一种数据扩充及分类的方法、系统
文献发布时间:2023-06-19 12:10:19
技术领域
本发明涉及数据扩充及分类技术领域,具体涉及一种数据扩充及分类的方法、系统。
背景技术
在生产过程中,受生产环境和人为以及机器误差等外在因素的影响,焊接产品并不能做到百分之百的无误。据调查显示,有很多产品由于未能及时检测到缺陷或缺陷尺寸检测不准而造成产品质量存在很大的安全隐患,从而导致重大事故的发生。所以需要对产品先进行检测和评定后再投放到市场中使用,以避免行业损失。目前对焊缝缺陷的检测识别,大多数是由经验丰富的人通过人眼进行观察判断,这种人工判别的检测方法具有耗费时间、效率低、主观性强等一系列问题。且在数据的采集上,由于焊缝缺陷没有公开的数据集且采集难度较大,数据不够丰富。
深度学习技术的出现为解决很多问题提供了一个新的思路和技术手段。对于深度学习技术需要依靠大量丰富的数据作为支撑,随着计算机视觉技术的,数据扩充算法模型以DCGAN模型为代表,在现代工业中应用广泛,采用DCGAN模型实现焊缝数据扩充已成为基本方式。在DCGAN模型中,生成器会自动地学习包含未标记数据的分布,通过两种网络之间的博弈,进而得出与真实样本无法区分的生成器,判别器用于确定数据的来源。但是目前DCGAN模型不稳定且所生成的图片存在瑕疵,并不是所有的生成图像都是成功的,部分图片没有意义并且缺乏多样性。
图像识别技术是利用计算机对图像进行分析处理,以达到识别目标的目的。在这个过程中,需要通过特征提取和选择将图像中感兴趣的信息提取出来,进行下一步的归类划分。由于特征提取和特征选择对计算机下一步的判断和处理有很大的影响,因此这一技术在图像处理的任务中起决定性作用。而对于深度学习中的分类模型以CNN模型为代表,CNN模型是常用的分类网络模型。该模型可以实现端到端的分类任务,其基本思想是通过模型中的滤波算子提取输入网络中的特征,然后输送到模型末端的分类器中,完成分类任务。但是传统的CNN模型有不同的结构,对于焊缝数据分类能力也不同,而且深层次网络对于特征不复杂的数据并没有很好的作用还会造成模型复杂化。
发明内容
DCGAN模型不稳定且所生成的图片存在瑕疵,并不是所有的生成图像都是成功的,部分图片没有意义并且缺乏多样性以及传统的CNN模型有不同的结构,对于焊缝数据分类能力也不同,而且深层次网络对于特征不复杂的数据并没有很好的作用还会造成模型复杂化的问题,本发明提供一种数据扩充及分类的方法、系统。
本发明的是技术方案是:
一方面,本发明技术方案提供一种数据扩充及分类的方法,包括如下步骤:
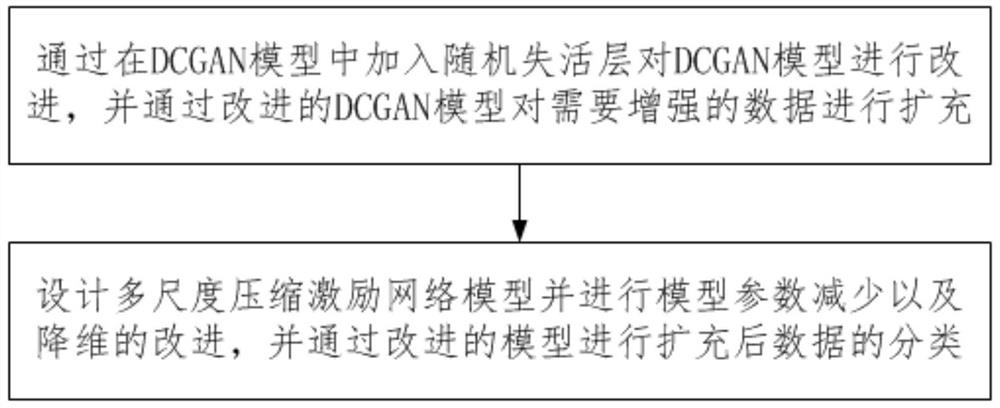
通过在DCGAN模型中加入随机失活层对DCGAN模型进行改进,并通过改进的DCGAN模型对需要增强的数据进行扩充;
设计多尺度压缩激励网络模型并进行模型参数减少以及降维的改进,并通过改进的模型进行扩充后数据的分类。
进一步的,所述的通过在DCGAN模型中加入随机失活层对DCGAN模型进行改进,并通过改进的DCGAN模型对需要增强的数据进行扩充的步骤中,通过在DCGAN模型中加入随机失活层对DCGAN模型进行改进的步骤包括:
在DCGAN模型的判别网络中加入随机失活层;
设置随机失活层的失活比例为非固定失活比例;
将DCGAN模型中损失函数设置为最小二乘损失函数。
