基于旅游场景的文本聚类方法、系统、设备及存储介质
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及旅游相关自然语义处理领域,具体地说,涉及基于旅游场景的文本聚类方法、系统、设备及存储介质。
背景技术
随着时代的发展,信息技术的广泛应用,特别是大数据技术的应用,数据也正在以前所未有的速度向海量、高维方向发展。聚类分析在数据挖掘领域中非常活跃的领域之一,运用统计分析的方法把数据分成指定个类簇的过程。它按照样本间的相似性将数据集划分为各个不同的类簇,使得属于同一个类簇的样本尽可能地相似,同时不属于同一个类簇的样本尽量不相似。这种分类技术是无监督的,它不需要数据分类的先验信息,可以根据数据对象内部之间的相似性来合理地分类这些数据对象,而这也推动了信息时代的发展。
网络信息时代产生了海量的数据,通常这些数据是无法预先知道的,没有办法给这些数据事先做好分类,这就需要依据数据的内在联系来进行聚类分析。比如电商时代推动的购物平台,购物平台无法知道用户的分类信息,但是可以依据用户以往的购物习惯,对用户搜索、购买等行为产生的数据进行聚类分析,购物平台通过物品类别、物品价格、位置信息等特征自动推送用户可能喜欢的商品。聚类在信息检索和数据挖掘等领域都有着很广泛的应用,例如金融分析、医学、生物分类、考古等众多领域。
聚类分析对数据集的分布特点十分敏感,在聚类发展过程中也遭遇到了很多问题。例如无法分辨出非凸型簇、对异常点敏感、时间复杂度过高、对参数比较敏感等。
因此,本发明提供了一种基于旅游场景的文本聚类方法、系统、设备及存储介质。
发明内容
针对现有技术中的问题,本发明的目的在于提供基于旅游场景的文本聚类方法、系统、设备及存储介质,克服了现有技术的困难,能够通过该聚类方案完成对线上用户输入的搜索词进行自动聚类,解决了聚类算法无法确定簇的数量以及每个簇的簇中心的问题,并且自动过滤掉已有的主题,从而挖掘出新主题。
本发明的实施例提供一种基于旅游场景的文本聚类方法,包括以下步骤:
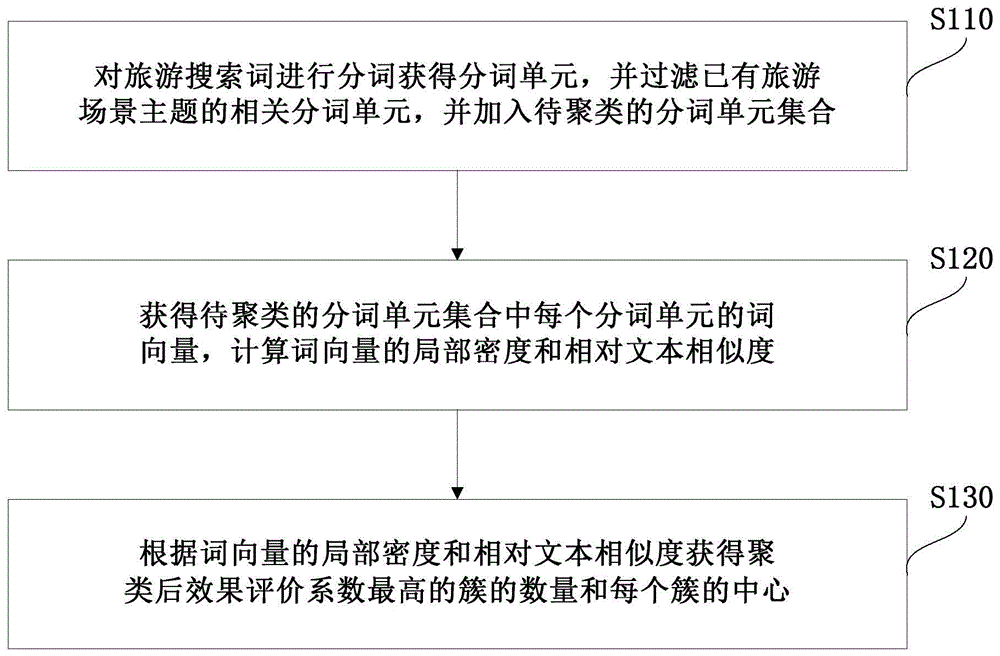
S110、对旅游搜索词进行分词获得分词单元,并过滤已有旅游场景主题的相关分词单元,并加入待聚类的分词单元集合;
S120、获得所述待聚类的分词单元集合中每个所述分词单元的词向量,计算所述词向量的局部密度和相对文本相似度;以及
S130、根据所述词向量的局部密度和相对文本相似度获得聚类后效果评价系数最高的簇的数量和每个簇的中心。
优选地,所述步骤S110,包括:
S111、对旅游搜索词进行分词获得分词单元;
S112、计算所述分词单元与基于预设的已有旅游场景主题对的相似度;
S113、过滤相似度大于预设阈值的分词单元,并加入待聚类的分词单元集合。
优选地,所述步骤S120,包括:
S121、将所述待聚类的分词单元集合中任意两个词向量为一组,获得每组词向量的文本相似度;
S122、将每个分词单元的搜索频次以及与所述分词单元的相似度大于预设阈值的其他分词单元的搜索频次进行加权求和,所述其他分词单元的权重小于所述分词单元的权重,获得的每个分词单元的评估参数;
S123、根据所述评估参数获得所述分词单元的局部密度;以及
S124、根据所述分词单元的局部密度,获得相对文本相似度。
优选地,所述步骤S121,获得两个向量的文本相似度的公式为:
similarity(a,b)=cos(a,b) (1)
其中,a和b代表不同的词向量,即文本相似度为两个词向量的余弦值。
优选地,所述步骤S122中,获得所述评估参数的公式为:
sumNum(c)=(2*num(c)+num1(c))*0.7+num2(c)*0.3 (2)
其中,c为一个分词单元,num(c)为分词单元c的搜索频次,num1(c)为与分词单元c的文本相似度大于0.79的其他分词单元对应的搜索频次的总和,num2(c)为与分词单元c的文本相似度大于0.7且小于等于0.79的其他分词单元对应的搜索频次的总和。
优选地,所述步骤S123中,获得所述分词单元的局部密度的公式为:
其中,minSumNum为所有分词单元的评估参数中的最小值,maxSumNum为所有分词单元的评估参数中的最大值。
