一种基于自对比学习的嵌套关系抽取算法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明属于人工智能与自然语言处理领域,具体涉及一种基于自对比学习的嵌套关系抽取算法。
背景技术
在自然语言处理中,实体与关系抽取技术根据任务复杂性主要分为三种,由简单到复杂依次分别为:扁平关系抽取(Flat Relation),重叠关系抽取(OverlappingRelation)和嵌套关系抽取(Nested Relation)。
现有关系抽取算法研究工作大多集中在扁平关系抽取与重叠关系抽取,只关注实体之间的关系。但是,在实际应用场景中,以嵌套结构形式呈现的关系信息更加常见,而现有的面向扁平结构的关系抽取算法不能解决嵌套关系抽取的问题。因此,嵌套关系抽取具有广阔的应用场景需求。
相比扁平关系抽取和重叠关系抽取任务只关注实体之间的关系,嵌套关系抽取任务不仅将实体作为关系的组成部分,而且低层的关系三元组也可以被作为高层关系的组成元素。因此,嵌套关系抽取的技术难度更大,相关的现有技术工作也较少,并且现有相关技术方法以完成垂直领域的嵌套关系抽取任务为目标,没有对嵌套关系抽取效果做出深入优化,所以现有嵌套关系抽取技术存在不能准确全面地识别出文本中所有嵌套关系的问题。
发明内容
发明目的:为了解决现有嵌套关系抽取技术方法对高层嵌套关系抽取不够准确与全面的问题,提出一种基于自对比学习的嵌套关系抽取算法,该算法设计实现了一种基于嵌套关系相似度的对比学习方法,联合优化关系抽取任务和自对比学习,增强模型对高层嵌套关系的识别准确性。
技术方案:为实现上述发明目的,本发明一种基于自对比学习的嵌套关系抽取算法,包括以下步骤:
(1)为了解决现有的嵌套关系抽取算法研究工作对于高层嵌套关系识别不够准确与全面的问题,首先提出一种基于自对比学习的嵌套关系抽取算法框架,包括嵌套关系与自对比学习两个步骤。嵌套关系抽取步骤使用预训练语言模型BERT对输入句子进行编码,为上层模型提供底层的语义表示支撑,再利用注意力机制获取实体对应序列片段的语义表示作为各个实体的语义表示,最后引入嵌套关系三元组的类型特征以及三元组中左右元素的位置特征与类型特征,并且使用Transformer迭代地进行关系三元组表示与分类后实现嵌套关系抽取。自对比学习步骤在嵌套关系抽取模型基础上,实现基于嵌套关系结构相似度的自对比学习算法,增强模型对输入句子中嵌套关系的整体编码表示能力。
(2)进一步提出基于自对比学习的嵌套关系抽取算法,包括嵌套关系抽取的迭代、基于Transformer的嵌套关系表示与分类、基于嵌套关系相似度的自对比学习方法、以及联合损失函数构建四个步骤,以此实现一种基于Transformer的嵌套关系表示和分类模型,提升模型对关系三元组的语义表示能力,并通过联合训练嵌套关系抽取任务与自对比学习,提升模型在嵌套关系抽取任务上的准确性。
有益效果:本发明能够有效解决现有嵌套关系抽取的问题与不足。其特点是,针对现有嵌套关系抽取算法对高层嵌套关系识别结果不准确的问题,提出一种基于自对比学习的嵌套关系抽取算法,将嵌套关系的层次化信息引入到对比学习算法中,基于嵌套关系的整体相似度,增强了模型对高层嵌套关系的语义编码能力,提升模型对高层嵌套关系的抽取准确性。
