用于为文本数据匿名化生成参考数据结构的方法和系统
文献发布时间:2023-06-19 18:35:48
相关申请案的交叉引用
本申请要求于2020年6月26日提交的发明名称为“用于为文本数据匿名化生成参考数据结构的方法和系统”的美国专利申请序列号16/913,711的优先权,该美国专利申请的内容通过引用全部并入本文。
技术领域
本发明涉及生成参考数据结构的方法和系统,具体地涉及生成用于文本数据匿名化的参考数据结构的方法和系统。
背景技术
随着技术的出现,所有学科的数据生成都以前所未有的速度增长。至少随着数据量的迅速增加而带来的主要挑战之一是提供数据隐私。数据匿名化是可用于保护隐私和确保防止个人身份或其敏感信息泄露的技术之一。
用于实现数据匿名化的方法之一是K匿名模型,广义上讲,它是一种泛化技术,用于描述匿名的数据集级别。K匿名模型假设给定数据集中的记录可以是结构化格式,以表的形式排列,其中行表示单个记录,列包含每个记录的属性。匿名化的过程涉及用不太具体的广义术语替换作为特定标识符的属性值。因此,K匿名模型的主要目标是转换数据集,使得记录与其对应实体之间的关联不能以大于1/K的概率确定(K是记录的数量)。为此,任何K匿名模型都要求将数据集中的记录划分为簇集,簇集中的每个簇至少包含K个记录,以便每个记录至少与(K–1)个其它记录无区分。为了提高数据质量,还期望给定簇中的记录也应尽可能彼此相似。当簇中的记录被修改为具有相同的广义词语时,这将有助于减少数据失真。
一些属性,例如那些包含数值的属性,可以很容易地泛化为数值区间。其它属性,例如那些具有基于文本的值的属性,则更难泛化。通常,当将K匿名应用于包含基于文本的属性的数据集时,部分或所有属性的文本值将被泛化并替换为类似的值,例如,语义一致但不太具体。
但是,过度泛化可能会加剧数据失真。可用于增强K匿名实现的技术之一是从数据生成参考数据结构,例如分类层次树。该参考数据结构可以将相似的实体聚类在一起,方式为使得一个簇中的实体彼此之间比其它簇中的其它实体更相似。更重要的是,参考数据结构中的每个簇都可以用一个广义词语来标识,该词语也可以作为一个有意义的名称来表示整个簇,并且可以用于替换同一簇的任何成员。然后,相同参考数据结构级别的簇的广义词语可以进一步泛化到更高级别,从而有助于减少数据失真。
目前,K匿名模型的参考数据结构通常是手动生成的,这是一项耗时的任务。每个新领域都需要不同的参考数据结构,需要每个领域的丰富专业知识来生成所需的广义词语。用于不同领域的预制参考数据结构可能需要与数据集一起提供,这增加了数据大小。
此外,还需要十分了解关于词分类以及词和短语的语义含义。为文本数据生成预先存在的参考数据结构的一个重大挑战是对具有多个上下文相关含义的词进行分组。
因此,需要一种改进的K匿名参考数据结构生成方法和系统。
发明内容
在各种示例中,在至少一个方面中,本发明描述了用于为基于文本的数据自动生成K匿名参考数据结构的方法。所公开的方法可以利用机器学习技术生成矢量空间,所述矢量空间可用于将输入文本数据转换为数值,并自动聚类类似的数据记录,并生成参考数据结构,该参考数据结构具有针对每个簇的有意义的标识符,其中,所述标识符可以在语义上表示簇。
在另一方面中,本文公开的方法可以自动生成K匿名参考数据结构,并不限于英语,并且可以能够支持多种语言的基于文本的数据。
在又一个方面中,自动生成数据的参考数据结构的方法可以节省处理成本和/或无需密集的人力劳动。具体来说,本文公开的方法可以不需要手动创建参考数据结构所要求的时间密集型手动劳动。此外,与现有技术相比,根据本发明的自动生成的参考数据结构也可以在较短的时间内更新(例如,以反映更新的文本语料库)。
在又一个方面中,通过在任何给定的文本上下文上重新训练矢量空间(表示文本序列的潜在代码空间),新的或附加信息(例如,文本序列的新语义含义)可以相对容易地在更新的参考数据结构中表示。
在另一方面中,根据本发明生成的参考数据结构可以根据需要生成,而不需要将额外的文件提供到使用K匿名进行匿名化的客户端。
在另一方面中,根据本发明的方法可以基于输入文本数据生成参考数据结构,而不需要为不同语义上下文创建大的参考数据结构。这可以使得参考数据结构的大小能够减小(与现有技术相比),这可以用于增强其搜索能力(例如,需要更少的处理资源来执行参考数据的搜索)。
在另一方面中,本发明涉及一种用于为包括多个输入文本词的输入文本数据生成参考数据结构的方法。所述方法包括:从包括多个参考文本词的参考文本数据生成矢量空间,其中,所述矢量空间由表示所述参考文本词的语义含义的数值矢量定义;使用所述矢量空间将所述多个输入文本词转换为相应的数值矢量;根据所述输入文本词之间的语义相似性将所述多个输入文本词形成词簇,所述词簇定义所述参考数据结构的相应节点,输入文本词对之间的语义相似性由从相应的数值矢量对确定的相应度量值表示,所述度量值用于确定是否满足聚类准则;将文本标签应用于所述参考数据结构的每个节点,所述文本标签表示所述词簇的元素共享的语义含义;存储所述参考数据结构。
在上述任一项中,所述方法可以包括,对于所述输入文本数据的每个给定词,用所述给定词所属的词簇的文本标签替换所述给定词。
在上述任一项中,所述度量值可以是欧氏距离、平方欧氏距离、曼哈顿距离、最大距离和马氏距离中的一个。
