答文本输入到LSTM时序分析模块,其结构见图3,训练过程为:
1)网络输入:输入层为回答文本进行词嵌入后的张量,使用Bert模型对文本的每个字进行词嵌入,得到Bert模型最后一层的768维张量作为词向量。
2)网络设置:LSTM隐藏层设置256个长期状态单元和64个输出单元,最长限制为512个时序数据。
3)训练方案:将最后一个时序输出单元的64维向量并入第8步中的神经网络进行端对端的训练。
8.对计算得到的多模态特征和高层的抽象子维度数据进行标准化后,使用3层全连接网络进行深度学习,得出精确的评估表达能力等级,其结构见图4,具体训练过程为:
1)标签处理:根据历史数据中各个面试者的表达能力得分高低,将表达能力分为5类等级(下、中下、中、中上、上);
2)网络输入:输入层为前述视频手势时序特征(64维向量)、回答文本时序特征(64维向量)和高层语义特征(5个)相连接而得,所有特征列都要进行标准化,公式同视频时序特征里的标准化方法;
3)网络隐藏层:使用3层全连接神经网络模型进行拟合训练,两层隐藏层各有1024个单元,激活函数为ReLU,输出层有5个输出值,使用softmax激活,分别代表5类表达能力的置信度。
4)全连接神经网络模型训练过程及参数:
[1]训练采用小批量训练法,batchsize=64;
[2]迭代次数epoch=300;
[3]多阶段学习率调整,初始学习率lr=0.001,milestones=[120,180,240],调整率为每次调整为当前学习率的2/10,即乘以gamma=0.2;
[4]采用动量优化法,momentum=0.9;
[5]采用权重衰减缓解过拟合,weight decay=2e-3;
[6]损失函数使用cross entropy loss交叉熵误差;
[7]梯度反向传播方法为:SGD随机梯度下降。
9.在对新面试视频计算表达能力评价时,将计算得到的视频时序特征、文本时序特征及高层语义特征按照训练网络时的标准化方式进行标准化后,连接并输入神经网络,计算得到该面试者的表达能力评级。