为多指令调度分支预测器的方法及装置
文献发布时间:2023-06-19 19:16:40
技术领域
本公开涉及计算机技术领域,尤其涉及一种为多指令调度分支预测器的方法及装置。
背景技术
高性能处理器采用流水线技术,随之而来的待解决问题是分支跳转(Branch)指令的周期损失,对于深度流水线结构的处理器,更为明显。因此,成熟、精准的分支预测器(branch predictor),对于提升处理器性能非常关键。目前,主流的分支方向预测器包括Bimode、GShare及TAGE等,它们均是以多位饱和计数器为基础的预测器。
当前技术中的分支预测器一拍并行预测多条指令,由于分支预测器的匹配使用存在一定的规律,导致无法有效地将所有分支预测器充分调用起来,会降低指令处理的效率和速度,导致资源的浪费。
发明内容
本公开旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本公开的一个目的在于提出一种为多指令调度分支预测器的方法。
本公开的第二个目的在于提出一种为多指令调度分支预测器的装置。
本公开的第三个目的在于提出一种电子设备。
本公开的第四个目的在于提出一种非瞬时计算机可读存储介质。
本公开的第五个目的在于提出一种计算机程序产品。
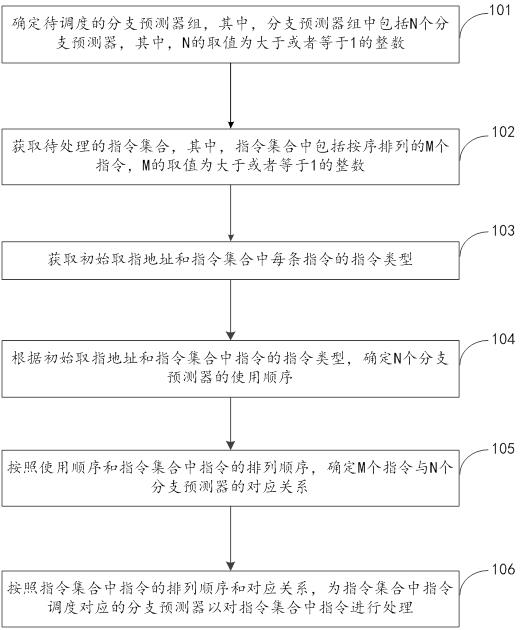
为达上述目的,本公开第一方面实施方式提出了一种为多指令调度分支预测器的方法,包括:确定待调度的分支预测器组,其中,分支预测器组中包括N个分支预测器,其中,N的取值为大于或者等于1的整数;获取待处理的指令集合,其中,指令集合中包括按序排列的M个指令,M的取值为大于或者等于1的整数;获取初始取指地址和指令集合中每条指令的指令类型;根据初始取指地址和指令集合中指令的指令类型,确定N个分支预测器的使用顺序;按照使用顺序和指令集合中指令的排列顺序,确定M个指令与N个分支预测器的对应关系;按照指令集合中指令的排列顺序和对应关系,为指令集合中指令调度对应的分支预测器以对指令集合中指令进行处理。
根据本公开的一个实施方式,根据初始取指地址和指令集合中指令的指令类型,确定N个分支预测器的使用顺序,包括:从N个分支预测器中,根据初始取指地址,确定指令集合中首条指令需要使用的分支预测器,并将首条指令需要使用的分支预测器确定为起始分支预测器;针对指令集合中剩余的第i条指令,根据第i条指令的指令类型,确定第i条指令对应的地址间隔,i为大于1的整数;根据起始分支预测器和第i条指令对应的地址间隔,确定N个分支预测器中剩余的分支预测器的使用顺序。
根据本公开的一个实施方式,根据起始分支预测器和第i条指令对应的地址间隔,确定N个分支预测器中剩余的分支预测器的使用顺序,包括:获取第i-1条指令需要使用的分支预测器;确定第i-1条指令需要使用的分支预测器的预测器序号;对第i-1条指令需要使用的分支预测器的预测器序号和第i条指令对应的地址间隔相加,得到第i条指令需要使用的分支预测器。
根据本公开的一个实施方式,方法还包括:在i的取值为2时,第i条指令为第二条指令,对起始分支预测器的预测器序号和第二条指令对应的地址间隔相加,得到第二条指令需要使用的分支预测器。
根据本公开的一个实施方式,根据第i条指令的指令类型,确定第i条指令对应的地址间隔,包括:响应于第i条指令的指令类型为压缩指令,确定第i条指令对应的地址间隔为第一数值;或者,响应于第i条指令的指令类型为非压缩指令,确定第i条指令对应的地址间隔为第二数值,其中,第一数值与第二数值不同。
根据本公开的一个实施方式,从N个分支预测器中,根据初始取指地址,确定指令集合中首条指令需要使用的分支预测器,包括:根据初始取指地址的高位地址,确定待组合的目标地址数组;对目标地址数组和初始取指地址的偏移地址进行异或处理或者相加处理或者哈希处理,得到起始使用序号;将N个分支预测器中预测器序号与起始使用序号一致的分支预测器,确定为首条指令需要使用的分支预测器。
根据本公开的一个实施方式,根据初始取指地址的高位地址,确定待组合的目标地址数组,包括:确定偏移地址的位数;按照偏移地址的位数,对高位地址进行连续截取,得到目标地址数组;或者,对高位地址进行折叠,直到折叠后高位地址的位数与偏移地址的位数相同,得到目标地址数组。
根据本公开的一个实施方式,对高位地址进行折叠,直到折叠后高位地址的位数与偏移地址的位数相同,得到目标地址数组,包括:从高位地址中选取与偏移地址的位数相同的多个候选地址数组;根据多个候选地址数组中的两个或两个以上的候选地址数组进行异或处理或者相加处理或者哈希处理,得到目标地址数组。
