一种三维实时人体姿态重建方法
文献发布时间:2023-06-19 12:13:22
技术领域
本发明涉及计算机的技术领域,特别是涉及一种三维实时人体姿态重建方法。
背景技术
人体运动的捕捉和跟踪是计算机视觉和图形学中的热点问题。它主要研究如何从输入深度数据流中快速重建准确的人体几何模型和人体运动序列。已有的人体姿态重建方法可大致分为基于模型的方法与非基于模型的方法两大类。
非基于模型的方法:该类方法通常在不考虑人体先验信息的情况下,通过特征点检测方法识别图像中的人体姿态。缺点是忽略了前一时刻对当前时刻人体运动姿态的影响,即忽略了人体运动是空间和时间变化的连续过程的本质。基于模型的方法(或称为数据驱动的方法)
基于模型的方法需要预先扫描的三维模型,并且预先构建运动姿态先验。三维扫描仪的成本很高,处理扫描的数据非常耗时,并且存在错误累积与无法跟踪长时间运动的问题。典型的方法包括:数据驱动方法通过从捕获的运动数据中获取准确的人体姿态重建结果。比如:已有方法通过从深度图像中检测特征点来估计每个图像中的人体姿态,由于数据库中的模型是标准的三维人体模型,因此当参与者体型与数据库中的标准模型有很大差异时,该方法不能总是获得合理的结果。再比如:已有方法基于多深度相机捕获的三维点云从数据库中检索获得最佳匹配的三维人类姿态。再比如:已有技术基于物理学运动重建算法,将来自3个深度相机输入的深度数据、可穿戴压力传感器的足部压力数据以及详细的全身几何形状相结合,离线重构出完整的人体全身运动过程。再比如:还有技术通过结合基于贝叶斯估计的四肢语义特征检测和逆向运动学优化计算并结合诸如避免关节极限的约束,成功地重建出了人体运动过程,但由于其假设图像中的人的头部必须始终位于腰部以上,因此该方法无法处理不满足此条件的运动姿态。再比如:另有技术通过求解最大后验概率算法解决点云匹配问题,快速、自动地使用单目深度相机捕获全身运动数据。
可以通过数据驱动方法同时重建出人体几何模型与运动姿态,但该方法要求事先通过人工方法确定非刚性模型和目标三维点云之间精确的点对应,才能实现大尺度动作变化时的精确三维人体姿态估计,因此无法满足实际需求。
发明内容
为解决上述技术问题,本发明提供一种精细个体化人体几何模型的低成本、实时在线准确重建精细的个体化人体几何模型,并且基于该几何模型实时在线准确捕获不同人的多种类型三维人体运动姿态序列的三维实时人体姿态重建方法。
本发明的一种三维实时人体姿态重建方法,包括:
S1,使用4台深度相机拍摄深度图像,深度图像的像素点表示为x,深度图像的像素点对应的深度值和三维点分别为d(x)和p;
S2,4台深度相机通过PCI数据接口连接计算机,计算机同步驱动4台深度相机完成数据采集工作;
S3,4台深度相机分别位于正方形的人体运动捕获场景的4个边角,其中美相邻2台深度相机基于棋盘格和立体视觉的标定方法;
S4,对4台深度相机捕获的深度图像的原始三维点进行预处理去噪;
S5,从运动捕获开源数据库中挑选运动序列并建立三维人体姿态数据库Q,并且在建立三维人体姿态数据库Q中进行运动重定向技术的骨架归一化;
S6,使用4台深度相机拍摄真实人体的A姿态图像,并且通过基于骨架驱动的方法对真实人体的A姿态图像的人体几何模型做姿态维度的变形,然后将精细个体化人体几何模型自动估计问题形式通过化为非线性优化问题以进行迭代优化求解;
