生物反应器运行状况分级预报预测方法及系统
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及生物反应器技术领域,尤其是涉及一种生物反应器运行状况分级预报预测方法及系统。
背景技术
生物反应器往往是按照既定的设计条件来制造的,相关的自动控制系统或装置等也是按照既定的控制策略来执行的。对于实际过程中随时可能出现的外部条件的波动、干扰与变化,生物反应器及其自动控制系统或装置是不能产生实时响应的。生产过程中产生的各类运行数据总是躺在文件柜、档案室里,并没有真正发挥作用。生物反应器的长期运行管理更多地依赖于人工管理,并且需要具有丰富运行管理经验的人员。同时,不同生产企业之间或企业内部存在的生物反应器硬件设施配置差异、运行管理人员经验与素质的差异,都难以保证运行管理的及时性、有效性和稳定性。
在实际生产过程中,生物反应器运行状况的优劣或者稳定与否,直接关系到生物反应器的产出是否稳定,关系到生物反应器产出的质量是否满足预期要求,关系到生物反应器状态的波动是否会造成其性能下降以及能耗增加等。
所以,如何提高反应器的实时响应能力,保障反应器运行的稳定性是一个亟待解决的问题。
发明内容
本发明的目的在于克服上述技术不足,提出一种生物反应器运行状况分级预报预测方法及系统,以提高反应器运行精细化水平;进而对生物反应器运行状况进行提前预测,并提供反应器运行实时应变对策,以提高反应器实时响应能力,保障反应器运行的稳定性。
为达到上述技术目的,本发明提供一种生物反应器运行状况分级预报预测方法,包括以下步骤:
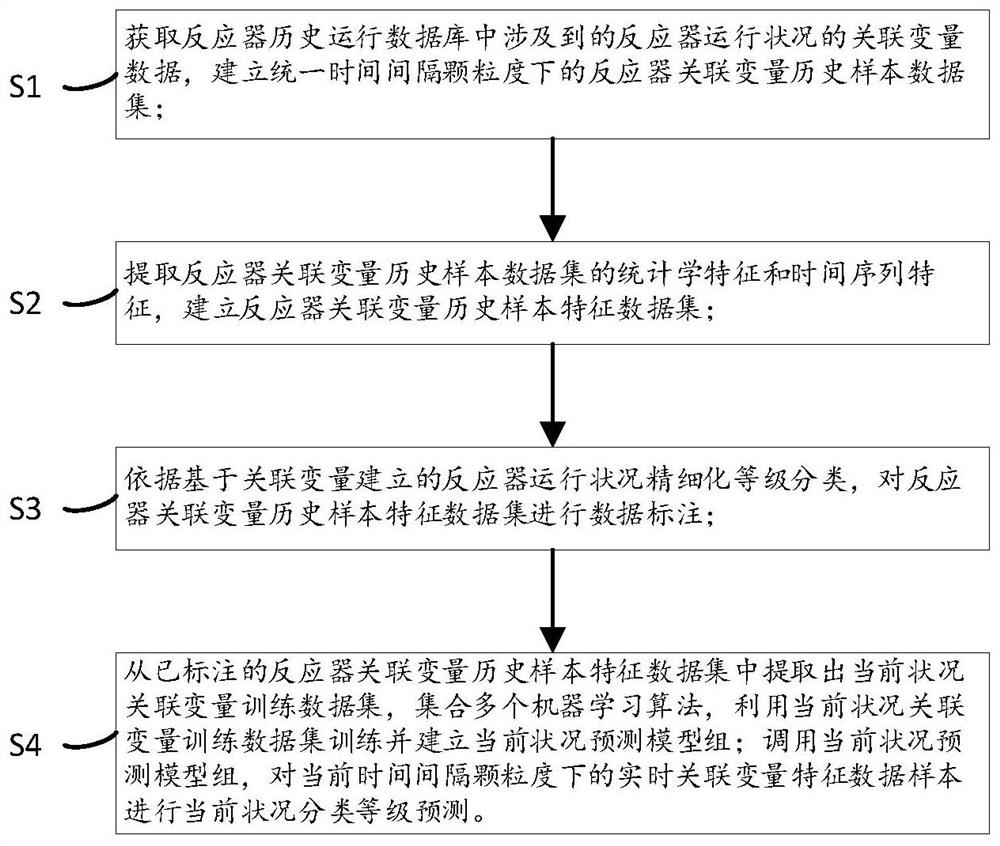
获取反应器历史运行数据库中涉及到的反应器运行状况的关联变量数据,建立统一时间间隔颗粒度下的反应器关联变量历史样本数据集;
提取反应器关联变量历史样本数据集的统计学特征和时间序列特征,建立反应器关联变量历史样本特征数据集;
依据基于关联变量建立的反应器运行状况精细化等级分类,对反应器关联变量历史样本特征数据集进行数据标注;
从已标注的反应器关联变量历史样本特征数据集中提取出当前状况关联变量训练数据集,集合多个机器学习算法,利用当前状况关联变量训练数据集训练并建立当前状况预测模型组;调用当前状况预测模型组,对当前时间间隔颗粒度下的实时关联变量特征数据样本进行当前状况分类等级预测。
本发明还提供一种生物反应器运行状况分级预报预测系统,包括如下功能模块:
历史数据预处理模块,用于获取反应器历史运行数据库中涉及到的反应器运行状况的关联变量数据,建立统一时间间隔颗粒度下的反应器关联变量历史样本数据集;
历史数据特征提取模块,用于提取反应器关联变量历史样本数据集的统计学特征和时间序列特征,建立反应器关联变量历史样本特征数据集;
历史数据标注模块,用于依据基于关联变量建立的反应器运行状况精细化等级分类,对反应器关联变量历史样本特征数据集进行数据标注;
实时分类预测模块,用于从已标注的反应器关联变量历史样本特征数据集中提取出当前状况关联变量训练数据集,集合多个机器学习算法利用当前状况关联变量训练数据集训练并建立当前状况预测模型组;调用当前状况预测模型组,对当前时间间隔颗粒度下的实时关联变量特征数据样本进行当前状况分类等级预测。
与现有技术相比,本发明所述生物反应器运行状况分级预报预测方法及系统,其具有以下有益效果:
(1)充分利用生物反应器运行状况各关联变量的运行数据,对不同来源、不同采集频率、不同时间间隔颗粒度的数据包容性好。
(2)基于关联变量建立的生物反应器运行状况等级分类,是生物反应器运行状况综合性评估的精细化分类;以此为依据,对生物反应器运行状况进行分类预测,比对单一指标或单一变量的预测更具有代表性、综合性和可靠性。
(3)确定表征生物反应器运行状况的、且具备细颗粒度时间序列的关键变量为目标变量,可以避免由于不同关联变量数据序列的时间间隔颗粒度差异产生的限制。在实时条件下,利用目标变量与可利用的关联变量,实施实时数据分析和不同场景不同预测任务,可以解决由于时间间隔颗粒度差异带来的数据不同步或数据缺失的问题。
(4)针对不同监督学习算法对特征数据的利用程度的差异可能带来的偏差,集合多种算法模型分类器,可以利用各个算法分类器的特点与优势,博采众长,增加预测的鲁棒性。
(5)通过实时数据分析与应用场景下的业务领域知识的深度结合,能够提供多维度多参数的未来状况关联变量水平预案,能够增加生物反应器运行实时应变对策、提高生物反应器实时响应能力;相对于传统的依赖单一参数的控制方法,对内外部环境的变化具有更强的适应能力。
(6)将应用场景下的业务领域知识、数据挖掘过程、机器学习算法三者深度结合,有利于提高预测过程的现实意义,预测结果的可解释性好。
附图说明
图1为本发明所述一种生物反应器运行状况分级预报预测方法的流程框图;
图2为图1中步骤S4的分流程框图;
图3为本发明所述一种生物反应器运行状况分级预报预测方法的另一流程框图;
图4为图3中步骤S5的分流程框图
图5为本发明所述一种生物反应器运行状况分级预报预测系统的功能模块框图;
图6为本发明所述一种生物反应器运行状况分级预报预测系统的另一功能模块框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供了一种生物反应器运行状况分级预报预测方法,如图1所示,其包括如下步骤:
S1、获取反应器历史运行数据库中涉及到的反应器运行状况的关联变量数据,建立统一时间间隔颗粒度下的反应器关联变量历史样本数据集。
具体的,获取反应器历史运行数据库,涉及到的表征反应器运行状况的关联变量,包括反应器输入变量(如流量、组分浓度等)、输出变量(如流量、组分浓度等)、过程变量(如溶解氧、氧化还原电位、pH、水温等)、关联设备运行参数(如进水设备、空气压缩机等)、序批周期设置参数、气象条件温度湿度等;过程变量的数据来源是在线监测仪表实时数据,其他变量的数据来源包括但不限于在线监测仪表实时数据、人工检测数据、人工记录数据。
根据生物反应器运行的周期性特征、以及上述关联变量数据采集频率的时间间隔颗粒度差异,设定统一的时间序列时间间隔颗粒度;将不同时间间隔颗粒度的关联变量数据,按照统一时间间隔颗粒度进行数据转换,建立统一时间间隔颗粒度下的反应器关联变量历史样本数据集。
S2、提取反应器关联变量历史样本数据集的统计学特征和时间序列特征,建立反应器关联变量历史样本特征数据集。
所述关联变量数据的统计学特征,包括但不限于关联变量数据的中心特征、离散度特征、分布特征、相关性特征等。
所述关联变量数据的时间序列特征,包括但不限于关联变量时间序列的时间特征、时间序列聚合特征、时间序列季节性特征、时间序列趋势特征等。
S3、依据基于关联变量建立的反应器运行状况精细化等级分类,对反应器关联变量历史样本特征数据集进行数据标注。
