一种基于多层次跨模态差异调和的多模态行人重识别方法
文献发布时间:2024-01-17 01:28:27
技术领域
本发明涉及计算机视觉领域,尤其涉及可用于智能视频监控、智能安防等的多模态行人重识别方法,该方法属于图像检索、多模态信息融合和深度学习的交叉应用。
背景技术
行人重识别(Person Re-identification),简称ReID,是指利用计算机手段,从大量的跨摄像头视频中快速、准确地检索目标查询人员图像的技术。随着城市的快速发展和交通摄像网络的完善,行人重识别技术在城市管理与公共安防方面有着巨大的应用前景。比如,对于频繁发生的幼童和老人走失事件,利用实时监控视频数据,迅速找到目标当前所在的位置,避免事态进一步恶化;在公共卫生领域,行人重识别技术可以实现人流信息的统计。行人重识别技术根据查询数据的类型可以分为两种:分别是基于图像的查询、基于文本的查询,基于图像查询的行人重识别近些年发展迅速,但在实际应用中无法保证拥有目标清晰有效的查询图像,使得这类方法在实践中存在较大的局限性。基于文本的行人重识别也称多模态行人重识别,是指用文本描述来检索图像或者视频序列中是否存在特定行人,因其支持开放形式的自然语言查询,可以克服基于图像行人重识别系统的局限性,而具有更广泛的应用价值。
多模态行人重新识别的主要挑战是在文本描述和图像外观之间存在着显著模态差异和高度非线性关系的情况下,提取出能够在不同模态之间进行有效匹配的特征。现有的方法通过构建跨模态特征匹配策略来解决这一挑战,相关方法大致可以分成两类。第一类是基于全局特征匹配的方法。该方法使用模态特定的预训练模型或设计先进的模型结构提取样本的全局特征,并设计跨模态损失函数来学习两种模态的共同特征空间。然而,这些方法无法有效地探索行人的细节特征,从而无法构建细粒度的跨模态交互,导致性能不佳。第二类方法基于细粒度局部特征来进行特征匹配和模态对齐。一些方法利用注意机制,构建局部文本描述(短语或单词)和图像块之间的对应关系来实现隐式跨模态对齐,提高行人重识别的精度。另外一些方法利用额外的语义先验信息(例如姿态信息、人体语义分割信息或者行人属性信息)来指导网络提取图像和文本中对应的语义部件的特征,实现显式跨模态对齐。然而,这些方法通常需要针对特定的查询-待查询文本图像对执行成对的跨模态交互操作,具有较高的时间复杂度。现有的方法未充分考虑到文本和图像在行人重识别任务中的多层次和多粒度对齐关系。例如,一个文本短语如"蓝色外套"可能对应同一图像中具有不同外观的图像块,也可能对应同一行人的不同图像,甚至对应不同行人却穿着相似的蓝色外套。因此,在图像和特定文本描述之间形成一对一的强关联时,不可避免地会导致两种模态之间的过度对齐,进而影响行人重识别任务的准确性。
发明内容
本发明克服了之前方法复杂度高,且未充分考虑到文本和图像在行人重识别任务中的多层次和多粒度对齐关系的不足,通过调和从细到粗三个层级,即图像块级别、实例级别和身份级别的跨模态差异,实现准确高效的行人重识别。其中包含了跨模态掩码重建方法,用来调和图像块级别和实例级别的跨模态差异。还包含了交叉身份双模拟方法,通过一个差异预测器,帮助不同身份行人特征间的相关性在不同模态间转换,来缓解身份级别的跨模态差异。
本发明提供的技术方案如下:
一种多模态行人重识别方法,其步骤包括:
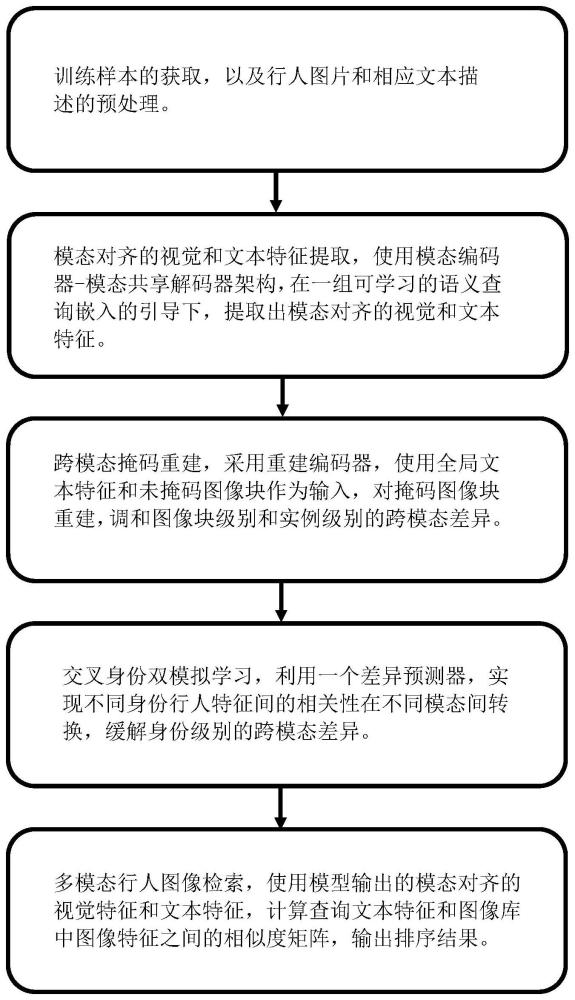
1)获取训练样本集,所述训练样本集包括多个训练样本,其中每一个训练样本均包括:行人图像、与行人图像对应的文字描述;每个行人图像被分割成图像块的个数为N,设定一个丢弃率p
2)使用模态编码器-模态共享解码器,在一组可学习的语义查询嵌入的引导下,提取一组模态对齐的视觉特征和文本特征;
