利用帧内预测的图像编码/解码方法以及装置
文献发布时间:2023-06-19 10:58:46
技术领域
本发明涉及一种图像编码/解码方法以及装置。
背景技术
随着因特网和便携式终端的普及以及信息通信技术的发展,多媒体数据的使用正在急剧增加。由此,为了通过在各种系统中的图像预测来执行各种服务或任务,针对改善图像处理系统的性能以及效率的需求正在显著增加,但是能够响应这种情况的研究开发结果却很不足。
如此,在现有技术中的图像编码/解码方法以及装置中,需要改善图像处理,尤其是需要改善图像编码或图像解码的性能。
发明内容
技术问题
本发明期望通过自适应块分割来提高编码/解码效率。
本发明期望通过基于矩阵的帧内预测来提高编码/解码效率。
本发明提供一种确定用于基于矩阵的帧内预测的参考样本和矩阵的方法和装置。
本发明提供一种用于基于矩阵的帧内预测的下采样和上采样的方法和装置。
技术方案
根据本发明的视频信号处理方法以及装置可以确定当前块的帧内预测模式、确定用于所述当前块的帧内预测的参考样本、基于所述帧内预测模式,确定预定的矩阵、基于所述参考样本和矩阵,预测所述当前块。
在根据本发明的视频信号处理方法以及装置中,确定所述参考样本,可以包括:确定所述当前块的相邻区域以及对所述已确定的相邻区域进行下采样。
在根据本发明的视频信号处理方法以及装置中,所述相邻区域区分为多个样本组,所述样本组由一个或一个以上的样本构成,所述样本组的代表值被确定为所述参考样本,所述代表值可以为平均值、最小值、最大值、众数、或中间值中的任意一个。
在根据本发明的视频信号处理方法以及装置中,所述矩阵通过进一步考虑所述当前块的编码信息而确定,所述编码信息可以包括所述当前块的大小、形状、帧内预测模式的角度或方向性。
在根据本发明的视频信号处理方法以及装置中,所述预测当前块,可以包括:通过对所述参考样本适用所述矩阵来生成预测块。
在根据本发明的视频信号处理方法以及装置中,所述预测当前块,还可以包括:重排列所述已生成的预测块的全部或部分预测样本。
在根据本发明的视频信号处理方法以及装置中,所述预测当前块,还可以包括:基于所述预测块或与所述当前块相邻的已重建的样本中的至少一个,对所述当前块进行插值。
技术效果
根据本发明,可以通过分割树状结构块来提高编码/解码效率。
根据本发明,可以通过基于矩阵的帧内预测来提高编码/解码效率。
根据本发明,可以通过用于基于矩阵的帧内预测的下采样或上采样来提高编码/解码效率。
附图说明
图1示出了作为本发明的一实施例的编码装置的示意性框图。
图2示出了作为本发明的一实施例的解码装置的示意性框图。
图3示出了作为适用本发明的一实施例的块分割类型。
图4示出了作为适用本发明的一实施例的基于树状结构的块分割方法。
图5示出了作为本发明的一实施例的基于矩阵对当前块进行帧内预测的过程。
图6示出了作为适用本发明的一实施例的对相邻区域进行下采样来确定参考样本的方法。
图7示出了作为适用本发明的一实施例的基于加权平均值的下采样方法。
图8示出了作为适用本发明的一实施例的第一预测样本的划分和对其余区域的插值方法。
图9示出了作为适用本发明的一实施例的在插值步骤中分配针对距离的权重值。
图10示出了作为适用本发明的一实施例的插值步骤的顺序。
具体实施方式
根据本发明的视频信号处理方法以及装置可以确定当前块的帧内预测模式、确定用于所述当前块的帧内预测的参考样本、基于所述帧内预测模式,确定预定的矩阵、基于所述参考样本和矩阵,预测所述当前块。
在根据本发明的视频信号处理方法以及装置中,确定所述参考样本,可以包括:确定所述当前块的相邻区域;以及对所述已确定的相邻区域进行下采样。
在根据本发明的视频信号处理方法以及装置中,所述相邻区域区分为多个样本组,所述样本组由一个或一个以上的样本构成,所述样本组的代表值被确定为所述参考样本,所述代表值可以为平均值、最小值、最大值、众数、或中间值中的任意一个。
在根据本发明的视频信号处理方法以及装置中,所述矩阵通过进一步考虑所述当前块的编码信息而确定,所述编码信息可以包括所述当前块的大小、形状、帧内预测模式的角度或方向性。
在根据本发明的视频信号处理方法以及装置中,所述预测当前块,可以包括:通过对所述参考样本适用所述矩阵来生成预测块。
在根据本发明的视频信号处理方法以及装置中,所述预测当前块,还可以包括:重排列所述已生成的预测块的全部或部分预测样本。
在根据本发明的视频信号处理方法以及装置中,所述预测当前块,还可以包括:基于所述预测块或与所述当前块相邻的已重建的样本中的至少一个,对所述当前块进行插值。
本发明可实施各种变更,且可具有多种实施例,将特定实施例示于附图中并详细地进行说明。然而,应理解,这些特定实施例并非是将本发明限定于特定的实施方式,包括本发明的思想及技术范围内的所有变更、等同物或替代物。在说明每个附图时,针对类似的构成要素使用了类似的附图标记。
第一、第二等术语可用于说明构成要素,但所述构成要素不应受所述术语的限定。所述术语仅用于将一个构成要素与其他构成要素区分开来。例如,可不脱离本发明的权利范围而将第一构成要素命名为第二构成要素,相似地,也可将第二构成要素命名为第一构成要素。所谓和/或的术语是指包含所记载的多个相关项目的组合或所记载的多个相关项目中的任一项目。
在描述某个构成要素“连接”或“连结”在另一构成要素时,应理解为可直接连接或连结在所述另一构成要素,也可在所述构成要素与所述另一构成要素之间存在其他构成要素。相反,在描述某个构成要素“直接连接”或“直接连结”在另一构成要素时,应理解为所述构成要素与所述另一构成要素之间不存在其他构成要素。
本申请中所使用的术语仅用于说明特定的实施例,并非意旨限定本发明。如果未在文中明确地表示其他含义,则单数的表达包含复数的表达。在本申请案中,“包含”或“具有”等术语应理解为用于指示存在说明书中所记载的特征、数字、步骤、动作、构成要素、零件或他们的组合,而并非预先排除一个或一个以上的其他特征、数字、步骤、动作、构成要素、零件或他们的组合的存在或附加可能性。
如果无其他定义,则包括技术或科学术语在内的所有术语具有与通常被本发明所属技术领域的普通技术人员理解的含义相同的含义。通常使用的词典中所定义的术语应解释为与相关技术文献中的含义一致,如果未在本申请案中明确地定义,则其含义不应被解释为理想或过度形式性。
以下,参考附图,将更详细地描述本发明的优选实施例。以下,针对附图上的相同构成要素使用相同的附图标记,并将省略针对相同的构成要素的重复描述。
图1示出了作为本发明的一实施例的编码装置的示意性框图。
参考图1,编码装置100可以包括:图像分割部110、预测部120、125、变换部130、量化部135、重排列部160、熵编码部165、反量化部140、反变换部145、滤波部150以及存储器155。
图1中表示的各个构成部被单独示出以在图像编码装置中表示不同的特征功能,并且这可能表示各个构成部由单独的硬件构成。然而,为了便于描述,每个构成部被列为各个构成部并将其包括在内,每个构成部中至少两个构成部被组成为一个构成部,或一个构成部可被分为多个构成部以执行功能,这种各个构成部的综合实施例以及单独的实施例,只要不脱离本发明本质,也包括在本发明的权利范围内。
另外,一些构成要素可以仅是用于提高性能的可选构成要素,并非是用于在本发明中执行基本功能的必要构成要素。本发明可以仅包括构成部来实现,该构成部在实现除了仅用于提高性能的构成要素以外的本发明的本质是必不可少的,仅包括除了仅用于提高性能的可选构成要素以外的必不可少的构成要素的结构也包括在本发明的权利范围内。
