一种基于优化的YOLOv5模型的车辆分类检测方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及目标识别技术领域,特别涉及一种基于优化的YOLOv5模型的车辆分类检测方法。
背景技术
近年来,随着经济的高速发展,全国汽车保有量飞速增长,与此同时对汽车信息统计和管理的费用也在逐年提升。随着计算机技术的火热发展与社会重视智能化的发展,图像识别与目标检测等技术近年来也发展迅速,不仅为人们的生活带来了便捷,也对社会的管理提供了一种新的选择,并进一步促进了自动驾驶技术甚至无人驾驶在未来广泛普及成为可能。
以往的车辆目标检测通常包含目标分割、候选区域生成、特征提取、分类器分类等步骤,但这类算法也在实际应用中显示出他疲软的一面,例如在复杂多变的实际场景中此类算法的准确度会发生明显的下降,并且人工设计的特征泛化能力较差。近年来,深度学习在目标检测和识别领域表现突出,Girshick等提出了R-CNN模型,将卷积神经网络应用到目标检测领域,随后改进的Fast R-CNN、Faster R-CNN模型不断提高检测精度。YOLO模型实现了端到端的实时目标检测,但也有一些仍待提高的方面。例如在识别小物体及重叠部分较多的目标进行检测时准确率较差。2020年6月,YOLOv5模型被提了出来,该算法使用CSPDarknet作为主干网络Backbone从输入图像中提取大量的信息特征,克服了主干网络优化的梯度信息重复现象。此外,YOLOv5模型中用到的两个优化函数Adam和SGD,两者都预设了与之对应的训练超参数,可训练较小的自定义数据集。总的来说,YOLOv5模型在之前的YOLO系列算法上有了大幅提升。但面对当前更为复杂的交通环境,如车辆图像偏小、车辆遮挡重叠、无法满足对车辆的检测速度和精度要求。
发明内容
本发明的目的在于提供一种基于优化的YOLOv5模型的车辆分类检测方法,以实现提高对车辆的检测的精度和速度的目的。
为了实现以上目的,本发明通过以下技术方案实现:
一种基于优化的YOLOv5模型的车辆分类检测方法,包括:
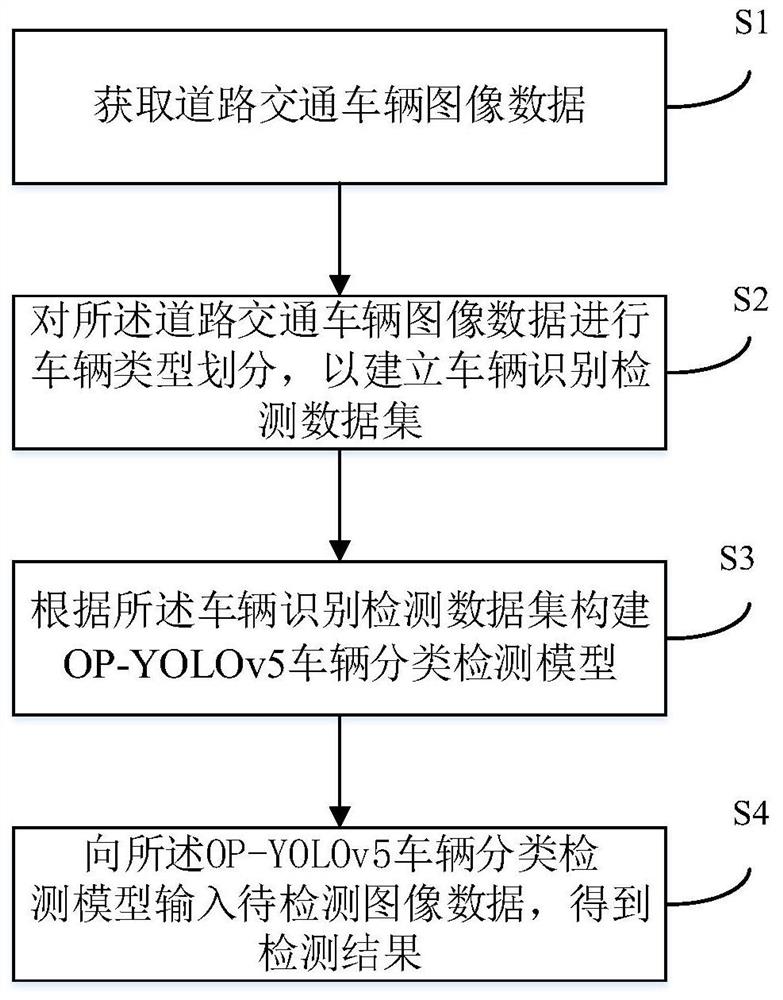
步骤S1、获取道路交通车辆图像数据;
步骤S2、对所述道路交通车辆图像数据进行车辆类型划分,以建立车辆识别检测数据集;
步骤S3、根据所述车辆识别检测数据集构建OP-YOLOv5车辆分类检测模型;
步骤S4、向所述OP-YOLOv5车辆分类检测模型输入待检测图像数据,得到检测结果。
优选地,所述步骤S1包括:利用监控摄像采集不同的待检测的道路上以及不同时段的道路交通车辆视频数据,对所述道路交通车辆视频数据以预设间隔的视频帧进行视频帧提取,得到所述道路交通车辆图像数据。
优选地,所述步骤S2包括:将所述道路交通车辆图像数据划分为五大类型,包括大货车类、大客车类、轿车类、自行车类和摩托车类;
对所述道路交通车辆图像数据中的每一图像中的车辆进行标注,并将所述图像信息转换成416×416分辨率的车辆图像信息;
将每一所述车辆图像信息生成相对应的xml文件,所述xml文件包含图片名称、图片路径、目标标签名称及目标位置坐标;
将每一所述xml文件在Python中进行图像格式转化,转换成YOLO模型支持的txt文件,得到所述车辆识别检测数据集;
将所述道路交通车辆图像数据及所述车辆识别检测数据集按照VOC数据文件结构进行存储。
优选地,所述OP-YOLOv5车辆分类检测模型包括:
依次连接的输入端、骨干网络、头部模块和输出端;