在上述任一项中,所述将所述输入文本数据的所述多个词形成词簇可以包括:初始化所述词簇,使得从所述输入文本数据的所述多个词转换的多个根词中的每个根词形成所述词簇中的每个词簇的元素;迭代地形成所述词簇,每次迭代包括:基于词簇对中的每个词簇的数值矢量,确定所述每个词簇对之间的度量值;当从所述词簇中的两个词簇确定的度量值满足聚类准则时,将所述两个词簇合并为单个词簇。
在上述任一项中,所述将所述输入文本数据的所述多个词形成词簇可以包括:初始化包括从所述输入文本数据的所述多个词生成的所有根词的单个词簇,所述单个词簇被定义为父簇;迭代地形成所述词簇,每次迭代包括:通过应用扁平聚类算法从所述父簇中识别潜在词簇;将所述潜在词簇中的一个潜在词簇从所述父簇中分离,以形成新的词簇。
在上述任一项中,所述聚类准则可以是以下中的一个:最大链接聚类、最小聚类、非权重平均链接聚类、加权平均链接聚类、最小能量聚类、所有簇内方差之和、Ward准则、V-链接、图度链接和某一簇描述符的增量。
在上述任一项中,所述文本标签可以是所述词簇的所述元素的公共下位词。
在上述任一项中,所述输入文本数据可以是第一语言,所述方法可以包括:将所述输入文本数据中的词从所述第一语言翻译为第二语言;使用所述翻译后的所述第二语言的词确定所述第二语言的公共下位词;将所述第二语言的所述公共下位词翻译为所述第一语言,所述翻译后的所述第一语言的词语用作所述词簇的所述文本标签。
在上述任一项中,所述生成所述矢量空间可以包括:收集文档语料库,以形成所述参考文本数据;将所述参考文本数据的所述多个词转换为根词;将所述根词映射到所述数值矢量。
在上述任一项中,所述将所述参考文本数据的所述多个词转换为根词可以包括:格式化所述参考文本数据的所述多个词,以删除对所述参考文本词的所述语义含义无用的数据;将所述格式化后的多个词分离为符号(token);将所述符号归一化为根词。
在上述任一项中,所述将所述符号归一化为根词可以包括以下中的至少一个:从所述符号截断词缀;将所述符号转换为基本形式。
在一些方面中,本发明描述了一种系统,所述系统包括:处理单元,用于执行指令以使得所述系统执行本文描述的任一方法。
在一些方面中,本发明描述了一种计算机可读介质,所述计算机可读介质有形地存储有指令。所述指令当由系统的处理单元执行时,使所述系统执行本文描述的任一方法。
附图说明
现在将通过示例参考示出本申请示例性实施例的附图,在附图中:
图1示出了可用于实现本文公开的方法和系统的示例性处理系统的框图;
图2示出了本发明的一个方面提供的用于为数据匿名化生成参考数据结构的示例性方法的流程图;
图3示出了图2中步骤110的示例的流程图;
图4示出了图3中步骤114的示例的流程图;
图5示出了可在图2中的步骤130实现的凝聚方法的流程图;
图6示出了可在图2中的步骤130实现的除法方法的流程图;
图7示出了包含示例性矢量距离确定方法的表;
图8示出了包含示例性聚类准则的表;
图9以二叉树的形式示出了本发明提供的未标记参考数据结构的树状图。
在不同的附图中可以使用相似的附图标记来表示相似的组件。
具体实施方式
为了帮助理解本文讨论的示例,首先描述示例性处理系统。处理系统可以实施为工作站、服务器或其它合适的计算系统。
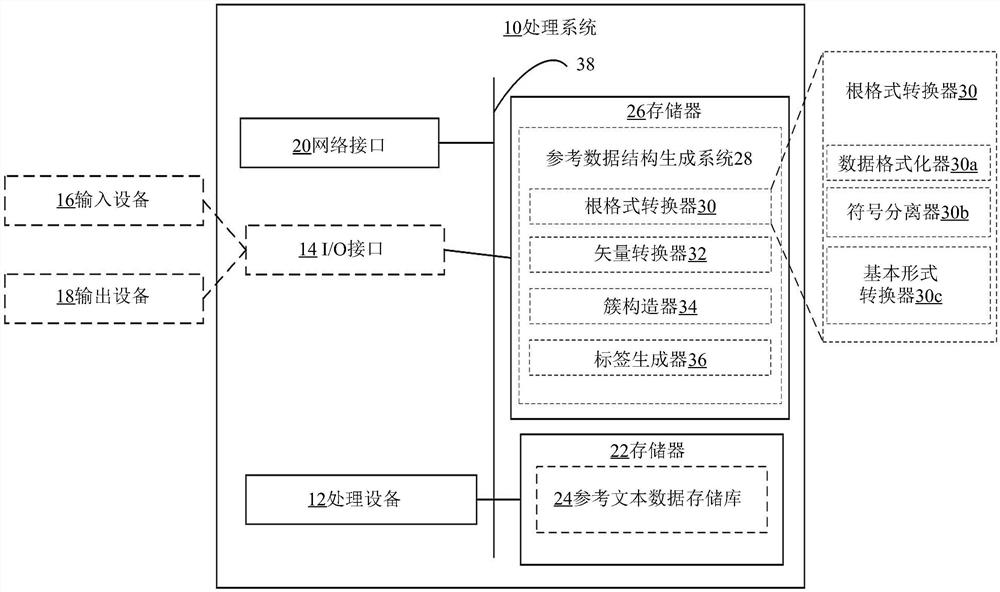
图1是可用于实现本文公开的实施例的示例性处理系统10的简化框图。其它处理单元可以适合于实现本发明中描述的实施例,并且可以包括与下面讨论的那些组件不同的组件。尽管图1示出了每个组件的单个实例,但在处理系统10中可以存在每个组件的多个实例。
处理系统10可以包括一个或多个处理设备12(也称为处理单元),例如处理器、微处理器、图形处理单元(graphics processing unit,GPU)、张量处理单元(tensorprocessing unit,TPU)、专用集成电路(application-specific integrated circuit,ASIC)、现场可编程门阵列(field-programmable gate array,FPGA)、专用逻辑电路或其组合。处理系统10可以可选地包括一个或多个输入/输出(input/output,I/O)接口14,以支持与一个或多个可选的输入设备16和/或输出设备18连接。处理系统10可以包括一个或多个网络接口20,用于与通信网络(未示出)进行有线或无线通信或与其它处理系统进行对等通信。一个或多个网络接口20可以包括用于进行内网通信和/或网外通信的有线链路(例如以太网线)和/或无线链路(例如一个或多个天线)。
处理系统10还可以包括一个或多个存储单元22,所述一个或多个存储单元22可以包括大容量存储单元,例如固态驱动器、硬盘驱动器、磁盘驱动器和/或光盘驱动器。在一些示例性实施例中,一个或多个存储单元22可以包括用于存储参考输入数据的参考文本数据存储库24,如下面进一步详细描述。尽管图1示出了包括参考文本数据存储库24的一个或多个存储单元22,但在替代实施例中,参考文本数据存储库24可以包括在一个或多个远程存储单元中,所述一个或多个远程存储单元可以通过无线或有线通信网络远程访问。参考文本数据的详细信息将在下文进一步讨论。
