用于确定测试人员的听阈的方法
文献发布时间:2023-06-19 11:24:21
技术领域
本发明涉及一种用于确定测试人员的听阈的方法。此外,本发明涉及一种用于设置听力设备的听力设备参数的方法。此外,本发明涉及一种听力设备系统。
背景技术
听力设备通常用于向相应的听力设备的用户的听觉器官再现声信号。为此,听力设备包括至少一个输出转换器,通常是扬声器(也称为“受话器receiver”)。以所谓的助听器的形式,听力设备用于向其听力减弱的人员提供声信号。为此,助听器通常包括至少一个麦克风、信号处理器以及上述输出转换器,该信号处理器主要用于对借助麦克风所采集到的声音进行特定于用户的、取决于频率的滤波、放大和/或衰减。根据听力障碍的类型,除了先前所描述的扬声器之外,输出转换器还可以被构建为骨传导听筒或耳蜗植入物,以对用户的听觉器官进行机械或电刺激。然而,除了助听器之外,原则上还使用耳机、头戴式耳机、“可听器(hearables)”等,以及术语“听力设备”。
为了对信号处理器中的信号处理进行单独调整,通常为用户创建所谓的听力图。又可以从中读出或确定所谓的听阈,即,用户可以从哪个音量值起听到特定音频的声响。传统上,在此首先向用户呈献具有增加或至少改变的音频的依次的声响,其中,在其值方面(连续地或逐步地)增大音量值。然而,该测试方法相对容易出错,因为用户总是预计在测试开始或确认先前的声响之后的时间段内呈献具有改变的音频的另一声响,并且因此可能会“盲目地”,即,在实际上并没有听到声响的条件下确认了声响。另一方面,该测试方法相对简单。
发明内容
因此,本发明要解决的技术问题是,使得能够可以尽可能鲁棒地确定听阈。
根据本发明,上述技术问题通过下面所描述的方法来解决。此外,根据本发明,上述技术问题通过下面所描述的计算机程序产品、下面所描述的另外的方法来解决。此外,根据本发明,上述技术问题通过下面所描述的听力设备系统来解决。在下面的描述中,阐述了本发明有利的以及一些本身有创造性的实施方式和进一步扩展。
根据本发明的方法用于确定测试人员的听阈。在此,尤其将如下声学信号、特别是声音(例如声响)的音量(或者也可以是:水平或等级)的最低值理解为“听阈”:在该声学信号下测试人员还能够感知、即听到该声音。因此特别地,听阈取决于频率。
在根据本发明的方法的范围内,借助输出转换器向测试人员依次呈献(或呈现)多个声响组(Tonsatz),这些声响组大多包含多个声音、特别是分别具有在一个声响组内保持相同但优选彼此至少部分不同的特性的多个声音。在每次呈现了这些声响组中的一个之后,询问测试人员来说明从该(即,特别是紧接在前)所呈现的声响组中感知到的声音的数量。依据感知到的声音的数量,为了呈现后续声响组,相对于在前声响组至少改变了(在该后续声响组中的)至少一部分声音的特性。然后,将该改变后的后续声响组呈现给测试人员。依据各个在所呈现的(尤其是至少两个,优选地多于两个的)声响组中感知到的声响的数量,估计测试人员的听阈的至少一个值,特别是单个的、优选地特定于频率的值和/或越过多个音频的走向。
换言之,向测试人员试奏带有多个(特别是具有互不相同但对其自身分别保持相同的特性的)声音的声响组。对于该声响组,测试人员必须做出关于其中所包含的感知到的声音的数量的说明。依据针对第一声响组所选择的声音特性,可能已经可以估计针对听阈的第一估计值,尤其是在测试人员没有听到(即,并未已说明为是可听到的)在该声响组的范围中所呈现的所有声音的情况下。为了验证和/或更精确地确定听阈的估计值,然后呈现至少一个另外的声响组,对于该至少一个另外的声响组中的声音至少部分地改变了特性。特别地,对于在第一声响组中或者必要时还在紧随其后的声响组中测试人员分别将所有声音说明为已听到的情况,适宜地还未设置针对听阈的(第一)估计值。
