技术领域
本发明属于网络安全技术领域,具体涉及一种基于Bert模型和三支决策算法的网页暗链检测方法。
背景技术
近年来,随着网络技术的不断发展,利用网络流量获取经济收益已经成为一种普遍的营销方式。然而,这种方式也被不法分子引入到网络黑灰产业链中,其中“网页暗链”就是一种典型的问题。网页暗链指不法分子通过夺取网站服务器一定权限,修改网页内容,将异常的网页链接以在线访客不可见、但搜索引擎能索引到的形式隐藏其中,以提升异常网页链接的搜索引擎排名,进而为异常网页引入大量流量。网页暗链往往被非法链接到色情、诈骗、赌博、非法游戏私服、虚假医疗等黑灰产业,甚至是反动信息。暗链严重扰乱了搜索引擎排名机制,使得搜索结果用户满意度下降,甚至因为误导用户造成损失而引起法律纠纷。且若将包含非法内容的暗链植入到政府、教育等公共网站,还会对上述网站及对应单位的信誉形象产生严重的负面影响。因此,关注网络安全威胁中的暗链问题对于保障网络安全和用户隐私都具有重要的现实意义,同时对于营造风清气正的网络空间和净化网络环境也具有重要的社会意义。
传统基于人工的暗链检测方法虽然准确可靠,但存在耗资巨大、效率低、技术要求高以及应对不及时等问题。因此,基于网页暗链的独有特征,如样式特征、文本特征等,利用机器学习算法自动检测网页暗链成为一种有效的解决方案。然而,随着暗链黑灰产中挂链用户的不断变化,网页暗链对应的关键词也在不断更新。此外,随着社会的发展,正常网站也不断引入新的关键词。面对网络空间中正常网页和暗链网页关键词的不断变化,而基于文本的机器学习暗链检测方法在面临未训练过的新词时,无法准确赋予其属于正类或者负类的隶属度概率值。同时,基于传统二支决策的暗链自动检测方法只有以下两种结果,即判断网页中存在或不存在暗链。此时,基于传统二支决策法的暗链检测模型面临以下风险:如果将正常网页误判为暗链网页,系统会将该网站发送给第三方处理,但将没有暗链的网站交给第三方处理无疑增加了第三方的工作量;如果将存在暗链的网页漏判为正常网页,将导致存在暗链的网站被忽略掉,暗链中所指向的博彩、虚假医疗、色情、游戏外挂等不正规、非法的网站就可能被普通用户信任并点击进入,从而造成经济损失、引起社会甚至法律纠纷。
上述分析表明,基于二支决策的暗链检测已经不能满足互联网快速发展的时代需求。为了解决这一现实需求,本发明提出一种基于三支决策的暗链检测算法。该算法不仅可以有效地分类经充分训练的正常和暗链网页,还通过将新获取的网页关键词分类到边界域并在满足一定条件后重新训练分类器的方式,解决了传统二支决策模型无法有效应对网页暗链不断变化的问题。
发明内容
本发明的目的是提供一种基于Bert模型和三支决策算法的网页暗链检测方法,用于解决现有基于人工的暗链检测技术效率低、成本高、技术要求高以及应对不及时等问题。同时,现有基于二支决策的暗链检测方法又难以应对网络空间中不断增加的正常、暗链网页,导致检测结果存在很多误报和漏报问题。
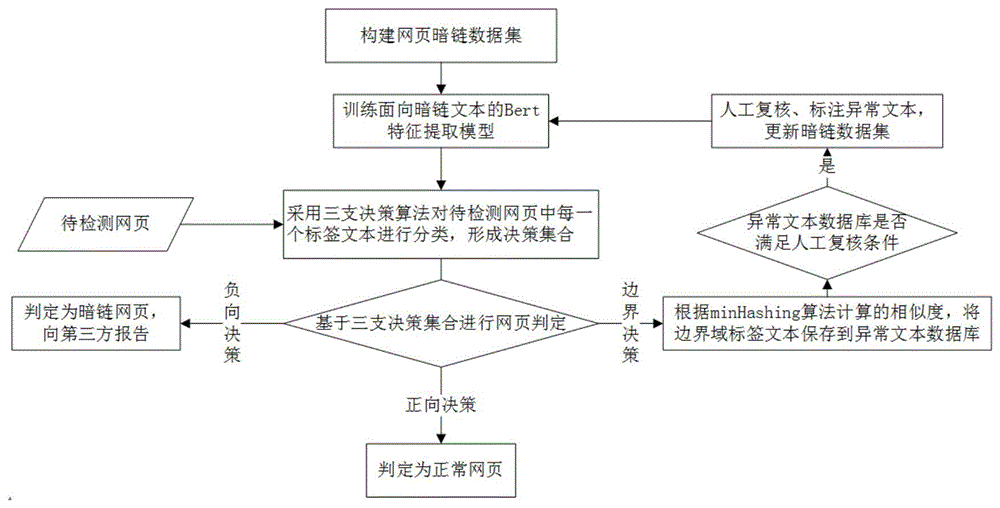
所述的一种基于Bert模型和三支决策算法的网页暗链检测方法,包括下列步骤。
S1、收集正常网页和网页暗链中的文本信息形成数据集,基于该数据集训练面向暗链文本特征的Bert模型;
S2、提取待检测网页中的文本信息,利用所述Bert模型从上述文本信息中提取特征向量,再通过三支决策算法对所述特征向量进行分类,得到待检测网页的决策集合,决策集合包含负向决策、正向决策和边界决策三种元素;
S3、根据三支决策算法的分类结果判断待检测网页是否存在暗链,当能确定待检测网页是否存在暗链时,根据判断结果向第三方警示、报告或结束本网页的检测,而后转到步骤S2;当网站中是否存在暗链无法判断时,将由下一步处理网站中无法判断的边界域标签文本;
S4、对于归为边界域的标签文本,通过minHashing算法依次计算其与异常文本数据库中所有记录的文本字段的相似度,根据相似度选择将该标签文本保存在异常文本数据库的已有类别中或新设置的类别中;
S5、根据异常文本数据库中某类异常文本的频数或者异常文本数据库中记录的总数是否超过对应阈值判断是否将异常文本数据库中异常文本交由人工复核审查,审查后更新数据集并重新训练Bert模型。
优选的,所述步骤S1包括:
S1.1、收集大量网站的URL地址。
S1.2、对于收集的URL地址集合中每条URL地址,进行分类、标注和保存,形成数据集。
S1.3、设定暗链数据集中暗链样本的数量阈值,当暗链样本的数量超过数量阈值,则停止数据集的采集,执行下一步Bert模型的训练,否则通过本步骤继续采集暗链样本以补充负样本,降低样本偏置;
S1.4、基于构建的暗链数据集,训练基于Bert的暗链文本分类模型。
优选的,所述步骤S1.2对URL地址集合中每条URL地址u
S1.2.1、爬取u
S1.2.2、计算超文本中
部分的Hash值hash(h
S1.2.3、对于超文本
部分,提取
以及<meta>标签中的文本信息;对于超文本<body>部分,提取每个具体锚文本中的文本信息,对于每个标签或锚文本中提取的文本信息分别进行人工标注,根据文本内容分别标注为负类、标注为正类或丢弃该文本;最后将标注的结果保存到网页暗链数据集中。