在分解的架构中提供加速功能作为服务的技术
文献发布时间:2023-06-19 10:48:02
本申请是2018年8月30日提交的申请号为201811006541.X的同名专利申请的分案申请。
相关申请的交叉引用
本申请要求于2016年11月29日提交的美国临时专利申请第62/427,268号和于2017年8月30日提交的印度临时专利申请第201741030632号的权益。
背景技术
通常,在工作负载(例如,应用)被分配给计算设备以便代表客户执行的数据中心中(例如,在云数据中心中),加速器设备(如果有的话)在分配用于执行工作负载的通用处理器本地(例如,在相同的板上),并且只能提供固定类型的加速。这样,如果由通用处理器执行的特定应用不包括可以利用本地加速器设备的加速能力的功能或操作(例如,任务),则应用以非加速的速度执行并且本地加速器设备在应用执行期间未使用,导致资源浪费。
附图说明
在此描述的概念在附图中以示例而非限制的方式示出。为了说明的简单和清楚起见,图中所示的元件不一定按比例绘制。在认为合适的地方,附图标记已在图中重复以指示相应或类似的元件。
图1是根据各种实施例的其中可以实现本文描述的一种或多种技术的数据中心的概念性概述的图;
图2是图1的数据中心的机架的逻辑配置的示例实施例的图;
图3是根据各种实施例的其中可以实现本文描述的一种或多种技术的另一数据中心的示例实施例的图;
图4是根据各种实施例的其中可以实现本文描述的一种或多种技术的数据中心的另一示例实施例的图;
图5是表示可以在图1、图3和图4的数据中心的各种板(sled)之间建立的链路层连接的连接方案的图;
图6是根据一些实施例的可以表示图1-4中所示的机架中的任何特定一个的架构的机架架构的图;
图7是可以与图6的机架架构一起使用的板的示例实施例的图;
图8是用于为具有扩展能力的板提供支撑的机架架构的示例实施例的图;
图9是根据图8的机架架构实现的机架的示例实施例的图;
图10是设计用于与图9的机架结合使用的板的示例实施例的图;
图11是根据各种实施例的其中可以实现本文描述的一种或多种技术的数据中心的示例实施例的图;
图12是用于提供加速功能作为服务的系统的至少一个实施例的简化框图。
图13是图12的系统的协调器服务器的至少一个实施例的简化框图;
图14是可以由图12和图13的协调器服务器建立的环境的至少一个实施例的简化框图;
图15-图17是可以由图12和13的协调器服务器执行的用于提供加速功能作为服务的方法的至少一个实施例的简化流程图;以及
图18是可以在与要用图12的系统加速的任务相关联的元数据中指示的信息类型的简化框图。
具体实施方式
虽然本公开的概念易于进行各种修改和替代形式,但是其具体实施例已经在附图中通过示例的方式示出,并且将在本文中进行详细描述。然而,应当意识到,不意图将本公开的概念限制为所公开的特定形式,而是相反,意图是覆盖与本公开和所附权利要求一致的所有修改方案、等同方案和替代方案。
说明书中对“一个实施例”、“实施例”、“示例性实施例”等的提及表示所描述的实施例可以包括特定的特征、结构或特性,但是每个实施例可以必然或可以不必包括该特定的特征、结构或特性。此外,这样的短语不一定指代相同的实施例。此外,当结合实施例描述特定特征、结构或特性时,认为结合其他实施例来实现这样的特征、结构或特性在本领域技术人员的知识内,无论是否明确描述。此外,应当意识到,列表中以“A、B和C中的至少一个”的形式包括的项目可以意味着(A);(B);(C):(A和B);(A和C);(B和C);或(A,B和C)。类似地,以“A、B或C中的至少一个”的形式列出的项目可以是(A);(B);(C):(A和B);(A和C);(B和C);或(A,B和C)。
在一些情况下,所公开的实施例可以以硬件、固件、软件或其任何组合来实现。所公开的实施例还可以被实现为由暂时性或非暂时性机器可读(例如,计算机可读)存储介质承载或存储在其上的指令,所述指令可由一个或多个处理器读取和执行。机器可读存储介质可以被实现为用于以机器可读的形式存储或发送信息的任何存储设备、机构或其他物理结构(例如,易失性或非易失性存储器、介质盘或其他介质设备)。
在附图中,可以以具体的布置和/或顺序示出一些结构或方法特征。然而,应当意识到,可能不要求这种具体的布置和/或排序。相反,在一些实施例中,这些特征可以以与说明性图中所示的不同的方式和/或顺序布置。另外,在特定附图中包括结构或方法特征并不意味着在所有实施例中都需要这样的特征,并且在一些实施例中可以不包括这些特征或者可以将其与其它特征组合。
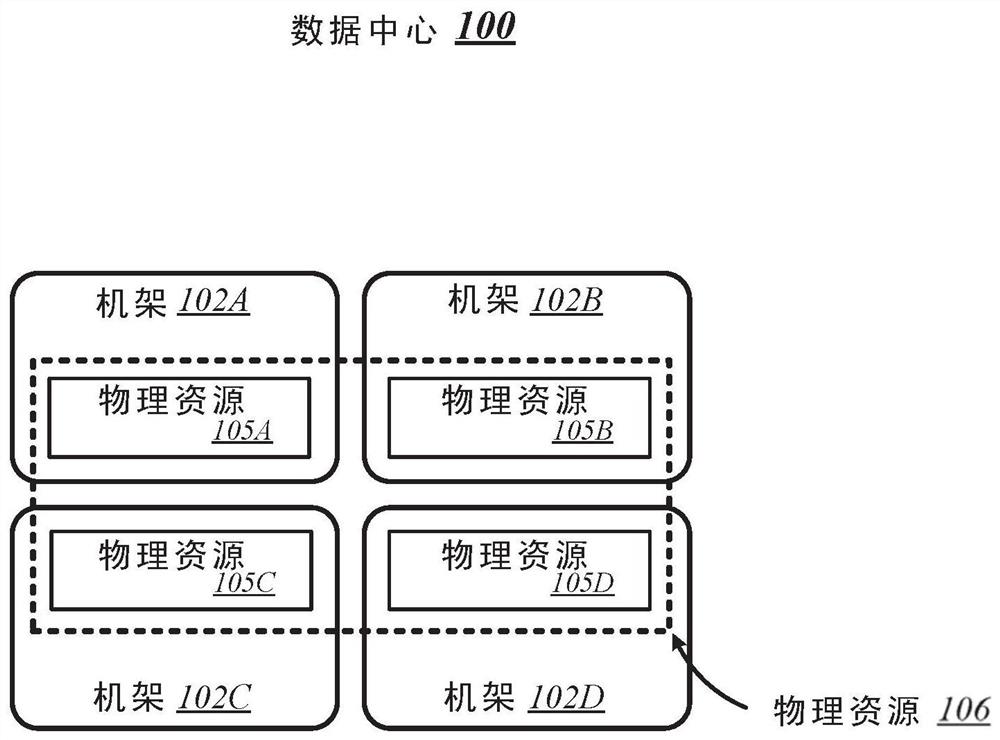
图1示出了数据中心100的概念性概述,该数据中心100通常可以代表其中可以根据各种实施例实现本文描述的一种或多种技术的数据中心或其他类型的计算网络。如图1所示,数据中心100通常可以包含多个机架,每个机架可以容纳包括相应的一组物理资源的计算设备。在图1中描绘的特定非限制性示例中,数据中心100包含四个机架102A至102D,其容纳包括各组物理资源(PCR)105A至105D的计算设备。根据该示例,数据中心100的集合的一组物理资源106包括分布在机架102A至102D之间的各种组物理资源105A至105D。物理资源106可以包括多种类型的资源,例如处理器、协处理器、加速器、现场可编程门阵列(FPGA)、存储器和存储装置。实施例不限于这些示例。
说明性数据中心100在许多方面不同于典型的数据中心。例如,在说明性实施例中,其上放置诸如CPU、存储器和其他组件之类的组件的电路板(“板”(sled))被设计用于提高热性能。特别地,在说明性实施例中,该板比典型的板(board)浅。换句话说,板从前到后较短,冷却风扇位于其中。这减少了空气必须穿过板上组件的路径的长度。此外,板上的组件与典型的电路板相比间隔得更远,并且这些组件被设置成减少或消除阴影(即,一个组件在另一组件的空气流动路径中)。在说明性实施例中,诸如处理器之类的处理组件位于板的顶侧,而诸如DIMM之类的附近存储器位于板的底侧。由于该设计提供的增强的气流,组件可以以比典型系统更高的频率和功率水平来操作,从而提高性能。此外,板被配置为与每个机架102A、102B、102C、102D中的电源和数据通信电缆盲匹配,增强了它们被快速移除、升级、重新安装和/或更换的能力。类似地,位于板上的各个组件(例如处理器、加速器、存储器和数据存储驱动器)被配置为由于它们彼此间隔增加而容易升级。在说明性实施例中,组件还包括硬件证明特征以证明其真实性。
此外,在说明性实施例中,数据中心100利用支持包括以太网和Omni-Path在内的多个其他网络架构的单个网络架构(“结构”)。在说明性实施例中,板经由光纤耦合到交换机,光纤提供比典型的双绞线布线(例如,类别5、类别5e、类别6等)更高的带宽和更低的延迟。由于高带宽、低延迟互连和网络架构,数据中心100可以在使用中汇集物理地分解的资源,例如存储器、加速器(例如,图形加速器、FPGA、ASIC等)以及数据存储驱动器,并根据需要将它们提供给计算资源(例如,处理器),使计算资源能够访问池化资源,就好像它们是本地的一样。说明性数据中心100另外接收针对各种资源的利用信息,基于过去的资源利用来预测不同类型的工作负载的资源利用,并基于该信息动态地重新分配资源。
数据中心100的机架102A、102B、102C、102D可以包括便于各种类型的维护任务的自动化的物理设计特征。例如,数据中心100可以使用设计为机器人访问的机架来实现,并且接受和容纳可机器人操纵的资源板。此外,在说明性实施例中,机架102A、102B、102C、102D包括集成电源,所述集成电源接收比针对电源的典型电压更大的电压。增加的电压使电源能够为每个板上的组件提供额外的电力,使组件能够以高于典型频率的频率运行。