S4、从已标注的反应器关联变量历史样本特征数据集中提取出当前状况关联变量训练数据集,集合多个机器学习算法,利用当前状况关联变量训练数据集训练并建立当前状况预测模型组;调用当前状况预测模型组,对当前时间间隔颗粒度下的实时关联变量特征数据样本进行当前状况分类等级预测。
如图2所示,所述步骤S4包括以下分步骤:
S41、设定目标变量,以当前时间间隔颗粒度下可利用的关联变量为提取条件,从已标注的反应器关联变量历史样本特征数据集中提取出包括目标变量在内的当前状况关联变量训练数据集。
具体的,设定目标变量,确定表征反应器运行状况的、且具备细颗粒度时间序列的关键变量作为目标变量,例如,可将溶解氧作为目标变量。
所述当前时间间隔颗粒度下可利用关联变量,指的是当前时间间隔颗粒度下可获得实时数据的关联变量;例如,可以包括S1所述关联变量中的关联设备运行参数、序批周期设置参数、过程变量、输入流量;也可以包括S1所述关联变量中的关联设备运行参数、序批周期设置参数、过程变量、输入流量、输入组分浓度;实时数据不同步或实时数据缺失的变量不包括在内。
根据当前时间间隔颗粒度下可利用关联变量,从已标注的关联变量历史样本特征数据集中,提取出包括目标变量以及上述当前时间间隔颗粒度下可利用关联变量在内的当前状况关联变量训练数据集。
S42、采用多个机器学习算法,利用当前状况关联变量训练数据集对每个算法训练并建立相应的当前状况预测模型,确定模型综合评分排列位于前列的多个算法模型,作为当前状况预测模型组。
采用多个机器学习算法同步进行分类预测,建立相应的当前状况预测模型组,所述机器学习算法的分类器,包括但不限于Random Forest Classifier,Extra TreesClassifier,CatBoost Classifier,Extreme Boosting Classifier,Gradient BoostingClassifier,Light Gradient Boosting Machine,Ada Boost Classifier,Decision TreeClassifier等。
S43、提取当前时间间隔颗粒度下的实时关联变量数据样本的统计学特征和时间序列特征,建立当前时间间隔颗粒度下的实时关联变量特征数据样本。
S44、调用当前状况预测模型组,对当前时间间隔颗粒度下的实时关联变量特征数据样本,进行当前状况分类等级预测,取分类多数的标签作为最终的分类等级预测标签,取分类多数的各个算法预测值的加权平均值作为最终的加权分类等级预测值。
具体的,调用当前状况预测模型组对当前时间间隔颗粒度下的实时关联变量特征数据样本进行当前状况分类等级预测,模型组中的每一个算法分类器,都得到一个相应的分类预测结果;取分类多数的标签作为最终的分类等级预测标签,取分类多数的各个算法预测值的加权平均值作为最终的加权分类等级预测值。
如图3所示,所述一种生物反应器运行状况分级预报预测方法还包括:
S5、从已标注的反应器关联变量历史样本特征数据集中提取出未来状况关联变量训练数据集,集合多个机器学习算法,利用未来状况关联变量训练数据集训练并建立未来状况预测模型组;基于参数水平调整生成未来预测时段的未来状况关联变量特征数据样本,调用未来状况预测模型组对未来状况关联变量特征数据样本进行未来状况分类等级预测、并且基于未来状况关联变量特征数据样本的未来状况分类等级预测结果符合期望的反应器运行状况分类等级。
如图4所示,所述步骤S5包括以下分步骤:
S51、设定目标变量,以未来预测时段可利用的关联变量为提取条件,从已标注的反应器关联变量历史样本特征数据集中提取出包括目标变量在内的未来状况关联变量训练数据集。
具体的,确定表征反应器运行状况的、且具备细颗粒度时间序列的关键变量作为目标变量,例如,可将溶解氧作为目标变量。
所述未来预测时段可利用关联变量,指的是未来预测时段可获得数据的关联变量,例如,包括S1所述关联变量中的关联设备运行参数、序批周期设置参数、过程变量、输入流量;未来预测时段数据缺失的变量不包括在内。
根据未来预测时段可利用关联变量,从已标注的关联变量历史样本特征数据集中,提取出包括目标变量以及上述未来预测时段可利用关联变量在内的未来状况关联变量训练数据集。
S52、采用多个机器学习算法,利用未来状况关联变量训练数据集对每个算法训练并建立相应的未来状况预测模型,确定模型综合评分排列位于前列的多个算法模型,作为未来状况预测模型组。
采用多个机器学习算法同步进行分类预测,建立相应的未来状况预测模型组,所述机器学习算法的分类器,包括但不限于Random Forest Classifier,Extra TreesClassifier,CatBoost Classifier,Extreme Boosting Classifier,Gradient BoostingClassifier,Light Gradient Boosting Machine,Ada Boost Classifier,Decision TreeClassifier等。
S53、根据反应器当前状况分类等级预测结果与期望的反应器运行状况分类等级的偏离程度,生成未来预测时段的未来状况关联变量数据样本。
具体的,根据反应器当前状况分类等级预测结果与期望的反应器运行状况分类等级的偏离程度、关联变量历史样本数据集的统计学特征和时间序列特征、关联变量间的相关关系,生成关联变量未来状况的水平,进而生成包括目标变量和上述未来预测时段可利用关联变量在内的未来状况关联变量数据样本。
所述期望的反应器运行状况分类等级,是指以反应器运行状况精细化等级分类的分类等级期望值为中心的分类等级范围。
所述关联变量未来状况的水平,可以是与该关联变量当前状况下的水平相同的水平,也可以是与该关联变量当前状况下的水平不同的水平;可以是一个关联变量的未来状况水平与其当前状况水平不同,也可以是多个关联变量的未来状况水平与其当前状况水平不同。
所述未来状况关联变量数据样本,可以涉及到S1所述关联变量中的一个或多个关联变量的水平变化,比如,可以只涉及到某一个关联设备(进水设备或空气压缩机)运行参数的水平变化,也可以涉及到关联设备运行参数、输入流量、序批周期设置参数等多个方面的多个参数的水平变化。
S54、提取未来预测时段的未来状况关联变量数据样本的统计学特征和时间序列特征,建立未来预测时段的未来状况关联变量特征数据样本。
S55、调用未来状况预测模型组对未来预测时段的未来状况关联变量特征数据样本进行未来状况分类等级预测,取分类多数的标签作为最终的分类等级预测标签,取分类多数的各个算法预测值的加权平均值作为最终的加权分类等级预测值。
具体的,调用未来时段状况预测模型组,对未来预测时段的未来状况关联变量特征数据样本进行未来状况分类等级预测,模型组中的每一个算法分类器,都得到一个相应的分类预测结果,取分类多数的标签作为最终的分类等级预测标签,取分类多数的各个算法预测值的加权平均值作为最终的加权分类等级预测值。