</p><p>优选的,所述步骤S1.3的采集过程中每隔一个指定时间,对于网页源数据库中每个URL地址u</p><p>S1.3.1、爬取u</p><p>S1.3.2、计算超文本中<head>部分的Hash值hash(h′</p><p>S1.3.3、对于超文本<head>部分,提取<title>以及<meta>标签中的文本信息;对于超文本<body>部分,提取每个具体锚文本中的文本信息,对于每个标签或锚文本中提取的文本信息分别进行人工标注,然后将标注为负类的结果保存到网页暗链数据集中;</p><p>S1.3.4、如果暗链数据集中暗链样本的数量超过阈值ξ,则停止数据集的采集,执行下一步Bert模型的训练;否则读取下一条URL地址u</p><p>优选的,所述步骤S2包括:</p><p>步骤S2.1、获取待检测的网页的超文本数据;</p><p>步骤S2.2、提取出网页中每一个标签的文本,然后对上述文本进行预处理,将文本数据中重复、无效的数据进行删减,形成待检测网页的特征文本集合</p><p>步骤S2.3、利用步骤S1训练好的Bert模型提取待检测网页标签文本的特征向量集合</p><p>步骤S2.4、通过三支决策算法对X中的每一个Bert文本特征x</p><p>优选的,所述步骤S3具体包括:如果待检测网页决策集合D中判断为负向决策的数量大于阈值</p><p>优选的,通过三支决策算法对Bert文本特征分类的方法包括:先将Bert文本特征x</p><p>优选的,根据相应决策所产生的代价值计算决策阈值α,β的方法具体为:以</p><p>优选的,所述步骤S4中包括:</p><p>步骤S4.1、提取步骤S3中判断为边界决策的标签文本;</p><p>步骤S4.2、通过minHashing算法依次计算其标签文本异常文本数据库中每条记录的文本字段的相似度;</p><p>步骤S4.3、统计标签文本与每一类异常文本的平均相似度;</p><p>步骤S4.4、确定平均相似度最大的类别;</p><p>步骤S4.5、如果标签文本与各类别的异常文本间最大的平均相似度大于等于设定的阈值ε,则将标签文本设置为平均相似度最大的类别,如果标签文本与各类别的异常文本间最大的平均相似度小于设定的阈值ε,则依顺序将标签文本的类别设置为新类别,同时更新异常文本类别数量;</p><p>步骤S4.6、将标签文本及其类别保存到异常文本数据库中;</p><p>步骤S4.7、读取下一条边界决策中的标签文本,如果标签文本有效,则转到步骤S4.2,继续处理该边界文本;如果标签文本为空,表明边界决策中的标签文本已处理完毕,结束本步骤。</p><p>优选的,所述步骤S5具体包括:</p><p>步骤S5.1、统计异常文本数据库中每一类异常文本的频数;</p><p>步骤S5.2、统计最大的异常文本类别频数;</p><p>步骤S5.3、统计异常文本数据库中异常文本总数;</p><p>步骤S5.4、如果存在异常文本类别的频数大于设定的阈值σ,或者异常文本的总数超过设定的阈值τ,则将异常文本数据库中异常文本交由人工复核审查是否包含非法敏感关键词;</p><p>步骤S5.5、对应异常文本数据库中异常文本,如果文本包含非法敏感关键词,则将其标注为负类;如果文本中只包含正常关键词,则将其标注为正类;如果文本中包含的关键词词性不明,则从数据库中删除,暂不处理;然后,将标注好的数据添加到数据集中;</p><p>步骤S5.6、采用更新的数据集重新训练Bert模型。</p><p>本发明具有以下优点:本发明基于三支决策算法来延迟决策模型中未经充分训练的数据,一方面减少传统二支决策带来的错判或者漏判风险,另一方面通过引入人工来复核被判断为边界决策的标签文本,对其进行标注并更新到暗链文本数据库中,进而更新Bert暗链文本分类模型,可以使得本发明在面对不断更新的暗链关键词时依然维持优异的鲁棒性。即本发明在进行暗链检测的同时不断地反馈更新现有的系统,从而能够更加有效地适应不断变化的网络环境,检测的准确性与召回率也得到大大增强。</p><p>附图说明</p><p>图1为本发明一种基于Bert模型和三支决策算法的网页暗链检测方法的流程图;</p><p>图2为本发明中采用三支决策算法进行判断的流程图。</p><p>具体实施方式</p><p>下面对照附图,通过对实施例的描述,对本发明具体实施方式作进一步详细的说明,以帮助本领域的技术人员对本发明的发明构思、技术方案有更完整、准确和深入的理解。</p><p>如图1、2所示,本发明提供了一种基于Bert模型和三支决策算法的网页暗链检测方法,包括下列步骤。</p><p>S1、收集正常网页和网页暗链中的文本信息形成数据集,基于该数据集训练面向暗链文本特征的Bert模型(即基于Bert的文本分类模型)。</p><p>该步骤具体包括下列子步骤。</p><p>S1.1、收集大量网站的URL地址。</p><p>S1.2、对于收集的URL地址集合中每条URL地址u</p><p>该子步骤具体执行以下操作:</p><p>S1.2.1、爬取u</p><p>S1.2.2、计算超文本中<head>部分的Hash值hash(h</p><p>S1.2.3、对于超文本<head>部分,提取<title>以及<meta>中“keyword”、“descriptions”等标签中的文本信息;对于超文本<body>部分,提取每个具体锚文本中的文本信息。然后,对于每个标签中提取的文本信息分别进行人工标注,如果文本中包含色情、诈骗、赌博、非法游戏私服、虚假医疗等非法敏感关键词,则将该文本标注为负类(即暗链);如果文本中只包含正常文本,则将该文本标注为正类;如果文本无意义或者词性不明,则丢弃该文本。最后,将标注的结果保存到网页暗链数据集中。</p><p>S1.3、由于包含暗链网页的网页只占网页中极少一部分,通过S1.2步骤构造的数据库中正、负样本偏置严重。本步骤设定暗链数据集中暗链样本的数量阈值,当暗链样本的数量超过数量阈值,则停止数据集的采集,执行下一步Bert模型的训练,否则通过本步骤继续采集暗链样本以补充负样本,降低样本偏置。</p><p>采集过程中每隔一个指定时间,对于网页源数据库中每个URL地址u</p><p>S1.3.1、爬取u</p><p>S1.3.2、计算超文本中<head>部分的Hash值hash(h′</p><p>S1.3.3、对于超文本<head>部分,提取<title>以及<meta>中“keyword”、“descriptions”等标签中的文本信息;对于超文本<body>部分,提取每个具体锚文本中的文本信息。