根据本公开的一个实施方式,方法还包括:获取指令集合中每条指令的地址,并提取每条指令的地址中相同部分作为高位地址;获取指令集合中首条指令的地址中的高位地址和剩余的低位地址,并从低位地址中确定偏移地址。
为达上述目的,本公开第二方面实施例提出了一种为多指令调度分支预测器的装置,包括:第一确定模块,用于确定待调度的分支预测器组,其中,分支预测器组中包括N个分支预测器,其中,N的取值为大于或者等于1的整数;第一获取模块,用于获取待处理的指令集合,其中,指令集合中包括按序排列的M个指令,M的取值为大于或者等于1的整数;第二获取模块,用于获取初始取指地址和指令集合中每条指令的指令类型;第二确定模块,用于根据初始取指地址和指令集合中指令的指令类型,确定N个分支预测器的使用顺序;第三确定模块,用于按照使用顺序和指令集合中指令的排列顺序,确定M个指令与N个分支预测器的对应关系;处理模块,用于按照指令集合中指令的排列顺序和对应关系,为指令集合中指令调度对应的分支预测器以对指令集合中指令进行处理。
根据本公开的一个实施方式,第二确定模块,还用于:从N个分支预测器中,根据初始取指地址,确定指令集合中首条指令需要使用的分支预测器,并将首条指令需要使用的分支预测器确定为起始分支预测器;针对指令集合中剩余的第i条指令,根据第i条指令的指令类型,确定第i条指令对应的地址间隔,i为大于1的整数;根据起始分支预测器和第i条指令对应的地址间隔,确定N个分支预测器中剩余的分支预测器的使用顺序。
根据本公开的一个实施方式,第二确定模块,还用于:获取第i-1条指令需要使用的分支预测器;确定第i-1条指令需要使用的分支预测器的预测器序号;对第i-1条指令需要使用的分支预测器的预测器序号和第i条指令对应的地址间隔相加,得到第i条指令需要使用的分支预测器。
根据本公开的一个实施方式,第二确定模块,还用于:在i的取值为2时,第i条指令为第二条指令,对起始分支预测器的预测器序号和第二条指令对应的地址间隔相加,得到第二条指令需要使用的分支预测器。
根据本公开的一个实施方式,第二确定模块,还用于:响应于第i条指令的指令类型为压缩指令,确定第i条指令对应的地址间隔为第一数值;或者,响应于第i条指令的指令类型为非压缩指令,确定第i条指令对应的地址间隔为第二数值,其中,第一数值与第二数值不同。
根据本公开的一个实施方式,第二确定模块,还用于:根据初始取指地址的高位地址,确定待组合的目标地址数组;对目标地址数组和初始取指地址的偏移地址进行异或处理或者相加处理或者哈希处理,得到起始使用序号;将N个分支预测器中预测器序号与起始使用序号一致的分支预测器,确定为首条指令需要使用的分支预测器。
根据本公开的一个实施方式,第二确定模块,还用于:确定偏移地址的位数;按照偏移地址的位数,对高位地址进行连续截取,得到目标地址数组;或者,对高位地址进行折叠,直到折叠后高位地址的位数与偏移地址的位数相同,得到目标地址数组。
根据本公开的一个实施方式,第二确定模块,还用于:从高位地址中选取与偏移地址的位数相同的多个候选地址数组;根据多个候选地址数组中的两个或两个以上的候选地址数组进行异或处理或者相加处理或者哈希处理,得到目标地址数组。
根据本公开的一个实施方式,第二确定模块,还用于:获取指令集合中每条指令的地址,并提取每条指令的地址中相同部分作为高位地址;获取指令集合中首条指令的地址中的高位地址和剩余的低位地址,并从低位地址中确定偏移地址。
为达上述目的,本公开第三方面实施例提出了一种电子设备,包括:至少一个处理器;以及与至少一个处理器通信连接的存储器;其中,存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行,以实现如本公开第一方面实施例的为多指令调度分支预测器的方法。
为达上述目的,本公开第四方面实施例提出了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,计算机指令用于实现如本公开第一方面实施例的为多指令调度分支预测器的方法。
为达上述目的,本公开第五方面实施例提出了一种计算机程序产品,包括计算机程序,计算机程序在被处理器执行时用于实现如本公开第一方面实施例的为多指令调度分支预测器的方法。
通过获取初始取指地址,基于指令集合中的指令类型,来确定每一条指令对应的分支预测器,可以实现对分支预测器的快速分配,同时可以保证选取到每一个分支预测器的概率都是相同的,提升分支预测器的使用率和指令处理的效率。