在此以及在以下,特别地将对具有“大多多个声音”的多个声响组的呈献理解为声响组原则上包含多个已演奏或待演奏的声音,但声响组也可能被个别地设置有仅一个声音(在极端情况下甚至没有声音)。在此,相对于声响组的总体数量,这种“单个声响组”或“空声响组”的数量很小,例如在直至20%的范围内。
在此以及在以下,尤其将术语“声音”理解为合适的测试声音,由于预先给定的并且优选地明确限定的特性,该测试声音不同于通常被作为“纯样品”来记录的“日常声音”或“环境声音”(例如,鸟鸣、电气设备的声音;其因此尤其具有在其各个组分方面未知的特性)。优选地,声音是合成地生成的(“经设计的”)声音或者还是在记录之后经处理(例如,通过过滤不期望的频率分量等)的声音样本。在“广义”上,声音因此近似代表一种尤其是在音乐意义上的声响。在此,例如可以通过“纯”正弦音、经调制的正弦音、声调(在声学意义上;即,例如还有和弦)、所谓的摇摆音、所谓的窄带噪声或者类似的声音信号来形成该声响(或者声音)。对于先前所描述的声音、特别是对于窄带噪声,优选地使用从大概三度至八度的频率宽度。虽然这种声音(例如,摇摆音等)原则上可以具有变化的、例如波动的频率,因为该频率在已知的以及特别是明确限定的范围(例如在为窄带噪声所规定的频率范围)内“运动”,但是由于声音本身保持相同,因此在此以及在以下将这优选地也理解为保持相同的特性。下面,为了更简单的理解,术语“声响”被用作对于“声音”的等效术语(而不排除声响作为正弦音、窄带噪声等的具体设计方案)。对应地,在此以及在以下,术语“声响组”也被用于如下的组:该组可以如先前已经描述的那样大多包含多个声响,然而在极端情况下也可以包含一个声响或者完全不包含声响。
在呈献声响组时,优选地时间上依次地、必要时通过时间间隙(或者“停顿”)间隔地呈现该声响组的声响。
优选地将扬声器用作输出转换器。即,因此,特别是在声学上呈现声响组,具体而言呈现其声响。然而,原则上,根据本发明的方法也可以以借助骨传导听筒或耳蜗植入物输出相应声响组的方式来执行。
优选地,测试人员没有获得关于相应声响组中所包含的声响数量的信息。
依据对(例如第一)“在前”声响组的应答而改变的“后续”声响组可选地是实际上紧随其后的声响组。替换地,然而也可以偏移了“所插入”(例如已经与在前声响组并行地在其声响中所选择出)的声响组地在后续呈现该经改变的后续声响组。因此,在此以及在以下,术语“后续”尤其描述了依据对应在前的声响组而改变的声响组。
由于测试人员必须说明声响的数量,而不是仅对一个声响本身的感知做出反应,因此降低了测试人员(不自觉或有意识地为改善结果而)做出错误说明的风险。由于依据所给出的说明调整了对对应的后续声响组的选择,因此对于测试人员还必须更困难地评估测试系统(例如,相较于在传统听力图的范围中依次以增加的音量来呈现的声响)。因此,可以以相对简单的方式期待更好的测试结果。
在优选的方法变形方案中,分别给相应的声响组内的每个声响分配不同的音量值作为特性。即,在声响组内呈现不同响度的声响。在这种情况下,如果测试人员说明了与实际呈现的声响数量相比减少了的感知到的声响数量,则可以由此得出结论:具有最低音量值的声响对于测试人员来说已经不可听到(即“太轻”)。例如,在(在方法开始时所选择的、即“第一”)声响组中呈现了具有40、45和50dB HL(dB“听力水平Hearing Level”;该度量单位特别涉及听力正常人员的听阈)的音量值的三个声响。在该示例中,如果测试人员说明已经听到了两个声响,则可以假定在40dB HL下的声响已经不可听到。