处理系统10可以包括一个或多个非瞬时性存储器26,所述一个或多个非瞬时性存储器26可以包括易失性或非易失性存储器(例如,闪存、随机存取存储器(random accessmemory,RAM)和/或只读存储器(read-only memory,ROM))。一个或多个非瞬时性存储器26可以存储由一个或多个处理设备12执行的指令,例如,以执行本发明中描述的示例性方法。一个或多个存储器26可以存储其它软件(例如,用于由一个或多个处理设备12执行的指令),例如操作系统和其它应用/功能。在一些实施例中,一个或多个数据集和/或模块可以由外部存储器(例如,与处理系统10进行有线通信或无线通信的外部驱动器)提供,也可以由瞬时性或非瞬时性计算机可读介质提供。非瞬时性计算机可读介质的示例包括RAM、ROM、可擦除可编程ROM(erasable programmable ROM,EPROM)、电可擦除可编程ROM(electrically erasable programmable ROM,EEPROM)、闪存、CD-ROM或其它便携式存储器。在一个实施例中,一个或多个存储器26存储参考数据结构生成系统28,所述参考数据结构生成系统28是包括存储在一个或多个存储器26中并可由处理设备12执行的机器可读指令的软件系统。参考数据结构生成系统28可以包括根格式转换器30、矢量转换器32、簇构造器34和标签生成器36,它们是系统28的软件单元(或软件子系统)。矢量转换器32可以是基于机器学习的软件单元,所述基于机器学习的软件单元实现将文本数据转换为数值矢量的学习模型,如下面进一步详细描述。在其它实施例中,矢量转换器32可以实现将文本数据转换为数值矢量的算法。在一些实施例中,系统28可以实现为单个硬件设备,例如专用集成电路(application specific integrated circuit,ASIC)、现场可编程门阵列(fieldprogrammable gate array,FPGA)或片上系统(system on a chip,SoC)。硬件设备包括执行单元30、32、34、36的功能的电子电路。在其它示例性实施例中,系统28可以实现为多个硬件设备(例如,多个ASIC、FPGA和/或SoC)。每个硬件设备包括执行单元30、32、34、36中的一个的功能的电子电路。根格式转换器30、矢量转换器32、簇构造器34和标签生成器36的细节将在下文进一步讨论。应当理解,单元30、32、34、36不一定是系统28的单独单元,并且将30、32、34、36作为系统28内的单独块的图示可能只是系统28的整体操作的概念表示。
可以存在总线38,在处理系统10的组件之间提供通信,所述组件包括一个或多个处理设备12、一个或多个可选I/O接口14、一个或多个网络接口20、一个或多个存储单元22和/或一个或多个存储器26。总线38可以是任何合适的总线架构,例如包括存储器总线、外围总线或视频总线。
在图1中,一个或多个输入设备16(例如,键盘、鼠标、麦克风、集成到显示设备中的触摸屏,可以包括UI和/或小键盘)和一个或多个可选输出设备18(例如,可以包括UI、扬声器和/或打印机的显示设备)示出为在处理系统10的外部。在其它示例中,一个或多个输入设备16和/或一个或多个输出设备18中的一个或多个可以是处理系统10的内部组件。一个或多个输入设备16可以包括具有显示屏的显示设备和用于使用户与显示设备显示的项目交互的用户界面(user interface,UI)导航设备(例如触摸屏输入、鼠标或手持控制器)。一个或多个输出设备18还可以包括具有显示屏的显示设备和用于显示本文公开的方法的生成结果的用户界面(user interface,UI)导航设备。
图2是示例性方法100的流程图,该方法可以由本发明的参考数据结构生成系统28执行,以用于为数据匿名化生成参考数据结构。具体地,方法100可用于自动生成文本输入数据的K匿名模型的参考数据结构。
在步骤110中,从包括多个文本词的参考文本数据生成矢量空间。图3是示出可以作为执行步骤110的一部分执行的示例性步骤的流程图。具体地,在步骤112中,可以收集文档语料库以形成参考文本数据。通常,参考文本数据可以包括可能包含标点符号、符号和大/小写字母的非结构化文本。在一些实施例中,参考文本数据可以包括从不同领域收集的词,这可以更全面地涵盖给定语言的词的词汇语义含义。参考文本数据包含多个词中的每个词的上下文信息。作为非限制性示例,对于参考文本数据的给定词,其周围词或上下文词可以提供上下文信息,例如给定词的语义含义。语义一致性、词汇覆盖率和参考文本数据通用性等因素也可能影响矢量转换步骤的准确性,如下文更详细地讨论。
在一些实施例中,参考文本数据可以通过网络接口20从第三方源收集,或者由输入设备16通过I/O接口14输入。所收集的参考文本数据可以存储在一个或多个存储单元22的参考文本数据存储库24中,以便易于由各种系统组件通过总线38访问。应当理解,参考文本数据可以通过一个或多个上述方法或任何其它合适的方法获得。
在步骤114中,根格式转换器30将来自参考文本数据的多个词转换为根词。
图4示出了可以作为执行示例性步骤114的一部分执行的示例性步骤的流程图。在所示的实施例中,转换步骤114还可以包括以下步骤:通过数据格式化器30a格式化数据114a;通过符号分离器30b将格式化数据分离为符号114b;通过基本形式转换器30c将符号转换为基本形式。
