一种基于深度学习的多尺度聚合Transformer遥感图像语义分割方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明属于图像处理技术领域,具体涉及一种基于深度学习的多尺度聚合Transformer遥感图像语义分割方法。
背景技术
在传感器技术的推动下,高分辨率遥感图像在全球范围内被越来越多的捕获,因其具有丰富的空间细节和潜在语义内容,遥感图像被广泛地用于语义分割和分类任务,出现了各种与之相关的应用,特别是具有高分辨率的城市遥感图像语义分割任务,如城市道路提取、城市规划和土地覆盖制图等。这些应用激励着研究人员探索有效和高效的分割网络。
深度学习的出现为遥感图像语义分割提供了一个新的方案。众多研究表明,与传统的图像语义分割方法相比,基于深度学习的图像语义分割方法可以极大地提高语义分割的精度,满足实际生产生活中的精度需要。由于遥感图像往往具有较大的分辨率和较大的尺度变化,这导致图像特征提取时面临“同类异谱”和“同谱异类”的问题,因此需要一种能够高效提取全局信息和局部信息的遥感图像语义分割方法解决遥感图像语义分割领域目前所面临的问题。同时,考虑到实际的应用场景,基于深度学习的遥感图像语义分割方法亟需在模型大小和计算复杂度上取得良好的平衡,解决难以在计算资源和存贮资源受限设备上部署应用的难题。
发明内容
本发明针对现有技术中存在的问题,提供一种基于深度学习的多尺度聚合Transformer遥感图像语义分割方法,方法设计并提出一个用于遥感图像的语义分割模型,主要应用于高分辨遥感图像的场景理解等任务。
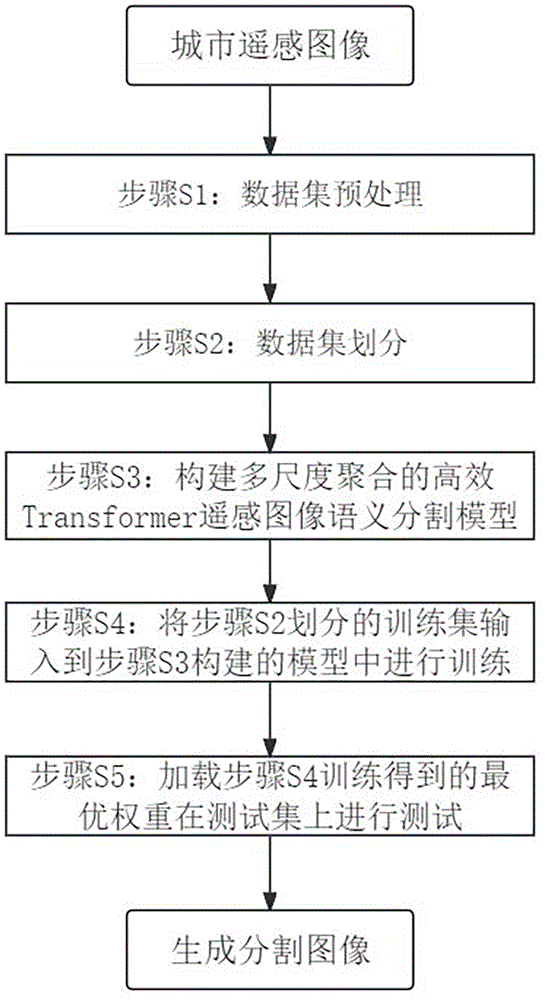
为实现上述技术目的,本发明所采用的技术方案为:一种基于深度学习的多尺度聚合Transformer遥感图像语义分割方法,包括以下步骤:
步骤S1:遥感图像预处理,对数据集进行裁剪扩充;
步骤S2:对步骤S1预处理后的数据集进行划分,分为训练数据集、验证数据集和测试数据集;
步骤S3:构建基于深度学习的多尺度聚合Transformer遥感图像语义分割模型;
步骤S4:使用步骤S2中的训练数据集和验证数据集对步骤S3构建的模型进行训练、验证和优化,并将得到的最优模型权重进行保存;
步骤S5:加载步骤S4所保存的最优模型权重,将步骤S2中的测试数据集输入步骤S3构建的模型中来分割遥感图像。
进一步的,步骤S1具体为:使用Vaihingen数据集,该数据集由33个非常精细的空间分辨率TOP图像块构成,平均大小为2494×2064像素,按照步长为1024像素对该数据集进行裁剪,得到每张为1024×1024像素的图像。
进一步的,步骤S2具体为:Vaihingen数据集由33个非常精细的空间分辨率TOP图像块构成,使用16个图像块进行训练,其余17个图像块进行验证和测试。
进一步的,步骤S3构建基于深度学习的多尺度聚合Transformer遥感图像语义分割模型,包括以下步骤:
S31:对于三通道的图像数据,首先经过一个3×3的卷积层扩展通道然后输入到MobileNetv2块中提取图像的浅层特征;
S32:对于提取到的浅层特征,利用具有高效的Transformer的MobileViTv2块来提取语义特征,编码器内包含3个MobileViTv2块,每个块和MobileNetv2块交替串联在一起;MobileViTv2块主要由两部分构成,局部表示部分和全局表示部分;对于输入的张量
S33:解码器具有四个阶段与编码器阶段对应,且每个阶段都有一个双线性插值操作,来恢复特征分辨率,前三个阶段的每个阶段都由部分卷积Transformer模块构成并且都采用高效的三明治设计,即高效的部分卷积Transformer模块夹在两个FFN层之间,具体来说,就是应用了一个自注意力层
S34:注意力层
S35:为了使QKV层学习到特征更丰富的信息提高其容量,使用级联的方式来计算每个头的注意力,将每个头的输出添加到后续头中,以逐步改进特征表示:
S36:每个阶段输出的特征经过双线性插值操作恢复特征分辨率输入到下一个阶段,将解码器每个阶段的特征通过加权求和操作与编码器中对应阶段的特征进行融合,加权求和公式为:
进一步的,步骤S4,使用步骤S2中的训练数据集和验证数据集对步骤S3构建的模型进行训练、验证和优化,并将得到的最优模型权重进行保存,具体为:
S41:构建用于模型参数优化更新的损失函数,模型选择以交叉熵Cross Entropy Loss函数作为损失函数来更新参数,交叉熵函数表达式为:
S42:设置模型训练参数,其中,batchsize设置为8,初始学习率设置为0.0002,迭代80K轮,每10k轮保存一次模型权重;训练时,使用随机裁剪、随机旋转和随机翻转数据增强技术,使用随机裁剪数据增强技术的目的是将输入的遥感图像裁剪为512×512像素,使用随机旋转和随机翻转的目的是增加数据的多样性提高模型的泛化能力和鲁棒性;
S43:使用mIoU作为主要评价指标来客观评价模型的分割性能,mIoU的计算公式为:
进一步的,步骤S5,加载步骤S4所保存的最优模型权重,将步骤S2中的测试数据集输入步骤S3构建的模型中来分割遥感图像,具体为:
S51:将步骤S2的测试数据集输入到步骤S3构建的模型中,并应用随机反转和随机旋转数据增强技术;
S52:加载步骤S4中的最优模型权重到步骤S3构建的模型中来分割遥感图像。
本发明设计并提出一个用于遥感图像的语义分割模型,主要应用于高分辨遥感图像的场景理解等任务。该方法模型沿用UNet的框架设计,主要分为编码器和解码器两部分。编码器中轻量级的CNN-Transformer混合网络MobileViTv2作为主干网,通过一系列的卷积、池化和非线性激活函数等操作,逐渐减少特征图的分辨率,同时提取出具有语义信息的高级特征。编码器的目标是在保留重要语义信息的同时,减少冗余和噪声,以便于后续的处理。解码器由部分卷积Transformer块构成。通过双线性插值上采样操作将编码器输出的低维特征映射恢复到原始图像的尺寸,同时利用部分卷积Transformer保留特征中丰富的语义信息,生成与输入图像相对应的每个像素的密集语义分割结果。
有益效果:本发明改进基于Transformer的遥感图像语义分割模型,可以高效地提取全局信息,更好地融合多尺度特征。相比于流行的基于Transformer的语义分割模型,本发明提出的模型拥有更少的参数量和计算量,大大减小资源占用,扩大了模型的实际应用场景。
附图说明
图1展示了本发明方法的整体流程图;
图2为本发明中多尺度聚合Transformer遥感图像语义分割模型的总体结构图;
图3为本发明中多尺度聚合Transformer遥感图像语义分割模型中的特征细化模块;
图4为本发明中多尺度聚合Transformer遥感图像语义分割模型中的部分卷积Transformer模块;
图5为本发明中多尺度聚合Transformer遥感图像语义分割模型中部分卷积Transformer模块中的部分卷积注意力;
图6为本发明中模型的训练流程图;
图7本发明方法与一些其他轻量级语义分割方法的在LoveDA数据集上的对比实验数据表;
图8为本专利方法与一些其他轻量级语义分割方法的在iSAID数据集上的对比实验数据表。
具体实施方式
下面结合具体实施例对本发明的技术方案做进一步说明,但不限于此。
实施例1
一种基于深度学习的多尺度聚合Transformer遥感图像语义分割方法,整体流程图如图1所示,包括以下步骤:
步骤S1,对遥感图像进行预处理;
S11:以ISPRS Vaihingen 2D数据集为例,该数据集是一个用于计算机视觉和机器学习研究的公开数据集,通常用于遥感图像分割任务。该数据集以德国斯图加特市的一个地区命名,包含高分辨率的航拍图像,通常用于测试和评估图像分割算法的性能。数据集是由航空摄影捕捉而来通常包含多光谱图像,包括红外波段。这些图像具有很高的空间分辨率,可用于识别城市地区中的不同地物和目标。该数据集由33个非常精细的空间分辨率TOP图像块构成,平均大小为2494×2064像素。首先按照步长为1024像素对该数据集进行裁剪,得到每张为1024×1024像素的图像。
步骤S2,对步骤S1预处理后的遥感图像进行数据集的划分;