优选地,所述步骤S124中,获得所述分词单元的相对文本相似度的公式为:
δ(a)=similarity(a,d)(4)
其中,d为一个词向量,且d为比所述旅游搜索词对应的词向量中比a词向量的局部密度大的词向量集合中的最小值。
优选地,所述步骤S130包括:
S131、获得每个分词单元的局部密度ρ(a)与该分词单元的相对文本相似度δ(a)的乘积γ(a):
γ(a)=δ(a)*ρ(a)(5)
S132、根据所述乘积γ(a)对所述分词单元进行排序,选中所述乘积γ(a)最大的前k个分词单元为作为簇中心进行聚类,k的取值范围为常数,50≤k≤500;
S133、获得用表示聚类之后当前簇内各个数据的相似程度的簇内相似度:
其中,E为聚类之后的某个簇,f、g为簇E中的分词单元,num(E)为簇E内的分词单元数量;
S134、获得用表示聚类之后两个簇之间的数据的簇间相似程度:
其中,H、I为聚类之后不同的两个簇,j是簇H中的分词单元,k是簇I中的分词单元,num(H)为簇H中的分词单元数量,num(I)为簇I中的分词单元数量;
S135、获得聚类的效果评价系数:
其中,k为簇的数量,simInCluster(i)为第i个簇的簇内相似度,simOutCluster(i)为第i个簇的簇间相似度;以及
S136、任取若干个不同数值的k进行聚类,分别获得效果评价系数,以效果评价系数最高的k作为最终的簇的数量,以及对应的每个簇的中心。
优选地,所述步骤S132包括:
S1321、根据所述乘积γ(a)对所述分词单元进行排序,选中所述乘积γ(a)最大的前k个分词单元为作为簇中心;
S1322、根据k个簇中心进行聚类,计算所有所述分词单元各自与k个簇中心的文本相似度;以及
S1323、将每个分词单元划分到文本相似度最大的那个簇中心下面,直到划分完所有的分词单元。
本发明的实施例还提供一种基于旅游场景的文本聚类系统,用于实现上述的基于旅游场景的文本聚类方法,所述基于旅游场景的文本聚类系统包括:
分词单元模块,对旅游搜索词进行分词获得分词单元,并过滤已有旅游场景主题的相关分词单元,并加入待聚类的分词单元集合;
聚类检测模块,获得所述待聚类的分词单元集合中每个所述分词单元的词向量,计算所述词向量的局部密度和相对文本相似度;以及
聚类评价模块,根据所述词向量的局部密度和相对文本相似度获得聚类后效果评价系数最高的簇的数量和每个簇的中心。
本发明的实施例还提供一种基于旅游场景的文本聚类设备,包括:
处理器;
存储器,其中存储有所述处理器的可执行指令;
其中,所述处理器配置为经由执行所述可执行指令来执行上述基于旅游场景的文本聚类方法的步骤。
本发明的实施例还提供一种计算机可读存储介质,用于存储程序,所述程序被执行时实现上述基于旅游场景的文本聚类方法的步骤。
本发明的目的在于提供基于旅游场景的文本聚类方法、系统、设备及存储介质,能够通过该聚类方案完成对线上用户输入的搜索词进行自动聚类,解决了聚类算法无法确定簇的数量以及每个簇的簇中心的问题,并且自动过滤掉已有的主题,从而挖掘出新主题。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显。
图1是本发明的基于旅游场景的文本聚类方法的流程图。
图2为本发明的基于旅游场景的文本聚类方法的实施过程中合成二维数据集的数据分布图。
图3为图2中数据集的策略图。
图4是本发明的基于旅游场景的文本聚类系统的模块示意图。
图5是本发明的基于旅游场景的文本聚类设备的结构示意图。
图6是本发明一实施例的计算机可读存储介质的结构示意图。
具体实施方式
以下通过特定的具体实例说明本申请的实施方式,本领域技术人员可由本申请所揭露的内容轻易地了解本申请的其他优点与功效。本申请还可以通过另外不同的具体实施方式加以实施或应用系统,本申请中的各项细节也可以根据不同观点与应用系统,在没有背离本申请的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
下面以附图为参考,针对本申请的实施例进行详细说明,以便本申请所属技术领域的技术人员能够容易地实施。本申请可以以多种不同形态体现,并不限定于此处说明的实施例。