S7,通过三维姿态数据库与精细个体化人体几何模型的多目深度相机进行三维人体运动姿态跟踪。
本发明的一种三维实时人体姿态重建方法,还包括:
同步捕获相邻2台的深度相机的多组包含棋盘格的红外图像对,使用角点检测算法从捕获的红外图像中提取棋盘格角点集合,基于立体视觉算法估计出该2台深度相机红外摄像头的内、外参数矩阵;
以其中1台深度相机所在坐标系为世界坐标系,其光心为世界坐标原点,将其余3台深度相机基于标定获得的外参数矩阵对齐到世界坐标系;
基于三维平面拟合技术估计出场景中的地板平面,基于三维圆柱体包围盒自动减除背景像素点,该包围盒的底平面平行于估计出的地板平面,底面中心点为采集场景中心点,以剩下的前景三维深度点云分布中心点为起始点,通过设置合适的三维深度点间距离阈值,求出三维空间中最大的连通区,完成三维深度点云去噪。
本发明的一种三维实时人体姿态重建方法,所述S6中,
人体几何模型用模型网格顶点集合的长向量s
其中,β是人体几何模型的低维参数向量,P
将人体骨架各关节中心J
其中,V
通过定义空间包围盒方式获得人体内嵌骨架关节中心各关节中心的近邻人体几何模型顶点集合;
顶点权重w的求解根据人体几何模板模型及其内嵌人体骨架,估计几何模型顶点,将其形式化为带约束的线性最小二乘问题,表示为:
根据公式(2),当给定个体化人体几何模型顶点坐标和顶点权重w
通过三维深度点云P,人体几何模型数据库S和人体姿态数据库Q,求个体化人体几何模型,个体化人体几何模型的参数化为人体姿态参数向量
其中,E
其中,“点到点”距离,指的是人体几何模型顶点v
其中,“点到面”距离,指的是人体几何模型顶点v
为保证人体几何模型重建结果的合理性,引入了人体骨骼长度对称能量项,表示为:
E
其中,{(M,N)}是对称骨骼段集合,l
设全局空间中的人体几何模型数据库构成多维高斯分布,则人体几何模型先验约束项最大化下述条件概率,表示为:
其中,Λ
其中,β是待求的人体几何模型的低维参数向量,P
设人体姿态数据库Q={q
其中,w是人体姿态的低维参数向量,P
设全局空间中的人体姿态数据构成多维高斯分布,则人体姿态先验约束项最大化下述条件概率,表示为:
其中,q是待求的人体姿态向量,δ
公式(11)中使用能量最小化形式,表示为:
结合公式(5)、公式(6)、公式(7)、公式(9)和公式(12),将公式(4)表示如下:
其中,
本发明的一种三维实时人体姿态重建方法,所述S7中,
通过当前帧捕获的三维深度点云P、精细个体化人体几何模型S
其中,G
“点到点”距离,指的是姿态q驱动的人体几何模型S
“点到面”距离,指的是姿态q驱动的人体几何模型S
根据前2帧重建的三维人体姿态
d
其中,J(·)表示三维人体姿态下前向运动学计算获得的三维关节中心坐标集合,T是将查询姿态q对齐到数据库中姿态q
已知人体姿态数据库Q
其中,w是人体姿态的低维参数向量,P
惩罚重建的三维人体姿态q与在线搜索出的K个姿态近邻Q
其中,q是待求的人体姿态向量,ε是常量;
通过将公式(19)中的概率最大化问题通常转化的能量最小化问题,表示如下:
人体姿态关节角范围限制能量项防止在迭代优化求解三维人体姿态关节角度变化值时超出合理的数值范围,导致出现非合理的三维人体姿态重建结果.表示为:
其中,
