一种结合重采样和集成学习的电力电子系统故障诊断方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于电力电子设备故障诊断技术领域,尤其涉及一种结合重采样和集成学习的电力电子系统故障诊断方法。
背景技术
电力电子变流器在能量转换系统中发挥着不可或缺的作用,广泛应用于光伏发电、铁路电力牵引运输、电池充电、航空航天系统等领域。由于电力电子设备容易发生故障,故障率高,电力电子变流器是常见的故障源之一,因此,准确的故障诊断对于故障后容错运行控制和系统的进一步维护具有重要意义。
随着人工智能和数据科学技术的快速发展,许多基于数据驱动的故障诊断方法被提出以应对电力电子变流器系统故障诊断方法中的难点问题和技术挑战,如多种故障类型、数学模型不准确等。然而,大多数情况下,智能诊断模型是由一个满意的数据集训练的,这不仅意味着有足够的样本和很少的噪声,而且意味着不同类别的样本分布是均衡的。实际上,电力电子变流器系统的故障状态很少,原始历史监测数据集总是不平衡的,正常运行数据样本大于故障数据样本。由于智能学习方法对每个样本都同等重视,少数故障样本容易被智能学习方法忽略,这导致诊断模型即使有高训练精度,少数故障样本的故障诊断性能也较差,出现故障类型误判。因此,在电力电子系统故障诊断中,针对数据不平衡问题,迫切需要设计一种分类器,可以为提高少数故障样本的诊断精度,而且不会严重牺牲大多数正常样本的精度。
发明内容
针对现有技术中的上述不足,本发明提供的一种结合重采样和集成学习的电力电子系统故障诊断方法解决了现有故障诊断方法中存在的原始数据样本不平衡、导致现有机器学习模型诊断不准确甚至判断错误的技术问题,有效地实现了电力电子系统的传感器和功率器件多种不同故障类型的诊断。
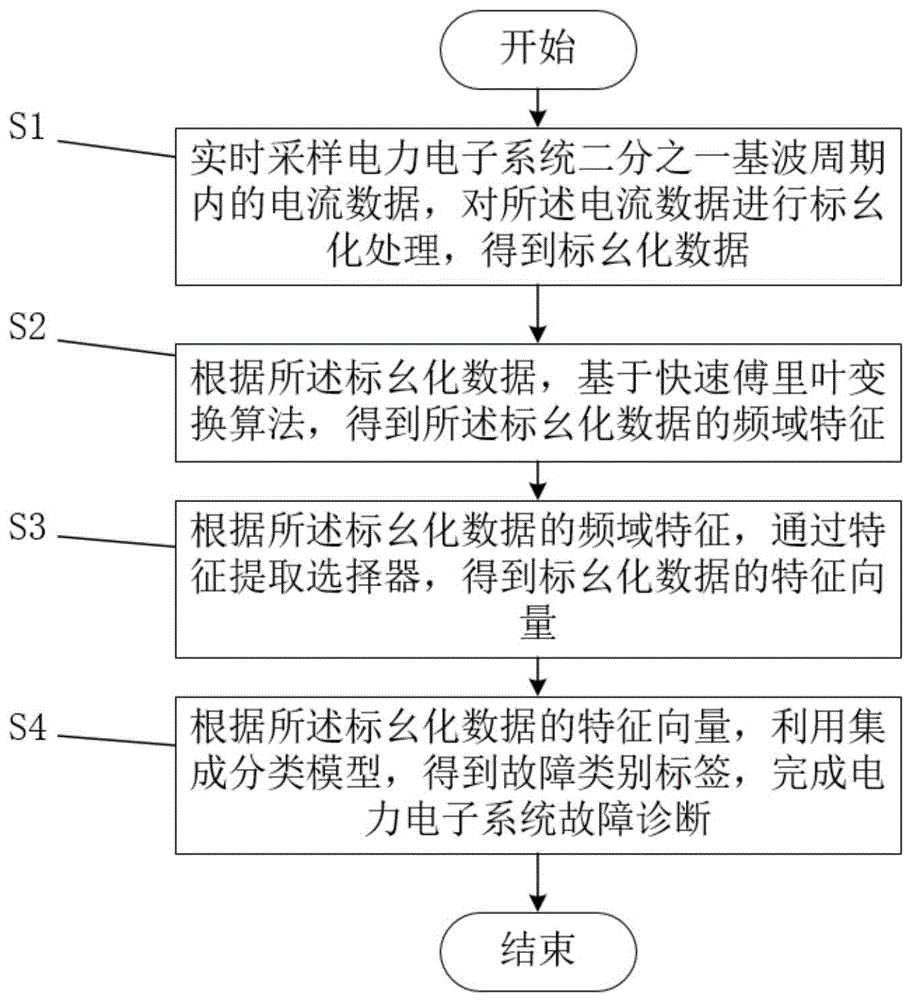
为了达到上述发明目的,本发明采用的技术方案为:一种结合重采样和集成学习的电力电子系统故障诊断方法,包括以下步骤:
S1、实时采样电力电子系统二分之一基波周期内的电流数据,对所述电流数据进行标幺化处理,得到标幺化数据;
S2、根据所述标幺化数据,基于快速傅里叶变换算法,得到所述标幺化数据的频域特征;
S3、根据所述标幺化数据的频域特征,通过特征提取选择器,得到标幺化数据的特征向量;
S4、根据所述标幺化数据的特征向量,利用集成分类模型,得到故障类别标签,完成电力电子系统故障诊断。
本发明的有益效果为:本发明有效利用特征提取选择器实现了特征向量的降维,使得重采样算法在不同的数据平衡率下取得了较好的效果;集成学习的思想进一步提高了分类器在不平衡数据下的准确率和分类能力;可以准确诊断功率器件和传感器故障的发生,并且实现了故障的实时在线识别,发现电力电子系统中的异常问题,同时提高维修效率。
进一步地,所述步骤S1中标幺化处理的表达式为:
x
其中,x
上述进一步方案的有益效果为:将数据进行标幺化,将不同运行工况和负载条件下的数据进行统一,易于比较电力系统各元件的特性及参数。
进一步地,所述步骤S3中特征提取选择器的构建包括以下步骤:
A1、获取电力电子系统正常数据样本和故障数据样本,对所述正常数据样本和故障数据样本进行预处理和标幺化,得到初始数据集;
A2、根据所述初始数据集,基于快速傅里叶变换算法,得到所述初始数据集的频域特征;
A3、根据所述初始数据集的频域特征,采用特征加权算法ReliefF评估频域特征中各特征属性和故障类别之间的相关性,得到各特征属性的特征权重,所述特征加权算法ReliefF的表达式为:
其中,W(A)为第A个特征的权重,A为特征编号,R为样本数据,H
A4、根据所述各特征属性的特征权重,剔除权重小于零的特征属性,得到第一特征属性集;
A5、根据所述第一特征属性集,选取平均互信息最大的m个特征属性,得到故障类别的特征子集:
其中,D(S,c)为特征子集S与故障类别c的平均互信息,S为特征子集,c为故障类别,I(·)为互信息技术度量结果,z
A6、根据所述特征子集,添加最小冗余条件选择m个互斥的特征属性,得到最大相关度-最小冗余度的特征集合:
mRMR=max(D-R)
其中,mRMR为最大相关度-最小冗余度的特征集合,R为最小冗余条件结果,z
A7、根据所述最大相关度-最小冗余度的特征集合,得到评估结果;
A8、根据所述评估结果,对所述第一特征属性集的特征属性进行排序,选择排序前20的特征属性,得到特征向量;
A9、判断m是否为保证特征向量测试精度大于95%的前提下的最小值,若是,得到特征提取选择器,否则,调整m的值,返回步骤A5。
上述进一步方案的有益效果为:特征提取选择器的引入能够提取更多的特征数据,实现特征向量的降维,并且使得特征选择后的新特征向量不同类别样本的边界更清晰,为数据重采样奠定了良好的基础。
进一步地,所述步骤S4中集成分类模型的构建方法包括以下步骤:
B1、根据所述特征提取选择器,得到所述初始数据集的新特征向量;
B2、根据所述新特征向量,对所述初始数据集进行提取,得到第一数据集;
B3、对所述第一数据集中的故障数据,采用安全级别过采样算法safe-levelSMOTE进行重采样,得到平衡数据集;
B4、根据所述平衡数据集,通过调整RVFL网络模型的参数,训练得到不同的若干个RVFL分类器;所述RVFL网络模型的输出函数的表达式为:
其中,f(X)为RVFL网络模型的输出函数值,X为RVFL网络模型的输入向量,ω
B5、对所述若干个RVFL分类器进行评估,选取评估值达到预设值的RVFL分类器,利用集成学习,得到集成分类器;
B6、根据所述集成分类器,添加集成分类模型输出决策,得到集成分类模型。
上述进一步方案的有益效果为:采用重采样技术解决数据不平衡的问题,并利用多个RVFL分类器对数据进行分类,提高分类的准确度。
进一步地,所述步骤B3包括以下步骤:
B301、根据所述第一数据集,得到故障数据集和正常数据集;
B302、根据所述故障数据集,得到安全水平比:
其中,S
B303、根据所述安全水平比,得到故障数据集的新样本:
x
其中,x
B304、判断所述故障数据集的新样本与正常数据集数量是否相等,若是,将第一数据集中的故障数据集更新为故障数据集的新样本,得到平衡数据集,否则,将故障数据集更新为故障数据集的新样本,并返回步骤将返回步骤B302。
上述进一步方案的有益效果为:平衡了数据集,避免了smote随机区域合成,可能会与正常数据样本重叠的缺点。
进一步地,所述步骤B5中采用度量指标F-score分数和G-means评估RVFL分类器;所述F-score分数的表达式为:
其中,F-score为F-score分数值,表示精确性和召回率之间的综合值,β
G-means的表达式为:
上述进一步方案的有益效果为:采用了两种度量指标进行评估,避免结果产生偏颇,同时度量指标的应用考虑到RVFL分类器的准确率和召回率,能有效避免低质量RVFL分类器的采纳。
进一步地,所述步骤B6中集成分类模型输出决策的表达式为:
Y
Y
其中,Y
上述进一步方案的有益效果为:该决策能够对各种可能故障标签的概率进行计算,方便工作人员进行查看。
附图说明
图1为本发明的方法流程图。
图2为本发明实施例中单相脉冲整流器拓扑图。
图3为本发明实施例中原始特征向量、mRMR算法、ReliefF算法、ReliefF和mRMR组合算法进行特征排序后的特征向量在不同特征维度下的平均测试精度结果示意图。
图4为本发明集成分类模型测试和诊断决策方法框图。
图5为本发明在单相脉冲整流器实验原型系统下做出的实施例在T
图6为本发明在单相脉冲整流器实验原型系统下做出的实施例在T