减少了过度拟合并显著提高了模型的通用性,缩减每轮迭代的时间从而加快训练速度。最小二乘损失函数使生成器的参数会不断的更新,从而使得生成的焊缝缺陷数据更加真实,模型训练更加稳定。
进一步的,在DCGAN模型的判别网络中加入随机失活层的步骤包括:
随机失活层分别加在DCGAN模型的判别网络的每个卷积层之间。
进一步的,设置随机失活层的失活比例为非固定失活比例中,非固定失活比例包括:
按照抛弃神经元数量递增的模式抛弃网络中的神经元。根据每一次循环次数为变量,随机的抛弃一些神经元,该方式可以使得网络采用不同的神经元学进行学习,并保证网络的稳定性。
进一步的,所述的通过在DCGAN模型中加入随机失活层对DCGAN模型进行改进,并通过改进的DCGAN模型进行数据扩充的步骤之前还包括:
对所需数据进行预处理操作,将数据分为要进行增强的数据和不需要进行增强的数据。针对图像数据存在对比度不均匀、细节不明显等问题,影响图片的质量,从而影响人们对图片的判断的问题。
进一步的,所述的设计多尺度压缩激励网络模型并进行模型参数减少以及降维的改进,并通过改进的模型进行扩充后数据的分类的步骤包括:
将预处理后的不需要增强的数据以及扩充后的数据生成新的数据集;
设计多尺度压缩激励网络模型并进行模型参数减少以及降维的改进,并通过改进的模型将生成的新的数据集内的数据进行分类。
进一步的,所述的设计多尺度压缩激励网络模型并进行模型参数减少以及降维的改进,并通过改进的模型将生成的新的数据集内的数据进行分类的步骤包括:
以串联卷积核为基础网络与多尺度压缩激励模块相结合,采用全局平均池化构成多尺度压缩激励网络模型;
采用生成的多尺度压缩激励网络模型将生成的新的数据集内的数据进行分类。采用全局平均池化,优势在于可以有效的减少模型的参数,串联卷积核为基础网络可以进行降维。
进一步的,所述的以串联卷积核为基础网络与多尺度压缩激励模块相结合的步骤包括:
采用四组两两串联的3x3卷积模块与多尺度压缩激励模块相结合。
另一方面,本发明技术方案还提供一种数据扩充及分类的系统,包括数据扩充模块以及与数据扩充模块连接的数据分类模块;
数据扩充模块,配置用于在DCGAN模型中加入随机失活层对DCGAN模型进行改进,并通过改进的DCGAN模型对需要增强的数据进行扩充;
数据分类模块,用于配置设计多尺度压缩激励网络模型并进行模型参数减少以及降维的改进,并通过改进的模型进行扩充后数据的分类。
进一步的,该系统还包括数据预处理模块、数据集生成模块;
数据预处理模块,配置用于对所需数据进行预处理操作,将数据分为要进行增强的数据和不需要进行增强的数据;
数据集生成模块,配置用于将预处理后的不需要增强的数据以及扩充后的数据生成新的数据集;
数据分类模块,配置具体用于设计多尺度压缩激励网络模型并进行模型参数减少以及降维的改进,并通过改进的模型将生成的新的数据集内的数据进行分类。
进一步的,数据扩充模块包括网络设置单元、失活比例设置单元和损失函数设置单元;
网络设置单元,配置用于在DCGAN模型的判别网络中加入随机失活层;
失活比例设置单元,配置用于设置随机失活层的失活比例为非固定失活比例;
损失函数设置单元,配置用于将DCGAN模型中损失函数设置为最小二乘损失函数。
