一种基于多轮情绪分析的生成式对话系统
文献发布时间:2023-06-19 09:24:30
技术领域
本发明涉及人工智能对话系统,特别是涉及当出现多轮人机对话的多轮情绪分析的生成式对话系统。
背景技术
随着人类社会信息化的不断演进以及人工服务成本的不断上升,人们越来越希望通过自然语言与计算机进行交流,智能对话机器人系统成为这样的历史背景下诞生的产物,尤其是能够理解用户情绪,能够记忆用户的历史对话,能够记忆用户历史情绪变动,能够给用户提供个性化的服务的智能对话系统,正成为各大公司及学术研究机构研发的方向和重点。
目前已有的智能对话系统的研究中,在人机单轮对话中,机器的表现尚佳,但是在多轮对话中,就暴露出不能基于多轮对话情绪分析出当前话语具体含义的问题,如在负面情绪的情况下说出正面的话语,即正话反说,而机器只会根据单论对话进行回答,不能基于背景情绪给出一个令人满意的答复。
本发明针对此缺陷提出,解决人机对话系统不能依据用户的情绪给出准确回答的问题。
发明内容
一种基于多轮情绪分析的生成式对话系统,其特征在于使用基于深度学习的Transformer的端到端方式,研究针对多轮情绪分析的人机智能对话系统,根据用户输入的当前轮次的对话文本,联系上下文信息判断出最终情绪,给出合理的回答。
本发明提供的技术方案包括如下步骤:在编码部分,将当前轮次客户输入的信息和前几轮的信息进行编码;解码部分,首先将编码后的向量输入到解码部分,进行解码生成回复语句的第一个字,之后将编码后的向量和解码生成的字向量输入到解码部分中,直到生成最后一个字符。
附图说明
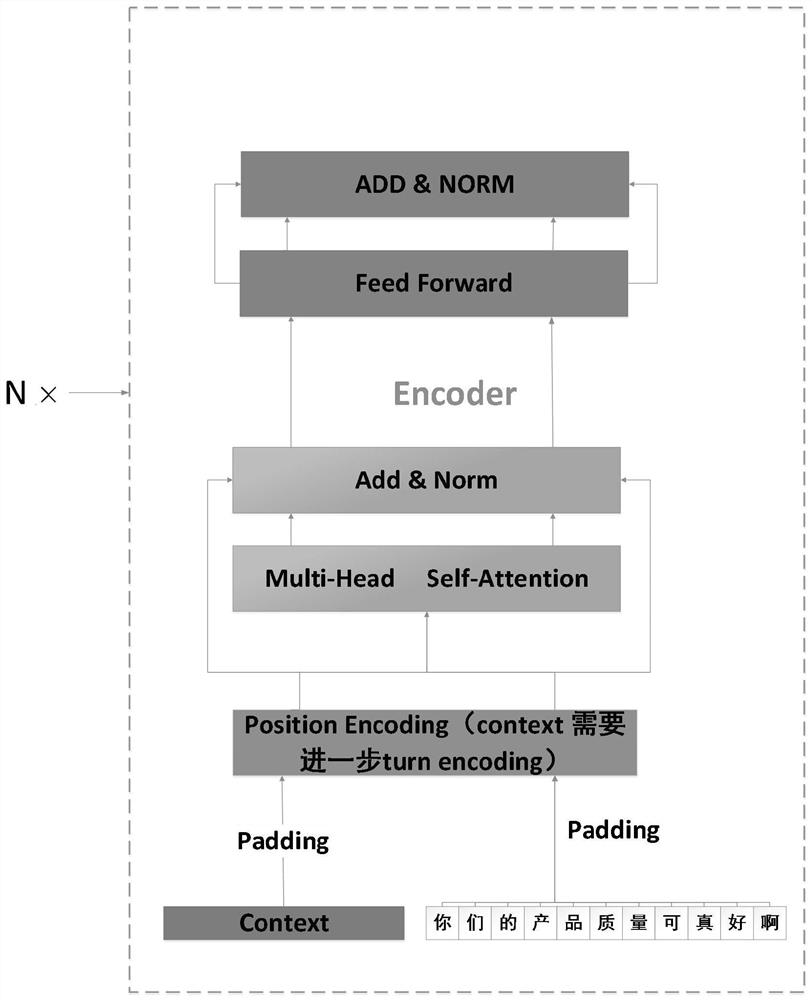
图1对话系统编码部分任务示意图。
图2对话系统解码部分任务示意图。
图3对话系统的总体示意图。
具体实施方式
第一步将当前话语与context进行字嵌入编码和位置编码,其中每个字嵌入编码的维度是常用字的维度设为4096,字向量的表示方式就是one-hot编码,即每个字向量中只有一个值为1的分量,这个1所在的槽位就是所准备的4000多个字语料库中该字的槽位。之后字嵌入编码与位置编码进行相加,位置编码的维度和字嵌入编码维度一样,句子的长度是对话语料库中最长句子中的字数,也就是每句话是用一个矩阵进行表示。然后将编码后的两个矩阵相拼接输入到Encoder层中,矩阵为当前对话和前几轮对话即context,同时将target输入到Decoder中进行掩码操作,Target是标签,即对当前话语(你们的产品质量可真好啊)的标准输出;第二步经过Encoder中的self-attentionlayer算出每个字符的注意力权重,进行残差连接和归一化操作,然后输入到Decoder中self-attentionlayer中,同时target在经过掩码后也输入到self-attentionlayer,其中编码的过程是并行的,位置顺序对self-attention没有任何影响;第三步在decoder进行解码由图中V’向量和Vi向量共同决定。