三维人体姿态平滑变化约束能量项惩罚重建的当前帧三维人体姿态q与前2帧重建姿态
其中,等号右边双括号内表示的含义是:从前一帧重建姿态
由公式(15)、公式(16)、公式(20)、公式(21)和公式(22)使公式(14)的能量函数的具体表达形式为:
其中,
本发明的有益效果为:
1、实时在线的方法,平均帧率能达到20帧/秒,成本低,效率高;
2、该建模过程简单、快速,且无需人工后处理;
3、约束姿态解空间,提高人体运动姿态重建准确性。
附图说明
图1是本发明的系统算法流程图;
图2是4台深度相机摆放及标定实例图;
图3是4台深度相机的三维点云对齐前和后结果实例图;
图4是三维多目深度点云预处理的实例图;
图5是人体几何模型估计算法流程图;
图6是人体几何模型内嵌骨架关节点的参数化实例图;
图7是基于前2帧重建姿态的当前帧姿态K近邻搜索实例图;
图8是基于GPU的三维人体姿态重建算法流程示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
实施例1
本发明的一种三维实时人体姿态重建方法,包括:
S1,使用4台深度相机拍摄深度图像,深度图像的像素点表示为x,深度图像的像素点对应的深度值和三维点分别为d(x)和p;
S2,4台深度相机通过PCI数据接口连接计算机,计算机同步驱动4台深度相机完成数据采集工作;
S3,4台深度相机分别位于正方形的人体运动捕获场景的4个边角,其中美相邻2台深度相机基于棋盘格和立体视觉的标定方法;
S4,对4台深度相机捕获的深度图像的原始三维点进行预处理去噪;
S5,从运动捕获开源数据库中挑选运动序列并建立三维人体姿态数据库Q,并且在建立三维人体姿态数据库Q中进行运动重定向技术的骨架归一化;
S6,使用4台深度相机拍摄真实人体的A姿态图像,并且通过基于骨架驱动的方法对真实人体的A姿态图像的人体几何模型做姿态维度的变形,然后将精细个体化人体几何模型自动估计问题形式通过化为非线性优化问题以进行迭代优化求解;
S7,通过三维姿态数据库与精细个体化人体几何模型的多目深度相机进行三维人体运动姿态跟踪。
实施例2
本发明的一种三维实时人体姿态重建方法,包括:
S1,使用4台深度相机拍摄深度图像,深度图像的像素点表示为x,深度图像的像素点对应的深度值和三维点分别为d(x)和p;
S2,4台深度相机通过PCI数据接口连接计算机,计算机同步驱动4台深度相机完成数据采集工作;
S3,4台深度相机分别位于正方形的人体运动捕获场景的4个边角,其中美相邻2台深度相机基于棋盘格和立体视觉的标定方法;
S4,对4台深度相机捕获的深度图像的原始三维点进行预处理去噪;
S5,从运动捕获开源数据库中挑选运动序列并建立三维人体姿态数据库Q,并且在建立三维人体姿态数据库Q中进行运动重定向技术的骨架归一化;
同步捕获相邻2台的深度相机的多组包含棋盘格的红外图像对,使用角点检测算法从捕获的红外图像中提取棋盘格角点集合,基于立体视觉算法估计出该2台深度相机红外摄像头的内、外参数矩阵;
以其中1台深度相机所在坐标系为世界坐标系,其光心为世界坐标原点,将其余3台深度相机基于标定获得的外参数矩阵对齐到世界坐标系;
