基于蒙特卡洛和深度学习的动力电池剩余寿命预测方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及基于蒙特卡洛和深度学习的动力电池剩余寿命预测方法,属于动力电池技术领域。
背景技术
在锂离子电池循环使用的过程中,其剩余寿命会逐渐衰减,动力电池的剩余寿命通常是指在一定条件下,电池容量从当前实际容量衰减到规定的失效阈值(一般为初始容量的80%)所进行的充放电循环次数。当电池剩余寿命耗尽时,若没及时更换,将会严重影响汽车的性能和安全。因此,准确地监测电池剩余寿命预测具有重要意义。
现有技术中,胡天中等人提出一种采用LSTM模型对电池寿命进行预测的方法(参见胡天中,&余建波.(2019).基于多尺度分解和深度学习的锂电池寿命预测.浙江大学学报:工学版,53(10),13.),该方法中,首先采用了集成经验模态分解技术将SOH时间序列分解成主趋势时间序列和波动时间序列,然后对主趋势时间序列利用DBN模型进行预测,而对波动时间序列则采用LSTM模型进行预测,最后将两模型的预测结果进行集成,得到了较高精度的预测结果,然而该方法中由于波动时间序列中的高频数据变化剧烈,LSTM模型难以挖掘其内在的数学规律,从而导致其对高频波动时间序列预测精度较低,因而该方法预测精度有待于进一步提高。
发明内容
为了实现对于动力电池剩余寿命的准确预测,以帮助企业合理决策何时替换动力电池,提高经济效益,本发明提供了一种基于蒙特卡洛和深度学习的动力电池剩余寿命预测方法,所述方法在进行动力电池剩余寿命预测时,首先利用集成经验模态分解技术和相关性分析方法将SOH时间序列分解成主趋势时间序列和波动时间序列,利用深度置信网络对主趋势时间序列进行预测,而对于波动时间序列,首先利用蒙特卡洛技术求得最优区间阈值集合,然后结合最优区间阈值集合对波动时间序列先进行数据预处理,然后采用分段三次埃尔米特插值技术对预处理之后的序列进行重采样,之后利用长短期记忆神经网络对重采样之后序列进行预测,然后再对波动序列预测结果进行反重采样和逆向数据处理得到波动时间序列最终预测值,然后将主趋势时间序列和波动时间序列预测结果进行集成得到最终的SOH预测结果,最后结合电池寿命结束时的SOH值得到剩余寿命的预测值,实现了动力电池剩余寿命的高精度预测。
一种基于蒙特卡洛和深度学习的动力电池剩余寿命预测方法,该方法包括:
步骤S1,获取动力电池健康状态SOH时间序列;
步骤S2,利用集成经验模态分解技术和相关性分析方法将SOH时间序列分解成主趋势时间序列M(t)和波动时间序列W
步骤S3,利用深度置信网络对主趋势时间序列进行预测,得到主趋势时间序列的预测值M
步骤S4,利用蒙特卡洛方法求得最优区间阈值集合;
步骤S5,结合最优区间阈值集合对波动时间序列W
步骤S6,采用分段三次埃尔米特插值技术对预处理后的波动时间序列进行重新采样,并利用长短期记忆神经网络对重采样之后的波动时间序列进行预测,再对波动序列预测结果进行反重采样和逆向数据处理得到波动时间序列最终预测值
步骤S7,将波动时间序列和主趋势时间序列的预测值进行集成,得到SOH时间序列预测值SOH
可选的,所述步骤S2包括:
步骤S2.1利用集成经验模态分解技术,对SOH时间序列进行分解,EEMD分解结果为:
其中,N为分解的IMF分量个数,IMF
步骤S2.2对步骤S2.1得到的各个分量与SOH时间序列进行相关性分析,计算各组分量与SOH时间序列的相关性系数,设置关联阈值,选取出强相关性的J组分量与余量组合成主趋势时间序列M(t),结果为:
剩余K组分量作为波动时间序列W
可选的,所述步骤S3包括:
步骤S3.1:将所述主趋势时间序列M(t)作为初始训练数据,初始化深度置信网络的输入节点数,最大层数,每层的节点数,最大迭代次数,初始训练数据的时间长度len以及所要预测的时间长度;
步骤S3.2:设置起始预测点t=1,
步骤S3.3:设置起始层数i=1;
步骤S3.4:根据初始训练数据,进行受限玻尔兹曼机无监督预训练;