将所述待检测图像数据通过所述输入端输入至所述骨干网络,
所述骨干网络用于对所述待检测图像数据提取具有不同尺寸的特征图;
所述头部模块用于进行目标框选及目标检测得到检测结果;
所述输出端用于将所述检测结果输出。
优选地,所述测试集图像数据集中每一所述输入图像都经过如下处理:
所述输入图像通过所述输入端输入至所述骨干网络内,
所述骨干网络用于对接收到的所述输入图像均进行如下处理:
所述输入图像依次经过了Focus操作、Conv卷积操作、BCSP
所述输入图像的第一特征图依次经过Conv卷积操作和BCSP
所述输入图像的第二特征图依次经过Conv卷积操作、SPP空间金字塔池化操作和BCSP
在所述头部模块中,
所述输入图像的第三特征图依次经过Conv卷积操作和上采样操作输出所述输入图像的第四特征图;
所述输入图像的第二特征图和所述输入图像的第四特征图进行Concat拼接操作后,依次经过BCSP
所述输入图像的第一特征图和所述输入图像的第五特征图进行Concat拼接操作后,得到所述输入图像的第六特征图;
所述输入图像的第六特征图经加入的SE注意力模块和BCSP
所述输入图像的第七特征图经过深度可分离卷积处理后与经过Conv卷积操作的所述输入图像的第四特征图进行Concat拼接操作后,输出所述输入图像的第八特征图;
所述输入图像的第八特征图依次经过加入的SE注意力模块和BCSP
所述输入图像的第九特征图经过替换后的深度可分离卷积处理后与经过Conv卷积操作的所述输入图像的第三特征图进行Concat拼接操作后,得到所述输入图像的第十特征图;
所述输入图像的第十特征图依次经过加入的SE注意力模块和BCSP
所述输出端对所述输入图像的第十一特征图进行目标Bounding box的损失函数计算,采用DIoU方式进行非极大值抑制操作,输出大小为20×20、40×40、80×60特征图,且该特征图的深度为255,由此得到所述检测结果。
另一方面,本发明还提供一种电子设备,包括处理器和存储器,所述存储器上存储有计算机程序,所述计算机程序被所述处理器执行时,实现如上文所述的方法。
另一方面,本发明还提供一种可读存储介质,所述可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时,实现如上文所述的方法。
本发明至少具有以下优点之一:
本发明所提供的一种基于优化的YOLOv5模型的车辆分类检测方法,包括:获取道路交通车辆图像数据;对所述道路交通车辆图像数据进行车辆类型划分,以建立车辆识别检测数据集;根据所述车辆识别检测数据集构建OP-YOLOv5车辆分类检测模型;向所述OP-YOLOv5车辆分类检测模型输入待检测图像数据,得到检测结果。通过设有的所述OP-YOLOv5车辆分类检测模型由此提高了对车辆的检测的精度和速度。
使用K-Means算法对数据集中所述已标注目标检测框的宽高进行重新聚类从而获得适用于道路视频监控中车辆检测数据集的Anchor尺寸,提高检测精度。
通过在Head部分加入了SE注意力模块,将部分普通卷积替换成了深度可分离卷积,可适应目标车辆较少且目标图像较小的情形,并且使检测速度进一步提升。
在输出端以DIoU的方式替换原IoU方式,将边界框列表及其对应的置信度得分列表并设定阈值,剔除重复的候选边界框,再进行DIoU计算,对于一些遮挡重叠的车辆目标可以提高辨识准确率。
附图说明
图1为本发明一实施例提供的一种基于优化的YOLOv5模型的车辆分类检测方法的流程示意图;
图2为本发明一实施例提供的原始的YOLOv5模型的结构框图;