图2示出了数据中心100的机架202的示例性逻辑配置。如图2所示,机架202通常可以容纳多个板,每个板可以包括相应的一组物理资源。在图2中描绘的特定非限制性示例中,机架202容纳包括相应的一组物理资源205-1至205-4的板204-1至204-4,每组物理资源构成包括在机架202中的集合的一组物理资源206的一部分。关于图1,如果机架202代表例如机架102A,则物理资源206可以对应于机架102A中包括的物理资源105A。在该示例的上下文中,物理资源105A因此可以由相应的一组物理资源组成,所述物理资源包括包含在机架202的板204-1至204-4中的物理存储资源205-1、物理加速器资源205-2、物理存储器资源205-3和物理计算资源205-5。实施例不限于该示例。每个板可以包含各种类型的物理资源(例如,计算、存储器、加速器、存储装置)中的每一个的池。通过具有包括分解的资源的机器人可访问和机器人可操纵的板,每种类型的资源能够彼此独立地并且以其自己的优化刷新率升级。
图3示出了数据中心300的示例,该数据中心300通常可以表示可以根据各种实施例实现本文描述的一种或多种技术。在图3中描绘的特定非限制性示例中,数据中心300包括机架302-1至302-32。在各种实施例中,数据中心300的机架可以以限定和/或容纳各种访问路径的方式布置。例如,如图3所示,数据中心300的机架可以以限定和/或容纳访问路径311A、311B、311C和311D的方式布置。在一些实施例中,这种访问路径的存在通常使得自动维护设备(例如机器人维护设备)能够物理地访问容纳在数据中心300的各种机架中的计算设备并执行自动维护任务(例如,替换故障的板、升级板)。在各种实施例中,可以选择访问路径311A、311B、311C和311D的尺寸、机架302-1至302-32的尺寸和/或数据中心300的物理布局的一个或多个其他方面以促进这种自动化操作。实施例不限于此上下文。
图4示出了数据中心400的示例,该数据中心400通常可以代表可以根据各种实施例实现本文描述的一种或多种技术的数据中心。如图4所示,数据中心400可以以光学结构412为特征。光学结构412通常可以包括光信令介质(例如光学电缆)和光学交换基础设施的组合,数据中心400中的任何特定板可以经由它们向数据中心400中的每个其他板发送信号(并且从其接收)。光学结构412提供给任何给定板的信令连接可以包括到同一机架中的其他板和其他机架中的板的连接。在图4中描绘的特定非限制性示例中,数据中心400包括四个机架402A至402D。机架402A至402D容纳相应的一对板404A-1和404A-2、404B-1和404B-2、440C-1和404C-2以及404D-1和404D-2。因此,在该示例中,数据中心400包括总共八个板。通过光学结构412,每个这样的板可以具有与数据中心400中的七个其他板中的每一个的信令连接。例如,经由光学结构412,机架402A中的板404A-1可以具有与机架402A中的板404A-2,以及分布在数据中心400的其他机架402B、402C和402D之间的六个其他板404B-1、404B-2、440C-1、440C-2、440D-1和404D-2的信令连接。实施例不限于该示例。
图5示出了连接方案500的概述,该连接方案500通常可以表示在一些实施例中可以在数据中心的各种板(例如,图1、图3和图4的示例数据中心100、300和400中的任何一个)之间建立的链路层连接。可以使用以双模光交换基础设施514为特征的光学结构来实现连接方案500。双模光交换基础设施514通常可以包括能够通过相同的统一的一组光信令介质根据多个链路层协议接收通信,并适当地切换这种通信的交换基础设施。在各种实施例中,可以使用一个或多个双模光交换机515来实现双模光交换基础设施514。在各种实施例中,双模光交换机515通常可以包括高基数交换机。在一些实施例中,双模光交换机515可以包括多层交换机,例如四层交换机。在各种实施例中,双模光交换机515可以以集成硅光子学为特征,与传统交换机设备相比,硅光子学使双模光交换机能够以显着减少的延迟切换通信。在一些实施例中,双模光交换机515可以构成叶脊结构中的叶片交换机530,叶脊结构另外包括一个或多个双模光脊交换机520。
在各种实施例中,双模光交换机能够经由光学结构的光信令介质接收承载因特网协议(IP分组)的以太网协议通信和根据第二高性能计算(HPC)链路层协议(例如,英特尔的Omni-Path架构的,Infiniband)的通信。如图5所反映的,对于具有到光学结构的光信令连接的任何特定的一对板504A和504B,连接方案500因此可以经由以太网链路和HPC链路提供对链路层连接的支持。因此,单个高带宽、低延迟交换结构可以支持以太网和HPC通信。实施例不限于该示例。
图6示出了机架架构600的总体概述,该机架架构600可以代表根据一些实施例的图1至图4中所示的机架中的任何特定一个的架构。如图6所示,机架架构600通常可以以多个板空间为特征,板可以插入其中,每个板空间可以经由机架访问区域601进行机器人可访问。在图6所示的特定非限制性示例中,机架架构600以五个板空间603-1至603-5为特征。板空间603-1至603-5以相应的多功能连接器模块(MPCM)616-1至616-5为特征。
图7示出了可以代表这种类型的板的板704的示例。如图7所示,板704可以包括一组物理资源705,以及MPCM 716,其被设计成当板704插入板空间(例如图6中的任何板空间603-1至603-5)时与配对MPCM耦合。板704还可以以扩展连接器717为特征。扩展连接器717通常可以包括插座、插槽或其他类型的连接元件,其能够接受一种或多种类型的扩展模块,例如扩展板718。通过与扩展板718上的配对连接器耦合,扩展连接器717可以为物理资源705提供对驻留在扩展板718上的补充计算资源705B的访问。实施例不限于此上下文。
图8示出了可以表示如下的机架架构的机架架构800的示例,该机架架构可以被实现以便为以扩展能力为特征的板(例如,图7的板704)提供支持。在图8中描绘的特定非限制性示例中,机架架构800包括七个板空间803-1至803-7,其以相应的MPCM 816-1至816-7为特征。板空间803-1至803-7包括相应的主区域803-1A至803-7A和相应的扩展区域803-1B至803-7B。关于每个这样的板空间,当相应的MPCM与插入的板的配对MPCM耦合时,主区域通常可以构成物理地容纳插入的板的板空间的区域。在插入的板被配置有这种模块的情况下,扩展区域通常可以构成可以物理地容纳扩展模块的板空间的区域,例如图7的扩展板718。
图9示出了机架902的示例,其可以代表根据一些实施例的根据图8的机架架构800实现的机架。在图9中描绘的特定非限制性示例中,机架902以七个板空间903-1至903-7为特征,其包括相应的主区域903-1A至903-7A和相应的扩展区域903-1B至903-7B。在各种实施例中,可以使用空气冷却系统来实现机架902中的温度控制。例如,如图9中所反映的那样,机架902可以以多个风扇919为特征,风扇919通常被布置为在各种板空间903-1至903-7内提供空气冷却。在一些实施例中,板空间的高度大于传统的“1U”服务器高度。在这样的实施例中,与传统机架配置中使用的风扇相比,风扇919通常可包括相对慢的大直径冷却风扇。相对于以较高速度运行的较小直径的冷却风扇而言,以较低速度运行较大直径的冷却风扇可以延长风扇寿命,同时仍能提供相同的冷却量。板比传统的机架尺寸物理上更浅。此外,每个板上都布置了组件以减少热阴影(即,没有沿气流方向串联布置)。因此,更宽、更浅的板允许设备性能的提高,因为由于改进的冷却,设备可以在更高的热封套(例如,250W)下操作(即,没有热阴影,设备之间的空间更大,更大的散热器空间等)。