在本申请的表示中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的表示意指结合该实施例或示例表示的具体特征、结构、材料或者特点包括于本申请的至少一个实施例或示例中。而且,表示的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本申请中表示的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
此外,术语“第一”、“第二”仅用于表示目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或隐含地包括至少一个该特征。在本申请的表示中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
为了明确说明本申请,省略与说明无关的器件,对于通篇说明书中相同或类似的构成要素,赋予了相同的参照符号。
在通篇说明书中,当说某器件与另一器件“连接”时,这不仅包括“直接连接”的情形,也包括在其中间把其它元件置于其间而“间接连接”的情形。另外,当说某种器件“包括”某种构成要素时,只要没有特别相反的记载,则并非将其它构成要素排除在外,而是意味着可以还包括其它构成要素。
当说某器件在另一器件“之上”时,这可以是直接在另一器件之上,但也可以在其之间伴随着其它器件。当对照地说某器件“直接”在另一器件“之上”时,其之间不伴随其它器件。
虽然在一些实例中术语第一、第二等在本文中用来表示各种元件,但是这些元件不应当被这些术语限制。这些术语仅用来将一个元件与另一个元件进行区分。例如,第一接口及第二接口等表示。再者,如同在本文中所使用的,单数形式“一”、“一个”和“该”旨在也包括复数形式,除非上下文中有相反的指示。应当进一步理解,术语“包含”、“包括”表明存在的特征、步骤、操作、元件、组件、项目、种类、和/或组,但不排除一个或多个其他特征、步骤、操作、元件、组件、项目、种类、和/或组的存在、出现或添加。此处使用的术语“或”和“和/或”被解释为包括性的,或意味着任一个或任何组合。因此,“A、B或C”或者“A、B和/或C”意味着“以下任一个:A;B;C;A和B;A和C;B和C;A、B和C”。仅当元件、功能、步骤或操作的组合在某些方式下内在地互相排斥时,才会出现该定义的例外。
此处使用的专业术语只用于言及特定实施例,并非意在限定本申请。此处使用的单数形态,只要语句未明确表示出与之相反的意义,那么还包括复数形态。在说明书中使用的“包括”的意义是把特定特性、区域、整数、步骤、作业、要素及/或成份具体化,并非排除其它特性、区域、整数、步骤、作业、要素及/或成份的存在或附加。
虽然未不同地定义,但包括此处使用的技术术语及科学术语,所有术语均具有与本申请所属技术领域的技术人员一般理解的意义相同的意义。普通使用的字典中定义的术语追加解释为具有与相关技术文献和当前提示的内容相符的意义,只要未进行定义,不得过度解释为理想的或非常公式性的意义。
图1是本发明的基于旅游场景的文本聚类方法的流程图。如图1所示,本发明的基于旅游场景的文本聚类方法包括:
S110、对旅游搜索词进行分词获得分词单元,并过滤已有旅游场景主题的相关分词单元,并加入待聚类的分词单元集合。
S120、获得待聚类的分词单元集合中每个分词单元的词向量,计算词向量的局部密度和相对文本相似度。以及
S130、根据词向量的局部密度和相对文本相似度获得聚类后效果评价系数最高的簇的数量和每个簇的中心。
本发明提供了一种基于密度峰值的短文本聚类方案,通过获得每个词的词向量,计算每个向量的局部密度和文本相似度,从而可以确定数据集中的簇的数量以及每个簇的簇中心,解决了聚类算法无法确定簇的数量的问题。目前,通过统计人工积累的主题已投入到线上,但是还不够全面。通过人工发现的新主题是有限的,因此可以通过该聚类方案完成对线上用户输入的搜索词进行自动聚类。过滤掉已有的主题,从而挖掘出新主题。
一个优选实施例中,步骤S110,包括:
S111、对旅游搜索词进行分词获得分词单元。
S112、计算分词单元与基于预设的已有旅游场景主题对的相似度。
S113、过滤相似度大于预设阈值的分词单元,并加入待聚类的分词单元集合,但不以此为限。
在一个优选实施例中,步骤S120,包括:
S121、将待聚类的分词单元集合中任意两个词向量为一组,获得每组词向量的文本相似度。
S122、将每个分词单元的搜索频次以及与分词单元的相似度大于预设阈值的其他分词单元的搜索频次进行加权求和,其他分词单元的权重小于分词单元的权重,获得的每个分词单元的评估参数。
S123、根据评估参数获得分词单元的局部密度。以及
S124、根据分词单元的局部密度,获得相对文本相似度,但不以此为限。
在一个优选实施例中,步骤S121,获得两个向量的文本相似度的公式为:
similarity(a,b)=cos(a,b)(1)
其中,a和b代表不同的词向量,即文本相似度为两个词向量的余弦值,但不以此为限。
在一个优选实施例中,步骤S122中,获得评估参数的公式为:
sumNum(c)=(2*num(c)+num1(c))*0.7+num2(c)*0.3 (2)
其中,c为一个分词单元,num(c)为分词单元c的搜索频次,num1(c)为与分词单元c的文本相似度大于0.79的其他分词单元对应的搜索频次的总和,num2(c)为与分词单元c的文本相似度大于0.7且小于等于0.79的其他分词单元对应的搜索频次的总和,但不以此为限。
在一个优选实施例中,步骤S123中,获得分词单元的局部密度的公式为:
其中,minSumNum为所有分词单元的评估参数中的最小值,maxSumNum为所有分词单元的评估参数中的最大值。
在一个优选实施例中,步骤S124中,获得分词单元的相对文本相似度的公式为:
δ(a)=similarity(a,d)(4)
其中,d为一个词向量,且d为比旅游搜索词对应的词向量中比a词向量的局部密度大的词向量集合中的最小值,但不以此为限。
在一个优选实施例中,步骤S130包括:
S131、获得每个分词单元的局部密度ρ(a)与该分词单元的相对文本相似度δ(a)的乘积γ(a):
γ(a)=δ(a)*ρ(a)(5)
S132、根据乘积γ(a)对分词单元进行排序,选中乘积γ(a)最大的前k个分词单元为作为簇中心进行聚类,k的取值范围为常数,50≤k≤500。
S133、获得用表示聚类之后当前簇内各个数据的相似程度的簇内相似度:
其中,E为聚类之后的某个簇,f、g为簇E中的分词单元,num(E)为簇E内的分词单元数量。
S134、获得用表示聚类之后两个簇之间的数据的簇间相似程度:
其中,H、I为聚类之后不同的两个簇,j是簇H中的分词单元,k是簇I中的分词单元,num(H)为簇H中的分词单元数量,num(I)为簇I中的分词单元数量。
S135、获得聚类的效果评价系数:
其中,k为簇的数量,simInCluster(i)为第i个簇的簇内相似度,simOutCluster(i)为第i个簇的簇间相似度。以及
S136、任取若干个不同数值的k进行聚类,分别获得效果评价系数,以效果评价系数最高的k作为最终的簇的数量,以及对应的每个簇的中心,但不以此为限。
在一个优选实施例中,步骤S132包括:
S1321、根据乘积γ(a)对分词单元进行排序,选中乘积γ(a)最大的前k个分词单元为作为簇中心。
S1322、根据k个簇中心进行聚类,计算所有分词单元各自与k个簇中心的文本相似度。以及
S1323、将每个分词单元划分到文本相似度最大的那个簇中心下面,直到划分完所有的分词单元,但不以此为限。
本发明是针对旅游线上用户输入的搜索词进行聚类的,通过对大量的用户主动输入的搜索词进行聚类,并统计每个簇的搜索量,从中挖掘出新的旅游主题类别,可以为用户推荐感兴趣的新主题,提升用户体验。
本发明的聚类算法一共分为三部分:
(1)处理数据。对搜索词进行分词,过滤掉脏数据和已有主题的相关数据,清洗分词之后的每个分词单元。
(2)计算局部密度和相对文本相似度,通过word2vec获得每个分词单元的词向量,计算每个词向量的局部密度和相对文本相似度。其中,Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
(3)确定聚类的簇的数量和簇中心。通过所有分词单元的局部密度和相对文本相似度确定聚类的簇的数量和每个簇的中心,完成聚类。(以下按照步骤顺序逐步说明)
(1)关于本发明中处理数据包括以下步骤:
本发明的主要目的是通过聚类挖掘和旅游相关的新的游玩主题,其数据源是旅游用户通过旅游APP输入的搜索词。通过研究发现通过对搜索词进行分词之后得到的分词单元可以更好的代表搜索词的主题意向。
比如,搜索词“长白山滑雪”,通过分词可以得到“长白山”、“滑雪”两个分词单元。其中“滑雪”可以更好的代表滑雪游玩主题,因此通过对搜索词进行分词之后得出的分词单元进行聚类对于新主题挖掘是可行的。而且,由于用户在旅游APP上输入的搜索词数量很大,会产生非常多的脏数据,通过对这些搜索词进行分词处理,有利于清洗数据,以提升聚类的效果。本发明针对用户输入的搜索词通过Ansj(Ansj中文分词是一个ictclas的java实现。基本上重写了所有的数据结构和算法。词典是用的开源版的ictclas所提供的。并且进行了部分的人工优化)进行分词,分词词库采用旅游度假业务线的本地词库。
目前,通过统计已有部分和旅游相关的主题投入到线上,针对这部分已经存在的主题不需要通过聚类去挖掘,因此通过计算用户输入的搜索词与已有主题的文本相似度,过滤掉这部分搜索词。其次,还需要过滤掉相关词库里poi类(兴趣点)的词以及停词,对剩下的长度大于1且小于15的搜索词进行聚类。
(2)关于本发明中计算局部密度和相对文本相似度包括以下步骤:
首先介绍一下密度峰值聚类算法,该算法是基于以下两种假设:
(a)类簇中心点的密度大于周围邻居点的密度;
(b)类簇中心点与更高密度点之间的距离相对较大。
通过以上两种假设可以发现,一般情况下,数据的密度越大,与更高密度点之间的距离越大,是簇中心的可能性就越大。图2为本发明的基于旅游场景的文本聚类方法的实施过程中合成二维数据集的数据分布图。可以看出该数据集有两个簇,且五角星标出来两个簇的簇中心。图3为图2中数据集的策略图,其横轴为每个数据的局部密度,纵轴为每个数据与更高密度点之间的距离。其中图2中的两个簇中心分别对应这图3中右上角被虚线框出来的两个点。因此通过这两个图可以进一步证明,数据的密度越大,与更高密度点之间的距离越大,是簇中心的可能性就越大。
受该算法启发,本发明的聚类场景是对分词单元进行聚类,因此通过计算两个词向量的余弦值获得两个向量的文本相似度代替密度峰值聚类算法的欧式距离。
以下是本发明用到的相关定义:
(2.1)计算文本相似度
similarity(a,b)=cos(a,b)(1)
其中a和b代表不同的词向量,即文本相似度为两个词向量的余弦值。
(2.2)获得评估参数
本发明会统计每个分词单元对应的搜索词的搜索频次,结合搜索频次和与每个分词单元的文本相似度高的数据量来计算每个分词单元的局部密度。
首先统计每个分词单元本身以及相似度高的分词单元的数量,即:
sumNum(c)=(2*num(c)+num1(c))*0.7+num2(c)*0.3(2)
其中,c为一个分词单元,num(c)为分词单元c的搜索频次,num1(c)为与分词单元c的文本相似度大于0.79的其他分词单元对应的搜索频次的总和,num2(c)为与分词单元c的文本相似度大于0.7且小于等于0.79的其他分词单元对应的搜索频次的总和。
(2.3)计算局部密度
可以看出,分词单元的sumNum值越大,其局部密度就越大。计算所有分词单元的sumNum值,通过max-min方法对这些sumNum值做归一化,归一化之后的结果为每个分词单元的局部密度,即:
其中,minSumNum为所有分词单元的评估参数中的最小值,maxSumNum为所有分词单元的评估参数中的最大值。
(2.4)计算相对文本相似度
δ(a)=similarity(a,d)(4)
其中,d为一个词向量,且d为比旅游搜索词对应的词向量中比a词向量的局部密度大的词向量集合中的最小值。通过以上定义,计算每个分词单元的局部密度和相对文本相似度。
(3)关于本发明中确定聚类的簇的数量和簇中心包括以下步骤:
(3.1)分词单元的密度越大,与更高密度的分词单元之间的文本相似度越大,是簇中心的可能性就越大。因此,获得每个分词单元的局部密度ρ(a)与该分词单元的相对文本相似度δ(a)的乘积γ(a):
γ(a)=δ(a)*ρ(a)(5)
(3.2)对所有分词单元的γ值进行非升序排序,γ值越大的分词单元是簇中心的可能性越大。为了更科学的确定簇中心的数量,假设簇中心的数量为k,即γ值最大的前k分词单元为簇中心。
