基于尺度特征感知和广泛感知卷积的伪装目标检测方法
文献发布时间:2024-05-31 01:29:11
技术领域
本发明属于伪装目标检测技术领域,具体涉及一种基于尺度特征感知和广泛感知卷积的伪装目标检测方法。
背景技术
伪装是生物学中一种普遍存在的现象,生物通过结构和生理特征的巧妙运用,融入周围环境,以避免捕食者的侦测。除了自然界的生物伪装外,人工伪装也相当常见。
为了检测这些完美融入环境的伪装生物和人工伪装目标,研究者们提出了多种伪装目标检测COD方法。然而,与一般目标检测GOD和显著性目标检测SOD相比,伪装目标在纹理、颜色、形状等方面与背景相似度极高,其边界与周围环境的视觉辨识度极低,因此检测伪装目标更具挑战性。
在面对伪装目标和背景对比度极低的复杂场景时,传统方法设计上高度依赖手工特征,导致模型泛化能力受限,容易受到噪声、光照、背景变化等因素的干扰,因而模型的鲁棒性相对较差。在最近几年,为了应对这些挑战,研究者们开始将深度学习技术引入伪装目标检测领域,提出了多种基于深度学习的伪装目标检测模型。
与类别相关的语义分割任务不同,伪装目标检测任务与类别无关。伪装目标检测的任务简单且易于定义。给定一张图像,该任务需要一个伪装目标检测算法来为每个像素分配一个置信度来表示像素的概率值。当置信度为0表示该像素不属于伪装目标,而置信度为1表示该像素完全属于伪装目标。
尽管现有COD方法可以增强伪装目标检测的性能,但在特征融合过程中未充分考虑全局语义信息,对多尺度特征融合方式有待提高,导致遗漏重要的特征信息,同时也使得特征之间无法充分利用互补信息,导致最终预测图的准确性不足。
发明内容
本发明提供了一种基于尺度特征感知和广泛感知卷积的伪装目标检测方法,解决了现有技术在特征融合过程中未充分考虑全局语义信息以及特征之间无法充分利用互补信息,导致最终预测的准确性不足的问题。
为了解决上述技术问题,本发明的技术方案为:一种基于尺度特征感知和广泛感知卷积的伪装目标检测方法,包括以下步骤:
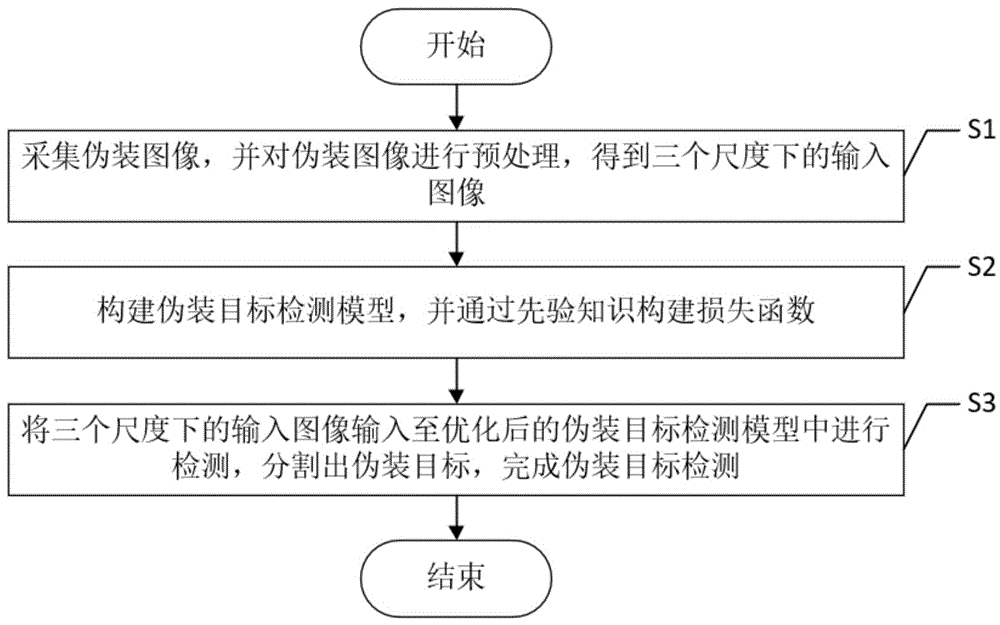
S1、采集伪装图像,并对伪装图像进行预处理,得到三个尺度下的输入图像;
S2、构建伪装目标检测模型,并通过先验知识构建损失函数;
S3、将三个尺度下的输入图像输入至优化后的伪装目标检测模型中进行检测,分割出伪装目标,完成伪装目标检测。
本发明的有益效果是:首先对伪装图像进行缩放,得到三个尺度下的输入图像,再通过共享特征编码模块提取不同缩放尺度下的特征;其次,通过尺度特征聚合模块SFAM来筛选和聚集特定尺度的特征;同时,利用特征通道交互和增强单元CIEM进一步挖掘不同尺度下目标对象和背景之间准确而细微的语义线索。最后,设计有效的广泛感知卷积EGAconv,增强全局信息的感知能力。此外,为了保证目标精准定位以及提高对困难、模糊区域检测性能,在引入动态加权的BCE损失DBCEL和引入动态加权交并比损失DIOUL的基础上,引入先验知识即不确定性感知损失UAL优化模型对不确定性区域的预测,使得伪装目标检测模型能精准地分割出伪装目标。
进一步地,所述S2中伪装目标检测模型包括依次连接的共享特征编码模块、尺度特征聚合模块SFAM、多层混合尺度解码模块以及广泛感知卷积模块。
进一步地,所述S2中损失函数的表达式为:
其中,
上述进一步方案的有益效果为:动态加权的BCE损失DBCEL和动态加权交并比损失DIOUL能够有效全面衡量目标和背景像素的差异重要性,为位于边界和结构上的像素分配通常较大的学习权重,迫使模型在优化过程中更加关注结构细节。并且采用先验知识,即不确定性感知损失UAL作为模型的监督约束,能够迫使模型增强决策的置信度并增加模糊预测的惩罚,促进模型学习困难伪装目标像素,提高检测的精度。
