基于电磁陷阱的自适应卫星通信干扰方法及系统
文献发布时间:2023-06-19 18:27:32
技术领域
本发明涉及通信干扰技术领域,具体涉及一种基于电磁陷阱的自适应卫星通信干扰方法及系统。
背景技术
近年来,各国大力发展卫星事业,以Starlink、Oneweb、鸿雁系统为代表的巨型星座迅速崛起,卫星数量呈现爆炸式增长;然而,频谱资源有限,传统的卫星通信方式逐渐无法满足资源分配的要求,而自适应技术可以有效提高频谱利用率;因此,具有学习能力的自适应卫星通信是一个重要的发展趋势。
面对复杂的电磁空间态势,卫星通信对抗日益激烈;然而,传统的卫星通信干扰样式无法有效打击自适应卫星节点;在通信对抗领域,人工智能提供了很好的解决思路;干扰和抗干扰双方想要智能对抗,需要与环境实时交互,学习状态和行为的映射关系,即学到对手策略,做出相应的动作,以获取最大累计回报;强化学习作为人工智能的研究热点,具有与环境在线交互与学习的能力,刚好可以满足通信对抗的需求;因此,被广泛应用到通信对抗领域。
在通信干扰领域,Q-Learning作为强化学习的典型算法,被应用于求解最佳干扰频率选择问题;此外,
Chen Z等人发表于2020 IEEE Wireless Communications and NetworkingConference (WCNC)上的Adversarial Jamming Attacks on Deep ReinforcementLearning Based Dynamic Multichannel Access[C]中基于Actor-Critic(AC)提出了2种信道攻击策略:1)基于前馈神经网络(feedforward neural network,FNN);2)基于深度强化学习(deep reinforcement learning,DRL)策略,使得基于DRL用户执行的动态多信道访问的准确性最小化;强化学习还可以应用于通信功率控制;Lu Z等人发表于2019 IEEE90th Vehicular Technology Conference (VTC2019-Fall)上的Dynamic Channel Accessand Power Control via Deep Reinforcement Learning[C]中基于DQN算法设计了一种干扰方式,在相同功率约束情况下,可以大大降低用户的总传输速率;在波束选择方面,Kim G等人发表于IEEE Access上的Reinforcement Learning Based Beamforming Jammer forUnknown Wireless Networks[J]中提出了一种基于MAB的干扰策略,在不知道对手网络拓扑和信道信息的情况下,干扰机找到了最佳的干扰波束宽度和方向。
上述基于强化学习的干扰策略可以有效打击传统抗干扰用户;然而,面对具备学习能力的自适应抗干扰智能用户,单一的智能干扰样式仍然存在效果不佳的问题,即面对具有自主决策能力的卫星节点,传统的干扰样式难以应对;此外,目前大部分研究主要以地面通信对抗为背景,卫星通信对抗的研究关注度较少;为了满足太空战场环境需求,如何有效干扰自主化、智能化卫星通信节点,成为亟待解决的问题。
发明内容
针对上述问题,本发明的一个目的是以低轨卫星为背景,针对基于Q-Learning的自适应卫星节点,结合传统与智能干扰方式,提出一种基于电磁陷阱的自适应卫星通信干扰方法,该方法基于强化学习算法,最终实现“诱骗反智”的作战效果,能有效干扰自适应卫星节点,提升干扰精确度,降低通信吞吐量。