附图说明
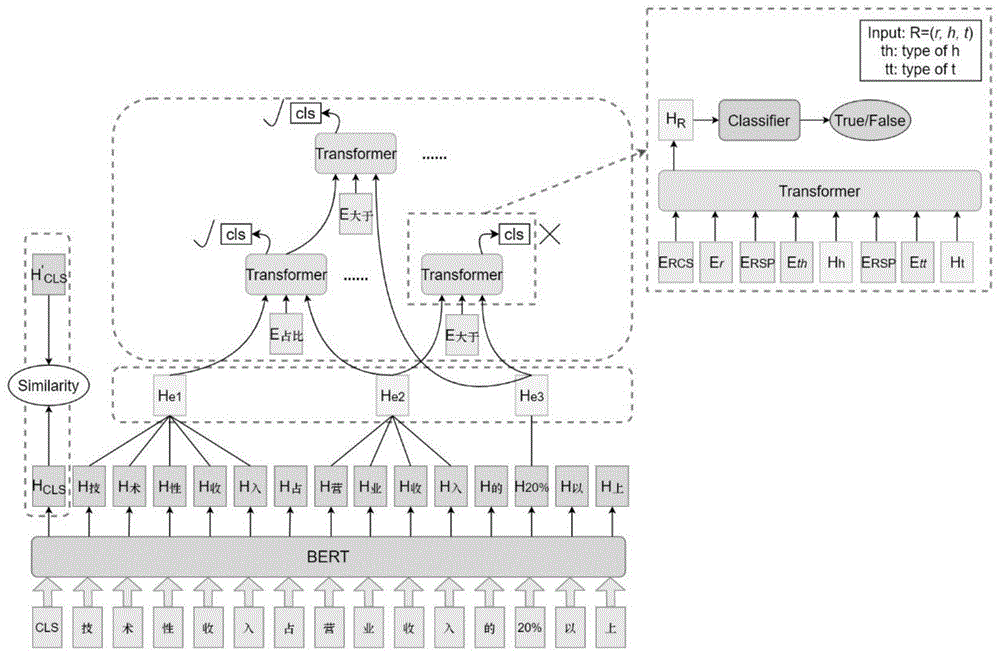
图1基于自对比学习的嵌套关系抽取算法框架
图2基于Transformer的嵌套关系表示与分类模型结构图
图3嵌套关系相似度实例1
图4嵌套关系相似度实例2
具体实施方式
下面结合附图,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
本发明提出了一种基于自对比学习的嵌套关系抽取算法,包括两个步骤:
步骤(1):基于自对比学习的嵌套关系抽取算法框架,包括嵌套关系与自对比学习两个步骤。嵌套关系抽取步骤使用预训练语言模型BERT对输入句子进行编码,为上层模型提供底层的语义表示支撑,再利用注意力机制获取实体对应序列片段的语义表示作为各个实体的语义表示,最后引入嵌套关系三元组的类型特征以及三元组中左右元素的位置特征与类型特征,并且使用Transformer迭代地进行关系三元组表示与分类后实现嵌套关系抽取。自对比学习步骤在嵌套关系抽取模型基础上,实现基于嵌套关系结构相似度的自对比学习算法,增强模型对输入句子中嵌套关系的整体编码表示能力。
步骤(2)基于自对比学习的嵌套关系抽取算法设计实现,包括嵌套关系抽取的迭代、基于Transformer的嵌套关系表示与分类、基于嵌套关系相似度的自对比学习方法、以及联合损失函数构建四个步骤,以此实现一种基于Transformer的嵌套关系表示和分类模型,提升模型对关系三元组的语义表示能力,并通过联合训练嵌套关系抽取任务与自对比学习,提升模型在嵌套关系抽取任务上的准确性。
具体的实施方式说明如下。
步骤(1):基于自对比学习的嵌套关系抽取算法框架实施方案1.算法整体框架设计
本发明提出的基于自对比学习的嵌套关系抽取算法整体框架如图1所示。该算法主要分为两个步骤:嵌套关系抽取与自对比学习,实施步骤如下。
(1)嵌套关系抽取
首先,使用预训练语言模型BERT对输入句子进行编码,为上层模型提供底层的语义表示支撑;然后,利用注意力机制获取实体对应序列片段的语义表示作为各个实体的语义表示;最后,引入嵌套关系三元组的类型特征以及三元组中左右元素的位置特征与类型特征,并且使用Transformer迭代地进行关系三元组表示与分类后实现嵌套关系抽取。
(2)自对比学习模块
在嵌套关系抽取模型基础上,实现基于嵌套关系结构相似度的自对比学习算法,增强模型对输入句子中嵌套关系的整体编码表示能力。
步骤(2):基于自对比学习的嵌套关系抽取算法实施方案
2.基于自对比学习的嵌套关系抽取算法设计
现有嵌套关系抽取算法技术方法较少,并且相关工作大多集中在对于嵌套关系进行语义编码的方面,而对于嵌套关系抽取整体结构信息的工作较少,因此,存在对于具有较高层次的嵌套关系抽取不够准确的问题。
为解决以上现有嵌套关系抽取的问题,本发明提出了一种基于自对比学习的嵌套关系抽取算法,通过挖掘嵌套关系的整体信息,提升算法准确性。
