日志解析方法及解析装置
文献发布时间:2023-06-19 10:38:35
技术领域
本申请属于信息安全技术领域,具体涉及一种日志解析方法及解析装置。
背景技术
当今的企业和组织在信息安全领域面临比以往更为复杂的日志环境,具体表现在,一方面日志没有统一规范,另一方面不同企业和组织有特殊的日志需求,日志种类在夜以继日的增多。分析繁杂的日志时,需要根据具体的日志编写对应的解析规则,这无疑是一项枯燥,繁琐的工作,需要投入大量的人力和物力。
发明内容
为至少在一定程度上克服相关技术中存在的问题,本申请提供了一种日志解析方法及解析装置。
根据本申请实施例的第一方面,本申请提供了一种日志解析方法,其包括以下步骤:
获取日志;
事件处理引擎对日志进行处理,其中,事件处理引擎包括解析规则库和智能解析引擎;事件处理引擎对日志进行处理过程为:
遍历解析规则库中的全部解析规则,为获取的日志匹配对应的解析规则;
如果解析规则库中不存在该日志对应的解析规则,则将该日志发送给智能解析引擎进行处理;
智能解析引擎为接收到的日志组合出完整的正则表达式,并将正则表达式与该日志进行匹配;
对于智能解析引擎未能解析出预设目标字段的日志,通过页面半智能解析工具为日志文件生成解析规则。
上述日志解析方法,还包括以下步骤:
维护标识库,其具体包括:
在标识库中添加标识;对标识库进行初始化。
上述日志解析方法中,所述智能解析引擎为接收到的日志组合出完整的正则表达式,并将正则表达式与该日志进行匹配包括以下步骤:
对日志进行拆解,得到准特征值数组;
对准特征值数组进行降噪;
对降噪后的准特征值数组中的特征值进行识别,并将识别出的特征值与标识库中的标识表达式进行匹配;
将识别出的特征值与标识表达式进行组合,得到该日志对应的正则表达式。
进一步地,所述对日志进行拆解,得到准特征值数组的具体过程为:
通过自然语言对日志进行一次拆解,得到日志对应的字符数组;
通过符号类型对字符数组中的字符进行二次拆解,得到新的字符数组;
对新的字符数组进行三次拆解,其过程为:
对二次拆解得到的新的字符数组进行重新遍历,根据内置符号对新的字符数组中的字符串进行重组,并通过ipv6正则、mac地址正则进行校验,得到准特征值数组。
进一步地,所述对降噪后的准特征值数组中的特征值进行识别的过程为:
将降噪后的准特征值数组中的准特征值与缓存的标识库中的标识值进行匹配,如果标识库中存在与降噪后的准特征值匹配的标识值字段,则将该准特征值识别为特征值。
进一步地,所述将识别出的特征值与标识表达式进行组合,得到该日志对应的正则表达式的过程为:
将识别出的特征值和标识表达式用[\S\s]*和[\S\s]+?进行连接,并按顺序组合成完整的正则表达式。
上述日志解析方法中,所述对于智能解析引擎未能解析出预设目标字段的日志,通过页面半智能解析工具为日志文件生成解析规则的具体过程为:
编写解析规则,其包括:
将日志拆解成各字段,并为拆解后的字段设置一一对应的数字标志,所述数字标志用于排序;
自动遍历拆解后的各字段,将拆解后的各字段与标识库中的标识表达式进行匹配,得到匹配的结果字段;
如果结果字段不是操作人员需要的目标字段,则操作人员通过人机交互对需要的目标字段和标识表达式进行配置,根据数字标志关系对象、标识表达式关系对象、事件属性关系对象和二次匹配对象,按照对应关系和顺序将标识表达式拼接组合成完整的正则表达式。
进一步地,所述在标识库中添加标识的具体过程为:
通过标识库管理页面手动添加标识;
通过机器学习算法丰富标识库,其过程为:
当操作人员通过半智能解析工具保存解析规则文件时,后台程序对保存对象中的特征值和标识表达式进行以下处理:
符合标识库规则的标识先放入机器学习中间表,并对标识的使用频率进行计数;