本发明的第二个目的是提供一种基于电磁陷阱的自适应卫星通信干扰系统。
本发明所采用的第一个技术方案是:一种基于电磁陷阱的自适应卫星通信干扰方法,包括以下步骤:
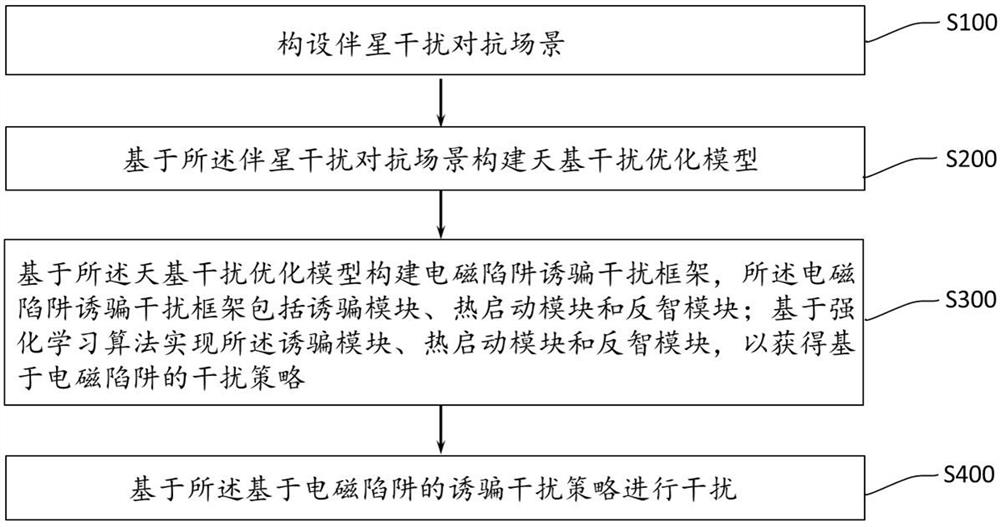
S100:构设伴星干扰对抗场景;
S200:基于所述伴星干扰对抗场景构建天基干扰优化模型;
S300:基于所述天基干扰优化模型构建电磁陷阱诱骗干扰框架,所述电磁陷阱诱骗干扰框架包括诱骗模块、热启动模块和反智模块;基于强化学习算法实现所述诱骗模块、热启动模块和反智模块,以获得基于电磁陷阱的干扰策略;
S400:基于所述基于电磁陷阱的诱骗干扰策略进行干扰。
优选地,所述步骤S200中的天基干扰优化模型通过以下公式表示:
式中,
优选地,所述步骤S300中基于电磁陷阱的干扰策略包括:
在诱骗模块,干扰卫星首先发动第一类干扰;卫星用户将学习第一类干扰策略,避开受扰信道,选择安全信道传输数据;随着不断地训练和学习,最终形成卫星用户的第一类抗干扰策略;
在热启动模块,干扰卫星学习卫星用户的第一类抗干扰策略,即基于Q-Learning进行在线训练,从而实现热启动;当干扰卫星完成热启动,即形成热启动模块训练好的干扰策略;
在反智模块,将干扰卫星发动第一类干扰切换为发动第二类干扰;利用热启动模块训练好的干扰策略,有针对性地干扰Q-Learning抗干扰卫星用户;在一段时间内,第二类干扰能有效干扰落入电磁陷阱的抗第一类干扰卫星用户;
当卫星用户的第一类抗干扰策略持续受扰后,卫星用户将逐渐形成新的抗干扰策略,此时干扰效果将逐渐降低;基于反智模块将诱骗模块中干扰卫星发动第二类干扰再次切换为第一类干扰,从而牵引卫星用户回归第一类抗干扰策略,至此,一个回合的对抗结束。
优选地,所述第一类干扰包括扫频干扰、梳状干扰和脉冲干扰,第二类干扰包括基于Q-Learning的干扰。
优选地,步骤S300中所述诱骗模块通过以下算法实现:
1)基于当前时隙卫星用户的信道选择和上一时隙的干扰信道,获得卫星用户在抗干扰信道选择过程中的当前状态;
2)卫星用户根据当前抗第一类干扰策略选择当前动作;
3)基于卫星用户在抗干扰信道选择过程中的当前状态、当前动作计算当前卫星用户信道选择奖励值;
4)根据卫星用户在抗干扰信道选择过程中的当前状态、当前动作以及当前卫星用户信道选择奖励值更新卫星用户在
5)输出当前卫星用户信道选择、奖励值以及抗第一类干扰策略。
优选地,步骤S300中所述热启动模块通过以下算法实现:
1)基于干扰卫星当前时隙干扰信道的选择
2)基于干扰卫星根据当前干扰策略
3)基于
4)根据
5)输出当前干扰信道选择奖励值
优选地,步骤S300中所述反智模块通过以下算法实现:
1)干扰卫星根据当前时隙卫星用户的信道选择
2)干扰卫星选择当前时隙的干扰信道
3)Q-Learning抗干扰卫星用户根据
4)记录当前时隙卫星用户的信道选择
优选地,所述当前卫星用户信道选择奖励值通过以下公式计算得到:
式中,
所述当前干扰信道选择奖励值通过以下公式计算得到:
式中,
优选地,通过以下公式更新卫星用户在
式中,
通过以下公式更新干扰在
式中,
本发明所采用的第二个技术方案是:一种基于电磁陷阱的自适应卫星通信干扰系统,包括对抗场景构设模块、天基干扰优化模型构建模块、基于电磁陷阱的干扰策略构建模块和干扰模块;