在所示的实施例中,在格式化数据步骤114a中,删除包含在参考文本数据中的可能对词或短语的语义含义无用的无关元素,并且归一化非结构化文本的格式化。例如,步骤114a可以包括删除HTML标记和URL、额外的空白字符、特殊字符(例如,“$”和“%”)和标点符号,将重音字符转换为非重音字符(例如,“café”到“cafe”),扩展收缩字符(例如,“don’t”到“do not”),使所有文本小写,和/或将数字词转换为数字形式或删除数字。格式化数据步骤122还可以包括删除停用词,停用词是对词或短语的语义含义作用不大的通用词或普通词。例如,包括“the(所述)”和“a(一)”的词通常对文本内容的语义含义没有很大作用。应当理解,其它适当的步骤可以在格式化数据步骤114a中实现。
在符号分离步骤114b中,根据分段策略,将来自步骤114a的格式化参考文本数据分离或分段成较小的片段或“符号”。可以采用各种分段策略来定义符号之间的边界。通过非限制性示例,分段边界可以定义为非字母数字字符、空白字符和/或标点符号。在其它实施例中,分段边界可以由字符熵的变化定义,所述字符熵确定字符之间所有发生转换的条件概率,以进一步确定可能的下一个邻居的数量,以及给定每个连续字符可以用作边界,超过阈值的概率的减少。在一些其它实施例中,可以使用手动创建的符号边界定义列表。应当理解,定义符号边界的其它分段策略可以是可能的。分段边界可以取决于参考文本数据的语言。例如,空白字符可以作为英语等语言的合适分段边界,但它可能不适合东亚语言,因为东亚语言中的字符之间没有空格。
在符号分离步骤114b之后,可以在步骤114c中对符号进行归一化,以将分离的符号转换为根格式,使得在字符序列中具有表面差异的两个符号,或具有相似含义的派生相关词的族(例如,“studying”、“studies”,“studied”)可以与相同的根词(例如,“study”)匹配。
归一化步骤114c可以包括词截断步骤115a,其中,每个符号可以进一步截断以删除词缀(例如,后缀、前缀、中缀、外缀),以得到符号的截断版本,或本领域已知的“词干”。在一些实施例中,词截断步骤115a(在本领域中也被称为“词干提取”)由基本形式转换器30c通过启发式过程来实现,该启发式过程简单地去除词结尾,并且通常包括去除派生词缀。例如,词“depression”和“depressed”可以通过分别截断后缀“ion”和“ed”而转换为词“depress”。可用于实现词截断步骤115a的其它可能算法包括Porter词干提取算法、Lancaster词干提取算法、单通Lovins词干提取算法和Paice/Husk词干提取算法等。
符号归一化步骤114c还可以包括基本形式转换步骤115b,其中,作为词的屈折或共轭形式的每个符号可以转换为基本形式或规范形式,所述基本形式或规范形式被定义为用于词典输入的最简单形式。这种基本形式也被称为“引理”。例如,词“better”可以返回其基本形式的词“good”。步骤115b的算法通常依赖于基于规则的方法,其中,可以根据特定语言手动定义基本形式转换规则,或者可以使用机器学习方法学习规则。现有的基本形式转换算法或引理器包括NLTK引理器、Wordnet引理器、Spacy引理器、TextBlob、CLiPS模式、Stanford CoreNLP、Gensim引理器和TreeTagger等可用于实现步骤115b。
在一些实施例中,词截断步骤115a可能需要更少的计算资源和更少的执行时间,因为其截断符号词的词缀的方法相对简单。但是,在某些情况下,结果可能不太准确。例如,在进行词截断步骤115a之后,词“better”可能变为“bett”,这并不能准确地反映原始词的词汇含义。相反,基本形式转换步骤115b可以为词“better”产生更准确的归一化形式“good”。但是,提高步骤115b的准确度可能以牺牲计算资源和执行时间为代价。因此,应当理解,步骤115a和115b可以根据例如计算资源限制或执行时间约束在归一化步骤115中相互独立或结合使用。
在符号归一化步骤115之后,将来自参考文本数据的符号转换为根词,所述根词又在步骤116中由矢量转换器32映射到数值矢量。词的矢量值可以指示词与其它词的语义含义。度量值是两个矢量之间矢量接近度的度量,其中,矢量接近度表示生成数值矢量的词之间的语义关系。语义关系可以定义为词、短语或句子的含义之间存在的关联。例如,具有相似含义的同义词可以被称为语义相似,反之亦然,具有不同含义的反义词可以被称为语义不同。如更详细地讨论,训练每个矢量的数值,以基于参考文本数据中呈现的给定词的上下文信息,反映给定词的语义含义。将词映射到实值数值矢量的一类技术也被称为词嵌入。优选地,具有相似语义含义的词用相似的数值矢量表示。
数值矢量的维度大小为(n),所有数值矢量共同定义了矢量空间。每个矢量的维度大小可能会影响捕获根词语义含义的能力。如果每个词和词的每个部分都用矢量的数值表示,则对于具有大量词的词汇表,将需要高维矢量。给定词可以映射到的结果矢量将主要由零组成,在与给定词对应的索引处只有一个非零条目(值1)。这是稀疏表示的一个示例,称为独热编码。在本发明的一些实施例中,每个数值矢量是n维的密集矢量,其中,n小于其对应的独热编码维度的维度。密集矢量可以包括浮点值,所述浮点值可以指示特定词的语义含义。较高的维度大小n可能能够以计算效率为代价更好地捕获词的语义含义。反之亦然,较低的维度大小n可以提供计算效率,但在捕获语义含义方面可能不太有效。维度大小n可以在训练期间设置为参数。
