基于云计算的数据资源质量评估与优化系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及大数据处理技术领域,特别涉及一种基于云计算的数据资源质量评估与优化系统。
背景技术
数据资源是指可用于分析、处理和应用的各种数据的集合,而《关于构建数据基础制度更好发挥数据要素作用的意见》中提出数据作为新型生产要素,是数字化、网络化、智能化的基础,已快速融入生产、分配、流通、消费和社会服务管理等各环节,深刻改变着生产方式、生活方式和社会治理方式。数据基础制度建设事关国家发展和安全大局,加快构建数据基础制度,充分发挥我国海量数据规模和丰富应用场景优势,激活数据要素潜能,做优、做强、做大数字经济,增强经济发展新动能,构筑国家竞争新优势已经成为大数据技术领域的主要发展方向,数据在该发展方向中扮演着重要角色,同理,数据资源在其中同样扮演着重要的角色。
但是,数据资源数量庞大,其中不乏有异常数据,因此如何对海量的数据资源进行处理,确保处理之后的数据资源的有效性、可用性和价值性在对数据基础制度建设具有重要的意义。为保证数据资源的有效性、可用性和价值性,需要对海量的数据资源进行评估和优化,但是,当前缺少适用于对海量的数据资源进行评估和优化的技术方案,这对于数据基础制度建设非常不利。
因此,如何对数据资源进行合理有效的评估,得到准确的评估结果,根据评估结果对数据资源进行优化,进而得到优化后的数据资源,保证数据资源的质量,提高数据资源的有效性,可用性和价值性,是当前大数据处理技术领域亟待解决的问题之一。
发明内容
本发明旨在至少一定程度上解决上述技术中的技术问题。为此,本发明的目的在于提供一种基于云计算的数据资源质量评估与优化系统,通过对采集的数据资源进行评估,根据评估结果筛选异常数据资源,对异常数据资源进行优化得到优化数据资源,从而实现了对数据资源进行合理有效的评估,得到准确的评估结果,根据评估结果对数据资源进行优化,进而得到优化后的数据资源,保证数据资源的质量,提高数据资源的有效性,可用性和价值性的技术效果。
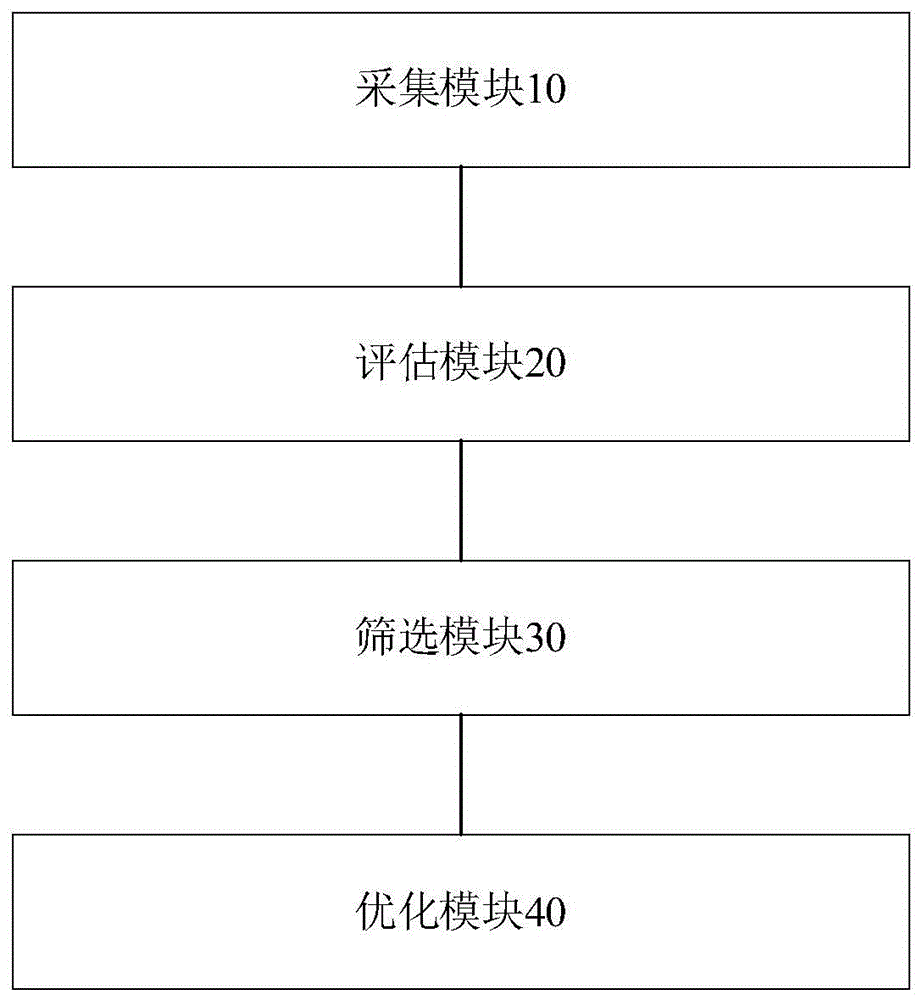
本发明提供一种基于云计算的数据资源质量评估与优化系统,包括:
采集模块,用于采集若干个数据资源;
评估模块,用于对若干个数据资源进行评估,得到资源评估结果;
筛选模块,用于根据资源评估结果,对若干个数据资源进行筛选,确定异常数据资源;
优化模块,用于对异常数据资源进行优化处理,得到优化数据资源。
优选的,基于云计算的数据资源质量评估与优化系统,若干个数据资源中的每个数据资源带有对应的资源信息,资源信息包括资源标签、资源收费方式、资源报价、资源覆盖地域、资源覆盖周期、资源覆盖率、资源更新频率和资源应用场景。
优选的,基于云计算的数据资源质量评估与优化系统,评估模块,包括:
分类子模块,用于根据每个数据资源对应的资源标签对若干个数据资源进行分类,得到若干个分类数据资源集;
指标获取子模块,用于获取每个分类数据资源集对应的评估指标;
结果确定子模块,用于根据每个分类数据资源集对应的评估指标,得到每个分类数据资源集对应的资源评估结果。
优选的,基于云计算的数据资源质量评估与优化系统,分类子模块,包括:
标签获取子模块,用于获取每个数据资源对应的资源标签中表示数据资源所属领域的领域标签;
资源集确定子模块,用于将领域标签相同的数据资源,确定为同一集合的数据资源,将该集合作为一个分类数据资源集,对所有的数据资源进行该操作,确定若干个分类数据资源集。
优选的,基于云计算的数据资源质量评估与优化系统,指标获取子模块,包括:
重复度获取子模块,用于:
选取任一分类数据资源集为待处理数据资源集,获取该待处理数据资源集中的数据资源总数;
从该待处理数据资源集中的第一个数据资源开始,确定当前数据资源为目标数据资源,将该目标数据资源对应的除资源标签之外的所有资源信息,与待处理数据资源集中除目标数据资源以外的所有的数据资源对应的除资源标签之外的资源信息进行信息匹配;