MPCM 916-1至916-7可以被配置为向插入的板提供对源自相应的电源模块920-1至920-7的电源的访问,每个电源模块可以从外部电源921汲取电力。在一些实施例中,外部电源921可以向机架902输送交流(AC)电力,并且电力模块920-1至920-7可以被配置为将这种AC电力转换为直流(DC)电力以供源于插入的板。在一些实施例中,例如,功率模块920-1至920-7可以被配置为将277伏AC功率转换为12伏DC功率,以经由相应的MPCM 916-1至916-7提供给插入的板。实施例不限于该示例。
MPCM 916-1至916-7还可以被布置为向插入的板提供与双模光交换基础设施914的光信令连接,双模光交换基础设施914可以与图5的双模光交换基础设施514相同或相似。在各种实施例中,包含在MPCM 916-1至916-7中的光学连接器可以被设计成与插入的板的MPCM中包含的配对光学连接器耦合,以向这种板提供经由各长度的光缆922-1至922-7与双模光学交换基础设施914的光信令连接。在一些实施例中,每个这样长度的光缆可以从其对应的MPCM延伸到在机架902的板空间外部的光学互连织机923。在各种实施例中,光学互连织机923可以布置成穿过支撑柱或支架902的其他类型的承载元件。实施例不限于此上下文。由于插入的板通过MPCM连接到光交换基础设施,因此可以节省通常耗费于手动配置机架布线以容纳新插入的板的资源。
图10示出了板1004的示例,其可以代表根据一些实施例的设计用于与图9的机架902结合使用的板。板1004可以以MPCM 1016为特征,MPCM 1016包括光学连接器1016A和电源连接器1016B,并且被设计成与将MPCM 1016插入到板空间中相结合而与板空间的配对MPCM耦合。将MPCM 1016与这样的配对MPCM耦合可以使电源连接器1016与配对MPCM中包括的电源连接器耦合。这通常使得板1004的物理资源1005能够经由电源连接器1016和电力传输介质1024从外部源获取电力,电力传输介质1024将电力连接器1016导电地耦合到物理资源1005。
板1004还可以包括双模光网络接口电路1026。双模光网络接口电路1026通常可以包括能够根据图9的双模光学交换基础设施914支持的多个链路层协议中的每一个通过光信令介质进行通信的电路。在一些实施例中,双模光网络接口电路1026能够进行以太网协议通信和根据第二高性能协议的通信。在各种实施例中,双模光网络接口电路1026可以包括一个或多个光收发器模块1027,每个光收发器模块1027能够在一个或多个光信道中的每一个上发送和接收光信号。实施例不限于此上下文。
将MPCM 1016与给定机架中的板空间的配对MPCM耦合可以使光学连接器1016A与配对MPCM中包括的光学连接器耦合。这通常可以经由一组光学信道1025中的每一个在板的光缆与双模光网络接口电路1026之间建立光学连接。双模光网络接口电路1026可以经由电信令介质1028与板1004的物理资源1005进行通信。除了板的尺寸和板上的用于提供改进的冷却并且能够在相对较高的热封套(例如,250W)下操作的组件的布置之外,如上面参考图9所述,在一些实施例中,板还可包括一个或多个附加特征以便于空气冷却,例如布置成耗散由物理资源1005产生的热量的热管和/或散热器。值得注意的是,尽管图10中所描绘的示例性板1004没有以扩展连接器为特征,但是根据一些实施例以板1004的设计元件为特征的任何给定板也可以以扩展连接器为特征。实施例不限于此上下文。
图11示出了数据中心1100的示例,该数据中心1100通常可以表示可以根据各种实施例的实现本文描述的一种或多种技术。如图11所反映的,可以实现物理基础设施管理框架1150A以便于管理数据中心1100的物理基础设施1100A。在各种实施例中,物理基础设施管理框架1150A的一个功能可以是管理数据中心1100内的自动维护功能,例如使用机器人维护设备来为物理基础设施1100A内的计算设备提供服务。在一些实施例中,物理基础设施1100A可以以先进的遥测系统为特征,该遥测系统执行遥测报告,该遥测报告足够鲁棒以支持物理基础设施1100A的远程自动化管理。在各种实施例中,由这种先进的遥测系统提供的遥测信息可以支持诸如故障预测/预防能力和容量规划能力之类的特征。在一些实施例中,物理基础设施管理框架1150A还可以被配置为使用硬件证明技术来管理物理基础设施组件的认证。例如,机器人可以在安装之前通过分析从与要安装的每个组件相关联的射频识别(RFID)标签收集的信息来验证组件的真实性。实施例不限于此上下文。
如图11所示,数据中心1100的物理基础设施1100A可以包括光学结构1112,其可以包括双模光交换基础设施1114。光学结构1112和双模光交换基础设施1114可以分别图4的光学结构412和图5的双模光交换基础设施514相同或相似,并且可以在数据中心1100的板之间提供高带宽、低延迟、多协议连接。如上所述,参考图1,在各种实施例中,这种连接的可用性可以使得对诸如加速器、存储器和存储装置之类的资源分解和动态地汇集成为可能。在一些实施例中,例如,一个或多个汇集的加速器板1130可以包括在数据中心1100的物理基础设施1100A中,每个物理基础设施1100A可以包括加速器资源池,诸如例如协处理器和/或FPGA,它们经由光学结构1112和双模光交换基础设施1114可以用于其他板全局访问。
在另一个示例中,在各种实施例中,一个或多个汇集的存储板1132可以包括在数据中心1100的物理基础设施1100A中,每个物理基础设施1100A可以包括可经由光学结构1112和双模光学交换基础设施1114供其他板全局访问的存储资源池。在一些实施例中,这种池化的存储板1132可以包括固态存储设备(例如,固态驱动器(SSD))池。在各种实施例中,一个或多个高性能处理板1134可以包括在数据中心1100的物理基础设施110A中。在一些实施例中,高性能处理板1134可以包括高性能处理器池以及增强空气冷却从而产生高达250W或更高的热封套的冷却特征。在各种实施例中,任何给定的高性能处理板1134可以以扩展连接器1117为特征,该扩展连接器1117可以接受远存储器扩展板,使得该高性能处理板1134本地可用的远存储器从处理器和包含在板上的附近存储器分解。在一些实施例中,这样的高性能处理板1134可以使用包括低延迟SSD存储的扩展板配置远存储器。光学基础设施允许一个板上的计算资源利用远程加速器/FPGA、存储器和/或SSD资源,这些资源在位于同一机架或数据中心任何其他机架上的板上分解。远程资源可以位于上面参考图5描述的脊-叶网络架构中的一个交换机跳跃或两个交换机跳跃。实施例不限于此上下文。
在各种实施例中,可以将一个或多个抽象层应用于物理基础设施1100A的物理资源,以便定义虚拟基础设施,例如软件定义的基础设施1100B。在一些实施例中,可以分配软件定义的基础设施1100B的虚拟计算资源1136以支持云服务1140的提供。在各种实施例中,可以将特定的一组虚拟计算资源1136分组以便以SDI服务1138的形式提供给云服务1140。云服务1140的示例可以包括但不限于软件即服务(SaaS)服务1142、平台即服务(PaaS)服务1144以及基础设施即服务(IaaS)服务1146。
在一些实施例中,可以使用虚拟基础设施管理框架1150B来进行软件定义的基础设施1100B的管理。在各种实施例中,虚拟基础设施管理框架1150B可以被设计为结合管理虚拟计算资源1136和/或SDI服务1138向云服务1140的分配来实现工作负载指纹技术和/或机器学习技术。在一些实施例中,虚拟基础设施管理框架1150B可以结合执行这样的资源分配来使用/咨询遥测数据。在各种实施例中,可以实现应用/服务管理框架1150C以便为云服务1140提供QoS管理能力。实施例不限于此上下文。
