一种口语训练自测自纠反馈系统及其应用方法
文献发布时间:2023-06-19 12:02:28
技术领域
本发明涉及听力学领域,特别涉及一种口语训练自测自纠反馈系统及其应用方法。
背景技术
听障人士是由于听力损失而导致听觉和口语交流出现障碍的一类人群。听障儿童属于听障人士的其中一个特殊群体。对于听障儿童面对听障除了需要验配助听器之外,还需要进行听觉口语训练,以获得听觉感知能力和语言能力。
目前,听障儿童的听觉口语训练需要在听障儿童教育中心接受教师与学生之间一对一的康复训练,以强化听觉口语训练促进儿童听觉语言发育发展。由于教师数量有限不可能全天候一对一教授,同时,一对一训练时教师需要不断纠正学生的发音,因此,目前的口语训练工作强度很大,事倍功半。
发明内容
本发明的目的是为了提供一种口语训练自测自纠反馈系统及其应用方法,该系统利用麦克风接收语音,利用摄像头捕捉面部表情和口型,让学习语言的孩子获得帮助,实时纠正口语发音,帮助听障儿童矫正听觉和口音,至少可以解决上述问题之一。
为实现上述目的,根据本发明的一个方面,提供了一种口语训练自测自纠反馈系统,包括声音输出装置以及与声音输出装置相配合的口语训练辅助装置,口语训练辅助装置包括弧形支架、主机、麦克风、摄像头和显示器,主机安装于弧形支架的底部,显示器安装于弧形支架的圆弧内,麦克风和摄像头安装于弧形支架且位于显示器的外周,麦克风和摄像头均指向显示器的正前方,麦克风、摄像头和显示器均与主机电性连接,主机与声音输出装置通信连接;
主机内存储有多组语音音频以及这些语音音频对应的文字和口型图像;
主机可将上述语音音频的音频信号传输至声音输出装置;
显示器可显示上述发射的语音音频对应的文字;
声音输出装置配置为使用者使用,使用者可根据听到的声音信号进行口述;
摄像头配置为捕捉使用者口述时的口型并反馈至主机;
麦克风配置为拾取使用者口述时的语音信号并反馈至主机;
主机可根据摄像头和麦克风反馈的信息与初始的语音音频和口型图像进行对比并进行相应的处理。
本发明提供了一种全新结构的口语训练自测自纠反馈系统,该系统的工作原理为:接受训练的儿童坐在弧形支架前,面对着显示器,佩戴好声音输出装置,打开主机进行语音音频的播放,通过蓝牙传输或者其他通信方式将该语音音频传入声音输出装置中,受训练的儿童根据所听到的声音信号跟随显示器显示的文字重复进行口述朗读,摄像头捕捉受训练的儿童的口型,麦克风拾取口述的语音,并反馈至主机与初始的口型图像和语音音频进行对比并作出相应的处理,如口型错误或者口述的语音错误则重复播放进行纠错,如完全正确则结束或者切换下一语音音频进行训练。
本发明的口语训练自测自纠反馈系统不仅结构简单且可以记录受训者的发音并纠错,然后重复播放,让受训者模仿朗读,这样进行听障儿童听觉口语训练就可以减轻教师一对一的负担,一个教师可同时教授多个学生,大大提高教学效率和教学质量,事半功倍。
在一些实施方式中,主机包括壳体、控制器和储存器,壳体安装于弧形支架的底部,控制器和储存器安装于壳体内部,储存器与控制器电性连接,麦克风、摄像头和显示器均与控制器电性连接,声音输出装置与控制器通信连接。
在一些实施方式中,主机还包括蓝牙发射器,蓝牙发射器安装于壳体内且与控制器电性连接,声音输出装置包括蓝牙接收器,蓝牙接收器与蓝牙发射器相配合。由此,蓝牙连接可实现口语训练辅助装置和声音输出装置的分体设置,使用方便。
