一种基于自监督对比学习的情绪脑电分类方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及情绪脑电分类技术领域,具体指一种基于自监督对比学习的情绪脑电分类方法。
背景技术
情感脑机接口领域目前已经取得了重大进展,研究人员能够有效地解释在受控实验室环境中收集的标记脑电图(EEG)数据。然而,脑电数据标注耗时长、资源密集,限制了其在现实场景中的实际应用。如何利用有限的标签识别情绪已经成为一个新的研究和应用瓶颈。
发明内容
本发明针对现有技术得不足,提出一种基于自监督对比学习的情绪脑电分类方法,可以有效地对情绪脑电信号进行分类,最高识别准确率可达到93、77%,并且也可以微调到其他下游任务。
为了解决上述技术问题,本发明的技术方案为:
本发明使用SEED数据集作为样本,将情绪脑电预处理后先进行预训练,训练完成后只保留其中的编码器部分,后连接一个多层感知机分类器进行微调训练,用于进行情绪识别分类,目的是通过模型的自监督预训练,通过输入无标签脑电信号在不同信号变换后在高维特征空间的表征对比,学习到信号的高维通用表征,再在微调阶段时候较少的标签迁移微调模型到具体的下游分类任务。具体包括以下步骤:
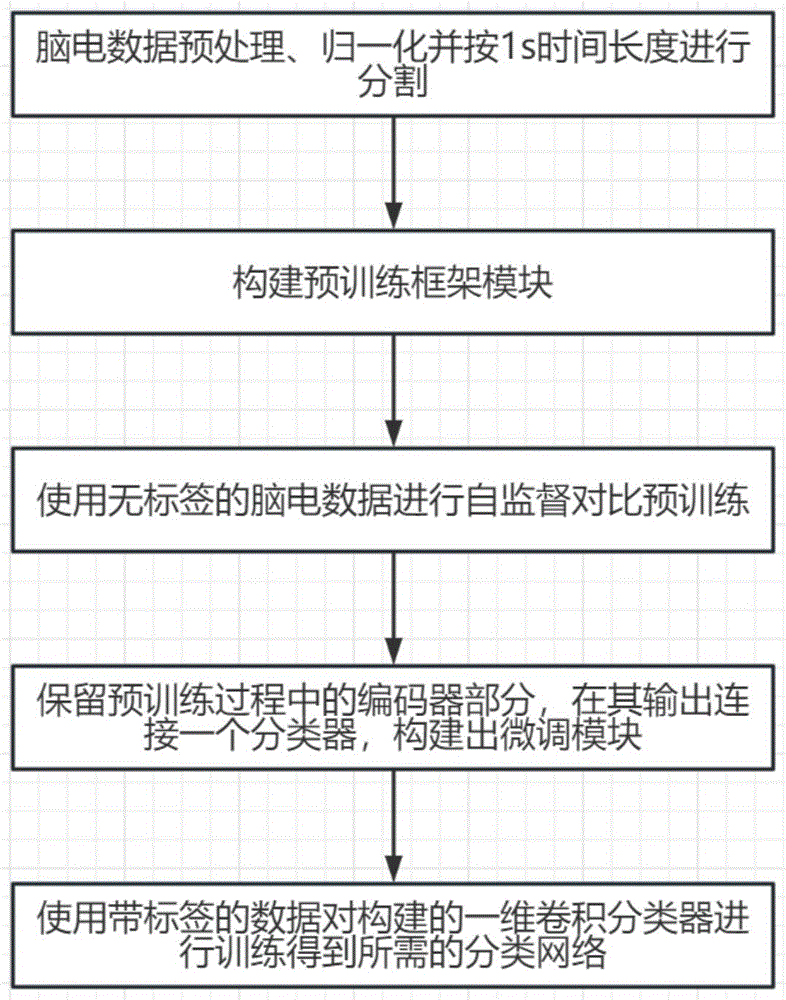
步骤1、对脑电数据进行预处理,并进行数据归一化,再划分为训练集和测试集,并将脑电信号数据按1s的分段划分,作为输入。
步骤2、构建预训练框架模块。
步骤3、使用无标签的脑电数据进行自监督对比预训练。
步骤4、保留预训练过程中的编码器部分,在其输出连接一个多次感知机,构建一维CNN分类器。
步骤5、使用带标签的数据,对构建的一维CNN分类器进行训练,得到所需的分类网络。
作为优选,所述的步骤1中,对脑电数据的预处理包括信号的降噪处理、降采样至200HZ、使用0-75Hz的低通滤波器进行滤波等,经过预处理后的信号能够滤掉大部分信号采集过程中的噪声和污染。
作为优选,所述的步骤2中,构建预训练框架模块,框架的主要结构是一个双流分支结构,一个分支是训练分支,一个分支是目标分支,其中训练分支由一个编码器一个投射器和一个预测器构成,而目标分支由一个编码器和一个投射器构成,两个分支的参数不进行共享的。其中编码器是由一维卷积神经网络构成,而投射器和预测器是由多层感知机构成的。
作为优选,所述的步骤3中,对比预训练过程中,训练分支的模型参数通过梯度下降的方式进行更新,而目标分支的模型参数通过训练分支的参数的移动指数平均来更新。最后训练分支的预测结果p
3-1、脑电信号分段x先通过两个随机的信号变换方法V(x)和U(x),得到经过变换后的信号v和v’。
3-2、通过一维卷积神经网络f(x)得到两个变换信号的高维特征y和y’。
3-3、训练分支的脑电特征数据还需要经过一个投射器和一个预测器,得到特征p,而目标分支的数据只经过投射器得到特征z。
3-4、特征p和特征z求得对比损失。特征越接近,损失越小,相反越大。
作为优选,所述的步骤4中,保留预训练阶段的编码器训练方法为:
4-1、网络起始搭建一个卷积层作为输入,随后连接一个BN层和RELU层。
4-2、随后连接一个带有最大池化的残差连接模块,模块中主要是由一个一维卷积、BN层、RELU激活单元以及Dropout层和另一个卷积层。Dropout层主要用于随机关闭一些网络的神经元,防止过拟合。