S21:由于Vaihingen数据集由33个非常精细的空间分辨率TOP图像块构成,使用16个图像块进行训练,其余17个图像块进行验证和测试。
步骤S3,构建基于深度学习的多尺度聚合的高效Transformer遥感图像语义分割方法,模型的整体结构图如图2所示;
S31:对于三通道的图像数据,首先经过一个
S32:对于提取到的浅层特征,利用具有高效的Transformer的MobileViTv2块来提取语义特征,编码器内包含3个MobileViTv2块,每个块和MobileNetv2块交替串联在一起,MobileViTv2块主要由两部分构成,局部表示部分和全局表示部分;对于输入的张量
S33:解码器具有四个阶段与编码器阶段对应,且每个阶段都有一个双线性插值操作,来恢复特征分辨率,前三个阶段的每个阶段都由部分卷积Transformer模块构成并且都采用高效的三明治设计,即高效的部分卷积Transformer模块夹在两个FFN层之间;具体来说,就是应用了一个自注意力层
S34:注意力层
S35:为了使QKV层学习到特征更丰富的信息提高其容量,使用级联的方式来计算每个头的注意力,将每个头的输出添加到后续头中,以逐步改进特征表示:
S36:每个阶段输出的特征经过双线性插值操作恢复特征分辨率输入到下一个阶段,将解码器每个阶段的特征通过加权求和操作与编码器中对应阶段的特征进行融合,加权求和公式为:
步骤S4,使用步骤S2中的训练数据集和验证数据集对步骤S3构建的模型进行训练、验证和优化,并保存最优权重。模型训练测试流程如图6所示;
S41:构建用于模型参数优化更新的损失函数,模型选择以交叉熵(Cross Entropy Loss)函数作为损失函数来更新参数,交叉熵函数表达式为:
S42:设置模型训练参数,其中,batchsize设置为8,初始学习率设置为0.0002,迭代80K轮,每10k轮保存一次模型权重;训练时,使用随机裁剪、随机旋转和随机翻转数据增强技术;使用随机裁剪数据增强技术的目的是将输入的遥感图像裁剪为512×512像素;
S43:使用mIoU作为主要评价指标来客观评价模型的分割性能;mIoU的计算公式为:
步骤S5,将步骤S2中的测试数据集输入到步骤S3构建的模型中,通过加载步骤S4中的最优模型权重来分割遥感图像;
S51:将步骤S2的测试数据集输入到步骤S3构建的模型中,并应用随机反转和随机旋转数据增强技术;
S52:加载S4中的最优模型权重到步骤S3构建的模型中来分割遥感图像。
为了评估本专利方法的有效性,在LoveDA数据集上进行了实验,图7为部分实验结果。LoveDA数据集包含城市和农村两个复杂场景的遥感图像,得益于有效的模型设计,本专利方法以有限的模型大小和计算成本很好的处理城市和农村两个场景,与最近的一些轻量级ViT模型相比,专利方法不仅取得了最好的mIoU(45.53%),而且在水域这个类别上取得了卓越的性能表现(60.12%),比CMT高13.16%,比LVT高2.18%。为了评估本专利方法的泛化性,在iSAID数据集上进行了进一步的实验,图8为部分实验结果,iSAID数据集作为遥感领域首个大规模分割数据集,共有15个类别;每幅图像都有大量的物体、大量的小物体和较大尺度的变化,这对轻量级的语义分割方法是一个挑战,实验结果可以看出,对比最近一些轻量级ViT模型,本专利方法取得了最好的mIoU(38.64%)和mAcc(45.17%)。
需要说明的是,上述实施例仅仅是实现本发明的优选方式的部分实施例,而非全部实施例。显然,基于本发明的上述实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的其他所有实施例,都应当属于本发明保护的范围。
- 基于网页标签的产品数据推送方法、装置、设备及介质
- 基于区块链的理财产品推荐方法、装置、介质及电子设备
- 基于模板的产品构建方法、装置、计算机设备及存储介质
- 基于模型的产品构建方法、装置、计算机设备及存储介质
- 基于图表的产品构建方法、装置、计算机设备及存储介质
- 基于标签库的系统投产方法、装置、设备、介质和产品
- 基于标签库的系统投产方法、装置、设备、介质和产品