S56、比较反应器未来状况分类等级预测结果与期望的反应器运行状况分类等级,若两者相符,则将上述未来状况关联变量数据样本以及基于其特征数据样本的未来状况分类等级预测结果确定为未来状况关联变量水平预案;若两者不相符,则返回到S53步骤,直到反应器未来状况分类等级预测结果与期望的反应器运行状况分类等级相符为止。
具体的,比较反应器未来状况分类等级预测结果与期望的反应器运行状况分类等级,若两者相符,则将上述未来状况关联变量数据样本以及基于其特征数据样本的未来状况分类等级预测结果确定为未来状况关联变量水平预案,未来状况预测结束;若两者不相符,则返回到S53步骤,重新生成新的未来状况关联变量数据样本,并调用未来状况预测模型组对新的未来状况关联变量特征数据样本进行未来状况分类等级预测,直到反应器未来状况分类等级预测结果与期望的反应器运行状况分类等级相符为止,最终的未来状况关联变量数据样本以及基于其特征数据样本的未来状况分类等级预测结果确定为未来状况关联变量水平预案。
本发明提供了一种生物反应器运行状况分级预报预测系统,如图5所示,所述生物反应器运行状况分级预报预测系统包括如下功能模块:
历史数据预处理模块10,用于获取反应器历史运行数据库中涉及到的反应器运行状况的关联变量数据,建立统一时间间隔颗粒度下的反应器关联变量历史样本数据集。所述历史数据预处理模块10还包括颗粒度转换单元11,用于将不同时间间隔颗粒度的关联变量数据,按照统一的时间间隔颗粒度进行数据转换,建立统一时间间隔颗粒度下的反应器历史样本数据集。
历史数据特征提取模块20,用于提取反应器关联变量历史样本数据集的统计学特征和时间序列特征,建立反应器关联变量历史样本特征数据集。
历史数据标注模块30,用于依据基于关联变量建立的反应器运行状况精细化等级分类,对反应器关联变量历史样本特征数据集进行数据标注。
实时分类预测模块40,用于从已标注的反应器关联变量历史样本特征数据集中提取出当前状况关联变量训练数据集,集合多个机器学习算法利用当前状况关联变量训练数据集训练并建立当前状况预测模型组;调用当前状况预测模型组,对当前时间间隔颗粒度下的实时关联变量特征数据样本进行当前状况分类等级预测。
如图5所示,所述实时分类预测模块40包括以下功能单元:
当前状况预测模型数据单元41,用于设定目标变量,以当前时间间隔颗粒度下可利用的关联变量为提取条件,从已标注的反应器关联变量历史样本特征数据集中提取出包括目标变量在内的当前状况关联变量训练数据集。
当前状况预测模型建模单元42,用于采用多个机器学习算法,利用当前状况关联变量训练数据集对每个算法训练并建立相应的当前状况预测模型,确定模型综合评分排列位于前列的多个算法模型,作为当前状况预测模型组。
实时数据特征提取单元43,用于提取当前时间间隔颗粒度下的实时关联变量数据样本的统计学特征和时间序列特征,建立当前时间间隔颗粒度下的实时关联变量特征数据样本。
当前状况分类预测单元44,用于调用当前状况预测模型组,对当前时间间隔颗粒度下的实时关联变量特征数据样本,进行当前状况分类等级预测,取分类多数的标签作为最终的分类等级预测标签,取分类多数的各个算法预测值的加权平均值作为最终的加权分类等级预测值。
如图6所示,所述一种生物反应器运行状况分级预报预测系统还包括:
未来状况分类预测模块50,用于从已标注的反应器关联变量历史样本特征数据集中提取出未来状况关联变量训练数据集,集合多个机器学习算法,利用未来状况关联变量训练数据集训练并建立未来状况预测模型组;基于参数水平调整生成未来预测时段的未来状况关联变量特征数据样本,调用未来状况预测模型组对未来状况关联变量特征数据样本进行未来状况分类等级预测、并且基于未来状况关联变量特征数据样本的未来状况分类等级预测结果符合期望的反应器运行状况分类等级。
所述未来状况分类预测模块50包括以下功能单元:
未来状况预测模型数据单元51,用于设定目标变量,以未来预测时段可利用的关联变量为提取条件,从已标注的反应器关联变量历史样本特征数据集中提取出包括目标变量在内的未来状况关联变量训练数据集;
未来状况预测模型建模单元52,用于采用多个机器学习算法,利用未来状况关联变量训练数据集对每个算法训练并建立相应的未来状况预测模型,确定模型综合评分排列位于前列的多个算法模型,作为未来状况预测模型组。
未来数据生成单元53,用于根据反应器当前状况分类等级预测结果与期望的反应器运行状况分类等级的偏离程度,生成未来预测时段的未来状况关联变量数据样本。
未来数据特征提取单元54,用于提取未来预测时段的未来状况关联变量数据样本的统计学特征和时间序列特征,建立未来预测时段的未来状况关联变量特征数据样本。
未来状况分类预测单元55,用于调用未来状况预测模型组对未来预测时段的未来状况关联变量特征数据样本进行未来状况分类等级预测,取分类多数的标签作为最终的分类等级预测标签,取分类多数的各个算法预测值的加权平均值作为最终的加权分类等级预测值。
未来状况预测结果判断与反馈单元56,用于比较反应器未来状况分类等级预测结果与期望的反应器运行状况分类等级,若两者相符,则将上述未来状况关联变量数据样本以及基于其特征数据样本的未来状况分类等级预测结果确定为未来状况关联变量水平预案,未来状况预测结束;若两者不相符,则返回到未来数据生成单元53,重新生成新的未来状况关联变量数据样本,再经过未来数据特征提取单元54和未来状况分类预测单元55,获得基于新的未来状况关联变量特征数据样本的未来状况分类等级预测结果,直到反应器未来状况分类等级预测结果与期望的反应器运行状况分类等级相符为止,最终的未来状况关联变量数据样本以及基于其特征数据样本的未来状况分类等级预测结果确定为未来状况关联变量水平预案。
本发明所述生物反应器运行状况分级预报预测方法及系统,依据基于关联变量建立的反应器运行状况精细化等级分类,以表征反应器运行状况且具备细颗粒度时间序列的关键变量作为目标变量,联合实时条件下可利用的关联变量,集合多种算法分类器,深度结合应用场景下的业务领域知识,采用“反应器当前状况预报--关联变量未来状况水平推算--关联变量未来状况水平下的反应器未来状况预测”工作流,实时预报反应器当前状况分类等级,提供未来状况关联变量水平预案以及未来状况关联变量水平预案下的未来状况分类等级预测;为增加反应器运行应变对策、提高反应器实时响应能力、提高反应器精细化运行水平提供重要的决策参考,并最终实现提供反应器运行实时应变对策、提高反应器的实时响应能力、保障反应器运行稳定性的目的。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述或记载的部分,可以参见其它实施例的相关描述。
以上所述,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 生物反应器运行状况分级预报预测方法及系统
- 基于时间序列的生物反应器运行状况分级预测方法及系统