基于机器学习的数据库管理系统自动调优系统及方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及一种数据库调优方法,更具体的说,本发明主要涉及一种基于机器学习的数据库管理系统自动调优系统及方法。
背景技术
数据库管理系统有很多可调节的配置参数,一个数据库管理系统的性能很大程度上取决于这些配置参数,但是,一方面数据库管理系统的配置参数调优是一个NP-hard的问题,另一方面传统的DBA人工调优时间长花费高,且只调优了很小一部分参数。事实上,当前的主流数据库调优还是人工调优,比如公司雇佣高级DBA帮助数据库管理系统调优。另外,也存在一些基于启发式的调优方法,比如PGTune,需要提供硬件配置和数据库版本,PGTune会返回一个计算后的结果。由前述可知,现有的数据库管理系统调优的主流解决方案是人工调优,其次是基于启发式的调优方案,也有一些学术界的调优方案,主要是没有经过工业化的洗礼,方案的可行性有待进一步商榷。而人工调优方案最大的缺点是就是人,人工成本高,调试周期长,而且数据库管理系统严重依赖环境,配置参数迁移成本高。如果有成千上万个数据库集群,人工调优基本上是不可能的。当然人工调优最大的优点也是人,人能处理各种异常情况,可适应性强。启发式的调优方案的缺点是无法找到最优的调优方案,但启发式调优方案会权衡调优时间和成本等。基于机器学习和深度强化学习的调优方案还没有被工业界大量采用,可能还要考虑更多的场景。
发明内容
本发明的目的之一在于针对上述不足,提供一种基于机器学习的数据库管理系统自动调优系统及方法,以期望解决现有技术中数据库人工调优成本高,周期长,启发式调优方案无法找到最佳的调优方案等技术问题。
为解决上述的技术问题,本发明采用以下技术方案。
本发明一方面提供了一种基于机器学习的数据库管理系统自动调优系统,所述系统包括:
客户端,用于启动目标数据库管理系统和基准测试程序,且在基准测试程序收集完成目标数据库管理系统的指标和测试数据后,将所述指标和测试数据传输至服务端。
服务端,用于将所述指标和测试数据解析后,保存到模型数据库中。
服务端还用于同时将所述指标和测试数据传输至工作负载特征化模块。
工作负载特征化模块选择确定指标和测试数据中的冗余部分,并进行裁剪,然后将裁剪后的指标和测试数据传输至配置参数调整模块。
配置参数调整模块选择确定指标和测试数据中最具影响负载的配置参数,然后将所述指标和测试数据传输至自动化调优模块。
自动化调优模块根据模型数据库中的所述指标和测试数据解析,以及指标和测试数据中最具影响负载的配置参数,产生当前最优的数据库配置参数。
服务端还用于将所述当前最优的数据库配置参数传输至客户端。
客户端还用于根据所述当前最优的数据库配置参数,更新目标数据库管理系统的配置,再次运行基准测试程序,判断当前目标数据库的负载是否达到预期,或者搜索空间是否耗尽。
作为优选,进一步的技术方案是:所述工作负载特征化模块通过因子分析法确定指标和测试数据中的冗余部分。
更进一步的技术方案是:所述配置参数调整模块利用Lasso的方法得到配置参数个数的超参数,所述超参数为指标和测试数据中最具影响负载的配置参数。
本发明所提供的一种基于机器学习的数据库管理系统自动调优方法,所述的方法包括如下步骤:
步骤A、客户端启动目标数据库管理系统和基准测试程序,且在基准测试程序收集完成目标数据库管理系统的指标和测试数据后,将所述指标和测试数据传输至服务端。
步骤B、服务端将所述指标和测试数据解析后,保存到模型数据库中;并同时将所述指标和测试数据传输至工作负载特征化模块。
步骤C、工作负载特征化模块选择确定指标和测试数据中的冗余部分,并进行裁剪,然后将裁剪后的指标和测试数据传输至配置参数调整模块。
步骤D、配置参数调整模块选择确定指标和测试数据中最具影响负载的配置参数,然后将所述指标和测试数据传输至自动化调优模块。
步骤E、自动化调优模块根据模型数据库中的所述指标和测试数据解析,以及指标和测试数据中最具影响负载的配置参数,产生当前最优的数据库配置参数。
步骤F、服务端将所述当前最优的数据库配置参数传输至客户端。
步骤G、客户端根据所述当前最优的数据库配置参数,更新目标数据库管理系统的配置,并再次运行基准测试程序,然后判断当前目标数据库的负载是否达到预期;如判断结果为是,则继续判断搜索空间是否耗尽;反之则重复步骤A至步骤G;如判断搜索空间是否耗尽的结果为否,则按照当前最优的数据库配置参数 对目标数据库管理系统进行调优,反之则重复步骤A至步骤G。
