一种基于MPP架构的多源异构数据聚合查询方法及装置
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及数据分析处理领域,特别涉及一种基于MPP架构的多源异构数据聚合查询方法及装置。
背景技术
随着终端安全的快速发展,越来越多的分布式系统应用在政企业务中,其中主机资产越来越被客户所重视,对于主机资产数据的识别和梳理显得尤为重要。现在的主机资产信息不仅包括主机的基本硬件和软件信息,还包括主机上的账号、服务等大量信息。当前,迫切需要将这些不同结构的数据从多台主机上获取并汇总,再以不同维度进行数据聚合,为用户展示多视角的统计数据。
现有技术中,对于处理大数据合并同时能提供实时查询的架构方案主要有以下几种:1、将数据存储在各个应用服务中,然后通过大数据引擎将各个应用服务中的数据汇总聚合,如专利号为CN112559567A的专利中将多个查询结果反馈到OLAP查询引擎中,但在查询请求量较大时,该方案从各个应用服务获取数据会出现执行缓慢的问题,降低了查询效率;2、采用OLAP类型的数据库作为存储方案,但现有技术对数据库架构的升级改造涉及对历史数据的迁移,上述迁移方式风险高、难度大,并不适用大数据场景,OLAP类型的数据库也不具备事务的特性,并不能保证实时数据的准确性;3、使用传统OLTP数据库做SQL优化或者分库分表优化等方案,例如申请号为CN108804459B的专利通过优化SQL查询的方式,一定程度上缩短了查询的响应时间,但涉及的数据量比较大且还需要排序分页,数据查询的整体性能较差。
发明内容
本发明实施例的目的是提供一种基于MPP架构的多源异构数据聚合查询方法及装置,通过第一数据库和第二数据库之间进行数据同步,将数据临时写入第一数据库中,基于关系型数据库事务保证数据的准确性,基于聚合规则按照一定的存储结构同步到第二数据库中,充分发挥基于OLAP数据库的查询性能高的优势,实现了多源异构数据的聚合查询。
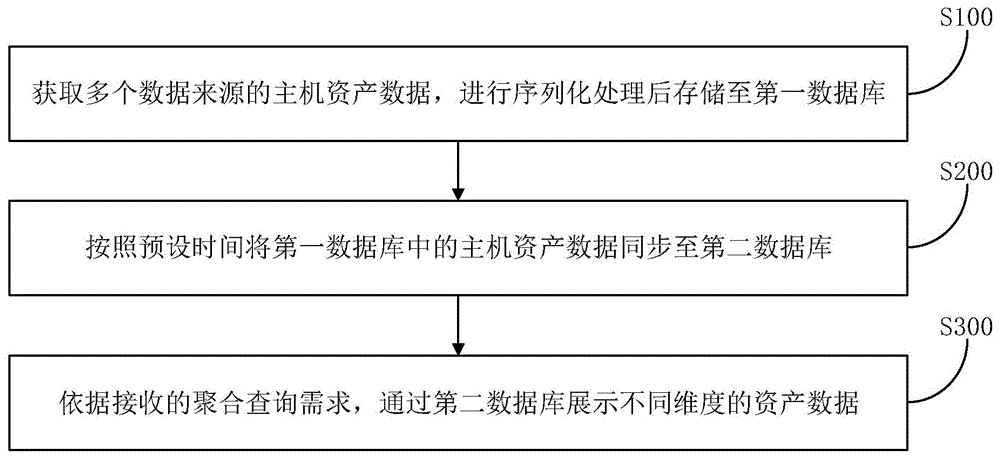
为解决上述技术问题,本发明实施例的第一方面提供了一种基于MPP架构的多源异构数据聚合查询方法,包括如下步骤:
获取多个数据来源的主机资产数据,进行序列化处理后存储至第一数据库;
按照预设时间将所述第一数据库中的所述主机资产数据同步至第二数据库;
依据接收的聚合查询需求,通过所述第二数据库展示不同维度的资产数据。
进一步地,所述获取多个数据来源的主机资产数据进行序列化处理存储至第一数据库,包括:
获取所述主机资产数据并将其存储至消息中间件;
依据预设数据格式对所述消息中间件中存储的所述主机资产数据进行序列化处理;
基于消息订阅模式将序列化处理后的所述主机资产数据发送至第一数据库的流水表,所述流水表存储有记录数据的主机id和资产类型。
进一步地,所述按照预设时间将所述第一数据库中的所述主机资产数据同步至第二数据库,包括:
通过定时任务扫描所述第一数据库未同步至所述第二数据库的数据记录,添加全局唯一锁,对未同步的所述主机资产数据进行反序列化处理;
将反序列化处理后的所述主机资产数据进行聚合处理,组装成与所述第二数据库的数据表相对应的表结构;
将聚合处理后的所述主机资产数据按照聚合类型分类存储至所述第二数据库的数据表。
进一步地,所述将反序列化处理后的所述数据按照聚合类型分别存储至所述第二数据库的数据表之后,还包括:
对已经存储至所述第二数据库的所述主机资产数据在所述第一数据库中的数据存储记录进行批量删除,并释放所述全局唯一锁。
进一步地,所述获取多源主机资产数据之后,还包括:
对同一数据来源中同种类型的所述主机资产数据进行数据压缩处理。
相应地,本发明示例的第二方面提供了一种MPP架构的多源异构数据聚合查询装置,包括:
数据获取模块,其用于获取多个数据来源的主机资产数据,进行序列化处理后存储至第一数据库;
