用于对声音进行分类并且训练患者的方法、计算机程序产品和设备
文献发布时间:2023-06-19 09:29:07
技术领域
本发明涉及磁共振成像领域。
背景技术
在磁共振成像(MRI)期间,声学噪声由梯度线圈产生。作为结果,患者会在MRI检查期间感觉不舒服。这样一来,许多成年人在经历MRI检查时感觉神经紧张,而儿童常常在扫描之前接收镇静或全身麻醉。年轻年龄时的麻醉/镇静会具有长期的负面健康效应。此外,在镇静的情况下的检查与清醒检查的大约三倍一样贵,而在麻醉的情况下的检查与清醒检查的九倍一样贵。
US2013/0275086Al公开了确定和/或调节磁共振检查的噪声音量的方法和磁共振装置,由此进行用于要被检查的对象的磁共振检查的磁共振序列的选择,并且在音量确定单元中使用选定的磁共振序列的协议参数进行磁共振检查的预期噪声音量的自动计算。关于预期音量的信息经由用户接口被提供给操作者。
US2013/0245364Al描述了用于降低患者在可以产生显著水平的声学噪声的医学扫描器中的医学扫描期间的焦虑的系统和方法。处理器或控制单元(CU)接收医学扫描期间的扫描器噪声(SN)的参数的变化量度(ESN),例如基于实际类型的扫描的估计的扫描器噪声水平。处理器然后根据扫描器噪声(SN)的参数的变化量度(ESN)生成到音频和视频回放单元(AS、VS)的输出(Al、Vl),所述音频和视频回放单元在扫描期间向患者相应地呈现音频-视频场景(A、V)。视频影像(V)中的图像物体(例如移动的图像物体)被联系到音频信号(A),从而转移患者的注意远离扫描器噪声(SN)。音频-视频场景(A、V)可以根据估计的扫描器噪声水平进行切换,例如在两种不同的场景之间的切换:一种用于嘈杂扫描阶段,而另一种用于安静时段。
US9557397B2公开了一种操作磁共振成像(MRI)设备以使患者和/或用户习惯于设备的操作的声学噪声的方法。所述方法包括:列出针对患者的所需脉冲序列集合(RSPS),将RSPS修改为还包括至少一个演示序列的新序列集合(NSPS),并且借助于生成脉冲序列根据NSPS进行操作。演示序列是仅仅用于声学声音习惯的冗余序列,而最初列出的RSPS用于医学读取,由此使患者和/或用户习惯于操作的声学噪声。
发明内容
在MRI期间,患者被暴露于非常大声且不熟悉的声学噪声。这些噪声在声压和谱特征方面会是非常困难的。发明人的见解是未预期的声学噪声会增加患者的焦虑。发明人的进一步见解是增加MRI检查的预测性可以减少一些患者的焦虑。减少的焦虑可以导致对于选定(年轻)患者组的麻醉或镇静的减少的需要。而且,由于减少的运动伪影,减少的焦虑可以导致一些患者的改进的图像质量。
本发明的目的是增加用于患者的MRI检查的可预测性。该目的通过独立的方法、计算机程序产品、MRI系统和设备权利要求来实现。
成为本发明的实施例下层的见解之一是,如果其MRI数据正被采集的患者提前知道什么种类的声音将由MRI系统产生,则可预测性可以增加。这能够例如通过提供要在下一时段(例如大约几秒)期间预期的声音的类型的实时可视化来实现。不同的视觉对象(visuals)或视觉元素将被分配给不同的声音类别。在特定图像采集时段之后,患者将已经学习将视觉对象与其对应的声音类别相关联。看见表示即将来临的声音的视觉对象然后将增加患者的(剩余)MRI检查的可预测性。