图像分割部110可以将输入的图像分割为至少一个块。此时,块可以表示编码单元(CU)、预测单元(PU)或变换单元(TU)。可以基于四叉树(Quad tree)、二叉树(Binarytree)、三叉树(Ternary tree)中的至少一个来执行所述分割。四叉树是一种将上层块四分割为具有上层块的一半的宽度和高度的下层块的方式。二叉树是一种将上层块二分割为具有上层块的一半的至少一个宽度或高度的下层块的方式。在二叉树的分割,通过具有上层块的一半的高度的基于前述的二叉树的分割,块不仅可以具有正方形,也可以具有非正方形的形状。
以下,本发明的实施例中,编码单元可以用于执行编码的单元,也可以用于执行解码的单元。
预测部120、125可以包括用于执行帧间预测的帧间预测部120和用于执行帧内预测的帧内预测部125。针对预测单元确定是否使用帧间预测还是帧内预测,并且可以确定根据各个预测方法的具体信息(例如,帧内预测模式、运动矢量、参考图像等)。此时,用于执行预测的处理单元可能与用于确定预测方法和具体内容的处理单元不同。例如,预测的方法和预测模式等可以由预测单元确定,预测也可以由变换单元执行。可以将所生成的预测块和原始块之间的残差值(残差块)输入至变换部130。另外,在熵编码部165中,对为了预测而使用的预测模式信息、运动矢量信息等可以与残差值一起被编码并传输至解码装置。当使用某个编码模式时,也可以按原样对原始块进行编码并传输至解码部,而无需通过预测部120、125来生成预测块。
帧间预测部120可以基于当前图像的上一个图像或下一个图像中至少一个图像的信息来预测预测单元,根据情况也可以基于已完成的当前图像内的编码的一些区域的信息来预测预测单元,预测部120可以包括参考图像插值部、运动预测部、运动补偿部。
参考图像插值部中,参考图像信息由存储器155提供,并且可在参考图像中生成整数像素以下的像素信息。针对亮度像素,为了以1/4像素单位生成整数像素以下的像素信息,可以使用具有不同滤波器系数的基于DCT的8抽头插值滤波器(DCT-basedInterpolation Filter)。针对色差信号,为了以1/8像素单位生成整数像素以下的像素信息,可以使用具有不同滤波器系数的基于DCT的4抽头插值滤波器(DCT-basedInterpolation Filter)。
运动预测部可以基于由参考图像插值部插值的参考图像来进行运动预测。FBMA(Full search-based Block Matching Algorithm)、TSS(Three Step Search)、NTS(NewThree-Step Search Algorithm)等各种方法均可以用作计算运动矢量的方法。基于插值像素,运动矢量可以具有1/2或1/4像素单位的运动矢量值。运动预测部可以通过不同的运动预测方法来预测当前预测单元。跳过(Skip)方法、合并(Merge)方法、高级运动矢量预测(Advanced Motion Vector Prediction,AMVP)方法等各种方法可以用作运动预测方法。
帧内预测部125可以基于当前块相邻的参考像素信息来生成预测单元,其中,所述当前块相邻的参考像素信息为当前图像中的像素信息。由于当前预测单元的相邻块为进行了帧间预测的块,则当参考像素为进行了帧间预测的像素时,可以将进行了帧间预测的块中包括的参考像素信息替换为进行了相邻的帧内预测的块的参考像素信息。也就是说,当参考像素不可用时,可以将不可用的参考像素信息替换为可用的参考像素中的至少一个参考像素。
帧内预测中的预测模式可以具有根据预测方向使用参考像素信息的定向性预测模式和进行预测时不使用方向性信息的非定向性模式。用于预测亮度分量的模式与用于预测色差分量的模式可以不同,并且可以利用用于预测亮度分量而使用的帧内预测模式或利用已预测/已重建的亮度分量来预测色差分量。
帧内预测方法可以在根据帧内预测模式将AIS(Adaptive Intra Smoothing)滤波器适用于参考像素之后生成预测块。适用于参考像素的AIS滤波器的类型可以不同。为了执行帧内预测方法,可以从位于当前预测单元的相邻的预测单元的帧内预测模式中预测当前预测单元的帧内预测模式。当利用从相邻预测单元中预测的模式信息来预测当前预测单元的预测模式时,若当前预测单元和相邻预测单元的帧内预测模式相同,则可以利用预定的标志信息来传输表示当前预测单元和相邻预测单元的帧内预测模式相同的信息,若当前预测单元和相邻预测单元的帧内预测模式不同,则可以进行熵编码以对当前块的帧内预测模式信息进行编码。
另外,在预测部120、125中可以生成包括作为所生成的预测单元和原始块之间的差值的残差值(Residual)信息。可以将所生成的残差块输入至变换部130中。
变换部130中可以使用DCT、DST等类型的变换来变换包括残差数据的残差块。此时,可以基于为了生成残差块而使用的预测单元的帧内预测模式来确定变换类型。
量化部135可以对由变换部130变换为频率区域的值进行量化。量化系数可以根据块或根据图像的重要程度而变化。可以将从量化部135中所计算的值提供给反量化部140和重排列部160。
重排列部160可以针对量化的残差块进行系数值的重排列。重排列部160可以通过系数扫描(Coefficient Scanning)方法将二维块形状的系数变更为一维矢量形状。例如,重排列部160可以利用预定的扫描类型从DC系数扫描至高频区域的系数以将其变更为一维矢量形状。
熵编码部165可以基于由重排列部160所计算出的值进行熵编码。熵编码可以使用各种编码方法,诸如指数哥伦布编码方法(Exponential Golomb)、CAVLC(Context-Adaptive Variable Length Coding)、自适应二进制算术编码(Context-Adaptive BinaryArithmetic Coding,CABAC)等。
熵编码部165可以对来自重排列部160以及预测部120、125的各种信息,例如编码单元的残差系数信息和块类型信息、预测模式信息、分割单元信息、预测单元信息和传输单元信息、运动矢量信息、参考图像信息、块的插值信息、滤波信息等进行编码。
熵编码部165可以对在排列部160输入的编码单元的系数值进行熵编码。
反量化部140以及反变换部145对在量化部135量化的值进行反量化,并对在变换部130变换的值进行反变换。反量化部140以及反变换部145生成的残差值(Residual)可以通过预测部120、125中所包括的运动估计部、运动补偿部以及帧内预测部,与所预测的预测单元进行合并,以生成重建块(Reconstructed Block)。
滤波部150可以包括去块滤波器、偏移校正部、自适应环路滤波器(Adaptive LoopFilter,ALF)中的至少一个。
去块滤波器可以去除由于在重建图像中的块之间的边界而引起的块失真。为了判断是否进行去块,基于块中所包括的几个列或行中包括的像素,来判断是否将去块滤波器适用于当前块。当将去块滤波器适用于块时,可以根据所需的去块滤波强度来适用强滤波器(Strong Filter)或弱滤波器(Weak Filter)。另外,在适用去块滤波器时,在进行垂直滤波以及水平滤波时,可以使水平方向滤波以及垂直方向滤波并行处理。
偏移校正部可以针对已进行去块的图像,以像素单位与原始图像的偏移进行校正。为了针对特定图像进行偏移校正,可以使用将图像中包括的像素区分为一定数量的区域之后,确定要偏移的区域,且将偏移适用于该区域的方法或通过考虑各个像素的边缘信息使用适用偏移的方法。
可以基于滤波的重建图像和原始图像的比较值进行ALF(Adaptive LoopFiltering)。将图像中包括的像素分为预定的组之后,确定适用于该组合的一个滤波器,并且可以针对每个组不同地进行滤波。对于是否适用ALF的信息,每个编码单元(CodingUnit,CU)可以传输亮度信号,并且要适用的ALF滤波器的形状以及滤波器系数可以根据每个块而改变。另外,无论适用对象块的特性如何,也可以适用相同形状(固定形状)的ALF滤波器。