当目标数据资源与任一数据资源的信息匹配结果为完全相同时,确定两个数据资源匹配成功,记录待处理数据资源集中与目标数据资源匹配成功的数据资源个数;
将匹配成功的数据资源个数与数据资源总数的比值作为目标数据资源对应的资源重复度,对待处理数据资源集中的所有数据资源进行以上操作,获取每个数据资源对应的资源重复度;
将所有数据资源对应的资源重复度的平均值作为分类数据资源集的第一评估指标,对所有分类数据资源集进行以上操作,获取每个分类数据集对应的第一评估指标;
空白信息判断子模块,用于:
判断分类数据资源集中的每个数据资源对应的除资源标签之外的所有资源信息中,是否存在空白信息;
如果其中至少存在一个空白信息,将分类数据资源集的第二评估指标设置为第一预设值;否则,将分类数据资源集的第二评估指标设置为第二预设值;
将第一评估指标及第二评估指标作为分类数据资源集对应的评估指标。
优选的,基于云计算的数据资源质量评估与优化系统,结果确定子模块,包括:
第一确定子模块,用于当分类数据资源集的第一评估指标大于预设阈值且分类数据资源集的第二评估指标为第一预设值时,确定该分类数据资源集的评估结果为存在重复数据资源且有数据资源存在资源信息空白;
第二确定子模块,用于当分类数据资源集的第一评估指标大于预设阈值且分类数据资源集的第二评估指标为第二预设值时,确定该分类数据资源集的评估结果为存在重复数据资源但没有数据资源存在资源信息空白;
第三确定子模块,用于当分类数据资源集的第一评估指标等于预设阈值且分类数据资源集的第二评估指标为第一预设值时,确定该分类数据资源集的评估结果为不存在重复数据资源但有数据资源存在资源信息空白;
第四确定子模块,用于当分类数据资源集的第一评估指标等于预设阈值且分类数据资源集的第二评估指标为第二预设值时,确定该分类数据资源集的评估结果为不存在重复数据资源且没有数据资源存在资源信息空白。
优选的,基于云计算的数据资源质量评估与优化系统,筛选模块,包括:
第一筛选子模块,用于当分类数据资源集对应的评估结果为存在重复数据资源且有数据资源存在资源信息空白时,将分类数据资源集中资源重复度不等于预设阈值的数据资源与存在资源信息空白的数据资源筛选为异常数据资源;
第二筛选子模块,用于当分类数据资源集对应的评估结果为存在重复数据资源但没有数据资源存在资源信息空白时,将分类数据资源集中的资源重复度不等于预设阈值的数据资源筛选为异常数据资源;
第三筛选子模块,用于当分类数据资源集对应的评估结果为不存在重复数据资源但有数据资源存在资源信息空白时,将分类数据资源集中存在资源信息空白的数据资源筛选为异常数据资源。
优选的,基于云计算的数据资源质量评估与优化系统,优化模块,包括:
去重子模块,用于对异常数据资源中资源重复度不等于预设阈值的数据资源进行去重操作,得到第一优化数据资源;
填充子模块,用于对异常数据资源中存在资源信息空白的数据资源进行空白信息填充,得到第二优化数据资源。
优选的,基于云计算的数据资源质量评估与优化系统,去重子模块,包括:
第一标记子模块,用于对分类数据资源集的异常数据资源中资源重复度不等于预设阈值的所有数据资源进行第一标记操作,所有进行了第一标记操作的数据资源组成第一标记资源集;
相似度距离确定子模块,用于:
从第一标记资源集中的第一个数据资源开始,将当前数据资源作为待处理数据资源,将待处理数据资源对应的除资源标签之外的所有资源信息输入到GloVe神经网络模型中,得到待处理数据资源对应的目标资源向量;
基于以上方法,获取第一标记资源集中位于待处理数据资源之后的所有数据资源对应的资源向量;
计算目标资源向量与每个数据资源对应的资源向量之间的向量距离,将该向量距离作为待处理数据资源与该数据资源的相似度距离;
哈希差值获取子模块,用于:
将待处理数据资源对应的除资源标签之外的所有资源信息依次输入到预设哈希函数中,得到每个资源信息对应的哈希值,将所有资源信息对应的哈希值相加得到待处理数据资源对应的目标总哈希值;