图3为本发明一实施例提供的基于图2所示的原始的YOLOv5模型进行优化的OP-YOLOv5车辆分类检测模型的结构框图;
图4为本发明一实施例提供的原始的YOLOv5模型的各指标与迭代次数关系示意图;
图5为本发明一实施例提供的优化的OP-YOLOv5车辆分类检测模型的各指标与迭代次数关系示意图。
具体实施方式
以下结合附图和具体实施方式对本发明提出的一种基于优化的YOLOv5模型的车辆分类检测方法作进一步详细说明。根据下面说明,本发明的优点和特征将更清楚。需要说明的是,附图采用非常简化的形式且均使用非精准的比例,仅用以方便、明晰地辅助说明本发明实施方式的目的。为了使本发明的目的、特征和优点能够更加明显易懂,请参阅附图。须知,本说明书所附图式所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技术的人士了解与阅读,并非用以限定本发明实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本发明所能产生的功效及所能达成的目的下,均应仍落在本发明所揭示的技术内容能涵盖的范围内。
如图1所示,本实施例提供的一种基于优化的YOLOv5模型的车辆分类检测方法,包括:
步骤S1、获取道路交通车辆图像数据。
步骤S2、对所述道路交通车辆图像数据进行车辆类型划分,以建立车辆识别检测数据集。
步骤S3、根据所述车辆识别检测数据集构建OP-YOLOv5车辆分类检测模型。
步骤S4、向所述OP-YOLOv5车辆分类检测模型输入待检测图像数据,得到检测结果。
具体的,所述步骤S4包括:所述的OP-YOLOv5车辆分类检测模型进行图像或视频流的输入,设置参数批量为32,动量为0.937,权重衰减配置为0.0005,总迭代次数为200次,初始学习率lr=0.01。经过训练得到车辆检测分类结果。
所述步骤S1包括:利用监控摄像采集不同的待检测的道路上以及不同时段的道路交通车辆视频数据,对所述道路交通车辆视频数据以预设间隔的视频帧进行视频帧提取,得到所述道路交通车辆图像数据。
具体的,通过人工截取出不同时段、不同道路的视频帧,为了尽量避免采集到的样本中含有过多过于相似的正样本,所述对采集到的视频至少每隔10帧图像取出一帧。
在一些其他的实施例中,所述道路交通车辆图像数据为利用监控摄像采集所需检测的道路上的交通车辆图片。
所述步骤S2包括:将所述道路交通车辆图像数据划分为五大类型,包括大货车类、大客车类、轿车类、自行车类和摩托车类,建立车辆识别检测数据集。
对所述道路交通车辆图像数据中的每一图像中的车辆进行标注,并对经标注的每一所述图像中的车辆进行特征提取,得到图像信息,并将所述图像信息转换成416×416分辨率的车辆图像信息。在本实施例中,标注格式参照VOC2007数据集。
将每一所述车辆图像信息生成相对应的xml文件,所述xml文件包含图片名称、图片路径、目标标签名称及目标位置坐标;
将每一所述xml文件在Python中进行图像格式转化,转换成YOLO模型支持的txt文件,得到所述车辆识别检测数据集。
将所述建立好的车辆识别检测数据集按照VOC数据文件结构进行存储,以供训练车辆检测模型使用。
具体的,所述步骤S2所述车辆识别检测数据集的建立过程如下:
S21:车辆识别检测数据集制作首先通过截取不同路段和时段的车载记录仪的视频,由此选出包含21000张有清晰样本的道路交通车辆图像数据,之后要对所述道路交通车辆图像数据中的每一图像中的车辆进行标注,标注格式参照VOC2007;在之后,要进行车辆类型划分,将其划分为五大类型,包括大货车(Car)、大客车(Bus)、轿车(Truck)、自行车(Bicycle)、摩托车(Motorcycle);再之后,并将其分成三部分:16800张图像作为训练集,2100张图像作为验证集,2100张图像作为测试集,由此得到车辆识别检测数据集具体参见表1。
