一种用于社交媒体的自演化假消息检测方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于深度学习技术领域,具体涉及一种自演化假消息检测方法。
背景技术
社交媒体平台(如新浪微博、推特等)上传播的假消息对社会稳定、公共安全产生了负面影响,例如疫情假消息对人们的日常出行、购物均会产生消极影响,同时容易造成恐慌。自动假消息检测对于假消息的治理至关重要,多数方法通过提取消息中包含的词法特征、句法特征、主题特征、传播特征等训练机器学习或深度学习分类器来检测假消息。这类方法均基于假设“不同事件的假消息的特征分布满足独立同分布”,然而不同事件假消息的特征分布往往存在一定的偏移,因为每个事件的消息都有独特的用词和传播模式。当新事件(模型训练过程中未见过的事件)与训练集中事件的数据分布差异较大时,这类方法难以检测出新事件当中的假消息。已有研究通过提取不同事件假消息的可迁移特征来检测新事件中的假消息,这些方法借助领域自适应、领域泛化等迁移学习技术将历史事件数据与新事件数据映射到同一特征空间,然后缩小事件分布差异以获取可迁移特征,再训练分类器以提升模型的泛化性。然而现有方法仍然存在如下缺陷:(1)每当新事件中的假消息需要检测时,模型需要联合所有历史事件数据从头开始训练针对新事件的检测模型。随着历史事件的增多,存在较大的存储开销和模型训练开销。(2)在迁移学习的过程中它们忽略了不同历史事件对新事件可迁移性的差异,容易导致负迁移而使新事件假消息检测效果下降。综上,现有方法仍然只关注一次性学习问题、持续学习能力差,难以适应社交媒体上不断演化、层出不穷的新闻事件。因此,针对现有假消息检测方法持续学习能力差、难以保留历史事件知识、无法有效检测新事件假消息的问题,
发明内容
为了克服现有技术的不足,本发明提供了一种用于社交媒体的自演化假消息检测方法,收集社交媒体上关于某个事件的帖子数据,利用深度学习模型提取帖子特征训练分类器,并利用特征相似度迁移模型存储的已学习相似历史事件知识帮助实现对新事件假消息分类器的训练,实现持续假消息检测。该发明基于两个核心机制实现:一是基于硬注意力的知识存储机制,包含一个知识记忆单元和事件掩码集合,其中记忆单元用于存储历史事件知识,事件掩码作为每个事件在记忆单元中的唯一标识可以随时调用历史事件知识;二是基于多头自注意力的知识迁移机制,用于量化相似历史事件对当前事件的可迁移程度,进而对历史事件知识进行融合以提升分类器在当前事件上的假消息检测效果。本发明可持续不断地对社交媒体上的假消息进行检测,无需存储历史数据从头开始训练模型,提升了假消息检测方法的自演化自适应能力。
本发明解决其技术问题所采用的技术方案包括如下步骤:
步骤1:利用Word2Vec将事件E
步骤2:引入一个由l层全连接神经网络组成的知识记忆单元,并利用一层随机初始化全连接网络为每个事件计算它们的事件嵌入向量
步骤3:根据
其中σ表示sigmoid函数,s表示一个扩展因子;将
步骤4:判断当前事件是否与历史事件相似,利用每个事件的第l个event mask计算事件之间的余弦相似度s
若s
步骤5:对于与当前事件E
其中
步骤6:若不存在与当前事件E
跳转至步骤8;
步骤7:根据特征向量
步骤8:根据特征向量
本发明的有益效果如下:
本发明可持续不断地对社交媒体上的假消息进行检测,无需存储历史数据从头开始训练模型,提升了假消息检测方法的自演化自适应能力。
附图说明
图1为本发明方法流程图。
图2为本发明实施例在PHEME数据集(Twitter数据)上,不同假消息事件学习顺序对本方法以及对比方法检测准确率的影响示意图。
图3为本发明实施例在PHEME数据集上本方法随着知识记忆单元大小、多头自注意力机制中“头”的数量的变化趋势示意图,(a)知识记忆单元的大小,(b)自注意力机制“头”的数量。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
本发明提出一种多事件累积知识迁移的分类方法。假设能够从一系列事件IE={E
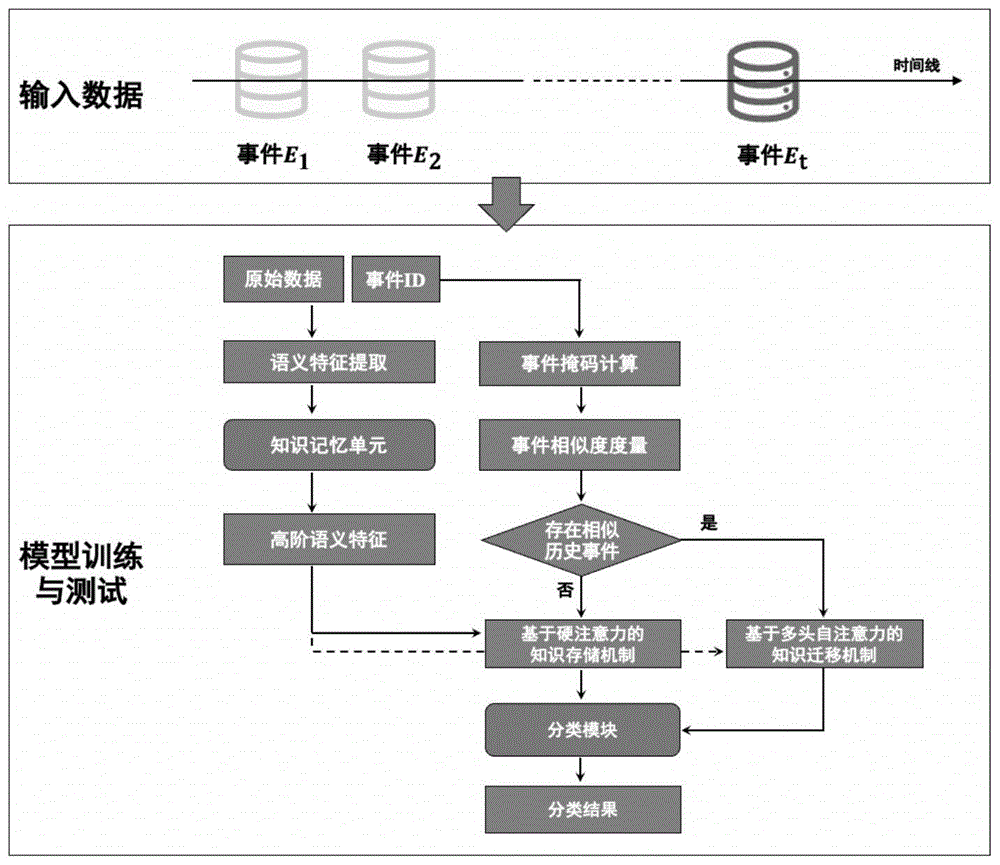
如图1所示,一种用于社交媒体的自演化假消息检测方法,包括以下步骤:
步骤1:利用Word2Vec将事件E
步骤2:为保留已学习历史事件知识,本发明引入了一个知识记忆单元(由l层全连接神经网络组成)并利用一层随机初始化全连接网络为每个事件计算它们的事件嵌入向量
步骤3:根据
其中σ表示sigmoid函数,s表示一个扩展因子。将
步骤4:判断当前事件是否与历史事件相似,利用每个事件的第l个(对应知识记忆单元的最后一个网络层)event mask计算事件之间的余弦相似度s
若s
步骤5:对于与当前事件E
其中
步骤6:若不存在与当前事件E
跳转至步骤8。
步骤7:根据特征向量
步骤8:根据特征向量
具体实施例:
本发明的具体步骤如下:
步骤一、收集事件假消息的帖子数据,确定每个事件的ID。
步骤二、利用Word2Vec将每个事件的消息数据转换为向量并利用Text-CNN进行语义特征提取;将事件ID转化为嵌入向量,并根据公式计算每个事件的掩码:
步骤三、将步骤二得到的语义特征输入知识记忆单元,继续提取每条消息的高阶语义特征。
步骤四、根据步骤二中得到的事件掩码计算事件之间的相似度,将全部历史事件划分为与当前事件相似和不相似两类事件集合。
步骤五、对于相似历史事件,根据基于多头自注意力的知识迁移机制计算融合特征向量(迁移相似历史事件知识);对于不相似历史事件,根据基于硬注意力的知识存储机制计算最终的特征向量(保护不相似历史事件知识以免被遗忘)。
步骤六、利用一层全连接神经网络对消息进行分类,预测当前输入消息是否为假消息。
如图2为本发明实施例在PHEME数据集(Twitter数据)上,不同假消息事件学习顺序对本方法以及对比方法检测准确率的影响示意图。
如图3为本发明实施例在PHEME数据集上本方法随着知识记忆单元大小、多头自注意力机制中“头”的数量的变化趋势示意图,(a)知识记忆单元的大小,(b)自注意力机制“头”的数量。
本发明为一种用于社交媒体的自演化假消息检测方法,通过激活/冻结神经网络单元的方式储存已学习历史事件的知识,并且利用自注意力机制选择性地迁移历史事件知识指导新事件假消息的检测,使假消息检测方法具备自演化能力,可持续不断地对社交媒体上的假消息进行检测。
- 一种用于焦距检测的双刀口差分检测装置、检测方法及数据处理方法
- 一种用于智能叉车臂故障的检测系统、检测方法及其处理方法
- 一种用于检测用户睡眠状态的检测系统及检测方法
- 一种用于社交媒体中假消息的检测方法
- 一种隐私保护的社交媒体假消息检测方法