一种实现涉诈应用收集和特征提取聚类的算法模型及系统
文献发布时间:2023-06-19 11:57:35
技术领域
本发明属于APP或网址上报与分析系统领域,特别是涉及一种实现涉诈应用收集和特征提取聚类的算法模型以及其对应的系统。
背景技术
识别犯罪团伙对案件侦办提供重要的技术支持。本发明中处理的数据是基于对受害人或办案民警上报的涉诈app或网址进行溯源获取其相关特征数据,现实中同一个诈骗犯罪团伙运营的app或网址的特征会有一定相似性,可能是一个或多个特征相似,比如相同的开发人员虚拟身份信息、相似的代码包结构、使用了相同的ip或域名、使用相同的第三方开发平台key等,通过对这些特征进行比对和计算相似度可以对app(或网址)进行聚类可识别犯罪团伙,进而进行串并案侦察。
发明内容
本发明提供了一种实现涉诈应用收集和特征提取聚类的算法模型及系统,解决了以上问题。
为解决上述技术问题,本发明是通过以下技术方案实现的:
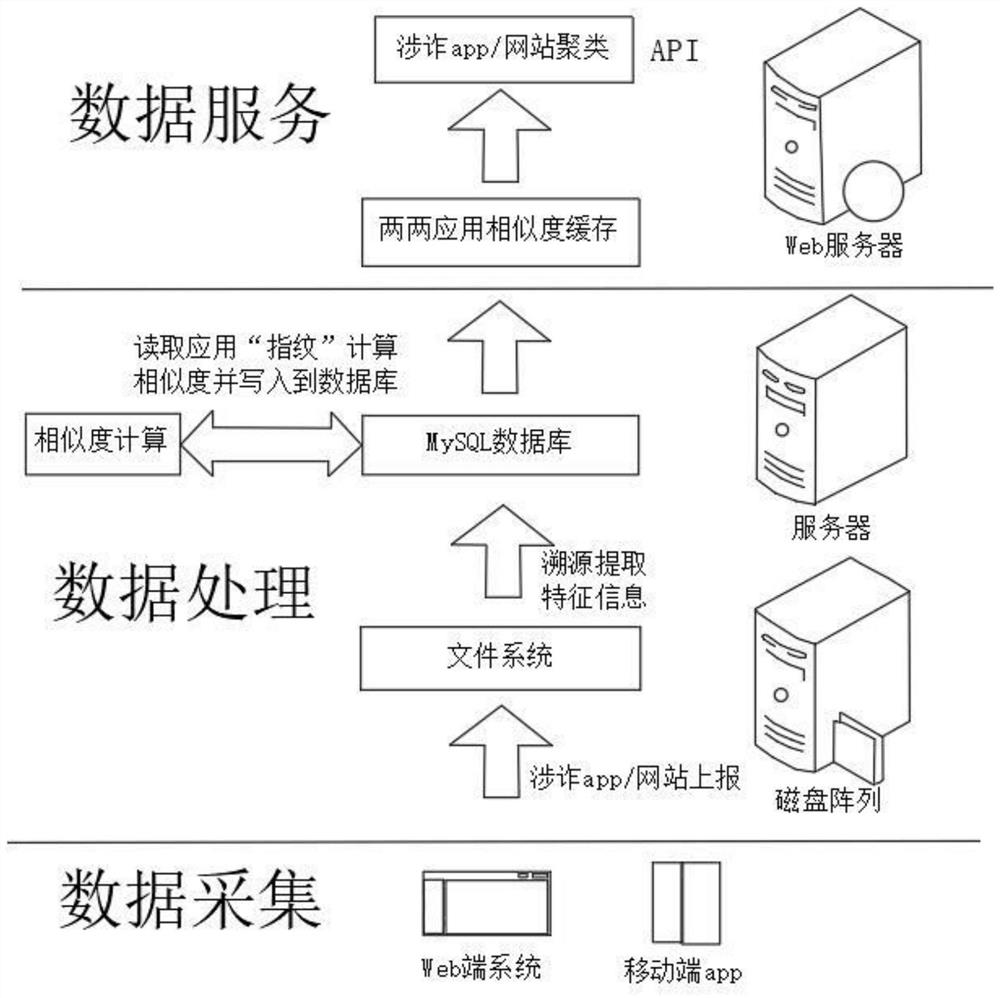
本发明的一种实现涉诈应用收集和特征提取聚类的算法模型系统,包括:web端和移动端涉诈上报系统、数据分析服务器;
其中,所述web端和移动端涉诈上报系统主要用于获取具体为app或网址的涉诈应用;
其中,所述数据分析服务器对获取的应用进行溯源提取“指纹”数据,所述“指纹”数据包括包名、应用MD5值、启动类、ip、域名、第三方开发平台key、应用签名、开发人员虚拟身份、包中文件路径及大小信息中任意一种或多种,通过所述“指纹”数据唯一确定一个应用,并对获取的应用特征数据进行聚类分析,最终完成涉诈应用的分类。
一种实现涉诈应用收集和特征提取聚类的算法模型,包括如下流程步骤:
S01、对于待聚类的一批涉诈应用,从数据库中获取每个应用对应的“指纹”数据,分别计算两两应用“指纹”数据的相似度,相似度的计算需要计算每个“指纹”数据对应特征项的相似值,如果某个app的某个特征项为空,则其与其他app对应的该特征项的相似度为0,具体考虑的计算方式如下:
(1)完全匹配
对于某个特征项只有一个值的时,特征项值相同则该特征项比对结果为1,特征项值不同则该特征项比对结果为0,如启动类、应用签名;
(2)多值任意匹配
对于某个特征项存在多个值的情况,只要其中一个值匹配则该特征项比对结果为1,全部特征项值不匹配则该特征项比对结果为0,针对实际情况,同一个犯罪团伙使用的ip前3位很可能是相同,可以对ip进行前缀匹配,如果完全匹配没有命中ip而前缀匹配命中了,则该特征项的比对结果为μ,所述μ默认为0.6,根据实际情况进行调整;
(3)字符串相似度计算
比如应用代码文件的路径,其目的是计算包代码目录结构的相似性,先计算待比对的两个app之间任意两个的代码文件路径的相似度,此处通过计算文件个数较小的app1的所有文件F1i与待比对app2的所有文件F2j两两文件路径相似度,对于app1的某个文件与app2所有文件选择相似度最大者,即:S
其中,两个字符串的相似度计算为相同子串长度,具体为大于等于2之和与两个字符串中较大的长度的比值,相同子串的检测如果存在部分重复的子串,选择长度较大者;
然后计算超过某个相似度阈值ɑ文件对个数分别与两个app中文件个数比值的平均值,,具体还考虑文件大小数值是否接近;
(4)数字近似计算
针对应用代码文件的大小,当两个app之间任意两个的代码文件路径的相似度超过某个阈值,进一步判断其文件大小是否数值接近,可通过两个文件大小值之差的绝对值与两个文件大小值之和的比值进行量化,令两个app1和app2的大小分别为s1和s2,衡量其差异的比值为