从以上技术方案可以看出,本发明具有以下优点:基于改进DCGAN模型,从而使模型更稳定,生成图片质量更好,为分类提供丰富数据集。基于改进从而降低计算量,提高分类准确率。此外,本发明设计原理可靠,结构简单,具有非常广泛的应用前景。
此外,本发明设计原理可靠,结构简单,具有非常广泛的应用前景。
由此可见,本发明与现有技术相比,具有突出的实质性特点和显著地进步,其实施的有益效果也是显而易见的。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明一个实施例的方法的示意性流程图。
图2是本发明另一个实施例的方法的示意性流程图。
图3是本发明一个改进的生成模型中的判别网络。
图4是本发明实施例的多尺度压缩激励模块图。
具体实施方式
为了使本技术领域的人员更好地理解本发明中的技术方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
如图1所示,本发明技术方案提供一种数据扩充及分类的方法,包括如下步骤:
步骤1:通过在DCGAN模型中加入随机失活层对DCGAN模型进行改进,并通过改进的DCGAN模型对需要增强的数据进行扩充;
步骤2:设计多尺度压缩激励网络模型并进行模型参数减少以及降维的改进,并通过改进的模型进行扩充后数据的分类。
在有些实施例中,所述的通过在DCGAN模型中加入随机失活层对DCGAN模型进行改进,并通过改进的DCGAN模型对需要增强的数据进行扩充的步骤中,通过在DCGAN模型中加入随机失活层对DCGAN模型进行改进的步骤包括:
在DCGAN模型的判别网络中加入随机失活层;
设置随机失活层的失活比例为非固定失活比例;
将DCGAN模型中损失函数设置为最小二乘损失函数。
需要说明的是,随机失活层添加到每个卷积层之间,每个卷积之后都会产生特征图。改进后,舍弃了原先的固定比例抛弃神经元的方法,取而代之的是按照抛弃神经元数量递增的模式,随机的抛弃网络中的一些神经元,在每一个批次训练的过程中,由于神经元的个数都是不同的,因此进行训练的网络也不相同,该方式的优势在于能够保证模型稳定的前提下最大限度的传输有效的神经元。采用不同的神经元学习相同的“概念”,减少了过度拟合并显著提高了模型的通用性,缩减每轮迭代的时间从而加快训练速度。其中,抛弃的神经元比例表达式如下所示:
式中f(x)为随机抛弃比例,x为迭代轮次(epoch)且x>1,k为初始的抛弃比例,0 将交叉熵损失函数舍弃,代替为最小二乘损失函数。交叉熵损失函数会造成当生成器并没有学习到焊缝缺陷真实数据的空间信息时,判别器误认为生成的样本为真实样本,生成器不会再进行学习,导致生成的焊缝缺陷数据实际上质量很差。而最小二乘损失函数对于生成器参数更新的依据除了判别器所判定结果外,还会以焊缝数据到决策边界的远近进行比对分析。将那些距离决策边界较远的样本向决策边界移动。这种做法的优势在于生成器的参数会不断的更新,从而使得生成的焊缝缺陷数据更加真实。两种损失函数的饱和点也不同。交叉熵损失函数的饱和点在x值为2之后都会存在,其斜率为0。最小二乘损失函数的饱和点只会在x值为1的时候才会发生,两者相比使用最小二乘损失函数模型训练会更加稳定。 如图2所示,在有些实施例中,所述的通过在DCGAN模型中加入随机失活层对DCGAN模型进行改进,并通过改进的DCGAN模型进行数据扩充的步骤之前还包括: 对所需数据进行预处理操作,将数据分为要进行增强的数据和不需要进行增强的数据。