作为优选,进一步的技术方案是:所述工作负载特征化模块通过因子分析法确定指标和测试数据中的冗余部分。
更进一步的技术方案是:所述配置参数调整模块利用Lasso的方法得到配置参数个数的超参数,所述超参数为指标和测试数据中最具影响负载的配置参数。
与现有技术相比,本发明的有益效果之一是:通过机器学习建模的方式进行数据库管理系统调优,降低数据库负载,相对于人工调优的方式而言,机器学习的自动调优能够提升寻找最优的数据库配置参数的速度,节约人工成本,应用范围广阔。
附图说明
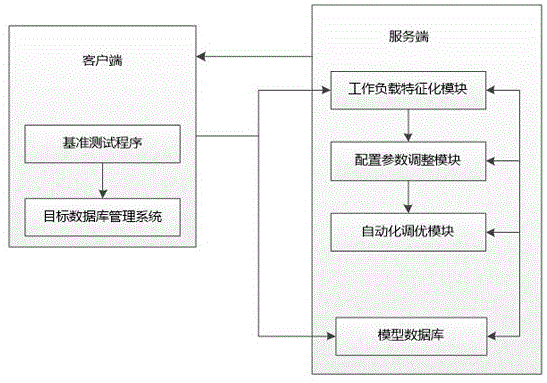
图1为用于说明本发明一个实施例的系统结构示意框图。
图2为用于说明本发明另一个实施例的方法流程图。
具体实施方式
本发明中所指的数据库管理系统自动调优,是指数据库管理系统有很多可调节的配置参数,一个数据库管理系统的性能很大程度上取决于这些配置参数。因此如何准确的找到这些配置参数,对于降低数据库负载有着直接的关系。目前通过DBA人工调优的成本很高,且只调优了很小一部分参数。如果利用机器学习来实现一种数据库管理系统自动调优的方法,不但可以节约大量的人力成本,而且调优速度快,调优范围广。
本发明所称的数据库管理系统自动调优主要的功能有三块组成,分别是工作负载特征化模块、配置参数调整模块和自动化调优模块。工作负载特征化模块使用数据库内部指标来特征化工作负载,数据库内部指标有一定的冗余性,可以利用因子分析的方法对数据库指标剪裁并利用聚类去除冗余的指标以降低机器学习模型的复杂度;数据库管理系统有数百个配置参数,可能只有部分影响负载,配置参数调整模块利用Lasso的方法来选择最具影响负载的配置参数,为了优化配置参数个数这个超参数,我们通过不断增加参数个数来自动化这个过程;自动化调优模块是整个调优过程的粘合剂,自动化调优模块利用从基准测试中获取的测试数据,首先对工作负载特征化模块的模型进行调整,然后对配置参数调整模块的模型进行调整,最后基于历史的数据和当前数据产生可能最优的配置参数返回给数据库管理系统,数据库管理系统使用这个配置进行下一轮基准测试,并将数据传输给调优工具,不断迭代上面的过程直至数据库的管理系统达到了期望。
上述的Lasso,其全称为least absolute shrinkage and selection operator,译为最小绝对值收敛和选择算子、套索算法, 是一种同时进行特征选择和正则化(数学)的回归分析方法,旨在增强统计模型的预测准确性和可解释性,最初由斯坦福大学统计学教授Robert Tibshirani(英语:Robert Tibshirani)于1996年基于Leo Breiman的非负参数推断(Nonnegative Garrote, NNG)提出。上述的超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。
因此本发明旨在解决的技术问题是减少人工参与,实现自动化调优,目标是提高数据库管理系统的负载,核心思想是基于机器学习的反馈迭代。
基准测试程序通过量化目标数据库管理系统的负载,并将测试和指标数据传送给数据库管理系统调优工具,调优工具主要分三个模块,工作负载特征化模块、配置参数调整模块和自动化调优模块。首先数据会保存到一个模型数据库中,其次当数据到达工作负载特征化模块,会结合模型数据库中的历史数据对负载模型进行调整,然后数据到达配置参数调整模块,同样结合模型数据库中的历史数据对配置参数模型进行调整,最后自动优化模块根据模型数据库的中的历史数据库和当前数据产生的可能最优的配置参数,并返回给数据库管理系统,数据库管理系统使用这个配置进行下一轮基准测试,并将数据传输给调优工具,循环往复直至数据库管理系统的负载达到了期望。
本发明所采用的是该方案是C/S架构,客户端主要收集数据库管理系统的基准测试数据,并将收集的数据传送给服务端,以及接收服务端推荐的配置参数,同时也有控制基准测试程序和目标数据库管理系统的功能(包括更新目标数据库管理系统配置,控制目标数据库管理系统和基准测试程序等)。
服务端主要接收客户端传送的测试和指标数据,主要有三个模块和一个模型数据库,三个模块分别是工作负载特征化模块、配置参数调整模块和自动化调优模块。服务端接收客户端传送来的数据,会先保存到模型数据库中,然后数据被依次传送给工作负载特征化模块、配置参数调整模块和自动化调优模块,然后自动调优模块会向客户端返回可能最优的配置参数。如此反复,直到达到了用户期望的负载或者搜索空间已经耗尽。