步骤S3.5:判断当前层数i是否小于最大层数,如果是,i=i+1,跳转到步骤S3.4,否则,跳转到步骤S3.6;
步骤S3.6:设置起始迭代次数j=1;
步骤S3.7:使用梯度下降算法进行反向微调;
步骤S3.8:判断j是否小于最大迭代次数,如果是,j=j+1,跳转到步骤S3.7,否则,深度置信网络网络训练结束,跳转到步骤S3.9。
步骤S3.9:利用训练结束的深度置信网络计算len+t时间点的预测值,将该时间点的预测值加入到初始训练数据中,更新训练数据;
步骤S3.10:判断t是否小于所要预测的时间长度,如果是,则t=t+1,跳转到步骤S3.3,否则,跳转到步骤S3.11;
步骤S3.11:输出主趋势时间序列的预测值M
可选的,所述步骤S4中利用蒙特卡洛方法求得最优区间阈值集合,包括:
步骤S4.1:确定各组波动时间序列对应的区间阈值所服从的正态分布的均值u和标准差σ以及区间阈值精度;
步骤S4.2:对每组波动时间序列分别按照均值为u和标准差为σ的正态分布生成随机数;
步骤S4.3:处理异常随机数以及消除区间阈值精度意义下的相同随机数;
步骤S4.4:计算各组波动时间序列不同区间阈值条件下对应的预测值;
步骤S4.5:对各组波动时间序列和所有区间阈值进行排列组合,得到一簇区间阈值集合;
步骤S4.6:计算每一个区间阈值集合对应的预测误差,得到误差最小值对应的区间阈值集合,即为最优区间阈值集合,记为threshold(k)。
可选的,所述步骤S5包括:
步骤S5.1:初始化优区间阈值集合threshold(k),k=1,2,...,K,其中K为波动时间序列的组数;
步骤S5.2:设置起始波动时间序列组数k=1;
步骤S5.3:初始化区间边界参数p=0.1,计算第k组波动时间序列W
步骤S5.4:根据下式计算区间边界boundary:
boundary=p×MAX
步骤S5.5:初始化当前在所划定区间内样本点的比例rate=0以及初始化记录区间边界之外数据的error
步骤S5.6:设置序列起始点j=1;
步骤S5.7:判断第k组波动时间序列第j个数据W
步骤S5.8:判断j是否小于LEN,如果是,j=j+1,跳转到步骤S5.7,否则,跳转到步骤S5.9;
步骤S5.9:判断rate是否小于等于threshold(k),如果是,p=p+0.1,跳转到步骤S5.4,否则,跳转到步骤S5.10;
步骤S5.10:针对error
步骤S5.11:判断k是否小于K,如果是,k=k+1,跳转到步骤S5.3,否则,跳转到步骤S5.12;
步骤S5.12:输出数据预处理之后的波动时间序列W′
可选的,所述步骤S6中采用分段三次埃尔米特插值技术对预处理后的波动时间序列进行重新采样,包括:
步骤S6.1.1:初始化波动时间序列起始组数k=1,采样放大倍数n;
步骤S6.1.2:按照下式设置原采样点向量x和重新采样点向量new_x;
x=[1,2,3,…,len
式中,len
步骤S6.1.3:调用MATLAB软件里的pchip()函数,将W′
W_pchip
步骤S6.1.4:判断k是否小于K,如果是,k=k+1,跳转到步骤S6.1.3,否则,跳转到步骤S6.1.5;
步骤S6.1.5:输出重采样之后的波动时间序列W_pchip
可选的,所述步骤S6中利用长短期记忆神经网络对重采样之后的波动时间序列进行预测,包括:
步骤S6.2.1:按照下式将W_pchip
式中,mu是W_pchip
步骤S6.2.2:初始化输入序列Xtrain=W_pchip′
步骤S6.2.3:按照公式,信号前向传播:
其中,h
步骤S6.2.4:采用梯度下降法进行误差反向传播,调整网络参数;
步骤S6.2.5:使用单步预测算法,生成目标长度的预测值;
步骤S6.2.6:输出波动时间序列预测值W_LSTM
可选的,所述步骤S6中对波动序列预测结果进行反重采样,包括:
步骤S6.3.1:初始化波动时间序列起始组数k=1,采样缩小倍数n;
步骤S6.3.2:按照下式设置原采样点向量x’和反重采样点向量new_x’;