进一步地,所述S3的具体步骤为:
S31、将三个尺度下的输入图像输入至共享特征编码模块中,得到尺度特征
S32、将尺度特征
S33、将尺度聚合特征
S34、将解码特征输入至广泛感知卷积模块中进行通道降维,得到单通道的特征图,完成伪装目标检测。
进一步地,所述S31中共享特征编码模块的表达式为:
其中,
进一步地,所述通道压缩单元CCU的表达式为:
其中,
所述改进空洞空间卷积池化金字塔LASPP的表达式为:
其中,
上述进一步方案的有益效果为:通过共享权重策略,提取不同尺度的特征信息,再通过通道压缩单元CCU对特征进行通道对齐,实现效率与效果的良好平衡,减少模型的参数数量,降低模型的计算复杂度。而改进空洞空间卷积池化金字塔LASPP为融合有效大核可分离注意力的空洞空间卷积池化金字塔,能够放大较小特征的感受野,探索更有价值的全局语义信息。
进一步地,所述S32中尺度特征聚合模块SFAM的表达式为:
其中,
上述进一步方案的有益效果为:尺度特征聚合模块SFAM能够聚合多个尺度特征的差异化信息,为多层混合尺度解码模块提供有效、可靠的特征信息,其中,通过上采样操作与下采样操作,将1.0的尺度特征和0.5的尺度特征保持与1.0的尺度特征的大小一致,引入有效大核可分离注意力ELSKA为不同尺度下的特征分配权重,达到有效聚合该层特征的目的,即将1.0和0.5尺度下的特征聚合至1.0尺度上。
进一步地,所述有效大核可分离注意力ELSKA的表达式为:
其中,
上述进一步方案的有益效果为:本发明设计的有效大核可分离注意力ELSKA,引入可变形卷积,从而可以灵活地扭曲采样网格,使模型能够适当地适应不同的数据模式。
进一步地,所述多层混合尺度解码模块的表达式为:
其中,
当
所述特征通道交互和增强单元CIEM的表达式为:
其中,
上述进一步方案的有益效果为:特征通道交互和增强单元CIEM,能够根据每个通道的重要性重新加权输入特征图,从而增强网络对不同通道的关注程度,提高特征的表征能力,在避免降维的同时,有效地实现特征增强。
进一步地,所述S34中的广泛感知卷积模块包括依次连接的3×3广泛感知卷积EGAconv和1×1卷积;
所述广泛感知卷积EGAconv的表达式为:
其中,
上述进一步方案的有益效果为:通过解码得到的特征图具有跨层级的语义信息,采用普通卷积可能会造成部分信息的丢失,因此,通过设计广泛感知卷积EGAconv替换普通卷积,在通道降维时充分全局的位置信息,从而实现有效特征图转化,广泛感知卷积EGAconv不仅强调了感受野滑块内不同特征的重要性,而且优先考虑了感受野空间特征,彻底解决了卷积核参数共享的问题。
附图说明
图1为本发明基于尺度特征感知和广泛感知卷积的伪装目标检测方法的流程图。
图2为本发明尺度特征聚合模块SFAM的结构示意图。
图3为本发明有效大核可分离注意力ELSKA的结构示意图。
图4为本发明多层混合尺度解码模块的结构示意图。
图5为本发明特征通道交互和增强模块CIEM的结构示意图。
图6为本发明广泛感知卷积EGAconv的结构示意图。
图7为本发明在CAMO数据集上的PR曲线图。
图8为本发明在CHAMELEON数据集上的PR曲线图。
图9为本发明在COD10K数据集上的PR曲线图。
图10为本发明在NC4K数据集上的PR曲线图。
图11为本发明在CAMO数据集上的
图12为本发明在CHAMELEON数据集上的
图13为本发明在COD10K数据集上的