对第一标记资源集中的所有数据资源进行以上操作,获取每个数据资源对应的总哈希值;
分别计算目标总哈希值与每个数据资源对应的总哈希值的哈希差值;
删除子模块,用于当待处理数据资源与位于其后的任一数据资源的相似度距离小于预设距离阈值且哈希差值小于预设差值阈值时,将位于其后的数据资源删除;对第一标记资源集中的所有数据资源进行以上操作,得到第一优化数据资源。
优选的,基于云计算的数据资源质量评估与优化系统,填充子模块,包括:
第二标记子模块,用于对分类数据资源集的异常数据资源中存在资源信息空白的数据资源进行第二标记操作;
相似资源确定子模块,用于:
选择任一进行了第二标记操作的数据资源作为当前数据资源,获取当前数据资源的每个非空白资源信息对应的目标二进制编码;
将分类数据资源集中未进行第二标记操作的数据资源作为未标记数据资源,基于当前数据资源的每个非空白资源信息,确定每个未标记数据资源的资源信息中与非空白资源信息对应的资源信息的二进制编码;
基于当前数据资源和未标记数据资源,获取每个资源信息对应的最大二进制编码;
将当前数据资源的每个非空白资源信息对应的目标二进制编码与每个未标记数据资源中与非空白资源信息对应的资源信息的二进制编码作差并求绝对值,得到编码差绝对值;
将编码差绝对值与该资源信息对应的最大二进制编码作比值,将预设系数与该比值的差值作为当前数据资源与未标记数据资源的资源相似度;
将相似度大于预设相似度阈值的未标记数据资源确定为与当前数据资源相似的相似数据资源;对所有进行了第二标记操作的数据资源进行以上操作,确定每个进行了第二标记操作的数据资源对应的相似数据资源;
信息填充子模块,用于:
当相似数据资源仅有一个时,获取该相似数据资源中与当前数据资源中的空白资源信息对应的资源信息,基于该资源信息对当前数据资源的空白资源信息进行填充,将完成信息填充的数据资源,作为第二优化资源数据;
当相似数据资源有若干个时,获取若干个相似资源中,与当前数据资源中的空白资源信息对应的若干个资源信息,确定若干个资源信息中出现次数最多的资源信息,基于出现次数最多的资源信息,对当前数据资源的空白资源信息进行填充,将完成信息填充的数据资源,作为第二优化资源数据。
本发明通过提供一种基于云计算的数据资源质量评估与优化系统,包括:采集模块,用于采集若干个数据资源;评估模块,用于对若干个数据资源进行评估,得到资源评估结果;筛选模块,用于根据资源评估结果,对若干个数据资源进行筛选,确定异常数据资源;优化模块,用于对异常数据资源进行优化处理,得到优化数据资源。从而实现了对数据资源进行合理有效的评估,得到准确的评估结果,根据评估结果对数据资源进行优化,进而得到优化后的数据资源,保证数据资源的质量,提高数据资源的有效性,可用性和价值性的技术效果。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在本申请文件中所写的特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例中一种基于云计算的数据资源质量评估与优化系统的框图;
图2为本发明实施例中一种可选的去重子模块的框图;
图3为本发明实施例中一种可选的填充子模块的框图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
参照图1,本发明实施例提供一种基于云计算的数据资源质量评估与优化系统,包括:
采集模块10,用于采集若干个数据资源;
评估模块20,用于对若干个数据资源进行评估,得到资源评估结果;
筛选模块30,用于根据资源评估结果,对若干个数据资源进行筛选,确定异常数据资源;
优化模块40,用于对异常数据资源进行优化处理,得到优化数据资源。
该实施例中,若干个数据资源可以从已有的数据资源供需智能系统中采集。