存储器155可以存储通过滤波部150计算出的重建块或图像,当进行帧间预测时所存储的重建块或图像可以提供给预测部120、125。
图2示出了作为本发明的一实施例的解码装置的示意性框图。
参考图2,解码装置200可以包括熵解码部210、重排列部215、反量化部220、反变换部225、预测部230、235、滤波部240、存储器245。
图2中表示的各个构成部被单独示出以用于在解码装置中表示不同的特征功能,并且这可能表示各个构成部由单独的硬件构成。然而,为了便于描述,每个构成部被列为各个构成部并将其包括在内,每个构成部中至少两个构成部被组成为一个构成部,或一个构成部可被分为多个构成部以执行功能,这种各个构成部的综合实施例以及单独的实施例,只要不脱离本发明本质,也包括在本发明的权利范围内。
熵解码部210可以针对输入码流进行熵解码。例如,为了进行熵解码,可以适用诸如指数哥伦布编码方法(Exponential Golomb)、CAVLC(Context-Adaptive VariableLength Coding)、CABAC(Context-Adaptive Binary Arithmetic Coding)等各种方法。
熵解码部210可以对关于编码装置进行的帧内预测以及帧间预测的信息进行解码。
重排列部215可以针对由熵解码部210进行熵解码的码流进行重排列。可以将以一维矢量形式表示的系数重建到二维块形式的系数来进行重排列。重排列部215可以接收关于编码装置进行的系数扫描的信息,并可以通过基于该编码装置进行的扫描顺序进行反向扫描的方法来进行重排列。
反量化部220可以基于量化参数和重排列的块的系数值进行反量化。
反变换部225可以以预定的变换类型对反量化的变换系数进行反变换。此时,可以基于关于预测模式(帧间/帧内预测)、块的大小/形状、帧内预测模式、分量类型(亮度/色差分量)、分割类型(QT、BT、TT等)等的信息中至少一个确定变换类型。
预测部230、235可以基于熵解码部210所提供的预测块生成相关信息和存储器245所提供的之前解码的块或图像信息来生成预测块。
预测部230、235可以包括预测单元判别部、帧间预测部以及帧内预测部。预测单元判别部可以接收各种信息,诸如熵解码部210输入的预测单元信息、帧内预测方法的帧内预测模式相关信息、帧间预测方法的运动预测相关信息等,在当前编码单元(CU)区分预测单元,判别预测单元进行帧间预测还是进行帧内预测。帧间预测部230可以利用编码装置提供的当前预测单元的帧间预测所需的信息,基于包括当前预测单元的当前图像的上一个图像或下一个图像中至少一个图像中包括的信息来进行针对当前预测单元的帧间预测。或者,也可以在包括当前预测单元的当前图像中基于已重建的一些区域的信息进行帧间预测。为此,所述已重建的一些区域可以添加至参考图像列表中。
为了进行帧间预测,以编码单元为基准,可以判断该编码单元中包括的预测单元的运动预测方法是跳过模式(Skip Mode)、合并模式(Merge Mode)、AMVP模式(AMVP Mode)、当前图像参考模式中的哪种方法。
帧内预测部235可以基于当前图像中的像素信息生成预测块。当预测单元为进行了帧内预测的预测单元时,可以基于编码装置所提供的预测单元的帧内预测模式信息,进行帧内预测。帧内预测部235可以包括AIS(Adaptive Intra Smoothing)滤波器、参考像素插值部、DC滤波器。AIS滤波器作为对当前块的参考像素进行滤波的部件,可以根据当前预测单元的预测模式确定是否适用滤波器来适用。可以利用编码装置所提供的预测单元的预测模式以及AIS滤波器信息,对当前块的参考像素进行AIS滤波。当当前块的预测模式为不进行AIS滤波的模式时,可以不适用AIS滤波器。
当预测单元的预测模式为基于对参考像素进行插值的像素的值来进行帧内预测的预测单元时,参考像素插值部可以对参考像素进行插值以生成整数值以下的像素单位的参考像素。当当前预测单元的预测模式为对参考像素不进行插值生成预测块的预测模式时,可以不对参考像素进行插值。当当前块的预测模式为DC模式时,DC滤波器可以通过滤波来生成预测块。
重建的块或图像可以提供于滤波部240。滤波部240可以包括去块滤波器、偏移校正部、ALF。
可以从编码装置接收关于是否将去块滤波器适用于该块或图像的信息,以及当适用了去块滤波器时,接收关于适用了较强的滤波器还是较弱的滤波器的信息。解码装置的去块滤波器可以接收编码装置提供的去块滤波器相关信息,解码装置可以对该块进行去块滤波。
偏移校正部在进行编码时可以基于适用于图像中的偏移校正类型以及偏移值信息等对重建的图像进行偏移校正。
ALF可以基于编码器提供的ALF适用与否信息、ALF系数信息等适用于编码单元。这种ALF信息可以通过包括在特定的参数集中被提供。
存储器245可以存储重建的图像或块作为参考图像或参考块,并且可以将重建的图像提供至输出部。
图3示出了作为适用本发明的一实施例的块分割类型。
参考图3,可以根据分割设置、分割方式获得a至s的块,也可以获得未示出的附加块形状。
作为一个示例(1),可以允许将不对称分割用于基于树的分割。例如,针对二叉树可以是如b、c的块,或也可以是诸如b~g的块。当允许不对称分割的标志根据编码/解码设置未显式或隐式地激活时,可获得的候选块可以为b或c,当激活允许不对称分割的标志时,可获得的候选块可以为b、d、e(本示例中的水平分割),也可以是c、f、g(本示例中的垂直分割)。
在所述示例中,假设以不对称分割的左:右或上:下的长度比例为1:3或3:1的情况进行描述,但并不限于此,也可以根据编码设置存在具有其他比例的候选群(例如,1:2、1:4、2:3、2:5、3:5等)。
以下示出关于二叉树分割(本示例中的1:1、1:3、3:1的候选群)中生成的分割信息的各种示例。
例如,除了指示是否分割的标志、指示分割方向的标志之外,还可以生成指示分割类型的标志。此时,分割类型可以表示对称或不对称分割。其中当不对称分割被确定为分割类型时,可以生成指示分割比例的标志,并且可以根据预设的候选群分配索引。若支持1:3或3:1的分割比例作为候选群,可以通过1比特标志选择分割比例。
或者,除了指示是否分割的标志、指示分割方向的标志之外,还可以生成指示分割比例的标志。本示例中,作为针对分割比例的候选群,可以包括具有1:1对称比例的候选。
本发明中假设(当激活允许不对称分割的标志时)二叉树分割具有如前例的结构的情况,除非另有说明,二叉树表示对称二叉树。
作为一个示例(2),对于基于树的分割,可以允许附加的树分割。例如,可以对三叉树(Ternary Tree)、四叉树类型(Quad Type Tree)、八叉树(Octa Tree)等进行分割,通过他们可以获得n个分割块(本示例中的3、4、8、n为整数)。针对三叉树,支持的块(当在本示例中分割为多个块时)可以为h~m,针对四叉类型的树,支持的块可以为n~p,针对八叉树,支持的块可以为q。可以根据编码/解码设置隐式地确定是否支持所述基于树的分割或显式地生成相关信息。另外,可以根据编码/解码设置单独使用或可以与二叉树、四叉树分割等混合使用。
例如,针对二叉树,可以使用诸如b、c的块,当混合使用二叉树和三叉树时(本示例中假设为二叉树的使用范围与三叉树的使用范围存在一部分重叠的情况)也可以使用诸如b、c、i、l的块。当根据编码/解码设置显式或隐式地非激活允许除了当前树以外的额外分割的标志时,可获得的候选块可以为b或c,当被激活时,可获得的候选块可以为b、i或b、h、i、j(本示例中的水平分割),也可以为c、l或c、k、l、m(本示例中的垂直分割)。