附图说明
图1是本公开一个实施方式的一种为多指令调度分支预测器的方法的示意图;
图2是本公开一个实施方式的TAGE分支预测器的结构示意图;
图3是本公开一个实施方式的另一种为多指令调度分支预测器的方法的示意图;
图4是一种包含多个TAGE分支预测器的TAGE分支预测器组的结构示意图;
图5是本公开一个实施方式的另一种为多指令调度分支预测器的方法的示意图;
图6是本公开一个实施方式的一种分支预测器的结构示意图;
图7是一种包含多个分支预测器的分支预测器组的结构示意图;
图8是本公开一个实施方式的另一种为多指令调度分支预测器的方法的示意图;
图9是本公开一个实施方式的一种为多指令调度分支预测器的装置的示意图;
图10是本公开一个实施方式的一种电子设备的示意图。
具体实施方式
下面详细描述本公开的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本公开,而不能理解为对本公开的限制。
图1为本公开提出的一种为多指令调度分支预测器的方法的示意图,如图1所示,该为多指令调度分支预测器的方法包括以下步骤:
S101,确定待调度的分支预测器组,其中,分支预测器组中包括N个分支预测器,其中,N的取值为大于或者等于1的整数
需要说明的是,本公开实施例中的分支预测器为支持压缩指令的分支预测部件,该分支预测器可为Bimode、GShare和TAGE等,此处不作任何限定。
以TAGE分支预测器为例,如图2所示,图2为本公开一个实施方式的TAGE分支预测器的结构示意图,共包含五个预测表和一个历史寄存器,分别通过T0、T1、T2、T3、T4、h表示。其中,T0(base predictor,基础预测器)仅通过程序计数器(Program Counter,PC)直接去查找,为基本默认预测表。T1、T2、T3和T4为带有tag的预测表,其中包含三个字段:pred为饱和计数器字段,用于通过最高有效位标识预测方向,如图所示,10表示pred字段;标签tag为地址的部分字段,如图所示,20表示tag字段;U为有效字段,用来管理表(table)的替换策略,如图所示,30表示U字段。在预测时,TI、T2、T3、T4和T0同时被访问,T0提供默认预测。
TAGE预测器占用的存储空间很大,不同的表,tag的长度不同,历史长度越长,tag位宽越大。5个组件的TAGE预测器,T1和T2的tag长度为8位,T3和T4的长度为9位。每个表项1K项数,共54Kbits。 8个组件的TAGE预测器,T1和T2的tag长度为8位,T3和T4的长度为10位,T5和T6的tag长度为11位,T7的长度为12位,每个表项512项,共53.5Kbits。实现中,如果需要并行进行16条指令的预测,需要16倍的存储容量。在TAGE预测器中,当带有tag的表命中时,采用历史长度最长的预测结果作为最终预测结果,当未命中时,会采用默认的预测器。
S102,获取待处理的指令集合,其中,指令集合中包括按序排列的M个指令,M的取值为大于或者等于1的整数。
需要说明的是,本公开实施例中的指令集合为待执行指令的集合,在获取指令集合后,可基于待执行指令的取指地址进行排序。
在本公开实施例中,指令集合中的指令的排列顺序可通过多种方法进行确定,此处不作任何限定,具体可根据实际的设计需要进行设定。
可选地,可根据指令集合中指令的取指地址来确定的,举例来说,使用顺序可为取指地址从小至大,也可为取指地址由大至小。
可选地,所有指令也可为同时执行。
可选地,可根据预设的排列顺序进行执行,该预设的排列顺序可为人工设定的,也可根据一定的规则进行设定,举例来说,根据指令的类型确定排列顺序等。
S103,获取初始取指地址和指令集合中每条指令的指令类型。
取值地址为指令所在内存单元的地址。在本公开实施例中,可通过选取取指地址最小或者最大的取指地址作为初始取指地址。
在本公开实施例中,指令类型包括压缩指令和非压缩指令。为了缩短代码长度,提高指令高速缓存的利用率,指令设计会包含压缩指令(也叫短指令)。例如ARM(AdvancedRISC Machines)公司设计了ARM Thumb指令集(ARM Thumb)和二代指令集(Thumb 2),MIPS(Microprocessorwithout interlocked piped stages)公司先后设计了MIPS16指令集和microMIPS指令集,此外还包括精简指令集第五代(ReducedInstruction Set Computer-Five,RISC-V)和16位压缩指令RV32C等。