现在参考图12,用于提供加速功能作为服务的系统1210可以根据上面参考图1、图3、图4和图11所描述的数据中心100、300、400、1100来实现。在说明性实施例中,系统1210包括通信地耦合到多个板的协调器服务器1220,板包括计算板1230和加速器板1240、1242。板1230、1240、1242中的一个或多个例如可以通过协调器服务器1220分组为受管节点,以共同执行工作负载,例如应用。受管节点可以体现为资源的集合(例如,物理资源206),诸如计算资源(例如,物理计算资源205-4)、存储器资源(例如,物理存储器资源205-3)、存储资源(例如,物理存储资源205-1)或来自相同或不同板(例如,板204-1、204-2、204-3、204-4等)或机架(例如,机架302-1至302-32中的一个或多个)的其他资源(例如,物理加速器资源205-2)等。此外,可以在将工作负载分配给受管节点时或者在任何其他时间由协调器服务器1220建立、定义或“旋转”受管节点,并且可以存在受管节点,而不管当前是否有任何工作负载分配给受管节点。系统1210可以位于数据中心中,并且向通过网络1212与系统1210通信的客户端设备1214提供存储和计算服务(例如,云服务)。协调器服务器1220可以支持云操作环境,例如OpenStack,并且由协调器服务器1220建立的受管节点可以代表客户端设备1214的用户执行一个或多个应用或过程(即,工作负载),诸如在虚拟机或容器中。
在说明性实施例中,计算板1230包括执行工作负载1234(例如,应用)的中央处理单元(CPU)1232(例如,能够执行一系列操作的处理器或其他设备或电路)。在说明性实施例中,加速器板1240包括多个加速器设备1260、1262,每个加速器设备包括多个内核1270、1272、1274、1276。每个加速器设备1260、1262可以体现为能够加速功能的执行的任何设备或电路(例如,专用处理器、FPGA、ASIC、图形处理单元(GPU)、可重配置硬件等)。每个内核1270、1272、1274、1276可以体现为一组代码或对应的加速器设备1260、1262的一部分的配置,其使得加速器设备1260、1262执行一个或多个加速功能(例如,加密操作、压缩操作等)。类似地,加速器板1242包括加速器设备1264、1266和对应的内核1278、1280、1282、1284,类似于加速器设备1260、1262和内核1270、1272、1274、1276。在操作中,协调器服务器1220维护哪些内核存在于哪些加速器板上(例如,在加速器板1240、1242之一的加速器设备上)的数据库,接收用于加速工作负载(例如,任务)的部分的请求,使用请求中的信息确定与任务相关联的加速的类型(例如,要加速的功能),并将任务分配给一个或多个相应的加速器板1240、1242。此外,为了提供额外的灵活性,协调器服务器1220可以协调安装和/或从加速器板移除内核以适应来自计算板(例如,计算板1230)的针对任务加速的请求。这样,系统1210提供加速功能作为针对工作负载的服务,而不是将工作负载限制为加速器设备的加速能力(如果有的话),其可以在执行工作负载的CPU 1232本地(例如,物理上位于计算板1230上)。
现在参考图13,协调器服务器1220可以体现为能够执行本文描述的功能的任何类型的计算设备,包括接收用于加速与通信地耦合到协调器服务器1220的加速器板(例如,加速器板1240)使用以执行任务的内核(例如,内核1270)相关联的任务的请求,响应于该请求并且利用指示内核和相关联的加速器板的内核映射数据库,确定包括被配置有与请求相关联的内核的加速器设备(例如,加速器设备1260)的加速器板(例如,加速器板1240),并将任务分配给所确定的加速器板以用于执行。
如图13所示,说明性协调器服务器1220包括计算引擎1302、输入/输出(I/O)子系统1308、通信电路1310和一个或多个数据存储设备1314。当然,在其他实施例中,协调器服务器1220可以包括其他或附加组件,例如计算机中常见的组件(例如,显示器、外围设备等)。另外,在一些实施例中,说明性组件中的一个或多个可以并入另一组件中,或者以其他方式形成另一组件的一部分。
计算引擎1302可以体现为能够执行下面描述的各种计算功能的任何类型的设备或设备集合。在一些实施例中,计算引擎1302可以体现为单个设备,诸如集成电路、嵌入式系统、现场可编程门阵列(FPGA)、片上系统(SOC)或其他集成系统或设备。另外,在一些实施例中,计算引擎1302包括或体现为处理器1304和存储器1306。处理器1304可以体现为能够执行本文描述的功能的任何类型的处理器。例如,处理器1304可以体现为单核或多核处理器、微控制器或其他处理器或处理/控制电路。在一些实施例中,处理器1304可以体现为、包括或耦合到FPGA、专用集成电路(ASIC)、可重新配置的硬件或硬件电路或其他专用硬件,以便于执行本文描述的功能。另外,在说明性实施例中,处理器1304包括内核跟踪器逻辑单元1320,其可以体现为能够从处理器1304卸载本文描述的与提供加速功能作为服务相关联的操作的任何电路或设备(例如,FPGA、ASIC、协处理器等)。
主存储器1306可以体现为能够执行本文描述的功能的任何类型的易失性(例如,动态随机存取存储器(DRAM)等)或非易失性存储器或数据存储装置。易失性存储器可以是需要电力以维持由介质存储的数据的状态的存储介质。易失性存储器的非限制性示例可以包括各种类型的随机存取存储器(RAM),诸如动态随机存取存储器(DRAM)或静态随机存取存储器(SRAM)。可以在存储器模块中使用的一种特定类型的DRAM是同步动态随机存取存储器(SDRAM)。在特定实施例中,存储器组件的DRAM可以符合由JEDEC颁布的标准,如对用于DDR SDRAM的JESD79F,用于DDR2 SDRAM的JESD79-2F,用于DDR3 SDRAM的JESD79-3F,用于DDR4 SDRAM的JESD79-4A,用于低功耗DDR(LPDDR)的JESD209,用于LPDDR2的JESD209-2,用于LPDDR3的JESD209-3和用于LPDDR4的JESD209-4(这些标准可在www.jedec.org上获得)。这些标准(和类似标准)可以被称为基于DDR的标准,并且实现这种标准的存储设备的通信接口可以被称为基于DDR的接口。
在一个实施例中,存储器设备是块可寻址存储器设备,诸如基于NAND或NOR技术的那些。存储器设备还可以包括下一代非易失性设备,诸如三维交叉点存储器设备(例如,Intel 3D XPoint
在一些实施例中,3D交叉点存储器(例如,Intel 3D XPoint
计算引擎1302经由I/O子系统1308通信地耦合到协调器服务器1220的其他组件,I/O子系统1308可以体现为用于促进与计算引擎1302(例如,与处理器1304和/或存储器1306)以及协调器服务器1220的其它组件的输入/输出操作的电路和/或组件。例如,I/O子系统1308可以体现为或以其他方式包括存储器控制器集线器、输入/输出控制集线器、集成传感器集线器、固件设备、通信链路(例如,点对点链路、总线链路、电线、电缆、光导、印刷电路板迹线等),和/或便于输入/输出操作的其他组件和子系统。在一些实施例中,I/O子系统1308可以形成片上系统(SoC)的一部分,并且与处理器1304、主存储器1306和协调器服务器1220的其他组件中的一个或多个一起并入计算引擎1302。
通信电路1310可以体现为能够实现在协调器服务器1220与另一计算设备(例如,计算板1230、加速器板1240、1242等)之间通过网络1212的通信的任何通信电路、设备或其集合。通信电路1310可以被配置为使用任何一种或多种通信技术(例如,有线或无线通信)和相关协议(例如,以太网、
