一种指标异常检测方法、装置、设备及存储介质
文献发布时间:2023-06-19 12:24:27
技术领域
本发明实施例涉及金融科技(Fintech)技术领域,尤其涉及一种指标异常检测方法、装置、设备及存储介质。
背景技术
随着计算机技术的发展,越来越多的技术应用在金融领域,传统金融业正在逐步向金融科技(Fintech)转变,但由于金融行业的安全性、实时性要求,也对技术提出的更高的要求。具体地,随着金融业务的增长,系统、虚拟机和容器数量不断的增加,监控指标的数量也突飞猛进,单靠人工运维,配置告警阈值,观察系统是否正常运行,需要消耗大量的人力,而且容易出错。
相关技术使用一种指标异常检测算法,检测所有场景下的指标是否异常,然而,每个场景的指标都有相应的特征,且每种异常检测算法都有自身的缺陷,若采用一种指标异常检测算法覆盖所有场景下的指标异常检测,由于无法涉及到所有场景的指标,将导致异常检测的准确性较低。
发明内容
本申请实施例提供了一种指标异常检测方法、装置、设备及存储介质,用于提高异常检测的准确性。
一方面,本申请实施例提供了一种指标异常检测方法,该方法包括:
获取目标业务指标的第一指标标签以及第一监测数据,所述目标业务指标的第一指标标签是通过对目标业务指标的历史监测数据进行特征提取获得历史指标特征,并基于所述历史指标特征预测获得的;
基于所述目标业务指标的第一指标标签,从异常检测规则库中获得对应的第一检测规则;
采用所述第一检测规则,对所述第一监测数据进行异常检测,确定所述目标业务指标是否为异常指标。
本申请实施例中,通过对业务指标的历史监测数据进行特征提取获得历史指标特征,然后基于历史指标特征预测获得业务指标的第一指标标签,故不需要人工为各个业务指标打上指标标签,实现打标签自动化,既提高了打标签的效率,又降低了人力成本。其次,基于目标业务指标的第一指标标签,从异常检测规则库中获得对应的第一检测规则,然后采用第一检测规则,对第一监测数据进行异常检测,确定目标业务指标是否为异常指标。针对不同指标的特征采用不同的异常检测规则,满足了不同指标的异常检测需求,从而提高了异常检测的准确性。
可选地,所述对目标业务指标的历史监测数据进行特征提取获得历史指标特征,包括:
采用N个特征提取模块依次对所述目标业务指标的历史监测数据进行特征提取,获得所述目标业务指标的历史指标特征,其中,每个特征提取模块至少包括卷积层和池化层,N为预设正整数。
可选地,所述N个特征提取模块包括第一特征提取模块、第二特征提取模块和第三特征提取模块,其中,第一特征提取模块包括第一卷积层、第二卷积层和第一池化层,所述第二特征提取模块包括第三卷积层和第二池化层,所述第三特征提取模块包括第四卷积层和第三池化层。
可选地,所述采用N个特征提取模块依次对所述目标业务指标的历史监测数据进行特征提取,获得所述目标业务指标的历史指标特征,包括:
采用所述第一卷积层、所述第二卷积层以及所述第一池化层,依次对所述目标业务指标的历史监测数据进行特征提取,获得第一特征;
采用所述第三卷积层以及所述第二池化层,依次对所述第一特征进行特征提取,获得第二特征;
采用所述第四卷积层以及所述第三池化层,依次对所述第二特征进行特征提取,获得所述目标业务指标的历史指标特征。
可选地,所述基于所述历史指标特征预测获得所述目标业务指标的第一指标标签,包括:
采用压平层对所述历史指标特征展开后输入全连接网络,获得所述目标业务指标的第一指标标签。
本申请实施例中,采用卷积神经网络模型自动预测业务指标的指标标签,既提高了打标签的效率,又降低了人力成本。其次,业务指标的监测数据较多,而卷积神经网络模型通过局部连接、权值共享、下采样,可以减少参数的数量,做到特征的提取压缩。利用多个卷积层和多个池化层进行特征提取,获得了各像素点之间的位置关系,同时解决全连接网络的梯度传导问题,提高了模型的性能,进而提高了预测获得的指标标签的准确性。
可选地,所述目标业务指标的第一指标标签表征所述目标业务指标为周期性指标;
所述采用所述第一检测规则,对所述第一监测数据进行异常检测,确定所述目标业务指标是否为异常指标,包括:
采用标准差模型、孤立随机森林模型和移动平均模型,分别对所述第一监测数据进行异常检测,获得各个模型输出的异常检测结果;
若获得的各个异常检测结果中存在至少两个异常检测结果,表征所述目标业务指标为异常指标,则确定所述目标业务指标为异常指标;否则,确定所述目标业务指标为正常指标。
可选地,所述确定所述目标业务指标为异常指标之后,还包括:
若确定所述第一监测数据的同环比满足预设告警条件,则触发告警。
本申请实施例中,根据周期性指标的周期性变化特点,为周期性指标编排了标准差模型、孤立随机森林模型和移动平均模型进行异常检测,从而提高了异常检测的能力。其次,综合标准差模型、孤立随机森林模型和移动平均模型三个异常检测模型的异常检测结果,判断目标业务指标是否为异常指标,避免了单个模型检测异常时的片面性,提高了异常检测的准确性。
可选地,所述目标业务指标的第一指标标签表征所述目标业务指标为周期性指标,且等级大于预设阈值;
所述采用所述第一检测规则,对所述第一监测数据进行异常检测,确定所述目标业务指标是否为异常指标,包括:
确定所述第一监测数据的同环比以及目标导数;
采用标准差模型、孤立随机森林模型、移动平均模型以及整合移动平均自回归模型,分别对所述第一监测数据进行异常检测,获得各个模型输出的异常检测结果;
采用已训练的综合识别模型,基于获得的各个异常检测结果、所述同环比以及所述目标导数,确定所述目标业务指标是否为异常指标。
本申请实施例中,综合同环比、目标导数、标准差模型、孤立随机森林模型、移动平均模型以及整合移动平均自回归模型,确定目标业务指标是否为异常指标,避免了单个模型检测异常时的片面性,提高了异常检测的准确性,满足了重要指标对异常检测的准确性的要求。
可选地,所述目标业务指标的第一指标标签表征所述目标业务指标为平稳指标或随机波动指标;
所述采用所述第一检测规则,对所述第一监测数据进行异常检测,确定所述目标业务指标是否为异常指标,包括:
采用波动检测模型,对所述第一监测数据进行波动检测,确定所述目标业务指标的目标波动值;
采用波动趋势识别模型,对所述第一监测数据进行波动趋势识别,确定所述目标业务指标的第一波动趋势;