而且,当在此处被称为“学习”或“训练阶段”期间的实际MRI数据采集之前为患者呈现特定的MRI声音时,患者的可预测性可以增加。以这种方式,患者已经熟悉MRI系统的声音,这继而可以减少一些患者的焦虑。甚至此外,这两个方面可以被组合。学习阶段可以用于学习将某些声音与某些视觉对象或视觉元素相关联。以这种方式,患者在MRI数据采集开始的时刻熟悉视觉对象和对应的声音。通过看见表示即将来临的声音的视觉对象,对于患者增加MRI检查的可预测性。优选地,训练在等候室中、在家中或远离MRI扫描器的另一位置处被执行。
因为大多数声音由梯度系统产生,以上内容能够通过对要被发送到MRI系统的梯度系统的波形的部分进行分类来实现。该分类的目的是将波形的部分分组在一起,以形成对应于由人耳识别的声学噪声“元素”的块,并且将这些块分类成不同类型的声音的类别。这些声学噪声元素在本文中被定义为声音类别。相同声音类别的时间连接的块在本文中被为声音块。声音类别的范例是:
-咔哒声音
-敲击声音
-长啁啾声
-单调的嗡嗡声
但是其他范例可以是可能的。此外,全MRI序列也可以被认为是声音块。
本发明具有都共享相同发明构思的多个方面。然而,本发明的实施例不必被涵盖在单个方法、计算机程序产品和/或设备内。优选地,本发明的部分由单独的计算机程序产品和/或设备执行。
根据一个方面,本发明是一种用于将MRI序列的声音分类成声音类别的方法,其中,所述磁共振序列包括一个或多个声音块,其中,个体声音块具有信号特性,并且其中,具有类似特性的声音块要被分类成相同声音类别,所述方法包括以下步骤:
-接收关于要在所述MRI序列中使用的一个或多个梯度波形的信息。该信息可以例如是梯度波形本身,但是也可以是一般将具有与梯度波形类似的波形的得到的声音。而且,信息可以是MRI序列,因为MRI序列也提供关于当使用该MRI序列时将被使用的梯度波形的信息。
-使用分类算法将波形信息映射到声音类别,并且;
-将视觉对象分配给所述声音类别。
声音块可以是整个MRI序列,但是优选地单个MRI序列包括多个(时间连接的)声音块。声音块能够通过其频谱的特性来识别。
该方法能够由MRI系统例如实时执行,如将在详细描述中讨论的。备选地或额外地,所述方法能够在磁共振之前例如在MRI系统上、在独立的工作站上或在云中被执行。
根据本发明的另外实施例,所述方法还包括优选地向患者显示所述视觉对象的步骤。
根据另外的实施例,所述方法包括以下步骤:
-借助于所述MRI序列借助于MRI系统采集MRI数据,
其中,对应于特定声音块的视觉对象在通过所述MRI系统的该声音块的声学显示之前被显示。
看见对应于声音类别的视觉对象可以增加患者的MRI检查的可预测性。
根据本发明的另外的实施例,要在MRI序列中使用的一个或多个梯度波形实时地从MRI系统接收。该实施例是有利的,因为其提供在非预期的情况方面的灵活性。例如,当检查需要被暂停、停止或以任何方式被改变时,正确的视觉对象仍然将在通过MRI系统的声音块的生成之前被显示。
根据另外的方面,本发明是一种被配置用于训练患者的计算机程序产品,其中,所述计算机程序产品包括用于使计算机执行根据以上权利要求中的任一项所述的方法的步骤的程序代码模块。