说明性通信电路1310包括网络接口控制器(NIC)1312,其也可以称为主机结构接口(HFI)。NIC 1312可以体现为一个或多个内置板、子卡、网络接口卡、控制器芯片、芯片组或可以由协调器服务器1220用来与另一计算设备(例如,计算板1230、加速器板1240、1242等)连接的其他设备。在一些实施例中,NIC 1312可以体现为包括一个或多个处理器的片上系统(SoC)的一部分,或者包括在也包含一个或多个处理器的多芯片封装上。在一些实施例中,NIC 1312可以包括本地处理器(未示出)和/或本地存储器(未示出),它们都在NIC 1312的本地。在这样的实施例中,NIC 1312的本地处理器能够执行本文描述的计算引擎1302的功能中的一个或多个。附加地或替代地,在这样的实施例中,NIC 1312的本地存储器可以在板级、插槽级、芯片级和/或其他级别集成到协调器服务器1220的一个或多个组件中。
一个或多个说明性数据存储设备1314可以体现为被配置用于对数据进行短期或长期存储的任何类型的设备,例如存储器设备和电路、存储卡、硬盘驱动器、固态驱动器或其他数据存储设备。每个数据存储设备1314可以包括存储数据存储设备1314的数据和固件代码的系统分区。每个数据存储设备1314还可以包括存储用于操作系统的数据文件和可执行文件的操作系统分区。
附加地或替代地,协调器服务器1220可以包括一个或多个外围设备1316。这样的外围设备1316可以包括通常见于计算设备中的任何类型的外围设备,诸如显示器、扬声器、鼠标、键盘和/或其他输入/输出设备、接口设备和/或其他外围设备。
现在参考图14,协调器服务器1220可以在操作期间建立环境1400。说明性环境1400包括网络通信器1420和加速服务管理器1430。环境1400的每个组件可以体现为硬件、固件、软件或其组合。这样,在一些实施例中,环境1400的一个或多个组件可以体现为电路或电子设备的集合(例如,网络通信器电路1420、加速服务管理器电路1430等)。应当意识到,在这样的实施例中,网络通信器电路1420或加速服务管理器电路1430中的一个或多个可以形成计算引擎1302、内核跟踪器逻辑单元1320、通信电路1310、I/O子系统1308和/或协调器服务器1220的其他组件中的一个或多个的一部分。在说明性实施例中,环境1400包括任务请求数据1402,其可以体现为指示由协调器服务器1220从计算板(例如,计算板1230)接收的用于加速与工作负载的全部或一部分相关联的任务(例如,一个或多个功能)的一个或多个请求的任何数据。另外,在说明性实施例中,环境1400包括内核映射数据1404,其可以体现为指示与加速器板1240、1242相关联的内核的任何数据。在说明性实施例中,如果加速器板的加速器设备当前被配置有内核(例如,FPGA的插槽被配置有内核),则内核与加速器板相关联。另外,在说明性实施例中,环境1400包括遥测数据1406,遥测数据1406可以体现为指示性能(例如,每秒的操作、当前正在使用的加速器设备的总计算容量的当前量,等等,本文称为利用负载)以及每个加速器板1240、1242的每个加速器设备1260、1262、1264、1266的其他条件(例如功率使用)的任何数据。
在说明性环境1400中,网络通信器1420(其可以体现为如上所述的硬件、固件、软件、虚拟化硬件、仿真架构和/或其组合)被配置为促进分别来往于协调器服务器1220的入站和出站网络通信(例如,网络业务、网络分组、网络流等)。为此,网络通信器1420被配置为接收和处理来自一个系统或计算设备(例如,计算板1230)的数据分组,并准备和发送数据分组到另一个计算设备或系统(例如,加速器板1240、1242)。因此,在一些实施例中,网络通信器1420的功能的至少一部分可以由通信电路1310执行,并且在说明性实施例中,由NIC1312执行。
加速服务管理器1430(其可以体现为硬件、固件、软件、虚拟化硬件、仿真架构和/或其组合)被配置为协调接收用于加速任务的请求,基于加速器板1240、1242是否已经具有与加速器设备上的任务相关联的内核或者具有用内核配置加速器设备的能力(例如,在FPGA插槽中)来确定用于执行任务的一个或多个加速器板1240、1242,并且将任务分配给所确定的加速器板1240、1242以用于执行。为此,在说明性实施例中,加速服务管理器1430包括任务请求管理器1432、内核管理器1434和利用管理器1436。在说明性实施例中,任务请求管理器1432被配置为接收任务请求并确定任务的特征,包括用于加速任务的功能的内核,是否可以同时由多个加速器设备执行任务(例如,通过虚拟化,通过虚拟化共享存储器来共享数据等)和/或服务质量目标(例如,目标延迟、目标吞吐量等)。在说明性实施例中,内核管理器1434被配置为使用内核映射数据1404确定哪个加速器板1240、1242(如果有的话)已经具有内核(例如,加速器板1240的加速器设备1260可能已经具有配置了内核的插槽)。在一些实施例中,如果内核不存在于加速器板1240、1242上,则内核管理器1434协调将加速器板1240、1242的加速器设备中的至少一个被配置有内核。在说明性实施例中,利用管理器1436被配置为收集遥测数据1406并分析遥测数据1406以帮助确定应当选择哪个加速器板1240、1242来加速任务。例如,如果多个加速器板1240、1242当前具有与任务请求相关联的内核,则利用管理器1436可以分析遥测数据1406以确定哪个加速器板1240、1242具有足够的利用容量(例如,利用负载满足预定义阈值)以满足服务质量目标(例如,用于完成任务的目标延迟)。
现在参考图15,协调器服务器1220在操作中可以执行方法1500以提供加速功能作为服务。方法1500以框1502开始,其中协调器服务器1220确定是否启用加速功能作为服务。在说明性实施例中,如果协调器服务器1220通信地耦合到一个或多个加速器板(例如,加速器板1240、1242)并且已将工作负载分配给计算板(工作负载1234分配给计算板1230),则协调器服务器1220可确定启用加速功能作为服务。在其他实施例中,协调器服务器1220可以基于其他因素确定是否启用加速功能作为服务。无论如何,响应于确定启用加速功能作为服务,方法1500前进到框1504,其中协调器服务器1220可以接收用于加速与内核相关联的任务的请求(例如,任务请求)。在这样做时,协调器服务器1220可以从执行工作负载(例如,工作负载1234)的计算板(例如,计算板1230)接收请求,如框1506所示。此外,在接收请求时,协调器服务器1220可以接收包括指示任务的特征和参数(例如,输入数据、设置等)的元数据的请求,如框1508所示。简要参考图18,元数据中指示的信息1800还可以包括要针对其加速任务的工作负载的类型(例如,支持卷积神经网络的工作负载、数据压缩工作负载、数据加密工作负载等)和特征,例如服务质量要求和/或任务的虚拟化能力。返回参考图15,在框1510中,协调器服务器1220可以接收具有指示任务的虚拟化能力(例如,任务是否可以被划分为可以由单独的虚拟机执行的功能)的元数据的请求。在说明性实施例中,协调器服务器1220可以接收指示并发执行能力(例如,功能是否可以在同一时间执行,例如在单独的虚拟机中)的元数据,如框1512所示。另外或可选地,协调器服务器1220可以接收具有指示任务的可虚拟化功能的数量的元数据的请求,如框1514所示。