x′=[1,2,3,…,len
new_x′=[1,1+n,1+2×n,1+3×n,…,len
式中,len
步骤S6.3.3:调用MATLAB软件里的pchip()函数,将W_LSTM
W_pchip_reverse
步骤S6.3.4:判断k是否小于K,如果是,k=k+1,跳转到步骤S6.3.3,否则,跳转到步骤S6.3.5;
步骤S6.3.5:输出反重采样之后的波动时间序列预测值W_pchip_reverse
可选的,所述步骤S6中所述对反重采样之后的预测结果进行逆向数据处理得到波动时间序列的最终预测值
步骤S6.4.1:初始化波动时间序列组数k=1;
步骤S6.4.2:初始化
步骤S6.4.3:对error
式中,W
步骤S6.4.4:判断k是否小于K,如果是,k=k+1,跳转到步骤S6.4.2,否则,跳转到步骤S6.4.5;
步骤S6.4.5:输出波动时间序列的最终预测值
可选的,所述步骤S7包括:
步骤S7.1:初始化搜索位置loc=1;
步骤S7.2:判断SOH
步骤S7.3:输出剩余寿命预测值EOL。
本发明有益效果是:
本申请针对动力电池SOH除了逐渐衰退以外,还会存在重生现象的问题,即动力电池SOH时间序列存在主趋势分量和波动分量模态混叠的问题,本发明提出采用集成经验模态分解技术将SOH时间序列分解成多组IMF(Intrinsic Mode Functions,IMF,内涵模态分量)分量和余量,然后将各组IMF分量和SOH时间序列进行相关性分析,将高度相关的IMF分量和余量集成主趋势分量,其余相关性较低的IMF分量作为波动分量,有效解决了SOH时间序列模态混叠的问题;
其次,针对高频波动时间序列预测精度较低,传统神经网络难以挖掘其内在的数学规律的问题,本发明提出,首先对尖端数据预处理,将主要波动范围之外的数据按照比例放缩进范围之内,然后采用分段三次埃尔米特插值对预处理之后的数据进行重采样,从而达到降低波动频率的效果,再将重采样之后的数据作为输入导入长短期记忆神经网络中进行预测,最后将预测结果反重采样和逆向数据处理,得到高频波动时间序列的最终预测结果,从而大幅度提高了高频波动时间序列的预测精度和可靠性。
再次,针对尖端数据预处理时所涉及的区间阈值如何确定的问题,本发明提出蒙特卡洛方法。本发明首先根据经验确定各组波动时间序列对应的区间阈值所服从的正态分布的均值u和标准差σ以及区间阈值精度,然后对每组波动时间序列分别按照均值为u和标准差为σ的正态分布生成随机数,接着处理异常随机数以及消除区间阈值精度意义下的相同随机数,之后计算各组波动时间序列不同区间阈值条件下的预测值并对各组波动时间序列和所有区间阈值进行排列组合,得到一簇区间阈值集合,最后计算每一个区间阈值集合对应的预测误差,得到误差最小值对应的区间阈值集合,即为最优区间阈值集合。有效解决了尖端数据处理时的区间阈值难以确定的问题,本申请通过该方法能够在众多可以选择的参数中选择最优参数以使得对应的预测精度在众多可能中最高,从而进一步提高了动力电池剩余寿命预测的精度,而且不再依赖技术人员的经验,提高了方法的可靠性。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
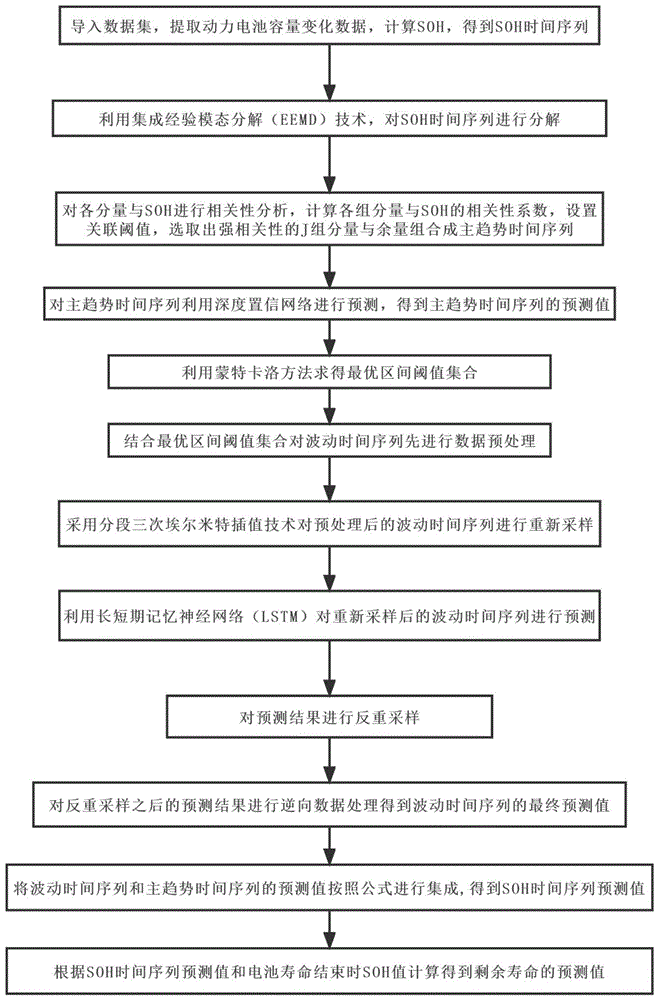
图1是本发明提供的基于蒙特卡洛和深度学习的动力电池剩余寿命预测方法的流程图。
图2是本发明一个实施例中公开的SOH时间序列经过集成经验模态分解技术之后的分解结果仿真图。
图3~图6是本发明一个实施例中公开的采用本申请方法和LSTM方法以及pchipLSTM方法得到的四组波动时间序列的预测结果对比图。
图7是本发明一个实施例中公开的采用本申请方法和LSTM方法以及pchipLSTM方法预测得到的集成波动时间序列的预测结果对比图。
图8是本发明一个实施例中公开的采用本申请方法和LSTM方法以及pchipLSTM方法预测得到的集成波动时间序列的预测误差对比图。