基于三维平面拟合技术估计出场景中的地板平面,基于三维圆柱体包围盒自动减除背景像素点,该包围盒的底平面平行于估计出的地板平面,底面中心点为采集场景中心点,以剩下的前景三维深度点云分布中心点为起始点,通过设置合适的三维深度点间距离阈值,求出三维空间中最大的连通区,完成三维深度点云去噪;
S6,使用4台深度相机拍摄真实人体的A姿态图像,并且通过基于骨架驱动的方法对真实人体的A姿态图像的人体几何模型做姿态维度的变形,然后将精细个体化人体几何模型自动估计问题形式通过化为非线性优化问题以进行迭代优化求解;
S7,通过三维姿态数据库与精细个体化人体几何模型的多目深度相机进行三维人体运动姿态跟踪。
实施例3
本发明的一种三维实时人体姿态重建方法,包括:
S1,使用4台深度相机拍摄深度图像,深度图像的像素点表示为x,深度图像的像素点对应的深度值和三维点分别为d(x)和p;
S2,4台深度相机通过PCI数据接口连接计算机,计算机同步驱动4台深度相机完成数据采集工作;
S3,4台深度相机分别位于正方形的人体运动捕获场景的4个边角,其中美相邻2台深度相机基于棋盘格和立体视觉的标定方法;
S4,对4台深度相机捕获的深度图像的原始三维点进行预处理去噪;
S5,从运动捕获开源数据库中挑选运动序列并建立三维人体姿态数据库Q,并且在建立三维人体姿态数据库Q中进行运动重定向技术的骨架归一化;
S6,使用4台深度相机拍摄真实人体的A姿态图像,并且通过基于骨架驱动的方法对真实人体的A姿态图像的人体几何模型做姿态维度的变形,然后将精细个体化人体几何模型自动估计问题形式通过化为非线性优化问题以进行迭代优化求解;
所述S6中,
人体几何模型用模型网格顶点集合的长向量s
其中,β是人体几何模型的低维参数向量,P
将人体骨架各关节中心J
其中,V
通过定义空间包围盒方式获得人体内嵌骨架关节中心各关节中心的近邻人体几何模型顶点集合;
顶点权重w的求解根据人体几何模板模型及其内嵌人体骨架,估计几何模型顶点,将其形式化为带约束的线性最小二乘问题,表示为:
根据公式(2),当给定个体化人体几何模型顶点坐标和顶点权重w
通过三维深度点云P,人体几何模型数据库S和人体姿态数据库Q,求个体化人体几何模型,个体化人体几何模型的参数化为人体姿态参数向量
其中,E
其中,“点到点”距离,指的是人体几何模型顶点v
其中,“点到面”距离,指的是人体几何模型顶点v
为保证人体几何模型重建结果的合理性,引入了人体骨骼长度对称能量项,表示为:
E
其中,{(M,N)}是对称骨骼段集合,l
设全局空间中的人体几何模型数据库构成多维高斯分布,则人体几何模型先验约束项最大化下述条件概率,表示为:
其中,Λ
其中,β是待求的人体几何模型的低维参数向量,P
设人体姿态数据库Q={q
其中,w是人体姿态的低维参数向量,P
设全局空间中的人体姿态数据构成多维高斯分布,则人体姿态先验约束项最大化下述条件概率,表示为:
其中,q是待求的人体姿态向量,δ
公式(11)中使用能量最小化形式,表示为:
结合公式(5)、公式(6)、公式(7)、公式(9)和公式(12),将公式(4)表示如下:
其中,
S7,通过三维姿态数据库与精细个体化人体几何模型的多目深度相机进行三维人体运动姿态跟踪。
实施例4
本发明的一种三维实时人体姿态重建方法,包括:
S1,使用4台深度相机拍摄深度图像,深度图像的像素点表示为x,深度图像的像素点对应的深度值和三维点分别为d(x)和p;