举例来说,以RISC-V指令集为例,如果将取指宽度设置为32字节,以标准RVI指令计算,每拍最多取出八条指令。由于RISC-V指令集支持压缩指令,处理器核如果实现了RISC-V压缩指令扩展,指令大小可能为二字节(16位)或四字节(32位),所以每拍实际上能取出最多十六条指令(假如全部是压缩指令)。在这样的取指宽度下,每一次取指遇到一条甚至多条转移指令的概率很大,因此需要支持多条指令的并行预测以避免行内指令的结构相关带来的性能损失。因此分支预测部件采用了全并行预测的设计,对于一次取到的32 字节中的全部16个可能的指令起始位置都进行预测。支持压缩指令的分支预测部件,并行预测全部取指宽度的指令,每条指令的分支预测都对应一整套查找表。由于对压缩指令分支预测的并行支持,会成倍的增加本来就已经占用很多存储资源的分支预测器的表项。由于这些表项都是按指令的地址索引的,在没有压缩指令时,就会造成一半的表空间的浪费。
S104,根据初始取指地址和指令集合中指令的指令类型,确定N个分支预测器的使用顺序。
为了解决空间浪费的问题,在获取到初始取指地址后,可基于初始取指地址确定首条指令对应的分支预测器的序号,然后基于指令集合中其他指令的指令类型,确定N个分支预测器的使用顺序。
需要说明的是,确定N个分支预测器的使用顺序的方法可为多种,举例来说,使用顺序可为分支预测器的序号由大至小,也可为由小至大,此处不作任何限定,具体可根据实际的设计需要进行限定。
可选地,还可基于指令类型确定分支预测器跳转的宽度,举例来说,当前指令对应的分支预测器的序号为X,当指令类型为压缩指令时,分支预测器跳转的宽度为A,当指令类型为非压缩指令时,分支预测器跳转的宽度为B,既如果下一条指令为压缩指令时,则基于当前的分支预测器的序号为X+A,如果下一条指令为非压缩指令时,则基于当前的分支预测器的序号为X+B。
需要说明的是,指令预测的分支预测器的序号大于分支预测器的数量N时,则可基于当前的序号和N确定实际的分支预测器求差值,并将差值作为当前的预测器序号。举例来说,当指令预测的分支预测器的序号为Q时,且Q>N,则将Q-N作为当前的预测器序号。
S105,按照使用顺序和指令集合中指令的排列顺序,确定M个指令与N个分支预测器的对应关系。
在本公开实施例中,在确定N个分支预测器的使用顺序后,可首先确定初始取指地址对应的分支预测器,然后按照指令集合中指令的排列顺序,将分支预测器按照使用顺序确定
S106,按照指令集合中指令的排列顺序和对应关系,为指令集合中指令调度对应的分支预测器以对指令集合中指令进行处理。
在本公开实施例中,首先确定待调度的分支预测器组,其中,分支预测器组中包括N个分支预测器,其中,N的取值为大于或者等于1的整数,然后获取待处理的指令集合,其中,指令集合中包括按序排列的M个指令,M的取值为大于或者等于1的整数,而后获取初始取指地址和指令集合中每条指令的指令类型,再之后根据初始取指地址和指令集合中指令的指令类型,确定N个分支预测器的使用顺序,再之后按照使用顺序和指令集合中指令的排列顺序,确定M个指令与N个分支预测器的对应关系,最后按照指令集合中指令的排列顺序和对应关系,为指令集合中指令调度对应的分支预测器以对指令集合中指令进行处理。由此,通过获取初始取指地址,基于指令集合中的指令类型,来确定每一条指令对应的分支预测器,可以实现对分支预测器的快速分配,同时可以保证选取到每一个分支预测器的概率都是相同的,提升分支预测器的使用率和指令处理的效率。
上述实施例中,根据初始取指地址和指令集合中指令的指令类型,确定N个分支预测器的使用顺序,还可通过图3进一步解释,该方法包括:
S301,从N个分支预测器中,根据初始取指地址,确定指令集合中首条指令需要使用的分支预测器,并将首条指令需要使用的分支预测器确定为起始分支预测器。
需要说明的是,初始取指地址为指令集合中首条指令的取指地址。该首条指令可为首条指令为待执行指令集合中取指地址最小的待执行指令,也可为首条指令为待执行指令集合中取指地址最大的待执行指令,此处不作任何限定。