在所述示例中,虽然假设了三叉树分割的左:中:右或上:中:下的长度比例为2:1:1或1:2:1或1:1:2的情况进行了描述,但并不限于此,也可以根据编码设置其他比例。
以下示出针对三叉树分割(本示例中的1:2:1的候选)中生成的分割信息的示例。
例如,除了指示是否分割的标志、指示分割方向的标志之外,还可以生成指示分割类型的标志。此时,分割类型可以表示二叉树或三叉树分割。
本发明中可以根据分割方式适用适应的编码/解码设置。
作为一个示例,可以根据块的类型确定分割方式。例如,编码块和变换块可以使用四叉树分割方式,预测块可以使用四叉树和二叉树(或三叉树等)分割方式。
作为一个示例,可以根据块的大小确定分割方式。例如,块的最大值和最小值之间的一些范围中(例如,a×b~c×d,当后者更大时)能够使用四叉树分割方式,一些范围中(例如,e×f~g×h)能够进行二叉树(或三叉树等)分割。此时,可以显式地生成或隐式地确定根据分割方式的范围信息,当所述范围重叠时也可以使用。
作为一个示例,可以根据块(或分割前的块)的形状确定分割方式。例如,块形状为正方形时可以进行四叉树和二叉树(或三叉树等)分割。或者,块的形状为长方形时可以进行基于二叉树(或三叉树等)的分割。
作为一个示例,可以根据块的类型确定分割设置。例如,在基于树的分割中,编码块和预测块可以使用四叉树,变换块可以使用二叉树分割。或者,针对编码块的分割允许深度可以设置为m,针对预测块的分割允许深度可以设置为n,针对变换块的分割允许深度可以设置为o,m、n和o可以相同或不同。
作为一个示例,可以根据块的大小确定分割设置。例如,块的一些范围(例如,a×b~c×d)中可以使用四叉树分割,一些范围(例如,e×f~g×h;本示例中假设c×d大于g×h)中可以使用二叉树分割,一些范围(例如,i×j~k×l;本示例中假设g×h大于或等于k×l)中可以使用三叉树分割。此时,所述范围可以包括块的最大值和最小值之间的所有范围,所述范围可以具有不重叠的设置或相互重叠的设置。例如,一些范围的最小值可能与一些范围的最大值相同,或一些范围的最小值可能小于一些范围的最大值。若具有相互重叠的范围时,具有更大的最大值的分割方式可以具有优先顺序或可以显式地生成针对使用哪种分割方式的信息。也就是说,具有优先顺序的分割方式中,可以根据分割结果确定是否进行具有优先级较低的分割方式,或可以根据分割方式选择信息确定使用哪种分割方式。
作为一个示例,可以根据块的形状确定分割设置。例如,块的形状为正方形时可以使用四叉树分割。或者,块的形状为长方形时可以使用二叉树或三叉树分割。
作为一示例,可以根据编码/解码信息(例如,切片类型,颜色分量,编码模式等)确定分割设置。例如,切片类型为I时,四叉树(或二叉树、三叉树)分割可以在一些范围(例如,a×b~c×d)内使用,切片类型为P时,可以在一些范围(例如,e×f~g×h)内使用,切片类型为B时,可以在一些范围(例如,i×j~k×l)内使用。另外,切片类型为I时,四叉树(或二叉树、三叉树分割)分割的分割允许深度可以设置为m,切片类型为P时,分割允许深度可以设置为n,切片类型为B时,分割允许深度可以设置为o,m、n和o可以相同或不同。针对一些切片类型可以与其他切片(例如,P和B切片)具有相同的设置。
作为其他示例,当颜色分量为亮度分量时,四叉树(或二叉树,三叉树)分割允许深度可以设置为m,当颜色分量为色差分量时可以设置为n,m和n可以相同或不同。另外,颜色分量为亮度分量时的四叉树(或二叉树、三叉树)分割的范围(例如,a×b~c×d)与颜色分量为色差分量时的四叉树(或二叉树、三叉树)分割的范围(例如,e×f~g×h)可以相同或不同。
作为其他示例,编码模式为Intra时,四叉树(或二叉树、三叉树)分割允许深度可以为m,编码模式为Inter时可以为n(本示例中假设n大于m),m和n可以相同或不同。另外,编码模式为Intra时的四叉树(或二叉树、三叉树)分割的范围与编码模式为Inter时的四叉树(或二叉树、三叉树)分割的范围可以相同或不同。
针对所述示例,可以显式地生成或隐式地确定针对是否支持根据编码/解码信息的自适应分割候选组结构的信息。
通过所述示例描述了根据编码/解码设置确定分割方式和分割设置的情况。所述示例表示了根据各个因素的一些情况,也可以存在其他情况下的变形。另外,也可以根据由于多个因素的组合确定分割方式和分割设置。例如,可以由块的类型、大小、形状、编码/解码信息等确定分割方式和分割设置。
另外,可以隐式地确定与所述示例中的分割方式、设置等有关的因素或显式地生成信息,以确定是否允许如上述示例的自适应情况。
所述分割设置中的分割深度表示基于初始块进行空间分割的次数(本示例中的初始块的分割深度为0),分割深度越大越能够分割为更小的块。这可以根据分割方式不同地设置深度相关设置。例如,进行基于树的分割的方式中,诸如二叉树的分割深度可与三叉树的分割共用一种深度,四叉树的分割深度可与二叉树的分割深度使用不同的深度等,可以根据树的类型使用各自的深度。
当在所述示例中根据树的类型使用各自的分割深度时,可以将在树的分割起始位置(在本示例中进行分割之前的块)中的分割深度设置为0。可以以开始分割的位置为中心计算分割深度,而不是基于各树的分割范围(本示例中的最大值)。
图4示出了作为适用本发明的一实施例的基于树状结构的块分割方法。
图中粗实线表示基本编码块,粗虚线表示四叉树分割界限、双实线表示对称二叉树分割界限、实线表示三叉树分割界限、细实线表示不对称二叉树分割界限。除了粗实线以外都表示根据各分割方法划分的界限。以下描述的分割设置(例如,分割类型、分割信息、分割信息配置顺序等)不仅限于该示例中的情况,也可以有各种变形的示例。
为了便于描述,假设以基本编码块(2N×2N;128×128)为基准的左上、右上、左下、右下块(N×N;64×64)具有各自的块分割设置的情况来进行描述。首先,假设已经由于初始块中的一次分割操作(分割深度0->1;即,分割深度增加1)获得了4个子块,并且针对四叉树的分割设置,最大编码块为128×128,最小编码块为8×8,最大分割深度为4的情况,这是共同适用于各个块的设置。
(第1;左上块;A1~A6)
本示例作为支持单个树方式的分割(本示例中的四叉树)的情况,可以通过一个块分割设置,诸如最大编码块、最小编码块、分割深度等,确定能够获得的块的大小以及形状。本示例作为根据分割能够获得的块为一个的情况(水平和垂直方向各进行2分割),一次分割操作(以分割前的块4M×4N为基准,分割深度增加1)所需的分割信息为指示是否分割的标志(若在本示例中为0,则不分割;为1,则分割),能够获得的候选可以为4M×4N和2M×2N。
(第2;右上块;A7~A11)
本示例作为支持多个树方式的分割(本示例中的四叉树、二叉树)的情况,可以通过多个块分割设置确定能够获得的块的大小以及形状。本示例中,假设针对二叉树的最大编码块为64×64,最小编码块为一个长度为4、最大分割深度为4。
本示例作为根据分割能够获得的块为2个以上的情况(本示例中为2个或4个),一次分割操作(四叉树分割深度增加1)所需的分割信息为指示是否分割的标志、指示分割类型的标志、指示分割类型的标志、指示分割方向的标志,能够获得的候选可以为4M×4N、4M×2N、2M×4N、4M×N/4M×3N、4M×3N/4M×N、M×4N/3M×4N、3M×4N/M×4N。
若四叉树和二叉树分割范围重叠(即,当前步骤中的能够进行四叉树分割和二叉树分割的范围),且当前块(未进行分割之前的状态)为由四叉树分割所获得的块(母块<分割深度比当前小1时>中由四叉树分割获得的块)时,可以通过以下情况区分并配置分割信息。即,当根据各个分割设置而支持的块可以由多个分割方法获得时,可以通过以下方式进行分类以生分量割信息。
(1)四叉树分割与二叉树分割重叠的情况
表1