数据同步模块,其用于按照预设时间将所述第一数据库中的所述主机资产数据同步至第二数据库;
数据展示模块,其用于依据接收的查询聚合需求,通过第二数据库展示不同维度的资产数据。
进一步地,所述数据获取模块包括:
数据获取单元,其用于获取所述主机资产数据并将其存储至消息中间件;
序列化处理单元,其用于依据预设数据格式对所述消息中间件中存储的所述主机资产数据进行序列化处理;
数据存储单元,其用于基于消息订阅模式将序列化处理后的所述主机资产数据发送至第一数据库的流水表,所述流水表存储有记录数据的主机id和资产类型。
进一步地,所述数据同步模块包括:
数据扫描单元,其用于通过定时任务扫描所述第一数据库中未同步至所述第二数据库的数据记录,添加全局唯一锁,对未同步的所述主机资产数据进行反序列化处理;
聚合处理单元,其用于将反序列化处理后的所述主机资产数据进行聚合处理,组装成与所述第二数据库的数据表相对应的表结构;
数据库转存单元,其用于将聚合处理后的所述主机资产数据按照聚合类型分类存储至所述第二数据库的数据表。
进一步地,所述数据同步模块还包括:
记录清理单元,其用于对已经存储至所述第二数据库的所述主机资产数据在所述第一数据库中的数据存储记录进行批量删除,并释放所述全局唯一锁。
进一步地,所述数据获取模块还包括:
数据压缩单元,其用于在获取多源主机资产数据之后,对同一数据来源中同种类型的所述主机资产数据进行数据压缩处理。
本发明实施例的第三方面还提供了一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器连接的存储器;其中,所述存储器存储有可被所述一个处理器执行的指令,所述指令被所述一个处理器执行,以使所述至少一个处理器执行上述MPP架构的多源异构数据聚合查询方法。
此外,本发明实施例的第四方面还提供了一种计算机可读存储介质,其上存储有计算机指令,该指令被处理器执行时实现上述MPP架构的多源异构数据聚合查询方法。
本发明实施例的上述技术方案具有如下有益的技术效果:
通过第一数据库和第二数据库之间进行数据同步,将数据临时写入第一数据库中,基于关系型数据库事务保证数据的准确性,基于聚合规则按照一定的存储结构同步到第二数据库中,充分发挥基于OLAP数据库的查询性能高的优势,实现了多源异构数据的聚合查询。
附图说明
图1是本发明实施例提供的基于MPP架构的多源异构数据聚合查询方法流程图;
图2是本发明实施例提供的基于MPP架构的多源异构数据聚合查询方法原理示意图;
图3是本发明实施例提供的基于MPP架构的多源异构数据聚合查询装置模块框图;
图4是本发明实施例提供的数据获取模块框图;
图5是本发明实施例提供的数据同步模块框图。
附图标记:
1、数据获取模块,11、数据获取单元,12、序列化处理单元,13、数据存储单元,14、数据压缩单元,2、数据同步模块,21、数据扫描单元,22、聚合处理单元,23、数据库转存单元,24、记录清理单元,3、数据展示模块。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
随着分布式和并行化的技术日渐成熟,MPP(Massive–Parallel-Processing)即大规模并行处理结构,核心思想是将任务散落到多个服务器或者多节点上,在每个节点上处理完成后,将各自的数据汇总在一起得到最终的结果。该架构已经被应用在越来越多的架构设计中,采用基于MPP架构的OLAP数据库就是最为典型的代表。OLAP也叫联机分析处理(Online Analytical Processing)系统,常常被用做大数据的查询分析。采用MPP架构的OLAP数据库通常分为两类,一类自身不存储数据,只负责计算的引擎,一类是自身即负责存储,也负责计算的引擎。