当前技术中,是将偏移地址作为首条指令对应的起始分支预测器的使用序号,然后根据起始分支预测器对其他的指令对应的分支预测器进行推算。如图4所示,图4是一种包含多个TAGE分支预测器的TAGE分支预测器组的结构示意图,以包含16个TAGE分支预测器的TAGE分支预测器为例,具体的TAGE分支预测器的结构可以参照图2,如全部是压缩指令的情况下,16个TAGE分支预测器会被用满。如没有压缩指令的情况下,非压缩指令的PC是按32位(4字节)对齐的。由于首条指令的取指地址PC的最低PC[1:0]两位总为00,因此偏移地址必定为偶数。例如PC=00000448a0,(二进制0000 0000 0000 0000 00000100 0100 10001010 0000),即偏移地址offset的起始地址PC[4:1]=0000都是偶数,比如0、2、4、……。如果是非压缩指令,下一条指令的地址间隔也都是偶数,这种情况下会导致奇数号的分支预测器没有被使用,而偶数号的分支预测器又因为使用过多,因表项满而发生替换,降低分支预测的准确率。
在本公开实施例中,在获取到初始取指地址后,可基于初始取指地址确定高位地址和偏移地址,然后基于高位地址和偏移地址确定指令集合中首条指令需要使用的分支预测器。
需要说明的是,高位地址是首条指令地址与指令计数器中的其他待执行指令的指令地址相同的部分,偏移地址为首条指令地址中的剩余部分去掉最后一位的地址。举例来说例,如首条指令的取指地址为PC=ffffffff839c5fc8(二进制:1111 1111 1111 111111111111 1111 1111 1000 0011 1001 1100 0101 1111 1100 1000),与其他待执行指令中相同的部分为pc =PC[63:5],即高位地址为:1111 1111 1111 11111111 1111 1111 11111000 0011 1001 1100 0101 1111 110 ,则偏移地址offset=PC[4:1]=0100。
在确定高位地址和偏移地址后,可根据高位地址和偏移地址进行数据处理,并按照预设的规则确定指令集合中首条指令需要使用的分支预测器。
在本公开实施例中预设的规则可为多种,举例来说,可基于高位地址中的某一位或者某几位对偏移地址进行替换、哈希或者相加等操作,以确定指令集合中首条指令需要使用的分支预测器。
S302,针对指令集合中剩余的第i条指令,根据第i条指令的指令类型,确定第i条指令对应的地址间隔,i为大于1的整数。
在本公开实施例中,指令类型包括压缩指令和非压缩指令。为了缩短代码长度,提高指令高速缓存的利用率,指令设计会包含压缩指令(也叫短指令)。需要说明的是,压缩指令的类型可为多种,此处不作任何限定,具体根据实际情况而定。例如ARM设计了ARM Thumb和Thumb2,MIPS先后设计了MIPS16和microMIPS,RISC-V(ReducedInstruction SetComputer-Five,精简指令集第五代)设计了16位压缩指令RV32C等。
在本公开实施例中,响应于第i条指令的指令类型为压缩指令,确定第i条指令对应的地址间隔为第一数值,响应于第i条指令的指令类型为非压缩指令,确定第i条指令对应的地址间隔为第二数值,其中,第一数值与第二数值不同。举例来说,第一数值可为1,第二数值可为2。
S303,根据起始分支预测器和第i条指令对应的地址间隔,确定N个分支预测器中剩余的分支预测器的使用顺序。
在获取到起始分支预测器后,可基于其他指令的压缩类型,来确定跳转的分支预测器的序号,并以此确定N个分支预测器中剩余的分支预测器的使用顺序。举例来说,初始指令取指地址PC=00000448a0(二进制0000 0000 0000 0000 0000 0100 0100 1000 10100000),起始使用序号的生成可通过偏移地址offset即PC[4:1]异或高位地址pc的低位即PC[8:5],既起始使用序号New_Offset=offset XOR(异或)PC[8:5],New_Offset= 0000 XOR0101 = 0101,将分支预测器的起始使用序号散射开,从0变成5,即分支预测器的使用序号变为:New_Offset 、New_Offset+下一条有效指令的地址间隔、New_Offset+下两条有效指令的地址间隔,以此类推。假设全部16条指令都是有效的且都为压缩指令,则按照顺序每条指令的分支预测器的使用序号变为5、6、7、……、15、0、1、2、3、4。如果指令均为非压缩指令,且全部8条指令都是有效的,那么按照顺序每条指令的分支预测器的使用序号为:5、7、9、11、13、15、1、3。