当这个比值小于某个阈值β,则可以认为这两个应用的代码大小接近,然后结合代码目录结构一起判断整个代码是否相似;
S02、通过上一步,可以得到待聚类的应用两两之间各特征项之间的相似值,接着计算两两应用之间的相似度;
若得到app1和app2每个特征项的相似值分别为v1、v2、...vn,对于待聚类应用A1、A2...An,两两应用的相似度为
S03、基于上一步得到的两两应用之间的相似度进行聚类,具体聚类步骤如下:
S031、保留相似度大于阈值θ的两两应用对,将不同两两应用对中存在交集的所有应用聚为一类,具体为:当某个应用对与现有分类中某类的某个应用相似度大于阈值则该应用对归为该类,反之与现有类所有应用的相似度都小于阈值的则新增一类,当两个类中出现有相同的应用则将这两个类合并为一类;对于与其它所有应用相似度都小于阈值的应用单独为一类,这一步完成后形成初始的C1、C2...Cn个类;
S032、对初始的应用超过2个的类的聚类结果进行修剪,对于一个初始聚类中的任意应用计算其与其他应用相似度的平均值,将平均相似度小于阈值θ的应用从该类中剔除,则该类中剩下的都是两两相似度较高的应用;
S033、递归对上一步中剔除的所有应用重新经过前面两步处理,直到所有被剔除的应用重新归类。
进一步地,上述算法模型中的所述阈值ɑ、β、θ根据实践验证进行调整。
进一步地,所述步骤S01中的字符串相似度计算,除了考虑分布式和多线程,还采用在算法逻辑上进行优化:分别对两个app的文件路径的长度进行排序,对于文件个数小的app1的每一个文件路径,如路径长度为len的待比对文件路径为app2中路径长度为(len*ɑ,len+len-len*ɑ),可减少两两文件计算相似度的次数,加快算法的执行速度。
进一步地,在实际部署中,经验证形成较优的算法模型参数后,还采用提前将两两应用的相似度计算好存到数据库或内存数据库中,当有新的应用加入时,只用增量计算该应用与现有应用两两相似度,而在web端可以选择任意应用进行聚类分析,此时只用从数据库或缓存中获取待聚类的应用两两之间的相似度进行所述步骤S03的聚类操作,如此便可实时出结果。
本发明相对于现有技术包括有以下有益效果:
1、本发明的算法模型根据应用“指纹”数据的特点设计与之匹配的聚类算法,设计多种不同类别维度属性的量化方式,算法具有很强的伸缩性,可对新增提取的特征属性进行扩展,该算法模型能够较准确的对应用进行分类,其一个类中的应用很可能为一个犯罪团伙在运营,这对串并案侦查提供重要支撑。
2、本发明对app或网址进行聚类需要考虑多种特征比对计算方式,根据特征实际情况设计合理的量化方案,支撑用于聚类的相似度计算;针对特征比对,考虑的比对方式主要有:完全匹配、多值任意匹配、字符串相似度计算、数字近似计算,其整体的特征比对识别执行精准度高、速度快,大大提高了网络案侦的效率。
3、本发明的算法模型中的阈值ɑ、β、θ需要经过实践验证进行调整,字符串相似度计算除了考虑分布式和多线程,还可以在算法逻辑上进行优化:分别对两个app的文件路径的长度进行排序,可减少两两文件计算相似度的次数,加快算法的执行速度。
4、本发明在实际部署中,经过验证形成较优的模型参数之后,可以提前将两两应用的相似度计算好存到数据库或内存数据库中,当有新的应用加入时,只用增量计算该应用与现有应用两两相似度,而在web端可以选择任意应用进行聚类分析,此时只用从数据库或缓存中获取待聚类的应用两两之间的相似度进行聚类操作,如此便可实时出结果。