根据另外的方面,本发明是一种MRI系统,其中,所述MRI系统被配置用于使用MRI序列采集MRI数据,其中,所述磁共振序列包括一个或多个声音块,其中,个体声音块具有信号特性,并且其中,具有类似信号特性的声音块被分类成相同声音类别,并且其中,不同的视觉对象被分配给每个个体声音类别,其中,所述MRI系统包括:
-梯度系统,其被配置用于产生磁场梯度,其中,所述梯度系统的使用导致声音块的产生,以及
-数据存储设备,其包括多个声音类别和被分配给所述声音类别中的每个的视觉对象;以及
-显示器或显示模块,其被配置用于在MRI系统由于梯度系统的使用而产生声音块之前的时间间隔内显示对应于声音块的声音类别的视觉对象。
优选地,在声音块由MRI系统产生之前,视觉对象被显示至少60秒。视觉对象能够以在非常大的程度上本领域中已知的许多不同方式被显示。例如,视觉对象能够被显示在显示器上或通过使用(虚拟现实)眼镜被显示,但是其也可以以其对患者可见的这样的方式被投影在例如检查室的壁上,使得其能够被患者观察,同时正在MRI系统中时,例如通过使用镜子。视觉对象也可以被投影在MRI系统的膛中。
根据本发明的另外的实施例,所述MRI系统还包括:
-用于监测将要被发送给所述梯度系统的梯度波形的模块,以及
-被配置用于将波形信息映射到声音类别的分类模块。
该实施例是有利的,因为通过实时监测梯度波形,实施例在未预期的情况下提供灵活性。例如,当检查需要被暂停、停止或以任何方式被改变时,正确的视觉对象仍然将在通过MRI系统的声音块的生成之前被显示。
根据另一实施例,所述MRI系统包括具有用于所述MRI序列中的一个或多个的视觉绘制的存储设备,其中,所述视觉绘制包括所述视觉对象中的一个或多个,其中,所述MRI系统被配置为使所述视觉绘制与选定的MRI序列同步,并且在借助于选定的MRI序列的MRI采集期间显示所述视觉绘制。
根据本发明的另外的方面,本发明是一种用于训练患者来将不同的视觉对象与不同的声音类别进行关联以便增加用于所述患者的未来MRI检查的可预测性的方法,其中,所述MRI检查包括一个或多个磁共振序列,其中,所述一个或多个磁共振序列包括一个或多个声音块,其中,个体声音块具有信号特性,并且其中,不同的视觉对象被分配给每个个体声音类别,其中,声音类别和视觉对象的类似组合被规划为在所述患者的未来磁共振检查中使用,其中,所述方法包括以下步骤:
-接收包括多个声音类别和被分配给所述声音类别中的每个的视觉对象的数据,并且;
-同时或在小于60秒的时间间隔内向所述患者提供来自声音类别的声音和被分配给所述声音类别的视觉对象。
更优选地时间间隔小于50秒,甚至更优选地其小于30秒,甚至更优选地其小于20秒,甚至更优选地其小于10秒,甚至更优选地其小于10秒,甚至更优选地其小于5或小于1秒。时间间隔应当至少足够长以使用户配准视觉对象,并且其应当足够短以将视觉对象与声音类别关联。
该方面是有利的,因为借助于所述方法,患者可以已经变得熟悉MRI特异性声音,这可以增加磁共振检查的可预测性,并且因此可以减少一些患者的焦虑。此外,通过使患者学习将某些视觉对象与特定的声音或声音类别相关联,当相同的视觉对象用于针对即将来临的声音通知患者时,MRI检查的可预测性可以进一步增加。这能够例如借助于电影来实现,其中,视觉对象被显示,同时来自其被分配给的声音类别的声音同时或在某些时间间隔内被播放。备选地或额外地,该方面能够以游戏的形式被实施。下面描述了此类游戏的范例。