针对图像数据存在对比度不均匀、细节不明显等问题,影响图片的质量,从而影响人们对图片的判断的问题。 在有些实施例中,所述的设计多尺度压缩激励网络模型并进行模型参数减少以及降维的改进,并通过改进的模型进行扩充后数据的分类的步骤包括: 将预处理后的不需要增强的数据以及扩充后的数据生成新的数据集; 设计多尺度压缩激励网络模型并进行模型参数减少以及降维的改进,并通过改进的模型将生成的新的数据集内的数据进行分类。 以串联卷积核为基础网络与多尺度压缩激励模块相结合,采用全局平均池化构成多尺度压缩激励网络模型; 采用生成的多尺度压缩激励网络模型将生成的新的数据集内的数据进行分类。采用全局平均池化,优势在于可以有效的减少模型的参数,串联卷积核为基础网络可以进行降维。 根据每一次循环次数为变量,随机的抛弃一些神经元,该方式可以使得网络采用不同的神经元学进行学习,并保证网络的稳定性。且最小二乘损失函数无论从决策边界还是饱和点都优于原先的交叉熵损失函数。 在有些实施例中,所述的以串联卷积核为基础网络与多尺度压缩激励模块相结合的步骤包括: 采用四组两两串联的3x3卷积模块与多尺度压缩激励模块相结合。利用其3x3串联卷积的优势,将四组两两串联的卷积模块与多尺度压缩激励模块相结合。四组串联卷积模块作为基础学习网络,用于从低到高的学习图像的特征,每组卷积模块后使用最大池化层对前面卷积层进行降维操作。将Inception模块与压缩激励模块(SE block)相结合,形成SI模块。在SI模块中通过执行多尺度卷积操作,扩大在焊缝缺陷特征图上获取特征的能力,之后重新校准通道维度。在网络的最后未使用全连接操作而是使用全局平均池化操作减少模型的参数,同时加快计算速度。 数据集包含裂纹、未熔合、未焊透、条形、圆形、正常的焊缝缺陷图片。利用仿真,对比相同数据集下不同模型后的分类结果。过程如下: (一)数据预处理 在实际生产应用中获取图像时,由于实时图像采集和传输过程中,存在不可避免的各种干扰因素。例如电子设备发热,被测钢管壁厚度不均等因素影响,原始图像通常包含噪声。噪声使焊缝缺陷图像存在对比度不均匀、细节不明显等问题,影响图片的质量,从而影响人们对图片的判断。为克服这些问题采用以直方图均衡化和中值滤波去噪对焊缝缺陷数据进行处理。 (二)数据集扩充 现在技术中心没有公开大规模焊缝缺陷X影像数据集,在获取到原先数据集的基础上,采用生成模型对数据进行扩充,原先的数据集一共有2454张,包括裂纹、未熔合、未焊透、条形、圆形、正常的焊缝缺陷图片六类。 (三)扩充模型改进 在DCGAN模型的判别器的每个卷积层之间加入Dropout层(随机失活层),使得模型在训练过程中可以随机的抛一些神经元,加快模型训练时间。改进后的网络模型如图3所示。 对所加入的Dropout层进行改进,对Dropout层随机抛弃比例不采用固定的随机抛弃比例而是采用基于迭代次数为变量的抛弃神经元递增的模式,该方式由于在每一轮次的神经元个数不同,因此网络训练也是不同的,可以使得模型更加稳定。 损失函数方面使用最小二乘损失函数代替交叉熵损失函数,最小二乘损失函数无论从决策边界还是饱和点都具有优势。 (四)分类模型设计 采用4组两两串联的3x3卷积模块学习数据的基本特征,两两串联的卷积模块七感受野等同于一个5x5的卷积模块,但是所采用的参数却少的多,由此可见在基于相同感受野情况下,选用两两串联的3x3卷积模块有效的减少了模型的参数。 