所述对抗场景构设模块用于构设伴星干扰对抗场景;
所述天基干扰优化模型构建模块用于基于所述伴星干扰对抗场景构建天基干扰优化模型;
所述基于电磁陷阱的干扰策略构建模块用于基于所述天基干扰优化模型构建电磁陷阱诱骗干扰框架,所述电磁陷阱诱骗干扰框架包括诱骗模块、热启动模块和反智模块;基于强化学习算法实现所述诱骗模块、热启动模块和反智模块,以获得基于电磁陷阱的干扰策略;
所述干扰模块用于基于所述基于电磁陷阱的诱骗干扰策略进行干扰。
上述技术方案的有益效果:
(1)本发明公开的一种基于电磁陷阱的自适应卫星通信干扰方法通过设置诱骗模块、热启动模块、反智模块,形成干扰闭环,达到“诱骗反智”的作战效果;仿真结果表明:相比其他算法,该方法可有效干扰自适应卫星节点,提升干扰精确度,降低通信吞吐量。
附图说明
图1为本发明的一个实施例提供的一种基于电磁陷阱的自适应卫星通信干扰方法的流程示意图;
图2为本发明一个实施例提供的场景构设示意图;
图3为本发明一个实施例提供的天基干扰可行性分析示意图;
图4为本发明一个实施例提供的基于电磁陷阱的诱骗干扰框架的示意图;
图5为本发明一个实施例提供的诱骗模块时频图;
图6为本发明一个实施例提供的热启动模块时频图;
图7为本发明一个实施例提供的干扰平均准确率对比图A;
图8为本发明一个实施例提供的用户平均吞吐量对比图A;
图9为本发明一个实施例提供的干扰平均准确率对比图B;
图10为本发明一个实施例提供的用户平均吞吐量对比图B;
图11为本发明一个实施例提供的不同干扰策略性能对比图;
图12为本发明的一个实施例提供的一种基于电磁陷阱的自适应卫星通信干扰系统的结构示意图。
具体实施方式
下面结合附图和实施例对本发明的实施方式作进一步详细描述。以下实施例的详细描述和附图用于示例性地说明本发明的原理,但不能用来限制本发明的范围,即本发明不限于所描述的优选实施例,本发明的范围由权利要求书限定。
在本发明的描述中,需要说明的是,除非另有说明,“多个”的含义是两个或两个以上;术语“第一”“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性;对于本领域的普通技术人员而言,可视具体情况理解上述术语在本发明中的具体含义。
实施例一
如图1所示,本发明的一个实施例提供了一种基于电磁陷阱的自适应卫星通信干扰方法,包括以下步骤:
S100:构设伴星干扰对抗场景;
如图2所示,伴星干扰对抗场景,该场景包括3部分:1组卫星收发对
式中,
卫星用户和干扰卫星的可用信道集分别通过以下公式表示:
式中,
假设卫星用户和干扰卫星的通信频带相同,即
本发明从空间位置以及天线角度方面分析天基干扰的可行性,如图3所示,
式中,
参考ITU-RS.1528建议书提供的卫星天线方向图,低轨卫星参考3dB波束宽度为1.6°;显然,夹角
S200:基于伴星干扰对抗场景构建天基干扰优化模型;
本发明从抗干扰的角度,描述卫星用户的吞吐量,从而引出天基干扰的优化目标;在干扰存在的情况下,卫星用户在信道
式中,
式中,
卫星通信的路径损耗可以用自由空间损耗模型来描述,节点
式中,
由表示卫星用户的信号与干扰、噪声的比的公式可知,卫星用户的信道选择决定着吞吐量的大小,因此,自主化、智能化抗干扰卫星的优化目标可以设定为平均累加信道选择奖励,从而最大化用户的吞吐量。