根据本发明的实施例,所述方法还包括以下步骤:
-向所述患者提供多个所述视觉对象,并且;
-接收来自所述患者的用户输入,其中,所述用户输入包括来自所述多个视觉对象中的视觉对象的选择,并且;
-响应于向所述患者提供声音的所述用户输入,其中,所述声音是来自选定视觉对象被分配给的声音类别的声音。
该实施例可以是有利的,因为它是更交互的,并且因此对于(儿科)患者而言会是更令人愉快的。这可以导致更好地参与训练并且因此导致改进的训练结果。例如,可以为患者提供显示视觉对象的多个按钮。患者可以使用按钮来播放音乐,或者基于他自己的创造力或通过重新播放歌曲或遵循指令。如对本领域技术人员而言将显而易见的,此类按钮可以在许多不同种类的游戏中使用。按钮可以是真实按钮或计算机程序产品(如例如app)中的按钮。
根据另外的方面,本发明是一种被配置用于训练患者的计算机程序产品,其中,所述计算机程序产品包括用于使计算机执行根据以上内容的方法的步骤的程序代码模块。
根据另外的方面,本发明是一种用于训练患者来将不同的视觉对象与不同的声音类别进行关联以便增加用于所述患者的未来MRI检查的可预测性的设备,其中,所述MRI检查包括一个或多个磁共振序列,其中,所述一个或多个磁共振序列包括一个或多个声音块,其中,个体声音块具有特定的信号特性,并且其中,不同的视觉对象被分配给每个个体声音类别,其中,声音类别和视觉对象的类似组合被规划为在所述患者的未来磁共振检查中使用,其中,所述设备包括:
-多个输入接收模块,其被配置用于接收来自患者的输入,其中,所述输入接收模块中的每个显示所述不同的视觉对象之一,以及;
-声音产生模块,其被配置用于响应于从由用户选择的输入接收模块接收的用户输入而产生声音,其中,产生的声音是对应于被显示在用户选定的输入接收模块上的视觉对象的声音类别中的声音。
设备可以例如是(教育)玩具。该实施例是有利的,因为其可以刺激(年轻)患者参与训练。声音产生模块可以例如包括扬声器。
根据本发明的实施例,所述视觉对象在一个或多个方向上的尺寸至少基于以下参数中的任一个被改变:所述声音块的持续时间、所述声音的强度、中心频率。该实施例是有利的,因为其提供关于即将来临的声音的更多信息。这可以进一步增加患者的MRI检查的可预测性。
参考下文所述的实施例,本发明的这些方面和其他方面将显而易见并且得到阐述。
附图说明
图1图解地示出了根据本发明的实施例的系统的基本设置,并且;
图2图解性地示出了根据本发明的实施例的处理流程,并且;
图3示出了潜在可视化的两个范例;
图4图解性地示出了根据本发明的其他实施例的系统,并且;
图5示出了用于实施本发明的实施例的可能扫描阶段系统架构,并且;
图6图解性地示出了能够在训练阶段中使用的产品的两个范例。
具体实施方式
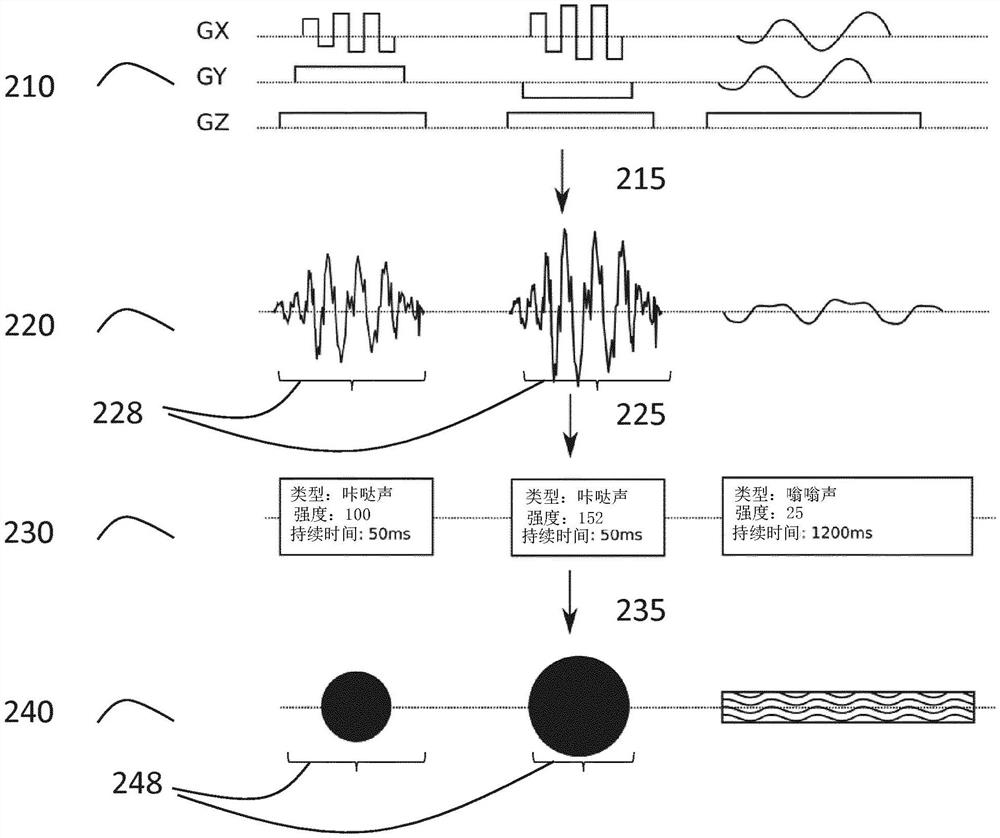