若所述目标波动值和/或所述第一波动趋势,满足相应的告警条件时,则确定所述目标业务指标为异常指标并触发告警;否则,确定所述目标业务指标为正常指标。
本申请实施例中,根据平稳指标或随机波动指标的特点,为平稳指标或随机波动指标编排了波动检测模型和波动趋势识别模型,使得待检测指标与检测模型之间更加匹配,从而提高了异常检测的准确性。
可选地,还包括:
获取目标基础指标的第二指标标签以及第二监测数据,所述目标基础指标的第二指标标签是基于所述目标基础指标的名称,通过正则匹配方式从指标标签库中获取的;
基于所述目标基础指标的第二指标标签,从异常检测规则库中获得对应的第二检测规则;
采用所述第二检测规则,对所述第二监测数据进行异常检测,确定所述目标基础指标是否为异常指标。
可选地,所述采用所述第二检测规则,对所述第二监测数据进行异常检测,确定所述目标基础指标是否为异常指标,包括:
采用波动趋势识别模型,对所述第二监测数据进行波动趋势识别,确定所述目标基础指标的第二波动趋势;
若所述第二波动趋势满足相应的告警条件,或者所述第二监测数据超出预设阈值范围,则确定所述目标基础指标为异常指标并触发告警;否则,确定所述目标基础指标为正常指标。
一方面,本申请实施例提供了一种指标异常检测装置,该装置包括:
获取模块,用于获取目标业务指标的第一指标标签以及第一监测数据,所述目标业务指标的第一指标标签是通过对目标业务指标的历史监测数据进行特征提取获得历史指标特征,并基于所述历史指标特征预测获得的;
匹配模块,用于基于所述目标业务指标的第一指标标签,从异常检测规则库中获得对应的第一检测规则;
检测模块,用于采用所述第一检测规则,对所述第一监测数据进行异常检测,确定所述目标业务指标是否为异常指标。
一方面,本申请实施例提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述指标异常检测方法的步骤。
一方面,本申请实施例提供了一种计算机可读存储介质,其存储有可由计算机设备执行的计算机程序,当所述程序在计算机设备上运行时,使得所述计算机设备执行上述指标异常检测方法的步骤。
本申请实施中,通过对业务指标的历史监测数据进行特征提取获得历史指标特征,然后基于历史指标特征预测获得业务指标的第一指标标签,故不需要人工为各个业务指标打上指标标签,实现打标签自动化,既提高了打标签的效率,又降低了人力成本。其次,基于目标业务指标的第一指标标签,从异常检测规则库中获得对应的第一检测规则,然后采用第一检测规则,对第一监测数据进行异常检测,确定目标业务指标是否为异常指标。针对不同指标的特征采用不同的异常检测规则,满足了不同指标的异常检测需求,从而提高了异常检测的准确性。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种系统架构示意图;
图2为本申请实施例提供的一种指标异常检测方法的流程示意图;
图3为本申请实施例提供的一种卷积神经网络的结构示意图;
图4为本申请实施例提供的一种卷积神经网络的结构示意图;
图5为本申请实施例提供的一种业务指标分类方法的流程示意图;
图6为本申请实施例提供的一种指标异常检测方法的流程示意图;
图7为本申请实施例提供的一种指标异常检测装置的结构示意图;
图8为本申请实施例提供的一种计算机设备的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
为了方便理解,下面对本发明实施例中涉及的名词进行解释。
CNN:Convolutional Neural Networks,卷积神经网络,一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks,SIANN)。
支持向量机(Support Vector Machine,简称SVM),一类按监督学习(supervisedlearning)方式对数据进行二元分类的广义线性分类器(generalized linearclassifier),其决策边界是对学习样本求解的最大边距超平面(maximum-marginhyperplane)。
决策树(Decision Tree):在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。
指标:监控系统采集的数据,反应系统的运行情况,包括基础指标和业务指标,其中,基础指标包括主机指标和程序运行时指标,主机指标又可以分为容器指标、虚拟机指标等,比如,中央处理器(central processing unit,简称CPU)、内存、IO、网络等。程序运行时指标包括Java虚拟机(Java Virtual Machine,简称JVM)运行时产生的各种指标,比如活跃线程数、Buffer大小、内存大小等。业务指标与具体业务相关,具体包括成功率、TPS、失败率、失败数量、平均延时、最大延时等。
参考图1,其为本申请实施例适用的一种系统架构图,该系统架构至少包括配置管理系统101、监控系统102、业务系统103以及异常检测系统104。
业务系统103作为新系统接入时,配置管理系统101配置业务系统103相应的系统信息。配置结束后,业务系统103可以为各个用户端提供相应的服务。在业务系统103运行过程中,监控系统102通过扫描业务系统103的日志,获得业务系统103的各个业务指标的监测数据;通过agent(代理)采集业务系统103的各个基础指标的监测数据。然后将各个业务指标的监测数据和各个基础指标的监测数据发送给异常检测系统104。
针对任意一个业务指标,异常检测系统104对该业务指标的历史监测数据进行特征提取获得历史指标特征,并基于历史指标特征预测获得该业务指标的第一指标标签,然后将该业务指标的第一指标标签保存在数据库中。
针对任意一个基础指标,异常检测系统104基于该基础指标的名称,通过正则匹配方式从指标标签库中获取该基础指标的第二指标标签,然后将该基础指标的第二指标标签保存在数据库中。