然后,对于每个标签中提取的文本信息分别进行人工标注,如果文本中包含色情、诈骗、赌博、非法游戏私服、虚假医疗等非法敏感关键词,则将该文本标注为负类(即暗链),然后将标注为负类的结果保存到网页暗链数据集中。</p><p>S1.3.4、如果暗链数据集中暗链样本的数量超过阈值ξ,则停止数据集的采集,执行下一步Bert模型的训练;否则读取下一条URL地址u</p><p>S1.4、基于步骤S1.2和S1.3中构建的暗链数据集,训练基于Bert的暗链文本分类模型。文本分类模型能对网页中的文本特征进行提取与分类,构建相应的网页暗链数据集,并提取网页暗链的锚文本特征形成特征库。</p><p>S2、提取待检测网页中的文本信息,利用所述Bert模型从上述文本信息中提取特征向量,再通过三支决策算法对所述特征向量进行分类,得到待检测网页的决策集合,决策集合包含负向决策、正向决策和边界决策三种元素。</p><p>该步骤具体包括:</p><p>步骤S2.1、获取待检测的网页的超文本数据。</p><p>步骤S2.2、提取出网页中每一个标签的文本,然后对上述文本进行预处理,将文本数据中重复、无效的数据进行删减,形成待检测网页的特征文本集合</p><p>步骤S2.3、利用步骤S1训练好的Bert模型提取待检测网页标签文本的特征向量集合</p><p>步骤S2.4、通过三支决策算法对X中的每一个Bert文本特征x</p><p>通过三支决策算法对Bert文本特征分类的方法包括:先将Bert模型从文本t</p><p>根据相应决策所产生的代价值计算决策阈值α,β的方法具体为:以</p><p>表1:三支决策代价表</p><p>定义如下:λ</p><p>S3、根据三支决策算法的分类结果判断待检测网页是否存在暗链,当能确定待检测网页是否存在暗链时,根据判断结果向第三方警示、报告或结束本网页的检测,而后转到步骤S2;当网站中是否存在暗链无法判断时,将由下一步处理网站中无法判断的边界域标签文本。</p><p>该步骤具体包括:如果待检测网页决策集合D中判断为负向决策的数量大于阈值</p><p>S4、对于归为边界域的标签文本,通过minHashing算法依次计算其与异常文本数据库中所有记录的文本字段的相似度,根据相似度选择将该标签文本保存在异常文本数据库的已有类别中或新设置的类别中。</p><p>具体包括:</p><p>步骤S4.1、提取步骤S3中判断为边界决策的标签文本t</p><p>步骤S4.2、通过minHashing算法依次计算标签文本t</p><p>步骤S4.3、统计标签文本t</p><p>步骤S4.4、确定平均相似度最大的类别</p><p>步骤S4.5、如果h(t</p><p>步骤S4.6、将标签文本t</p><p>步骤S4.7、读取下一条边界决策中的标签文本t</p><p>S5、根据异常文本数据库中某类异常文本的频数或者异常文本数据库中记录的总数是否超过对应阈值判断是否将异常文本数据库中异常文本交由人工复核审查,审查后更新数据集并重新训练Bert模型。</p><p>所述步骤S5包括:</p><p>步骤S5.1、统计异常文本数据库中每一类异常文本的频数,记第k类异常文本的频数为TF</p><p>步骤S5.2、统计最大的异常文本类别频数,记为</p><p>步骤S5.3、统计异常文本数据库中异常文本总数,记为</p><p>步骤S5.4、如果TF</p><p>步骤S5.5、对应异常文本数据库中异常文本,如果文本包含非法敏感关键词,则将其标注为负类;如果文本中只包含正常关键词,则将其标注为正类;如果文本中包含的关键词词性不明,则从数据库中删除,暂不处理;然后,将标注好的数据添加到数据集中。</p><p>步骤S5.6、采用更新的数据集重新训练Bert模型。</p><p>本发明的优点在于当面对大量的数据集时可以提供准确的分析,且能够根据收集到的暗链属性针对目标网址提供清晰的反馈。对于较新的可疑敏感关键词也可以精准捕捉,在检测的同时不断地反馈更新现有的系统,从而更加有效全面地检测网站中的暗链。在提高网站管理方在检测暗链植入方面的效率的同时,也可以降低日常维护网站的费用。</p><p>上面结合附图对本发明进行了示例性描述,显然本发明具体实现并不受上述方式的限制,只要采用了本发明的发明构思和技术方案进行的各种非实质性的改进,或未经改进将本发明构思和技术方案直接应用于其它场合的,均在本发明保护范围之内。</p>
</div>
<div class="gradBox" style="display: block;"></div>
<div class="download">
<a href="javascript:orderEmailTipnew('06120116498879',95,12);;">完整全部详细技术资料下载</a>
</div>
</div>
<div class="col-art-footer" style="background-color: #fff;line-height: 25px;padding: 25px;">
<ul>
<li><span>该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。</span></li>
<li><span>专利发明人:</span></li>
<li><span>专利申请人:江苏警官学院;</span></li>
</ul>
<ul>
<li><span>上一篇:</span><a style="color: #666;"
href="https://zhuanli.zhangqiaokeyan.com/patent_8_138/06120116498877.html" title="上一篇">一种噪声智能控制系统柜</a></li>
<li><span>下一篇:</span><a style="color: #666;"