在步骤116中,矢量转换器32可以实现各种方法,用于将根词映射到数值矢量。在一些实施例中,步骤116可以通过机器学习方法执行。
在一些实施例中,矢量转换器32的步骤116的执行可以使用word2vec算法实现,该算法使用浅层2层神经网络将离散对象(词)映射到n维实数特征矢量,其方式是使具有相似语义含义是类似表示的特征矢量。应当理解,将词映射到数值矢量的其它算法,如全局矢量(Global Vector,GloVe)、doc2vec等,也是可能的。
在word2vec的情况下,word2vec不是通过重建针对输入词进行训练,而是针对在提供目标输入词上下文信息的参考文本数据中与词相邻的其它词对词进行训练。训练模型可以以两种方式中的一个实现,即连续词袋(continuous bag of words,CBOW)模型,或skip-gram模型。连续词袋(continuous bag of words,CBOW)模型可能适合于更快的模型训练,并为更频繁出现的词提供更好的表示。连续skip-gram模型可以很好地处理少量的训练数据,并改进了稀有词或短语的表示。
CBOW模型架构试图从提供目标词上下文信息的源上下文词或周围词预测当前目标词(中心词)。应当理解,要考虑的上下文大小可以变化。具体地,CBOW模型的目的是最大化下面的等式(1),其中,wt是待从提供关于目标词wt的上下文信息的周围上下文词wt–1、wt–2、……、wt–c和wt+1、wt+2、……、wt+c预测的词。变量|V|表示参考文本数据中根词的总数,c是上下文大小。例如,对于c值4,考虑了目标词wt之前的4个词和之后的4个词。
等式(1)
CBOW模型使用上下文词作为输入,并以使用随机权重值初始化的权重矩阵的形式传递到嵌入层。嵌入层为传递到λ层的上下文词生成特征矢量,在该λ层中,对特征矢量进行求和和平均,以形成单个平均上下文矢量。然后,该平均上下文矢量可以被传递到密集的softmax层,以对目标词进行预测。softmax层本质上实现了softmax函数,该softmax函数将K个实数矢量作为输入,并将其归一化为由与输入数的指数成比例的K个概率组成的概率分布。然后将预测与实际目标词t进行比较,以计算损失或误差,该损失或误差被反向传播,以更新嵌入层的权重值。
或者,skip-gram模型试图通过尝试预测给定目标词的上下文词(周围词)来实现CBOW模型的相反效果。skip-gram模型的目的是最大化下面的等式(2),其中,|V|是参考文本数据中根词的总数,c是上下文大小。
等式(2)
在一些实施例中,使用skip-gram模型预测上下文词的任务可以简化为由目标词和上下文词组成的词对。词对和相关性指示符是skip-gram模型的输入。相关性指示符表示目标词与上下文词之间的相关性。例如,上下文指示符值“1”表示语义相似的对,值“0”表示两个词之间的语义不同。将每个词对连同相关性指示符以用随机权重值初始化的权重矩阵的形式传递到对应的嵌入层。然后,嵌入层为目标词和上下文词生成数字特征矢量,然后将数字特征矢量传递到合并层,在合并层中,确定这两个矢量的点积。然后,将该点积值传递到密集的sigmoid层,该sigmoid层根据这两个词是上下文相关的还是只是随机词来预测1或0。将相关性预测与实际相关性指示符值进行比较,以计算损失或误差,该损失或误差被反向传播,以更新嵌入层的权重值。
在完成后,具有嵌入权重矩阵形式的更新权重值的嵌入层可用于数值矢量转换。在一些实施例中,根词与对应的行标识符一起存储,其中,行标识符标识嵌入权重矩阵的行,其中,列值或更新的权重值是其对应的数值矢量的数值。
在本发明的一些实施例中,可以采用连续skip-gram模型的扩展,在训练期间对频繁出现的词进行子采样。在一些其它实施例中,步骤116还可以采用噪声对比估计来训练skip-gram模型,这可以产生更快的训练和更准确的矢量表示。
在一些实施例中,可以采用词频(term frequency,TF)和逆文档频率(inversedocument frequency,IDF)(term frequency-inverse document frequency,TF-IDF)加权算法,其中,IDF因子的功能是消除或最小化命题等常用词的影响,以使TF因子更准确地表示正在处理的文档的主题。
应当理解,通过返回步骤112以获得额外的参考文本数据,可以多次应用训练过程。
在一些实施例中,步骤116还可以包括降维等子步骤,以进一步增强方法100的性能,以获得更准确的根词表示。具体地,如上所述,高维矢量的分析可能是耗时和计算资源密集型的。因此,可能希望减小矢量的维度,同时保留尽可能多的有意义的信息。降维的其它优点可能包括减少数据存储所需的空间和缩短计算/训练时间。此外,通过降维,可以更容易地以图形方式可视化或显示数据。一种可能的降维算法是t-分布随机近邻嵌入(t-distributed stochastic neighbor embedding,t-SNE)算法。t-SNE算法首先在数值矢量等高维对象对上构建概率分布,其方式使相似对象被挑选的概率很高,而不同点具有被挑选的概率极低。然后,t-SNE算法在低维地图中的点上定义了相似的概率分布,并将两个分布之间关于点位置的Kullback–Leibler散度(KL散度)最小化。其它一些合适的降维算法可以包括潜在语义分析(latent semantic analysis,LSA)和一致流形估计和映射(uniformmanifold approximation and projection,UMAP)等。