设计了多尺度压缩激励模块,如图4所示,在模块的前半部分,通过使用多个1x1卷积模块,在提取焊缝缺陷数据丰富特征的同时还可以进行降维。之后还使用多个尺度卷积再聚合的方式来提高焊缝缺陷图像的特征提取能力。该操作的作用包括:从不同尺度提取特征;稀疏矩阵分解成密集矩阵可以加快收敛速度。在模块中通过后半部分的压缩激励操作对一系列卷积操作后产生的特征图进行特征重标定,将有用的特征赋予较大的权值,将无用的特征赋予较小的权值。通过模块中的多尺度特征融合以及压缩激励操作,对基础卷积操作所提取的焊缝缺陷特征进一步处理,利用多尺度卷积,提高对焊缝缺陷特征的提取能力。后续通过压缩激励操作对所提取的特征图进行特征重标定,使得有用的特征权值变大,有效提高焊缝缺陷分类的准确率。 采用全局平均池化代替全连接层,优势在于可以有效的减少模型的参数。全局平均池化可以计算上一层中每个特征图的平均输出,之所以采用该操作而不是全连接层,主要是为了减少最终分类的参数。 具体步骤如下: 步骤1:对所需数据进行一个预处理操作; 步骤2:通过在DCGAN网络模型的判别器中加入改进的Dropout层,以及采用最小二成损失函数代替交叉熵损失函数; 步骤3:通过改进的DCGAN模型对焊缝数据进行数据扩充; 步骤4:设计多尺度压缩激励网络模型,以串联卷积核为基础网络,加入多尺度压缩激励模块以及采用全局平均池化代替全连接层; 步骤5:通过设计的多尺度压缩激励网络对焊缝数据进行分类。 另外,本发明实施例还提供一种数据扩充及分类的系统,包括数据扩充模块以及与数据扩充模块连接的数据分类模块; 数据扩充模块,配置用于在DCGAN模型中加入随机失活层对DCGAN模型进行改进,并通过改进的DCGAN模型对需要增强的数据进行扩充; 数据分类模块,用于配置设计多尺度压缩激励网络模型并进行模型参数减少以及降维的改进,并通过改进的模型进行扩充后数据的分类。 在有些实施例中,该系统还包括数据预处理模块、数据集生成模块; 数据预处理模块,配置用于对所需数据进行预处理操作,将数据分为要进行增强的数据和不需要进行增强的数据; 数据集生成模块,配置用于将预处理后的不需要增强的数据以及扩充后的数据生成新的数据集; 数据分类模块,配置具体用于设计多尺度压缩激励网络模型并进行模型参数减少以及降维的改进,并通过改进的模型将生成的新的数据集内的数据进行分类。 进一步需要说明的是,数据扩充模块包括网络设置单元、失活比例设置单元和损失函数设置单元; 网络设置单元,配置用于在DCGAN模型的判别网络中加入随机失活层; 失活比例设置单元,配置用于设置随机失活层的失活比例为非固定失活比例; 损失函数设置单元,配置用于将DCGAN模型中损失函数设置为最小二乘损失函数。 尽管通过参考附图并结合优选实施例的方式对本发明进行了详细描述,但本发明并不限于此。在不脱离本发明的精神和实质的前提下,本领域普通技术人员可以对本发明的实施例进行各种等效的修改或替换,而这些修改或替换都应在本发明的涵盖范围内/任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 一种数据扩充及分类的方法、系统
- 一种数据集扩充和阴影图像分类辅助的阴影检测方法