在所述表中,a是指示是否进行四叉树分割的标志,1表示进行四叉树分割(QT)。所述标志为0,则确认作为指示是否进行二叉树分割的标志的b。b为0,则在该块不再进行分割(No Split),b为1,则进行二叉树分割。
c作为指示分割方向的标志,若c为0,则指进行水平分割(hor),若c为1,则指进行垂直分割(ver),d作为指示分割类型的标志,若d为0,则指进行对称分割(SymmetricBinary Tree,SBT),若d为1,则指进行不对称分割(Asymmetric Binary Tree,ABT)。当只有在d为1时,确认针对不对称分割中的详细分割比例的信息(1/4或3/4),d为0时,则在左/右块或上/下块中,左块与上块具有1/4的比例,右块与下块具有3/4的比例,若d为1,则与其相反。
(2)只能进行二叉树分割的情况
在所述表中,可以通过除了a之外的b至e的标志表示分割信息。
针对图4中的A7块,由于分割前块(A7~A11)中可以进行四叉树分割(即,虽然可以进行四叉树分割但进行了二叉树分割而不是四叉树分割),则属于(1)中的生分量割信息的情况。
相反,针对A8至A11,由于分割前块(A8~A11)中已经进行了二叉树分割而不是四叉树分割(即,在该块
(第3;左下块;A12~A15)
本示例作为支持多个树方式的分割(本示例中的四叉树、二叉树、三叉树)的情况,可以通过多个块分割设置来确定能够获得的块的大小以及形状。本示例中,假设针对二叉树/三叉树最大编码块为64×64,最小编码块为一个长度为4、最大分割深度为4。
本示例作为根据分割能够获得的块为2个以上的情况(本示例中为2、3、4个),一次分割操作中需要的分割信息为,指示是否进行分割的标志、指示分割类型的标志、指示分割方向的标志,能够获得的候选可以为4M×4N、4M×2N、2M×4N、4M×N/4M×2N/4M×N、M×4N/2M×4N/M×4N。
若四叉树与二叉树/三叉树分割范围重叠,且当前块为由四叉树分割所获得的块时,可以通过以下情况区分并配置分割信息。
(1)四叉树分割与二叉树/三叉树分割重叠的情况
表2
在所述表中,a是指示是否进行四叉树分割的标志,若为1表示进行四叉树分割。若所述标志为0,则会确认作为指示是否进行二叉树或三叉树分割的标志的b。b为0,则在该块不再进行分割,b为1,则进行二叉树或三叉树分割。
c作为指示分割方向的标志,若c为0,则指进行水平分割,若c为1,则指进行垂直分割,d作为指示分割分类的标志,若d为0,则指进行二叉树分割(BT),若d为1,则指进行三叉树分割(TT)。
(2)只能进行二叉树/三叉树分割的情况
在所述表中,可以通过除了a之外的b至d的标志表示分割信息。
针对图4中的A12、A15块,由于分割前块(A12~A15)中可以进行四叉树分割,因此属于(1)中的生分量割信息的情况。
相反,A13和A14作为分割前块(A13、A14)中已经进行了三叉树分割,而不是四叉树分割的情况,则属于(2)中的生分量割信息的情况。
(第4;左下块;A16~A20)
本示例作为支持多个树方式的分割(本示例中的四叉树、二叉树、三叉树)的情况,可以通过多个块分割设置确定能够获得的块的大小以及形状。本示例中,假设针对二叉树/三叉树最大编码块为64×64,最小编码块为一个长度为4、最大分割深度为4。
本示例作为根据分割能够获得的块为2个以上的情况(本示例中为2、3、4个),一次分割操作所需的分割信息为指示是否进行分割的标志、表示分割分类的标志、指示分割类型的标志、指示分割方向的标志,能够获得的候选可以为4M×4N、4M×2N、2M×4N、4M×N/4M×3N、4M×3N/4M×N、M×4N/3M×4N、3M×4N/M×4N、4M×N/4M×2N/4M×N、M×4N/2M×4N/M×4N。
若四叉树与二叉树/三叉树分割范围重叠,且当前块为由四叉树分割所获得的块时,可以通过以下情况区分并配置分割信息。
(1)四叉树分割与二叉树/三叉树分割重叠的情况
表3
在所述表中,a是指指示是否进行四叉树分割的标志,若为1表示进行四叉树分割。所述标志为0,则确认作为用于指示是否进行二叉树分割的标志的b。b为0,则在该块不再进行分割,b为1则进行二叉树或三叉树分割。
c作为指示分割方向的标志,若c为0,则指进行水平分割,若c为1,则指进行垂直分割,d作为指示分割分类的标志,若d为0,则指进行三叉树分割,若d为1,则指进行二叉树分割。d为1时,确认作为针对分割类型的标志的e,以在e为0时进行对称分割,e为1时,进行不对称分割。e为1时确认不对称分割中的详细分割比例的信息,这与上一个示例相同。
(2)只能进行二叉树/三叉树分割的情况
在所述表中,可以通过除了a以外的b至f的标志表示分割信息。
由于图4中的A20块为分割前块(A16~A19)中可以进行四叉树分割的情况,则属于(1)中的生分量割信息的情况。
相反,针对A16至A19,其作为分割前块(A16~A19)中已经进行了二叉树分割而不是四叉树分割的情况,则属于(2)中的生分量割信息的情况。
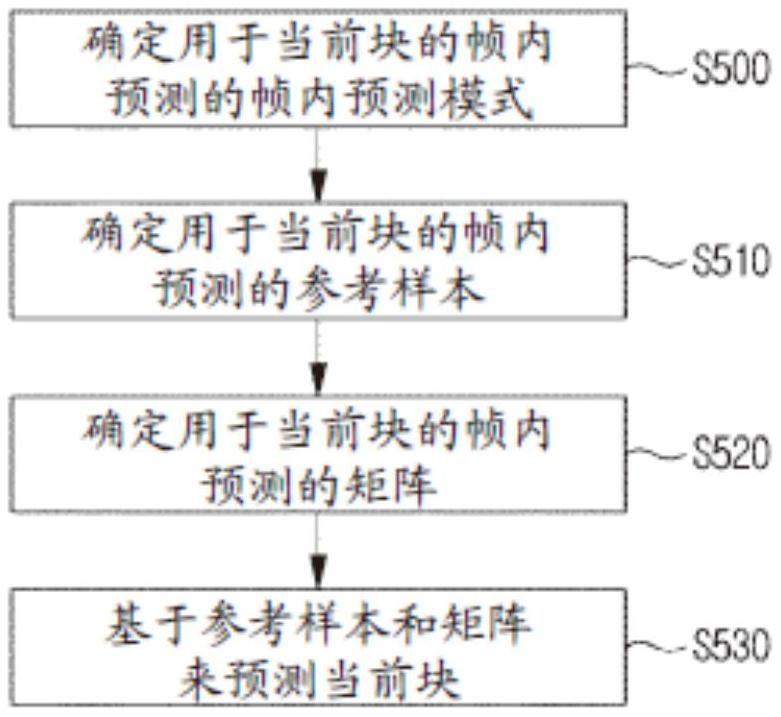
图5示出了作为本发明的一实施例的基于矩阵对当前块进行帧内预测的过程。
参考图5,可以确定用于当前块的帧内预测的帧内预测模式(S500)。
编码/解码装置当进行当前块的帧内预测时,可以确定帧内预测模式。所述当前块可以为编码块(CU)、预测块(PU)、变换块(TU)、或这些字块中的任意一个。
(实施例1)可以基于传递信号的信息确定所述帧内预测模式。所述信息可以指定在编码/解码装置中预定义的N个帧内预测模式中的任意一个。所述预定义的帧内预测模式表示能够利用当前块的所有帧内预测模式,N可以为小于或等于67,且大于或等于11的自然数(例如,67、35、11)。另外,可以基于当前块的大小确定N的取值。例如,当前块小于8×8时,N被确定为35,否则,N可以被确定为19或11中的任意一个。
(实施例2)也可以通过编码/解码装置中预先约定的默认模式或索引确定所述帧内预测模式。所述默认模式可以为Planar mode(索引0、DC模式(索引1)、水平模式(索引18)、垂直模式(索引50)、对角线模式(索引2、34、66)中的至少一个。其中,索引对应于预定义的帧内预测模式为67个的情况,并且可以根据所述N的取值对每个模式划分不同的索引。
(实施例3)可以基于编码信息可变地确定所述帧内预测模式。其中,编码信息不仅可以包括在编码装置中进行编码并传递信号的信息,还可以包括基于在解码装置中传递信号的信息导出的信息。所述编码信息可能是关于当前块或相邻块中的至少一个的信息。相邻块包括当前块的空间和/或时间相邻块,空间相邻块可以表示与当前块的左侧、上层、左上层、左下层或右上层中的至少一个相邻的块。
所述编码信息可以包括:块大小/形状、块的可用性、分割类型、分割次数、分量类型、预测模式、关于帧内预测模式的信息、帧间模式、运动信息、变换类型、变换跳过模式、关于non-zero残差系数的信息、扫描顺序、颜色格式,环路滤波器信息等。所述块大小可以通过宽度或高度中的任意一个、宽度和高度中的最小值/最大值、宽度与高度的和、属于块的样本的数量等表示出来。可以通过考虑块位置、并行处理区域的范围、解码顺序等来判断所述块的可用性。所述预测模式可以表示用于指示帧内模式或帧间模式的信息。关于所述帧内预测模式的信息可以包括:与帧内预测模式是否为非定向性模式、帧内预测模式是否为垂直/水平模式、帧内预测模式的方向性、编码/解码装置中预定义的帧内预测模式的数量等有关的信息。所述帧间模式可以表示用于指示合并/跳过模式、AMVP模式或当前图像参考模式的信息。所述当前图像参考模式表示利用当前图像的已重建的区域来预测当前块的方法。所述当前图像可以为所述当前块所属的图像。所述当前图像可以添加到参考图像列表以进行帧间预测,所述当前图像可以排列在参考图像列表中的近距离(short-term)参考图像或长距离(long-term)参考图像之后。所述运动信息可以包括:预测方向标志、运动矢量、参考图像索引等。