图7为本发明在单相脉冲整流器实验原型系统下做出的实施例在电流传感器偏移故障前后变换器输出网侧电压电流、直流侧电压波形、集成分类模型输出故障标签的变化结果示意图。
图8为本发明在单相脉冲整流器实验原型系统下做出的实施例在电流传感器增益故障前后变换器输出网侧电压电流、直流侧电压波形、集成分类模型输出故障标签的变化结果示意图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
实施例1
如图1所示,在本发明的一个实施例中,一种结合重采样和集成学习的电力电子系统故障诊断方法,包括以下步骤:
S1、实时采样电力电子系统二分之一基波周期内的电流数据,对所述电流数据进行标幺化处理,得到标幺化数据;
S2、根据所述标幺化数据,基于快速傅里叶变换算法,得到所述标幺化数据的频域特征;
S3、根据所述标幺化数据的频域特征,通过特征提取选择器,得到标幺化数据的特征向量;
S4、根据所述标幺化数据的特征向量,利用集成分类模型,得到故障类别标签,完成电力电子系统故障诊断。
本实施例中,基本思想是利用安全级别过采样算法(safe-level SMOTE))对少数类进行过采样,从数据的角度出发平衡数据集;利用随机功能链路网络(random vectorfunctional link network,RVFL)计算速度快的优点训练数据集,生成RVFL网络模型,基于集成学习的思想改变网络模型的权重和参数,获取多样化的RVFL网络模型,从算法的角度解决不平衡数据中少数类故障样本的识别问题。针对实际中电力电子变流器系统中的时域故障特征容易被噪声淹没、不同故障特征相似的特点,首先通过数据预处理、特征提取和特征选择,对原始数据集进行处理,以获得低维、更相关的特征。根据精心挑选的特征,采用safe-level SMOTE对少数类进行过采样平衡数据集。然后采用RVFL网络模型设计了一种快速的集成学习方法,采用不同的度量指标F-score和G-means评估RVFL分类器,最终集成分类模型输出决策进行概率计算,准确识别故障模式。
所述步骤S1中标幺化处理的表达式为:
x
其中,x
本实施例中,电力电力系统的原始运行数据通常为时域特征信号,具有周期性和时序性,以电流波形的一个基波周期为窗口长度截取特征数据。考虑不同运行工况和负载条件,基于电力电子系统实验平台获取正常运行数据和故障数据样本,通过除以每组样本数据中的最大值对数据样本进行标幺化。
所述步骤S3中特征提取选择器的构建包括以下步骤:
A1、获取电力电子系统正常数据样本和故障数据样本,对所述正常数据样本和故障数据样本进行预处理和标幺化,得到初始数据集;
本实施例中,考虑电力电子系统原始样本较少的特点,制作包括大量正常样本、少量功率器件开路故障样本和少量传感器故障样本的数据集,共获数据样本320组,其中,正常样本、功率器件故障样本和传感器故障样本比例为2:1:1。
A2、根据所述初始数据集,基于快速傅里叶变换算法,得到所述初始数据集的频域特征;
本实施例中,为了提取更多的特征数据,利用快速傅里叶变换提取数据样本中的频谱特征,和原始时域特征构成新的特征向量。
A3、根据所述初始数据集的频域特征,采用特征加权算法ReliefF评估频域特征中各特征属性和故障类别之间的相关性,得到各特征属性的特征权重,所述特征加权算法ReliefF的表达式为:
其中,W(A)为第A个特征的权重,A为特征编号,R为样本数据,H
本实施例中,ReliefF是一种特征加权算法,它根据特征属性和故障类别之间的相关性为特征分配不同的权重,特征权重越大,特征的分类能力越强,否则,分类能力越弱。因此,如果特征权重小于权重阈值,在本工作中设置为零,则该特征被剔除。
A4、根据所述各特征属性的特征权重,剔除权重小于零的特征属性,得到第一特征属性集;
A5、根据所述第一特征属性集,选取平均互信息最大的m个特征属性,得到故障类别的特征子集:
其中,D(S,c)为特征子集S与故障类别c的平均互信息,S为特征子集,c为故障类别,I(·)为互信息技术度量结果,z
A6、根据所述特征子集,添加最小冗余条件选择m个互斥的特征属性,得到最大相关度-最小冗余度的特征集合:
mRMR=max(D-R)
其中,mRMR为最大相关度-最小冗余度的特征集合,R为最小冗余条件结果,z
A7、根据所述最大相关度-最小冗余度的特征集合,得到评估结果;
A8、根据所述评估结果,对所述第一特征属性集的特征属性进行排序,选择排序前20的特征属性,得到特征向量;
A9、判断m是否为保证特征向量测试精度大于95%的前提下的最小值,若是,得到特征提取选择器,否则,调整m的值,返回步骤A5。
本实施例中,为了实现特征向量的降维,结合特征加权算法ReliefF和最大相关最小冗余(max-relevance min-redundance,mRMR)算法,去除特征信号中的冗余、不相关分量。首先采用ReliefF算法评估特征属性和故障类别之间的相关性,然后剔除权重小于零的特征属性,保留特征权重大于零的特征属性。然后采用mRMR算法进一步评估保留的特征属性和故障类别之间的相关性以及特征之间的冗余性,根据评估结果对特征属性重新排序。最终,选择排序前20的特征属性作为新特征向量。通过两种特征选择算法的结合,可以将故障特征向量中的每一个属性按照对于分类标签的权重、相关性和冗余性进行排序。最终选择出质量较高的特征属性构建维数较低的新特征向量,使得特征选择后的新特征向量不同类别样本的边界更清晰,为数据重采样奠定了良好的基础。
本实施例中,为了验证特征选择结果的有效性,将包括原始数据样本,按mRMR算法、ReliefF算法、mRMR和ReliefF组合算法排序后的特征向量进行对比,通过逐步引入不同维数的特征向量来训练和测试常见的分类算法,然后可以计算平均测试精度,判断特征属性质量,最终在保证特征向量质量较高(测试精度大于95%)的前提下选择维度最小的特征向量,完成最关键的特征属性选择。
所述步骤S4中集成分类模型的构建方法包括以下步骤:
B1、根据所述特征提取选择器,得到所述初始数据集的新特征向量;
B2、根据所述新特征向量,对所述初始数据集进行提取,得到第一数据集;
B3、对所述第一数据集中的故障数据,采用安全级别过采样算法safe-levelSMOTE进行重采样,得到平衡数据集,包括以下步骤:
B301、根据所述第一数据集,得到故障数据集和正常数据集;
B302、根据所述故障数据集,得到安全水平比:
其中,S
B303、根据所述安全水平比,得到故障数据集的新样本:
x
其中,x
B304、判断所述故障数据集的新样本与正常数据集数量是否相等,若是,将第一数据集中的故障数据集更新为故障数据集的新样本,得到平衡数据集,否则,将故障数据集更新为故障数据集的新样本,并返回步骤将返回步骤B302。
本实施例中,基于特征提取后的新特征向量,对于功率器件故障和传感器故障少数类样本,采用safe-level SMOTE算法采样,获取新样本,平衡数据集。重采样技术有望用于克服不平衡数据问题的挑战,包括过采样或欠采样方法。通常,过采样方法更适用于数据集较小的电力电子系统,因为欠采样可能会丢失一些重要信息,从而影响测试精度。safe-level SMOTE算法,在生成合成样本之前分配每个实例的安全级别,新的合成实例仅在安全区域中创建,并且更靠近最大安全级别,通过选择少数样本的最近少数邻居,随机生成合成样本。其中安全水平的计算方法如下:
首先定义数据集D是所有待过采样少数类样本数据的集合,p是D中的某一个样本,计算样本p的k个最近邻样本,slp等于其数据集D中的实例数量,任意取一个最近邻样本记为n;计算样本n的k个最近邻样本,slp等于其数据集D中的实例数量。
然后计算S
新样本x
x
其中,β根据不同安全水平比取值。当S
