一种基于流重构和帧预测结合的视频异常检测方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及视频异常检测技术领域,尤其涉及一种基于流重构和帧预测结合的视频异常检测方法。
背景技术
随着视频的不断普及,自动识别视频中的异常事件变得越来越有重要,智能的视频异常检测可以在一定程度上节省人力资源,提高效率,视频异常检测是一种计算机视觉技术,旨在从视频流中自动识别和检测出异常行为或事件,在视频异常检测任务中,系统会分析输入视频数据,并尝试找出与正常行为或场景不一致的部分,这些部分通常被称为异常,这些异常可能是不寻常的行为、突发事件、异常对象或不正常的活动。
视频异常检测在许多实际场景中具有广泛的应用,如监控系统、安防、交通管理、智能制造等领域,通过自动检测和警示异常事件,视频异常检测技术可以帮助提高监控效率、减少人力资源的浪费,并增强对潜在风险的预警能力。
视频异常检测的实现涉及多种技术,包括特征提取、异常定义和标注、异常检测算法等,特征提取用于将视频数据转换为可用于分析的有意义的特征表示,异常定义和标注是确定何为异常行为,并准备用于模型训练的标记数据,异常检测算法根据提取的特征和标记数据来识别视频中的异常行为。
目前,视频异常检测是一个具有挑战性的任务,因为异常事件通常是低频事件,并且正常行为的模式可能在不同场景中变化,导致异常行为不易被发现,不能以较小的预测误差成功预测未来框架,因此需要综合考虑不同的技术手段,包括传统的统计方法和现代的深度学习技术,以获得准确性和鲁棒性较高的异常检测结果,因此,本发明提出一种基于流重构和帧预测结合的视频异常检测方法以解决现有技术中存在的问题。
发明内容
针对上述问题,本发明的目的在于提出一种基于流重构和帧预测结合的视频异常检测方法,解决现有的视频异常检测技术中,由于异常事件通常是低频事件,并且正常行为的模式可能在不同场景中变化,导致异常行为不易被发现,不能以较小的预测误差成功预测未来框架的问题。
为了实现本发明的目的,本发明通过以下技术方案实现:一种基于流重构和帧预测结合的视频异常检测方法,包括以下步骤:
步骤一:先在UCSD Ped2、CUHK Avenue和ShanghaiTech三个国际公认的公共视频异常检测数据集上获取训练样本,再将训练样本中的视频数据处理成相应的帧数据;
步骤二:先提取训练和测试视频帧的光流及其所有前景对象,其中每个前景对象由RoI边界框标识,对于每个RoI边界框标识,构建一个时空立方体;
步骤三:使用基于TransUNet的多级记忆网络作为光流重构网络对步骤二中提取出的光流进行重构训练,输入时空立方体,输出重构后的光流图像,并计算重构误差及重构损失;
步骤四:采用条件变分自动编码器CVAE作为预测网络模型,并以原始视频帧数据以及重构后的光流图像输入预测网络模型进行训练,输出预测后的帧数据,并计算预测误差以及预测损失;
步骤五:使用训练好的模型进行测试,输入待检测图像,将流重构误差和帧预测误差进行加权得到异常分数,若异常分数超过预设阈值则判定当前帧图像被检测为异常帧。
进一步改进在于:所述步骤二中,构建的时空立方体包含当前帧中的对象和包含前t帧的同一边界框中的内容,其中t=4,时空立方体的宽度和高度都被调整为32。
进一步改进在于:所述步骤三中,所述基于TransUNet的多级记忆网络为基于Transformer和U-Net的网络结构,用于图像分割任务,所述光流重构网络由编码器、记忆模块、解码器、内存模块和记忆模块构成。
进一步改进在于:所述编码器部分首先将输入图片经过resnet50进行特征提取,其中的三个接口层的输出将保留并用于后续跳跃连接,接着将resnet50输出的特征图进行序列化,送入transformer网络模型中进行序列预测,输出一个序列,然后将该输出序列合并、重塑成一个新的特征图;
所述解码器的每个级别首先从编码器复制特征映射,然后将解码器的每个级别与较低级别的上采样特征映射连接起来,然后依次串联三层,每一层包含两个卷积块、一个存储模块和一个上采样层,卷积块包含卷积层、批处理规范化层和ReLU激活层;
所述内存模块为一个矩阵M∈R