4-3、第三部分是一个堆叠8次的一维卷积层模块。该模块先经过BN和RELU,然后再通过卷积、BN、RELU、Dropout、卷积,其中还包含来自模块入口输入的残差连接。
4-4、在经过一个BN和平均池化层后得到编码器的输出。
作为优选,步骤5中,编码器输出后面还需要接一个全连接多层感知机构成情绪分类任务的分类器。
5-1、多层感知机由一个全连接层起始,输出维度为384,后接BN层和RELU层,然后再是一个Dropout层。
5-2、重复一次步骤4-6中的结构,其中全连接层的维度为192。
5-3、最后以一个全连接层作为收尾得到输出,输出维度为3。
本发明具有以下的特点和有益效果:
采用上述技术方案,在无标签预训练过程中让训练分支通过向目标分支进行学习、模仿、对比的方式,无需大量负样本的方式也能学习到脑电信号的高维通用表征。使得通过预训练以后的编码器,可以在仅使用部分标签的数据进行微调的情况,也能达到优秀的情绪分类准确率,同时学习到的通用表征还可以用于其他的下游分类任务。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的流程图;
图2为本发明实施例中分类器的结构;
图3为本发明实施例中预训练框架模块的框架图。
具体实施方式
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”等的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以通过具体情况理解上述术语在本发明中的具体含义。
本实施例使用SEED数据集作为样本,对其中的情绪脑电进行预处理和数据分割,再进行数据归一化,先使用对比学习方法进行预训练,使模型学习到脑电数据的高维通用表征,再取出预训练完成的编码器,并抛弃掉其他模块,连接上一个由多层感知机组成的分类器,再以带标签的数据作为输入微调整个模型,使预训练得到的高维特征表征能力能够针对特定的数据分布和分类任务进行微调特化。该方法可以有效地对情绪脑电信号进行分类,最高识别准确率可达到93、77%,并且也可以微调到其他下游任务。
具体的,如图1所示,包括如下步骤:
步骤1、使用脑电采集设备采集人脑脑电情绪信号,其中采集的脑电信号源使用国际10-20导联系统获得,采样频率为1000Hz;
步骤2、对采集到的脑电数据进行200Hz的降采样,并进行0-75Hz的带通滤波。
步骤3、对处理好的脑电数据分段,每1s作为一个片段进行数据分割,并展开,即输入的数据维度为1*12400,并对数据进行归一化处理,其中预处理好的脑电数据包括无标签脑电数据和带标签脑电数据。
步骤4、预处理好的无标签脑电数据输入到预训练框架中,训练过程中,无标签脑电数据会先经过两个不同的随机的数据扩增,得到相同数据源下的两个不同数据视角,分别作为两个分支的输入进行训练。训练分支的参数通过梯度下降算法进行更新,而目标分支没有梯度,其参数通过训练分支的移动指数平均来进行更新,给定一个衰减率τ∈[0,1],求得参数ξ=τξ+(1-τ)θ,其中等式右边的ξ为目标分支的原参数,θ为训练分支的参数。