在确定各个业务指标和各个基础指标的指标标签之后,若异常检测系统104接收到监控系统102发送的目标业务指标的第一监测数据,则异常检测系统104从数据库中获取目标业务指标的第一指标标签,然后基于目标业务指标的第一指标标签,从异常检测规则库中获得对应的第一检测规则,之后再采用第一检测规则,对第一监测数据进行异常检测,确定目标业务指标是否为异常指标。
若异常检测系统104接收到监控系统102发送的目标基础指标的第二监测数据,则异常检测系统104从数据库中获取目标基础指标的第二指标标签,然后基于目标基础指标的第二指标标签从异常检测规则库中获得对应的第二检测规则,之后再采用第二检测规则,对第二监测数据进行异常检测,确定目标基础指标是否为异常指标。
需要说明的是,本申请实施例中,上述各个系统可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、内容分发网络(Content Delivery Network,CDN)、以及大数据和人工智能平台等基础云计算服务的云服务器。上述各个系统之间可以通过有线或无线通信方式进行直接或间接地连接,本申请在此不做限制。
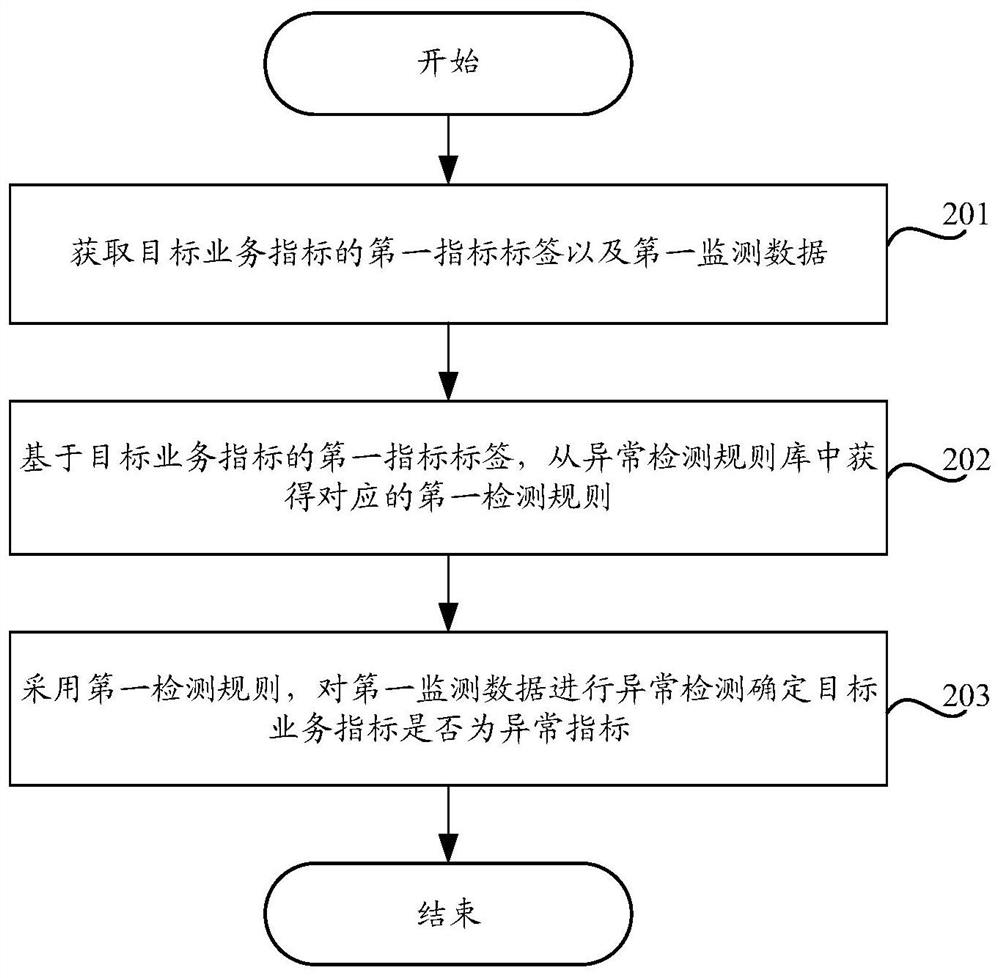
基于图1所示的系统架构图,本申请实施例提供了一种指标异常检测方法的流程,如图2所示,该方法的流程由计算机设备执行,该计算机设备可以是图1所示的异常检测系统104,包括以下步骤:
步骤S201,获取目标业务指标的第一指标标签以及第一监测数据。
具体地,业务指标与具体业务相关,包括:成功率、TPS、失败率、失败数量、平均延时、最大延时等。目标业务指标可以是各个业务指标中的任意一个。第一指标标签用于表征业务指标类型,业务指标类型包括周期性指标、平稳指标、随机波动指标。目标业务指标的第一指标标签是通过对目标业务指标的历史监测数据进行特征提取获得历史指标特征,并基于历史指标特征预测获得的。可选地,基于历史指标特征预测目标业务指标的第一指标标签时,可以基于历史指标特征中的局部特征与各个业务指标类型类型之间的相似度,将历史指标特征中的各个局部特征划分至各个业务指标类型。然后基于各个业务指标类型中划分的局部特征的数量,确定各个业务指标类型对应的概率,将概率最大的业务指标类型作为第一指标标签。
采用同样的方式可以获得目标业务指标之外的其他业务指标的第一指标标签。在获得各个业务指标的第一指标标签之后,将各个业务指标的第一指标标签保存在数据库中,以便在检测业务指标是否异常时调用。
步骤S202,基于目标业务指标的第一指标标签,从异常检测规则库中获得对应的第一检测规则。
具体地,预先针对各个第一指标标签编排相应的异常检测规则,然后将各个第一指标标签和相应的异常检测规则对应保存在异常检测规则库中。在获得目标业务指标的第一指标标签之后,基于目标业务指标的第一指标标签查询异常检测规则库,从各个异常检测规则中获得第一检测规则。
步骤S203,采用第一检测规则,对第一监测数据进行异常检测,确定目标业务指标是否为异常指标。
具体地,一个异常检测规则中可以包括一个或多个异常检测模型。当一个异常检测规则中包括多个异常检测模型时,异常检测规则还包括多个异常检测模型之间的执行顺序,以及综合多个异常检测模型的输出结果确定最终异常检测结果的策略。第一检测规则为各个异常检测规则中,与第一指标标签匹配的异常检测规则。
当第一检测规则中只包括一个异常检测模型,采用该异常检测模型对第一监测数据进行异常检测,确定目标业务指标是否为异常指标。当第一检测规则中只包括多个异常检测模型时,分别采用多个异常检测模型对第一监测数据进行异常检测,然后综合多个异常检测模型的输出结果,确定目标业务指标是否为异常指标。
本申请实施中,通过对业务指标的历史监测数据进行特征提取获得历史指标特征,然后基于历史指标特征预测获得业务指标的第一指标标签,故不需要人工为各个业务指标打上指标标签,实现打标签自动化,既提高了打标签的效率,又降低了人力成本。其次,基于目标业务指标的第一指标标签,从异常检测规则库中获得对应的第一检测规则,然后采用第一检测规则,对第一监测数据进行异常检测,确定目标业务指标是否为异常指标。针对不同指标的特征采用不同的异常检测规则,满足了不同指标的异常检测需求,从而提高了异常检测的准确性。
可选地,在上述步骤S201中,可以采用卷积神经网络对目标业务指标的历史监测数据进行特征提取获得历史指标特征。具体地,卷积神经网络包括N个特征提取模块,采用训练样本对卷积神经网络进行训练之后,采用卷积神经网络中的N个特征提取模块依次对目标业务指标的历史监测数据进行特征提取,获得目标业务指标的历史指标特征,其中,每个特征提取模块至少包括卷积层和池化层,N为预设正整数。
一种可能的实施方式,N个特征提取模块包括第一特征提取模块、第二特征提取模块和第三特征提取模块,其中,第一特征提取模块包括第一卷积层、第一池化层,第二特征提取模块包括第二卷积层和第二池化层,第三特征提取模块包括第三卷积层和第三池化层。
进一步地,为了聚合更多的数据,以提高指标异常检测的准确性,本发明实施例中,优选采用另一种可能的实施方式,如图3所示,N个特征提取模块包括第一特征提取模块、第二特征提取模块和第三特征提取模块,其中,第一特征提取模块包括第一卷积层、第二卷积层和第一池化层,第二特征提取模块包括第三卷积层和第二池化层,第三特征提取模块包括第四卷积层和第三池化层。
采用第一卷积层、第二卷积层以及第一池化层,依次对目标业务指标的历史监测数据进行特征提取,获得第一特征。然后采用第三卷积层以及第二池化层,依次对第一特征进行特征提取,获得第二特征。再采用第四卷积层以及第三池化层,依次对第二特征进行特征提取,获得目标业务指标的历史指标特征。需要说明,本实施例在第一特征提取模块中设置第一卷积层、第二卷积层,可以使得聚合的数据更多,后续进行指标异常检测的准确性更高。
具体地,上述各个卷积层的作用是利用各像素点之间的位置关系,提取局部特征,上述各个池化层的作用是下采样,去除不重要的样本,减少参数的数量。
可选地,如图4所示,卷积神经网络还包括压平层和全连接网络,在提取目标业务指标的历史指标特征之后,采用压平层对历史指标特征展开后输入全连接网络,获得目标业务指标的第一指标标签。
下面结合具体实施场景,对上述卷积神经网络的结构、训练过程以及分类过程进行举例说明:
第一、训练样本的获取过程:
设定监控系统第一预设时长(本实施例可选为一分钟,在其他实施例,可选设为其他值如两分钟)采集一次监测数据,针对每个业务指标,一天共采集1440个监测数据点。采用第二预设时长(本实施例可选为5分钟,在其他实施例,可选设为其他值如10分钟)的时间窗口,对1440个监测数据点进行压缩,获得288个监测数据点,其中,5分钟内的监测数据点取均值。监控系统通过metricID标识每一个业务指标。
人工基于各个业务指标的监测数据,对各个业务指标进行分类并打上指标标签,作为训练样本集,指标标签包括{0:随机波动指标、1:周期性指标、2:平稳指标}。在训练样本集中,三种指标标签的样本数据量的基本相同。
本申请实施例采用以下方式导入训练样本集:
训练样本集中包括两部分数据,分别为监测数据和指标标签。采用数据拉取模块定时从监控系统的接口将监测数据导入数据库,通过excel导入或机器人导入的方式将指标标签导入数据库。
其中,excel导入指将指标标签写入对应的excel,然后编写特定的脚本,将excel中的指标标签导入数据库。
机器人导入指编写机器人脚本,然后通过机器人脚本,将指标标签导入数据库。
第二、卷积神经网络模型的训练过程:
卷积神经网络包括卷积层1、卷积层2、池化层1、卷积层3、池化层2、卷积层4、池化层3、压平层和全连接网络。
具体地,卷积层1的属性参数为:3*1*4,其中,3表示提取相邻3个数据点的数据特征,1表示一维矩阵,4表示4个不同的滤波器(filter),比如,4个滤波器分别为[1,0,1]、[-1,0,-1]、[1,0,-1]、[-1,0,1],采用不同的滤波器可以提取不同的特征。
卷积层2的属性参数为:3*1*1,卷积层2的属性参数的意义与卷积层1的属性参数的意义相同,此处不再赘述。
池化层1的属性参数为:3*1,表示从3个数据点中选取值最大的数据点,从而去除不重要的样本,减少数据点的数量。
卷积层3的属性参数为:3*1*4。
池化层2的属性参数为:3*1,池化层2的属性参数的意义与池化层1的属性参数的意义相同,此处不再赘述。
卷积层4的属性参数为:3*1*1。
池化层3的属性参数为:3*1,
由于ReLu函数的速度快、且能够减轻梯度消失的问题,因此选择ReLu函数作为上述卷积神经网络中各层之间的激活函数,ReLu函数如以下公式(1)所示:
F(x)=Max(0,x)……………………(1)
根据研究表明,神经网络的激活率处于15%-30%之间是最理想的,而当Relu函数的输入小于0时是不激活的,所以ReLu函数可以采用一个较小的激活率,比如激活率为15%。
上述网络结构中,采用卷积层提取出数据点(时间序列)之间的联系,采用池化层压缩参数,采用多个卷积层和多个池化层,提取更加精细的指标特征,从而提高模型的准确性。
确定网络结构之后,采用python的keras框架搭建卷积神经网络,将训练样本集按照比例7:3划分为训练集和验证集。采用训练集对卷积神经网络进行迭代训练40次,每次迭代训练都可以获得一个候选模型,然后采用验证集对各个候选模型进行验证,确定各个候选模型的损失函数,选取损失函数最小的候选模型作为训练好的卷积神经网络模型。
第三、分类过程:
获取30天的目标业务指标的历史监测数据,每天包括1440个数据点,然后采用5分钟的时间窗口对一天内的数据点进行压缩,获得288个数据点。
针对一天的历史监测数据对应的288个数据点,如图5所示,将288个数据点作为一维图像(288*1*1,其中,288*1表示图像高度288和图像宽度1,1表示通道数1),输入训练好的卷积神经网络模型。
卷积层1基于属性参数(3*1*4)对一维图像(288*1*1)进行特征提取,获得第一特征图像(286*1*4,其中,286*1表示图像高度286和图像宽度1,4表示通道数4)。
将第一特征图像输入卷积层2,卷积层2基于属性参数(3*1*1)对第一特征图像(286*1*4)进行特征提取,获得第二特征图像(284*1*4,其中,284*1表示图像高度284和图像宽度1,4表示通道数4)。
将第二特征图像输入池化层1,池化层1基于属性参数(3*1)对第二特征图像(284*1*4)进行下采样,获得第一池化图像(94*1*4,其中,94*1表示图像高度94和图像宽度1,4表示通道数4)。
将第一池化图像输入卷积层3,卷积层3基于属性参数(3*1*4)对第一池化图像(94*1*4)进行特征提取,获得第三特征图像(92*1*16,其中,92*1表示图像高度92和图像宽度1,16表示通道数16)。
将第三特征图像输入池化层2,池化层2基于属性参数(3*1)对第三特征图像(92*1*16)进行下采样,获得第二池化图像(30*1*16,其中,30*1表示图像高度30和图像宽度1,16表示通道数16)。
将第二池化图像输入卷积层4,卷积层4基于属性参数(3*1*1)对第二池化图像(30*1*16)进行特征提取,获得第四特征图像(28*1*16,其中,28*1表示图像高度28和图像宽度1,16表示通道数16)。
将第四特征图像输入池化层3,池化层3基于属性参数(3*1)对第四特征图像(28*1*16)进行下采样,获得第三池化图像(9*1*16,其中,9*1表示图像高度9和图像宽度1,16表示通道数16)。
将第三池化图像(9*1*16)输入压平层展开,获得第五特征图像(144*1*1,其中,144*1表示图像高度144和图像宽度1,1表示通道数1)。
将第五特征图像(144*1*1)输入全连接网络,全连接网络基于第五特征图像中的局部特征与各个类别之间的相似度,将第五特征图像中的144个局部特征划分至随机波动指标、周期性指标、平稳指标三个类别中,然后根据随机波动指标、周期性指标、平稳指标三个类别中划分的局部特征的数量,确定随机波动指标、周期性指标、平稳指标这三个类别对应的概率,将概率最大类别,作为目标业务指标的第一指标标签。
另外,在实际应用中,可以预先将上述各个过程封装成不同的函数,后续可以直接调用函数实现模型搭建、模型训练、业务指标分类等。比如,用model.compile()函数建好模型,用model.fit()函数进行训练,最后用model.save_weights()函数将模型存起来。在实际应用中,需要提取模型时,调用model.load_weights()函数将模型加载好,然后调用model.predict函数预测目标业务指标的第一指标标签。
