基于无锚框全框与可见框融合的遮挡行人检测方法
文献发布时间:2023-06-19 18:30:43
技术领域
本发明涉及计算机视觉领域中的遮挡行人检测方法,特别是涉及采用无锚框融合可见框信息进行遮挡行人检测的方法。
背景技术
行人检测是计算机视觉中一个十分重要的研究领域,它是推断输入图像(或视频帧)中是否含有行人,若含有行人则标出行人位置的任务。行人检测技术在自动驾驶,智能监控,人际交互等方面具有广泛的应用场景。不同于一般的目标检测,行人检测的研究难点一直在于复杂密集行人场景下,行人之间的互相遮挡影响干扰严重,造成遮挡行人的检测准确性下降问题。
近年来,随着计算机视觉,大数据,云计算等技术在生活中的普及,面向自动驾驶感知周围环境与智能监控追踪人员等的应用需求,对于图像处理中的行人检测准确性提出了更高的要求,尤其是针对当下存在缺陷的密集行人场景下的遮挡行人的检测。因此,本专利主要研究如何提高遮挡行人的检测准确性。
行人检测隶属于目标检测的范畴,因此当前主流行人检测算法也都是目标检测通用的,目标检测任务可分为两部分:骨干网络的特征提取,检测头部的分类与定位。行人检测与一般目标检测比较不同在于行人与背景的辨识度更小,以及对行人场景中普遍存在的遮挡问题的处理。
行人检测类似于目标检测大体上可分为基于锚框,无锚框和两者的融合三类方法,其中,基于锚框的方法是对定义大量矩形框进行判断分类,计算复杂,过程繁琐,超参数多配置调试不易,如准确率较高的双阶段检测器Faster RCNN[1]和速度较快的单阶段检测器SSD[2]等。基于无锚框的方法将目标检测转化为了关键点或中心点与大小尺度的预测,进而生成目标检测框,思路简单,运算量小,效果良好,如CSP[3]预测行人的中心点与高,TLL[4]预测行人的头部和底部。
对于解决遮挡问题的研究,行人检测中的大多数方法都是通过利用可见部分作为附加监督来改善遮挡性能。这些方法大致可分为四种:一是为每种遮挡模式训练的独立检测器,再融合所有遮挡模式进行推断,如Zhou等人[5]利用AdaBoost.MH多标签学习方法构建了行人身体各个部位检测器共享的决策树来捕获所有部分的总体分布;二是采用注意力机制来更好的捕获特征,如MGAN[6]在特征层中利用了像素级注意图突出显示了可见部分并抑制遮挡部分;三是加入可见框的分类器将置信度的得分融入最终得分,如Bibox[7]等人采用Faster RCNN框架用正例训练全锚框和用正负例训练可见锚框,在推理过程中融合两个锚得分;四是提出针对于拥挤场景的新损失函数,如RepLoss[8]设计了一种新颖的回归损失以防止目标建议框转移到周围的行人。但是大部分方法都无法准确找到可见框与全框的对应关系并融合两者信息来解决遮挡问题。
参考文献:
[1]S.Q.Ren,K.M.He,G.R,and J Sun.Faster R-CNN:Towards real-time objectdetection with region proposal networks[J].IEEE Transactions on PatternAnalysis and Machine Intelligence,2017,39(6):1137-49.
[2]W.Liu,D.Anguelov,D.Erhan,C.Szegedy,S.Reed,C.Y.Fu,and B.A.C.SSD:Single shot multibox detector[C].In Proceedings of the 14th EuropeanConference on Computer Vision,2016.
[3]W.Liu,S.C.Liao,W.Q.Ren,W.D.Hu,and Y.N.Yu.High-level semanticfeature detection:A new perspective for pedestrian detection[C].InProceedings of IEEE International conference on Computer Vision and PatternRecognition,2019.
[4]T.Song,L.Sun,D.Xie,H.Sun,and S.Pu.Small-scale pedestrian detectionbased on topological line localization and temporal feature aggregation[C].InProceedings of the 15th European Conference on Computer Vision,2018.