另外或替代地,在接收请求时,协调器服务器1220可以接收具有指示目标服务质量数据(例如,根据服务水平协议(SLA))的元数据的请求,如框1516所示。例如,如框1518所示,元数据可以指示目标延迟(例如,在特定功能完成之前可能经过的最大毫秒数)。作为另一示例,元数据可指示目标吞吐量(例如,每秒的最小操作数),如框1520所示。在说明性实施例中,请求识别与任务相关联的内核,如框1522所示。这样,并且如框1524所示,在一些实施例中,协调器服务器1220可以接收包括内核本身的请求,例如以比特流的形式,如框1526所示,或者体现内核的可执行代码,如在框1528中所示。在说明性实施例中,请求包括内核的标识符(例如,通用唯一标识符(UUID)),如框1530所示。在框1532中,协调器服务器1220基于是否收到任务请求来确定后续的动作过程。如果没有接收到任务请求,则方法1500循环回到框1502以确定是否继续启用加速功能作为服务。否则,方法1500前进到图16的框1534,其中协调器服务器1220确定与任务相关联的内核是否已经存在于加速器板1240、1242中。
现在参考图16,在确定内核是否已经存在于加速器板中时,协调器服务器1220可以将内核的标识符与指示内核标识符和加速器板(例如,在其上存在相对应内核的加速器板)的内核映射数据库进行比较,如框1536所示。在这样做时,协调器服务器1220可以执行与任务请求中包括的内核标识符(例如,来自图15的框1530的内核标识符)的比较,如框1538所示。可选地,协调器服务器1220可以执行与任务请求中包括的内核的散列(例如,由比特流或可执行代码的协调器服务器1220产生的散列)的比较,如框1540所示。在框1542中,协调器服务器1220根据内核是否已经存在于加速器板1240、1242中来确定随后的动作过程。如果不是,则方法1500前进到框1544,其中协调器服务器1220确定具有要配置内核的容量的加速器板。在这样做时,协调器服务器1220可以请求加速器板1240、1242以确定是否存在未使用的容量,如框1546所示。在这样做时,并且如框1548所示,协调器服务器1220可以查询加速器板1240、1242以确定是否存在未使用的FPGA槽(例如,如果加速器设备1260、1262、1264、1266中的一个或多个是FPGA)。如框1550所示,协调器服务器1220可以通过移除不满足阈值使用级别的内核(例如,内核在预定义时间段内尚未使用)来请求加速器板1220生成容量。例如,在生成容量时,可以将要移除的内核的比特流保存在存储器中,但是可以基于用于新内核的比特流来指定相应FPGA槽的门用于重新编程。随后,协调器服务器1220将内核(例如,体现内核的比特流或可执行代码)发送到所确定的加速器板以进行配置(例如,用于编程),如框1552所示。之后,方法1500前进到框1554。其中,协调器服务器1220更新内核映射数据库(例如,内核映射数据1404)以指示内核与所确定的加速器板相关联。随后,或者如果协调器服务器1220在框1542中确定内核已经存在于加速器板中,则方法1500前进到框1556,其中协调器服务器1220接收指示每个加速器板1240、1242的利用负载(例如,所使用的可用加速容量的量)的遥测数据(例如,遥测数据1406)。在这样做时,在说明性实施例中,协调器服务器1220接收指示每个加速器板1240、1242的每个加速器设备的利用负载的遥测数据。尽管描述为在方法1500中的序列中的特定位置处发生,但是应当理解,协调器服务器1220可以在任何时间接收遥测数据1406,包括与在方法1500中执行的其他操作并发地进行。
现在参考图17,方法1500继续到框1560,其中协调器服务器1220选择加速器板1240、1242以执行任务,其被配置有内核并且具有满足预定义阈值的利用负载。在这样做时,协调器服务器1220可以选择具有满足与目标服务质量相关联的阈值的利用负载的加速器板1240、1242(例如,当前利用负载小于80%以满足与一种服务质量相关联的目标延迟或与吞吐量或利用负载小于60%以满足与比第一服务质量要求更高的第二服务质量相关联的目标延迟或吞吐量),如框1562所示。如框1564所示,协调器服务器1220可以将用于每个加速器板的遥测数据1406与预定义阈值进行比较。在一些实施例中,协调器服务器1220可以在来自系统1210的管理员或者来自另一个源的配置设置中根据可以在任务请求元数据中指示的附加标准(例如,目标功率使用)来选择加速器板,如框1566所示。在一些实施例中,协调器服务器1220可以选择多个加速器板1240、1242来执行任务(例如,任务可以被划分为跨多个加速器设备和加速器板的多个虚拟化功能),如框1568所示。
随后,在框1570中,协调器服务器1220将与任务请求相关联的任务分配给所选择的加速器板以用于执行。在这样做时,在说明性实施例中,协调器服务器1220将分配请求发送到所选择的加速器板,如框1572所示。如框1574所示,协调器服务器1220可以发送包括来自任务请求的元数据(例如,在图15的框1508中接收的元数据的全部或部分)的分配请求。在发送具有元数据的分配请求时,协调器服务器1220可以发送包括服务质量目标数据(例如,在图15的框1516中接收的服务质量目标数据)的分配请求,如框1576所示。附加地或替代地,协调器服务器1220可以发送包括虚拟化数据(例如,在图15的框1510中接收的虚拟化能力数据)的分配请求,如框1578所示。此外,如框1580所示,协调器服务器1220可以发送包括并发执行数据的分配请求,如框1580所示,共享虚拟存储器地址数据,如框1582所示,和/或多个加速器设备和/或加速器板的标识符,所述多个加速器设备和/或加速器板用于共享数据以执行任务(例如,通过共享的虚拟存储器地址和/或通过将数据直接从加速器设备和/或加速器板发送到另一个)。随后,方法1500循环回到图15的框1502,其中协调器服务器1220确定是否继续启用加速功能作为服务。
示例
以下提供本文公开的技术的说明性示例。这些技术的实施例可以包括下面描述的示例中的任何一个或多个,以及任何组合。
示例1包括一种计算设备,该计算设备包括:计算引擎,用于:接收针对加速任务的请求,其中该任务与如下内核相关联,所述内核能够由通信地耦合到所述计算设备的加速器板使用以执行所述任务;响应于该请求并且利用指示内核和相关联的加速器板的数据库,确定包括被配置有与该请求相关联的内核的加速器设备的加速器板;以及将所述任务分配给确定的加速器板以用于执行。
示例2包括示例1的主题,并且其中,确定包括被配置有所述内核的加速器设备的加速器板包括:确定加速器板当前没有与所述内核相关联;确定具有要被配置有所述内核的容量的加速器板;将所述内核发送到确定的加速器板进行配置;以及更新所述数据库以指示所述内核与确定的加速器板相关联。
示例3包括示例1和2中任一项的主题,并且其中,确定具有要被配置有所述内核的容量的加速器板包括:确定具有要被配置有所述内核的未使用的插槽的现场可编程门阵列(FPGA)。
示例4包括示例1-3中任一项的主题,并且其中,确定包括被配置有所述内核的加速器设备的加速器板包括:确定多个加速器板,所述多个加速器板中的每个加速器板包括被配置有所述内核的加速器设备;以及其中,所述计算引擎还用于选择被配置有所述内核并且具有满足用于执行任务的预定义阈值的利用负载的加速器板;以及其中,将任务分配给所确定的加速器板包括将任务分配给所选择的加速器板。
示例5包括示例1-4中任一项的主题,并且其中,所述计算设备通信地耦合到所述多个加速器板,并且所述计算引擎还用于:从每个加速器板接收指示与每个加速器板相关联的利用负载的数据;以及其中,选择被配置有所述内核并且具有满足用于执行任务的预定义阈值的利用负载的加速器板包括将从每个加速器板接收的数据与所述预定义阈值进行比较。
示例6包括示例1-5中任一项的主题,并且其中,接收针对加速任务的请求包括接收包括指示所述任务的特征和参数的元数据的请求。