在上面刚刚描述的方法变形方案的适宜的扩展中,为了特别简单地、取决于频率地确定声响组的至少一个第一子集的听阈(具体而言其特定于频率的值),作为特性,给该第一子集的每个声响组的声响分配相同的音频(特别是在正弦音的情况下),或者在先前所描述的替换方案、例如经调制的正弦音、声调、窄带噪声等方面分配相同的频率范围(其例如对称地包围了待检查的音频)。换言之,在多个优选地依次呈现的声响组中,总是呈现相同的声响,这些相同的声响仅具有不同的音量值。由此,首先可以以简单的方式为当前的音频(或当前的频率范围)确定对应的特定于频率的听阈的值。因此,优选地借助第二子集,特别是在利用多个声响组进一步运行的范围内,确定针对另外的音频(或另外的频率范围)的听阈的值。在该情况下,例如(针对第一特定于频率的听阈的值)在2000Hz下(或者在围绕2000Hz的范围内)呈现在先前所描述的实施例中所呈现的三个声响。如果确定了特定于频率的听阈的值,则优选地针对另外的音频(或另外的频率范围)启动类似的流程。
在另外的适宜的方法变形方案中,尤其是针对声响的音频(或频率范围)保持相同的情况,为了呈现后续声响组,作为特性,改变至少一部分声响的音量值。
在对于以上方法变形方案的扩展中,优选地依据估计值来选择(特别是后续声响组的)至少该部分声响的音量值,该估计值根据一个或多个在前声响组中感知到(“听到”)的声响的数量来选择(或推导)。优选地,尤其将在未听到的声响中的“最响”声响到下个更响的尚可听到的声响的范围内的值、例如该下个更响的声响的音量值假设为针对听阈的(第一“粗糙”)估计值。因此,该音量值与包含在被说明为可听到的数个声响中的最低音量值对应。因此,如果呈现了(延续先前所描述的实施例例如具有40、45和50dB HL的音量值的)三个(优选地统一音频或者相同频率范围的)声响,并且测试人员说明已经听到了两个声响,则在具有中等音量值(在此即为45dB HL)的声响下假设针对听阈的估计值。然后,在后续(必要时,紧随其后)的声响组中,呈现了例如35、40和45dB HL下的三个声响。如果测试人员说明仅已经(“尚”)可听到一个声响,则听阈很可能为45dB HL。同样,也可以(在该声响组中或附加地在另外的声响组的范围中)呈现45、50和55dB HL的音量值。如果测试人员说明已经听到了三个声响,则听阈在45dB HL的可能性也会增加。
在适宜的方法变形方案中,将声响组的各个声响之间的音量值的步长选择为在各个声响组之间恒定。即,在所有所呈现的声响组中,各个音量值的间距彼此相同。
在替换的变形方案中,为了更精确地限制听阈的值,音量值之间的步长也同样被更改。例如,在呈现了40、45和50dB HL的音量值并且说明已经听到两个声响之后,将音量值设置为42、44和45dB HL。
在可选的方法变形方案中,分别给相应的声响组内的每个声响分配不同的音频(或不同的频率范围)作为特性。例如,在此,(至少在声响组内或者超越声响组的子集地)选择了针对声响的恒定的音量值。在该情况下,因此在音量保持不变的情况下改变音频(或频率范围),以便找出相应的特定于频率的听阈值。替换地,音频(或频率范围)和音量都改变。在后一种情况下,需要组合分析和/或与保持恒定的特性相比更复杂的试验计划。
在优选的方法变形方案中,将已经说明特别是在超过50%的如下声响组中、但至少在两个声响组中是(“尚”)可听到的(也就是因此作为估计值)的音量值确定为针对音频的听阈(具体而言,确定为听阈的值),根据这些声响组分别可以推导出针对听阈的估计值(即,在这些声响组中优选地既不是所有的声响都已经被说明为可听到也不是没有声响被说明为可听到),即特别地根据测试人员的说明该音量值可以被推导为最低可听到的音量值。在先前所描述的实施例的意义上,如果在包含音量值35、40和45dB HL的后续声响组中在测试人员侧说明了一个可听到的声响,则将音量值45dB HL设置为听阈的值。