步骤116的其它子步骤可以包括类比推理(或评估嵌入)。
回到图2,在步骤120中,使用从参考文本数据生成的矢量空间,将包括多个词的输入文本数据转换为数值矢量。具体地,由参考数据结构生成系统28接收包括多个词的输入文本数据。输入文本数据可以是结构化数据格式,例如具有多个列的表或数据集,其中一个或多个列包含待匿名化的数据值。需要匿名化的每个列可以由多个行组成。
基于从步骤110导出的矢量空间,将从输入文本数据匿名化的多个词中的一个或多个转换为数值矢量。在进行数值矢量转换之前,将待从输入文本数据匿名化的词首先转换为根词。在一些实施例中,可以使用相同的步骤114(即使用如图4所示的相同的步骤114a至114c)将来自输入文本数据的词转换为根词,使得可以将来自输入文本数据的相同词转换为与用于生成矢量空间的参考文本数据的词相同的根词。因此,给定输入文本数据根词的数值矢量可以通过搜索在嵌入权重矩阵中查找根词来获得。作为非限制性示例,可能已经将来自参考文本数据的词“better”转换为根词“good”,然后可以将该根词“good”映射到对应的数值矢量,例如[0.1,0.23,0.45,0.78,0.05],该数值矢量可以是嵌入权重矩阵中的行50。根词“good”可以用行标识符50存储。然后,通过将相同的步骤120应用于输入文本数据,输入文本数据中出现的词“better”也可以转换为根词“good”。然后,矢量转换器32可以简单地查找根词“good”的条目,并检索与根词一起存储的行标识符。使用行标识符,即50,根词“good”的数值矢量可以从嵌入权重矩阵的行50中检索,并用于将词来自输入文本数据的“better”转换为其对应的数值矢量[0.1,0.23,0.45,0.78,0.05]。在一些实施例中,输入文本数据可以包含在参考文本数据中没有遇到的词或短语,或词汇表外的词。在这种情况下,搜索词汇表外的词的根词可能不会从嵌入权重矩阵中返回对应的数值矢量。有许多合适的方法来处理词汇表外的词,包括返回零矢量,或使用子词信息(例如字符n-gram)生成对应的矢量。
在已经将输入文本数据的根词转换为数值矢量后,在步骤130中,来自输入文本数据的根词被簇构造器34迭代地和分层地形成为词簇。具体地,基于满足聚类准则设置的相似性条件的代表矢量的度量值形成词簇,其中,每个词簇定义了参考数据结构的节点。代表矢量可能取决于聚类准则。词簇的形成可以用“自下而上”的方法或凝聚聚类方法来实现,其中,输入文本数据的每个词从其自己的词簇中开始,并以分层的方式迭代合并在一起,直到出现单个簇。或者,分组可以用“自上而下”方法或分裂聚类方法来实现,其中,输入文本数据的所有根词都从单个词簇开始,并递归地分割成较小的词簇,直到例如每个词簇包括K匿名模型可能需要的至少K个根词。
图5示出了可以在步骤130中实现的分组的凝聚方法250的流程图。
在步骤252期间,初始化N个词簇,使得输入文本数据的N个根词中的每一个形成唯一词簇的元素。
在步骤254中,确定N个词簇中的两个词簇的数值矢量之间的度量值,如下文更详细地描述。度量值可以表示两个词簇之间的语义相似性。
在步骤256中,当两个簇的代表矢量的度量值满足聚类准则时,N个词簇中的两个词簇可以被认为彼此最接近。代表矢量可以由聚类准则决定。因此,两个最接近的词簇被合并以形成新的词簇。
迭代地重复步骤254和步骤256,直到在步骤258中在参考数据结构的顶部出现单个词簇。
图6示出了可在步骤130实现的用于形成词簇的分裂聚类方法350的流程图。在步骤352中,输入文本数据的所有根词被初始化以形成单个词簇。在步骤354中,可以应用扁平聚类算法来识别潜在词簇。通过非限制性示例,可以实现K均值扁平聚类算法,其中,K是期望聚类的数量。K均值扁平聚类算法的目的是最小化数据点与其分配的质心之间的度量值,如平均平方差。该算法首先将K个质心随机分配给父簇。根据到每个质心的矢量距离,分配最接近质心的数据点,或者在这种情况下,分配根词。然后,将每个质心重新计算为在重新分配时分配给质心的矢量的平均值。迭代地重复该过程,直到满足停止条件。在完成步骤354时,将识别K个潜在簇的K个质心。在步骤356中,基于聚类准则从K个潜在簇中选择最佳潜在词簇,并从父簇中分离,例如通过在新形成的簇与父簇之间形成链接。每个词簇定义了参考数据结构中的一个节点。迭代地重复步骤354和356,直到在步骤358中实现了完成准则,例如每个簇仅包括单个元素或多个期望簇。
在一些实施例中,分裂聚类方法350相对于凝聚聚类方法250可能更复杂,因为分裂聚类方法350需要扁平聚类方法。但是,在不完整的参考数据结构并不一直延伸到单个数据叶子的情况下,分裂聚类可能更高效。凝聚聚类的时间复杂度为O(n
如上所述,用于步骤130的度量值指示矢量接近度,该矢量接近度表示词之间的语义相似性。多个度量值可以适合作为数值矢量接近度的指示符,进而指示词簇之间的语义相似性。