示例7包括示例1-6中任一项的主题,并且其中,接收包括指示所述任务的特征和参数的元数据的请求包括:接收包括指示与所述任务相关联的目标服务质量的元数据的请求;其中,确定包括被配置有内核的加速器设备的加速器板包括确定多个加速器板,所述多个加速器板中的每个加速器板包括被配置有所述内核的加速器设备;以及其中,计算引擎还用于选择被配置有内核并且具有满足与用于执行任务的目标服务质量相关联的预定义阈值的利用负载的加速器板
示例8包括示例1-7中任一项的主题,并且其中,接收包括指示所述任务的特征和参数的元数据的请求包括:接收包括指示所述任务的虚拟化能力的元数据的请求。
示例9包括示例1-8中任一项的主题,并且其中,接收包括指示所述任务的特征和参数的元数据的请求包括:接收包括指示所述任务的并发执行能力的元数据的请求;以及其中,分配任务包括将任务分配给多个加速器板以用于并发执行。
示例10包括示例1-9中任一项的主题,并且其中,将所述任务分配给多个加速器板以用于并发执行包括:将分配请求发送到所述多个加速器板,其中,所述分配请求包括分配给所述任务的以使数据能够在任务被并发执行时在分配的加速器板之间共享的所述多个加速器板的标识符。
示例11包括示例1-10中任一项的主题,并且其中,将所述任务分配给多个加速器板以用于并发执行包括:将分配请求发送到所述多个加速器板,其中,所述分配请求包括所述多个加速器板可用于在任务被并发执行时在虚拟存储器中共享数据的共享虚拟存储器地址数据。
示例12包括示例1-11中任一项的主题,并且其中,接收所述请求包括:接收包括所述内核的标识符的请求;以及其中,响应于该请求并且利用指示内核和相关联的加速器板的数据库,确定包括被配置有与该请求相关联的内核的加速器设备的加速器板包括将接收到的标识符与数据库中的内核标识符进行比较。
示例13包括示例1-12中任一项的主题,并且其中,接收请求包括:接收包括内核的请求;并且其中,响应于该请求并且利用指示内核和相关联的加速器板的数据库,确定包括被配置有与该请求相关联的内核的加速器设备的加速器板包括获得所接收的内核的散列;并将散列与数据库中的内核标识符进行比较。
示例14包括示例1-13中任一项的主题,并且其中接收请求包括从执行与任务相关联的工作负载的计算板接收请求。
示例15包括一种方法,包括:由计算设备接收针对加速任务的请求,其中该任务与如下内核相关联,所述内核能够由通信地耦合到所述计算设备的加速器板使用以执行所述任务;由计算设备并且响应于该请求并且利用指示内核和相关联的加速器板的数据库,确定包括被配置有与该请求相关联的内核的加速器设备的加速器板;并且由计算设备将所述任务分配给确定的加速器板以用于执行。
示例16包括示例15的主题,并且其中,确定包括被配置有所述内核的加速器设备的加速器板包括:确定加速器板当前没有与所述内核相关联;确定具有要被配置有所述内核的容量的加速器板;将所述内核发送到确定的加速器板进行配置;以及更新所述数据库以指示所述内核与确定的加速器板相关联。
示例17包括示例15和16中任一项的主题,并且其中确定具有要被配置有所述内核的容量的加速器板包括:确定具有要被配置有所述内核的未使用的插槽的现场可编程门阵列(FPGA)。
示例18包括示例15-17中任一项的主题,并且其中确定包括被配置有所述内核的加速器设备的加速器板包括:确定多个加速器板,所述多个加速器板中的每个加速器板包括被配置有所述内核的加速器设备;并且所述方法还包括:由所述计算设备选择被配置有所述内核并且具有满足用于执行任务的预定义阈值的利用负载的加速器板;并且其中将任务分配给所确定的加速器板包括将任务分配给所选择的加速器板。
示例19包括示例15-18中任一项的主题,并且其中计算设备通信地耦合到多个加速器板,该方法还包括由计算设备并且从每个加速器板接收指示与每个加速器板相关联的利用负载的数据;并且其中选择被配置有所述内核并且具有满足用于执行任务的预定义阈值的利用负载的加速器板包括将从每个加速器板接收的数据与所述预定义阈值进行比较。
示例20包括示例15-19中任一项的主题,并且其中,接收针对加速任务的请求包括接收包括指示所述任务的特征和参数的元数据的请求。
示例21包括示例15-20中任一项的主题,并且其中,接收包括指示所述任务的特征和参数的元数据的请求包括:接收包括指示与所述任务相关联的目标服务质量的元数据的请求;并且其中确定包括被配置有内核的加速器设备的加速器板包括确定多个加速器板,所述多个加速器板中的每个加速器板包括被配置有所述内核的加速器设备;并且该方法还包括由计算设备选择被配置有内核并且具有满足与用于执行任务的目标服务质量相关联的预定义阈值的利用负载的加速器板。
示例22包括示例15-21中任一项的主题,并且其中接收包括指示所述任务的特征和参数的元数据的请求包括:接收包括指示所述任务的虚拟化能力的元数据的请求。
示例23包括示例15-22中任一项的主题,并且其中接收包括指示所述任务的特征和参数的元数据的请求包括:接收包括指示所述任务的并发执行能力的元数据的请求;并且其中分配任务包括将任务分配给多个加速器板以用于并发执行。
示例24包括示例15-23中任一项的主题,并且其中将所述任务分配给多个加速器板以用于并发执行包括:将分配请求发送到所述多个加速器板,其中,所述分配请求包括分配给所述任务的以使数据能够在任务被并发执行时在分配的加速器板之间共享的所述多个加速器板的标识符。
示例25包括示例15-24中任一项的主题,并且其中将所述任务分配给多个加速器板以用于并发执行包括:将分配请求发送到所述多个加速器板,其中,所述分配请求包括所述多个加速器板可用于在任务被并发执行时在虚拟存储器中共享数据的共享虚拟存储器地址数据。
示例26包括示例15-25中任一项的主题,并且其中,接收所述请求包括:接收包括所述内核的标识符的请求;以及其中,响应于该请求并且利用指示内核和相关联的加速器板的数据库,确定包括被配置有与该请求相关联的内核的加速器设备的加速器板包括将接收到的标识符与数据库中的内核标识符进行比较。
示例27包括示例15-26中任一示例的主题,并且其中接收请求包括接收包括内核的请求;并且其中,响应于该请求并且利用指示内核和相关联的加速器板的数据库而确定包括被配置有与该请求相关联的内核的加速器设备的加速器板包括获得所接收的内核的散列;并将散列与数据库中的内核标识符进行比较。
示例28包括示例15-27中任一项的主题,并且其中接收请求包括从执行与任务相关联的工作负载的计算板接收请求。
示例29包括一个或多个机器可读存储介质,其包括存储在其上的多个指令,其响应于被执行而使计算设备执行示例15-28中任一个的方法。
示例30包括一种计算设备,该计算设备包括用于执行示例15-28中任一示例的方法的单元。
示例31包括一种计算设备,包括:一个或多个处理器;一个或多个存储器设备,其中存储有多个指令,当由一个或多个处理器执行指令时,使得网络交换机执行示例15-28中任一示例的方法。
示例32包括一种计算设备,该计算设备包括用于接收针对加速任务的请求的网络通信器电路,其中该任务与如下内核相关联,所述内核能够由可通信地耦合到计算设备的加速器板使用以执行该任务;以及加速服务管理器电路,用于响应于该请求并且利用指示内核和相关联的加速器板的数据库,确定包括被配置有与该请求相关联的内核的加速器设备的加速器板;并将任务分配给确定的加速器板以用于执行。
示例33包括示例32的主题,并且其中,确定包括被配置有所述内核的加速器设备的加速器板包括:确定加速器板当前没有与所述内核相关联;确定具有要被配置有内核的容量的加速器板;将内核发送到确定的加速器板进行配置;以及更新所述数据库以指示所述内核与确定的加速器板相关联。
示例34包括示例32和33中任一项的主题,并且其中确定具有要被配置有所述内核的容量的加速器板包括:确定具有要被配置有所述内核的未使用的插槽的现场可编程门阵列(FPGA)。