[5]C.Zhou and J.Yuan.Multi-label learning of part detectors forheavily occluded pedestrian detection[C].In Proceedings of the IEEEInternational Conference on Computer Vision,2017.
[6]Y.W.Pang,J.Xie,M.H.Khan,R.M.Anwer,F.S.Khan,and L.Shao.Mask-guidedattention network for occluded pedestrian detection[C].In Proceedings of theIEEE International Conference on Computer Vision,2019.
[7]C.Zhou and J.Yuan.Bi-box regression for pedestrian detection andocclusion estimation[C].In Proceedings of the 15th European Conference onComputer Vision,2018.
[8]X.Wang,T.Xiao,Y.Jiang,S.Shao,J.Sun and C.Shen.Repulsion loss:Detecting pedestrians in a crowd[C].In Proceedings of IEEE Internationalconference on Computer Vision and Pattern Recognition,2018.
发明内容
本发明的目的是克服现有行人检测过程中在密集行人场景下遮挡造成的准确率下降不足,提出了基于无锚框全框与可见框融合的遮挡行人检测方法。
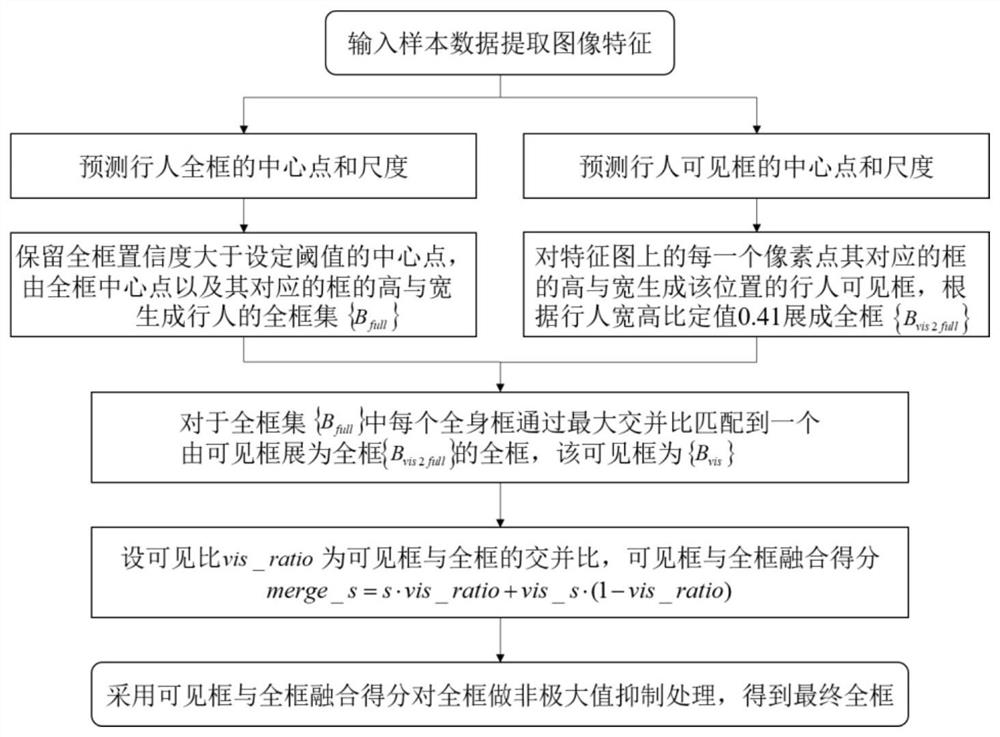
一种基于无锚框全框与可见框融合的遮挡行人检测方法,包括下列步骤:
步骤1:输入训练样本,利用深度卷积网络对其进行特征提取,得到特征图F;
步骤2:在特征图F上用两个分支分别采用无锚框的方法,通过全连接层得到分类的置信度图与回归的热力图,来预测行人全框与可见框的中心点以及中心点对应的框的高与宽;
步骤3:保留全框置信度大于设定阈值的中心点,由全框中心点以及其对应的框的高与宽生成行人的全框集{B
步骤4:对特征图上的每一个像素点其对应的框的高与宽生成该位置的行人可见框,根据行人宽高比定值0.41展成全框{B
步骤5:对于步骤3中全框集中每个全框,通过最大交并比匹配到一个由步骤4中可见框展为全框的全框,该可见框为{B
步骤6:设可见比vis_ratio为可见框与全框的交并比,全框与可见框的得分分别为s与vis_s,那么表示全框与可见框融合得分merge_s:
merge_s=s·vis_ratio+vis_s·(1-vis_ratio),
步骤7:根据上述的可见框与全框融合得分对全框做非极大值抑制处理,得到最终的全框。