图14为本发明在NC4K数据集上的
图15为不同方法可视化结果示意图。
具体实施方式
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
实施例1
如图1所示,本发明提供了一种基于尺度特征感知和广泛感知卷积的伪装目标检测方法,包括以下步骤:
S1、采集伪装图像,并对伪装图像进行预处理,得到三个尺度下的输入图像;
S2、构建伪装目标检测模型,并通过先验知识构建损失函数;
S3、将三个尺度下的输入图像输入至优化后的伪装目标检测模型中进行检测,分割出伪装目标,完成伪装目标检测。
本实施例1中,对伪装图像进行预处理的公式为:
其中,
所述S2中伪装目标检测模型包括依次连接的共享特征编码模块、尺度特征聚合模块SFAM、多层混合尺度解码模块以及广泛感知卷积模块。
所述S2中损失函数的表达式为:
其中,
本实施例1中,BCE损失不加区别地和独立地对待所有像素,忽略了不同像素的贡献的差异,并且丢失了整体结构信息。其次,与背景相比,图像中属于被遮挡对象的像素是稀疏的,像素位于崎岖和狭窄的边界通常提供更多的关键信息,从背景中区分被包围的对象。
因此设计一种有效而灵活的机制来全面衡量目标和背景像素的差异重要性,本实施例1通过引入动态加权的BCE,通过为位于边界和结构上的像素分配通常较大的学习权重,迫使模型在优化过程中更加关注结构细节。
其中,
而第二超参数
此外,多个背景窗口可以更准确地估计位于不同位置的像素的难度比单个背景窗口,这应该被集成到权重分配。
以
而最小约束条件为:
其中,
所述S3的具体步骤为:
S31、将三个尺度下的输入图像输入至共享特征编码模块中,得到尺度特征
S32、将尺度特征
S33、将尺度聚合特征
S34、将解码特征输入至广泛感知卷积模块中进行通道降维,得到单通道的特征图,完成伪装目标检测。
所述S31中共享特征编码模块的表达式为:
其中,
所述通道压缩单元CCU的表达式为:
其中,
所述改进空洞空间卷积池化金字塔LASPP的表达式为:
其中,
本实施例中,S31的具体步骤为:通过主干网络SE_ResNeXt50分别提取每个输入图像的5层提取特征,将每个输入图像的5层提取特征分别输入至通道压缩单元CCU中进行通道对齐,得到0.5倍、1.0倍和1.5倍尺度下的尺度特征,即第
本实施例1中,通过主干网络SE_ResNeXt50提取到输入图像的5层提取特征,即第
而通道压缩单元CCU对输入的多层提取特征进行通道压缩对齐,对尺度较小的第5层尺度为
所述S32中尺度特征聚合模块SFAM的表达式为:
其中,
本实施例1中,在共享特征编码之后,分别获得来自1.0、0.5和1.0三个尺度下的五层特征。接下来,将同一层的三个尺度的特征输入尺度特征聚合模块SFAM,进行上采样操作与下采样操作,聚合多个尺度特征的差异化信息,得到第
如图3所示,所述有效大核可分离注意力ELSKA的表达式为:
其中,
所述多层混合尺度解码模块的表达式为:
其中,
当
所述特征通道交互和增强单元CIEM的表达式为:
其中,
本实施例1中,S33中的多层混合尺度解码模块由5个特征通道交互和增强单元CIEM构成,多层混合尺度解码模块如图4所示,其中,UP表示特征上采样操作,×2即是特征上采样操作的倍率,
而设计的特征通道交互和增强单元CIEM如图5所示,其中,
所述S34中的广泛感知卷积模块包括依次连接的3×3广泛感知卷积EGAconv和1×1卷积;
所述广泛感知卷积EGAconv的表达式为:
其中,