图1图解性地示出了根据本发明的实施例的系统的基本设置。该系统包括MRI系统控制单元120。MRI系统控制单元(扫描器主机)根据选定的MRI序列计算梯度波形。这些波形被发送到梯度放大器110,并且得到的梯度电流被引入到梯度线圈,从而产生不同类型的声音。梯度系统是MRI系统105的部分。设置的该部分表示磁共振梯度控制的目前普通实施方式。本发明的实施例提出了延伸具有接口122的扫描器主机以访问计算的(未来)梯度波形和其(精确)定时,包括当波形将被应用时的(绝对)时间。接口122在扫描器操作期间可访问,并且将递送关于目前预期的未来波形的信息。如果扫描被放弃或扫描参数在开始扫描之前被改变,则关于预期的梯度波形的信息被实时更新。
关于梯度波形的信息首先由预测模块130处理。预测模块被配置用于将波形信息映射到声音。这可以例如借助于包含计算对梯度波形的力学响应的梯度线圈(并且可能地其周围元件)的磁-力学模型来实现。这种力学响应能够用作听得见的声音的预测。力学响应的计算可以单独地根据针对三个梯度方向中的每个的频率和幅度来执行。MRI序列的整个响应然后能够通过对于所有涉及的频率的响应的线性叠加来模拟。该系统能够使用耦合的磁力学微分方程来建模,所述磁力学微分方程可以利用可用Multiphysics工具箱来求解。商业Multiphysics产品的范例是ANSYS和COMSOL。
关于听得见的声音的信息然后由分类模块140处理。这种分类的目的是将波形的部分分组在一起以形成对应于由人耳识别的声音类别的块,并且将这些块分类成不同类型的声音的类别。
噪声块类别的范例是:
-咔哒声音
-敲击声音
-长啁啾声
-单调的嗡嗡声
-等等
能够通过已知的特征(诸如功率和中心频率)到先前定义的类别集合的映射或通过使用机器学习以基于由人标记的声音块的测试数据集执行这种映射来进行分类。在定义或创建声音类别之后,不同的视觉对象将被分配给不同声音类别中的每个。
应当注意,一些类型的算法(例如基于人工智能的算法)可以能够直接将波形信息分类成声音类别而无需单独的预测模块130。
声音分类算法可以包括两个步骤:
1.可能由安静(声音块)分离的不同的块的识别,以及
2.个体声音块的分类。
而且,算法可以是更简单的。算法可以例如直接将视觉对象分配给一种类型的序列,例如将正方形分配给T1w序列,而将三角形分配给FLAIR序列。
除了声音类别之外,每个声音块可以被分配声音强度值以及块的开始和结束的绝对时间戳。声音块可以例如通过以下数据集来描述:开始时间、结束时间(备选地:持续时间)、声音类别和任选地声音参数(例如,强度、中心频率)。使用预期的和先前的声音块(例如,覆盖相对于当前时间的+/-10、20、30、40、50或60秒的时间跨度),可视化引擎150将块和其性质转变为要在显示设备155上被呈现给患者的视觉物体(视觉对象)。可视化也可以包括表示当前时间的标记。可视化可以被实时更新,即视觉物体跨屏幕移动,向患者示出哪些声音块要被预期以及何时预期它们。
图2图解性地示出了根据本发明的实施例的处理流程。在该范例中,MRI序列210产生咔哒和嗡嗡声音220。这些声音215能够借助于预测模块130来预测。这些声音能够被识别为声音块228。声音块能够被分类225为声音类别230,并且然后被变换235成被分配给声音类别的可视化物体或视觉对象248。