上述技术方案的技术原理和技术效果是:采集若干个数据资源;对若干个数据资源进行评估,得到资源评估结果;根据资源评估结果,对若干个数据资源进行筛选,确定异常数据资源;对异常数据资源进行优化处理,得到优化数据资源。实现了对数据资源进行合理有效的评估,得到准确的评估结果,根据评估结果对数据资源进行优化,进而得到优化后的数据资源,保证数据资源的质量,提高数据资源的有效性,可用性和价值性的技术效果。
本发明实施例提供基于云计算的数据资源质量评估与优化系统,若干个数据资源中的每个数据资源带有对应的资源信息,资源信息包括资源标签、资源收费方式、资源报价、资源覆盖地域、资源覆盖周期、资源覆盖率、资源更新频率和资源应用场景。
本发明实施例提供基于云计算的数据资源质量评估与优化系统,评估模块,包括:
分类子模块,用于根据每个数据资源对应的资源标签对若干个数据资源进行分类,得到若干个分类数据资源集;
指标获取子模块,用于获取每个分类数据资源集对应的评估指标;
结果确定子模块,用于根据每个分类数据资源集对应的评估指标,得到每个分类数据资源集对应的资源评估结果。
该实施例中,资源标签可以由领域标签(用于说明数据资源属于哪一个领域,例如:属于与空气质量有关的领域,则数据资源的领域标签为空气质量)、类型标签(用于说明数据资源是API接口类、数据工具类还是数据服务类,类型标签包括API接口、数据工具和数据服务三种)和使用标签(用于说明数据资源是否可以试用,使用标签包括可试用和不可试用两种)等多个标签组成。
上述技术方案的技术原理和技术效果是:根据每个数据资源对应的资源标签对若干个数据资源进行分类,得到若干个分类数据资源集;获取每个分类数据资源集对应的评估指标;根据每个分类数据资源集对应的评估指标,得到每个分类数据资源集对应的资源评估结果。实现了基于数据资源的标签对数据资源进行分类得到分类数据资源集,获取分类数据资源集的评估指标,基于评估指标对分类数据资源集进行评估,确保每个分类数据资源集的评估准确性的技术效果。
本发明实施例提供基于云计算的数据资源质量评估与优化系统,分类子模块,包括:
标签获取子模块,用于获取每个数据资源对应的资源标签中表示数据资源所属领域的领域标签;
资源集确定子模块,用于将领域标签相同的数据资源,确定为同一集合的数据资源,将该集合作为一个分类数据资源集,对所有的数据资源进行该操作,确定若干个分类数据资源集。
上述技术方案的技术原理和技术效果是:获取每个数据资源对应的资源标签中表示数据资源所属领域的领域标签;将领域标签相同的数据资源,确定为同一集合的数据资源,将该集合作为一个分类数据资源集,对所有的数据资源进行该操作,确定若干个分类数据资源集。实现了通过领域标签对多个数据资源进行分类,得到多个分类数据资源集,进而提高数据资源处理效率和处理速度的技术效果。
本发明实施例提供基于云计算的数据资源质量评估与优化系统,指标获取子模块,包括:
重复度获取子模块,用于:
选取任一分类数据资源集为待处理数据资源集,获取该待处理数据资源集中的数据资源总数;
从该待处理数据资源集中的第一个数据资源开始,确定当前数据资源为目标数据资源,将该目标数据资源对应的除资源标签之外的所有资源信息,与待处理数据资源集中除目标数据资源以外的所有的数据资源对应的除资源标签之外的资源信息进行信息匹配;
当目标数据资源与任一数据资源的信息匹配结果为完全相同时,确定两个数据资源匹配成功,记录待处理数据资源集中与目标数据资源匹配成功的数据资源个数;
将匹配成功的数据资源个数与数据资源总数的比值作为目标数据资源对应的资源重复度,对待处理数据资源集中的所有数据资源进行以上操作,获取每个数据资源对应的资源重复度;
将所有数据资源对应的资源重复度的平均值作为分类数据资源集的第一评估指标,对所有分类数据资源集进行以上操作,获取每个分类数据集对应的第一评估指标;
空白信息判断子模块,用于:
判断分类数据资源集中的每个数据资源对应的除资源标签之外的所有资源信息中,是否存在空白信息;
如果其中至少存在一个空白信息,将分类数据资源集的第二评估指标设置为第一预设值;否则,将分类数据资源集的第二评估指标设置为第二预设值;
将第一评估指标及第二评估指标作为分类数据资源集对应的评估指标。