(实施例4)也可以基于MPM列表以及MPM索引导出所述帧内预测模式。所述MPM列表包括多个MPM,可以基于当前块的空间/时间相邻块的帧内预测模式确定MPM。MPM的数量为x个,x可以为3、4、5、6、或更大的整数。
例如,MPM列表可以包括相邻块的帧内预测模式mode A、(mode A-n)、(mode A+n)或默认模式中的至少一个。所述n的取值可以为1、2、3、4或更大的整数。所述相邻块可以表示与当前块的左侧和/或上层相邻的块。默认模式可以为Planar模式、DC模式、或预定的定向性模式中的至少一个。预定的定向性模式可以包括水平模式(mode V)、垂直模式(modeH)、(mode V-k)、(mode V+k)、(mode H-k)或(mode H+k)中的至少一个。
所述MPM索引可以指定MPM列表的MPM中,与当前块的帧内预测模式相同的MPM。也就是说,由MPM索引指定的MPM可以设置为当前块的帧内预测模式。
可以选择性地利用前述的实施例1至4中的任意一个来确定当前块的帧内预测模式,并且可以基于实施例1至4中的至少2个组合来确定当前块的帧内预测模式。可以利用预定的标志用于所述选择,此时标志可以由编码装置进行编码并传输信号。
参考图5,可以确定用于当前块的帧内预测的参考样本(S510)。
所述参考样本可以从当前块的相邻区域导出。所述当前块的相邻区域可以包括所述当前块的左侧、右侧、上层、左下层、左上层、右下层、或右上层中的至少一个。
所述相邻区域可以包括一个或一个以上的样本线。具体地,属于相邻区域的样本线的数量为k个,其中k可以为1、2、3、4,或可以是大于这些的自然数。k值可以为编码/解码装置中预先约定的固定值,也可以基于前述的编码信息可变地确定。例如,当当前块为第一大小(e.g.,4×4、4×8、8×4)时,相邻区域可以配置为1个样本线,当当前块为第二大小(e.g.,8×8、16×16等)时,相邻区域可以配置为2个样本线。可以根据相邻区域的位置以垂直方向或水平方向确定所述样本线。并且,所述样本线可以与当前块接触,也可以以当前块为基准在垂直和/或水平方向远离预定的距离。
所述多个样本线,以当前块为基准在垂直和/或水平方向上连续存在,或也可以相互远离预定的距离。作为一个实施例,当当前块的上层存在2个样本线时,从所述2个线中最下层的样本线到向上方向,分别命名为第一、第二样本线。此时,第一样本线和第二样本线可以相互接触,或远离预定的距离。其中,预定的距离可以由i个线长度(即,宽度或高度)来表示。其中,i可以为0、1、2、3或更大的自然数。作为一个实施例,当当前块的上层存在3个样本线时,从所述多个样本线中最下层的样本线到向上方向,分别命名为第一、第二、第三样本线。此时,第一样本线可以与第二样本线相互接触,第二样本线可以与第三样本线相互接触。或者,第一至第三样本线也可以远离前述的预定的距离。此时,第一以及第二样本线之间的间隔(d1)可与第二以及第三样本线之间的间隔(d2)具有相同的间隔。或者,可以将d1设置为大于d2,相反也可以将d1设置为小于d2。作为一个实施例,当在当前块的上层存在4个以上的样本线时,可以与所述3个样本线的情况相同的方法来确定所述4个样本线。另外,本实施例不仅可以适用于位于上层的样本线,还可以同样适用于位于左侧的样本线,关于具体描述在此省略。
可以通过利用属于相邻区域的样本的全部或部分来导出所述参考样本。
(实施例1)所述相邻区域的一些样本可以为编码/解码装置中预先约定的位置处的样本。所述预先约定的位置可以包括:上层样本线的最左侧样本、最右侧样本或中间样本中的至少一个。所述预先约定的位置可以包括:左侧样本线的最上层样本、最下层样本或中间样本中的至少一个。或者,预先约定的位置可以包括:上层和/或左侧样本线的第奇数样本中的至少一个,或第奇数样本中的至少一个。或者,预先约定的位置也可以包括:在上层样本线的样本中具有j的倍数的x坐标的样本,或在左侧样本线的样本中具有j的倍数的y坐标的样本。其中,j可以为2、3、4,或更大的自然数。
(实施例2)也可以基于编码信息可变地确定所述相邻区域的一些样本。其中,编码信息如前述,关于详细描述在此省略。
可以选择性地利用所述实施例1或2中的任意一个,或可以基于实施例1和2的组合指定一些样本。此时,如前述,可以相同设置一些样本之间的间隔,但并不限于此,也可以不同地设置一些样本之间的间隔。
所述一些样本的数量可以为编码/解码装置中预定义的1个、2个、3个、4个或以上。另外,分别针对当前块的左侧相邻区域和上层相邻区域,可以不同地定义一些样本的数量。例如,当前块的宽度大于高度时,属于上层相邻区域的一些样本的数量(numSamA)可以大于属于左侧相邻区域的一些样本的数量(numSamL)。相反,当前块的宽度小于高度时,numSamA可以小于numSamL。或者,也可以基于前述的编码信息可变地确定一些样本的数量。
所述相邻区域的样本可以为预测样本或重建样本。可以通过帧内预测或帧间预测获得所述预测样本。所述重建样本可以为适用环路滤波器之前的重建样本,也可以为适用了环路滤波器之后的重建样本。
另一方面,参考样本可以直接通过相邻区域的样本导出(CASE 1),或可以通过对相邻区域的样本进行下采样的方式导出(CASE 2)。可以选择性地利用所述CASE 1和CASE 2中的任意一个。可以基于前述的编码信息进行所述选择。例如,当前块的大小小于预定的阈值时,可以基于CASE 1导出参考样本,否则,可以基于CASE 2导出参考样本。其中,大小可以通过当前块的宽度、高度、宽度与高度的最大值/最小值、宽度与高度的比例或宽度与高度的积中的任意一个表示出来。作为一个示例,当前块小于8×8时,可以通过相邻区域的样本导出参考样本,否则,可以通过对相邻区域的样本进行下采样导出参考样本。针对所述下采样方法,通过参考图6和图7进行进一步的了解。
参考图5,可以确定用于基于矩阵的帧内预测的矩阵(S520)。
可以基于步骤S500中确定的帧内预测模式或当前块的大小中的至少一个来确定所述矩阵。或者,可以限制仅考虑当前块的帧内预测模式来确定所述矩阵,或可以限制仅考虑当前块的大小来确定所述矩阵。所述大小可以通过宽度或高度中的任意一个、宽度和高度中的最小值/最大值、宽度与高度的和、属于当前块的样本的数量等来表示出来。然而,并不限于此,可以进一步考虑关于当前块的编码信息来确定所述矩阵。其中,编码信息如前述,关于详细描述在此省略。
具体地,编码/解码装置中预先约定的矩阵可以分为多个矩阵组。所述多个矩阵组可以由第一矩阵组、第二矩阵组、…、第m矩阵组配置。其中,m可以为2、3、4、5或更大的自然数。基于当前块的大小,当前块可以选择性地利用多个矩阵组中的任意一个。例如,当前块的大小为4×4时可以利用第一矩阵组,当前块的大小为8×4、4×8以及8×8时可以利用第二矩阵组,并且在除此之外的情况下可以利用第三矩阵组。基于当前块的大小选择的矩阵组可以包括一个或一个以上的矩阵候选。可以通过当前块的矩阵来确定多个矩阵候选中的任意一个。可以基于当前块的编码信息(e.g.,帧内预测模式)进行所述确定。
所述预先约定的矩阵的数量可以与前述的预定义的帧内预测模式的数量相同。另外,所述预先约定的矩阵的数量可以小于所述预定义的帧内预测模式的数量。此时,一个矩阵可以与多个帧内预测模式匹配。例如,一个矩阵可与2个帧内预测模式匹配。此时,所述预先约定的矩阵的数量可以具有预定义的帧内预测模式的数量的1/2倍的值。然而,并不限于此,与一个矩阵匹配的帧内预测模式的数量可以为3个、4个、5个、6个或以上。