可视化240能够具有许多不同的形状。图3示出了潜在可视化的两个范例。图3A示出了移动时间线可视化,其中,声音块301a、301b、302被可视化为从右向左移动的符号。箭头312指示移动的方向。垂直线310指示当前的移动,使得当前跨线的符号对应于在相同时刻听得见的声音。声音块的类型和强度(或其他性质)在符号的形状、尺寸和填充类型方面进行编码。例如声音块301a和301b属于相同的声音类别,但是其尺寸不同。尺寸上的差异可以用于例如指示声音块301b的声音的强度大于301a的强度。除了声音时间线,其他信息314能够被显示,诸如剩余扫描时间。
图3B示出了声音块321、322的另一可能的可视化。声音块以提醒计算机游戏的方式被映射到视觉物体(视觉对象)。在该范例中,时间通过沿着道路行驶来表示。箭头312指示可视化的运动的方向。当前时刻通过更低的边缘(或备选地,道路上的汽车)来指示。声音块以减速措施、不同的道路表面等的形式出现。噪声块(诸如强度)的性质还能够在这些物体的尺寸、其颜色或其视觉外观方面进行编码。这种可视化不仅让患者预期噪声,其还可以使噪声出现更自然,因为它们被连接到已知的视觉场景。
图4图解性地示出了根据本发明的其他实施例的系统。通常,医院具有针对不同解剖结构和临床问题的扫描协议。取决于被布置用于MRI检查的扫描协议,患者将被暴露于不同的MRI序列,并且因此,被暴露于不同的声音类别。根据本发明的实施例,当MRI检查被布置时,医疗保健提供者(例如,儿童生活专家或转诊医师)借助于协议选择器412在临床医师仪表板410中选择或录入规划的协议。仪表板被连接到处理单元420,处理单元420接收选定的协议作为输入并且基于具有协议和相关联的脉冲序列的数据库(未在图4中示出)将那些转换为脉冲序列。随后,算法基于其听觉相似度422将为所有选定的脉冲序列的部分的所有脉冲聚类在一起,并且然后在其在规划的时段424中发生的频率的基础上对对应的声音类别进行排名。前N个发生声音类别被传输到患者面对的app/玩具(430和图6600),其中,N优选地等于可用于患者在app/玩具430上按压的符号按钮图6,602的数量。app/玩具针对每个选定的声音类别显示相关联的符号和声音432,并且然后当符号按钮中的一个被按压时呈现适当的声音。符号与脉冲之间的关联以后在扫描阶段中被再次使用。声音类别和其分配的视觉对象被存储在app/玩具430中的存储设备434中。
在学习阶段来到扫描阶段之后,在此期间患者在MRI扫描器的膛中。在该阶段期间,患者接收关于当前正被执行的序列的实时反馈。此外,可以向他们呈现关于将在此之后被执行的序列的信息。图5示出了用于实施本发明的实施例的可能扫描阶段系统架构。该系统包括MRI技术控制台510、处理单元520和(膛内的)显示器或显示模块530。
在扫描阶段开始之前,MR技术人员设置时段并且安排相关的脉冲序列512。系统520将安排的脉冲序列输入到处理单元520内,处理单元520由以下三个元件组成:
1.数据库522,其存储有用的资源(视觉对象,例如,如符号和/或注释的图像,取决于实施例)和其与特定脉冲的关联(与在学习阶段的数据库中相同的关联);
2.缓冲器524,其被填充有准备好在需要时被传输到膛内显示器的规划的脉冲序列的视觉绘制;以及