后台程序预设默认次数,如果标识的使用频率大于或等于默认次数,判定此标识的用户使用频率较高,将其放入标识库并加载到缓存中。
进一步地,所述对标识库进行初始化的过程为:
类型归类:
智能解析引擎使用时将加载缓存数据,加载缓存数据时对标识进行归类;
特征归类:
标识表达式在标识库中有两种格式,一种是存在标识值的格式,一种是不存在标识值的格式;后台程序通过hash算法对标识是否存在标识值进行判断,进而进行区分存储;
标识排序:
通过排序算法按照匹配优先级对标识进行排序。
根据本申请实施例的第二方面,本申请还提供了一种日志解析装置,其包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器;所述处理器用于运行所述计算机程序时执行上述任一项所述日志解析方法中的各步骤。
根据本申请的上述具体实施方式可知,至少具有以下有益效果:本申请能够对复杂日志进行智能解析处理;本申请日志解析方法具有以下特点,信息丰富:能够精确的提取日志信息;处理能力强:能够更快的解析出日志信息;入门成本低:不需要学习正则编写,只需了解页面操作即可;编写耗时低:单条日志编写可以实时查看结果,不需要反复验证,降低实施周期;维护成本低:只需要了解页面操作,任何人都可以进行解析规则的编写;本申请能够极大地节省人力和物力。
应了解的是,上述一般描述及以下具体实施方式仅为示例性及阐释性的,其并不能限制本申请所欲主张的范围。
附图说明
下面的所附附图是本申请的说明书的一部分,其示出了本申请的实施例,所附附图与说明书的描述一起用来说明本申请的原理。
图1为本申请具体实施方式提供的一种日志解析方法的流程图之一。
图2为本申请具体实施方式提供的一种日志解析方法的流程图之二。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚明白,下面将以附图及详细叙述清楚说明本申请所揭示内容的精神,任何所属技术领域技术人员在了解本申请内容的实施例后,当可由本申请内容所教示的技术,加以改变及修饰,其并不脱离本申请内容的精神与范围。
本申请的示意性实施例及其说明用于解释本申请,但并不作为对本申请的限定。另外,在附图及实施方式中所使用相同或类似标号的元件/构件是用来代表相同或类似部分。
关于本文中所使用的“第一”、“第二”、…等,并非特别指称次序或顺位的意思,也非用以限定本申请,其仅为了区别以相同技术用语描述的元件或操作。
关于本文中所使用的“包含”、“包括”、“具有”、“含有”等等,均为开放性的用语,即意指包含但不限于。
关于本文中所使用的“及/或”,包括所述事物的任一或全部组合。
关于本文中的“多个”包括“两个”及“两个以上”;关于本文中的“多组”包括“两组”及“两组以上”。
某些用以描述本申请的用词将于下或在此说明书的别处讨论,以提供本领域技术人员在有关本申请的描述上额外的引导。
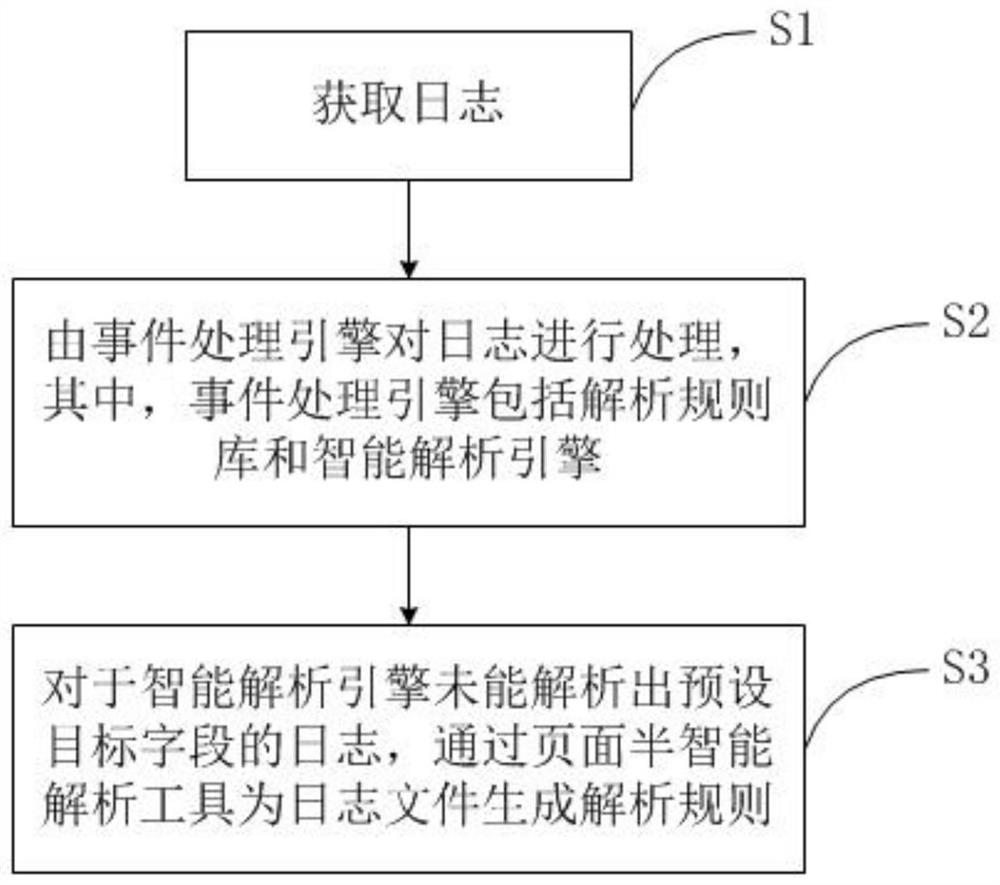
图1为本申请具体实施方式提供的一种日志解析方法的流程图之一。图2为本申请具体实施方式提供的一种日志解析方法的流程图之二。如图1和2所示,本申请提供的日志解析方法包括以下步骤:
S1、获取日志;
通过syslog方式获取需要接入的设备的日志,或者通过配置采集任务采集数据库、应用、邮件服务器、主机和其他设备的文本类日志。
S2、由事件处理引擎对日志进行处理,其中,事件处理引擎包括解析规则库和智能解析引擎,其具体过程为:
S21、遍历解析规则库中的全部解析规则,为获取的日志匹配对应的解析规则;
如果解析规则库中存在该日志对应的解析规则,则停止遍历,向日志库返回一个事件对象,并自动学习,将该日志对应的设备地址和对应的解析规则进行绑定。