表1车型(车辆)识别检测数据集
如图2和图3所示,所述步骤S3包括利用所述车辆识别检测数据集初步搭建YOLOv5算法模型,并对所述YOLOv5算法模型进行优化,形成OP-YOLOv5车辆分类检测模型。所述待检测图像数据可以为上述的测试集。
请继续参考图3所示,所述OP-YOLOv5算法模型结构包括以下部分:
输入端:经所述输入端输入的测试集图像数据集中每一所述输入图像的大小为640×640,通道为3;并对每一所述输入图像进行马赛克(Mosaic)数据增强、自适应图片缩放以及自适应锚框计算处理后输入给骨干网络(Backbone)。
骨干网络:每一所述输入图像均经过如下处理,例如:所述输入图像依次经过了Focus操作、Conv卷积操作、BCSP
所述输入图像的第一特征图依次经过Conv卷积操作和BCSP
所述输入图像的第二特征图依次经过Conv卷积操作、SPP空间金字塔池化操作和BCSP
所述输入图像的第三特征图依次经过Conv卷积操作和上采样(UpSamping)操作输出所述输入图像的第四特征图。
所述输入图像的第二特征图和所述输入图像的第四特征图进行Concat拼接操作后,依次经过BCSP
所述输入图像的第一特征图和所述输入图像的第五特征图进行Concat拼接操作后,得到所述输入图像的第六特征图。
所述输入图像的第六特征图经加入的SE注意力模块(SElayer)和BCSP
所述输入图像的第七特征图经过深度可分离卷积处理(DWConv)后与经过Conv卷积操作的所述输入图像的第四特征图进行Concat拼接操作后,输出所述输入图像的第八特征图。
所述输入图像的第八特征图依次经过加入的SE注意力模块和BCSP
所述输入图像的第九特征图经过深度可分离卷积处理(DWConv)后与经过Conv卷积操作的所述输入图像的第三特征图进行Concat拼接操作后,得到所述输入图像的第十特征图。
所述输入图像的第十特征图依次经过加入的SE注意力模块和BCSP
输出端:对所述输入图像的第十一特征图进行目标Bounding box的损失函数计算,将原有IoU方式改为DIoU方式进行非极大值抑制操作,输出大小为20×20、40×40、80×60特征图,且该特征图的深度为255。
YOLOv5模型采用GIOU_loss作为Bounding box的损失函数,并采用加权nms的方式。
此外,OP-YOLOv5车辆分类检测模型中的Conv卷积操作含义为步长为2的卷积操作+BN(Batch Normalization)操作+HardSwish(激活函数)操作;其中,BN操作为批量归一化的运算;+HardSwish操作具体采用Leaky ReLU为激活函数运算。
OP-YOLOv5车辆分类检测模型中的第一BCSP
其中,BCSP
由此OP-YOLOv5车辆分类检测模型中的BCSP
OP-YOLOv5车辆分类检测模型中的Focus操作含义是通过slice操作来对输入图片进行分片,之后进行Concat拼接操作以及一次Conv卷积操作,具有下采样的效果,减少浮点运算量从而加快运算速度。