式中,
卫星用户的目的是通过选择最优信道,从而最大化吞吐量;因此,通过干扰卫星的优化目标获得最大化干扰平均准确率,从而降低用户吞吐量;其中,天基干扰优化模型通过以下公式表示:
式中,
S300:基于天基干扰优化模型构建电磁陷阱诱骗干扰框架,所述电磁陷阱诱骗干扰框架包括诱骗模块、热启动模块和反智模块;基于强化学习算法实现所述诱骗模块、热启动模块和反智模块,以获得基于电磁陷阱的干扰策略;
(1)基于天基干扰优化模型构建电磁陷阱诱骗干扰框架;
电磁陷阱诱骗干扰框架,所述电磁陷阱诱骗干扰框架包括诱骗模块、热启动模块和反智模块;
电磁陷阱诱骗干扰框架包括2类干扰和3个对抗模块;其中,第一类干扰是指传统干扰(例如扫频干扰、梳状干扰、脉冲干扰等),第二类干扰是指具备感知学习能力的智能干扰(例如基于Q-Learning的干扰)样式;在一个对抗回合中包含3个对抗模块:诱骗模块、热启动模块以及反智模块。
(2)基于强化学习算法实现所述诱骗模块、热启动模块和反智模块,以获得基于电磁陷阱的干扰策略;
基于电磁陷阱的干扰策略包括:
在诱骗模块,干扰卫星首先发动第一类干扰(例如扫频干扰);卫星用户将学习第一类干扰策略,避开受扰信道,选择安全信道传输数据;随着不断地训练和学习,最终形成卫星用户的第一类抗干扰策略;
在热启动模块,干扰卫星学习卫星用户的第一类抗干扰策略,即干扰卫星收集并记录卫星用户的信道选择,基于Q-Learning进行在线训练,从而实现热启动;当干扰卫星完成热启动,即形成热启动模块训练好的干扰策略;
在反智模块,将干扰卫星发动第一类干扰切换为发动第二类干扰;利用热启动模块训练好的干扰策略,有针对性地干扰Q-Learning抗干扰卫星用户;在一段时间内,基于热启动的第二类干扰可以有效干扰落入电磁陷阱的抗第一类干扰卫星用户,从而实现“诱骗反智”的作战效果;
当卫星用户的第一类抗干扰策略持续受扰后,由于卫星用户具有学习与自主决策能力,当卫星用户的第一类抗干扰策略持续受扰后,卫星用户将逐渐改变并形成新的抗干扰策略,此时干扰效果将逐渐降低;当干扰效果不再明显,为防止Q-Learning抗干扰卫星用户形成新的抗干扰策略;基于反智模块将诱骗模块中干扰卫星发动第二类干扰再次切换为第一类干扰,从而“牵引”卫星用户回归原始的第一类抗干扰策略,至此,一个回合的对抗结束。
如图4所示,第一类干扰以扫频干扰为例,第二类干扰以基于Q-Learning的干扰为例,分析诱骗干扰过程(即基于电磁陷阱的干扰策略):
在诱骗模块,基于干扰卫星首先发动扫频干扰作为“陷阱”,诱骗Q-Learning抗干扰卫星用户;随后,具有学习能力的卫星用户将学习扫频干扰策略(即扫频规律),避开受扰信道,选择安全信道传输数据;随着不断地训练和学习,最终形成卫星用户的抗扫频干扰策略,并进行环境反馈。
在热启动模块,干扰卫星将根据环境反馈,学习卫星用户的抗扫频干扰策略,即基于Q-Learning进行在线训练,从而实现热启动;当干扰卫星完成热启动,即形成热启动模块训练好的干扰策略。
在反智模块,将诱骗模块中干扰卫星发动扫频干扰切换为发动基于Q-Learning的干扰样式,新切换的基于Q-Learning的干扰样式不再需要初始化,而是直接利用热启动模块训练好的干扰策略,有针对性地干扰Q-Learning抗干扰卫星用户(即自主化、智能化抗干扰卫星用户);在一段时间内,基于热启动的Q-Learning干扰可以有效干扰落入电磁陷阱的抗扫频卫星用户,从而实现“诱骗反智”的作战效果。