在本公开实施例中,首先从N个分支预测器中,根据初始取指地址,确定指令集合中首条指令需要使用的分支预测器,并将首条指令需要使用的分支预测器确定为起始分支预测器,然后针对指令集合中剩余的第i条指令,根据第i条指令的指令类型,确定第i条指令对应的地址间隔,i为大于1的整数,最后根据起始分支预测器和第i条指令对应的地址间隔,确定N个分支预测器中剩余的分支预测器的使用顺序。通过首条指令的高位地址和偏移地址确定首条指令对应的起始分支预测器,再基于起始分支预测器确定指令计数器中其他指令对应的分支预测器,以此可以保证随机选取到每一个分支预测器,保证分支预测器的使用率,提升处理的效率。
上述实施例中,根据起始分支预测器和第i条指令对应的地址间隔,确定N个分支预测器中剩余的分支预测器的使用顺序,还可通过图5进一步解释,该方法包括:
S501,获取第i-1条指令需要使用的分支预测器。
S502,确定第i-1条指令需要使用的分支预测器的预测器序号。
需要说明的是,不同的分支预测器对应的分支预测器的预测器序号不同,以此,可以实现通过分支预测器的预测器序号将指令进行准确的分配。
S503,对第i-1条指令需要使用的分支预测器的预测器序号和第i条指令对应的地址间隔相加,得到第i条指令需要使用的分支预测器。
在本公开实施例中,在确定第i-1条指令需要使用的分支预测器的预测器序号后,可将第i-1条指令需要使用的分支预测器的预测器序号和第i条指令对应的地址间隔进行相加。
当第i条指令的指令类型为压缩指令时,则将起始分支预测器的预测器序号和第一数值相加,当第i条指令的指令类型为非压缩指令时,则将起始分支预测器的预测器序号和第二数值相加,以确定第i条指令需要使用的分支预测器的序号。
需要说明的是,在i的取值为2时,第i条指令为第二条指令,对起始分支预测器的预测器序号和第二条指令对应的地址间隔相加,得到第二条指令需要使用的分支预测器。
在确定后续指令的分支预测器时,基于指令地址间隔进行迭代的方式,可以准确的确定每一条指令对应的分支预测器。
举例来说,在确定起始使用序号New_Offset=0100,此时分支预测器的预测器序号为4,如果第二条指令是压缩指令,第三条指令是非压缩指令,第四条指令是压缩指令,那么每条指令的分支预测器的预测器序号分别为4、5、7、8。
在本公开实施例中,首先获取第i-1条指令需要使用的分支预测器,然后确定第i-1条指令需要使用的分支预测器的预测器序号,最后对第i-1条指令需要使用的分支预测器的预测器序号和第i条指令对应的地址间隔相加,得到第i条指令需要使用的分支预测器。通过指令的指令类型确定指令对应的地址间隔,在确定起始分支预测器后,通过迭代的方式可以确定后续所有指令集合中的指令对应的起始分支预测器,无需对每个指令的偏移地址进行处理,而只需根据上一指令的分支预测器既可确定当前指令的分支预测器,可以提升处理效率,节省处理成本。
需要说明的是,其他基于预测表的分支预测器,例如Bimode、GShare也都与TAGE分支预测器类似,用分支预测表记录预测信息,如图6所示,图6是本公开一个实施方式的一种分支预测器的结构示意图,分支预测器设有多个分支预测表,而且分支预测表每项都存有tag,通过分支指令的取指地址pc和分支历史寄存器中的数据,当带有tag的表命中时,采用历史长度最长的预测结果作为最终预测结果。
图7是一种包含多个分支预测器的分支预测器组的结构示意图,如图7所示,该分支预测器组包含16个分支预测器的分支预测器组,具体的分支预测器结构可参照图6。如果预测表的分支预测器支持压缩指令集,并行预测多条指令,都需要多个预测器,预测器的起始地址都可以用上述实施例中的方法。例如通过偏移地址offset异或高位地址pc中的指定位,或者将高位地址pc进行折叠变换,并与偏移地址offset进行异或计算等来实现。
上述实施例中,从N个分支预测器中,根据初始取指地址,确定指令集合中首条指令需要使用的分支预测器,还可通过图8进一步解释,该方法包括:
S801,根据初始取指地址的高位地址,确定待组合的目标地址数组。
需要说明的是,待组合的目标地址数组的位数与偏移地址的位数相同,确定目标地址数组的方法可为多种,此处不作任何限定。
可选地,可首先确定偏移地址的位数,对高位地址进行处理,得到与偏移地址的位数相同的数组,作为目标地址数组,该截取位置可为提前设定好的,也可为随机的,此处不作任何限定。举例来说,初始指令取指地址PC=00000448a0,(二进制0000 0000 0000 000000000100 0100 1000 1010 0000),用偏移地址offset即PC[4:1]异或高位地址pc中任意位,如PC[14:11],New_Offset=offset XOR PC[4:1](异或)PC[14:11],则New_Offset=0000 XOR 1001 = 1001,此时分支预测器的其实序号为9,如果指令均为非压缩指令,那么分支预测器的使用序号为: 9、11、13、15、1、3、5、7。