在一些实施方式中,声音输出装置为助听器。由此,助听器具有一定的改善听觉的功能,适用于听觉损失较为严重的受训者。
在一些实施方式中,声音输出装置为蓝牙耳机。由此,蓝牙耳机具有方便携带、时尚美观等优点,适用于听觉轻度损伤的受训者。
在一些实施方式中,弧形支架由上边框、下边框和左右两个侧边框围合形成,上边框和下边框为圆弧形,麦克风和摄像头均为多个,上边框、下边框和左右两个侧边框上各设置有至少一个麦克风和至少一个摄像头,所有麦克风和摄像头均指向弧形支架的圆弧中心所在的中心线。由此,使用时,所有麦克风和摄像头环绕于使用者头部四周,且均指向使用者嘴巴部位,可对声音和口型进行精确的识别,提高精准度。
根据本发明的另一个方面,还提供了一种口语训练自测自纠反馈系统的应用方法,包括以下步骤:
S1、匹配连接:使用者将声音输出装置佩戴于左右耳,然后将声音输出装置与口语训练辅助装置蓝牙通信连接;
S2、播放初始语音音频:通过主机开启口语训练辅助装置并播放初始的语音音频,使用者通过声音输出装置可听到该语音音频,通过显示器可看到该语音音频对应的文字;
S3、使用者口述:使用者可根据听到的声音信号进行口述;
S4、记录反馈:摄像头捕捉使用者口述时的口型并反馈至主机,麦克风拾取使用者口述时的语音信号并反馈至主机;
S5、比对处理:主机可根据摄像头和麦克风反馈的信息与初始的语音音频和口型图像进行对比并进行相应的处理。
由此,本应用方法为上述口语训练自测自纠反馈系统的使用方法,整个使用过程简单,方便快捷的实现口语训练,即使师资缺乏的情况下也能轻松应对。
在一些实施方式中,在步骤S6中,相应的处理包括:
S51、当使用者口述时的语音信号和/或口型图像与初始的语音音频和/或口型图像不一致时,所述主机控制声音输出装置重复播放该语音音频;
S52、当使用者口述时的语音信号和口型图像与初始的语音音频和口型图像完全一致时,所述主机控制声音输出装置播放另一语音音频或者直接结束。
本发明的有益效果:
本发明的口语训练自测自纠反馈系统的工作原理为:接受训练的儿童坐在弧形支架前,面对着显示器,佩戴好声音输出装置,打开主机进行语音音频的播放,通过蓝牙传输或者其他通信方式将该语音音频传入声音输出装置中,受训练的儿童根据所听到的声音信号跟随显示器显示的文字重复进行口述朗读,摄像头捕捉受训练的儿童的口型,麦克风拾取口述的语音,并反馈至主机与初始的口型图像和语音音频进行对比并作出相应的处理,如口型错误或者口述的语音错误则重复播放进行纠错,如完全正确则结束或者切换下一语音音频进行训练。
本发明的口语训练自测自纠反馈系统不仅结构简单且可以记录受训者的发音并纠错,然后重复播放,让受训者模仿朗读,这样进行听障儿童听觉口语训练就可以减轻教师一对一的负担,而一个教师可以同时教授多个学生,大大提高教学效率和教学质量,事半功倍。
附图说明
图1为本发明的实施例1的口语训练自测自纠反馈系统的简化立体结构示意图;
图2为图1所示的口语训练自测自纠反馈系统的正视结构示意图;
图3为图1所示的口语训练自测自纠反馈系统的简化控制框图;
图4为本发明的实施例1的口语训练自测自纠反馈系统的应用方法的流程示意图;
图5为本发明的实施例2的口语训练自测自纠反馈系统的简化控制框图。
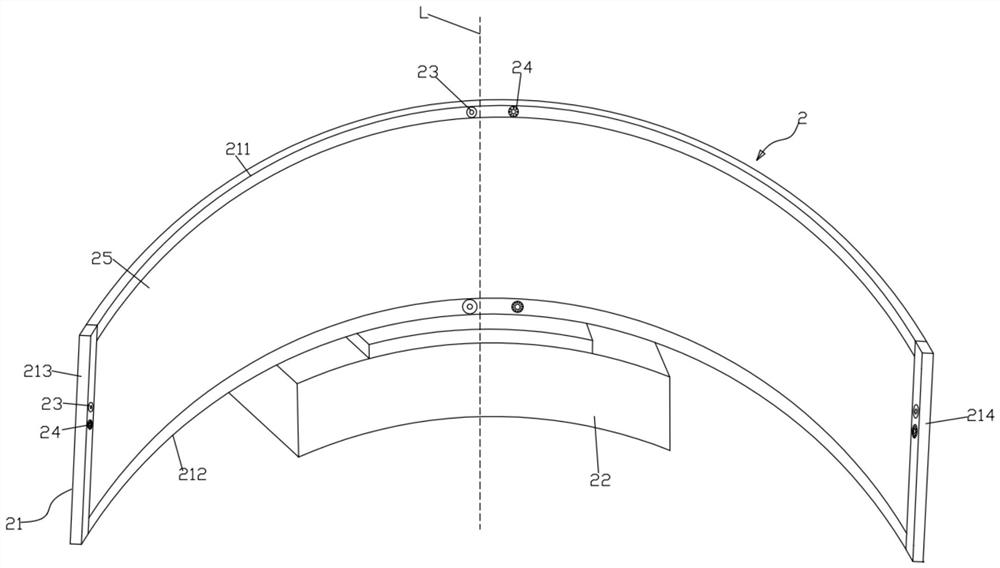
图1~5中的附图标记:1-声音输出装置;2-口语训练辅助装置;21-弧形支架;22-主机;23-麦克风;24-摄像头;25-显示器;211-上边框;212-下边框;213-左侧边框;214-右侧边框;221-壳体;222-控制器;223-储存器;224-蓝牙发射;225-电源。