图9是本发明一个实施例中公开的采用本申请方法和MT、LSTM、pchipLSTM方法得到的SOH时间序列预测结果对比图。
图10是本发明一个实施例中公开的采用本申请方法和MT、LSTM、pchipLSTM方法得到的SOH时间序列的预测误差对比图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
实施例一:
本实施例提供一种基于蒙特卡洛和深度学习的动力电池剩余寿命预测方法。参见图1,所述方法包括:
步骤S1,获取动力电池健康状态SOH时间序列;
动力电池健康状态SOH时间序列可以根据动力电池容量变化数据通过计算得到;实际应用中可从公开的数据集中提取出动力电池容量变化数据,也可以自采集动力电池容量变化数据,进而根据下式计算出动力电池健康状态SOH时间序列:
其中,C
步骤S2,利用集成经验模态分解技术和相关性分析方法将SOH时间序列分解成主趋势时间序列M(t)和波动时间序列W
EEMD分解结果为:
其中,N为分解的IMF分量个数,IMF
设置关联阈值,选取出强相关性的J组分量与余量组合成主趋势时间序列M(t),结果为:
剩余K组分量作为波动时间序列W
步骤S3,利用深度置信网络对主趋势时间序列进行预测,得到主趋势时间序列的预测值M
步骤S4,利用蒙特卡洛方法求得最优区间阈值集合;
步骤S4.1:确定各组波动时间序列对应的区间阈值所服从的正态分布的均值u和标准差σ以及区间阈值精度;
步骤S4.2:对每组波动时间序列分别按照均值为u和标准差为σ的正态分布生成随机数;
步骤S4.3:处理异常随机数以及消除区间阈值精度意义下的相同随机数;
步骤S4.4:计算各组波动时间序列不同区间阈值条件下对应的预测值;
步骤S4.5:对各组波动时间序列和所有区间阈值进行排列组合,得到一簇区间阈值集合;
步骤S4.6:计算每一个区间阈值集合对应的预测误差,得到误差最小值对应的区间阈值集合,即为最优区间阈值集合,记为threshold(k)。步骤S5,结合最优区间阈值集合对波动时间序列W
步骤S6,采用分段三次埃尔米特插值技术对预处理后的波动时间序列进行重新采样,并利用长短期记忆神经网络对重采样之后的波动时间序列进行预测,再对波动序列预测结果进行反重采样和逆向数据处理得到波动时间序列最终预测值
步骤S7,将波动时间序列和主趋势时间序列的预测值按照下式进行集成,得到SOH时间序列预测值SOH
进而根据SOH
实施例二
本实施例提供一种基于蒙特卡洛和深度学习的动力电池剩余寿命预测方法,所述方法包括:
步骤一:获取动力电池健康状态SOH时间序列;
本实施例通过导入公开数据集,提取动力电池容量变化数据,进而通过下式计算SOH,得到SOH时间序列:
其中,C
本实施例采用的数据集是NASA PCoE研究中心在爱达荷州国家实验室(IdahoNational Lab)测试的NASA锂电池数据,本数据集是采用额定容量为2A·h的18650市售锂电池分为多组开展实验,在室温下通过3种不同的工作曲线(充电、放电和阻抗)进行试验.表1给出各项实验参数,即环境温度(AT)、充电电流(CC)、放电电流(DC)、放电结束电压(EOC)和寿命结束标准(EOLC)。
表1:NASA锂电池实验数据
本实验例选取了该数据集中#6电池的数据,其中#6电池数据有cycle一个字段,cycle字段中包括type,ambient_temperature,time,data四个字段,其中,type字段表示该次测量数据的类型,包括充电,放电,阻抗三种类型;ambient_temperature为本次测量时的温度,time为时间,data字段为测量数据,充电类型包括Voltage_measured,Current_measured,Temperature_measured,Current_charge,Voltage_charge,Time等字段;放电类型包括Voltage_measured,Current_measured,Temperature_measured,Current_load,Voltage_load,Time,Capacity等字段;阻抗类型包括Sense_current,Battery_current,Current_ratio,Battery_impedance,Rectified_Impedance,Re,Rct等字段。