如果解析规则库中不存在该日志对应的解析规则,则停止遍历,向日志库返回一个空对象,并将该日志发送给智能解析引擎进行处理。
S22、智能解析引擎组合完整的正则表达式,并将正则表达式与日志进行匹配,其具体过程为:
S221、日志拆解;
对日志进行拆解,得到一准特征值数组,其具体过程为:
通过自然语言对日志进行一次拆解,得到日志对应的字符数组;
具体地,使用Netbeans(开源软件开发集成环境)搭载JDK1.8(JDK是Java语言的软件开发工具包)环境编程,实现基于概率最大化的分词算法,生成日志对应的字符数组。
通过符号类型对字符数组中的字符进行二次拆解,得到新的字符数组;
具体地,对字符数组进行遍历,通过符号对字符数组中的字符进行二次拆解,具体过程为:判断字符数组中的各字符是否是符号类型;如果字符数组中的某字符是符号类型,则向前查找距离该字符最近的字符,将该字符与查找到的字符组合成新的字符串,遍历整个字符数组,最后输出组合成的新的字符数组。
需要说明的是,对于字符数组中的有些符号不做拆解,对其进行独立判断,这些符号可以为_、-、.、%、\、/和:等。通过符号对字符数组中的字符进行二次拆解中的符号指不包括_、-、.、%、\、/和:在内的所有符号。
对新的字符数组进行三次拆解;
考虑ipv6及mac地址等特殊要求,对二次拆解得到的新的字符数组进行重新遍历,根据内置符号对新的字符数组中的字符串进行重组,并通过ipv6正则、mac地址正则进行校验,得到准特征值数组。其中,内置符号可以为冒号、分号等。此次拆解能够对字符串中不需要拆解的字符进行重组。例如,字符数组中字符串SERSIP:192.168.1.1经过二次拆解被拆解成SERSIP:192、168、1、1,其中IP地址是不需要拆解的,通过三次拆解,能够将不需要拆解的192、168、1、1重组成192.168.1.1。
通过对日志进行三次拆解,能够将数据精细化,便于后续操作。
S222、降噪;
对步骤S221得到的准特征值数组进行遍历过滤,排除字段类型为IP类型、Mac类型和数字类型的字段。需要说明的是,此处的排除是指不进行本次流程处理,从而减少处理量。
S223、特征值识别;
将步骤S222降噪后的准特征值数组中的准特征值与缓存的标识库中的标识值进行匹配,如果标识库中存在与降噪后的准特征值匹配的标识值字段,则将该准特征值识别为特征值,通过校验特征值的方式获取该特征值,并将该特征值与标识库中的标识表达式进行匹配。
S224、表达式组合;
对步骤S223得到的特征值和标识表达式用[\S\s]*和[\S\s]+?进行连接,并按顺序组合成一个完整的正则表达式。例如,对于字符串SERSIP:192.168.1.1,其完整的正则表达式可以为SERSIP:[\S\s]+?,IP地址的正则表达式,SERSIP:name,[\S\s]*。其中,name在标识库中不存在与其匹配的标识值字段。
S225、正则匹配;
将步骤S224组合后得到的正则表达式及其对应的日志进行匹配,生成事件对象后进行存储,具体地,可以存储至数据库中,例如Elasticsearch。
S226、日志归类;
采用步骤S221和S222的方法对下一条日志进行拆解和降噪处理;
采用相似度算法对下一条日志降噪后得到的准特征值与当前条日志对应标识库中的标识值进行对比,如果二者的匹配度大于或等于90%,则判定下一条日志与当前条日志属于同一类,可以采用当前条日志对应的正则表达式对下一条日志进行解析。
S3、对于智能解析引擎未能解析出预设目标字段的日志,通过页面半智能解析工具为日志文件生成解析规则,其具体包括以下步骤:
S31、编写解析规则,其具体过程为:
S311、字段拆解和区分显示;