本申请实施例中,采用卷积神经网络模型自动预测业务指标的指标标签,既提高了打标签的效率,又降低了人力成本。其次,业务指标的监测数据较多,而卷积神经网络模型通过局部连接、权值共享、下采样,可以减少参数的数量,做到特征的提取压缩。利用多个卷积层和多个池化层进行特征提取,获得了各像素点之间的位置关系,同时解决全连接网络的梯度传导问题,提高了模型的性能,进而提高了预测获得的指标标签的准确性。
需要说明的是,本申请实施例中,卷积神经网络的结构并不仅限于上述实施例介绍的结构,可以根据实际需要调整卷积神经网络中卷积层和池化层的数量以及位置关系,另外,在对业务指标进行分类时,也不仅限于采用卷积神经网络模型,还可以是支持向量机、决策树、K聚类等具备分类功能的模型,对此,本申请不做具体限定。
可选地,本申请实施例中除了业务指标之外,还包括基础指标,其中,基础指标包括主机指标和程序运行时指标,主机指标又可以分为容器指标、虚拟机指标等,比如,CPU、内存、IO、网络等。程序运行时指标包括Java虚拟机运行时产生的各种指标,比如活跃线程数、Buffer大小、内存大小等。
本申请实施例对基础指标进行异常检测的方法如图6所示,包括以下步骤:
步骤S601,获取目标基础指标的第二指标标签以及第二监测数据。
具体地,目标基础指标的第二指标标签是基于目标基础指标的名称,通过正则匹配方式从指标标签库中获取的。指标标签库包括设计好的各类指标标签,比如:CPU使用率、CPU1分钟负载、CPU5分钟负载、CPU15分钟负载、IO读次数、IO写次数、内存使用率、网络进包数、丢包数、GC(Garbage Collection,即垃圾回收,计算机术语)时间、活跃线程数等。通过监控系统获得各个基础指标的名称,然后采用基础指标的名称正则匹配指标标签库中各个指标标签,获得基础指标的第二指标标签。
另外,对于重要指标或者通过正则匹配和卷积神经网络模型依然没有打上标签的指标,可以采用人工方式打标签。
步骤S602,基于目标基础指标的第二指标标签,从异常检测规则库中获得对应的第二检测规则。
步骤S603,采用第二检测规则,对第二监测数据进行异常检测,确定目标基础指标是否为异常指标。
本申请实施例中,通过正则匹配指标标签库的方式,自动为各个基础指标打上指标标签,故不需要人工为各个基础指标打标签,既提高了打标签的效率,又降低了人力成本。其次,从异常检测规则库中第二检测规则,对第二监测数据进行异常检测,确定基础指标是否为异常指标。针对不同指标的特征采用不同的检测规则,满足了不同指标的异常检测需求,从而提高了异常检测的准确性。
可选地,上述异常检测规则库是预先构建的,异常检测规则库至少包括以下几种异常检测模型:
1、同环比,用于反应指标的波动范围,也可以反应指标的周期性。
同环比包括同比和环比,其中,同比是通过比较当前时间点的监测数据与过去一段时间内同一时间点的监测数据平均值获得的,具体如以下公式(2)所示:
f
其中,f
举例来说,设定当前时间为4月19日14:23分,获取在4月19日14:23分目标业务指标的监测数据,然后获取过去7天内14:21分-14:25分目标业务指标的监测数据,即4月18日14:21分-14:25分、4月17日14:21分-14:25分等7天内目标业务指标的监测数据,然后计算获取的7天内目标业务指标的监测数据平均值,之后再采用上述公式(2)计算目标业务指标的同比。
环比是通过比较当前时间点的监测数据与过去各个周期内同一时间点的监测数据平均值获得的,具体如以下公式(3)所示:
f
其中,f
举例来说,设定当前时间为4月19日(周一)14:23分,获取在4月19日14:23分目标业务指标的监测数据,同时获取过去4周内周一14:21分-14:25分的监测数据,即4月12日14:21分-14:25分、4月5日14:21分-14:25分等4个周一的目标业务指标的监测数据,然后计算获取的4个周一的目标业务指标的监测数据平均值,之后再采用上述公式(3)计算目标业务指标的环比。
将同比与环比的平均值作为同环比,预先设置同环比的告警条件,比如同环比大于50%。在同环比满足告警条件时触发告警。
2、一阶导数和二阶导数。
一阶导数反映了指标的变化趋势,二阶导数反映了斜率的变化。
3、标准差模型。
标准差表示指标的监测数据的离散程度。
4、孤立随机森林模型。
孤立随机森林用于孤立指标的监测数据中的异常数据点,反映了数据的离散情况。
5、移动平均模型。
移动平均模型用于对指标未来的监测数据进行预测。
6、整合移动平均自回归模型,Autoregressive Integrated Moving Averagemodel,简称ARIMA模型。
ARIMA模型用于对指标未来的监测数据进行预测。
7、波动检测模型。
具体地,通过比较当前时间点的监测数据与过去一段时间内的监测数据平均值确定指标的波动值,具体以下公式(4)所示:
f
其中,f
进一步地,预先设置波动值对应的告警条件,比如,针对基础指标,若波动值位于波动范围[-20%,30%]之间,则不触发告警,若波动值没有位于波动范围[-20%,30%]之间,则触发告警。
又比如,针对业务指标,若波动值位于波动范围[-30%,20%]之间,则不触发告警,若波动值没有位于波动范围[-30%,20%]之间,则触发告警。
8、波动趋势识别模型。
具体地,波动趋势识别模型用于识别指标的监测数据的变化趋势,变化趋势包括趋增和趋减,在具体识别时,可以从分钟维度、小时维度、天维度等多个维度的识别波动趋势。
举例来说,分钟维度:获取当前5分钟内的第一监测数据平均值,以及过去10个5分钟内的监测数据平均值。对过去10个5分钟内的监测数据平均值求平均,获得第二监测数据平均值,再计算第一监测数据平均值与第二监测数据平均值之间的分钟维度波动值。基于分钟维度波动值判断分钟维度的监测数据的变化趋势。同时设置波动范围[-10%,10%],若分钟维度波动值位于波动范围[-10%,10%]之间,则不触发告警,若分钟维度波动值没有位于波动范围[-10%,10%]之间,则触发告警。
小时维度:
1、获取当前1小时(今天17点至18点)内的第一监测数据平均值,以及过去10个小时内(今天7点至17点)的监测数据平均值。对过去10个小时内的监测数据平均值求平均,获得第二监测数据平均值,再计算第一监测数据平均值与第二监测数据平均值之间的小时维度波动值。基于小时维度波动值判断小时维度的监测数据的变化趋势。同时设置波动范围[-10%,10%],若小时维度波动值位于波动范围[-10%,10%]之间,则不触发告警,若小时维度波动值没有位于波动范围[-10%,10%]之间,则触发告警。
2、获取当前1小时(今天17点至18点,今天为周一)内的第一监测数据平均值,以及上周一同一时间点过去10个小时(上周一7点至17点)内的监测数据平均值。对过去10个小时内的监测数据平均值求平均,获得第二监测数据平均值,再计算第一监测数据平均值与第二监测数据平均值之间的小时维度波动值。基于小时维度波动值判断小时维度的监测数据的变化趋势。同时设置波动范围[-10%,10%],若小时维度波动值位于波动范围[-10%,10%]之间,则不触发告警,若小时维度波动值没有位于波动范围[-10%,10%]之间,则触发告警。
天维度:
1、获取今天的第一监测数据平均值,以及昨天的第二监测数据平均值。然后计算第一监测数据平均值与第二监测数据平均值之间的天维度波动值。基于天维度波动值判断天维度的监测数据的变化趋势。同时设置波动范围[-10%,10%],若天维度波动值位于波动范围[-10%,10%]之间,则不触发告警,若天维度波动值没有位于波动范围[-10%,10%]之间,则触发告警。
2、获取今天的第一监测数据平均值,以及过去一个月的第二监测数据平均值。然后计算第一监测数据平均值与第二监测数据平均值之间的天维度波动值。基于天维度波动值判断天维度的监测数据的变化趋势。同时设置波动范围[-10%,10%],若天维度波动值位于波动范围[-10%,10%]之间,则不触发告警,若天维度波动值没有位于波动范围[-10%,10%]之间,则触发告警。
8、综合识别模型。
基于上述1-6所述模型输出的异常检测结果,训练一个综合识别模型。训练结束后,针对指标的监测数据,先分别采用上述1-6所述模型,确定指标的多个异常检测结果,然后将多个异常检测结果输入综合识别模型,获得一个更加准确的综合检测结果。
具体地,采用上述1-6所述的模型,对指标的历史监测数据进行处理,获得用于训练综合识别模型的训练样本。
针对任意一段时间内的历史监测数据,基于指标的历史监测数据计算指标的同环比、一阶导数、二阶导数。将指标的历史监测数据输入标准差模型,获得指标的标准差。将指标的历史监测数据输入孤立随机森林模型,获得指标的异常数据点。将指标的历史监测数据输入移动平均模型,获得指标的第一预测监控数据。将指标的历史监测数据输入ARIMA模型,获得指标的第二预测监控数据。
将上述获得的各个异常检测结果,以及预先标记的指标的综合检测结果组成一个训练样本,各个异常检测结果包括指标的同环比、一阶导数、二阶导数、标准差、异常数据点、第一预测监控数据、第二预测监控数据,预先标记的综合检测结果可以是各个异常检测结果中准确性最高的异常检测结果,也可以是结合各个异常检测结果获得的综合检测结果。其他的训练样本可以采用相同的方式构建,此处不再赘述。
采用获得的训练样本对综合识别模型进行训练。在训练结束后,针对目标业务指标的监测数据,基于目标业务指标的监测数据计算目标业务指标的同环比、一阶导数、二阶导数。将目标业务指标的监测数据输入标准差模型,获得目标业务指标的标准差。将目标业务指标的监测数据输入孤立随机森林模型,获得目标业务指标的异常数据点。将目标业务指标的监测数据输入移动平均模型,获得目标业务指标的第一预测监控数据。将目标业务指标的监测数据输入ARIMA模型,获得目标业务指标的第二预测监控数据。
之后再将目标业务指标的同环比、一阶导数、二阶导数、标准差、异常数据点、第一预测监控数据、第二预测监控数据输入训练好的综合识别模型,获得目标业务指标的综合检测结果。
需要说明的是,本申请实施例中并不限于结合上述1-6所述模型的输出结果构建综合识别模型,还可以采用上述1-6所述模型中部分模型的输出结果构建综合识别模型,对此,本申请不做具体限定。
本申请实施例中,异常检测规则库预先配置有各种各样的异常检测算法,比如时间序列算法、神经网络算法,数据概率统计算法等,从而满足各种指标的异常检测需求。
可选地,在异常检测规则库中各个异常检测模型的基础上,本申请实施例针对各类指标的特点,为各类指标编排了对应的异常检测规则。
一种可能的实施方式,目标业务指标的第一指标标签表征目标业务指标为周期性指标。采用标准差模型、孤立随机森林模型和移动平均模型,分别对第一监测数据进行异常检测,获得各个模型输出的异常检测结果。若获得的各个异常检测结果中存在至少两个异常检测结果,表征目标业务指标为异常指标,则确定目标业务指标为异常指标;否则,确定目标业务指标为正常指标。
具体地,将第一监测数据输入标准差模型,确定目标业务指标的标准差。然后判断目标业务指标的标准差是否在预设范围内,若是,则确定目标业务指标为正常指标,否则确定目标业务指标为异常指标。
采用孤立随机森林模型,对第一监测数据进行异常检测,确定第一监测数据中的异常点,然后根据第一监测数据中的异常点,确定第一监测数据的离散程度。若第一监测数据的离散程度大于预设阈值,则确定目标业务指标为异常指标,否则确定目标业务指标为正常指标。
采用移动平均模型,基于第一监测数据预测目标业务指标在未来一段时间的监测数据,然后根据未来一段时间的监测数据,判断目标业务指标是否为异常指标。
当上述三种模型输出的异常检测结果中,至少存在两个异常检测结果表明目标业务指标为异常指标时,确定目标业务指标为异常指标。
可选地,确定目标业务指标为异常指标之后,确定第一监测数据的同环比是否满足预设告警条件,若是,则触发告警。
具体地,计算第一监测数据的同比和环比,然后将第一监测数据的同比和环比的平均值,作为第一监测数据的同环比,告警条件可以根据实际需求进行设置,比如,第一监测数据的同环比大于50%。同比、环比以及同环比的计算方式在前文已有介绍,此处不再赘述。