提取出#6电池放电类型中Capacity数据作为本实验例中动力电池容量时间序列,按照下式,计算得到SOH时间序列:
其中,C
步骤二:利用集成经验模态分解(EEMD)技术,对SOH时间序列进行分解,EEMD分解结果为:
其中,N为分解的IMF分量个数,IMF
记步骤一计算得到的SOH时间序列为x(t);
步骤2.1,设定总体平均次数M=100;
步骤2.2,将一个具有标准正态分布的白噪声n
x
式中,n
步骤2.3,对所得含噪声的信号x
式中,C
其中,经验模态分解按照以下步骤进行;
第一步,找出原始信号中全部的局部极大值和极小值点,然后通过曲线拟合的方法结合各个极值点构造出上包络线和下包络线,这样原始信号就被上下包络线所包络。
第二步,由上下包络线可构造出它们的均值曲线m(t),再用原始信号f(t)减去均值曲线,这样得到的H(t)就是IMF。
第三步,由于第一、二步得到的IMF通常不会满足IMF的两个条件,所以要不断重复第一二步,直到SD(筛分门限值,一般取值0.2~0.3)小于门限值时才停止,这样得到的第一个满足条件的H(t)就是第一个IMF。
SD的求法:
第四步,残差r(t)=f(t)-H(t),重复第一、二、三步,直到r(t)满足预先设定的条件。
接着,重复步骤2.2和步骤2.3M次,每次分解加入幅值不同的白噪声信号得到IMF的集合为:
C
最后,利用不相关序列的统计平均值为零的原理,将上述对应的IMF分量进行集合平均运算,得到EEMD分解后最终的IMF分量,即:
式中,C
最终将SOH时间序列分解成为6组IMF分量和一组余量。
步骤三:对各IMF分量与SOH进行相关性分析,计算各组分量与SOH的相关性系数,设置关联阈值,选取出强相关性的J组分量与余量组合成主趋势时间序列M(t),结果为:
剩余K组分量作为波动时间序列W
首先,将SOH时间序列与所有的IMF分量分别按照下式进行归一化处理;
式中,SOH_normalization(t)为SOH时间序列归一化之后的时间序列,IMF_normalization
然后,根据下式求各个IMF分量与SOH时间序列的Pearson相关系数:
式中,r
表2:相关性系数结果
接着,根据所求的相关系数,按照下式,确定关联阈值:
式中,CT为关联阈值,r_ave为N个相关系数的平均值;
所求CT值为0.3786;
最后,按照以下规则,给各组IMF分量打上0,1标签flag:
将标签flag为1的J组IMF分量和余量R(t)按照公式,集成主趋势时间序列M(t),将flag为0的IMF分量作为波动时间序列W
其中,第1~4组IMF分量flag标签为0,第5~6组IMF分量flag标签为1,即第1~4组IMF分量作为波动时间序列,第5~6组IMF分量和余量集成作为主趋势时间序列。
步骤四:对主趋势时间序列利用深度置信网络进行预测,得到主趋势时间序列的预测值M
Step1,初始化输入节点数,最大层数,每层的节点数,最大迭代次数,初始训练数据的时间长度len以及所要预测的时间长度;
表3:相关参数
Step2:设置起始预测点t=1;
Step3:设置起始层数i=1;
Step4:根据训练数据,进行受限玻尔兹曼机(RBM)无监督预训练;
Step5:判断i是否小于最大层数,如果是,i=i+1,跳转到Step4,否则,跳转到Step6;
Step6:设置起始迭代次数j=1;
Step7:使用梯度下降算法进行反向微调;
Step8:判断j是否小于最大迭代次数,如果是,j=j+1,跳转到Step7,否则,DBN网络训练结束,跳转到Step9。
Step9:利用训练结束的DBN网络计算len+t时间点的预测值,将该时间点的预测值加入到训练数据中,更新训练数据;