然而,由于卫星用户具有学习与自主决策能力,当卫星用户的抗扫频干扰策略持续受扰后,卫星用户将逐渐改变并形成新的抗干扰策略,此时干扰效果将逐渐降低;当干扰效果不再明显,为防止Q-Learning抗干扰卫星用户形成新的抗干扰策略;基于反智模块将诱骗模块中干扰卫星发动基于Q-Learning干扰样式再次切换为扫频干扰,从而“牵引”卫星用户回归原始的抗扫频干扰策略,至此,一个回合的对抗结束。
(1)诱骗模块;
在诱骗模块,干扰卫星发动扫频干扰作为“陷阱”,诱骗卫星用户学习扫频规律;卫星用户的信道选择过程可以被建模为马尔科夫决策过程(Markov Decision Process,MDP);该过程可以被定义为一个四元组
诱骗模块通过以下算法实现:
1)基于当前时隙卫星用户的信道选择和上一时隙的干扰信道,获得卫星用户在抗干扰信道选择过程中的当前状态
其中,卫星用户在抗干扰信道选择过程中的当前状态通过以下公式表示:
式中,
2)卫星用户根据当前的抗扫频干扰策略
卫星用户在抗干扰信道选择过程中的当前动作是指用户在当前状态下选择下一时隙的信道,通过以下公式表示:
式中,
3)基于
式中,
4)根据
针对MDP问题,通常通过值迭代和策略迭代解决,由于环境先验信息(即状态转移概率
式中,
5)输出当前卫星用户信道选择
诱骗模块的具体对抗过程,如表1所示。
表1诱骗模块的具体对抗过程
(2)热启动模块;
在热启动模块,虽然干扰卫星仍处于在线扫频干扰模式,Q-Learning抗干扰卫星用户(即自主化、智能化卫星用户)也逐渐学习到较为稳定的卫星用户的抗扫频干扰策略;干扰卫星收集并记录卫星用户的信道选择,并且基于Q-Learning进行在线训练,从而实现热启动,为反智模块做准备。
干扰卫星在线训练热启动模块过程的MDP四元组被定义为
热启动模块通过以下算法实现:
1)干扰卫星当前时隙干扰信道的选择
其中,干扰信道选择过程中的当前状态通过以下公式表示:
式中,
2)干扰卫星根据当前干扰策略
干扰信道选择过程中的当前动作是指干扰卫星在当前状态下选择下一时隙的干扰信道,通过以下公式表示:
式中,
3)基于
式中,
4)根据
干扰卫星根据以下公式更新
式中,
5)输出当前干扰信道选择奖励值
干扰卫星在线训练热启动模块的过程,与自主化、智能化卫星用户学习扫频干扰的过程类似,详细的训练过程如表2所示。
表2 在线训练热启动模块的过程
(3)反智模块;
不同于诱骗模块和热启动模块,反智模块的干扰样式由扫频干扰切换为基于Q-Learning的干扰;此模块是基于热启动的干扰卫星与Q-Learning抗干扰卫星用户之间的对抗;反智模块通过以下算法实现:
1)干扰卫星根据当前时隙卫星用户的信道选择
2)干扰卫星选择当前时隙的干扰信道
3)Q-Learning抗干扰卫星用户根据
4)记录当前时隙卫星用户的信道选择
具体对抗过程如表3所示。
表3 反智模块的对抗过程
在算法2-1~算法2-3的基础上,基于强化学习的电磁陷阱诱骗干扰算法的具体对抗过程如算法表4所示;
所述基于电磁陷阱的干扰策略就是利用智能化卫星的学习能力,结合扫频干扰和智能干扰2种干扰样式;利用扫频干扰引诱用户落入“陷阱”;而后,用完成在线训练的基于热启动的Q-Learning干扰有针对性的发起攻击,从而实现“诱骗反智”的作战效果。
表4 基于强化学习的电磁陷阱干扰算法