该实施例中,确定当前数据资源为目标数据资源,将该目标数据资源对应的除资源标签之外的所有资源信息,与待处理数据资源集中除目标数据资源以外的所有的数据资源对应的除资源标签之外的资源信息进行信息匹配的具体实施方式是:将目标数据资源对应的资源收费方式、资源报价、资源覆盖地域、资源覆盖周期、资源覆盖率、资源更新频率和资源应用场景与待处理数据资源集中除目标数据资源之外的每个数据资源对应的资源收费方式、资源报价、资源覆盖地域、资源覆盖周期、资源覆盖率、资源更新频率和资源应用场景逐一进行信息匹配。
该实施例中,当目标数据资源与任一数据资源的信息匹配结果为完全相同时即为目标数据资源与某一数据资源的资源收费方式、资源报价、资源覆盖地域、资源覆盖周期、资源覆盖率、资源更新频率和资源应用场景全部相同。
该实施例中,确定待处理数据资源集中的数据资源总数为sum,确定待处理数据资源集中与目标数据资源匹配成功的数据资源个数为num,则目标数据资源对应的资源重复度为R
该实施例中,确定任一分类数据集中的数据资源总数为n,该分类数据资源集中的所有数据资源对应的资源重复度为R
该实施例中,判断分类数据资源集中的每个数据资源对应的除资源标签之外的所有资源信息中,是否存在空白信息即为判断数据资源对应的资源收费方式、资源报价、资源覆盖地域、资源覆盖周期、资源覆盖率、资源更新频率和资源应用场景中是否存在信息空白。
该实施例中,判断分类数据资源集中的每个数据资源对应的除资源标签之外的所有资源信息中,是否存在空白信息的具体实施方式可以是:获取历史资源信息及历史资源信息对应的资源信息描述(空白信息或非空白信息),基于历史资源信息及历史资源信息对应的资源信息描述对神经网络模型进行训练,得到信息识别模型,将资源信息依次输入信息识别模型中,得到识别结果,识别结果包括空白信息和非空白信息两种,根据识别结果判断是否存在空白资源信息。
该实施例中,第一预设值为1,第二预设值为0。
上述技术方案的技术原理和技术效果是:获取分类数据资源集中的数据资源总数,将分类数据资源集中的每一个数据资源与该分类数据资源集中的其余数据资源进行信息匹配,获取匹配成功的数据资源个数,根据数据资源总数和匹配成功的数据资源个数确定该数据资源的资源重复度,基于分类数据集中的所有数据资源的资源重复度确定分类数据资源集的第一评估指标;通过判断分类数据资源集中是否有数据资源存在资源信息空白,确定分类数据资源集的第二评估指标。实现了获取分类数据集的多个评估指标,进而确保后续根据评估指标对分类数据资源集进行评估时,得到的评估结果的准确性的技术效果。
本发明实施例提供基于云计算的数据资源质量评估与优化系统,结果确定子模块,包括:
第一确定子模块,用于当分类数据资源集的第一评估指标大于预设阈值且分类数据资源集的第二评估指标为第一预设值时,确定该分类数据资源集的评估结果为存在重复数据资源且有数据资源存在资源信息空白;
第二确定子模块,用于当分类数据资源集的第一评估指标大于预设阈值且分类数据资源集的第二评估指标为第二预设值时,确定该分类数据资源集的评估结果为存在重复数据资源但没有数据资源存在资源信息空白;
第三确定子模块,用于当分类数据资源集的第一评估指标等于预设阈值且分类数据资源集的第二评估指标为第一预设值时,确定该分类数据资源集的评估结果为不存在重复数据资源但有数据资源存在资源信息空白;
第四确定子模块,用于当分类数据资源集的第一评估指标等于预设阈值且分类数据资源集的第二评估指标为第二预设值时,确定该分类数据资源集的评估结果为不存在重复数据资源且没有数据资源存在资源信息空白。
该实施例中,预设阈值为0。