图7示出了包含可用于步骤130的一些度量值的表700。
度量值包括欧氏距离702a,该欧氏距离702a用于计算欧几里德空间中两个点之间的直线距离。作为一个说明性示例,对于维度大小为i的矢量a和b,这两个点之间的距离可以用公式702b确定,如下所示:
平方欧氏距离704a(可以是步骤130中可以使用的另一个度量值)是使用类似于欧氏距离702b的等式704b但不取平方根确定的。因此,使用基于欧几里德平方距离度量进行聚类可能比使用常规欧氏距离进行聚类更快。
可能的度量值还可以包括曼哈顿距离706a,该曼哈顿距离706a以曼哈顿岛上大多数街道的网格状布局命名,这可能类似于计算从一个数据点到另一个数据点的距离,如果遵循网格状路径。两个项目之间的曼哈顿距离是它们对应的分量的差值之和,如公式706b所示。
可以在步骤130中使用的另一个可能的度量值是最大距离708a,该最大距离708a通过公式708b将两个矢量之间的距离确定为它们沿任何坐标维度的最大差值。
可以在步骤130中使用的另一个可能的度量值包括马氏距离710a,该马氏距离710a计算多元空间中两个点之间的距离。在常规欧几里德空间中,变量(例如,x、y、z)由彼此成直角绘制的轴表示。但是,如果两个或两个以上变量相关,则轴不再是直角。通过公式710b确定的马氏距离测量点之间的距离,即使对于具有多个变量的相关点也是如此。
应当理解,其它合适的度量值,例如汉明(Hamming)距离或莱文斯坦(Levenshtein)距离,也可以用于步骤130。
在确定了度量值之后,使用聚类准则基于在步骤254、步骤354中确定的度量值确定特定词簇的形成。更具体地,该准则将词簇之间的相似性确定为它们之间的成对度量的函数。例如,在每个步骤中,将由最短欧几里德矢量距离或任何其它度量值分隔的两个簇组合成一个词簇。“最短距离”的定义区分了不同凝聚聚类方法。
图8包含列出各种聚类准则的表800,除其它外,其中任何一个聚类准则都可以适合在步骤256中实现。聚类准则表示用于基于表示所讨论的词簇的矢量的度量值合并词簇的语义相似性条件,如下面关于每个准则更详细地讨论。
准则802a是最大或完全链接聚类准则。在完全链接聚类中,一个词簇的每个元素都链接到另一个词簇的对应元素,从而形成多个元素对。两个词簇之间的矢量距离被定义为等于代表矢量之间的距离,所述代表矢量是彼此最远或具有最长链接的元素对的矢量。在每次聚类迭代期间,链路最短的两个聚类被合并为一个词簇。在公式802b中,簇A与B之间的矢量距离定义为元素对a与b之间的矢量距离的最大值,其中,a和b分别是簇A和B的元素。矢量距离公式d可以是图7中所示的公式中的任何一个或矢量距离确定方法的其它合适方法。
准则804a是最小或单链接聚类准则,它将簇与其最近的相邻簇合并。准则804a可以能够生成最小跨度层次结构树。也被称为单链接聚类准则,该准则在给定的相似性(或距离)级别将一个簇与另一个簇分组,可能只需要将即将凝聚的两个簇中的每个簇在该级别上相互链接。在公式804b中,簇A与B之间的矢量距离定义为元素对a和b的矢量(代表矢量)之间的矢量距离的最小值,其中,a和b分别是簇A和B的元素。矢量距离公式d可以是图7中所示的公式中的任何一个或矢量距离确定方法的其它合适方法。
另一个准则是未加权平均链接聚类806a,也称为组平均排序或不加权算术平均组对方法(unweighted pair-group method using arithmetic,UPGMA)。该准则对原始相似性给予了相等的权重,它假设每组中的元素构成参考总体中对应的较大对象组的代表性样本。因此,如果将结果外推到较大的参考总体,则UPGMA聚类准则806a可能非常适合简单的随机或系统采样设计。UPGMA准则806a可以使对象以该对象与组的所有成员之间的距离的平均值加入组或簇。两个簇以一个组的所有成员与另一个组的所有成员之间的距离的平均值合并在一起。在公式806b中,通过簇A中的对象x与簇B中的对象y对之间的距离公式d确定的所有距离的平均值按簇大小|A|和|B|平均。
加权平均链接聚类准则808a可用于表示不同情况(因此可能形成不同组)的元素组由不相等数量的元素表示的情况。在这种情况下,当大簇和小簇发生融合时,上述未加权UPGMA准则806a可能被扭曲。在公式808b中,在每次合并迭代中,最近的两个簇(例如i和j)被合并为一个更高级别的簇i∪j。然后,它到另一个簇k的距离被定义为k和i以及k和j的所有成员之间的平均距离(如使用距离公式d所确定)的算术平均值。因此,簇i和j的所有成员的所有矢量都是代表矢量。
质心链接聚类准则810a,也被称为未加权质心聚类准则(unweighted centroidclustering criterion,UPGMC)是另一个可以采用的准则。在元素簇中,质心作为簇的代表矢量,是具有簇中所有对象的平均坐标的点。如公式810b中所示,UPGMC 810a确定它们的质心C
应当认识到,尽管表800列出了多个聚类准则,但还可以使用其它适当的聚类准则,例如所有簇内方差之和;被合并的簇的方差增量(Ward准则);候选簇从同一分布函数中产生的可能性(V-链接);k近邻图上的入度和出度的乘积(图度链接);在合并两个簇后一些簇描述符的增量(即,为测量簇质量而定义的量)。
