一种基于驾驶员风格的DQN紧急制动自适应控制方法
文献发布时间:2024-04-18 19:58:53
技术领域:
本发明属于新能源汽车制动领域,具体地说是一种基于驾驶员风格的DQN紧急制动自适应控制方法。
技术背景:
自动紧急制动系统(AEB)是一项先进的汽车安全技术,旨在减少交通事故的发生并降低其严重程度。AEB系统可以在车辆检测到潜在碰撞威胁时自动采取行动,以减少碰撞风险或最大程度地减小碰撞损害。
AEB系统使用各种传感器和摄像头来监测车辆前方的道路情况。这些传感器可以识别前方的车辆、行人、自行车等障碍物。一旦系统检测到潜在碰撞威胁,AEB系统首先会向驾驶员发出警告,提示他们采取紧急刹车或避让动作。这种警告通常以声音、视觉或震动的形式来提醒驾驶员。如果在提示过后驾驶员未能及时作出反应,AEB系统将自动激活车辆的制动系统,以避免碰撞或减小碰撞冲击,从而保护车辆乘客和其他道路用户。
传统的AEB系统通常配备了多种传感器,包括雷达、摄像头、激光器和超声波传感器。这些传感器负责监测车辆前方的道路情况,包括其他车辆、行人、障碍物和交通信号。在获取信息后,传统控制策略通常需要建立复杂的规则来进行控制,这些规则通常来源于人工经验。面对复杂工况和场景时,不光建立模型比较困难,还要面临大量的手动调参、控制精度不够和运用时鲁棒性较差等一系列问题。
基于深度强化学习的控制策略可以端到端的将状态输入转换为油门和刹车等控制动作,这极大地减少了建模的困难。并且可以较大限度的发挥机器学习的优势,根据所处的环境自适应地学习策略。深度强化学习模型能够通过与环境交互进而不断被优化,它还可以在大规模数据上进行有效训练,通过大量样本来提高泛化性能。这些特点使深度强化学习在建模和解决实际问题时具有巨大的潜力,已经在多个领域取得了显著的成就。但现有方法都缺乏对驾驶员风格的考虑,这使得部分驾驶员对智能汽车制动系统缺乏一定的信任度和满意度。
本发明应用深度强化学习驱使智能车辆在安全完成制动的同时可以考虑驾驶员风格的不同。高维的语义分割照片信息、驾驶员风格信息、一维的相对位置与相对速度信息共同组成了DQN算法的状态输入。深度神经网络利用上述状态输入拟合强化学习的值函数,强化学习用试错的方式不断探索环境,使得智能车辆在面对不同驾驶风格的驾驶员时有着不同的控制策略,实现智能车辆的制动系统兼具人性化。
发明内容:
为了使新能源汽车紧急制动系统具有足够的安全性且能人性化地考虑不同驾驶员的驾驶风格,本发明提供一种基于驾驶员风格的DQN紧急制动自适应控制方法。该方法在车辆行驶过程中遇到有碰撞风险的场景时采取合适的制动动作,实现预期的制动效果。本发明中的自主制动系统使用组合的多类型信息,在面临危险场景时自动决策采取何种制动动作。该制动问题可以描述为马尔可夫决策过程寻找最优策略的问题。动作空间有4个制动动作,它们分别对应制动踏板的4个不同压力。制动控制策略通过深度Q网络来学习,在学习的过程中为了保证能学习到理想的控制策略,本发明提出了多目标奖励函数引导智能车辆学习最优的控制策略。本发明里的DQN训练场景为不同驾驶风格的驾驶员驾乘智能车辆遇到行人横穿马路的场景。