对于OP-YOLOv5车辆分类检测模型中的SPP空间金字塔池化操作的含义为:首先进行一次Conv卷积操作,之后进行最大池化操作,分别采用5×5、9×9、13×13的池化核大小,包括一条直连线路,再进行Concat拼接操作从而提高感受野,最后进行Conv卷积操作并输出。该部分总共经过5次下采样,即32倍的下采样,主要作用为提取原始图片的不同尺寸的特征图,用以后续的检测。
由此可知,本实施例提供的OP-YOLOv5车辆分类检测模型中的头部(Head)模块部分:包括Conv操作,上采样操作,BSP
由此可知,本实施例提供的OP-YOLOv5车辆分类检测模型相比于图2中的YOLOv5模型做了如下优化:
目标先验框Anchor Boxes的改进:使用K-Means算法对数据集中所述已标注目标检测框的宽高进行重新聚类从而获得适用于不同大小车辆检测数据集的Anchor尺寸。
聚类方法中的距离公式见下式:
d(box,centroid)=1-IoU(box,centroid)d(box,centroid)=1-IoU(box,centroid) (1)
式中,d表示聚类距离度量参数;box表示标注的边框坐标;centroid表示簇的中心;IoU表示簇的中心框和聚类框的交并比;
选取合适的先验框k值可以使得在尽可能高IoU的情况下,模型复杂度也较低,取得一个较好的平衡。
经过试验,得到了OP-YOLOv5车辆分类检测模型适用的九组适用于本数据集的Anchor,大小分别为:[32,28,70,59,127,119],[252,227,585,275,596,392],[454,577,587,477,573,580]。
Head部分的改进:
加入了SE注意力模块,能够忽略无关信息而将注意力放在重点关注信息上。在车辆检测过程中,可以将检测视野集中于所需检测的目标车辆上,这样可以大大减少了背景建筑物的干扰。
将部分普通卷积操作替换成了深度可分离卷积操作,将一个完整的卷积运算划分为两个过程完成,分别为逐深度卷积与逐点卷积。逐深度卷积是将单个滤波器应用到每一个输入通道,之后逐点卷积应用1×1卷积以组合形式输出深度卷积,得到最终的输出。
进行深度可分离卷积后与普通卷积的计算量之比为
所述改进可适应少量目标车辆且图像较小的情形,并且使检测速度进一步提升。
输出端:在输出端以DIoU的方式替换原IoU方式进行非极大值抑制,将边界框列表及其对应的置信度得分列表并设定阈值,剔除重复的候选边界框,再进行DIoU计算,其原理公式如下式:
其中,S
DIoU在IoU基础上引入了惩罚项R,目的是最小化两个与预测框的中心点距离。
当两边界框的距离越大时,惩罚项将越大。
当式子中S
DIoU可以直接最小化两个目标框的距离,因此比IoU速度快。对于包含两个车辆交错重叠的情况,采用DIoU-nms的方式可以将其区分检测出来,检测效果有了进一步改善。
试验结果见下表2:
表2改进前后方法实验对比结果
选取P查准率、R查全率来评价车辆检测模型。模型损失随着训练次数的增加而逐渐下降,当训练次数达100次左右时,模型的损失变化趋于平缓,基本达到收敛;当训练次数达到200次时,各个车辆检测模型的损失均降到0.0025以下,改进前后模型的损失基本不再变化,此时终止训练即可获得稳定的模型权重。此外,模型检测的准确性会随着查全率的升高而降低,当查全率约为90%时,查准率约为90%,此时模型在具有较高的查全率的同时,又保证了较高的检测精度。当查准率相等时,相对于YOLOv5模型来说,OP-YOLOv5车辆分类检测模型能够取得更高的查全率。上表可以看出OP-YOLOv5车辆分类检测模型获得了高达95.7%的平均检测精度,同时在检测速度上优于所有其他方法,达到了60.5f/s的快速识别检测速度,对于大客车、摩托车检测效果最佳,具有良好的检测实时性。