href="https://zhuanli.zhangqiaokeyan.com/patent_8_138/06120116498880.html" title="下一篇">一种建筑施工用预制件浇筑设备</a></li>
</ul>
</div>
<div class="detailxgjs">
<div class="tit">相关技术</div>
<div class="left">
<ul>
<li>
基于机器学习的网页暗链检测方法和装置
</li>
<li>
一种基于三支决策的双激素人工胰脏模型预测控制算法
</li>
<li>
域识别加主题识别构建机器学习模型检测网页暗链的方法
</li>
</ul>
</div>
</div>
</div>
<div class="aside">
<div class="asidelist">
<div class="title">技术分类</div>
<ul>
<li><a href="/patent_1_9/" title="农业、林业、畜牧业、狩猎、诱捕、捕鱼">农业;林业;畜牧业;狩猎;诱捕;捕鱼</a></li>
<li><a href="/patent_1_10/" title="焙烤;制作或处理面团的设备;焙烤用面团">焙烤;制作或处理面团的设备;焙烤用面团</a></li>
<li><a href="/patent_1_11/" title="屠宰;肉品处理;家禽或鱼的加工">屠宰;肉品处理;家禽或鱼的加工</a></li>
<li><a href="/patent_1_12/" title="其他类不包含的食品或食料;及其处理">其他类不包含的食品或食料;及其处理</a></li>
<li><a href="/patent_1_13/" title="烟草、雪茄烟、纸烟、吸烟者用品">烟草、雪茄烟、纸烟、吸烟者用品</a></li>
<li><a href="/patent_1_14/" title="服装">服装</a></li>
<li><a href="/patent_1_15/" title="帽类制品">帽类制品</a></li>
<li><a href="/patent_1_16/" title="鞋类">鞋类</a></li>
<li><a href="/patent_1_17/" title="服饰缝纫用品、珠宝">服饰缝纫用品、珠宝</a></li>
<li><a href="/patent_1_18/" title="手携物品或旅行品">手携物品或旅行品</a></li>
<li><a href="/patent_1_19/" title="刷类制品">刷类制品</a></li>
<li><a href="/patent_1_20/" title="家具、家庭用的物品或设备、咖啡磨、香料磨、一般吸尘器">家具、家庭用的物品或设备、咖啡磨、香料磨、一般吸尘器</a></li>
<li><a href="/patent_1_21/" title="医学或兽医学、卫生学">医学或兽医学、卫生学</a></li>
<li><a href="/patent_1_22/" title="救生、消防">救生、消防</a></li>
<li><a href="/patent_1_23/" title="运动、游戏、娱乐活动">运动、游戏、娱乐活动</a></li>
<li><a href="/patent_1_24/" title="本部其他类目中不包括的技术主题">本部其他类目中不包括的技术主题</a></li>
<li><a href="/patent_2_25/" title="一般的物理或化学的方法或装置">一般的物理或化学的方法或装置</a></li>
<li><a href="/patent_2_26/" title="破碎、磨粉或粉碎、谷物碾磨的预处理">破碎、磨粉或粉碎、谷物碾磨的预处理</a></li>
<li><a href="/patent_2_27/" title="用液体或用风力摇床或风力跳汰机分离固体物料、从固体物料或流体中分离固体物料的磁或静电分离、高压电场分离">用液体或用风力摇床或风力跳汰机分离固体物料、从固体物料或流体中分离固体物料的磁或静电分离、高压电场分离</a></li>
<li><a href="/patent_2_28/" title="用于实现物理或化学工艺过程的离心装置或离心机">用于实现物理或化学工艺过程的离心装置或离心机</a></li>
<li><a href="/patent_2_29/" title="一般喷射或雾化、对表面涂覆液体或其他流体的一般方法">一般喷射或雾化、对表面涂覆液体或其他流体的一般方法</a></li>
<li><a href="/patent_2_30/" title="一般机械振动的发生或传递">一般机械振动的发生或传递</a></li>
<li><a href="/patent_2_31/" title="将固体从固体中分离、分选">将固体从固体中分离、分选</a></li>
<li><a href="/patent_2_32/" title="清洁">清洁</a></li>
<li><a href="/patent_2_33/" title="固体废物的处理、被污染土壤的再生">固体废物的处理、被污染土壤的再生</a></li>
<li><a href="/patent_2_34/" title="基本上无切削的金属机械加工、金属冲压">基本上无切削的金属机械加工、金属冲压</a></li>
<li><a href="/patent_2_35/" title="铸造、粉末冶金">铸造、粉末冶金</a></li>
<li><a href="/patent_2_36/" title="机床、其他类目中不包括的金属加工">机床、其他类目中不包括的金属加工</a></li>