在步骤130完成时,生成未标记的参考数据结构。图9示出了可以在步骤250之后通过使用欧氏距离702a和最小或单链接聚类准则804a生成的二叉树形式的示例性未标记参考数据结构900的树状图。多个词簇902(各自包括输入文本数据的根词中的一个)在最低层次级别形成二叉树的叶子节点。
为每个词簇对确定欧几里德矢量距离,作为度量值。词簇902a和902b(各自包括表示它们各自簇的单个词)被确定为具有最小欧氏距离,如树状图上的最低链接形成高度所证明。最小欧氏距离指示词簇902a和902b在所有词簇中语义最相似。因此,根据单链接聚类准则,词簇902a和902b被合并到词簇904a中。在方法步骤254、256的下一次迭代中,词簇902c和902d被确定为具有最小欧氏距离,并且根据单链接聚类准则合并到词簇904b中。重复迭代,直到出现单个词簇906。
如上所述,从步骤130生成的参考数据结构是未标记的。在步骤140中,标签生成器36为每个词簇生成标签。在一些实施例中,标签是文本标签,该文本标签表示由每个词簇的成员共享的语义含义中的相似性。
在一些实施例中,可以使用外部数据库(例如WordNet,一种可以生成英语形式的词的下义词的大型词汇数据库)来生成每个词簇的文本标签。多个基于WordNet的词相似性算法在被称为WordNet::Similarity的Perl包中和被称为NLTK的Python包中实现。其它更复杂的基于WordNet的相似性技术包括ADW,其实现在Java中可用。通过合并基于WordNet的编程包中的一个,给定词簇的根词可以用于生成根词的最低公共下位词。下义词可以用作词簇的文本标签。例如,根词“cat(猫)”和“tiger(老虎)”可以生成下位词“feline(猫科动物)”,它可以用作包括“cat(猫)”和“tiger(老虎)”的词簇的文本标签。然后,当词簇被合并为新词簇时,可以使用词簇的文本标签来表示词簇,以生成新词簇的文本标签。步骤160继续,直到所有词簇都被标记。
在本发明的一些实施例中,可以支持为除英语之外的第二语言的文本输入数据生成参考数据结构。作为非限制性示例,第二语言的输入文本数据用于使用相同的方法100生成参考数据结构。在完成步骤130后,第二语言的根词可以通过适当的翻译器、这种自动翻译算法或通过手动手段转换为英语。然后,翻译后的英语输入文本数据根词可用于生成下位词,所述下位词又可被翻译回第二语言,以用作词簇的文本标签。可以理解的是,在一些实施例中,翻译可以由能够提供第二语言的词的下位词的外部源(例如相当于WordNet)执行。
在步骤150中,标记的参考数据结构可以本地存储在计算机可读介质中,例如数据存储器22中,或者通过网络接口20远程存储在例如异地服务器或云数据库中。
在步骤160中,标记的参考数据结构可用于匿名化原始输入文本数据。如上所述,输入文本数据通常是结构化数据的形式,如表,其中,待匿名化的数据是表的某些列的行值。为了实现K匿名化,待匿名化的行值各自被来自参考数据结构的词簇标签替换,使得至少K个行值彼此无法区分。在一些实施例中,对于待匿名化的给定行值,基于行值遍历生成的参考数据结构,以定位包含至少K个根词的对应词簇。然后,可以使用所定位的词簇的文本标签来替换行值。步骤180将继续,直到所有待匿名化的值都被词簇标签替换,使得每个值与至少K个其它值无法区分。
尽管本发明通过按照一定的顺序执行的步骤描述方法和过程,但是可以适当地省略或改变方法和过程中的一个或多个步骤。在适当情况下,一个或多个步骤可以按所描述的顺序以外的顺序执行。
尽管本发明在方法方面至少部分地进行了描述,但本领域普通技术人员将理解,本发明也针对用于执行所述方法的至少一些方面和特征的各种组件,无论是通过硬件组件、软件还是其任意组合。相应地,本发明的技术方案可以通过软件产品的形式体现。合适的软件产品可以存储在预先记录的存储设备或其它类似的非易失性或非瞬时性计算机可读介质中,包括DVD、CD-ROM、USB闪存盘、可移动硬盘或其它存储介质等。软件产品包括有形地存储在其上的指令,所述指令使得处理设备(例如,个人计算机、服务器或网络设备)能够执行本文中公开的方法的示例。
在不脱离权利要求书的主题的前提下,本发明可以通过其它特定形式实现。所描述的示例性实施例在各方面都仅仅是示意性的,而不是限制性的。可以组合从一个或多个上述实施例中选择的特征,以创建非显式描述的可选实施例,在本发明的范围内可以理解适合于此类组合的特征。
还公开了公开范围内的所有值和子范围。此外,尽管本文所公开和显示的系统、设备和流程可包括特定数量的元素/组件,但可以修改所述系统、设备和组件,以包括此类元素/组件中的更多或更少的元素/组件。例如,尽管所公开的任何元件/组件可以引用为单个数量,但是可以修改本文所公开的实施例以包括多个此类元件/组件。本文所描述的主题旨在覆盖和涵盖所有适当的技术变更。
在本发明中识别的所有发表论文的内容通过引用的方式并入本文。
- 文本检索方法、用于文本检索的倒排表生成方法以及系统
- 用于针对在安全系统键区上显示的文本来定制和提供自动化语音提示的系统和方法
- 一种适用于区块链的海量数据摘要生成系统和方法
- 病历文本数据结构化的文本分词解析方法及系统
- 数据结构管理装置、数据结构管理系统、数据结构管理方法以及用于记录数据结构管理程序的计算机可读介质