Step10:判断t是否小于所要预测的时间长度,如果是,则t=t+1,跳转到Step3,否则,跳转到Step11;
Step11:输出主趋势时间序列的预测值M
步骤五:利用蒙特卡洛方法求得最优区间阈值集合;
步骤5.1:根据经验确定各组波动时间序列对应的区间阈值所服从的正态分布的均值u和标准差σ以及区间阈值精度;
表4:各细区间阈值
区间阈值精度为0.01;
步骤5.2:对每组波动时间序列分别按照均值为u和标准差为σ的正态分布生成随机数;
步骤5.3:处理异常随机数以及消除区间阈值精度意义下的相同随机数;
因为区间阈值有个合理的范围,所以应该将范围之外的正态分布随机数调整到范围之内,即将大于等于1的随机数调整为0.99,小于等于0的随机数为0.01;
精度意义下的相同:两个区间阈值差值小于等于精度0.01即视为精度意义下的相同。
因为精度意义下的相同区间阈值对于波动数据的预测效果是基本没有影响的,所以为提高算法速度,可以将精度意义下的相同区间阈值消除。
步骤5.4:计算各组波动时间序列不同区间阈值条件下该组波动数据该阈值对应的预测值;对于每一组波动数据的每一个区间阈值随机数都按照
“结合区间阈值对波动数据预处理”→“重采样”→“LSTM预测”→“反重采样”→“逆向数据处理”的步骤得到其对应的预测值。
步骤5.5:对各组波动时间序列和所有区间阈值进行排列组合,得到一簇区间阈值集合;
表5:一簇区间阈值
通过四组波动时间序列的区间阈值的排列组合,一共会得到39×38×36×18=960,336个区间阈值集合。
步骤5.6:计算每一个区间阈值集合对应的预测误差,得到误差最小值对应的区间阈值集合,即为最优区间阈值集合。
通过计算并比较这960,336个区间阈值集合所对应的预测误差,得到均方根误差(RMSE)最小值为0.0034,其所对应的区间阈值集合见表6:
表6:区间阈值集合
即为最优区间阈值集合。
通常现有技术中确定区间阈值是由技术人员根据经验确定,但根据经验确定区间阈值缺乏足够的科学性和依据,而且无法保证根据经验确定的区间阈值为最优区间阈值,如果采用的区间阈值不是最优,则会较大程度影响最终的预测精度,因此,本申请通过蒙特卡洛技术确定最优区间阈值参数,以便后续对波动时间序列进行数据预处理时根据最优区间阈值进行,从而进一步提高动力电池剩余寿命预测的精度。
步骤六:结合最优区间阈值集合对波动时间序列先进行数据预处理;
对波动时间序列的数据预处理按照如下步骤进行:
Step1:初始化各组波动时间序列对应的区间阈值threshold(k)为权利要求6所得到的最优区间阈值集合,k=1,2,...,K,其中K为波动时间序列的组数
各组最优区间阈值见表7:
表7:最优区间阈值
Step2:设置起始波动时间序列组数k=1;
Step3:初始化区间边界参数p=0.1,计算第k组波动时间序列W
Step4:根据公式,计算区间边界boundary:
boundary=p×MAX
Step5:初始化当前在所划定区间内样本点的比例rate=0以及初始化记录区间边界之外数据的error
Step6:设置序列起始点j=1;
Step7:判断第k组波动时间序列第j个数据W
Step8:判断j是否小于LEN,如果是,j=j+1,跳转到Step7:,否则,跳转到Step9:;
Step9:判断rate是否小于等于threshold(k),如果是,p=p+0.1,跳转到Step4,否则,跳转到Step10;
Step10:针对error
Step11:判断k是否小于K,如果是,k=k+1,跳转到Step3,否则,跳转到Step12。
Step12:输出数据预处理之后的波动时间序列W′
步骤七:采用分段三次埃尔米特插值技术对预处理后的波动时间序列进行重新采样;
Step1:初始化波动时间序列起始组数k=1,采样放大倍数n;
Step2:按照下式设置原采样点向量x和重新采样点向量new_x;
x=[1,2,3,…,len
式中,len
Step3:调用MATLAB软件里的pchip()函数,将W′
W_pchip