<li><a href="/patent_2_37/" title="磨削、抛光">磨削、抛光</a></li>
<li><a href="/patent_2_38/" title="手动工具、轻便机动工具、手动器械的手柄、车间设备、机械手">手动工具、轻便机动工具、手动器械的手柄、车间设备、机械手</a></li>
<li><a href="/patent_2_39/" title="手动切割工具、切割、切断">手动切割工具、切割、切断</a></li>
<li><a href="/patent_2_40/" title="木材或类似材料的加工或保存、一般钉钉机或钉U形钉机">木材或类似材料的加工或保存、一般钉钉机或钉U形钉机</a></li>
<li><a href="/patent_2_41/" title="加工水泥、黏土或石料">加工水泥、黏土或石料</a></li>
<li><a href="/patent_2_42/" title="塑料的加工、一般处于塑性状态物质的加工">塑料的加工、一般处于塑性状态物质的加工</a></li>
<li><a href="/patent_2_43/" title="压力机">压力机</a></li>
<li><a href="/patent_2_44/" title="纸品或纸板或类似纸的方式加工的材料制品制作、纸或纸板或类似纸的方式加工的材料的加工">纸品或纸板或类似纸的方式加工的材料制品制作、纸或纸板或类似纸的方式加工的材料的加工</a></li>
<li><a href="/patent_2_45/" title="层状产品">层状产品</a></li>
<li><a href="/patent_2_46/" title="附加制造技术">附加制造技术</a></li>
<li><a href="/patent_2_47/" title="印刷、排版机、打字机、模印机">印刷、排版机、打字机、模印机</a></li>
<li><a href="/patent_2_48/" title="装订、图册、文件夹、特种印刷品">装订、图册、文件夹、特种印刷品</a></li>
<li><a href="/patent_2_49/" title="书写或绘图器具、办公用品">书写或绘图器具、办公用品</a></li>
<li><a href="/patent_2_50/" title="装饰艺术">装饰艺术</a></li>
<li><a href="/patent_2_51/" title="一般车辆">一般车辆</a></li>
<li><a href="/patent_2_52/" title="铁路">铁路</a></li>
<li><a href="/patent_2_53/" title="无轨陆用车辆">无轨陆用车辆</a></li>
<li><a href="/patent_2_54/" title="船舶或其他水上船只、与船有关的设备">船舶或其他水上船只、与船有关的设备</a></li>
<li><a href="/patent_2_55/" title="飞行器、航空、宇宙航行">飞行器、航空、宇宙航行</a></li>
<li><a href="/patent_2_56/" title="输送、包装、贮存、搬运薄的或细丝状材料">输送、包装、贮存、搬运薄的或细丝状材料</a></li>
<li><a href="/patent_2_57/" title="卷扬、提升、牵引">卷扬、提升、牵引</a></li>
<li><a href="/patent_2_58/" title="开启或封闭瓶子、罐或类似的容器、液体的贮运">开启或封闭瓶子、罐或类似的容器、液体的贮运</a></li>
<li><a href="/patent_2_59/" title="鞍具、家具罩面">鞍具、家具罩面</a></li>
<li><a href="/patent_2_60/" title="微观结构技术">微观结构技术</a></li>
<li><a href="/patent_2_61/" title="纳米技术">纳米技术</a></li>
<li><a href="/patent_3_63/" title="无机化学">无机化学</a></li>
<li><a href="/patent_3_64/" title="水、废水、污水或污泥的处理">水、废水、污水或污泥的处理</a></li>
<li><a href="/patent_3_65/" title="玻璃、矿棉或渣棉">玻璃、矿棉或渣棉</a></li>
<li><a href="/patent_3_66/" title="水泥、混凝土、人造石、陶瓷、耐火材料">水泥、混凝土、人造石、陶瓷、耐火材料</a></li>
<li><a href="/patent_3_67/" title="肥料、肥料制造">肥料、肥料制造</a></li>
<li><a href="/patent_3_68/" title="炸药、火柴">炸药、火柴</a></li>
<li><a href="/patent_3_69/" title="有机化学">有机化学</a></li>
<li><a href="/patent_3_70/" title="有机高分子化合物、其制备或化学加工、以其为基料的组合物">有机高分子化合物、其制备或化学加工、以其为基料的组合物</a></li>
<li><a href="/patent_3_71/" title="染料、涂料、抛光剂、天然树脂、黏合剂、其他类目不包含的组合物、其他类目不包含的材料的应用">染料、涂料、抛光剂、天然树脂、黏合剂、其他类目不包含的组合物、其他类目不包含的材料的应用</a></li>
