一种结合离线采样学习与在线优化的无人车路径规划方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及无人车路径规划领域,具体为一种结合离线采样学习与在线优化的无人车路径规划方法。
背景技术
传统的机器人路径规划算法研究中,最常用的方法包括基于采样的方法和基于图搜索的方法,这些方法能够保证路径规划的最优性和可解释性。然而这类方法计算开销较大,为保证计算效率则不得不牺牲性能,难以适用于高速、高度动态的场景。为此,本文采取的思路是将这类方法从在线计算转变为离线计算,用于生成专家数据供机器学习模型进行学习。这种思路既有效利用了采样搜索方法的最优性和可解释性,又避免了计算开销大而难以满足在线运行需求的问题。
在动态场景中进行路径规划是一个具有挑战性的问题。传统的路径规划方法通常基于静态地图或固定环境,在面对动态变化的障碍物、交通状况和其他实时信息时,往往无法提供准确和实时的路径规划解决方案。因此,需要一种能够在动态场景下实现高效路径规划的技术。为了解决这一问题,本发明提出了一种基于混合A*算法的路径规划方法,并结合离线路径规划、模型训练、自回归路径规划、集束搜索和路径评估与优化等方案进行综合处理。
发明内容
本发明的目的在于提供一种结合离线采样学习与在线优化的无人车路径规划方法,以解决上述背景技术中提出的问题。
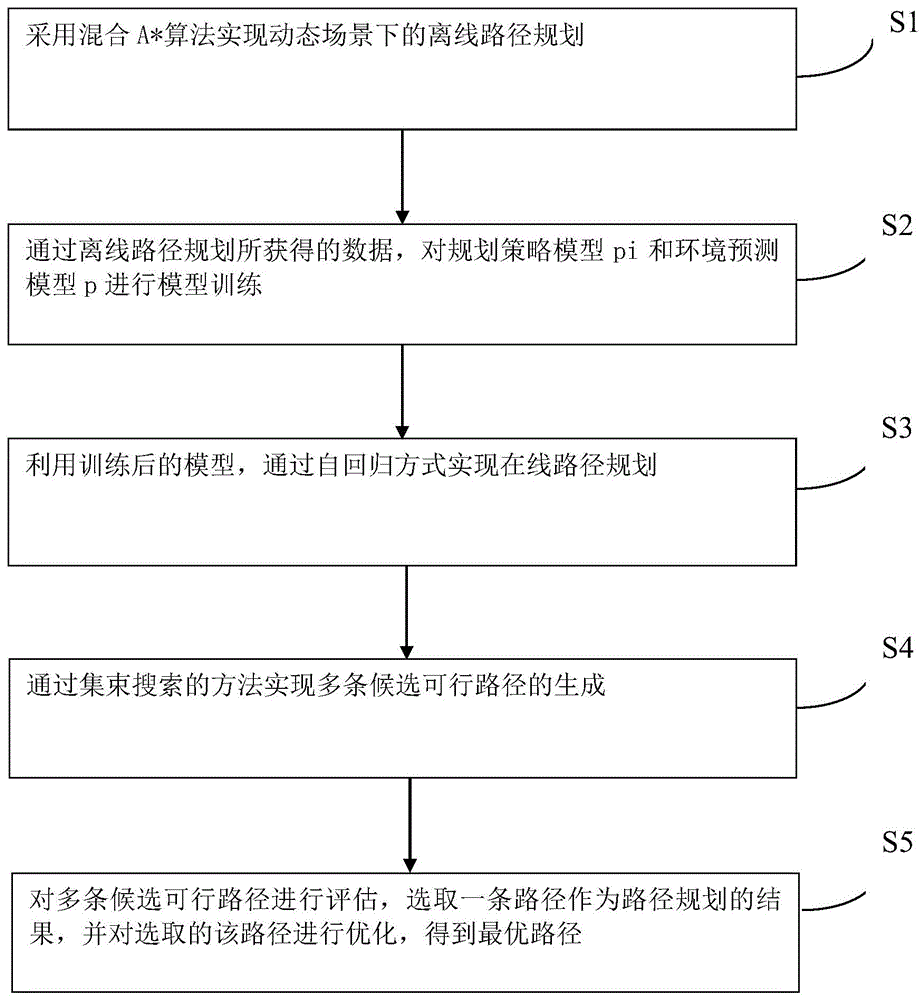
为了解决上述技术问题,本发明提供如下技术方案:一种结合离线采样学习与在线优化的无人车路径规划方法,所述方法包括:步骤S1:采用混合A*算法实现动态场景下的离线路径规划;步骤S2:通过离线路径规划所获得的数据,对规划策略模型pi和环境预测模型p进行模型训练;步骤S3:利用训练后的模型,通过自回归方式实现在线路径规划;步骤S4:通过集束搜索的方法实现多条候选可行路径的生成;步骤S5:对多条候选可行路径进行评估,选取一条路径作为路径规划的结果,并对选取的该路径进行优化,得到最优路径。
进一步的,混合A*算法的工作过程包括如下步骤:
S1-1:混合A*算法在车辆的运动空间上进行采样,选取不同的速度v以及方向盘转角phi,以固定时间间隔Δt生成平滑、符合车辆运动学的行驶路径;
S1-2:混合A*算法中引入了Reeds-Shepp曲线来衔接当前位姿和终点位姿,Reeds-Shepp曲线由三部分组成,包括一段向左的圆弧、一段线段和一段向右的圆弧;
S1-3:由于Reeds-Shepp曲线生成较快,在车辆接近终点时,若生成的Reeds-Shepp曲线符合碰撞条件,各时刻车身均完全落在可行驶区域内,则混合A*算法对可行路径的搜索完成;若生成的Reeds-Shepp曲线不符合碰撞条件,即车辆与障碍物相交或碰撞,混合A*算法继续搜索可行路径,直到找到满足碰撞条件的路径为止;所述碰撞条件指车辆在沿着生成的路径行驶时,不与任何障碍物相交或碰撞。
进一步的,混合A*算法对已发代价函数g(x)和启发代价函数h(x)进行设定;已发代价函数g(x)包含两个参数,第一个参数是起点到当前节点的距离,通过车辆的行驶速度与时间的乘积获得;第二个参数是路径的平滑程度,对频繁变化的行驶速度和行驶方向进行惩罚,其数值通过当前节点与父节点的控制量(v,phi)的差值得到;启发代价函数h(x)设定两种代价计算方式,最后取其中较大的值作为最终代价;第一种代价计算符合车辆运动学,但不考虑路径是否发生碰撞,第一种代价计算使用Reeds-Shepp曲线来实现,首先生成从当前位姿到目标位姿的Reeds-Shepp曲线,使用Reeds-Shepp曲线的长度作为第一种代价;第二种代价计算考虑碰撞检测,但不考虑车辆运动学;第二种代价计算将搜索空间划分为二维网格,使用Dijkstra算法计算当前点到目标点的网格数,以此得到估计的路径长度,作为第二种启发代价;其中,A*中使用的代价函数如图3所示。