具体实施方式
下面结合具体实施例和附图对本发明作进一步详细的说明。
实施例1
图1~4示意性地显示了一种实施方式的一种口语训练自测自纠反馈系统。
如图1~4所示,该口语训练自测自纠反馈系统包括声音输出装置1以及与声音输出装置1相配合的口语训练辅助装置2。
口语训练辅助装置2包括弧形支架21、主机22、麦克风23、摄像头24和显示器25。主机22安装于弧形支架21的底部,显示器25安装于弧形支架21的圆弧内。麦克风23和摄像头24安装于弧形支架21且位于显示器25的外周。麦克风23和摄像头24均指向显示器25的正前方。麦克风23、摄像头24和显示器25均与主机22电性连接,主机22与声音输出装置1通信连接。
主机22包括壳体221、控制器222和储存器223,壳体221安装于弧形支架21的底部,控制器222和储存器223安装于壳体221内部,储存器223与控制器222电性连接,麦克风23、摄像头24和显示器25均与控制器222电性连接,声音输出装置1与控制器222通信连接;
储存器223用于存储语音音频以及这些语音音频对应的文字和口型图像;
主机22用于将上述语音音频的音频信号传输至声音输出装置1;
声音输出装置1用于播放上述音频信号;
显示器25用于显示正在播放的语音音频对应的文字;
声音输出装置1配置为使用者使用,使用者可根据听到的声音信号进行口述;
摄像头24用于捕捉使用者口述时的口型并反馈至主机22;
麦克风23用于拾取使用者口述时的语音信号并反馈至主机22;
主机22可根据摄像头24和麦克风23反馈的信息与初始的语音音频和/或口型图像进行对比并进行相应的处理。
本实施方式的控制器222可以为CPU或者单片机等常用控制件。储存器223中可以存储不同级别的语音音频、文字以及波形和图形,文字形式可以包括单音字母、单字、双音节词、短句、段落等等标准数据。
主机22还包括蓝牙发射器224,蓝牙发射器224安装于壳体221内且与控制器222电性连接,声音输出装置1包括蓝牙接收器,蓝牙接收器与蓝牙发射器224相配合。本实施方式的蓝牙发射器224和蓝牙发射器224均为市购产品。由此,蓝牙连接可实现口语训练辅助装置2和声音输出装置1的分体设置,使用方便。
主机22还包括有电源225,电源225设置于壳体221内且与控制器222、储存器223、麦克风23、摄像头24和显示器25均电性连接。由此,电源225用于给用电部件供电。本实施方式的电源225可以为蓄电池,使用方便。
本实施方式的主机22的壳体221上可以设置操作按键或者数据传输端口,以实现相应的功能。
如图1和图2所示,本实施方式的弧形支架21由上边框211、下边框212、左侧边框213和右侧边框214围合形成。上边框和下边框为圆弧形,左、右两个侧边框213、214为直条形。麦克风23和摄像头24均为多个,上边框211、下边框212和左右两个侧边框213、214上各设置有至少一个麦克风23和至少一个摄像头24,所有麦克风23和摄像头24均指向弧形支架21的圆弧中心所在的中心线L。使用时,所有麦克风23和摄像头24环绕于使用者头部四周,且均指向使用者嘴巴部位。由此,可对声音和口型进行精确的识别,提高精准度。