采用本发明所述方法,通过两个分支同时预测行人的全框与可见框再根据遮挡程度融合两者得分得到的检测器是能融合全框与可见框信息的遮挡行人检测器。相对于基于传统仅全框信息检测行人的方法而言,同时预测可见框与全框,之后融合两者的得分的分类器,有效的融合了可见框相对于全框相互遮挡少的优点,进而可以减少行人相互遮挡情况的漏检率,提高检测器的准确率。同时,该方法思路简单,仅在原有无锚框行人检测器中训练阶段添加了预测可见框的分支和测试阶段的可见框与全框得分融合,便可以有效解决行人遮挡问题。
附图说明
图1中描述了本专利在自动驾驶与智能监控中遮挡行人检测的应用示例。
图2中描述了传统的无锚框行人检测的方法示例。
图3描述了本专利提出的基于无锚框全框与可见框融合的遮挡行人检测方法。
图4中描述了本专利提出的全框与可见框融合模块具体实施方法。
图5描述了本专利提出的基于无锚框全框与可见框融合的遮挡行人检测方法框图。
具体实施方式
下面结合附图对本专利作进一步的描述。
本专利提出的基于无锚框全框与可见框融合的遮挡行人检测方法。首先,通过CNN学习到图像的特征,利用无锚框的方法同时预测该图中的全框与可见框对应的中心点与大小,取置信度大于设定阈值的全框,将可见框采用行人宽高比为定值展成全框,将保留下的全框按最大交并比匹配到一个可见框展成的全框,求出该可见框与全框的交并比作为可见率,融合全框与对应可见框的得分进行非极大值抑制处理,此时的全框是融合了全框与可见框信息得到的,最终得到行人全框。
图2描述了传统的无锚框行人检测的示例。具体地,该类方法将原始图像输入到无锚框检测网络中,然后直接预测行人全框的中心点与尺度,得到最终检测框。产生预测仅包含全框,并不能很好的应对遮挡情况下,行人有较大的不可见区域。
图3描述了本专利所提出的基于无锚框全框与可见框融合的遮挡行人检测方法。具体地,该网络包含三个主要部分:卷积特征提取网络,全框与可见框预测网络和全框与可见框融合网络。卷积特征提取网络主要用来提取通用的特征。全框与可见框预测网络在卷积特征提取网络的基础上,进一步分别预测行人全框与可见框的中心点热图与尺度图。在中心点热图中,存在行人的位置响应值显著,而其他没有行人存在的位置响应值不显著,能够有效的反映出行人所在位置。之后由于可见框遮挡较少,经过全框与可见框融合网络对预测的可见框和全框进行了融合,从而显著地减少行人相互遮挡情况的漏检率,提高检测器的准确率。该全框与可见框融合网络仅用于测试阶段。
为了后面叙述方便,首先进行一些简要说明。在深度卷积网络提取图像的特征后,采用两个独立的无锚框检测分支分别预测全框与可见框的分类与回归,对于置信度大于设定阈值而保留下来的全框{B
merge_s=s·vis_ratio+vis_s·(1-vis_ratio), (1)
其中,s与vis_s分别是匹配后全框与可见框的得分。
最后用全框与可见框的融合得分来进行非极大值抑制后处理,得到最终的全框。
本发明从融合全框与可见框信息这一思想出发,提出了基于无锚框全框与可见框融合的遮挡行人检测方法。该方法同时预测全框与可见框,并对两者匹配之后进行信息融合,解决遮挡问题。所提方法包括图像特征提取、无锚框全框与可见框预测和全框与可见框的融合检测遮挡行人,其具体步骤如下:
步骤1:输入训练样本,利用卷积网络对其进行特征提取,得到特征图F;
步骤2:在特征图F上用两个分支分别采用无锚框的方法,通过全连接层得到分类的置信度图与回归的热力图,来预测行人全框与可见框的中心点以及中心点对应的框的高与宽;
步骤3:保留全框置信度大于设定阈值的中心点,由全框中心点以及其对应的框的高与宽生成行人的全框集{B
步骤4:对特征图上的每一个像素点其对应的框的高与宽生成该位置的行人可见框,根据行人宽高比定值0.41展成全框{B
步骤5:对于步骤3中全框集中每个全框,通过最大交并比匹配到一个由步骤4中可见框展为全框的全框,该可见框为{B
步骤6:设可见比vis_ratio为可见框与全框的交并比,全框与可见框的得分分别为s与vis_s,那么表示全框与可见框融合得分merge_s:
merge_s=s·vis_ratio+vis_s·(1-vis_ratio),
步骤7:根据上述的可见框与全框融合得分对全框做非极大值抑制处理,得到最终的全框。
具体地,本专利的网络参数训练包含以下几个步骤:
步骤1:准备训练图像集,每张图像中需至少包含一个行人,给出训练集对应图像的行人标注信息,包括行人所在区域的类别与标注框信息。另外为提升模型的检测精度,可以对数据进行增强。增强的方式包括但不限于:随机翻转,颜色变化,随机裁剪,加入随机噪声,图像缩放等。
步骤2:设置训练阶段的相关超参数,包括输入图像尺度、输入图像批大小、迭代次数、初始学习率、学习率权重衰减系数、训练判定正负例的分类得分阈值、各损失函数权重等。
步骤3:初始化卷积特征提取网络和全框与可见框预测网络权重,卷积特征提取网络可以选取ResNet,DenseNet,ResNeXt等网络结构,另外可以利用ImageNet预训练模型初始化相关的卷积权重。设定训练阶段的损失函数,该损失函数包括可见框与全框预测的损失函数,其中回归损失常采用的为L1 Smooth损失函数,分类损失常采用的为Softmax损失函数。
步骤4:根据深度卷积网络中常用的反向传播算法,计算每一层参数的梯度,采用梯度下降法(SGD)不断更新卷积特征提取网络和全框与可见框预测网络的权重参数。停止标准可以选择损失函数的损失值趋近于收敛(在一个稳定值附近波动,无明显变化)停止迭代信号。当迭代次数结束时,所学习的权重参数为最终的网络参数。
然后,我们介绍一下具体的测试过程:
步骤1:准备训练图像集,若为测试模型性能,准备的测试集应具有如训练图像一样的数据标注格式,并计算测试结果的mAP指标作为性能度量。若为实际应用测试,则不需具备标注信息。
步骤2:将测试图像输入网络中,利用训练得到的全框与可见框网络输出全框与可见框检测结果。基于全框与可见框检测结果,通过最大交并比策略进行一对一匹配,根据可见比对可见框与全框得分进行融合,根据该融合得分对全框检测结果进行非极大值抑制(NMS)处理,移除同一位置重叠较大的行人检测框,保留置信度较高的框作为最终的行人检测输出。
步骤3:可以测试模型mAP指标和可视化行人的检测框显示在图像上。
- 基于无锚框和提议框的场景文字检测方法
- 基于无锚框和提议框的场景文字检测方法