进一步改进在于:所述步骤三中,所述重构训练过程中的损失函数为:
其中M为内存模块个数,
进一步改进在于:所述步骤四中,所述预测网络模型由两个编码器E
进一步改进在于:所述预测网络模型训练过程中,从后验分布中采样z,并将z与条件E
进一步改进在于:所述步骤五中,异常分数的计算公式为:
其中,S为异常分数,μ
本发明的有益效果为:本发明基于流重构和帧预测结合的视频异常检测方法,分别使用基于TransUNet改进的多级记忆网络和条件变分自编码器训练,首先,捕获了视频帧和光流之间的高度相关性,其次,重构的正常流通常具有较高的质量,预测模块能够以较小的预测误差成功预测未来框架,最后,重构误差扩大了预测误差,使异常更容易被发现,从而能获得准确性和鲁棒性较高的异常检测结果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
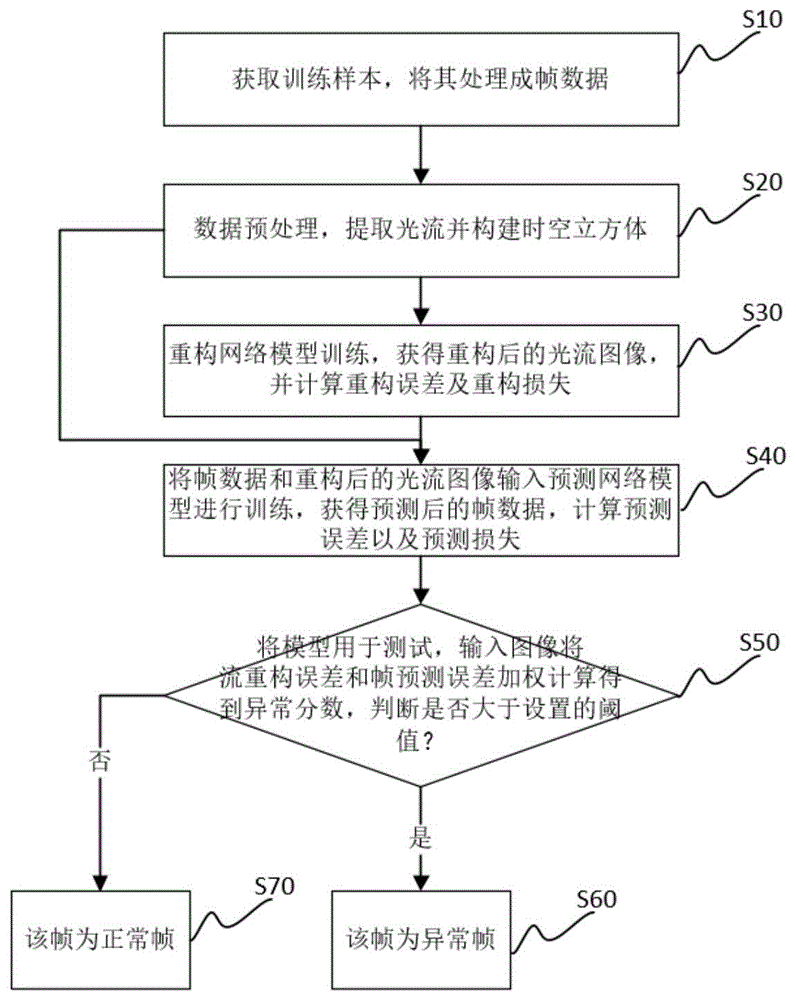
图1是本发明的视频异常检测方法流程示意图;
图2是本发明的视频异常检测的整体网络模型结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参见图1、图2,本实施例提供了一种基于流重构和帧预测结合的视频异常检测方法,包括以下步骤:
S10:先在UCSD Ped2、CUHK Avenue和ShanghaiTech三个国际公认的公共视频异常检测数据集上获取训练样本,再使用ffmpeg工具将训练样本中的视频数据处理成相应的帧数据;
S20:先提取训练和测试视频帧的光流及其所有前景对象,其中每个前景对象由RoI边界框标识,对于每个RoI边界框标识,构建一个时空立方体(STC),构建的时空立方体(STC)包含当前帧中的对象和包含前t帧的同一边界框中的内容,其中t=4,时空立方体的宽度和高度都被调整为32;
S30:使用基于TransUNet的多级记忆网络作为光流重构网络对步骤二中提取出的光流进行重构训练,输入时空立方体,输出重构后的光流图像,并计算重构误差及重构损失,重构训练过程中的损失函数为:
其中M为内存模块个数,
如图2所示,本实施例的整体网络模型结构由两个分支构成,分别为光流重构分支和帧预测分支,本实施例中基于TransUNet的多级记忆网络为基于Transformer和U-Net的网络结构,用于图像分割任务,光流重构网络由编码器、记忆模块、解码器、内存模块和记忆模块构成,编码器部分首先将输入图片经过resnet50进行特征提取,其中的三个接口层(stage)的输出将保留并用于后续跳跃连接(skip-connection),接着将resnet50输出的特征图进行序列化,送入transformer网络模型中进行序列预测,输出一个序列,然后将该输出序列合并、重塑(reshape)成一个新的特征图;
解码器的每个级别首先从编码器复制特征映射,然后将解码器的每个级别与较低级别的上采样特征映射连接起来,然后依次串联三层,每一层包含两个卷积块、一个存储模块和一个上采样层,卷积块包含卷积层、批处理规范化层和ReLU激活层;
内存模块为一个矩阵M∈R
S40:采用条件变分自动编码器CVAE作为预测网络模型,并以原始视频帧数据以及重构后的光流图像输入预测网络模型进行训练,输出预测后的帧数据,并计算预测误差以及预测损失,预测网络模型由两个编码器E
S50:使用训练好的模型进行测试,输入待检测图像,将流重构误差和帧预测误差进行加权得到异常分数,异常分数的计算公式为:
其中,S为异常分数,μ
S60:该帧图像为异常帧;
S70:该帧图像为正常帧。
本发明使用流重构和帧预测误差作为最终的异常检测计算因素,首先,多层存储器模块采用跳跃连接编码器解码器结构,保证了正常模式被很好地记忆,从而敏感地识别异常事件或活动;其次,使用流重构和帧预测相结合的方法,从之前的视频帧和相应的光流中预测未来的帧,但是光流事先被重建,重构误差扩大了预测误差,使异常更容易被发现。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于视频帧预测的开集视频异常检测方法
- 基于记忆增强未来视频帧预测的监控视频异常检测方法