本实施例1中,在特征解码后,为了得到单通道的特征图。一般来说,通过普通的3×3卷积和1×1卷积即可完成通道降维。而通过解码得到的特征图具有跨层级的语义信息,采用普通卷积可能会造成部分信息的丢失。因此,设计3×3广泛感知卷积EGAconv替换普通3×3卷积,在通道降维时充分全局的位置信息,从而实现有效特征图转化,当
如图6所示,为3×3广泛感知卷积EGAconv的结构示意图,其中,输入广泛感知卷积EGAconv的特征图,通过两个分支,第一个分支进行全局平均池化、分组卷积和Softmax函数,得到感受野特征权重,第二个分支通过3×3的分组卷积得到感受野空间特征。然后,将感受野特征权重与感受野空间特征相乘,从而实现空间特征权重的重组,有效地保留了空间位置信息。再通过特征形状调整操作Reshape,调整特征形状,而由于在调整形状之后,特征的高度和宽度是3倍,需要3×3的2D卷积运算来提取特征信息,得到广泛感知卷积EGAconv的输出特征。其中,特征形状调整操作Reshape单元为特征图展开的反解,即将不同位置的特征再还原到特征图上,从而实现特征形状的调整。
广泛感知卷积EGAconv不仅强调了感受野滑块内不同特征的重要性,而且优先考虑了感受野空间特征,该方法彻底解决了卷积核参数共享的问题。利用分组卷积快速提取感受野空间特征,利用全局平均池化来聚合每个感受野特征的全局信息,然后使用分组卷积运算来交互信息,最后使用softmax来强调接收场特征中每个特征的重要性。
实施例2
本实施例2中,主干网络使用在ImageNet数据集上预训练的权重用于初始化特征权重,本发明方法的其他部分则随机初始化。本实验使用自动混合精度以加速在GPU上的训练,输入图像,使用动量为0.9,重量衰减为0.0005的SGD作为优化器。学习率初始化为0.05,使用余弦预热和余弦衰减的策略,以端到端的方式训练了60个epoch,批量大小为8。本实施例中训练数据集来自CAMO数据集和COD10K数据集,在训练和推理过程中,输入图像主尺度为384×384,将图像随机翻转和旋转用来增加训练数据。
本实施例2中,采用结构相似性度量
表1为在CAMO数据集和COD10K数据集上的性能对比表,其中,“
表1 在CAMO数据集和COD10K数据集上的性能对比表
如表1所示,与8个先进方法对比,本发明方法在结构相似性度量
为了进一步评估本发明模型的泛化性,在未训练的CHAMELEON数据集和NC4K数据集上进行模型泛化性测试,结果如表2所示,其中,表2为在CHAMELEON数据集和NC4K数据集上的性能对比表。
表2 在CHAMELEON数据集和NC4K数据集上的性能对比表
本发明方法在CHAMELEON和CHAMELEON两个数据集上均取得了最好的性能,展现了较好的泛化能力。例如,与SINet-V2在NC4K数据集上对比,本发明方法结构相似性度量
此外,如图7-图14所示,绘制了4个数据集上的PR曲线和
如图15所示,将本发明方法与其他先进方法的最终预测图像进行视觉对比,在8组图像中,包含了大目标、小目标、多目标、形状复杂、遮挡以及背景干扰等情形,其中,Image表示原始图像。通过前两列对比,本发明方法相对于其他方法,能够较好地检测出伪装目标的复杂形状,而缺失部分较少。对比第2列、第3列和第5列,本发明方法在检测不同尺度目标时不仅保留了明晰的边界,而且很少引入错误的目标像素点。对比第4列和第7列,对于多伪装目标的检测,本发明方法和ZoomNet方法引入较少的错误,并且保留了一些较小的纹理细节,可见本发明构建的模型对于多尺度的感知能力。对比第6列和第8列,当目标存在遮挡或者背景干扰严重时,本发明方法不仅有较清晰的边界,而且预测图产生的噪声较少,整体完整度更高。总的来说,在面对纹理复杂、边界模糊、小目标、遮挡以及背景复杂等多种情形时,本发明方法相对于其他方法都展现了较好的性能。