当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种实现涉诈应用收集和特征提取聚类的算法模型系统的结构图;
图2为本发明算法模型的流程步骤图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
本发明的技术方案主要由两部分组成:涉诈应用收集和特征提取聚类的算法模型系统以及聚类算法模型。
涉诈应用采集是通过web端和移动端涉诈应用上报系统实现,这里的应用可以是app,也可以是网址。应用数据的提取涉及到计算机软件反向工程技术,指通过对目标程序进行“逆向分析、研究”工作,以推导出该软件产品所使用的思路、原理、结构、算法、处理过程、运行方法等设计要素,某些特定情况下可能推导出源代码,利用反编译工具、抓包工具和信息检索提取正,通过正则匹配等获取应用的“指纹”数据。应用“指纹”数据提取大部分工作通过自主开发的自动化溯源工具完成,少量筛选工作由人工完成。
请参阅图1所示,本发明的一种实现涉诈应用收集和特征提取聚类的算法模型系统,包括web端和移动端涉诈上报系统、数据分析服务器;
其中,web端和移动端涉诈上报系统主要用于获取具体为app或网址的涉诈应用;
其中,数据分析服务器对获取的应用进行溯源提取“指纹”数据,“指纹”数据包括:包名、应用MD5值、启动类、ip(属性信息包括:归属地、所属服务商、历史绑定域名等)、域名(属性信息包括:当前解析ip、历史解析ip、子域名、备案信息、WHOIS信息等)、第三方开发平台key、应用签名、开发人员虚拟身份、包中文件路径及大小等,其中大部分字段会存在多个值,通过包名和应用MD5值基本可以唯一确定一个应用,如果是网址溯源则主要是ip、域名等信息。通过“指纹”数据唯一确定一个应用,并对获取的应用特征数据进行聚类分析,最终完成涉诈应用的分类;人工对提取的信息进行简单筛选,确保能过滤掉确定无用的信息;根据特征实际情况设计合理的量化方案,支撑用于聚类的相似度计算,通过聚类分析可以揭示归属同一类应用很可能属于同一犯罪团伙运营。
如图2所示,一种实现涉诈应用收集和特征提取聚类的算法模型,其特征在于,包括如下流程步骤:
S01、对于待聚类的一批涉诈应用,从数据库中获取每个应用对应的“指纹”数据,分别计算两两应用“指纹”数据的相似度,相似度的计算需要计算每个“指纹”数据对应特征项的相似值,如果某个app的某个特征项为空,则其与其他app对应的该特征项的相似度为0,具体考虑的计算方式如下:
(1)完全匹配
对于某个特征项只有一个值的时,特征项值相同则该特征项比对结果为1,特征项值不同则该特征项比对结果为0,如启动类、应用签名;
(2)多值任意匹配
对于某个特征项存在多个值的情况,只要其中一个值匹配则该特征项比对结果为1,全部特征项值不匹配则该特征项比对结果为0,针对实际情况,同一个犯罪团伙使用的ip前3位很可能是相同,可以对ip进行前缀匹配,如果完全匹配没有命中ip而前缀匹配命中了,则该特征项的比对结果为μ,μ默认为0.6,根据实际情况进行调整;
(3)字符串相似度计算
比如应用代码文件的路径,其目的是计算包代码目录结构的相似性,先计算待比对的两个app之间任意两个的代码文件路径的相似度,此处通过计算文件个数较小的app1的所有文件F1i与待比对app2的所有文件F2j两两文件路径相似度,对于app1的某个文件与app2所有文件选择相似度最大者,即:S