Step4:判断k是否小于K,如果是,k=k+1,跳转到Step3,否则,跳转到Step5;
Step5:输出重采样之后的波动时间序列W_pchip
步骤八:利用长短期记忆神经网络(LSTM)对重新采样后的波动时间序列进行预测;
首先,按照公式,将W_pchip
式中,mu是W_pchip
然后,初始化输入序列Xtrain=W_pchip′
其次,按照公式,信号前向传播:
其中,h
接着,采用梯度下降法进行误差反向传播,调整网络参数;
之后,使用单步预测算法,生成目标长度的预测值;
最后,输出波动时间序列预测值W_LSTM
步骤九:对预测结果进行反重采样;
Step1:初始化波动时间序列起始组数k=1,采样缩小倍数n;
Step2:按照下式设置原采样点向量x’和反重采样点向量new_x’;
x′=[1,2,3,…,len
new_x′=[1,1+n,1+2×n,1+3×n,…,len
式中,len
Step3:调用MATLAB软件里的pchip()函数,将W_LSTM
W_pchip_reverse
Step4:判断k是否小于K,如果是,k=k+1,跳转到Step3,否则,跳转到Step5;
Step5:输出反重采样之后的波动时间序列预测值W_pchip_reverse
步骤十:对反重采样之后的预测结果进行逆向数据处理得到波动时间序列的最终预测值
Step1:初始化波动时间序列组数k=1;
Step2:初始化
Step3:对error
式中,W
Step4:判断k是否小于K,如果是,k=k+1,跳转到Step2,否则,跳转到Step5;
Step5:输出波动时间序列的最终预测值
步骤十一:将波动时间序列和主趋势时间序列的预测值按照公式进行集成,得到SOH时间序列预测值SOH
步骤十二:根据SOH时间序列预测值SOH
Step1:初始化搜索位置loc=1;
Step2:判断SOH
Step3:输出剩余寿命预测值EOL。
为评估本申请方法(后续简称为MC-pchip-LSTM方法)的预测性能,本实施例中通过仿真实验将本申请方法与LSTM方法、MT方法以及pchip-LSTM方法的评估结果做对比,对比结果如下所示;
其中,LSTM方法为直接使用长短时记忆网络方法预测波动时间序列从而得到SOH时间序列的预测值,可参考:“[1]胡天中,余建波.基于多尺度分解和深度学习的锂电池寿命预测[J].浙江大学学报(工学版),2019,53(10):1852-1864.”中的介绍。
MT方法为忽略波动时间序列对SOH时间序列的影响,即直接将主趋势预测值作为SOH预测值。
pchip-LSTM方法为根据经验确定区间阈值并按照本申请中“结合区间阈值对波动数据预处理”→“重采样”→“LSTM预测”→“反重采样”→“逆向数据处理”的步骤得到不同区间阈值对应的预测值,从而得到SOH时间序列预测值的方法。
不同预测方法下的电池SOH预测误差对比如下表8所示,不同预测方法下的电池SOH预测得到的电池剩余寿命如表9所示。
表8:不同预测方法下的电池SOH预测误差对比
表9:不同预测方法下的电池剩余寿命预测结果对比
为验证本申请所提出的一种动力电池剩余寿命预测方法的精确性和有效性,采用本申请方法和MT、LSTM,pchip-LSTM方法进行如下仿真实验,实验过程中,采用NASA PCoE研究中心在爱达荷州国家实验室(Idaho National Lab)测试的NASA锂电池数据集中的#6电池数据进行工程验证,其中选取前60%作为训练集样本,后40%作为测试集样本。
对于在实际生产工艺情况,图2展示了SOH时间序列经EEMD分解之后各IMF分量和余量的曲线图;图3~图6展示了四组波动时间序列使用LSTM、pchip-LSTM方法和本发明提出的MC-pchip-LSTM方法的预测结果对比;图7和图8分别是波动时间序列分别使用LSTM方法、pchip-LSTM方法和MC-pchip-LSTM方法得到的集成预测结果对比图和误差对比图;图9和图10展示了SOH时间序列使用MT方法、LSTM方法、pchip-LSTM方法以及本发明提出的MC-pchip-LSTM方法得到的预测结果对比图和误差对比图。