上述技术方案的技术原理和技术效果是:当分类数据资源集的第一评估指标大于预设阈值且分类数据资源集的第二评估指标为第一预设值时,确定该分类数据资源集的评估结果为存在重复数据资源且有数据资源存在资源信息空白;当分类数据资源集的第一评估指标大于预设阈值且分类数据资源集的第二评估指标为第二预设值时,确定该分类数据资源集的评估结果为存在重复数据资源但没有数据资源存在资源信息空白;当分类数据资源集的第一评估指标等于预设阈值且分类数据资源集的第二评估指标为第一预设值时,确定该分类数据资源集的评估结果为不存在重复数据资源但有数据资源存在资源信息空白;当分类数据资源集的第一评估指标等于预设阈值且分类数据资源集的第二评估指标为第二预设值时,确定该分类数据资源集的评估结果为不存在重复数据资源且没有数据资源存在资源信息空白。实现了通过第一评估指标和第二评估指标对分类数据资源集进行评估,根据评估结果确定分类数据资源集存在的问题,保证后续可以针对性地对分类数据资源集进行优化,进而提高数据资源处理的速度和效率的技术效果。
本发明实施例提供基于云计算的数据资源质量评估与优化系统,筛选模块,包括:
第一筛选子模块,用于当分类数据资源集对应的评估结果为存在重复数据资源且有数据资源存在资源信息空白时,将分类数据资源集中资源重复度不等于预设阈值的数据资源与存在资源信息空白的数据资源筛选为异常数据资源;
第二筛选子模块,用于当分类数据资源集对应的评估结果为存在重复数据资源但没有数据资源存在资源信息空白时,将分类数据资源集中的资源重复度不等于预设阈值的数据资源筛选为异常数据资源;
第三筛选子模块,用于当分类数据资源集对应的评估结果为不存在重复数据资源但有数据资源存在资源信息空白时,将分类数据资源集中存在资源信息空白的数据资源筛选为异常数据资源。
该实施例中,将分类数据资源集中存在资源信息空白的数据资源筛选为异常数据资源的具体实施方式可以是:获取历史资源信息及历史资源信息对应的资源信息描述(空白信息或非空白信息),基于历史资源信息及历史资源信息对应的资源信息描述对神经网络模型进行训练,得到信息识别模型,将资源信息依次输入信息识别模型中,得到识别结果,识别结果包括空白信息和非空白信息两种,根据识别结果筛选存在资源信息空白的数据资源。
上述技术方案的技术原理和技术效果是:当分类数据资源集对应的评估结果为存在重复数据资源且有数据资源存在资源信息空白时,将分类数据资源集中资源重复度不等于预设阈值的数据资源与存在资源信息空白的数据资源筛选为异常数据资源;当分类数据资源集对应的评估结果为存在重复数据资源但没有数据资源存在资源信息空白时,将分类数据资源集中的资源重复度不等于预设阈值的数据资源筛选为异常数据资源;当分类数据资源集对应的评估结果为不存在重复数据资源但有数据资源存在资源信息空白时,将分类数据资源集中存在资源信息空白的数据资源筛选为异常数据资源。实现了根据评估结果筛选异常数据资源,确保后续能够针对性地进行数据资源优化,保证数据处理效率性和准确性的技术效果。
本发明实施例提供基于云计算的数据资源质量评估与优化系统,优化模块,包括:
去重子模块,用于对异常数据资源中资源重复度不等于预设阈值的数据资源进行去重操作,得到第一优化数据资源;
填充子模块,用于对异常数据资源中存在资源信息空白的数据资源进行空白信息填充,得到第二优化数据资源。
上述技术方案的技术原理和技术效果是:对异常数据资源中资源重复度不等于预设阈值的数据资源进行去重操作,得到第一优化数据资源;对异常数据资源中存在资源信息空白的数据资源进行空白信息填充,得到第二优化数据资源。实现了根据异常数据资源产生异常的原因,针对性地对异常数据资源进行优化操作,提高数据资源处理效率性和准确性,节省资源的技术效果。
参照图2,本发明实施例提供基于云计算的数据资源质量评估与优化系统,去重子模块,包括:
第一标记子模块4011,用于对分类数据资源集的异常数据资源中资源重复度不等于预设阈值的所有数据资源进行第一标记操作,所有进行了第一标记操作的数据资源组成第一标记资源集;
相似度距离确定子模块4012,用于:
从第一标记资源集中的第一个数据资源开始,将当前数据资源作为待处理数据资源,将待处理数据资源对应的除资源标签之外的所有资源信息输入到GloVe神经网络模型中,得到待处理数据资源对应的目标资源向量;
基于以上方法,获取第一标记资源集中位于待处理数据资源之后的所有数据资源对应的资源向量;