本申请实施例中,根据周期性指标的周期性变化特点,为周期性指标编排了标准差模型、孤立随机森林模型和移动平均模型进行异常检测,从而提高了异常检测的能力。其次,综合标准差模型、孤立随机森林模型和移动平均模型三个异常检测模型的异常检测结果,判断目标业务指标是否为异常指标,避免了单个模型检测异常时的片面性,提高了异常检测的准确性。
一种可能的实施方式,目标业务指标的第一指标标签表征目标业务指标为周期性指标,且等级大于预设阈值。
确定第一监测数据的同环比以及目标导数,然后采用标准差模型、孤立随机森林模型、移动平均模型以及整合移动平均自回归模型,分别对第一监测数据进行异常检测,获得各个模型输出的异常检测结果。再采用已训练的综合识别模型,基于获得的各个异常检测结果、同环比以及目标导数,确定目标业务指标是否为异常指标。
具体地,目标业务指标的等级大于预设阈值时,说明目标业务指标为重要指标,重要指标对异常检测的准确性要求较高。第一监测数据的目标导数包括第一监测数据的一阶导数和二阶导数,综合识别模型为神经网络模型,训练综合识别模型的过程在前文已有介绍,此处不再赘述。
基于第一监测数据计算目标业务指标的同环比、一阶导数、二阶导数。将第一监测数据输入标准差模型,获得目标业务指标的标准差。将第一监测数据输入孤立随机森林模型,获得目标业务指标的异常数据点。将第一监测数据输入移动平均模型,获得目标业务指标的第一预测监控数据。将第一监测数据输入ARIMA模型,获得目标业务指标的第二预测监控数据。
之后再将目标业务指标的同环比、一阶导数、二阶导数、标准差、异常数据点、第一预测监控数据、第二预测监控数据输入训练好的综合识别模型,获得目标业务指标的综合检测结果。再基于目标业务指标的综合检测结果确定目标业务指标是否为异常指标。
本申请实施例中,综合同环比、目标导数、标准差模型、孤立随机森林模型、移动平均模型以及整合移动平均自回归模型,确定目标业务指标是否为异常指标,避免了单个模型检测异常时的片面性,提高了异常检测的准确性,满足了重要指标对异常检测的准确性的要求。
一种可能的实施方式,目标业务指标的第一指标标签表征目标业务指标为平稳指标或随机波动指标。
采用波动检测模型,对第一监测数据进行波动检测,确定目标业务指标的目标波动值。然后采用波动趋势识别模型,对第一监测数据进行波动趋势识别,确定目标业务指标的第一波动趋势。若目标波动值和/或第一波动趋势,满足相应的告警条件时,则确定目标业务指标为异常指标并触发告警;否则,确定目标业务指标为正常指标。
具体地,目标业务指标的第一波动趋势可以是分钟维度、小时维度、天维度等维度的波动趋势。告警条件可以根据实际需求进行设置,比如,目标波动值对应的告警条件可以是波动范围没有位于[-10%,10%],第一波动趋势对应的告警条件可以是:趋增时,波动范围大于20%,趋减时,波动范围大于30%。当目标波动值和第一波动趋势中,至少存在一个参数满足相应的告警条件时,则确定目标业务指标为异常指标并触发告警。计算目标波动值和第一波动趋势的方式在前文中已有介绍,此处不再赘述。
本申请实施例中,根据平稳指标或随机波动指标的特点,为平稳指标或随机波动指标编排了波动检测模型和波动趋势识别模型,使得待检测指标与检测模型之间更加匹配,从而提高了异常检测的准确性。
一种可能的实施方式,采用波动趋势识别模型,对第二监测数据进行波动趋势识别,确定目标基础指标的第二波动趋势。若第二波动趋势满足相应的告警条件,或者第二监测数据超出预设阈值范围,则确定目标基础指标为异常指标并触发告警;否则,确定目标基础指标为正常指标。
具体地,预先设置第二监测数据的预设阈值范围,当第二监测数据超出预设阈值范围时,确定目标基础指标为异常指标并触发告警。为了提前获知第二监测数据的异常情况,本申请实施例中采用波动趋势识别模型,对第二监测数据进行波动趋势识别,确定目标基础指标的第二波动趋势。当第二波动趋势满足相应的告警条件,比如,第二波动趋势为趋增,且波动值大于10%时,说明增长过快,即便此时第二监测数据没有超出预设阈值范围,也可以进行告警,从而保证了系统的安全性。
需要说明的是,在异常检测规则库中设置各个异常检测模型的基础上,为各类指标编排的异常检测规则不限于上述几种,还可以是其他规则,比如针对每种类型的指标配置一种异常检测算法等。
基于相同的技术构思,本申请实施例提供了一种指标异常检测装置,如图7所示,该装置700包括:
获取模块701,用于获取目标业务指标的第一指标标签以及第一监测数据,所述目标业务指标的第一指标标签是通过对目标业务指标的历史监测数据进行特征提取获得历史指标特征,并基于所述历史指标特征预测获得的;
匹配模块702,用于基于所述目标业务指标的第一指标标签,从异常检测规则库中获得对应的第一检测规则;
检测模块703,用于采用所述第一检测规则,对所述第一监测数据进行异常检测,确定所述目标业务指标是否为异常指标。
可选地,还包括标签识别模块704;
所述标签识别模块704具体用于:
采用N个特征提取模块依次对所述目标业务指标的历史监测数据进行特征提取,获得所述目标业务指标的历史指标特征,其中,每个特征提取模块至少包括卷积层和池化层,N为预设正整数。
可选地,所述N个特征提取模块包括第一特征提取模块、第二特征提取模块和第三特征提取模块,其中,第一特征提取模块包括第一卷积层、第二卷积层和第一池化层,所述第二特征提取模块包括第三卷积层和第二池化层,所述第三特征提取模块包括第四卷积层和第三池化层。
可选地,所述标签识别模块704具体用于:
采用所述第一卷积层、所述第二卷积层以及所述第一池化层,依次对所述目标业务指标的历史监测数据进行特征提取,获得第一特征;
采用所述第三卷积层以及所述第二池化层,依次对所述第一特征进行特征提取,获得第二特征;
采用所述第四卷积层以及所述第三池化层,依次对所述第二特征进行特征提取,获得所述目标业务指标的历史指标特征。
可选地,所述标签识别模块704具体用于:
采用压平层对所述历史指标特征展开后输入全连接网络,获得所述目标业务指标的第一指标标签。
可选地,所述目标业务指标的第一指标标签表征所述目标业务指标为周期性指标;
所述检测模块703具体用于:
采用标准差模型、孤立随机森林模型和移动平均模型,分别对所述第一监测数据进行异常检测,获得各个模型输出的异常检测结果;
若获得的各个异常检测结果中存在至少两个异常检测结果,表征所述目标业务指标为异常指标,则确定所述目标业务指标为异常指标;否则,确定所述目标业务指标为正常指标。