<li><a href="/patent_3_72/" title="石油、煤气及炼焦工业、含一氧化碳的工业气体、燃料、润滑剂、泥煤">石油、煤气及炼焦工业、含一氧化碳的工业气体、燃料、润滑剂、泥煤</a></li>
<li><a href="/patent_3_73/" title="动物或植物油、脂、脂肪物质或蜡、由此制取的脂肪酸、洗涤剂、蜡烛">动物或植物油、脂、脂肪物质或蜡、由此制取的脂肪酸、洗涤剂、蜡烛</a></li>
<li><a href="/patent_3_74/" title="生物化学、啤酒、烈性酒、果汁酒、醋、微生物学、酶学、突变或遗传工程">生物化学、啤酒、烈性酒、果汁酒、醋、微生物学、酶学、突变或遗传工程</a></li>
<li><a href="/patent_3_75/" title="糖工业">糖工业</a></li>
<li><a href="/patent_3_76/" title="使用化学药剂、酶类或微生物处理小原皮、大原皮或皮革的工艺,如鞣制、浸渍或整饰、其所用的设备、鞣制组合物(皮革或毛皮的漂白入D06L、皮革或毛皮的染色入D06P)">使用化学药剂、酶类或微生物处理小原皮、大原皮或皮革的工艺,如鞣制、浸渍或整饰、其所用的设备、鞣制组合物(皮革或毛皮的漂白入D06L、皮革或毛皮的染色入D06P)</a></li>
<li><a href="/patent_3_77/" title="铁的冶金">铁的冶金</a></li>
<li><a href="/patent_3_78/" title="冶金、黑色或有色金属合金、合金或有色金属的处理">冶金、黑色或有色金属合金、合金或有色金属的处理</a></li>
<li><a href="/patent_3_79/" title="对金属材料的镀覆、用金属材料对材料的镀覆、表面化学处理、金属材料的扩散处理、真空蒸发法、溅射法、离子注入法或化学气相沉积法的一般镀覆、金属材料腐蚀或积垢的一般抑制">对金属材料的镀覆、用金属材料对材料的镀覆、表面化学处理、金属材料的扩散处理、真空蒸发法、溅射法、离子注入法或化学气相沉积法的一般镀覆、金属材料腐蚀或积垢的一般抑制</a></li>
<li><a href="/patent_3_80/" title="电解或电泳工艺、其所用设备">电解或电泳工艺、其所用设备</a></li>
<li><a href="/patent_3_81/" title="晶体生长">晶体生长</a></li>
<li><a href="/patent_3_82/" title="组合技术">组合技术</a></li>
<li><a href="/patent_4_84/" title="天然或化学的线或纤维、纺纱或纺丝">天然或化学的线或纤维、纺纱或纺丝</a></li>
<li><a href="/patent_4_85/" title="纱线、纱线或绳索的机械整理、整经或络经">纱线、纱线或绳索的机械整理、整经或络经</a></li>
<li><a href="/patent_4_86/" title="织造">织造</a></li>
<li><a href="/patent_4_87/" title="编织、花边制作、针织、饰带、非织造布">编织、花边制作、针织、饰带、非织造布</a></li>
<li><a href="/patent_4_88/" title="缝纫、绣花、簇绒">缝纫、绣花、簇绒</a></li>
<li><a href="/patent_4_89/" title="织物等的处理、洗涤、其他类不包括的柔性材料">织物等的处理、洗涤、其他类不包括的柔性材料</a></li>
<li><a href="/patent_4_90/" title="绳、除电缆以外的缆索">绳、除电缆以外的缆索</a></li>
<li><a href="/patent_4_91/" title="造纸、纤维素的生产">造纸、纤维素的生产</a></li>
<li><a href="/patent_5_93/" title="道路、铁路或桥梁的建筑">道路、铁路或桥梁的建筑</a></li>
<li><a href="/patent_5_94/" title="水利工程、基础、疏浚">水利工程、基础、疏浚</a></li>
<li><a href="/patent_5_95/" title="给水、排水">给水、排水</a></li>
<li><a href="/patent_5_96/" title="建筑物">建筑物</a></li>
<li><a href="/patent_5_97/" title="锁、钥匙、门窗零件、保险箱">锁、钥匙、门窗零件、保险箱</a></li>
<li><a href="/patent_5_98/" title="一般门、窗、百叶窗或卷辊遮帘、梯子">一般门、窗、百叶窗或卷辊遮帘、梯子</a></li>
<li><a href="/patent_5_99/" title="土层或岩石的钻进、采矿">土层或岩石的钻进、采矿</a></li>
<li><a href="/patent_6_101/" title="一般机器或发动机、一般的发动机装置、蒸汽机">一般机器或发动机、一般的发动机装置、蒸汽机</a></li>
<li><a href="/patent_6_102/" title="燃烧发动机、热气或燃烧生成物的发动机装置">燃烧发动机、热气或燃烧生成物的发动机装置</a></li>
<li><a href="/patent_6_103/" title="液力机械或液力发动机、风力、弹力或重力发动机、其他类目中不包括的产生机械动力或反推力的发动机">液力机械或液力发动机、风力、弹力或重力发动机、其他类目中不包括的产生机械动力或反推力的发动机</a></li>