作为一个实施例,可以通过考虑帧内预测模式的方向性和/或对称性来确定所述匹配。
预定义的帧内预测模式可以包括具有预定的角度的定向性模式。定向性模式可以区分为具有水平方向性的第一模式组和具有垂直方向性的第二模式组。假设定向性模式的数量为65个的情况,所述第一模式组可以配置为属于索引2至索引34之间的模式,所述第二模式组可以配置为属于索引34至索引66之间的模式。
编码/解码装置仅仅定义针对第一模式组的矩阵,第二模式组同样可以利用针对第一模式组所定义的矩阵。相反,编码/解码装置仅仅定义针对第二模式组的矩阵,第一模式组同样可以利用针对第二模式组所定义的矩阵。此时,预先约定的矩阵的数量可以具有预定义的帧内预测模式数量的1/2倍的值。作为一个实施例,所述具有对称性的模式组为x个时,所述预先约定的矩阵的数量可以具有预定义的帧内预测模式数量的1/x倍的值。其中,x可以为3、4或以上。
所述对称性可以以具有-45°角度的帧内预测模式为基准,包括具有垂直方向性的模式和具有水平方向性的模式之间的预测角度的对称性。其中,具有方向性的帧内预测模式具有根据各个方向性的预测角度(PredAngle)。其中,具有垂直方向性的模式可以以所述角度为-45°的帧内预测模式为基准,包括从该模式和该模式沿x轴方向具有-45°<(PredAngle)≤45°的角度的模式。其中,具有水平方向性的模式可以以所述角度为-45°的帧内预测模式为基准,包括除了该模式以外的从该模式沿y轴方向具有-45°<(PredAngle)≤45°的角度的模式。
参考图5,可以基于参考样本和矩阵来预测当前块(S530)。
当在步骤S510中确定参考样本,在步骤S520中确定矩阵,则编码/解码装置可以基于所述参考样本和矩阵来预测当前块。
所述预测当前块的步骤,可以包括:将所述矩阵适用于所述参考样本中以获得DS块的预测样本(以下,称为第一预测样本)的步骤。所述DS块可以表示当前块,也可以表示已进行下采样的当前块。也就是说,DS块也可以与当前块具有相同的大小,当前块的大小也可以具有(宽度或高度中的至少一个)的1/2、1/4、1/8或1/16的大小。例如,当前块为4×4、4×8或8×4块时,DS块可以为4×4块。或者,当前块未8×8、8×16或16×8块时,DS块可以为4×4或8×8块。或者,当前块大于或等于16×16时,DS块可以为8×8或16×16块。然而,DS块不限于正方形块,也可以为非正方形块。或者,DS块也可以限于正方形块。其中,所述矩阵的适用可以包括将所述参考样本乘以从所述矩阵获得的加权值。
获得所述第一预测样本的步骤,可以包括:添加offset值的步骤或滤波步骤中的至少一个。
获得所述第一预测样本的步骤,还可以包括:对第一预测样本进行重排列的步骤。可以仅限于一个矩阵中匹配多个帧内预测模式的情况进行所述重排列。
或者,当当前块的帧内预测模式属于具有水平方向性的第一模式组时可以进行所述重排列。例如,当当前块的帧内预测模式属于具有水平方向性的第一模式组时,进行针对DS块的第一预测样本的重排列,当当前块的帧内预测模式属于具有垂直方向性的第二模式组时,可以不进行针对DS块的第一预测样本的重排列。
相反,当当前块的帧内预测模式属于具有垂直方向性的第一模式组时可以进行所述重排列。例如,当当前块的帧内预测模式属于具有水平方向性的第一模式组时,不进行针对DS块的第一预测样本的重排列,当当前块的帧内预测模式属于具有垂直方向性的第二模式组时,可以进行针对DS块的第一预测样本的重排列。
可以如下列公式1进行所述重排列。其中,x可以表示×轴坐标值,y可以表示y轴坐标值。也就是说,所述重排列可以表示将(x,y)坐标的第一预测样本分配至(y,x)坐标的过程。
[公式1]
第一预测样本[x][y]=第一预测样本[y][x]
或者,根据本发明的重排列也可以表示由第一预测样本构成的DS块以预定的角度旋转的过程。其中,预定的角度可以表示顺时针方向上的90度或180度,也可以表示逆时针方向上的90度或180度。
所述预测当前块的步骤,还可以包括:基于相邻的已重建的样本或所述第一预测样本中的至少一个对所述当前块进行上采样以获得第二预测样本的步骤。
所述上采样过程中,可以基于当前块的编码信息来确定是否进行所述上采样或所述进行上采样的方法中的至少一个。例如,可以基于由所述第一预测样本构成的DS块的大小和当前块的大小来确定是否进行所述上采样或所述进行上采样的方法中的至少一个。所述块大小可以通过宽度或高度中的任意一个、宽度和高度中的最小值/最大值、宽度与高度的和、属于块的样本的数量等表示出来。
可以仅在由所述第一预测样本构成的DS块的大小小于所述当前块的大小时确定是否进行所述上采样。
所述进行上采样的方法可以包括:利用由所述第一预测样本构成的DS块的大小和所述当前块的大小的比例,将所述第一预测样本分配至所述当前块内的预定的位置中;以及对所述当前块内的剩余区域进行插值。所述剩余区域可以表示在当前块中除了对所述第一预测样本进行划分的区域以外的区域。将参考图8至图10详细描述针对所述第一预测样本的划分以及针对剩余区域的插值方法。
图6示出了作为适用本发明的一实施例的对相邻区域进行下采样来确定参考样本的方法。
参考图6,图6的(a)示出了用于帧内预测的相邻区域位于当前块的左侧以及上层的情况。另外,作为一个实施例,位于当前块的左侧的样本线与当前块接触,并由垂直方向上的1个样本线构成。位于当前块的上层的样本线与当前块接触,并由水平方向上的1个样本线构成。
所述参考样本可以包括通过对所述当前块的相邻区域进行下采样而形成的下采样区域。
可以由属于所述相邻区域的全部或一些样本的平均值、最大值、最小值、众数、或进行了滤波的值而导出所述下采样区域。
当由所述平均值导出时,可以通过将不同的N个样本的平均值分配至下采样区域的样本中的方法形成所述下采样区域。
所述不同的N个样本可以为连续排列的样本,或可以相隔一定间隔。所述一定间隔为一个或一个以上的样本大小的间隔。当所述间隔为多个时,所述多个间隔可以均匀或不均匀。(其中,N大于2,并且小于属于所述相邻区域的样本的总数量。)另外,将所述不同的N个样本的组合称为样本组。此时,第一样本组可与第二样本组重叠,或不重叠。
作为一个实施例,图6示出了N为2,2个样本组相互不重叠,并将属于各个样本组的2个样本的平均值分别分配至下采样区域中的1个样本中,以进行下采样。
或者,连续的3个样本(S1、S2、S3)可以构成第一样本组,并且可以将属于第一样本组的3个样本的平均值分配至下采样区域的样本(DS1)中。连续的3个样本(S2、S3、S4)可以构成第二样本组,并且可以将属于第二样本组的3个样本的平均值分配至下采样区域的样本(DS2)中。
或者,确定属于第一样本组的2个样本(S1、S2)中的最小值或最大值之后,可以将其分配至下采样区域的样本(DS1)中。同样地,确定属于第二样本组的2个样本(S3、S4)中的最小值或最大值之后,可以将其分配至下采样区域的样本(DS2)中。在第一/第二样本组由3个样本构成的情况下也可以相同地利用。
或者,上层相邻区域中,属于第一样本组的多个样本中预定义的位置处的样本可以分配至下采样区域的样本(DS1)中,属于第二样本组的多个样本中预定义的位置处的样本可以分配至下采样区域的样本(DS2)中。所述预定义的位置可以表示编码/解码装置中预先约定的固定位置,作为一个示例,可以为最左侧、最右侧或中间位置中的任意一个。左侧相邻区域中,属于各个样本组的多个样本中预定义的位置处的样本也可以分别分配至下采样区域的样本中。此时,预定义的位置可以为最上层、最下层或中间位置中的任意一个。
图7示出了作为适用本发明的一实施例的基于加权平均值的下采样方法。
本实施例中,平均值可以通过以下式来计算(以下,称第一平均表达式):