本技术方案考虑数据的存储能力和分析能力,第一数据库选择为MySQL数据库;第二数据库选择列式数据库ClickHouse,该数据库在计算层面做了很细致的工作,通过多核并行,分布式计算,向量化执行与SIMD指令等多种重要技术,极大的提升查询速度。
请参照图1和图2,本发明实施例的第一方面提供了一种基于MPP架构的多源异构数据聚合查询方法,包括如下步骤:
步骤S100,获取多个数据来源的主机资产数据,主机资产数据主要包括主机硬件信息(如网卡、cpu、内存等信息)、主机的软件信息(如进程、端口、账号、软件、安装包等信息),将上述主机硬件信息和主机软件信息进行序列化处理后存储至MySQL数据库。
步骤S200,按照预设时间将MySQL数据库中的主机资产数据同步至ClickHouse数据库。
步骤S300,依据接收的聚合查询需求,通过ClickHouse数据库展示不同维度的资产数据。
根据客户的聚合需求,展示不同维度的资产数据,ClickHouse数据库通过多个CPU核心分别处理其中一部分查询任务来实现并行数据处理,这种极致的并行处理能力,能够明显降低查询延时,提高查询效率。
上述技术方案能够在不考虑数据迁移的情况下,利用原有分布式架构中MySQL数据库的事务保证数据的准确性,同时在兼顾大数据的情况下,利用ClickHouse数据库实现高效的查询性能,提升了查询效率,做到百亿级数据查询,秒级响应的效果。
进一步地,步骤S100中,获取多源主机资产数据并将其存储至MySQL数据库,包括:
步骤S110,获取主机资产数据并将其存储至消息中间件。
具体的,上述主机资产数据可以定时更新或者手动更新,然后将数据统一上报,并存入消息中间件,利用消息中间件实现流量削峰,尤其在高并发场景下,可以提升系统的数据并发处理能力。
此外,步骤S110,获取多源主机资产数据之后,还包括:步骤S110a,对同一数据来源中同种类型的主机资产数据进行数据压缩处理。
步骤S120,依据预设数据格式对消息中间件中存储的主机资产数据进行序列化处理。通过序列化处理,可以进一步提升主机资产数据传输效率。
通过订阅消息中间件的主机资产数据,将其存入MySQL数据库中,每类资产数据的数据格式各不相同,需要对原始数据进行序列化后存入MySQL的流水表中,该表结构需要记录数据的主机id和资产的类型。
步骤S130,基于消息订阅模式将序列化处理后的主机资产数据发送至MySQL数据库的流水表,流水表存储有记录数据的主机id和资产类型。
进一步地,步骤S200,按照预设时间将MySQL数据库中的主机资产数据同步至ClickHouse数据库,包括:
步骤S210,通过定时任务扫描MySQL数据库未同步至ClickHouse数据库的数据记录,添加全局唯一锁,对未同步的主机资产数据进行反序列化处理。
步骤S220,将反序列化处理后的主机资产数据进行聚合处理,组装成与ClickHouse数据库的数据表相对应的表结构。
具体的,聚合处理主要是利用ClickHouse的内置函数对数据表的单个字段或多个字段做多维统计,单个字段的聚合处理使用GROUP BY关键字,多个字段的聚合处理使用GROUPING SETS关键字,全字段的聚合处理使用CUBE关键字。
步骤S230,将聚合处理后的主机资产数据按照聚合类型分类存储至ClickHouse数据库的数据表。
常见的聚合类型如以主机为单一维度统计单台主机中进程的数量、以某类资产为单一维度统计包含该资产的主机信息等。
进一步地,步骤S230中的将反序列化操作后的数据按照聚合类型分别存储至ClickHouse数据库的数据表之后,还包括:
步骤S240,对已经存储至ClickHouse数据库的主机资产数据在MySQL数据库中的数据存储记录进行批量删除,并释放全局唯一锁。