<li><a href="/patent_6_104/" title="液体变容式机械、液体泵或弹性流体泵">液体变容式机械、液体泵或弹性流体泵</a></li>
<li><a href="/patent_6_105/" title="流体压力执行机构、一般液压技术和气动技术">流体压力执行机构、一般液压技术和气动技术</a></li>
<li><a href="/patent_6_106/" title="工程元件或部件、为产生和保持机器或设备的有效运行的一般措施、一般绝热">工程元件或部件、为产生和保持机器或设备的有效运行的一般措施、一般绝热</a></li>
<li><a href="/patent_6_107/" title="气体或液体的贮存或分配">气体或液体的贮存或分配</a></li>
<li><a href="/patent_6_108/" title="照明">照明</a></li>
<li><a href="/patent_6_109/" title="蒸汽的发生">蒸汽的发生</a></li>
<li><a href="/patent_6_110/" title="燃烧设备、燃烧方法">燃烧设备、燃烧方法</a></li>
<li><a href="/patent_6_111/" title="供热、炉灶、通风">供热、炉灶、通风</a></li>
<li><a href="/patent_6_112/" title="制冷或冷却、加热和制冷的联合系统、热泵系统、冰的制造或储存、气体的液化或固化">制冷或冷却、加热和制冷的联合系统、热泵系统、冰的制造或储存、气体的液化或固化</a></li>
<li><a href="/patent_6_113/" title="干燥">干燥</a></li>
<li><a href="/patent_6_114/" title="炉、窑、烘烤炉、蒸馏炉">炉、窑、烘烤炉、蒸馏炉</a></li>
<li><a href="/patent_6_115/" title="一般热交换">一般热交换</a></li>
<li><a href="/patent_6_116/" title="武器">武器</a></li>
<li><a href="/patent_6_117/" title="弹药、爆破">弹药、爆破</a></li>
<li><a href="/patent_7_119/" title="测量、测试">测量、测试</a></li>
<li><a href="/patent_7_120/" title="光学">光学</a></li>
<li><a href="/patent_7_121/" title="摄影术、电影术、利用了光波以外其他波的类似技术、电记录术、全息摄影术">摄影术、电影术、利用了光波以外其他波的类似技术、电记录术、全息摄影术〔4〕</a></li>
<li><a href="/patent_7_122/" title="测时学">测时学</a></li>
<li><a href="/patent_7_123/" title="控制、调节">控制、调节</a></li>
<li><a href="/patent_7_124/" title="计算、推算、计数">计算、推算、计数</a></li>
<li><a href="/patent_7_125/" title="核算装置">核算装置</a></li>
<li><a href="/patent_7_126/" title="信号装置">信号装置</a></li>
<li><a href="/patent_7_127/" title="教育、密码术、显示、广告、印鉴">教育、密码术、显示、广告、印鉴</a></li>
<li><a href="/patent_7_128/" title="乐器、声学">乐器、声学</a></li>
<li><a href="/patent_7_129/" title="信息存储">信息存储</a></li>
<li><a href="/patent_7_130/" title="仪器的零部件">仪器的零部件</a></li>
<li><a href="/patent_7_131/" title="特别适用于特定应用领域的信息通信技术">特别适用于特定应用领域的信息通信技术</a></li>
<li><a href="/patent_7_132/" title="核物理、核工程">核物理、核工程</a></li>
<li><a href="/patent_8_134/" title="基本电气元件">基本电气元件</a></li>
<li><a href="/patent_8_136/" title="发电、变电或配电">发电、变电或配电</a></li>
<li><a href="/patent_8_137/" title="基本电子电路">基本电子电路</a></li>
<li><a href="/patent_8_138/" title="电通信技术">电通信技术</a></li>
<li><a href="/patent_8_140/" title="其他类目不包含的电技术">其他类目不包含的电技术</a></li>
<li><a href="/patent_9999_9999/" title="其他专利">其他专利</a></li>
</ul>
</div>
</div>
<div class="paging"></div>
</div>
</div>
<div style="clear: both;"></div>
<div style="display:none">
<p id="docid">06120116498879</p>