具体的,如图3所示,所述预训练框架模块包括训练分支和目标分支,所述训练分支由一个编码器一个投射器和一个预测器构成,所述目标分支由一个编码器和一个投射器构成,两个分支的参数不进行共享的,所述编码器是由一维卷积神经网络构成,所述投射器和预测器是由多层感知机构成的。
步骤5、对比学习通过在训练过程中尽可能减小两个分支的输出特征之间的差异性,进而学习到数据的通用表征。
步骤6、在预训练完成以后只保留下编码器部分及其参数,移除其他的部分。
步骤7、在训练分支中的编码器的后面连接一段多层感知机,构成一个分类器,多层感知机的参数是随机初始化的。
步骤8、使用带标签的脑电数据对步骤7中构建的分类器进行常规的全监督训练,得到能够使用脑电数据进行情绪识别的一维卷积神经网络模型。
具体的,如图2所示,所构建的分类器中编码器的编码方法为:
S8-1、网络起始搭建一个卷积层作为入口,输入为经过数据分段后的脑电数据,输入维度为1×12400,随后连接一个BN批量归一化层和RELU激活层,其中,带BN和RELU的一维卷积层,有12个滤波器,卷积核设置为1*32,步长为1*1,输出维度为12×6200维。
S8-2、随后连接一个带有最大池化的残差连接模块,输入是S7-1的输出,残差连接模块中主要是由一个一维卷积、BN层、RELU激活单元以及Dropout层和另一个卷积层,带有最大池化残差块的一维卷积层,由一个卷积层开头,经过BN和RELU激活后,进行Dropout,再由一个一维卷积层收尾,最后加上经过最大池化后的残差块,最大池化的核大小为1*3,步长为2,卷积核的尺寸为1*33,输出维度为24×3100维。
S8-3、接下来是一组堆叠8次的卷积层模块,该卷积层模块先经过BN和RELU,然后再通过卷积、BN、RELU、Dropout、卷积,其中还包含来自堆叠8次的卷积层模块输入的残差块;
S8-4、S8-3得到的输出再经过一个BN和平均池化层后得到编码器的输出,输出的维度为1×384维。
S8-5、多层感知机由一个全连接层起始,输入特征的维度为384,后接BN层和RELU层,然后再是一个Dropout层;
S8-6、重复一次步骤S8-5中的结构,其中全连接层的输出维度为192维;
S8-7、最后以一个全连接层作为收尾得到输出,输出维度为3并经过softmax得到分类结果。
全部工作的流程图,如图1所示,这里以SEED数据集为例,16个受试者为实验对象,每个受试者3次实验,每次实验记录62个通道,经过预处理和数据分割,得到作为模型网络输入的样本。表1是基于SEED数据集,对比全监督分类模型的三分类效果对比:
表1模型分类准确率对比
通过预训练和微调相结合的自监督学习模型进行情绪识别的三分类准确率得到了可观的结果,准确率达到了93、77%,相比其他分类算法有一定提高。表2是基于SEED数据集对比在微调阶段,使用不同百分比的标签时,模型的三分类效果对比:
表2不同标签率的模型分类准确率对比
可以得出经过预训练以后,模型在使用部分标签数据进行微调训练的时候,同样可以得到相当的准确率,使得后续相关的研究得以减少对数据标签的需求。
以上结合附图对本发明的实施方式作了详细说明,但本发明不限于所描述的实施方式。对于本领域的技术人员而言,在不脱离本发明原理和精神的情况下,对这些实施方式包括部件进行多种变化、修改、替换和变型,仍落入本发明的保护范围内。