使用时,可以让受试者嘴巴对准显示器25的中心,像照镜子一样的进行受训。此种状态下,所有麦克风23和摄像头24环绕于头部外周且均对准嘴巴所在位置,便于声音的精准摄取以及口型的精准捕捉,提高精准度。
本实施方式的声音输出装置1为助听器。由此,助听器具有一定的改善听觉的功能,适用于听觉损失较为严重的受训者。
本实施方式的显示器25可以为柔性液晶显示器25。由此,柔性显示器25是由柔软的材料制成,可变形可弯曲的显示装置。使用了PHOLED磷光性OLED技术,具有低功耗,直接可视柔性面板,由柔软的材料制成,可变型可弯曲的显示装置。
本发明的口语训练自测自纠反馈系统的工作原理为:接受训练的儿童坐在弧形支架21前,面对着显示器25,佩戴好声音输出装置1,打开主机22进行语音音频的播放,通过蓝牙传输或者其他通信方式将该语音音频传入声音输出装置1中,受训练的儿童根据所听到的声音信号跟随显示器25显示的文字重复进行口述朗读,摄像头24捕捉受训练的儿童的口型,麦克风23拾取口述的语音,并反馈至控制器222与储存器223内储存的初始的口型图像和语音音频进行对比,控制器222根据对比结果作出相应的处理,如口型错误或者口述的语音的其中一个错误或者两个均错误则重复播放这一语音音频进行纠错,如完全正确则结束或者切换下一语音音频进行训练。
本发明提供了一种全新结构的口语训练自测自纠反馈系统,不仅结构简单且可以记录受训者的发音并纠错,然后重复播放,让受训者模仿朗读,这样进行听障儿童听觉口语训练就可以减轻教师一对一的负担,而一个教师可以同时教授多个学生,大大提高教学效率和教学质量,事半功倍。
图4示意性地显示了本实施例的口语训练自测自纠反馈系统的应用方法。
如图4所示,该口语训练自测自纠反馈系统的应用包括以下步骤:
S1、匹配连接:使用者将助听器佩戴于左右耳,然后将助听器与口语训练辅助装置2蓝牙无线连接;
S2、播放初始语音音频:通过主机22开启口语训练辅助装置2并播放初始的语音音频,使用者通过声音输出装置1可听到该语音音频,通过显示器25可看到该语音音频对应的文字;
S3、使用者口述:使用者可根据听到的声音信号进行口述;
S4、记录反馈:摄像头24捕捉使用者口述时的口型并反馈至主机22,麦克风23拾取使用者口述时的语音信号并反馈至主机22;
S6、比对处理:主机22可根据摄像头24和麦克风23反馈的信息与初始的语音音频和口型图像进行对比并进行相应的处理。
在本步骤中,相应的处理包括:
S61、当使用者口述时的语音信号和/或口型图像与初始的语音音频和/或口型图像不一致时,主机22控制声音输出装置1重复播放该语音音频;
S62、当使用者口述时的语音信号和口型图像与初始的语音音频和口型图像完全一致时,主机22控制声音输出装置1播放另一语音音频或者直接结束。
由此,本应用方法为上述口语训练自测自纠反馈系统的使用方法,整个使用过程简单,方便快捷的实现口语训练,即使师资缺乏的情况下也能轻松应对。
实施例2
图5示意性地显示了另一种实施方式的口语训练自测自纠反馈系统。
如图5所示,本实施方式的口语训练自测自纠反馈系统与实施例1的结构基本相同,其区别在于:本实施方式的声音输出装置1为蓝牙耳机。
由此,蓝牙耳机具有方便携带、时尚美观等优点,适用于听觉轻度损伤的受训者。
以上所述的仅是本发明的一些实施方式。对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 一种口语训练自测自纠反馈系统及其应用方法
- 一种星载高可靠自测试单脉冲雷达系统及其应用方法