可见,电磁陷阱有3个作用:
(1)诱骗用户学习第一类干扰(例如扫频干扰)规律,使其形成稳定的抗第一类干扰信道选择策略;从而掉入陷阱;
(2)为第二类干扰争取训练时间;切换干扰模式后,基于热启动的干扰卫星可以较为准确的攻击抗第一类干扰用户;
(3)当第二类干扰,即智能干扰(例如基于Q-Learning干扰)再次切换为第一类干扰(例如扫频干扰)时,牵引用户回归抗第一类干扰策略,推动下一回合的对抗。
S400:基于所述基于电磁陷阱的诱骗干扰策略进行干扰。
下面结合相关的仿真试验具体说明本发明的有益效果:
考虑低轨单个自主化、智能化卫星局部对抗场景,假设干扰卫星、用户发射卫星以及接收卫星均匀分布在550km的倾斜轨道上,且相邻卫星之间的星间距离为100km,主要仿真参数设置如下:基于Q-Learning的卫星单位数据传输时间
1、学习与训练过程分析
如图5所示,展示了诱骗模块中,基于Q-Learning抗干扰用户学习扫频干扰的时频图;显然,通过不断地学习,自主化、智能化卫星用户可以有效躲避干扰攻击,当然,从基于电磁陷阱诱骗干扰策略的角度分析,用户已经落入干扰“陷阱”。
图6展示了热启动模块中,基于Q-Learning干扰的在线训练过程;可以观察到,干扰方通过不断地训练与学习,基本可以学习到卫星用户的抗扫频干扰策略,实现了干扰频点与用户频点基本重合,从而完成热启动。
在仿真过程中,设置每200次迭代作为一个周期,从干扰平均准确率的角度,分析算法2-1诱骗模块和算法2-2热启动模块的仿真效果;如图7所示,扫频干扰vs基于Q-Learning抗干扰表示基于Q-Learning抗干扰对抗扫频干扰的学习过程;基于Q-Learning干扰vs基于Q-Learning抗扫频干扰表示基于Q-Learning干扰的在线训练过程;显然,自主化、智能化卫星抗干扰用户可以很快的学习到扫频干扰规律,并且可以较好地规避干扰;此外,基于Q-Learning干扰通过在线训练,也可以基本学习到卫星用户的抗扫频策略,从而实现较高的干扰准确率。
为了说明干扰平均准确率这一评价指标的有效性,从平均吞吐量的角度验证诱骗模块和热启动模块对抗效果,如图8所示;可以观察到图7和图8具有相反的变化趋势,该现象验证了干扰平均准确度与用户平均吞吐量的反比关系。
2、对抗过程分析
以下从整个对抗过程的角度,分析基于电磁陷阱诱骗策略的干扰效果:
如图9所示,针对Q-Learning抗干扰卫星用户,分别将单一扫频干扰(扫频干扰vs基于Q-Learning抗干扰)和单一基于Q-Learning干扰策略(基于Q-Learning干扰vs基于Q-Learning抗干扰)作为对比算法;分析基于所提干扰(即所述基于电磁陷阱干扰策略)vs基于Q-Learning抗干扰的干扰平均准确率;观察整个对抗过程,可以得到以下两点规律:
(1)相比于单一扫频干扰和单一基于Q-Learning干扰,所提算法具有更高的干扰平均准确率,这体现了所提干扰策略的优越性;
(2)所提算法的干扰平均准确率曲线波动很大;下面,具体分析波动原因。
设置干扰样式每隔10个迭代周期切换一次,观察图中的所提干扰(是指基于电磁陷阱干扰策略)vs基于Q-Learning抗干扰曲线,首先,在0-5迭代周期范围内,干扰方处于“诱骗模块”;干扰卫星执行扫频干扰,引诱Q-Learning的抗干扰卫星用户学习扫频规律;显然,随着干扰平均准确率的逐渐降低,抗干扰方逐渐学习到扫频规律。