(3.3)计算簇内相似度
簇内相似度是用来聚类之后当前簇内各个数据的相似程度,即:
其中,E为聚类之后的某个簇,f、g为簇E中的分词单元,num(E)为簇E内的分词单元数量。
(3.4)计算簇间相似度
簇间相似度是用来衡量不同的两个簇之间的数据的相似程度,即:
其中,H、I为聚类之后不同的两个簇,j是簇H中的分词单元,k是簇I中的分词单元,num(H)为簇H中的分词单元数量,num(I)为簇I中的分词单元数量。
(3.5)另k从50开始,假设γ值最大的前50个分词单元为簇中心,计算所有的分词单元和这两个簇中心的文本相似度,将每个分词单元划分到文本相似度最大的那个簇中心下面,直到划分完所有的数据。对得到的50个簇计算簇内相似度和簇间相似度,其中每个簇的簇间相似度为该簇与其他簇之间的相似度的最大值。
(3.6)通过每个簇的簇内相似度和簇间相似度计算在k为50的条件下,此次聚类的效果评价系数,即:
其中,k为簇的数量,simInCluster(i)为第i个簇的簇内相似度,simOutCluster(i)为第i个簇的簇间相似度。
另k>=50且k<=500,计算k个簇聚类之后的效果评价系数effEvaluation(k),选取另该系数最大的k为最终的簇的数量,即k个簇中心。
本发明是在旅游场景下,针对用户在旅游APP输入的搜索关键词进行聚类,从而挖掘出新的旅游主题。选取了以往全年的搜索词数据,清洗数据,过滤掉了和已有主题相关的搜索词和POI相关搜索词,对剩余数据进行分词,对分词单元进行聚类。通过该发明可以获得很好的聚类效果,通过聚类出来的每个簇可以发现有价值的和旅游相关的游玩新主题。
本发明的实施流程包括:
(1)清洗数据,选取长度大于1且小于15的搜索词,对搜索词使用Ansj分词器进行分词。
(2)对分词之后的分词单元过滤掉已有主题搜索词和POI相关的词。
(3)计算每个分词单元的局部密度。
(4)通过局部密度,计算每个分词单元和比其局部密度大的分词单元之间的文本相似度的最小值,作为每个分词单元的相对文本相似度。
(5)计算每个分词单元的局部密度和相对文本相似度的乘积,并按降序方式排序。
(6)设k为聚类的簇的数量,另k>=50且k<=500,选取局部密度和相对文本相似度的乘积最大的前k个分词单元作为k个簇的中心,进行迭代聚类。计算每次聚类中每个簇的簇内相似度和簇间相似度,计算当前聚类的效果评价系数。
(7)选取效果评价系数最大的k作为簇的数量,完成聚类。
图4是本发明的基于旅游场景的文本聚类系统的模块示意图。如图4所示,本发明的实施例还提供一种基于旅游场景的文本聚类系统,用于实现上述的基于旅游场景的文本聚类方法,基于旅游场景的文本聚类系统包括:
分词单元模块51,对旅游搜索词进行分词获得分词单元,并过滤已有旅游场景主题的相关分词单元,并加入待聚类的分词单元集合。
聚类检测模块52,获得待聚类的分词单元集合中每个分词单元的词向量,计算词向量的局部密度和相对文本相似度。以及
聚类评价模块53,根据词向量的局部密度和相对文本相似度获得聚类后效果评价系数最高的簇的数量和每个簇的中心。
在一个优选实施例中,分词单元模块51被配置为对旅游搜索词进行分词获得分词单元。计算分词单元与基于预设的已有旅游场景主题对的相似度。过滤相似度大于预设阈值的分词单元,并加入待聚类的分词单元集合。
在一个优选实施例中,聚类检测模块52被配置为将待聚类的分词单元集合中任意两个词向量为一组,获得每组词向量的文本相似度。
将每个分词单元的搜索频次以及与分词单元的相似度大于预设阈值的其他分词单元的搜索频次进行加权求和,其他分词单元的权重小于分词单元的权重,获得的每个分词单元的评估参数。根据评估参数获得分词单元的局部密度。以及根据分词单元的局部密度,获得相对文本相似度。
在一个优选实施例中,聚类检测模块52中获得两个向量的文本相似度的公式为:
similarity(a,b)=cos(a,b)(1)
其中,a和b代表不同的词向量,即文本相似度为两个词向量的余弦值。
在一个优选实施例中,聚类检测模块52中获得评估参数的公式为:
sumNum(c)=(2*num(c)+num1(c))*0.7+num2(c)*0.3(2)