按照以上规则循环直到满足要达到的过采样数量为止,最终使得少数类样本和正常数据样本的数量一致,获得正常样本和故障数据样本平衡的数据集,共计480组样本。
B4、根据所述平衡数据集,通过调整RVFL网络模型的参数,训练得到不同的若干个RVFL分类器;所述RVFL网络模型的输出函数的表达式为:
其中,f(X)为RVFL网络模型的输出函数值,X为RVFL网络模型的输入向量,ω
B5、对所述若干个RVFL分类器进行评估,选取评估值达到预设值的分类器,利用集成学习,得到集成分类器;
B6、根据所述集成分类器,添加集成分类模型输出决策,得到集成分类模型。
本实施例中,基于平衡数据集,利用RVFL网络模型训练得到RVFL分类器,通过调整RVFL网络模型的参数,获取不同的RVFL分类器,采用不同的度量指标F-score和G-means评估RVFL分类器,然后利用集成学习的思想,构建和组合多个表现优异的RVFL分类器,得到集成分类器,来完成学习任务。
定义输入数据X=[x
RVFL网络模型随机产生隐含层神经元的权值和偏重,通过矩阵运算Moore-Penrose伪逆计算求解出输出权值实现训练。在满足训练精度的前提下,通过调整RVFL网络模型的隐藏层节点数目和激活函数类型训练不同RVFL分类器,并采用度量指标F-score和G-means来评估RVFL分类器,最终获取包含多个RVFL分类器的集成分类器。
本实施例中,通常集成分类器的最终决策输出由绝大多数投票法决定,但该方法无法计算出各种可能故障标签的概率。引入“softmax”函数对单个分类器的输出进行转换,得到范围为[0 1]的概率矩阵,函数表示如下:
然后对所有RVFL分类器的输出进行计算,计算同一故障标签对应的概率平均值,输出最大概率数值所对应的故障标签作为最后的结果输出Ro。
所述步骤B5中采用度量指标F-score分数和G-means评估RVFL分类器;所述F-score分数的表达式为:
其中,F-score为F-score分数值,表示精确性和召回率之间的综合值,β
G-means的表达式为:
所述步骤B6中集成分类模型输出决策的表达式为:
Y
Y
其中,Y
本实施例中,定义TP和TN分别表示集成分类器在测试样本集上准确输出的正样本和故障样本数,FP和FN分别表示RVFL分类器在测试样本集上错误输出的正样本和故障样本数,准确率和召回率是分类模型的两个基本指标,分别用P=TP/(TP+FP)和R=TP/(TP+FN),F-score分数是精确性和召回率之间的综合值,表示如下:
其中,β
G-means是P和R的几何平均值,表示如下:
通常采用F-score和G-means两种指标评估不平衡数据分类性能,F-score和G-means数值越高,说明RVFL分类器的性能越好。
实施例2
本发明提供的一种结合重采样和集成学习的电力电子系统故障诊断方法,以单相脉冲整流器功率器件T
本发明所提出一种结合重采样和集成学习的电力电子系统故障诊断方法输入量为:网侧电流is;单相脉冲整流器在线故障诊断算法输出量为:集成分类模型输出故障标签。
首先,采集单相脉冲整流器的原始运行数据,其原始运行数据有网侧电压u
进一步地,利用快速傅里叶变换提取数据样本中的频谱特征,提取更多的频域特征数据,计算快速傅里叶变换后的频域分量幅值作为新特征向量,得到100维的频域特征数据,和原始200维的电流数据样本组合为特征向量,维度为300。
进一步地,为了实现特征向量的降维,去除特征信号中的冗余、不相关分量,组合ReliefF和mRMR算法,进行特征排序并验证。首先采用ReliefF算法通过计算权重来评估特征属性和故障类别之间的关系,然后剔除权重小于零的200维特征属性,保留特征权重较大的100维特征属性。然后采用最大相关最小冗余(max-relevance min-redundance,mRMR)算法进一步评估特征属性和故障类别之间的相关性以及特征之间的冗余性,对特征属性重新排序。