结合图1所示,本发明的一个实施例是一种基于机器学习的数据库管理系统自动调优系统,该系统包括客户端与服务端,其中:
客户端用于启动目标数据库管理系统和基准测试程序,且在基准测试程序收集完成目标数据库管理系统的指标和测试数据后,将指标和测试数据传输至服务端。
服务端用于将所述指标和测试数据解析后,保存到模型数据库中;正如图中所示出的,上述的服务端主要包括三个模块,分别为上述的工作负载特征化模块以及配置参数调整模块与自动化调优模块。
服务端还同时将上述指标和测试数据传输至工作负载特征化模块。
工作负载特征化模块选择确定指标和测试数据中的冗余部分,并进行裁剪,然后将裁剪后的指标和测试数据传输至配置参数调整模块。正如上述所提到的,工作负载特征化模块通过因子分析法确定指标和测试数据中的冗余部分。
配置参数调整模块选择确定指标和测试数据中最具影响负载的配置参数,然后将所述指标和测试数据传输至自动化调优模块。正如上述所提到的,配置参数调整模块利用Lasso的方法得到配置参数个数的超参数,所述超参数为指标和测试数据中最具影响负载的配置参数。
自动化调优模块根据模型数据库中的所述指标和测试数据解析,以及指标和测试数据中最具影响负载的配置参数,产生当前最优的数据库配置参数。
服务端还用于将当前最优的数据库配置参数传输至客户端。
客户端还用于根据所述当前最优的数据库配置参数,更新目标数据库管理系统的配置,再次运行基准测试程序,判断当前目标数据库的负载是否达到预期,或者搜索空间是否耗尽。
基于上述的系统,本发明的另个实施例是一种基于机器学习的数据库管理系统自动调优方法,该方法为计算机程序,如图2所示,是按照如下步骤执行的:
S1、完成客户端、基准测试程序和目标数据库管理系统之间的配置,由客户端启动目标数据库管理系统和基准测试程序,客户端的初始化工作完成,客户端启动一定时间间隔的基准测试程序。客户端等基准测试程序完成收集指标和测试数据的指标和测试数据,并将指标和测试数据按照一定的传输协议传输给服务端。
S2、服务端接收到客户端传输的指标和测试数据,并按照既定的协议解析后,保存到模型数据库中,等待后面的模块使用。
S3、在服务端中,当前会话的指标和测试数据会首先传送到工作负载特征化模块,该模块主要是利用数据库内部指标来构建工作负载模型,数据库内部指标有很大的冗余性,而且很多指标和负载没有关系,本实施例中利用因子分析的方法选择和工作负载相关的指标,并利用聚类算法把类似的指标分类,选择最具代表性的指标来解决冗余性问题。利用模型数据库中的数据和当前指标和测试数据数据来构建工作负载模型。
S4、然后指标和测试数据会传送到配置参数调整模块,配置参数类别多,为了构建配置参数模型,使用Lasso的方法来选择最具影响负载的配置参数,为了优化配置参数个数这个超参数,可通过不断增加参数个数来自动化该过程。
S5、最后指标和测试数据到达自动化调优模块,该模块会根据模型数据库中的历史数据以及指标和测试数据产生可能最优的数据库配置参数。
S6、服务端将配置参数数据传送给客户端,客户端根据配置参数来更新目标数据库的配置,并根据情况决定是否重启,运行基准测试程序,并判断负载是否达到了期望,或者搜索空间是否耗尽。如果没有满足上面两个条件,继续重复上述步骤S1-S5,直至找到的配置参数满足前述的两个条件为止。
在本实施例中,通过机器学习建模的方式进行数据库管理系统调优,降低数据库负载,相对于人工调优的方式而言,机器学习的自动调优能够提升寻找最优的数据库配置参数的速度,节约人工成本,且调优范围广。
除上述以外,还需要说明的是在本说明书中所谈到的“一个实施例”、“另一个实施例”、“实施例”等,指的是结合该实施例描述的具体特征、结构或者特点包括在本申请概括性描述的至少一个实施例中。在说明书中多个地方出现同种表述不是一定指的是同一个实施例。进一步来说,结合任一实施例描述一个具体特征、结构或者特点时,所要主张的是结合其他实施例来实现这种特征、结构或者特点也落在本发明的范围内。
尽管这里参照本发明的多个解释性实施例对本发明进行了描述,但是,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。更具体地说,在本申请公开、附图和权利要求的范围内,可以对主题组合布局的组成部件和/或布局进行多种变型和改进。除了对组成部件和/或布局进行的变型和改进外,对于本领域技术人员来说,其他的用途也将是明显的。