<span id="06120116498879down" data-source="6,"
data-out-id="CN117201055A," data-f-source-id="6" data-title="一种基于Bert模型和三支决策算法的网页暗链检测方法" data-price="10"
data-transnum="0" style="display:none;"></span></div>
<div class="xllindexfooter">
<div style="width: 1120px;margin: 0 auto;margin-top: 30px; ">
<div>
<div class="hotlinklisttitle">
<ul >
<li><a href="javascript:;">友情链接</a></li>
</ul>
</div>
<div class="hotlinklistcontent">
<div class="hotlinklistcontent1">
<ul style="overflow:hidden">
<li><a title="掌桥专利" href="https://zhuanli.zhangqiaokeyan.com/" target="_blank">掌桥专利</a></li>
<li><a title="科技查新" href="https://kejichaxin.zhangqiaokeyan.com/" target="_blank">科技查新</a></li>
<li><a title="掌桥科研" href="https://www.zhangqiaokeyan.com/" target="_blank">掌桥科研</a></li>
<li><a title="浸没式液冷" href="http://www.blueocean-china.net " target="_blank">浸没式液冷</a></li>
<li><a title="步入式恒温恒湿试验箱" href="http://www.deruitest.com" target="_blank">步入式恒温恒湿试验箱</a></li>
<li><a title="杭州室内设计培训" href="http://www.qingfengsheji.com" target="_blank">杭州室内设计培训</a></li>
<li><a title="散文精选" href="http://www.mangowenxue.com" target="_blank">散文精选</a></li>
<li><a title="管理博士" href="https://www.pxemba.com" target="_blank">管理博士</a></li>
<li><a title="雅思培训" href="https://www.longre.com" target="_blank">雅思培训</a></li>
</ul>
</div>
</div>
</div>
</div>
</div>
<div class="footer">
<p>
<a href="https://www.zhangqiaokeyan.com/about.html" title="关于我们">关于我们</a><span class="line">|</span>
<a onclick="window.open('https://103941.kefu.easemob.com/webim/im.html?configId=e4dad0df-e3b7-4d34-ba80-342ddc88f278','','width=980,height=600,left=529,top=261');" rel="nofollow" title="联系方式">联系方式</a><span
class="line"></span>
</p>
<p> 六维联合信息科技 (北京) 有限公司©版权所有,并保留所有权利。京ICP备15016152号-6 </p>
</div>
</body>
<script type="text/javascript" src="/js/jquery-1.12.4.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/jquery.cookie.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/variable.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/tip.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/login.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/common.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/lwlh_ajax.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/down.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/tj.js?v=5.1.1"></script>
<script type="text/javascript" src="https://www.zhangqiaokeyan.com/statistics/static/pagecollection.js"></script>
<script>
</script>
</html>