将获取的日志带入日志样本框中,通过自然语言和拆解算法,采用与步骤S221相同的方法,将日志拆解成一个个字段,并对拆解后的字段设置一一对应的数字标志,该数字标志用于排序。数字标志可以存储在前台对象中。拆解后的字段可以用不同的预设颜色在人机交互界面中进行显示,以便于操作人员进行查看。
S312、智能查找目标字段;
自动遍历步骤S311中拆解后的字段,将拆解后的字段与标识库中的标识表达式进行匹配。
为提高匹配速度,匹配前模糊判断该字段的类型。其中,字段的类型包括时间类型、MAC类型、IP类型、源地址和目标地址等。对于时间类型、MAC类型和IP类型这类较高命中类型进行优先匹配,对于源地址和目标地址这类较低命中类型进行次一级匹配。
为增加匹配的准确度,优先匹配标识库中存在标识值的标识表达式,再匹配不存在标识值的标识表达式。
将匹配成功的结果返回前端界面,并将标识表达式和对应的字段存放在前台对象中。对在前端界面上匹配成功的字段进行标黄突出显示,并将匹配的结果字段以列表的方式展示,以便于操作人员进行下一步操作。
S313、操作人员进行配置操作;
如果查找到的字段不是操作人员需要的目标字段,操作人员可以通过前端界面删除该查找到的字段。删除后,该字段不再进行标黄显示,并在列表中消失。同时,在前台对象中删除该字段与标识表达式的对应关系。
操作人员通过在前端界面拖动鼠标划选目标字段:
后台程序根据划选的目标字段优先从标识库中寻找标识表达式,如果无法找到对应的标识表达式,则利用程序内置的几种表达式匹配该目标字段。其中,程序内置的几种表达式可以为\s匹配空白字符,包括空格、制表符、换页符等;\d匹配数字字符;\w匹配包括下划线的任何单词字符,等价于“[A-Za-z0-9]”。完成后将结果返回前端界面,并将标识表达式和目标字段存放在前台对象中,并对目标字段进行标黄突出显示,目标字段在列表上展示,以便于操作人员进行下一步操作。
拖选特征值:
操作人员可以拖选结果列表上的目标字段。支持两种方式拖选:一种是从头部拖选,将目标字段分割成两部分:特征值和目标字段;对应的正则表达式为:特征值和标识表达式。另一种是从中间拖选,将目标字段分割成三部分:特征值、通配表达式和目标字段,对应的正则表达式为特征值、[\S\s]{n}和标识表达式。其中,[\S\s]{n}表示正则表达式中的通配符。
选择事件属性:
操作人员划选出目标字段后,需要为目标字段绑定事件属性。在绑定之前,后台程序通过模糊匹配目标字段的类型,为操作人员提供相应类型的事件属性。绑定完成后,后台程序将目标字段和事件属性的对应关系存在到前台对象中,同时在前端界面实时结果区域进行展示,以便于操作人员实时查看。
操作人员完成绑定后,可为此事件属性填写默认值,当匹配为空时,将该默认值作为结果值。或者为目标字段配置二次匹配,后台程序支持两种方式进行结果值转换:一种为字典匹配,该匹配方式以key-value形式存放,将key转换成value,key为固定值;另一种为正则匹配,该匹配方式以match-value形式存放,当match匹配的结果不为空时,将match匹配的结果作为结果值。当match匹配的结果为空时,将value作为结果值。
解析规则生成:
当操作人员选取配置完成后,点击保存,以上存放的数字标志关系对象、标识表达式关系对象、事件属性关系对象,二次匹配对象等传给后台程序,后台程序按对应关系和顺序将标识表达式拼接组合成一个完整的表达式,并使用组合算法将以上配置的默认值、事件属性关系、二次匹配等生成解析规则文件。
S32、启停解析规则;
利用页面规则启停的方式,通过是否要将解析规则加载到缓存中控制事件处理引擎中的规则是否生效以及事件处理引擎中规则的数量。
本申请提供的日志解析方法还包括以下步骤:
S4、维护标识库,其中,标识库是智能解析和半智能解析正常工作的基础,其具体过程为:
S41、在标识库中添加标识,具体可以通过以下两种方式实现:
通过标识库管理页面手动添加标识;
为防止人工添加的标识不正确,系统预置有数字正则;Ipv4正则;Ipv6正则;汉字、字母、数字、下划线、百分号、冒号、斜杠和点组合正则;mac地址正则。
通过机器学习算法丰富标识库;
当操作人员通过半智能解析工具保存解析规则文件时,后台程序对保存对象中的特征值和标识表达式进行以下处理:
符合标识库规则的标识先放入机器学习中间表,并对标识的使用频率进行计数。例如,标识库规则可以为:标识库中不存在的标识,且该标识存在标识值。
后台程序预设默认次数,如果标识的使用频率大于或等于默认次数,判定此标识的用户使用频率较高,将其放入标识库并加载到缓存中。
S42、对标识库进行初始化,其具体过程为:
进程启动后,后台程序将标识库中的标识值等字段初始化到缓存中,供智能解析和半智能解析使用,其中,初始化方法具体包括:
类型归类:
智能解析引擎在使用时将加载缓存数据,加载缓存数据时对标识进行归类。例如:时间类型、MAC地址类型、端口类型、IP类型以及其他等类型。
特征归类:
标识表达式在标识库中有两种格式,一种是存在标识值的格式,一种是不存在标识值的格式。后台程序通过hash算法对标识是否存在标识值进行判断,进而进行区分存储。
标识排序:
通过排序算法按照匹配优先级对标识进行排序。具体地,标识库中某标识的使用频率越高,表示其匹配优先级越高。
为了实现本申请实施例提供的日志解析方法,本申请实施例还提供了一种日志解析装置,其包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器。其中,所述处理器用于运行所述计算机程序时执行上述日志解析方法中的各步骤。
在示例性实施例中,本申请实施例还提供了一种计算机存储介质,是计算机可读存储介质,例如,包括计算机程序的存储器,上述计算机程序可由日志解析装置中的处理器执行,以完成上述日志解析方法中的所述步骤。计算机可读存储介质可以是磁性随机存取存储器(FRAM,ferromagnetic random access memory)、只读存储器(ROM,Read OnlyMemory)、可编程只读存储器(PROM,Programmable Read-Only Memory)、可擦除可编程只读存储器(EPROM,Erasable Programmable Read-OnlyMemory)、电可擦除可编程只读存储器(EEPROM,Electrically Erasable Programmable Read-Only Memory)、快闪存储器(FlashMemory)、磁表面存储器、光盘、或只读光盘(CD-ROM,Compact Disc Read-OnlyMemory)等存储器。
上述的本申请实施例可在各种硬件、软件编码或两者组合中进行实施。例如,本申请的实施例也可为在数据信号处理器中执行上述方法的程序代码。本申请也可涉及计算机处理器、数字信号处理器、微处理器或现场可编程门阵列执行的多种功能。可根据本申请配置上述处理器执行特定任务,其通过执行定义了本申请揭示的特定方法的机器可读软件代码或固件代码来完成。可将软件代码或固件代码发展为不同的程序语言与不同的格式或形式。也可为不同的目标平台编译软件代码。然而,根据本申请执行任务的软件代码与其他类型配置代码的不同代码样式、类型与语言不脱离本申请的精神与范围。
以上所述仅为本申请示意性的具体实施方式,在不脱离本申请的构思和原则的前提下,任何本领域的技术人员所做出的等同变化与修改,均应属于本申请保护的范围。
- 日志解析模板的生成方法、日志解析方法、装置及设备
- 基于日志解析同步的并行日志解析方法和数据同步系统