其中,c为一个分词单元,num(c)为分词单元c的搜索频次,num1(c)为与分词单元c的文本相似度大于0.79的其他分词单元对应的搜索频次的总和,num2(c)为与分词单元c的文本相似度大于0.7且小于等于0.79的其他分词单元对应的搜索频次的总和。
在一个优选实施例中,聚类检测模块52中获得分词单元的局部密度的公式为:
其中,minSumNum为所有分词单元的评估参数中的最小值,maxSumNum为所有分词单元的评估参数中的最大值。
在一个优选实施例中,聚类检测模块52中获得分词单元的相对文本相似度的公式为:
δ(a)=similarity(a,d)(4)
其中,d为一个词向量,且d为比旅游搜索词对应的词向量中比a词向量的局部密度大的词向量集合中的最小值。
在一个优选实施例中,聚类评价模块53被配置为获得每个分词单元的局部密度ρ(a)与该分词单元的相对文本相似度δ(a)的乘积γ(a):
γ(a)=δ(a)*ρ(a)(5)
根据乘积γ(a)对分词单元进行排序,选中乘积γ(a)最大的前k个分词单元为作为簇中心进行聚类,k的取值范围为常数,50≤k≤500。
获得用表示聚类之后当前簇内各个数据的相似程度的簇内相似度:
其中,E为聚类之后的某个簇,f、g为簇E中的分词单元,num(E)为簇E内的分词单元数量。
获得用表示聚类之后两个簇之间的数据的簇间相似程度:
其中,H、I为聚类之后不同的两个簇,j是簇H中的分词单元,k是簇I中的分词单元,num(H)为簇H中的分词单元数量,num(I)为簇I中的分词单元数量。
获得聚类的效果评价系数:
其中,k为簇的数量,simInCluster(i)为第i个簇的簇内相似度,simOutCluster(i)为第i个簇的簇间相似度。以及
任取若干个不同数值的k进行聚类,分别获得效果评价系数,以效果评价系数最高的k作为最终的簇的数量,以及对应的每个簇的中心。
在一个优选实施例中,聚类评价模块53中根据乘积γ(a)对分词单元进行排序,选中乘积γ(a)最大的前k个分词单元为作为簇中心。根据k个簇中心进行聚类,计算所有分词单元各自与k个簇中心的文本相似度。以及将每个分词单元划分到文本相似度最大的那个簇中心下面,直到划分完所有的分词单元。
本发明的基于旅游场景的文本聚类系统能够通过该聚类方案完成对线上用户输入的搜索词进行自动聚类,解决了聚类算法无法确定簇的数量以及每个簇的簇中心的问题,并且自动过滤掉已有的主题,从而挖掘出新主题。
本发明实施例还提供一种基于旅游场景的文本聚类设备,包括处理器。存储器,其中存储有处理器的可执行指令。其中,处理器配置为经由执行可执行指令来执行的基于旅游场景的文本聚类方法的步骤。
如上所示,该实施例本发明的基于旅游场景的文本聚类系统能够通过该聚类方案完成对线上用户输入的搜索词进行自动聚类,解决了聚类算法无法确定簇的数量以及每个簇的簇中心的问题,并且自动过滤掉已有的主题,从而挖掘出新主题。
所属技术领域的技术人员能够理解,本发明的各个方面可以实现为系统、方法或程序产品。因此,本发明的各个方面可以具体实现为以下形式,即:完全的硬件实施方式、完全的软件实施方式(包括固件、微代码等),或硬件和软件方面结合的实施方式,这里可以统称为“电路”、“模块”或“平台”。
图5是本发明的基于旅游场景的文本聚类设备的结构示意图。下面参照图5来描述根据本发明的这种实施方式的电子设备600。图5显示的电子设备600仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。
如图5所示,电子设备600以通用计算设备的形式表现。电子设备600的组件可以包括但不限于:至少一个处理单元610、至少一个存储单元620、连接不同平台组件(包括存储单元620和处理单元610)的总线630、显示单元640等。
其中,存储单元存储有程序代码,程序代码可以被处理单元610执行,使得处理单元610执行本说明书上述电子处方流转处理方法部分中描述的根据本发明各种示例性实施方式的步骤。例如,处理单元610可以执行如图1中所示的步骤。
存储单元620可以包括易失性存储单元形式的可读介质,例如随机存取存储单元(RAM)6201和/或高速缓存存储单元6202,还可以进一步包括只读存储单元(ROM)6203。