在有利的方法变形方案中,为一部分声响组选择如下声响,该声响具有在至少对于测试人员来说(在每个情况下)可听到的音量值之下的音量值。优选地,在此针对该声响,音量值甚至被选择为,声响独立于测试人员地是不可听到的,即,优选地位于对于没有听力障碍的人员而言可听到的音量值之下(听力正常人员的听阈通常为0dB HL,这在1000Hz下还对应于大约3dB SPL;在该方法变形方案中,“为安全起见”,优选地将音量值设置为-10dBHL)。优选地,这种声响组与“正常”声响组(即,具有至少潜在地可被测试人员听到的音量值的声响组)交替。由此,能够有利地实现对于所谓的“假阳性”(英语:“false positive”)的应答的控制。对于测试人员尤其还多次在这种声响组中将所有声响说明为可听到的情况,则例如输出警告或错误通报。特别地,可以在在此以及在以下所描述的方法的自动化方面简单地实施该变形方案,因为仅需要改变音量值。
在替换的(或可选地附加的)方法变形方案中,在相应的声响组之间,所包含的声响的数量也发生变化。在此,对声响的“更多说明”(即,感知到的声响比所呈现的声响的数量更多)同样能够实现如下结论:测试人员做出了“错误的”说明。在此还可想到,对于该控制,还个别地呈献具有仅一个再现的声响的声响组,或者在极端情况下还呈献没有声响(或者必要时具有至少对于测试人员、优选地对于听力正常人员不可听到的声响)的声响组以及优选地具有整个声响组持续时间的声响组,其与具有多个声响的声响组相似。
为了进一步提高错误抵抗力,在适宜的方法变形方案中,在声响组内和/或在声响组之间改变各个声响的持续时间。
附加地或替换地,改变各个声响之间的间隙(“停顿”)的持续时间。通过该时间上的改变,降低了测试人员成功尝试估计声响组的持续时间并例如从中推断所包含的声响数量的可能性。
此外附加地,还改变声响组内的以及优选地还有在声响组之间的声响的顺序、特别是音量值(必要时还有音频)的顺序。换言之,不仅呈现了下降(即递减)或上升的顺序,而且还呈现了混合的顺序(例如按照顺序55、45和50dB HL的音量值)。
在另外的可选的方法变形方案中,还特别地具有间隔地(即,在多个另外的声响组之后)再次呈现了已经呈现了一次的声响组。由此,可以进一步提高对听阈的值的估计精度。
特别地针对在声响组中没有声响被说明为可听到的情况,在后续声响组中输出至少一个声响,该声响具有相对于在前声响组的最高音量值提高了例如5dB的音量值。
针对声响组中所有声响被说明为可听到的情况,在下一个声响组中优选地输出如下声响:该声响包含与在前声响组的最低音量值相比低了例如10dB的音量值。
针对(特别是对于听力正常者可容忍的或者还有最大可输出的)最高音量值被(优选地两次)说明为不可听到的情况,优选地以具有另外的音频的声响的声响组的新的子集来继续在此以及以下的方法。
适宜地,在实际确定听阈之前,即特别是在选择第一声响组之前,执行适应环境阶段。在此,特别是对于对所有声响使用了相同音频或(在经调制的声响、声调或窄带声音的意义上)使用了相同频率范围的情况,向测试人员试奏为后续声响组、特别是为声响组的后续子集而使用的声响。由此,测试人员可以为后续测试进行设置。
在优选的方法变形方案中,借助输出转换器、特别是借助听力设备(优选地,助听器)的扬声器来呈现声响组。
在适宜的方法变形方案中,通过单独的控制设备,进行对输出转换器、特别是听力设备的在前扬声器的控制以及对测试人员的询问,以及特别地还对后续声响组、即至少对其相应部分的声响进行先前所描述的改变。换言之,因此优选地通过该控制设备进行对先前所描述的方法的控制(或者还有:“处理”)。优选地,控制设备是具有可执行地安装的软件应用程序(App)的移动终端设备,优选地是智能电话、平板电脑等,软件应用程序在移动终端设备上实施时其被设计为优选地自动执行先前所描述的方法。特别地,控制设备在此包括具有数据存储器的微处理器,在该数据存储器上存储了上述应用程序。在按规定的运行中,微处理器处理应用程序的程序代码中包含的命令,从而执行先前所描述的方法。