可选地,所述检测模块703还用于:
所述确定所述目标业务指标为异常指标之后,若确定所述第一监测数据的同环比满足预设告警条件,则触发告警。
可选地,所述目标业务指标的第一指标标签表征所述目标业务指标为周期性指标,且等级大于预设阈值;
所述检测模块703具体用于:
确定所述第一监测数据的同环比以及目标导数;
采用标准差模型、孤立随机森林模型、移动平均模型以及整合移动平均自回归模型,分别对所述第一监测数据进行异常检测,获得各个模型输出的异常检测结果;
采用已训练的综合识别模型,基于获得的各个异常检测结果、所述同环比以及所述目标导数,确定所述目标业务指标是否为异常指标。
可选地,所述目标业务指标的第一指标标签表征所述目标业务指标为平稳指标或随机波动指标;
所述检测模块703具体用于:
采用波动检测模型,对所述第一监测数据进行波动检测,确定所述目标业务指标的目标波动值;
采用波动趋势识别模型,对所述第一监测数据进行波动趋势识别,确定所述目标业务指标的第一波动趋势;
若所述目标波动值和/或所述第一波动趋势,满足相应的告警条件时,则确定所述目标业务指标为异常指标并触发告警;否则,确定所述目标业务指标为正常指标。
可选地,所述获取模块701还用于:
获取目标基础指标的第二指标标签以及第二监测数据,所述目标基础指标的第二指标标签是基于所述目标基础指标的名称,通过正则匹配方式从指标标签库中获取的;
所述匹配模块702还用于:
基于所述目标基础指标的第二指标标签,从异常检测规则库中获得对应的第二检测规则;
所述检测模块703还用于:
采用所述第二检测规则,对所述第二监测数据进行异常检测,确定所述目标基础指标是否为异常指标。
可选地,所述检测模块703具体用于:
采用波动趋势识别模型,对所述第二监测数据进行波动趋势识别,确定所述目标基础指标的第二波动趋势;
若所述第二波动趋势满足相应的告警条件,或者所述第二监测数据超出预设阈值范围,则确定所述目标基础指标为异常指标并触发告警;否则,确定所述目标基础指标为正常指标。
本申请实施中,通过对业务指标的历史监测数据进行特征提取获得历史指标特征,然后基于历史指标特征预测获得业务指标的第一指标标签,故不需要人工为各个业务指标打上指标标签,实现打标签自动化,既提高了打标签的效率,又降低了人力成本。其次,基于目标业务指标的第一指标标签,从异常检测规则库中获得对应的第一检测规则,然后采用第一检测规则,对第一监测数据进行异常检测,确定目标业务指标是否为异常指标。针对不同指标的特征采用不同的异常检测规则,满足了不同指标的异常检测需求,从而提高了异常检测的准确性。
基于相同的技术构思,本申请实施例提供了一种计算机设备,计算机设备可以是终端或服务器,如图8所示,包括至少一个处理器801,以及与至少一个处理器连接的存储器802,本申请实施例中不限定处理器801与存储器802之间的具体连接介质,图8中处理器801和存储器802之间通过总线连接为例。总线可以分为地址总线、数据总线、控制总线等。
在本申请实施例中,存储器802存储有可被至少一个处理器801执行的指令,至少一个处理器801通过执行存储器802存储的指令,可以执行上述指标异常检测方法中所包括的步骤。
其中,处理器801是计算机设备的控制中心,可以利用各种接口和线路连接计算机设备的各个部分,通过运行或执行存储在存储器802内的指令以及调用存储在存储器802内的数据,从而进行指标异常检测。可选的,处理器801可包括一个或多个处理单元,处理器801可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解的是,上述调制解调处理器也可以不集成到处理器801中。在一些实施例中,处理器801和存储器802可以在同一芯片上实现,在一些实施例中,它们也可以在独立的芯片上分别实现。
处理器801可以是通用处理器,例如中央处理器(CPU)、数字信号处理器、专用集成电路(Application Specific Integrated Circuit,ASIC)、现场可编程门阵列或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件,可以实现或者执行本申请实施例中公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者任何常规的处理器等。结合本申请实施例所公开的方法的步骤可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及软件模块组合执行完成。
存储器802作为一种非易失性计算机可读存储介质,可用于存储非易失性软件程序、非易失性计算机可执行程序以及模块。存储器802可以包括至少一种类型的存储介质,例如可以包括闪存、硬盘、多媒体卡、卡型存储器、随机访问存储器(Random AccessMemory,RAM)、静态随机访问存储器(Static Random Access Memory,SRAM)、可编程只读存储器(Programmable Read Only Memory,PROM)、只读存储器(Read Only Memory,ROM)、带电可擦除可编程只读存储器(Electrically Erasable Programmable Read-Only Memory,EEPROM)、磁性存储器、磁盘、光盘等等。存储器802是能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。本申请实施例中的存储器802还可以是电路或者其它任意能够实现存储功能的装置,用于存储程序指令和/或数据。
基于同一发明构思,本申请实施例提供了一种计算机可读存储介质,其存储有可由计算机设备执行的计算机程序,当程序在计算机设备上运行时,使得计算机设备执行上述指标异常检测方法的步骤。
本领域内的技术人员应明白,本发明的实施例可提供为方法、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 一种指标异常检测方法、装置、设备及存储介质
- 调用链指标异常的检测方法、装置、电子设备及存储介质