如公式1所示,其中V’表示情绪向量,是由context(前n-1轮对话)在Encoder中生成的,V指的是当前语句(如图1中,“你们的产品质量可真好啊”这句话)在Encoder中生成的起始向量,传入到Decoder,使Decoder接收到开始解码的信息,算出第一个字为‘对’时概率最大,如公式二所示,第二个字为‘不’,依此类推最后得出整句回复“对不起我们马上处理并给您一个满意的答复”。
这是在模型训练完之后的效果,模型的构造和参数以及训练过程在编码和解码部分。
Y(1)=max(P(word1|V',V,word0)) (公式1)
Y(2)=max(P(word2|V',V,word1)) (公式2)
编码部分:字嵌入操作最开始就是随机初始化后续通过学习可得到精准的字嵌入向量,位置编码是经验赋值,经验赋值公式如公式3,其中PE(pos;2i)为对偶数位置的字符进行位置编码,PE(pos;2i+1)为对奇数位置的字符进行位置编码。
输入到self-attention;当前对话进行字嵌入操作得到的输入向量为公式5,context进行字嵌入操作得到的输入向量为公式6。
在self-attention中多头注意力Q,K,V的计算为公式7~8其中Q
其中Multihead(Q,K,V)是以query,key,value矩阵为输入参数的多头注意力机制向量拼接然后乘以一个降维矩阵,降维到d
I
I
E
FFN=max(0,xW
MultiHead(Q,K,V)=Concat(head
head
解码部分:解码器的层数和编码器的层数一样,每一层也都是残差连接层,第一个残差连接的多头自注意力机制为公式13,R为每一轮的reply,第二个残差连接层的输入一部分由解码器第一个残差连接的输出和编码器的输出组成,情绪向量的多头自注意力机制为公式14,当前对话的多头自注意力机制为公式15,第三层为一个全连接的前向传播层,公式16,其中
M
预测输出优化:在生成回复语句是依据概率输出的,概率值小于1,生成的话语字数越多,概率经过连乘后,值变得越小,像“呵呵”和“我不知道”这种答复,字数少而且在任何情况下都是正确的,因此生成这样的结果概率值最大,因此采用最大相互信息MMI方式的奖惩措施,使生成这样结果的概率值降低,在给定话语S,生成回复T的概率为公式17,加入惩罚机制后生成回复T的概率为lnP(T│S),公式18为P(T)的值,为了方便对P(T)分配权重,采用公式19,g(k)的表达式为公式20,其中γ为设定的字符长度的阈值,比如说像“呵呵”,“我不知道”这样的词就小于γ,g(k)就等于1,因此新生成回复T的概率就为公式21,从而将生成万能句的概率降低。
lnP(T|S)-λlnP(T) (公式17)
logP(T|S)-λlogU(T) (公式21)
- 一种基于多轮情绪分析的生成式对话系统
- 一种基于多模态词向量的生成式对话系统编码方法及编码器