实施例3
本实施例3中,进行消融实验,从而验证本发明提出模块的有效性。针对有效大核可分离注意力ELSKA,在改进空洞空间卷积池化金字塔LASPP和尺度特征聚合模块SFAM中均有作用,因此分别拆分进行消融研究。基础网络Baseline采用空洞空间卷积池化金字塔ASPP,未采用有效大核可分离注意力ELSKA的尺度特征聚合模块SFAM用多层卷积层替换。
本实施例3中,采用Baseline、Baseline+LA、Baseline+SWL和Baseline+LA+SWL的组合方法验证有效大核可分离注意力ELSKA的有效性,如表3所示。
表3为有效大核可分离注意力ELSKA消融分析表,其中,Baseline表示基础网络,LA表示改进空洞空间卷积池化金字塔LASPP,SWL表示采用有效大核可分离注意力ELSKA的尺度特征聚合模块SFAM,Baseline+LA表示Baseline与LA共同作用时的方法,Baseline+SWL表示Baseline与SWL共同作用时的方法,Baseline+LA+SWL表示Baseline与LA和SWL共同作用时的方法。
表3 有效大核可分离注意力ELSKA消融分析表
分析上表可知,LA和SWL单独作用时,相对基础网络Baseline各个指标均有提升,当同时加入LA和SWL时指标进一步提升,由此可见有效大核可分离注意力ELSKA具有强大的感受野扩张能力。
本实施例3中,还对特征通道交互和增强单元CIEM和广泛感知卷积EGAconv进行消融分析。基础网络Baseline采用逐层上采样相加解码的方式,而将特征图转化为单通道时使用普通卷积。
并且采用Baseline、Baseline+CIEM、Baseline+EGAconv以及Baseline+CIEM+EGAconv的组合方法验证模块和设计卷积的有效性,对比结果如表4所示。
表4为CIEM和EGAconv消融分析表,其中,CIEM表示特征通道交互和增强单元,EGAconv表示广泛感知卷积,Baseline+CIEM表示Baseline与CIEM共同作用时的方法,Baseline+EGAconv表示Baseline与EGAconv共同作用时的方法,Baseline+CIEM+EGAconv表示与CIEM和EGAconv共同作用时的方法。
表4 CIEM和EGAconv消融分析表
分析上表可知,特征通道交互和增强单元CIEM和广泛感知卷积EGAconv单独作用均对模型提升有一定贡献,这可表明特征通道交互和增强单元CIEM和广泛感知卷积EGAconv的有效性。加入特征通道交互和增强单元CIEM后,各项评价指标也均有提升,尤其表现在平均强度度量
综上所述,本发明提出了一种基于尺度特征感知和广泛感知卷积的伪装目标检测方法,通过共享特征编码模块对多尺度输入图像进行特征提取。然后设计尺度特征聚合模块SFAM,将多尺度信息聚合到同一尺度,其中通过有效大核可分离注意力ELSKA为特征分配权重。接下来,通过多层混合尺度解码模块,采用逐级上采样相加完成特征图的整合,其中,通过特征通道交互进一步有效地挖掘不同通道蕴含的语义信息,进而增强特征。最后,通过广泛感知卷积模块将特征图转化为单通道的特征图。在4个公开的数据集上的实验结果表明,本发明方法相较于现有先进方法,取得了更好的检测效果。
- 一种基于频率感知的伪装目标检测方法及系统
- 基于上下文信息感知机理的夜间和伪装目标检测方法