S2,4台深度相机通过PCI数据接口连接计算机,计算机同步驱动4台深度相机完成数据采集工作;
S3,4台深度相机分别位于正方形的人体运动捕获场景的4个边角,其中美相邻2台深度相机基于棋盘格和立体视觉的标定方法;
S4,对4台深度相机捕获的深度图像的原始三维点进行预处理去噪;
S5,从运动捕获开源数据库中挑选运动序列并建立三维人体姿态数据库Q,并且在建立三维人体姿态数据库Q中进行运动重定向技术的骨架归一化;
S6,使用4台深度相机拍摄真实人体的A姿态图像,并且通过基于骨架驱动的方法对真实人体的A姿态图像的人体几何模型做姿态维度的变形,然后将精细个体化人体几何模型自动估计问题形式通过化为非线性优化问题以进行迭代优化求解;
S7,通过三维姿态数据库与精细个体化人体几何模型的多目深度相机进行三维人体运动姿态跟踪;
所述S7中,
通过当前帧捕获的三维深度点云P、精细个体化人体几何模型S
其中,G
“点到点”距离,指的是姿态q驱动的人体几何模型S
“点到面”距离,指的是姿态q驱动的人体几何模型S
根据前2帧重建的三维人体姿态
d
其中,J(·)表示三维人体姿态下前向运动学计算获得的三维关节中心坐标集合,T是将查询姿态q对齐到数据库中姿态q
已知人体姿态数据库Q
其中,w是人体姿态的低维参数向量,P
惩罚重建的三维人体姿态q与在线搜索出的K个姿态近邻Q
其中,q是待求的人体姿态向量,ε是常量;
通过将公式(19)中的概率最大化问题通常转化的能量最小化问题,表示如下:
人体姿态关节角范围限制能量项防止在迭代优化求解三维人体姿态关节角度变化值时超出合理的数值范围,导致出现非合理的三维人体姿态重建结果.表示为:
三维人体姿态平滑变化约束能量项惩罚重建的当前帧三维人体姿态q与前2帧重建姿态
其中,等号右边双括号内表示的含义是:从前一帧重建姿态
由公式(15)、公式(16)、公式(20)、公式(21)和公式(22)使公式(14)的能量函数的具体表达形式为:
其中,
实施例5
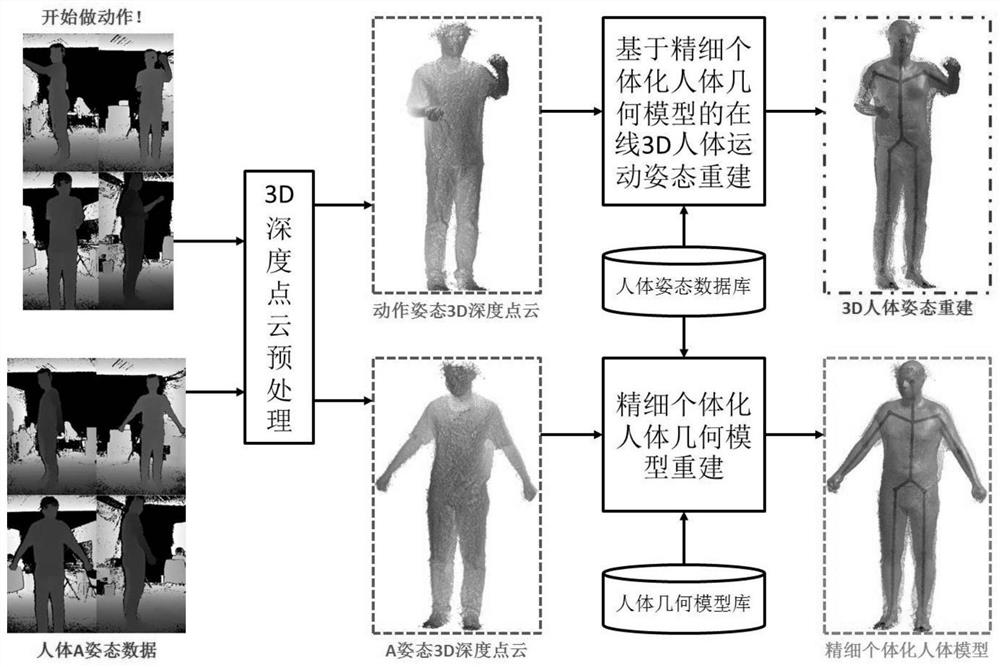
整体算法流程如图1,本发明的一种三维实时人体姿态重建方法,包括:
S1,使用4台深度相机拍摄深度图像,深度图像的像素点表示为x,深度图像的像素点对应的深度值和三维点分别为d(x)和p;
S2,4台深度相机通过PCI数据接口连接计算机,计算机同步驱动4台深度相机完成数据采集工作,从时间上是自然同步的;
S3,4台深度相机分别位于正方形的人体运动捕获场景的4个边角,,且均朝向该场景中心位置摆放,如图2(a)所示,其中美相邻2台深度相机基于棋盘格和立体视觉的标定方法;首先,同步捕获相邻2台深度相机的多组包含棋盘格的红外图像对,如图2(b)显示的是其中的一个红外图像对;然后,使用角点检测算法从捕获的红外图像中提取棋盘格角点集合,如图2(c)所示;最后,基于立体视觉算法估计出该2台深度相机红外摄像头的内、外参数矩阵。本项专利以其中1台深度相机所在坐标系为世界坐标系,其光心为世界坐标原点,将其余3台深度相机基于标定获得的外参数矩阵对齐到世界坐标系,4台深度相机的三维点云对齐前、后结果实例如图3所示;