以下对算法中各个步骤的详细设计与实现过程进行介绍,包括嵌套关系抽取算法的迭代过程、基于Transformer的嵌套关系表示与分类算法实现、基于嵌套关系相似度的自对比学习、基于自对比学习的嵌套关系抽取算法的联合训练等步骤。具体实施方案如下。
(1)嵌套关系抽取的迭代过程
嵌套关系抽取的迭代过程可以分为两个步骤:嵌套关系候选三元组的生成与筛选。首先,先根据已有的嵌套关系元素,生成候选三元组;然后,对候选三元组进行筛选,得到正确的嵌套关系三元组;接着,不断迭代进行候选三元组的生成和筛选两个步骤,直到没有新的正确嵌套关系三元组生成。下面介绍这两个步骤的具体实现。
1)嵌套关系候选三元组生成
生成嵌套关系候选三元组时,需要定义嵌套关系类型rt
约束条件(Constraint):对于关系类型rt
其中,
生成嵌套关系候选三元组时,当且仅当两个元素满足关系类型rt
关系类型的左右元素约束条件需要实际嵌套关系抽取任务预先设定,因此,在生成嵌套关系候选三元组过程中,关系类型的约束条件起到先验筛选作用,从而减少嵌套关系抽取算法的搜索空间。
给定所有关系类型的左元素与右元素约束条件后,根据当前已有的嵌套关系元素,可以生成所有可能的候选三元组,具体实现算法如下。
首先,算法1将已有的嵌套关系元素两两组合,形成左元素与右元素对
然后,将每个元素对与每种关系类型的左右元素约束条件进行比对,如果该元素对符合关系类型r
最后,输出所有候选三元组的集合S
2)嵌套关系候选三元组筛选
获得嵌套关系候选三元组的集合S
(2)基于Transformer的嵌套关系表示与分类
在嵌套关系抽取迭代过程中进行嵌套关系候选三元组筛选时,需要使用嵌套关系抽取模型对候选嵌套关系三元组进行表示与分类。本处采用基于Transformer的嵌套关系表示与分类模型。模型结构如图2所示。
对于嵌套关系三元组r
1)关系类型向量
关系类型向量指关系类型对应的嵌入向量,将关系类型r
2)元素类型向量
元素类型向量指元素类型对应的嵌入向量,因为嵌套关系中元素是实体或已有关系三元组,所以元素类型包括实体类型与关系类型。与关系类型向量类似,元素类型向量也是通过嵌入层emb
3)特殊单词向量
特殊单词向量指在输入特征序列中特殊单词对应的嵌入向量。为了区分输入序列中的不同特征,引入两种特殊符号“CLS”与“SEP”,分别用于表示输入序列的起始单词和分隔标记。“CLS”与“SEP”的符号向量通过嵌入层emb
4)元素语义向量
元素语义向量指元素语义对应的隐层向量。元素分为实体与已有关系三元组,所以,元素的语义向量也分为实体语义向量与关系三元组语义向量。
基于Transformer的嵌套关系表示模型的输出嵌套关系三元组的语义表示后,使用二分类模型判断该关系三元组是否正确。如果判断该关系三元组为正确,则将该关系三元组加入最终的输出结果,并且用于生成新的嵌套关系三元组,否则将该关系三元组筛选去除。关系三元组r
其中,W∈R
(3)基于嵌套关系相似度的自对比学习方法
现有对比学习的基本思想是,通过算法自动构造相似实例(正样本)与不相似实例(负样本),使模型着重学习相似实例间的共同特征以及不相似实例之间的不同之处,从而使相似实例之间的语义编码距离越近,不相似实例之间的语义编码距离越远。