通过定时任务扫描MySQL数据库未同步到ClickHouse数据库的记录,添加全局唯一锁,保证该操作的唯一性,将每类资产的数据批量取出,对该类数据进行反序列化。按照聚合规则,将反序列化之后的数据进行聚合处理,组装成对应的表结构,保证ClickHouse数据库在下次查询过程中只需要关联1-2张表即可完成查询任务,这种做法能够有效避免因为数据量过大而导致的查询延迟问题。将反序列化的数据按照聚合的类型分别存储在不同的ClickHouse数据表中,ClickHouse数据库是集群化部署,由可扩展性的分片组成。对已经存入ClickHouse数据库中的MySQL记录进行批量删除,并释放全局唯一锁。
上述技术方案通过MySQL数据库和ClickHouse数据库进行数据同步,利用MySQL的事务保证数据的准确性,将不同的数据按照聚合规则同步到ClickHouse数据库,通过ClickHouse高效的聚合查询能力展示出不同维度的数据结果。
相应地,请参照图3,本发明示例的第二方面提供了一种MPP架构的多源异构数据聚合查询装置,包括:
数据获取模块1,其用于获取多个数据来源的主机资产数据,进行序列化处理后存储至MySQL数据库;
数据同步模块2,其用于按照预设时间将MySQL数据库中的主机资产数据同步至ClickHouse数据库;
数据展示模块3,其用于依据接收的查询聚合需求,通过ClickHouse数据库展示不同维度的资产数据。
请参照图4,具体的,数据获取模块1包括:
数据获取单元11,其用于获取主机资产数据并将其存储至消息中间件;
序列化处理单元12,其用于依据预设数据格式对消息中间件中存储的主机资产数据进行序列化处理;
数据存储单元13,其用于基于消息订阅模式将序列化处理后的主机资产数据发送至MySQL数据库的流水表,流水表存储有记录数据的主机id和资产类型。
请参照图5,具体的,数据同步模块2包括:
数据扫描单元21,其用于通过定时任务扫描MySQL数据库中未同步至ClickHouse数据库的数据记录,添加全局唯一锁,对未同步的主机资产数据进行反序列化处理;
聚合处理单元22,其用于将反序列化处理后的主机资产数据进行聚合处理,组装成与ClickHouse数据库的数据表相对应的表结构;
数据库转存单元23,其用于将聚合处理后的主机资产数据按照聚合类型分类存储至ClickHouse数据库的数据表。
进一步地,数据同步模块2还包括:记录清理单元24,其用于对已经存储至ClickHouse数据库的主机资产数据在MySQL数据库中的数据存储记录进行批量删除,并释放全局唯一锁。
进一步地,数据获取模块1还包括:数据压缩单元14,其用于在获取多源主机资产数据之后,对同一数据来源中同种类型的主机资产数据进行数据压缩处理。
本发明实施例的第三方面还提供了一种电子设备,包括:至少一个处理器;以及与至少一个处理器连接的存储器;其中,存储器存储有可被一个处理器执行的指令,指令被一个处理器执行,以使至少一个处理器执行上述MPP架构的多源异构数据聚合查询方法。
此外,本发明实施例的第四方面还提供了一种计算机可读存储介质,其上存储有计算机指令,该指令被处理器执行时实现上述MPP架构的多源异构数据聚合查询方法。
本发明实施例旨在保护一种基于MPP架构的多源异构数据聚合查询方法及装置,其中方法包括如下步骤:获取多源主机资产数据,并将其存储至MySQL数据库;按照预设时间将MySQL数据库中的主机资产数据同步至ClickHouse数据库;依据聚合查询需求,通过ClickHouse数据库展示不同维度的资产数据。上述技术方案具备如下效果:
通过MySQL数据库和ClickHouse数据库之间进行数据同步,将数据临时写入MySQL中,基于关系型数据库事务保证数据的准确性,基于聚合规则按照一定的存储结构同步到clickhouse数据库中,充分发挥基于OLAP数据库的查询性能高的优势,实现了多源异构数据的聚合查询。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。