因此,根据本发明的计算机程序产品优选地形成上述应用,并且因此具有带有命令的程序代码,在通过处理器、具体而言上述微处理器实施程序代码时,这些命令促使该程序代码尤其自动地实施先前所描述方法。
根据本发明的用于设置测试人员的听力设备(具体而言,先前所描述的听力设备、优选地助听器)的听力设备参数的方法包括先前所描述的用于确定测试人员的听阈的方法。此外,在确定了听阈、具体而言其值、优选地听阈在多个音频上的走向之后,基于听阈来调整听力设备的信号处理算法。优选地,用于设置听力设备参数的功能也包含在先前所描述的应用程序中。
根据本发明的听力设备系统至少包括听力设备,并且被配置为用于优选地自动地、至少部分地与测试人员交互地执行先前所描述的用于确定测试人员的听阈的方法。为此,听力设备系统优选地包括先前所描述的移动终端设备。因此,特别是在终端设备的控制下,根据本发明的听力设备系统被配置为用于借助输出转换器、特别是听力设备向测试人员依次呈献多个声响组,多个声响组大多包含多个声音、特别是具有分别在声响组内保持不变、但是优选地至少彼此部分不同的特性的多个声音。此外,听力设备系统被配置为用于在每次呈现这些声响组中的一个之后询问测试人员来说明从该所呈现的(即,尤其是紧接在前的)声响组中感知到的声音的数量,以及依据感知到的声音的数量,为了呈现后续声响组,相对于在前声响组至少改变了(在该后续声响组中的)至少一部分声音的特性。此外,听力设备系统被配置为用于然后向测试人员呈现该改变的后续声响组,并且依据各个在所呈现的(尤其是至少两个,优选地多于两个的)声响组中感知到的声响的数量,估计测试人员的听阈的至少一个值,特别是单个的、优选特定于频率的值和/或越过多个音频的走向。
因此,听力设备系统以及先前提到的根据本发明的方法(以及还有在通过处理器实施时的计算机程序产品)分享相同的优点以及从相应的描述得出的物质特征。
在此以及以下,连词“和/或”尤其被理解为,借助该连词所关联的特征既可以共同构建,也可以作为彼此的替换来构建。
附图说明
下面,根据附图更详细地阐述本发明的实施例。附图中:
图1以示意图示出了听力设备系统,以及
图2以示意性流程图示出了由听力设备系统执行的方法。
在所有附图中,彼此对应的部分始终具有相同的附图标记。
具体实施方式
图1中,示意性地示出了听力设备系统1,该听力设备系统被配置并且被设置为用于照顾听力减弱的人员。听力设备系统1包括听力设备2,该听力设备被构建为助听器、在当前实施例中被构建为佩戴在耳后的助听器。在此,听力设备2具有作为电子组件的两个麦克风4、作为输出转换器的扬声器6以及信号处理器8。在按规定的运行中,麦克风4采集环境声音,并将这些环境声音以电麦克风信号的形式转发给信号处理器8。信号处理算法在后者上运行,信号处理算法的参数使得能够将听力设备2与人员的听力障碍的类型和严重程度匹配,并具体反映在按规定的运行中。例如,通过参数预先给定了特定于频率的放大值,以便特别地提高其音量值位于人员的听阈的值之下的麦克风信号并且由此使其对于人员(也被称为“听力设备佩戴者”)是可听到的。随后,经由扬声器6输出经处理的麦克风信号。
为了确定正确的参数,定期创建人员的听力图。为了自动创建听力图,听力设备系统1具有控制设备10,该控制设备被配置为用于以与人员交互的方式执行下面根据图2更详细地描述的方法。具体地,通过移动终端设备、特别是智能电话12来形成控制设备10,在该移动终端设备上可执行地安装控制软件(也被称为:“计算机程序产品”,下面也简称为:“应用程序14”)。在按规定的运行中,智能电话12与听力设备2处于无线的通信连接16。