计算目标资源向量与每个数据资源对应的资源向量之间的向量距离,将该向量距离作为待处理数据资源与该数据资源的相似度距离;
哈希差值获取子模块4013,用于:
将待处理数据资源对应的除资源标签之外的所有资源信息依次输入到预设哈希函数中,得到每个资源信息对应的哈希值,将所有资源信息对应的哈希值相加得到待处理数据资源对应的目标总哈希值;
对第一标记资源集中的所有数据资源进行以上操作,获取每个数据资源对应的总哈希值;
分别计算目标总哈希值与每个数据资源对应的总哈希值的哈希差值;
删除子模块4014,用于当待处理数据资源与位于其后的任一数据资源的相似度距离小于预设距离阈值且哈希差值小于预设差值阈值时,将位于其后的数据资源删除;对第一标记资源集中的所有数据资源进行以上操作,得到第一优化数据资源。
该实施例中,对分类数据资源集的异常数据资源中资源重复度不等于预设阈值的所有数据资源进行第一标记操作的具体实施方式可以是:为分类数据资源集的异常数据资源中资源重复度不等于预设阈值的所有数据资源在已有的资源标签之后增加第一标记标签。
该实施例中,计算目标资源向量与每个数据资源对应的资源向量之间的向量距离的具体实施方式可以是:确定目标资源向量为
该实施例中,预设哈希函数可以是基于MD5哈希算法的哈希函数或基于SHA-1哈希算法的哈希函数。
该实施例中,预设距离阈值为目标资源与每个数据资源对应的相似度距离对应的距离均值。
该实施例中,预设差值阈值为目标资源与每个数据资源对应的哈希差值对应的差值均值。
上述技术方案的技术原理和技术效果是:对分类数据集中资源重复度不等于预设阈值的数据资源进行第一标记并组成第一标记资源集;将第一标记资源集中的数据资源对应的除资源标签之外的所有资源信息输入到GloVe神经网络模型中,得到每个数据资源对应的资源向量;将第一标记资源集中的数据资源对应的除资源标签之外的所有资源信息输入到预设哈希函数中,得到对应的总哈希值;根据每个数据资源与第一数据资源集中其余数据资源对应的资源向量之间的向量距离和哈希差值,得到数据资源对应的重复数据资源,将该重复数据资源删除。实现了根据数据资源之间对应的向量距离和哈希差值得到数据资源对应的重复资源,确保了找到的重复资源的正确性,进而保证优化过程和优化结果准确性的技术效果。
参照图3,本发明实施例提供基于云计算的数据资源质量评估与优化系统,填充子模块,包括:
第二标记子模块4021,用于对分类数据资源集的异常数据资源中存在资源信息空白的数据资源进行第二标记操作;
相似资源确定子模块4022,用于:
选择任一进行了第二标记操作的数据资源作为当前数据资源,获取当前数据资源的每个非空白资源信息对应的目标二进制编码;
将分类数据资源集中未进行第二标记操作的数据资源作为未标记数据资源,基于当前数据资源的每个非空白资源信息,确定每个未标记数据资源的资源信息中与非空白资源信息对应的资源信息的二进制编码;
基于当前数据资源和未标记数据资源,获取每个资源信息对应的最大二进制编码;
将当前数据资源的每个非空白资源信息对应的目标二进制编码与每个未标记数据资源中与非空白资源信息对应的资源信息的二进制编码作差并求绝对值,得到编码差绝对值;
将编码差绝对值与该资源信息对应的最大二进制编码作比值,将预设系数与该比值的差值作为当前数据资源与未标记数据资源的资源相似度;
将相似度大于预设相似度阈值的未标记数据资源确定为与当前数据资源相似的相似数据资源;对所有进行了第二标记操作的数据资源进行以上操作,确定每个进行了第二标记操作的数据资源对应的相似数据资源;
信息填充子模块4023,用于:
当相似数据资源仅有一个时,获取该相似数据资源中与当前数据资源中的空白资源信息对应的资源信息,基于该资源信息对当前数据资源的空白资源信息进行填充,将完成信息填充的数据资源,作为第二优化资源数据;
当相似数据资源有若干个时,获取若干个相似资源中,与当前数据资源中的空白资源信息对应的若干个资源信息,确定若干个资源信息中出现次数最多的资源信息,基于出现次数最多的资源信息,对当前数据资源的空白资源信息进行填充,将完成信息填充的数据资源,作为第二优化资源数据。