3.选择器机构526,其根据MRI技师决定执行哪个脉冲序列来选择缓冲器中的哪个绘制被传输到(膛内)显示器。
一旦安排的脉冲序列被加载到处理单元中,每个脉冲序列基于存在于序列中的特定脉冲、其时间顺序、其定时和可能其他性质(诸如响度、音高或主观不适)被自动转换成视觉绘制。这些视觉绘制与MRI序列同步。时间脉冲的视觉绘制连同将它们匹配于特定序列的id一起被存储在时段缓冲器中。
当扫描阶段开始时,MR技术人员在MRI技术控制台512中发起第一脉冲序列。这被提前传递到处理单元520。处理单元继而从缓冲器524选择与脉冲序列相关联的视觉绘制,并且将其传输到控制(膛内)显示器的单元,所述显示器继而在脉冲序列开始的时刻显示视觉绘制524。
在训练完成之后,MRI技术人员可以决定继续下一规划的脉冲序列,或重复先前的序列514(例如,因为在扫描期间存在过度移动,从而导致降低的图像质量)。下一序列(规划的或任何先前的序列)然后恰好在它被发起之前被传递到处理单元。如上面描述的相同逻辑针对每一个脉冲序列被重复,直至所有规划的序列和未规划的重复都已经完成并且该时段由MR技术人员终止。
图6图解性地示出了能够在训练阶段600、软件应用610和物理设备620中使用的产品的两个范例。在一些实施例中,在学习阶段期间,游戏用于向患者教导MRI-声音与视觉对象之间的关系601。声音块可以是整个MRI序列,但是优选地,这些声音块是对应于由人耳识别的声音类别的波形组。声音块能够通过其频谱的特性来识别。
所使用的视觉对象602a、602b能够充当按钮,并且用户可以通过按压这些按钮并组合声音来创建音乐,类似于儿童的音乐玩具。物理设备(玩具)还包括声音产生模块604(例如扬声器)以便产生声音。此外,物理设备包括数据存储设备,所述数据存储设备包括声音类别或针对声音类别的声音表示和其到被分配给它们的视觉对象的联系。该设备可以被制作为使得新的数据能够被容易上传到设备,以便使设备适合于不同的MRI检查和其相应的声音。软件应用或物理设备620能够被制作为在医院的等候室中可用,或能够被提供给患者以在家中使用。每当(儿科)患者按压音乐玩具上的按钮时,伴随的额MRI-声音被生成。代替于使用任意的符号,符号也可以被联系到声音的频率和/或音高。例如,声音类别能够以与在声音类别中的声音中相同的频率与人物跳绳的动画相关联。
图6此外示出了扫描阶段650。与在训练阶段期间使用的相同的视觉对象652在扫描期间被使用。
而且,软件应用610或物理设备620可以用于显示电影,其中,电影中的视觉对象被显示,同时来自其被分配给的声音类别的声音同时或在特定时间间隔内被播放。
用于特定患者的视觉对象与声音块之间的关系可以被存储。以这种方式当患者来进行重新扫描或随访时,相同的视觉对象/声音块组合可以被使用。
尽管已经在附图和前面的描述中详细图示和描述了本发明,但是这样的图示和描述应当被认为是说明性或示范性的,而非限制性的;本发明不限于所公开的实施例。
- 用于对声音进行分类并且训练患者的方法、计算机程序产品和设备
- 用于对不透明介质的内部进行光学成像的方法、用于重建不透明介质内部的图像的方法、用于对不透明介质的内部成像的设备、医疗图像采集设备以及用于所述方法和设备中的计算机程序产品