进一步地,为了验证特征选择结果的有效性,将包括原始数据样本,按mRMR算法、ReliefF算法、mRMR和ReliefF组合算法排序后的特征向量进行对比,通过逐步引入不同维数的特征向量来训练和测试常见的分类算法,然后可以计算平均测试精度,结果如图3所示,可以看出,当特征维数大于40时,所有特征向量获取的测试精度都大于95.1%。也就是说,在不考虑任何特征选择的情况下,具有高维度的特征的有效性是可以接受的。然而,通对mRMR和ReliefF组合算法对于最关键的特征选择,RVFL分类器在20维特征的情况下也达到了96.6%的准确率。最终,选择排序前20的特征属性作为新特征向量。
进一步地,基于特征提取和选择后的新特征向量,通过调整对于功率器件故障和传感器故障少数类样本的数量,设置不同不平衡比率4:1:1:1:1,8:1:1:1:1和16:1:1:1:1,分别获取不平衡数据集D1,D2,和D3。采用safe-level SMOTE算法基于数据集D1,D2和D3分别采样,获取新样本,最终使得少数类样本和正常数据样本的数量一致,获得正常样本和故障数据样本平衡的数据集,共计480组样本构建平衡数据集D11,D22和D33。利用常见的分类算法训练不平衡数据集D1,D2,和D3以及平衡数据集D11,D22和D33,获取不同的分类模型,在同一测试集的平均测试精度分别为0.9511,0.8455,0.7909,0.9841,0.9034和0.8659。可以看出,重采样后的数据集获得了更好的分类性能。
进一步地,基于重采样后的平衡数据集,利用RVFL网络训练得到分类器,采用不同的度量指标测试精度,F-score和G-means评估分类器。通过调整RVFL网络模型的参数,基于数据集D11训练和测试,单个RVFL分类器可以实现0.9667的测试精度,F-score和G-means分别为0.9619和0.9768;基于数据集D22,单个RVFL分类器可以实现0.8875的测试精度,F-score和G-means分别为0.8503和0.8988;基于数据集D33,单个RVFL分类器可以实现0.8381的测试精度,F-score和G-means分别为0.7214和0.8096。
进一步地,通过改变RVFL网络模型的激活函数类型和隐藏层节点个数,获取n个不同的RVFL分类器,本发明中n取5,然后利用集成学习的思想,构建和组合多个表现优异的RVFL分类器,得到训练好的集成分类模型,完成学习任务。
进一步地,如图4所示,所有RVFL分类器输出计算,计算同一故障标签对应的概率平均值,输出最大概率数值所对应的故障标签作为最后的结果输出。基于数据集D11训练和测试,集成RVFL分类器可以实现0.9810的测试精度,F-score和G-means分别为0.9751和0.9838;基于数据集D22,单个RVFL分类器可以实现0.9143的测试精度,F-score和G-means分别为0.8988和0.9103;基于数据集D33,单个RVFL分类器可以实现0.8476的测试精度,F-score和G-means分别为0.7522和0.8223。
进一步地,实时采样二分之一基波周期内的电流数据,依次参考离线训练过程进行数据标幺化,采样快速傅里叶变换算法进行频域特征提取、ReliefF和mRMR算法特征选择,构造特征向量后,输入到训练好的集成分类模型进行诊断决策,输出故障类别标签。
基于RT-box控制器和实物硬件测试平台进行上述诊断算法进行在线测试,单相脉冲整流器不同功率器件开路故障和电流传感器增益和偏移故障下的测试结果如图5~8所示(图5为网侧电压u
- 基于数据重采样的Adaboost集成学习电网故障诊断系统及方法
- 信息论与专家系统相结合进行电力系统故障诊断的方法