其次,在5-10迭代周期内,干扰方处于“热启动模块”;此时,干扰平均准确率稳定在0%,说明卫星用户已经形成较为稳定的抗扫频干扰方案;干扰卫星虽然仍执行在线扫频干扰,但也开始基于Q-Learning进行在线训练。
第10个迭代周期内,干扰方切换干扰策略,开始执行基于热启动的Q-Learning干扰;可以观察到,此时,干扰平均准确率由0%陡然提升至95%左右,这说明“热启动模块”中在线训练的干扰策略可以精准干扰抗扫频卫星用户,验证了所提算法的优越性。
然而,在10-20迭代周期范围内,干扰平均准确率逐渐降低;这是由于信道数目对于卫星用户是有优势的,用户只需要在6个信道中,躲避一个干扰信道即可正常通信;此外,由于Q-Learning的抗干扰卫星用户具有实时学习能力,卫星用户发现抗扫频策略效果不佳,因此,开始寻找新的抗干扰策略。
在20-25迭代周期内,为了避免卫星用户找到新的抗干扰策略,干扰方再次切换为扫频干扰,“牵引”卫星用户再次落入扫频“陷阱”,从而推动下一回合的对抗。
对比图9和图10,平均用户吞吐量的变化趋势印证了干扰平均准确率的曲线走向,从物理意义的角度,再次验证了干扰准确率对用户吞吐量的决定性作用;此外,相比于其他干扰策略,可以观察到所提方法下(所提干扰vs基于Q-Learning抗干扰曲线)用户表现出更低的平均吞吐量,体现了所提算法的优越性。
图11对比了一个对抗回合不同干扰策略的干扰平均准确率和平均用户吞吐量,从图11中可以看出,相比于其他两种干扰样式,本发明所提方法具有更高的干扰准确率和更低的用户吞吐量;准确的来说,相比于单一扫频干扰,本发明所提干扰策略的干扰平均准确率高出37.4%,用户吞吐量降低0.264Mb/s;相比于基于Q-Learning干扰策略,本发明所提方法的干扰平均准确率高出29.5%,用户吞吐量降低0.206Mb/s。
本发明研究了诱骗干扰信道选择问题,首先,考虑伴星干扰场景,分析了天基干扰的可行性;其次,受到雷达拖引干扰启发,构建了电磁陷阱诱骗干扰框架,通过设置诱骗模块、热启动模块以及反智模块,形成干扰闭环,实现“诱骗反智”的作战效果;随后,基于强化学习,设计了一种电磁陷阱干扰算法;最后,从收敛性和干扰性能两个角度仿真分析对抗过程,得出如下结论:
相比于单一扫频干扰,本发明所提干扰策略的干扰平均准确率高出37.4%,用户吞吐量降低0.264Mb/s;相比于基于Q-Learning干扰策略,本发明所提算法下的干扰平均准确率高出29.5%,用户吞吐量降低0.206Mb/s。
实施例二
如图12所示,本发明的一个实施例提供了一种基于电磁陷阱的自适应卫星通信干扰系统,包括对抗场景构设模块、天基干扰优化模型构建模块、基于电磁陷阱的干扰策略构建模块和干扰模块;
所述对抗场景构设模块用于构设伴星干扰对抗场景;
所述天基干扰优化模型构建模块用于基于所述伴星干扰对抗场景构建天基干扰优化模型;
所述基于电磁陷阱的干扰策略构建模块用于基于所述天基干扰优化模型构建电磁陷阱诱骗干扰框架,所述电磁陷阱诱骗干扰框架包括诱骗模块、热启动模块和反智模块;基于强化学习算法实现所述诱骗模块、热启动模块和反智模块,以获得基于电磁陷阱的干扰策略;
所述干扰模块用于基于所述基于电磁陷阱的诱骗干扰策略进行干扰。
在本申请所提供的实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。