S4,对4台深度相机捕获的深度图像的原始三维点进行预处理去噪;首先,基于三维平面拟合技术估计出场景中的地板平面;然后,基于三维圆柱体包围盒自动减除背景像素点,该包围盒的底平面平行于估计出的地板平面,底面中心点为采集场景中心点,半径1.2m、高2.5米;最后,以剩下的前景三维深度点云分布中心点为起始点,0.02m为三维深度点间距离阈值,求出三维空间中最大的连通区,完成三维深度点云去噪,如图4所示;
估计精细的个体化人体几何模型的方法如图5所示,S5,从运动捕获开源数据库中挑选运动序列并建立三维人体姿态数据库Q,并且在建立三维人体姿态数据库Q中进行运动重定向技术的骨架归一化;
同步捕获相邻2台的深度相机的多组包含棋盘格的红外图像对,使用角点检测算法从捕获的红外图像中提取棋盘格角点集合,基于立体视觉算法估计出该2台深度相机红外摄像头的内、外参数矩阵;
以其中1台深度相机所在坐标系为世界坐标系,其光心为世界坐标原点,将其余3台深度相机基于标定获得的外参数矩阵对齐到世界坐标系;
基于三维平面拟合技术估计出场景中的地板平面,基于三维圆柱体包围盒自动减除背景像素点,该包围盒的底平面平行于估计出的地板平面,底面中心点为采集场景中心点,以剩下的前景三维深度点云分布中心点为起始点,通过设置合适的三维深度点间距离阈值,求出三维空间中最大的连通区,完成三维深度点云去噪;
其中,三维人体姿态表示:定义三维人体姿态为关节自由度构成的向量q∈R
S6,使用4台深度相机拍摄真实人体的A姿态图像,并且通过基于骨架驱动的方法对真实人体的A姿态图像的人体几何模型做姿态维度的变形,然后将精细个体化人体几何模型自动估计问题形式通过化为非线性优化问题以进行迭代优化求解;
人体几何模型用模型网格顶点集合的长向量s
其中,β是人体几何模型的低维参数向量,P
将人体骨架各关节中心J
其中,V
通过定义空间包围盒(三维球)方式获得人体内嵌骨架关节中心各关节中心的近邻人体几何模型顶点集合,如图6所示,图中每种颜色的人体几何模型顶点集合表示对应人体骨架关节周围的“近邻”;
顶点权重w的求解根据人体几何模板模型及其内嵌人体骨架,估计几何模型顶点,将其形式化为带约束的线性最小二乘问题,表示为:
根据公式(2),当给定个体化人体几何模型顶点坐标和顶点权重w
通过三维深度点云P,人体几何模型数据库S和人体姿态数据库Q,求个体化人体几何模型,个体化人体几何模型的参数化为人体姿态参数向量
其中,E
其中,“点到点”距离,指的是人体几何模型顶点v
其中,“点到面”距离,指的是人体几何模型顶点v
为保证人体几何模型重建结果的合理性,引入了人体骨骼长度对称能量项,表示为:
E
其中,{(M,N)}是对称骨骼段集合,l
设全局空间中的人体几何模型数据库构成多维高斯分布,则人体几何模型先验约束项最大化下述条件概率,表示为:
其中,Λ
其中,β是待求的人体几何模型的低维参数向量,P
设人体姿态数据库Q={q
其中,w是人体姿态的低维参数向量,P
设全局空间中的人体姿态数据构成多维高斯分布,则人体姿态先验约束项最大化下述条件概率,表示为:
其中,q是待求的人体姿态向量,δ
公式(11)中使用能量最小化形式,表示为:
结合公式(5)、公式(6)、公式(7)、公式(9)和公式(12),将公式(4)表示如下:
其中,
S7,通过三维姿态数据库与精细个体化人体几何模型的多目深度相机进行三维人体运动姿态跟踪;
通过当前帧捕获的三维深度点云P、精细个体化人体几何模型S
其中,G
“点到点”距离,指的是姿态q驱动的人体几何模型S