3)采用重建编码器,使用全局文本特征和未掩码图像块作为输入,实现跨模态掩码重建,重建损失包括自实例重建的损失和跨实例重建的损失;
4)针对不同ID的训练样本,利用一个差异预测器,将一个模态的特征差异作为输入去预测另一个模态的特征偏差,计算双模拟损失;且采用交叉熵损失作为行人身份的分类损失,同时,采用排序损失增大相同ID的特征相似度,减小不同ID的特征相似度;
5)模型总体损失函数包含重建损失、双模拟损失、行人身份的分类损失和排序损失,使用输出的模态对齐的视觉特征和文本特征,计算查询文本特征和图像库中图像特征之间的相似度矩阵,实现多模态行人重识别。
进一步,在步骤2)中,使用模态编码器提取图像全局特征、图像局部特征、文本全局特征和文本局部特征,具体步骤为:对于一个包含N个图像块的行人图像,使用一个线性映射层将其转化为一组图像块嵌入,再将一个额外的可学习的嵌入加入到该组图像块嵌的第一个位置来表示全局信息;同时,在这组图像块嵌入中加入可学习的位置编码对空间信息进行编码,将图像块嵌入输入到视觉编码器中,得到图像全局特征和图像局部特征;对于包含M个单词的文本描述,先将其输入到预训练的BERT模型得到离散的词嵌入,再将其输入到双向的LSTM模型,将前向LSTM和后向LSTM相应的隐层特征输出连接得到文本全局特征和文本局部特征。模态共享解码器包含一个自注意力层和交叉注意力层,以及一组可学习的语义查询嵌入,首先,可学习的语义查询嵌入通过自注意力层进行自身交互,然后通过交叉注意力层分别与图像局部特征和文本局部特征交互,生成一组模态对齐的图像局部特征和文本局部特征,最后,将模态对齐的局部特征和对应模态的全局特征连接起来形成最终的视觉特征和文本特征。
进一步,在步骤3)中,在重建之前,在所有被掩码的位置添加一个全局共享的可学习掩码嵌,对于填充后的的视觉特征序列加上位置编码学习空间相关性,利用训练样本的文本全局特征作为重建条件,与填充后的的视觉特征序列一起输入到重建编码器中,实现自实例重建。对于当前训练批次的训练样本A,从数据集中选取同一行人ID的一个训练样本B,基于训练样本A的文本全局特征对训练样本B的被掩码的图像块嵌入
进一步,在步骤4)中,针对不同ID的训练样本A和C,
采用公式(1)计算双模拟损失,其中<·>表示余弦相似度,||·||表示取模;
本发明的有益效果是:
1、本发明基于模态特定编码器-模态共享解码器架构提出了新的多模态行人重识别方法,实现从细到粗三个层级调和,即图像块级别、实例级别和身份级别的跨模态差异,实现准确高效的行人重识别。
2、本发明既调和图像块级别和实例级别的跨模态差异,还包含了交叉身份双模拟方法,通过学习一个差异预测器,帮助不同身份行人特征间的相关性在不同模态间转换,来缓解身份级别的跨模态差异。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。
图1是本发明实施例提供的基于多层次跨模态差异调和的多模态行人重识别方法的实施流程图。
图2是本发明基于多层次跨模态差异调和的多模态行人重识别方法的模型框架图。
具体实施方法
为使本发明的目的、技术方法及优点更加清晰,下面结合附图及具体实例,对本发明做进一步的详细说明。这些实例仅仅是说明性的,而并非对本发明的限制。
本发明实施提供一种基于多层次跨模态差异调和的多模态行人重识别方法。视觉编码器为Transformer网络架构,采用与ViT[1]相同的标准结构。编码层、特征维度、多头注意力的数量分别设置为12、768、8,并采用可学习的位置编码。所述文本编码器采用预训练的BERT[2]模型与一个双向LSTM[3]模型级联构成。所述的模态共享解码器采用标准的Transformer网络架构。编码层、特征维度、多头注意力的数量分别设置为2、768、6,并采用可学习的位置编码。如图1所示,具体步骤包括:
(1)获取训练样本集,所述训练样本集包括多个训练样本,其中每一个训练样本均包括:行人图像、与行人图像对应的文字描述;对于当前训练批次的每一个训练样本A(包含行人图片
(2)模态对齐的视觉和文本特征提取。以训练样本A为例,具体步骤包括:
(2.1)将一个行人图像切分出的N个图像块,使用一个线性映射层将其转化为一组图像块嵌入
(2.2)将图像块嵌入输入到视觉编码器中,得到图像特征序列,表示为
(2.3)将包含M个单词的文本描述输入到预训练的BERT模型中,得到一组离散的词嵌入,再将其输入到双向的LSTM模型。将前向LSTM和后向LSTM相应的隐层特征输出连接起来得到文本全局特征
(2.4)定义一组数量为N
(2.5)可学习的语义查询嵌入通过模态共享解码器的自注意力层D
(2.6)将模态对齐的局部特征和对应模态的全局特征连接起来形成最终的视觉特征
(3)跨模态掩码重建,如图2所示。
(3.1)根据步骤(1),得到没有被掩码的图像块嵌入
(3.2)利用训练样本A的文本全局特征
自实例重建公式为:
自实例重建的损失函数为:
跨实例重建公式为:
跨实例重建的损失函数为:
(4)交叉身份双模拟学习。
(4.1)对(2.6)中的获取的视觉特征和文本特征计算特征差异。对于两个不同ID的样本A和样本C,
(4.2)为了消除身份级别的模态差异,利用一个差异预测器(利用多层感知器实现),将一个模态的特征偏差作为输入去预测另一个模态的特征偏差。预测公式如下:
P
(4.3)采用交叉熵损失作为行人身份的分类损失,计算公式如下,f
同时,采用排序损失增大相同ID的特征相似度,减小不同ID的特征相似度;
其中S指余弦相似度,α指margin值,
(5)模型总体的损失函数包含身份的分类损失、排序损失、重建损失、双模拟损失,计算公式为:
其中λ
使用模型输出的模态对齐的视觉特征和文本特征,计算查询文本特征和图像库中图像特征之间的相似度矩阵,实现多模态行人重识别。
在模型的训练过程中,使用常用的身份损失和排序损失对模型提取出的模态对齐的视觉特征和文本特征进行约束,使用均方误差损失对重建编码器输出的未掩码图像块的预测值和真实值进行约束,同时使用所提出的互模拟损失来对当前批次的样本对之间的视觉特征偏差和文本特征偏差进行约束。
参考文献:
[1]Dosovitskiy A,Beyer L,Kolesnikov A,et al.An Image is Worth 16x16Words:Transformers for Image Recognition at Scale[C]//InternationalConference on Learning Representations.
[2]Devlin J,Chang M W,Lee K,et al.Bert:Pre-training of deepbidirectional transformers for language understanding[J].arXiv preprintarXiv:1810.04805,2018.
[3]Sarafianos N,Xu X,Kakadiaris I A.Adversarial representationlearning for text-to-image matching[C]//Proceedings of the IEEE/CVFinternational conference on computer vision.2019:5814-5824.
- 基于解纠缠和特征级差异学习的跨模态行人重识别方法
- 基于解纠缠和特征级差异学习的跨模态行人重识别方法