其中,两个字符串的相似度计算为相同子串长度,具体为大于等于2之和与两个字符串中较大的长度的比值,相同子串的检测如果存在部分重复的子串,选择长度较大者,如两个字符串长度分别为L1和L2,其相同子串有l1、l2、l3...ln(如:有两字符串abcdefg1234和cdef123789,则相同字串有cdef、123),相同子串的长度之和L=L
然后计算超过某个相似度阈值ɑ文件对个数分别与两个app中文件个数比值的平均值,,具体还考虑文件大小数值是否接近;例如app1和app2的文件个数分别为m和n,两个app代码文件相似度超过ɑ(考虑文件大小)的文件个数为g,则这两个应用代码目录结构的相似度为
(4)数字近似计算
针对应用代码文件的大小,当两个app之间任意两个的代码文件路径的相似度超过某个阈值,进一步判断其文件大小是否数值接近,可通过两个文件大小值之差的绝对值与两个文件大小值之和的比值进行量化,令两个app1和app2的大小分别为s1和s2,衡量其差异的比值为
当这个比值小于某个阈值β,则可以认为这两个应用的代码大小接近,然后结合代码目录结构一起判断整个代码是否相似;
S02、通过上一步,可以得到待聚类的应用两两之间各特征项之间的相似值,接着计算两两应用之间的相似度;
若得到app1和app2每个特征项的相似值分别为v1、v2、...vn,对于待聚类应用A1、A2...An,两两应用的相似度为
S03、基于上一步得到的两两应用之间的相似度进行聚类,具体聚类步骤如下:
S031、保留相似度大于阈值θ的两两应用对,将不同两两应用对中存在交集的所有应用聚为一类,如:S
S032、对初始的应用超过2个的类的聚类结果进行修剪,对于一个初始聚类中的任意应用计算其与其他应用相似度的平均值,将平均相似度小于阈值θ的应用从该类中剔除,则该类中剩下的都是两两相似度较高的应用;
S033、递归对上一步中剔除的所有应用重新经过前面两步处理,直到所有被剔除的应用重新归类。
其中,上述算法模型中的阈值ɑ、β、θ根据实践验证进行调整。
其中,步骤S01中的字符串相似度计算,因为一个app的文件可能有三四千个,两个app的任意两个文件的组合较多的可能是千万级别,计算量较大,除了考虑分布式和多线程,还采用在算法逻辑上进行优化:分别对两个app的文件路径的长度进行排序,对于文件个数小的app1的每一个文件路径,如路径长度为len的待比对文件路径为app2中路径长度为(len*ɑ,len+len-len*ɑ),可减少两两文件计算相似度的次数,加快算法的执行速度。
其中,在实际部署中,经验证形成较优的算法模型参数后,还采用提前将两两应用的相似度计算好存到数据库或内存数据库中,当有新的应用加入时,只用增量计算该应用与现有应用两两相似度,而在web端可以选择任意应用进行聚类分析,此时只用从数据库或缓存中获取待聚类的应用两两之间的相似度进行步骤S03的聚类操作,如此便可实时出结果。
与现有技术相比,本发明具有如下有益效果:算法模型通过考虑多种特征比对计算方式,根据特征实际情况设计合理的量化方案,通过聚类分析,可以为串并案侦查提供重要支撑。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
- 一种实现涉诈应用收集和特征提取聚类的算法模型及系统
- 一种跨网络涉诈关联分析方法、系统及计算机存储介质