“点到面”距离,指的是姿态q驱动的人体几何模型S
根据前2帧重建的三维人体姿态
d
其中,J(·)表示三维人体姿态下前向运动学计算获得的三维关节中心坐标集合,T是将查询姿态q对齐到数据库中姿态q
已知人体姿态数据库Q
其中,w是人体姿态的低维参数向量,P
惩罚重建的三维人体姿态q与在线搜索出的K个姿态近邻Q
其中,q是待求的人体姿态向量,ε是常量;
通过将公式(19)中的概率最大化问题通常转化的能量最小化问题,表示如下:
人体姿态关节角范围限制能量项防止在迭代优化求解三维人体姿态关节角度变化值时超出合理的数值范围,导致出现非合理的三维人体姿态重建结果.表示为:
是二值指示函数:如果第i个关节角低于下限q
三维人体姿态平滑变化约束能量项惩罚重建的当前帧三维人体姿态q与前2帧重建姿态
其中,等号右边双括号内表示的含义是:从前一帧重建姿态
由公式(15)、公式(16)、公式(20)、公式(21)和公式(22)使公式(14)的能量函数的具体表达形式为:
其中,
捕获的三维深度点云中存在一定的数据噪声,造成人体几何模型顶点与捕获深度点云的噪声点构成空间匹配点对,从而影响人体几何模型估计结果的准确性,所以时间中,设置p=L
相比非基于模型的三维人体运动捕获方法,基于模型的三维人体运动捕获方法由于使用了个体化的三维人体几何模型,等价于增加了三维人体形状先验知识,所以一般情况下,能获得更准确的三维人体运动姿态序列。更进一步,相比基于模型的单目深度相机的三维人体运动捕获方法,基于模型的多目深度相机三维人体运动方法由于使用了更多视角的数据输入信息,能最大程度降低由于肢体遮挡及自遮挡造成三维人体姿态重建的歧义性。因此,本项专利主要解决如何基于多目深度相机实时在线地重建三维人体姿态的技术问题。
本项专利提出一种基于精细个体化人体几何模型的低成本、实时在线准确捕获三维人体运动姿态序列的系统。关键思路是:首先基于人体几何模型库,根据多目深度相机捕获的三维深度点云数据,自动在线构建精细的个体化人体几何模型及其内嵌的人体骨架;然后,直接基于重建出的人体几何模型,根据多目深度相机捕获的三维深度点云数据,构建一个低成本、实时在线准确捕获三维人体运动姿态序列的系统。本项专利方法能够根据多目深度相机捕获的三维深度点云数据,自动准确重建精细的个体化人体几何模型,并且基于该几何模型实时在线准确捕获不同人的多种类型三维人体运动姿态序列,在GPU上多线程上的平均帧率约为20帧/秒。
如图8,基于GPU的三维人体姿态重建算法流程,包括“基于GPU的Levenberg-Marquardt非线性优化”,GPU和CPU对图像进行处理过程,数字表示每个步骤的实际平均处理耗时;其中“GPU计算3D深度点云”、“基于GPU前景提取与去噪”、“基于GPU的LBS算法”、“基于GPU的最近点搜索与注册”、“基于GPU的姿态K近邻搜索”和“基于GPU的线性化A=J‘*J,g=J‘*rq”均由GPU进行处理;“读取深度图像”、“更新3D人体姿态”、“消除误匹配点对”和“显示3D姿态跟踪结果”均由CPU进行处理。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 一种三维实时人体姿态重建方法
- 一种基于骨骼长度约束的人体三维姿态重建方法及系统