可选地,还可按照偏移地址的位数,对高位地址进行连续截取,得到目标地址数组。
可选地,还可对高位地址进行折叠,直到折叠后高位地址的位数与偏移地址的位数相同,得到目标地址数组。
从高位地址中选取与偏移地址的位数相同的多个候选地址数组,根据多个候选地址数组中的两个或两个以上的候选地址数组进行异或处理或者相加处理或者哈希处理,得到目标地址数组。举例来说,初始指令取指地址PC=00000448a0(二进制0000 0000 00000000 00000100 0100 1000 1010 0000),对高位地址PC[16:5]=0010 0100 0101折叠,即将PC[16:5]分成三组,每组4位,可以将其中两组数字进行相加或异或处理后,再和offset进行相加或异或处理,也可以将三组数字进行相加或异或处理后,得到目标地址数组。
S802,对目标地址数组和初始取指地址的偏移地址进行异或处理或者相加处理或者哈希处理,得到起始使用序号。
以异或处理为例,初始取指地址1111 1111 1111 1111 1111 1111 1111 11111000 0011 1001 1100 01011111 1100 1000,则对应的高位地址为1111 1111 1111 11111111 11111111 1111 1000 0011 1001 1100 0101 1111 110,偏移地址为0100。截取PC[9:6]的地址代码为1111作为目标地址数组,基于目标地址数组1111和偏移地址0100,可进行多种运算,以确定起始使用序号。例如,可对目标地址数组1111和偏移地址0100进行异或,则对应的初始地址标识为1011。
S803,将N个分支预测器中预测器序号与起始使用序号一致的分支预测器,确定为首条指令需要使用的分支预测器。
在确定起始使用序号后,可将N个分支预测器中预测器序号为起始使用序号的分支预测器确定为首条指令需要使用的分支预测器。举例来说,起始使用序号为1011,则可将分支预测器中预测器序号为11的分支预测器,作为首条指令需要使用的分支预测器。
在本公开实施例中,首先根据初始取指地址的高位地址,确定待组合的目标地址数组,然后对目标地址数组和初始取指地址的偏移地址进行异或处理或者相加处理或者哈希处理,得到起始使用序号,最后将N个分支预测器中预测器序号与起始使用序号一致的分支预测器,确定为首条指令需要使用的分支预测器。以此,通过对高位地址和偏移地址进行处理,确定起始使用序号,相较于现有技术中确定初始地址标识的方法,可以防止初始地址标识永远为偶数,以此可以提升分支预测器的使用率。
与上述几种实施例提供的为多指令调度分支预测器的方法相对应,本公开的一个实施例还提供了一种为多指令调度分支预测器的装置,由于本公开实施例提供的为多指令调度分支预测器的装置与上述几种实施例提供的为多指令调度分支预测器的方法相对应,因此上述为多指令调度分支预测器的方法的实施方式也适用于本公开实施例提供的为多指令调度分支预测器的装置,在下述实施例中不再详细描述。
图9为本公开提出的一种为多指令调度分支预测器的装置的示意图,如图 9所示,该为多指令调度分支预测器的装置900,包括:第一确定模块910、第一获取模块920、第二获取模块930、第二确定模块940、第三确定模块950和处理模块960。
其中,第一确定模块910,用于确定待调度的分支预测器组,其中,分支预测器组中包括N个分支预测器,其中,N的取值为大于或者等于1的整数。
第一获取模块920,用于获取待处理的指令集合,其中,指令集合中包括按序排列的M个指令,M的取值为大于或者等于1的整数。
第二获取模块930,用于获取初始取指地址和指令集合中每条指令的指令类型。
第二确定模块940,用于根据初始取指地址和指令集合中指令的指令类型,确定N个分支预测器的使用顺序
第三确定模块950,用于按照使用顺序和指令集合中指令的排列顺序,确定M个指令与N个分支预测器的对应关系。
处理模块960,用于按照指令集合中指令的排列顺序和对应关系,为指令集合中指令调度对应的分支预测器以对指令集合中指令进行处理。