本处提出基于嵌套关系相似度的自对比学习方法,采样与对比学习相似的思想,通过嵌套关系相似度来衡量两个句子之间的相似程度。任意句子的嵌套关系与其句子的语义具有一致性。如果两个句子的嵌套关系越相似,则这两个句子的语义也越相似,语义编码之间的距离越近;反之,如果两个句子的嵌套关系越不同,则这两个句子的语义也越不同,语义编码之间的距离越远。
所以,基于嵌套关系相似度的自对比学习方法,使得模型学习嵌套关系与语义编码的一致性,模型使得两个嵌套关系越相似的句子之间对应语义编码表示向量的距离尽可能相近,两个嵌套关系越不相似的句子之间对应语义编码表示向量的距离尽可能远。
基于嵌套关系相似度的自对比学习方法包括两个重要子模块:嵌套关系相似度定义与自对比学习损失函数设计。
1)嵌套关系相似度定义
假设两个输入句子x
其中,S(L
嵌套关系相似度的计算过程总结如下:
首先,公式(3)按照句子中嵌套关系层次,自底向上逐层地计算两个输入句子x
然后将每层类别相同的嵌套关系三元组个数进行累加,得到满足要求的嵌套关系三元组总个数;
最后,计算出满足要求的嵌套关系三元组总个数占两个句子中嵌套关系三元组总数的比例,即为两个句子x
嵌套关系相似度的具体计算实例如图3和图4。
图3中,左边句子为“技术性收入占营业收入的20%以上。”,该句子中第一层嵌套关系三元组是<技术性收入,占比,营业收入>。右边句子为“研究开发费用大于总支出的30%。”,该句子中第一层嵌套关系三元组是<研究开发费用,占比,总支出>,这两个句子中第一层嵌套关系有1个类别相同的关系三元组。
左边句子中第二层嵌套关系三元组是 因此,这两个句子中满足要求的嵌套关系三元组总个数为2,而两个句子都具有2个嵌套关系三元组,最终计算出这两个句子的嵌套关系相似度为1。 图4中,左边句子为“技术性收入占营业收入的20%以上。”,该句子中第一层嵌套关系三元组是<技术性收入,占比,营业收入>。右边句子为“2019年研发费用不少于100万元。”,该句子中第一层嵌套关系三元组是<2019年,@,研发费用>,这两个句子中第一层嵌套关系没有类别相同的关系三元组。 左边句子中第二层嵌套关系三元组是 因此,这两个句子中满足要求的嵌套关系三元组总个数为0,而两个句子都具有2个嵌套关系三元组,最终计算出这两个句子的嵌套关系相似度为0。 2)自对比学习损失函数设计与实现 设两个输入句子为x 其中,s(x 如果两个句子x 自对比学习损失函数的训练目标是使句子的嵌套关系与其句子语义保持一致性。对于长度为N的一个batch训练数据,自对比学习损失函数loss 其中,S 自对比学习损失函数loss (4)联合损失函数构建 假设一个输入句子x 其中, 对于长度为N的一个batch训练数据,嵌套关系抽取任务的损失函数为这个batch中所有句子的候选嵌套关系三元组的分类损失平均值,具体计算公式如下: 其中, 公式(8)首先计算batch中各个句子的候选嵌套关系三元组的分类损失;然后再对各项损失函数进行求和;最后,除以候选嵌套关系三元组的总数,得到一个batch训练数据的嵌套关系抽取损失。 定义嵌套关系抽取任务的损失函数loss Loss=λ·loss 其中,λ表示自对比学习损失函数所占权重,loss 3.