由图2可以看出,SOH时间序列经过EEMD分解之后总共分解成为6组IMF分量和1组余量,而且1~4组分量大致呈现波动的趋势,而5~6组波动性较弱,余量呈现出下降的趋势。这一点从相关性分析之后,将1~4组作为波动数据,5~6组IMF分量和余量作为主趋势数据的结果中也能相互印证。
在图3~图6中,星线表示SOH真实值,圈线表示LSTM方法预测结果,三角线表示MC-pchip-LSTM方法预测结果,虚线表示pchip-LSTM方法预测结果。可以看出pchip-LSTM方法对于4组波动时间序列的预测结果以及对真实值的逼近程度都远远优于LSTM方法。特别需要注意的是第1组波动时间序列,它是一组超高频波动时间序列,而LSTM方法的预测结果基本是一条值为0的水平线,即基本无法预测超高频序列,但是pchip-LSTM方法却能很好得到超高频序列的预测值,而本发明提出的MC-pchip-LSTM方法的预测效果比pchipLSTM方法更好,体现出了本方法的优越性和对高频序列预测的精确性。
在图7中,可以大致看出来对于4组波动时间序列预测结果的集成来说,MC-pchip-LSTM方法和pchip-LSTM方法的预测精度要优于LSTM方法,而从图8中,更能直观的看出来MC-pchip-LSTM方法比pchip-LSTM方法和LSTM方法的精度都要高。在图8中,pchip-LSTM方法和MC-pchip-LSTM方法的预测误差基本都在-0.005~0.005之间,而MC-pchip-LSTM方法得到的预测结果相比pchip-LSTM方法预测值误差在-0.005~0.005范围之外的占比更少,而LSTM方法的预测结果甚至有不少一部分在[-0.01,0.01]区间之外,从这一点也可以体现出MC-pchip-LSTM方法的优越性。
在图9中,可以看出MT方法,LSTM方法,pchip-LSTM方法,MC-pchip-LSTM方法都能预测出SOH时间序列的大致走向,而在图10中可以看出,MT方法和LSTM方法得到的最终SOH时间序列的预测值误差都存在较大偏差的时刻,而且整体误差都要远远大于pchip-LSTM方法和本发明提出的MC-pchip-LSTM方法,而pchip-LSTM方法和MC-pchip-LSTM方法对比来看,MC-pchipLSTM方法的整体预测误差更小。
在针对三种误差指标的对比中,pchip-LSTM方法的动力电池SOH预测精度与LSTM方法相比分别提高了52.6%,62.8%,58.6%,与MT方法相比分别提高了29.5%,36.0%,31.3%,而本发明提出的MC-pchip-LSTM方法得到的动力电池SOH预测精度相比pchip-LSTM方法又分别提高了16.4%,12.5%,17.4%。可见在动力电池SOH预测过程中,利用本文所提出的MC-pchip-LSTM方法可以大幅度提高预测精度。说明本发明提出的动力电池SOH预测方法具有预测精度高、可靠性强等特点。
对于本实验例动力电池剩余寿命预测结果,MT方法,LSTM方法,pchip-LSTM方法和MC-pchip-LSTM方法得到的剩余寿命预测误差分别为2个充放电周期,3个充放电周期,1个充放电周期,0个充放电周期。从结果来看,MT方法,LSTM方法,pchip-LSTM方法都会有一定的预测误差,而本发明提出的MC-pchip-LSTM方法却能非常精准的预测动力电池剩余寿命,再次体现出本发明提出的MC-pchip-LSTM方法的预测精度高、可靠性强等优势。
本发明实施例中的部分步骤,可以利用软件实现,相应的软件程序可以存储在可读取的存储介质中,如光盘或硬盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 机械装备剩余使用寿命快速有效预测的深度学习方法
- 基于蒙特卡洛和深度学习的动力电池剩余寿命预测方法
- 基于深度学习的盾构机刀具剩余使用寿命预测方法