属于样本组的样本和/样本数量;
或通过以下式来计算(以下,称第二平均表达式):
Sum(加权值×属于样本组的样本)/样本数量。
图7的(a)示出了前述的样本组由3个样本构成的情况。此时,适用于3个样本的加权值可以被确定为1:2:1的比例。如图7的(b)所示,当样本组由5个样本构成时,所述加权值可以被确定为1:1:4:1:1的比例。如图7的(c)所示,当样本组由6个样本构成时,所述加权值可以以左侧上层为起始点,在Z方向上,被确定为1:2:1:2:2:1或1:2:2:1:2:1的比例。另外,所述图7的(a)和(c)虽然示出了适用于上层相邻区域的加权值,但这也可以同样适用于左侧相邻区域中。
所述平均值也可以包括:在通过所述第一平均表达式或第二平均表达式计算出来的多个平均值中适用预定的运算而导出的结果值。其中,预定的运算可以为前述的第一平均表达式或第二平均表达式。例如,若3个样本(即,第一至第三样本)属于样本组时,可以分别计算第一样本和第二样本之间的平均值(第一值),以及第二样本和第三样本之间的平均值(第二值)。可以由计算出来的第一值以及第二值之间的平均值导出所述平均值。
前述的下采样方法可以仅适用于上层相邻区域,相反地,也可以仅适用于左侧相邻区域。或者,根据图6的下采样方法(以下,称第一方法)可以适用于上层或左侧相邻区域中的任意一个,根据图7的下采样方法(以下,称第二方法)可以适用于上层或左侧相邻区域中的另一个。
另外,考虑当前块的大小/形状,可以选择性地利用第一方法或第二方法中的至少一个。例如,当前块的宽度大于预定的阈值时,第一方法可以适用于当前块的上层相邻区域,否则,可以适用第二方法。也可以通过同样的方式对当前块的高度进行下采样。或者,当前块为非正方形时,第一方法可以适用于上层或左侧相邻区域中的任意一个,第二方法可以适用于另一个区域中。此时,当前块的宽度大于高度时,第一方法可以适用于上层相邻区域,第二方法可以适用于左侧相邻区域。相反,当前块的宽度小于高度时,第二方法可以适用于上层相邻区域,第一方法可以适用于左侧相邻区域。当前块为正方形时,上层以及左侧相邻区域中可以使用相同的下采样方法,其中下采样方法也可以限于所述第一方法。
图8示出了作为适用本发明的一实施例的第一预测样本的划分和对其余区域的插值方法。
参考图8的(a),DS块的预测样本可以分配至当前块中预定的位置处的预测样本中。其中,可以通过考虑当前块和DS块之间的大小比例而确定预定的位置。例如,DS块和当前块之间的预测样本的对应关系可以如以下公式2定义。
[公式2]
第一预测样本curBLK[(x+1)×r-1][(y+1)×r-1]=第一预测样本dsBLK[x][y]
其中,r表示当前块与DS块之间的大小比例,x、y分别为每个DS块内的第一预测样本的x轴、y轴坐标。第一预测样本curBLK可以表示当前块内的第一预测样本的位置,第一预测样本dsBLK可以表示DS块内的第一预测样本的位置。
所述插值,参考图8的(b),可以利用与向当前块划分的所述第一预测样本或所述当前块相邻的已重建的样本中的至少一个(以下,称为插值参考样本)而导出在当前块中没有对所述第一预测样本进行划分的样本(以下,称为插值对象样本)。另外,所述插值参考样本还可以包括在当前插值对象样本之前通过插值生成的预测样本(即,上一个插值对象样本)。
与所述当前块相邻的已重建的样本的位置以及范围与前述的参考样本相同,故在此省略其详细描述。
根据插值对象样本的位置,所述插值参考样本可以由多个第一预测样本构成,或可以由至少一个第一预测样本和至少一个已重建的相邻样本构成。所述已重建的相邻样本可以选择性地利用具有与插值对象样本相同的x坐标或y坐标样本中的任意一个,或可以利用x坐标或y坐标中的至少一个与插值对象样本的多个样本。可以基于插值对象样本的位置进行所述选择。例如,若插值对象样本具有与第一预测样本相同的x坐标时,已重建的相邻样本可以仅包括具有与插值对象样本相同的x坐标的样本。相反,若插值对象样本具有与第一预测样本相同的y坐标时,已重建的相邻样本可以仅包括具有与插值对象样本相同的y坐标的样本。或者,已重建的相邻样本也可以包括位于与插值对象样本相同的水平以及垂直线上的多个样本。
所述插值对象样本可以由多个插值参考样本的代表值而导出,其中,代表值可以包括平均值、最小值、最大值、众数、或中间值中的任意一个。
所述平均值可以通过以下式来计算(以下,称第一平均表达式):
差值参考样本总和/差值参考样本数量;
或可以通过以下式来计算(以下,称第二平均表达式):
Sum(加权值×差值参考样本)/差值参考样本数量。
可以基于插值对象样本和插值参考样本之间的相对/绝对距离确定根据第二平均表达式的加权值,这可以参考图9详细描述。
图9示出了作为适用本发明的一实施例的在插值步骤中分配针对距离的权重值。
根据本发明的加权值可以包括基于从插值对象样本到插值参考样本的距离而确定的加权值。作为一个实施例,参考图9,若对第一插值对象样本910进行插值,由于从第一插值对象样本910到第一插值参考样本911和第二插值参考样本912的各自的距离比例为3:1,因此适用于第一插值参考样本911和第二插值参考样本的加权值比例可以为1:3。若对第二插值对象样本920进行插值,由于从第二插值对象样本920到每个第一插值参考样本921和第二插值参考样本922的的距离比例为1:1,因此适用于第一插值参考样本和第二插值参考样本921、922的加权值比例可以为1:1。
另外,根据本发明的插值滤波器可以具有方向性。所述方向性可以包括垂直、水平、z型、对角线等方向。
可以基于预定的优先顺序进行所述插值。所述优先顺序可以为在垂直方向进行插值后在水平方向进行插值的情况(第一顺序)或在水平方向进行插值后在垂直方向进行插值的情况(第二顺序)中的任意一个。或可以同时在垂直方向以及水平方向进行插值(第三顺序)。
可以仅利用前述的第一顺序至第三顺序中的任意一个对当前块进行插值,或可以利用第一顺序至第三顺序中的至少2个组合对其进行插值。针对插值顺序,请参考图10详细了解。
图10示出了作为适用本发明的一实施例的插值步骤的顺序。
图10的(a)为关于图9中的第一顺序。具体地,可以先对第一预测样本所属的垂直线进行插值,再基于进行了插值的线和当前块左侧的插值参考样本,对水平线进行插值。
图10的(b)为关于图9中的第二顺序。具体地,可以先对第一预测样本所属的水平线进行插值,再基于进行了插值的线和当前块上层的插值参考样本,对垂直线进行插值。
图10的(c)为关于图9中的第三顺序。首先,可以对第一预测样本所属的垂直以及水平线进行插值。然后,针对没有进行插值的剩余样本进行插值,此时可以仅对垂直线或水平线进行插值,或可以同时对垂直以及水平线进行插值。若同时对所述垂直以及水平线进行插值时,一个插值对象样本可以同时具有垂直线上的第一插值值以及水平线上的第二插值值。此时,可以将第一插值值和第二插值值之间的代表值分配至所述插值对象样本中。其中,可以由平均值、最小值、最大值、众数、或中间值来导出代表值。
所述插值顺序可以为编码/解码装置中预先约定的顺序,或可以基于当前块的编码信息来选择性地确定。其中,编码信息如前所述,因此省略其详细描述。
可以基于块大小确定所述顺序。所述块大小可以通过宽度或高度中的任意一个、宽度和高度中的最小值/最大值、宽度与高度的和、属于块的样本的数量等表示出来。
例如,当前块的大小大于预定的阈值时,可以进行所述第一插值,否则可以进行所述第二插值。相反,当前块的大小小于预定的阈值时,可以进行所述第二插值,否则可以进行所述第一插值。所述阈值可以为8、16、32或更大的自然数。
- 利用帧内预测的图像编码/解码方法以及装置
- 用于执行帧内预测的图像解码方法及其装置以及用于执行帧内预测的图像编码方法及其装置