实施例35包括实施例32-34中任一项的主题,并且其中确定包括被配置有所述内核的加速器设备的加速器板包括:确定多个加速器板,所述多个加速器板中的每个加速器板包括被配置有所述内核的加速器设备;并且其中加速服务管理器电路还用于选择被配置有所述内核并且具有满足用于执行所述任务的预定义阈值的利用负载的加速器板;并且其中将任务分配给所确定的加速器板包括将任务分配给所选择的加速器板。
示例36包括示例32-35中任一示例的主题,并且其中计算设备通信地耦合到多个加速器板,并且加速服务管理器电路还用于从每个加速器板接收指示与每个加速器板相关联的利用负载的数据;并且其中,选择被配置有内核并且具有满足用于执行任务的预定义阈值的利用负载的加速器板包括将从每个加速器板接收的数据与预定义阈值进行比较。
示例37包括示例32-36中任一示例的主题,并且其中接收针对加速任务的请求包括:接收包括指示所述任务的特征和参数的元数据的请求。
示例38包括示例32-37中任一示例的主题,并且其中接收包括指示所述任务的特征和参数的元数据的请求包括:接收包括指示与所述任务相关联的目标服务质量的元数据的请求;其中,确定包括被配置有内核的加速器设备的加速器板包括确定多个加速器板,所述多个加速器板中的每个加速器板包括被配置有内核的加速器设备;并且其中加速服务管理器电路还用于选择被配置有内核并且具有满足用于执行所述任务的与所述目标服务质量相关联的预定义阈值的利用负载的加速器板。
示例39包括示例32-38中任一项的主题,并且其中接收包括指示所述任务的特征和参数的元数据的请求包括:接收包括指示所述任务的虚拟化能力的元数据的请求。
示例40包括示例32-39中任一项的主题,并且其中,接收包括指示所述任务的特征和参数的元数据的请求包括:接收包括指示所述任务的并发执行能力的元数据的请求;以及其中,分配任务包括将任务分配给多个加速器板以用于并发执行。
示例41包括示例32-40中任一项的主题,并且其中,将所述任务分配给多个加速器板以用于并发执行包括将分配请求发送到所述多个加速器板,其中所述分配请求包括分配给任务的以使数据在任务被并发执行时能够在分配的加速器板之间共享的所述多个加速器板的标识符。
示例42包括示例32-41中任一项的主题,并且其中,将所述任务分配给多个加速器板以用于并发执行包括将分配请求发送到所述多个加速器板,其中所述分配请求包括所述多个加速器板可用于在任务被并发执行时在虚拟存储器中共享数据的共享虚拟存储器地址数据。
示例43包括示例32-42中任一示例的主题,并且其中,接收所述请求包括接收包括所述内核的标识符的请求;以及其中,响应于该请求并且利用指示内核和相关联的加速器板的数据库,确定包括被配置有与该请求相关联的内核的加速器设备的加速器板包括将接收到的标识符与数据库中的内核标识符进行比较。
示例44包括示例32-43中任一示例的主题,并且其中,接收请求包括:接收包括内核的请求;并且其中,响应于该请求并且利用指示内核和相关联的加速器板的数据库,确定包括被配置有与该请求相关联的内核的加速器设备的加速器板包括获得所接收的内核的散列;并将散列与数据库中的内核标识符进行比较。
示例45包括示例32-44中任一示例的主题,并且其中接收请求包括从执行与任务相关联的工作负载的计算板接收请求。
示例46包括一种计算设备,该计算设备包括:用于接收针对加速任务的请求的电路,其中该任务与如下内核相关联,所述内核能够由可通信地耦合到计算设备的加速器板使用以执行任务;用于响应于该请求并且利用指示内核和相关联的加速器板的数据库来确定包括被配置有与该请求相关联的内核的加速器设备的加速器板的单元;以及用于由计算设备将任务分配给所确定的加速器板以用于执行的电路。
示例47包括示例46的主题,并且其中用于确定包括被配置有所述内核的加速器设备的加速器板的单元包括:用于确定加速器板当前没有与所述内核相关联的电路;用于确定具有要被配置有内核的容量的加速器板的电路;用于将所述内核发送到确定的加速器板进行配置的电路;以及用于更新所述数据库以指示内核与确定的加速器板相关联的电路。
示例48包括示例46和47中任一项的主题,并且其中用于确定具有要被配置有所述内核的容量的加速器板的电路包括用于确定具有要被配置有所述内核的未使用的插槽的现场可编程门阵列(FPGA)的电路。
示例49包括示例46-48中任一示例的主题,并且其中用于确定包括被配置有所述内核的加速器设备的加速器板的单元包括用于确定多个加速器板的电路,所述多个加速器板中的每个加速器板包括被配置有内核的加速器设备;并且计算设备还包括用于选择被配置有所述内核并且具有满足用于执行任务的预定义阈值的利用负载的加速器板的电路;并且其中用于将任务分配给所确定的加速器板的电路包括用于将任务分配给所选择的加速器板的电路。
示例50包括示例46-49中任一项的主题,并且其中计算设备通信地耦合到多个加速器板,该计算设备还包括用于从每个加速器板接收指示与每个加速器板相关联的利用负载的数据的电路;并且其中用于选择被配置有内核并且具有满足用于执行任务的预定义阈值的利用负载的加速器板的单元包括用于将从每个加速器板接收的数据与预定义阈值进行比较的电路。
示例51包括示例46-50中任一项的主题,并且其中用于接收针对加速任务的请求的电路包括用于接收包括指示任务的特征和参数的元数据的请求的电路。
示例52包括示例46-51中任一示例的主题,并且其中用于接收包括指示任务的特征和参数的元数据的请求的电路包括用于接收包括指示与任务相关的目标服务质量的元数据的请求的电路;并且其中用于确定包括被配置有内核的加速器设备的加速器板的单元包括用于确定多个加速器板的电路,所述多个加速器板中的每个加速器板包括被配置有内核的加速器设备;并且计算设备还包括用于选择被配置有内核并且具有满足用于执行任务的与目标服务质量相关联的预定义阈值的利用负载的加速器板的电路。
示例53包括示例46-52中任一示例的主题,并且其中用于接收包括指示任务的特征和参数的元数据的请求的电路包括用于接收包括指示任务的虚拟化能力的元数据的请求的电路。
示例54包括示例46-53中任一示例的主题,并且其中用于接收包括指示任务的特征和参数的元数据的请求的电路包括用于接收包括指示任务的并发执行能力的元数据的请求的电路;并且其中用于分配任务的电路包括用于将任务分配给多个加速器板以用于并发执行的电路。
示例55包括示例46-54中任一示例的主题,并且其中用于将任务分配给多个加速器板以用于并发执行的电路包括用于将分配请求分配给多个加速器板的电路,其中分配请求包括:分配给任务的以使数据能够在任务被并发执行任务在所分配的加速器板之间共享的多个加速器板的标识符。
示例56包括示例46-55中任一示例的主题,并且其中用于将任务分配给多个加速器板以用于并发执行的电路包括将分配请求发送给多个加速器板,其中分配请求包括多个加速器板可用于在任务被并发执行时共享虚拟存储器中的数据的共享虚拟存储器地址数据。
示例57包括示例46-56中任一示例的主题,并且其中用于接收请求的电路包括用于接收包括内核的标识符的请求的电路;并且其中用于响应于该请求并且利用指示内核和相关联的加速器板的数据库来确定包括被配置有与该请求相关联的内核的加速器设备的加速器板的单元包括用于将所接收的标识符与数据库中的内核标识符进行比较的电路。
示例58包括示例46-57中任一示例的主题,并且其中用于接收请求的电路包括用于接收包括内核的请求的电路;并且其中用于响应于该请求并且利用指示内核和相关联的加速器板的数据库来确定包括被配置有与该请求相关联的内核的加速器设备的加速器板的单元包括用于获得所接收的内核的散列的电路;以及用于将散列与数据库中的内核标识符进行比较的电路。
示例59包括示例46-58中任一示例的主题,并且其中用于接收请求的电路包括用于从执行与任务相关联的工作负载的计算板接收请求的电路。
- 在分解的架构中提供加速功能作为服务的技术
- 在分解的架构中提供加速功能作为服务的技术