此外,对于道路交通中存在的小尺度目标及车辆重叠遮挡的车辆,检测效果有了提升,如图4所示,图4中横坐标为迭代次数,纵坐标从左到右依次为定位损失(Box loss)、置信度损失(Objectness loss)以及分类损失(Classfication loss)、查准率(Precision)、查全率(Recall),mAP@0.5(平均检测精度,当IoU交并比≥0.5时)。
如图5所示,图5中,横坐标为迭代次数,纵坐标从左到右依次为定位损失(Boxloss)、置信度损失(Objectness loss)以及分类损失(Classfication loss)、查准率(Precision)、查全率(Recall),mAP@0.5(平均检测精度,当IoU≥0.5时)。
综上所述,本发明所提出的OP-YOLOv5车辆分类检测模型在车辆检测的精度及速度上都有了提升,可以保证检测实时性的要求,并且能够很好地对车辆进行分类。另外,对于道路交通中存在的小尺度目标及车辆重叠遮挡的车辆,漏检率更低。
本实施例设计了一种基于优化YOLOv5模型的车辆分类检测方法。该方法具有处理速度快,准确率高等优点。本实施例在目标先验框处理部分使用到了K-Means算法来获取适用于不同大小车辆检测数据集的Anchor尺寸,并在Head部分加入了SE注意力模块且将普通卷积替换成了深度可分离卷积,这样做的目的是为了适应少量目标车辆且图像较小的情形。另一方面,在输出端以DIoU的方式替换原IoU方式进行非极大值抑制,实现了对于一些遮挡重叠的车辆目标辨识准确率的提升,有效的克服了原有的YOLOv5模型在识别小物体时准确率较低的缺陷。即OP-YOLOv5车辆分类检测模型基于现有的YOLOv5模型做了如下三方面的改进Kmeans聚类生成锚框,引入SE模块和卷积核部分替换、非极大值抑制方式修改为DIoU。同时,本实施例在原有识别技术的基础上提高了收敛速度和精度,改善了对于重叠部分较多的目标的识别。实验结果表明,本实施例有较好的识别效果,可用于道路交通流的实时检测和分类。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
应当注意的是,在本文的实施方式中所揭露的装置和方法,也可以通过其他的方式实现。以上所描述的装置实施方式仅仅是示意性的,例如,附图中的流程图和框图显示了根据本文的多个实施方式的装置、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序或代码的一部分,所述模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令,所述模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现方式中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用于执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
另外,在本文各个实施方式中的各功能模块可以集成在一起形成一个独立的部分,也可以是各个模块单独存在,也可以两个或两个以上模块集成形成一个独立的部分。
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
- 一种基于优化的YOLOv5模型的车辆分类检测方法
- 一种基于滚动优化裂缝分类识别模型的路面裂缝检测方法