该实施例中,对分类数据资源集的异常数据资源中存在资源信息空白的数据资源进行第二标记操作的具体实施方式可以是:为分类数据资源集的异常数据资源中资源重复度不等于预设阈值的所有数据资源在已有的资源标签之后增加第二标记标签。
该实施例中,二进制编码可以通过已有的二进制转换代码实现,二进制转换代码可以在CSDN等技术网站中得到。
该实施例中,基于当前数据资源的每个非空白资源信息,确定每个未标记数据资源的资源信息中与非空白资源信息对应的资源信息的二进制编码的具体实施方式可以是:如果当前数据资源的非空白资源信息为资源信息包括资源收费方式、资源报价和资源覆盖地域,则确定每个未标记数据资源的资源信息中资源收费方式、资源报价和资源覆盖地域对应的二进制编码。
该实施例中,基于当前数据资源和未标记数据资源,获取每个资源信息对应的最大二进制编码的具体实施方式可以是:如果资源信息中,拥有二进制编码的只有资源收费方式、资源报价和资源覆盖地域三个,则将当前数据资源和未标记数据资源对应的若干个资源收费方式二进制编码进行比较,确定资源收费方式最大二进制编码;将当前数据资源和未标记数据资源对应的若干个资源报价二进制编码进行比较,确定资源报价最大二进制编码;将当前数据资源和未标记数据资源对应的若干个资源覆盖地域二进制编码进行比较,确定资源覆盖地域最大二进制编码。
该实施例中,预设系数可以是1。
该实施例中,预设相似度阈值可以是当前数据资源与每个未标记数据资源的资源相似度对应的相似度平均值。
该实施例中,当相似数据资源仅有一个时,获取该相似数据资源中与当前数据资源中的空白资源信息对应的资源信息,基于该资源信息对当前数据资源的空白资源信息进行填充的具体实施方式可以是:如果当前数据资源A仅有一个相似数据资源B,A中的空白资源信息为资源覆盖地域,则将A中的资源覆盖地域用B中的资源覆盖地域填充。
该实施例中,当相似数据资源有若干个时,获取若干个相似资源中,与当前数据资源中的空白资源信息对应的若干个资源信息,确定若干个资源信息中出现次数最多的资源信息,基于出现次数最多的资源信息,对当前数据资源的空白资源信息进行填充的具体实施方式可以是:如果当前数据资源A有3个相似数据资源B、C和D,A中的空白资源信息为资源覆盖地域,B中的资源覆盖地域信息为Z,C中的资源覆盖地域信息为Z,D中的资源覆盖地域信息为Y,Z出现了两次,则将A中的资源覆盖地域填充为Z。需要说明的是,如果若干个相似资源中的资源覆盖地域信息均不同时,选择任一相似资源中的对应地域覆盖信息进行填充。
上述技术方案的技术原理和技术效果是:对分类数据集中存在资源信息空白的数据资源进行第二标记,选择任一进行了第二标记操作的数据资源作为当前数据资源,获取当前数据资源的每个非空白资源信息对应的目标二进制编码;将分类数据资源集中未进行第二标记操作的数据资源作为未标记数据资源,基于当前数据资源的每个非空白资源信息,确定每个未标记数据资源的资源信息中与非空白资源信息对应的资源信息的二进制编码;基于当前数据资源和未标记数据资源,获取每个资源信息对应的最大二进制编码;将当前数据资源的每个非空白资源信息对应的目标二进制编码与每个未标记数据资源中与非空白资源信息对应的资源信息的二进制编码作差并求绝对值,得到编码差绝对值;将编码差绝对值与该资源信息对应的最大二进制编码作比值,将预设系数与该比值的差值作为当前数据资源与未标记数据资源的资源相似度;基于相似度确定当前数据资源相似的相似数据资源;根据相似资源的数量对当前数据资源中的空白资源信息进行填充。实现了根据相似度距离确定相似数据资源,根据相似数据资源进行空白资源填充,确保填充信息准确性和合理性的技术效果。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 一种基于多模态数据的网络学习资源质量评估方法及系统
- 一种基于大数据挖掘的互联网资源质量评估方法及系统