本发明解决技术问题所采取的技术方案如下:
一种基于驾驶员风格的DQN紧急制动自适应控制方法,其特征在于,该方法包括训练任务设计、驾驶员风格检测、状态与动作空间设计、多目标奖励函数设计及DQN参数设置。首先,根据不同的交通场景对训练任务展开设计。其次,收集驾驶员对不同工况的处理数据分析得到驾驶员风格系数。再次,将摄像头所获取的图片信息进行处理,与雷达传感器所获取的低维信息和驾驶员风格系数进行融合,作为DQN算法的状态输入。多目标奖励函数设计使得控制策略在充分保证车辆制动安全性的前提下更加拟人化。最后,根据所提出方法中的超参数对DQN参数进行设置,利用Carla仿真软件对智能汽车进行循环训练得到最优制动策略。
该方法包括以下步骤:
步骤1、训练任务设计:
步骤1.1、建立制动控制决策中的马尔可夫模型:
基于深度强化学习的紧急制动过程具备马尔可夫性,即下一时刻的状态只与当前时刻的状态有关,而与之前过往的历史状态无关。马尔可夫决策过程基于智能车辆与环境交互的过程进行建立,包括动作、奖励、状态三要素。智能车辆感知当前状态环境,通过控制策略实施动作,进入下一时刻的环境状态并得到奖励。状态S、动作A、状态转移概率P、奖励R和折扣因子γ的合集(S、A、P、R、γ)构成了强化学习马尔可夫过程的五元组。本发明将考虑驾驶员风格的紧急制动过程建模为马尔可夫决策过程,通过强化学习使得智能车辆学习到最优的控制策略。
步骤1.2、制动控制训练任务设计:
在训练任务中,主车的初速度为V
步骤2、考虑驾驶员风格的最小安全距离修正方法设计:
步骤2.1、驾驶员风格系数的获取:
此步骤需要捕捉连续的车辆行驶工况信息,得到每一时刻车辆的速度、加速度和冲击度J,然后以T作为一个周期进行处理,得到驾驶员风格系数R
式中,SD
步骤2.2、最小安全距离的修正:
此步骤提出最小安全距离d
式中,a,b,c,d都是常数。
步骤3、状态与动作空间设计:
步骤3.1、语义图像的处理:
在Carla仿真软件中,将具有语义分割功能的相机设定到主车正上方的位置,相机所拍到的场景信息具有俯视图特征。进而对照片进行预处理,首先,对图片中不同物体分配不同的像素类别,并对应不同的颜色,由此,处理后的分割图片由不同颜色块组成。除训练任务需要的主要参与对象,场景中的树木和建筑物等次要对象均改为相同的颜色,因此,处理后的分割图片只由路面、车道线、主车、行人和其他所有事物5种颜色组成。
步骤3.2、多维信息的组合:
每一帧图片经过步骤3.1处理后,再经由三层卷积层和一层全连接层所构成的卷积神经网络分别对预处理后的图像进行特征提取,同时,利用其中的全连接层将多维的图像特征铺展为一维矩阵。而后,利用另一层全连接层将前述一维矩阵和步骤2.1所述驾驶员风格系数及传感器所获取的一维信息进行拼接获得新一维信息矩阵并作为DQN算法的状态输入。
步骤3.3、动作空间设计:
动作空间包含车辆的4个制动动作(弱制动、较弱制动、强制动、较强制动),将步骤3.2得到的一维矩阵输入到DQN算法中,经过神经网络的前向传播输出层输出与4个动作相对应的Q值。