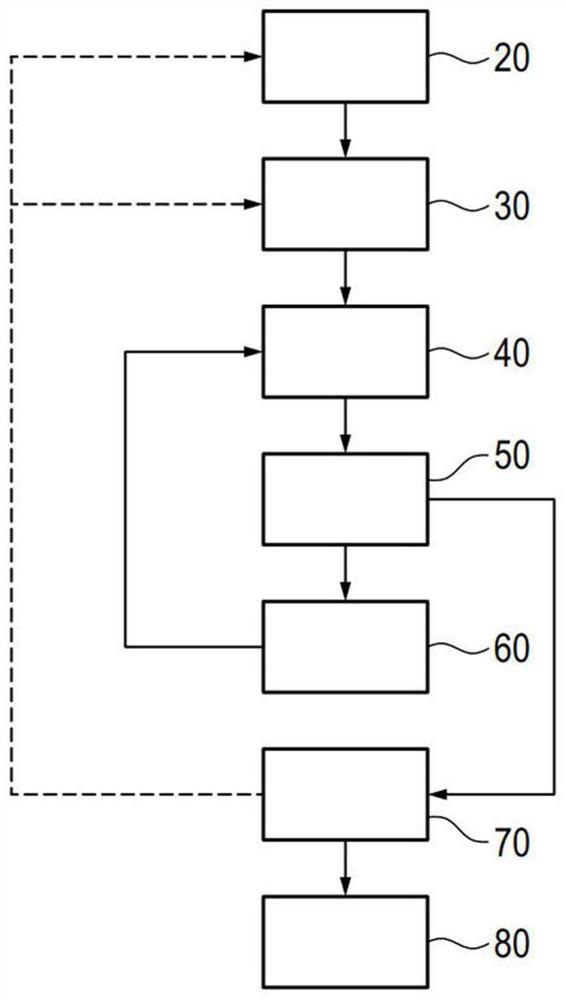
在第一方法步骤20(参见图2)中,向(在该情况下代表测试人员的)人员试奏声响(在本实施例中,具有特定音频、在此具体并且示例性为2000Hz的纯正弦音)。如果人员听到该(正弦)声响,则可以开始测试以确定人员的听阈的特定于频率的值。方法步骤20代表适应环境阶段。
作为纯正弦音的替换,也可以使用具有从大概三度至八度的频率范围的经调制的正弦音、声调或窄带噪声。
在第二方法步骤30中,由控制设备编排具有三个声响的第一声响组,这三个声响具有不同的音量值(例如60、50和55dB HL),并且经由听力设备2的扬声器6向人员呈现、即试奏该第一声响组。分别通过停顿来彼此分隔各个声响。
在后续的方法步骤40中,询问人员(具体地,在智能电话12上显示对应的问题,可选地还朗读出对应的问题)该人员可以听到多少个声响。
在另外的方法步骤50中,对人员已经在智能电话12上输入的应答进行分析,并为另外的声响组编排了具有部分改变的音量值的(具有相同的音频的)三个新声响。对于人员说明已经听到了三个声响的情况,则编排三个新的声响,这三个新的声响中最响的音量值比在前声响组中最轻的音量值低10dB(在本实施例中即45、40和35dB HL)。在另外的声响组的范围内,在后续方法步骤60中呈献这些声响。反之,如果没有听到声响,则在方法步骤60中再次提供具有改变的音量值的三个声响,其中,音量值比在前声响组中最响的音量值响了至少5dB,在此即65、70和75dB HL。
如果在后续声响组中的第一个或其中一个中未感知到至少一个声响,则升序排序音量值,并且“删除”数个从最低音量值开始的未听到的声响。在此,将最低的“剩余”音量值用作针对听阈的估计值。因此如果示例性地在呈献具有音量值50、55和60dB HL的三个声响时从人员方面说明已经听到了两个声响(这因此对应于一个未感知到的声响),则将估计值设置为55dB HL。对于在第一或紧随其后的声响组中所有接收到的声响被说明为已听到或没有声响被说明为已听到的情况,则换言之首先还不能设置针对听阈的估计值。
在此,各个声响之间的停顿(即,时间间隙)以及声响长度本身在声响组内以及在声响组之间发生变化。
在方法步骤60之后,返回到方法步骤40,获得人员的应答并且在方法步骤50中进行分析。
如果在重复呈献与听阈的估计值对应的音量值时,(对于相对于这一个音量值的呈献次数超过50%的情况)同样重复地将该音量值说明为最低的可听到的音量值,则转到随后的方法步骤70并将该估计值设置为(“最终”或“经确认”)的听阈的值。换言之,如果对于声响组(该声响组包含至少一个具有相同音量值的声响)的所有呈献中超过50%的情况,该音量值被已经确定为最低的可听到的值(并因此已经被考虑作估计值),则该音量值恰好在方法步骤70中被设置为听阈的值。随后跳回到方法步骤20或方法步骤30,并以新的音频重新执行相同的方法。
如果针对每个音频例如以500、1000、2000、3000至4000Hz的步长来确定听阈的值,则在此基础上在另外的方法步骤80中重新设置/预先给定参数,并将其发送到听力设备2。
本发明的内容不限于先前所描述的实施例。更确切地说,可以由本领域技术人员从先前的描述中推导出本发明的另外的实施方式。特别地,根据不同的实施例来描述的本发明的单个特征及其设计变形方案也可以以另外的方式彼此组合。
附图标记列表
1 听力设备系统
2 听力设备
4 麦克风
6 扬声器
8 信号处理器
10 控制设备
12 智能电话
14 应用程序
16 通信连接
20 方法步骤
30 方法步骤
40 方法步骤
50 方法步骤
60 方法步骤
70 方法步骤
80 方法步骤。
- 用于确定测试人员的听阈的方法
- 一种用于调节测试人员的认真程度的刺激方法