在本公开的一个实施例中,第二确定模块940,还用于:从N个分支预测器中,根据初始取指地址,确定指令集合中首条指令需要使用的分支预测器,并将首条指令需要使用的分支预测器确定为起始分支预测器;针对指令集合中剩余的第i条指令,根据第i条指令的指令类型,确定第i条指令对应的地址间隔,i为大于1的整数;根据起始分支预测器和第i条指令对应的地址间隔,确定N个分支预测器中剩余的分支预测器的使用顺序。
在本公开的一个实施例中,第二确定模块940,还用于:获取第i-1条指令需要使用的分支预测器;确定第i-1条指令需要使用的分支预测器的预测器序号;对第i-1条指令需要使用的分支预测器的预测器序号和第i条指令对应的地址间隔相加,得到第i条指令需要使用的分支预测器。
在本公开的一个实施例中,第二确定模块940,还用于:在i的取值为2时,第i条指令为第二条指令,对起始分支预测器的预测器序号和第二条指令对应的地址间隔相加,得到第二条指令需要使用的分支预测器。
在本公开的一个实施例中,第二确定模块940,还用于:响应于第i条指令的指令类型为压缩指令,确定第i条指令对应的地址间隔为第一数值;或者,响应于第i条指令的指令类型为非压缩指令,确定第i条指令对应的地址间隔为第二数值,其中,第一数值与第二数值不同。
在本公开的一个实施例中,第二确定模块940,还用于:根据初始取指地址的高位地址,确定待组合的目标地址数组;对目标地址数组和初始取指地址的偏移地址进行异或处理或者相加处理或者哈希处理,得到起始使用序号;将N个分支预测器中预测器序号与起始使用序号一致的分支预测器,确定为首条指令需要使用的分支预测器。
在本公开的一个实施例中,第二确定模块940,还用于:确定偏移地址的位数;按照偏移地址的位数,对高位地址进行连续截取,得到目标地址数组;或者,对高位地址进行折叠,直到折叠后高位地址的位数与偏移地址的位数相同,得到目标地址数组。
在本公开的一个实施例中,第二确定模块940,还用于:从高位地址中选取与偏移地址的位数相同的多个候选地址数组;根据多个候选地址数组中的两个或两个以上的候选地址数组进行异或处理或者相加处理或者哈希处理,得到目标地址数组。
在本公开的一个实施例中,第二确定模块940,还用于:获取指令集合中每条指令的地址,并提取每条指令的地址中相同部分作为高位地址;获取指令集合中首条指令的地址中的高位地址和剩余的低位地址,并从低位地址中确定偏移地址。
为了实现上述实施例,本公开实施例还提出一种电子设备1000,图10是本公开一个实施方式的一种电子设备的示意图,如图10所示,该电子设备1000包括:处理器1001和处理器通信连接的存储器1002,存储器1002存储有可被至少一个处理器执行的指令,指令被至少一个处理器1001执行,以实现如本公开图1至图8的实施例的分支预测器匹配方法。
为了实现上述实施例,本公开实施例还提出一种存储有计算机指令的非瞬时计算机可读存储介质,其中,计算机指令用于使计算机实现如本公开图1至图8的实施例的分支预测器匹配方法。
为了实现上述实施例,本公开实施例还提出一种计算机程序产品,包括计算机程序,计算机程序在被处理器执行时实现如本公开图1至图8的实施例的分支预测器匹配方法。
在本公开的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”、“顺时针”、“逆时针”、“轴向”、“径向”、“周向”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本公开和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本公开的限制。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本公开的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本公开的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本公开的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本公开的限制,本领域的普通技术人员在本公开的范围内可以对上述实施例进行变化、修改、替换和变型。
- 用于配网分支线调度场景的调度方法
- 多节点路径选择方法、装置、云平台资源调度方法及装置
- 一种发送调度请求及调度请求失败后的配置方法及装置
- 分支预测器、分支预测方法、装置和计算设备
- 一种轻量级的处理器芯片分支预测器内容隔离方法及电子装置