步骤4、多目标奖励函数设计:
为保证制动过程中车辆的稳定性与安全性,本发明采用与驾驶风格存在对应关系的最小安全距离作为奖励函数的设计依据,并设定修正后的理想安全距离位置与其外延q米之间的范围为理想停车区域。当车辆停车位置处在理想停车区域内时,给予回合正奖励,鼓励车辆停止在理想停车区域。而停车位置在理想停车区域以外时,难以满足不同风格驾驶员对于制动距离与停车后最小安全距离的心理预期,给予回合负奖励。此外,当车辆停止位置与行人之间的距离小于最小安全距离时,可能有发生碰撞的风险,给予回合负奖励。因此,对奖励函数的设计如下:
式中,α、β、γ、ω、ξ、η、λ与
步骤5、DQN参数设置:
步骤5.1、参数设定:
此步骤中,对DQN模型中所涉及初始参数的取值进一步说明。折扣因子γ,用来表征训练时对未来回报情况的注重程度,取值范围通常为[0,1],值越大则越看重未来,因此,在本发明的训练模型中,γ取0.95。学习率α,用来表示学习速度,取值范围通常为[0,1],取值越大学习速度越快,但容易发生局部收敛现象,取值越小稳定性越好,但学习速度较慢,故在本模型中α取0.95。经验池Buffer size,用来暂时储存状态、动作、奖励和下一时刻的状态等数据,目的是加快收敛,取值范围通常在[10000,100000],本发明中Buffer size取值为25000。探索概率ε决定了DQN探索和利用的平衡,在本发明中最终ε取0.01,经历3000回合从1下降到0.01。
步骤5.2、迭代训练优化:
基于步骤5.1中对初始超参数的设置,对模型进行循环训练,每一个训练回合中,现实网络Q
步骤5.3、网络参数的保存:
通过迭代训练实现算法收敛后,将网络中的参数进行保存,并将优化后的参数加载到神经网络控制器中,以实现在线使用;通过对当前行驶环境下状态的采集,使用该神经网络控制器实时输出控制动作,实现基于驾驶员风格的紧急制动自适应控制。
本发明的有益效果是:基于驾驶员风格的DQN紧急制动自适应控制方法,可以在面对不同驾驶风格类型的驾驶员驾车时满足驾驶员的制动心理预期和制动安全性,减少交通事故发生率;基于驾驶员风格的DQN紧急制动自适应控制方法拥有端到端控制的优势,免去了复杂的传统建模过程;在传统的AEB系统上加入驾驶员风格的输入,能更加保证AEB系统的人性化,为新能源汽车智能制动的发展提供一定的参考。
附图说明
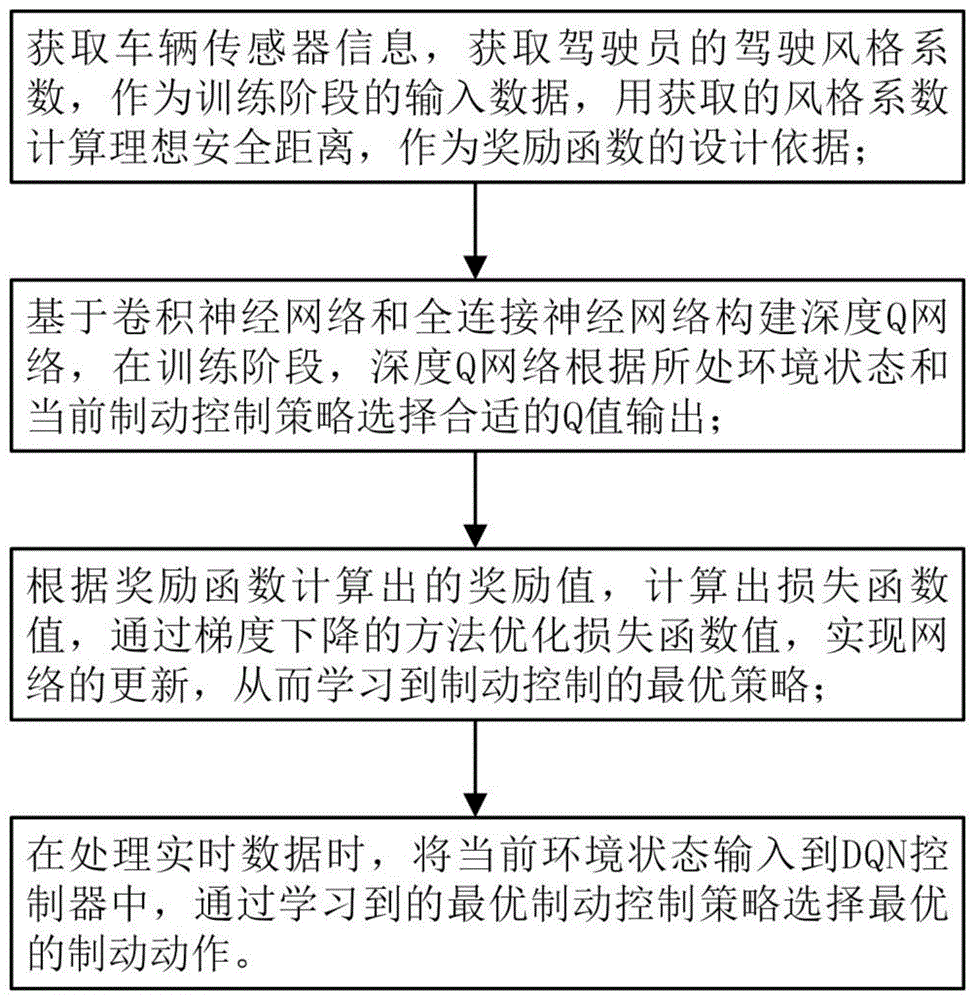
图1是本发明的控制方法流程图。
图2是本发明的强化学习模型示意图。
图3是本发明的应用场景示意图。
图4是本发明的神经网络架构图。
具体实施方式
下面结合附图对本发明进行详细的描述。
本发明提出一种基于驾驶员风格的DQN紧急制动自适应控制方法,将高维语义分割图片信息与驾驶员风格等低维信息相结合作为DQN算法的状态输入,结合多目标奖励函数,使得控制策略在充分保证车辆制动安全性的前提下更加拟人化,提升驾驶员对制动系统的信任度。参照图1的流程,具体包括以下步骤:
步骤1、训练任务设计:
步骤1.1、建立制动控制决策中的马尔可夫模型:
基于深度强化学习的紧急制动过程具备马尔可夫性,即下一时刻的状态只与当前时刻的状态有关,而与之前过往的历史状态无关。基于智能车辆与环境的交互对马尔可夫决策过程进行建立,包括动作、奖励、状态三要素。智能车辆通过传感器系统来感知当前状态环境,通过控制策略实施相关动作,进而进入下一时刻的环境状态并获得相应的奖励。状态S、动作A、状态转移概率P、奖励R和折扣因子γ的合集(S、A、P、R、γ)构成了强化学习马尔可夫过程的五元组。如图2所示,本发明将考虑驾驶员风格的紧急制动控制决策建模为马尔可夫决策过程,通过强化学习的方法学习最优模型参数,提升智能车辆控制策略的适应能力和驾驶员对制动系统的信任度。
步骤1.2、制动控制训练任务设计:
如图3所示,在训练任务中,参考中国新车评价规程(C-NCAP)测试场景,选取了针对行人横穿马路的CVFA-25和CVNA-75场景。所以主车的初速度V
步骤2、考虑驾驶员风格的最小安全距离修正方法设计:
步骤2.1、驾驶员风格系数的获取:
此步骤需要捕捉连续的车辆行驶工况信息,得到每一时刻车辆的速度、加速度和冲击度J,在检测驾驶员风格系数时,考虑到交通工况的随机性,所以检测周期T取为10s,进行处理后得到驾驶员风格系数R
式中,SD
步骤2.2、最小安全距离的修正:
此步骤提出最小安全距离d
步骤3、状态与动作空间设计:
步骤3.1、语义图像的处理:
在Carla仿真软件中,将具有语义分割功能的相机设定到主车正上方的位置,相机所拍到的场景信息具有俯视图特征。进而对照片进行预处理,首先,对图片中不同物体分配不同的像素类别,并对应不同的颜色,由此,处理后的分割图片由不同颜色块组成。除训练任务需要的主要参与对象,场景中的树木和建筑物等次要对象均改为相同的颜色。因此,处理后的分割图片只由路面、车道线、主车、行人和其他所有事物5种颜色组成。
步骤3.2、多维信息的组合:
如图4所示,每一帧图片经过步骤3.1处理后,再经由三层卷积层和一层全连接层所构成的卷积神经网络分别对预处理后的图像进行特征提取,同时,利用其中的全连接层将多维的图像特征铺展为一维矩阵。而后,利用另一层全连接层将前述一维矩阵和步骤2.1所述驾驶员风格系数及传感器所获取的一维信息进行拼接获得新一维信息矩阵并作为DQN算法的状态输入。
步骤3.3、动作空间设计:
动作空间包含车辆的4个制动动作(弱制动、较弱制动、强制动、较强制动),将步骤3.2得到的一维矩阵输入到DQN算法中,经过神经网络的前向传播输出层输出与4个动作相对应的Q值。
步骤4、多目标奖励函数设计:
为保证制动过程中车辆的稳定性与安全性,本发明采用与驾驶风格存在对应关系的最小安全距离作为奖励函数的设计依据。停车范围的阈值通常小于等于最小安全距离,所以本发明中设定修正后的理想安全距离位置与其外延3m之间的范围为理想停车区域。当车辆停车位置处在理想停车区域内时,给予回合正奖励,鼓励车辆停止在理想停车区域。而停车位置在理想停车区域以外时,难以满足不同风格驾驶员对于制动距离与停车后的最小安全距离的心理预期,给予回合负奖励。此外,当车辆停止位置与行人之间的距离小于最小安全距离时,可能有发生碰撞的风险,给予回合负奖励。为引导智能车辆学习到本发明中理想的制动控制策略,设定了奖励函数中各超参数的数值。其中,α=-10,β=-100,γ=130,ω=45,ξ=-15,η=-150,λ=0.5,φ=1。因此,对奖励函数的设计如下:
式中,d为车辆制动停止后车头距行人之间的距离,d
步骤5、DQN参数设置:
步骤5.1、参数设定:
此步骤中,对DQN模型中所涉及初始参数的取值进一步说明。折扣因子γ,用来表征训练时对未来回报情况的注重程度,取值范围通常为[0,1],值越大则越看重未来,因此,在本发明的训练模型中,γ取0.95。学习率α,用来表示学习速度,取值范围通常为[0,1],取值越大学习速度越快,但容易发生局部收敛现象,取值越小稳定性越好,但学习速度较慢,故在本模型中α取0.95。经验池Buffer size,用来暂时储存状态、动作、奖励和下一时刻的状态等数据,目的是加快收敛,取值范围通常在[10000,100000],本发明中Buffer size取值为25000。探索概率ε决定了DQN探索和利用的平衡,在本发明中最终ε取0.01,经历3000回合从1下降到0.01。
步骤5.2、迭代训练优化:
步骤5.2.1、初始化经验回放池,本发明中设定它的容量为25000,初始化现实网络Q
步骤5.2.2、初始化每一训练回合的状态,本发明中状态环境为10km/h至60km/h的车速,前方(TTC·V
步骤5.2.3、训练时循环遍历每个回合,本发明中的回合数为3000回合;
步骤5.2.4、智能车辆在每一步的制动动作由ε-greedy策略来选择,车辆以ε的概率选择随机的制动动作,以1-ε的概率选择能使Q(s,a,ω)取最大值的制动动作;
步骤5.2.5、在智能车辆执行步骤5.2.4中的动作以后,车辆与环境交互进入下一个状态S
步骤5.2.6、将上述信息组成一个样本(S
步骤5.2.7、随机从经验池中抽取一个批次的样本,本发明中每个批次选择256个样本;
步骤5.2.8、如果在一个回合内车辆进入下一状态回合就终止,则Q=r,如果进入下一状态回合还未终止,则Q=r+max Q(s,a,ω);
步骤5.2.9、计算目标网络与现实网络Q值的均方差Loss,并对Loss采用关于ω
步骤5.2.10、每隔一定的步数更新一下目标网络Q
步骤5.2.11、循环训练直到算法收敛。
步骤5.3、网络参数的保存:
通过迭代训练实现算法收敛后,将网络中的参数进行保存,并将优化后的参数加载到神经网络控制器中,以实现在线使用;通过对当前行驶环境下状态的采集,使用该神经网络控制器实时输出控制动作,实现基于驾驶员风格的紧急制动自适应控制。
- 一种基于改进DQN的视频游戏模拟方法
- 一种基于脑电信号的驾驶员紧急制动意图检测方法
- 一种基于驾驶员风格识别的纯电动汽车制动能量回收方法