算法效果评估 为了验证本算法在嵌套关系抽取任务上的有效性,将嵌套关系抽取模型在数据集Policy上进行了对比实验,分别统计“From Scratch”与“Guided”两种模式下嵌套关系抽取模型的实验结果。 “From Scratch”模式指模型按层次迭代地预测嵌套关系,当前层次预测出的错误关系三元组可能被用于下一层嵌套关系三元组,导致误差传播,模型性能随着层次增加而衰减。 “Guided”模式指在预测下一层的嵌套关系时,使用当前层的正确嵌套关系三元组来代替模型预测结果,避免误差传播。两种模式对比可以测试嵌套关系层次之间预测结果误差传播的影响。 表1NestRESTL对比实验整体结果 表2NestRESTL对比实验各层结果 对比实验结果如表1与表2所示。表1中,模型从第1层开始依次预测出所有嵌套关系三元组后,计算整体评价指标;表2中,LayerL=l表示仅计算第l层中嵌套关系三元组的评价指标,L≥l表示计算层次大于等于l的所有嵌套关系三元组的评价指标。 从表1可以得到以下三点结论: 1)提出的基于自对比学习的嵌套关系抽取算法NestRESTL在“From Scratch”与“Guided”两种模式下整体指标都达到了最优结果,相比SOTA基线模型INN,在“FromScratch”与“Guided”两种模式下F1分别提升了12.79(18.05%)与9.37(11.72%),说明了本算法在嵌套关系抽取任务上的有效性。 2)本算法在不使用自对比学习的情况下,表示为BERT+Transformer,也相比SOTA基线模型在“From Scratch”模式下F1上提升了2.23(2.77%),证明了基于Transformer的嵌套关系表示与分类模型比使用LSTM的准确性更好。同时,使用BERT替换INN的LSTM编码器后得到的变体模型INN 3)在“Guided”模式下各个模型的整体指标都高于“From Scratch”模式,说明了嵌套关系抽取过程中当前层预测结果的误差传播会导致后面层的嵌套关系抽取指标下降,也证明了嵌套关系抽取任务的复杂困难程度比传统的关系抽取任务更高。 从表2可以得到以下两点结论: 1)基于自对比学习的嵌套关系抽取算法NestRESTL在“From Scratch”与“Guided”两种模式下,除了L≥3,其他都实现了F1最高;相比在不使用自对比学习的情况下的模型BERT+Transformer,本算法NestRESTL在“From Scratch”模式下的F1从L=1到L≥3,分别提升了1.15(1.31%)、1.23(1.55%)与0.12(0.20%)。该现象说明了基于自对比学习的嵌套关系抽取算法能够有效提升嵌套关系抽取任务中高层嵌套关系抽取的准确性。 2)当嵌套关系层数L增大时,从L=1到L≥3,模型INN、INN
- 一种光纤复合碳纤维导线缺陷的检测系统及其检测方法
- 一种光纤露点湿度检测装置、系统及其控制方法
- 一种干涉式光纤水听器光路系统及其声波信号检测方法
- 一种低反射能量光纤光栅的检测系统及方法
- 一种基于蓝宝石光纤光栅传感器的温度检测系统及方法
- 一种光纤多元参量检测系统及方法
- 一种光纤多元参量检测系统及方法