存储单元620还可以包括具有一组(至少一个)程序模块6205的程序/实用工具6204,这样的程序模块6205包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。
总线630可以为表示几类总线结构中的一种或多种,包括存储单元总线或者存储单元控制器、外围总线、图形加速端口、处理单元或者使用多种总线结构中的任一总线结构的局域总线。
电子设备600也可以与一个或多个外部设备700(例如键盘、指向设备、蓝牙设备等)通信,还可与一个或者多个使得用户能与该电子设备600交互的设备通信,和/或与使得该电子设备600能与一个或多个其它计算设备进行通信的任何设备(例如路由器、调制解调器等等)通信。这种通信可以通过输入/输出(I/O)接口650进行。并且,电子设备600还可以通过网络适配器660与一个或者多个网络(例如局域网(LAN),广域网(WAN)和/或公共网络,例如因特网)通信。网络适配器660可以通过总线630与电子设备600的其它模块通信。应当明白,尽管图中未示出,可以结合电子设备600使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、RAID系统、磁带驱动器以及数据备份存储平台等。
本发明实施例还提供一种计算机可读存储介质,用于存储程序,程序被执行时实现的基于旅游场景的文本聚类方法的步骤。在一些可能的实施方式中,本发明的各个方面还可以实现为一种程序产品的形式,其包括程序代码,当程序产品在终端设备上运行时,程序代码用于使终端设备执行本说明书上述电子处方流转处理方法部分中描述的根据本发明各种示例性实施方式的步骤。
如上所示,该实施例本发明的基于旅游场景的文本聚类系统能够通过该聚类方案完成对线上用户输入的搜索词进行自动聚类,解决了聚类算法无法确定簇的数量以及每个簇的簇中心的问题,并且自动过滤掉已有的主题,从而挖掘出新主题。
图6是本发明的计算机可读存储介质的结构示意图。参考图6所示,描述了根据本发明的实施方式的用于实现上述方法的程序产品800,其可以采用便携式紧凑盘只读存储器(CD-ROM)并包括程序代码,并可以在终端设备,例如个人电脑上运行。然而,本发明的程序产品不限于此,在本文件中,可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
程序产品可以采用一个或多个可读介质的任一组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以为但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任一以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任一合适的组合。
计算机可读存储介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任一合适的组合。可读存储介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。可读存储介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、有线、光缆、RF等等,或者上述的任一合适的组合。
可以以一种或多种程序设计语言的任一组合来编写用于执行本发明操作的程序代码,程序设计语言包括面向对象的程序设计语言—诸如Java、C++等,还包括常规的过程式程序设计语言—诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任一种类的网络,包括局域网(LAN)或广域网(WAN),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。
综上,本发明的目的在于提供基于旅游场景的文本聚类方法、系统、设备及存储介质,能够通过该聚类方案完成对线上用户输入的搜索词进行自动聚类,解决了聚类算法无法确定簇的数量以及每个簇的簇中心的问题,并且自动过滤掉已有的主题,从而挖掘出新主题。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。