进一步的,对于动态障碍物,混合A*算法设定离线数据中相邻两帧数据的时间间隔为Δt,设定搜索中相邻节点的时间间隔为Δt;在进行路径探索时,在每一节点下,车辆位于其对应时刻的场景可行驶区域内,以实现动态场景下的离线路径规划。
进一步的,通过离线路径规划所获得的数据对规划策略模型pi和环境预测模型p进行模型训练的工作过程包括:
S2-1:离线路径规划所获得的数据包括:给定历史状态动作序列fau(t)=(fs{t-n},fa{t-n},...,fs{t-1},fa{t-1},fs(t)),该序列包含当前时刻的环境状态fs(t)以及过去n个时刻下的环境状态与车辆动作;
S2-2:通过监督学习的方法,定义历史状态动作序列fau(t)作为输入数据,将对应的车辆动作fa(t)和下一时刻的环境状态fs(t+1)作为目标数据,来训练模型;规划策略模型pi的训练目标是根据当前环境状态fs(t)生成当前时刻下的车辆动作fa(t);环境预测模型p的训练目标是根据历史状态动作序列fau(t)和当前动作fa(t),预测下一时刻的环境状态fs(t+1);其中,环境状态fs为已知的车辆可行驶区域,车辆动作fa则为车辆行驶时的速度与方向盘角度(v,phi)。
进一步的,在模型训练上,使用Transformer模型来处理序列数据;使用二维图像来表示场景的可行驶区域;引入两个卷积神经网络作为图像的编码器和解码器;编码器将图像编码为一个一维向量,解码器则将一维向量还原为图像;其中,Transformer模型工作内容如图4所示。
进一步的,利用训练后的策略模型,通过自回归方式实现在线路径规划的工作过程包括:
S3-1:在线规划时,将规划策略模型与环境预测模型结合在一起,利用当前时刻下的历史状态动作序列fau(t)预测当前时刻的车辆动作fa(t)和下一时刻的环境状态fs(t+1);规划策略模型pi利用fau(t)生成当前时刻下的车辆动作fa(t),环境预测模型p则使用fau(t)和fa(t)预测下一时刻的环境状态fs(t+1);
S3-2:将fau(t)与fa(t)、fs(t+1)组合为fau(t+1),在线规划模型继续预测未来的动作和环境状态,从而通过自回归的方式实现对车辆的路径规划;其中,自回归路径生成过程如图5所示。
进一步的,通过集束搜索的方法将动作空间进行离散化,解决模型训练时的多解问题,实现多条候选可行路径的生成;集束搜索过程中,记长度为l的路径为L=(fa(t),fa(t+1),...,fa(t+1-1)),定义其概率为P(L)=prod{i=0}^{l-1}P(fa(t+i)),在每一步搜索过程中保留概率最大的k条路径,最终得到k条候选可行路径;其中,集束搜索示意图如图6所示。
进一步的,利用离线路径规划中的代价函数,对k条候选可行路径进行评估,从中选取代价函数值最小的路径作为路径规划的结果,并对选取的该路径进行优化,得到最优路径;最优路径的设定过程中,涉及到参考线约束(lr)、无碰撞约束(lc)、动力学约束(ld)和平滑性约束(ls);实现最终路径优化目标的工作过程包括:
S5-1:所述参考线约束(lr)使得优化后的路径尽可能靠近原始路径,设定规划策略模型的路径包含N个点,以规划策略模型的路径作为参考线,则参考线约束公式为:
其中,k表示车辆行驶路径中的第k个点,x表示车辆位置的横坐标,y表示车辆位置的纵坐标、phi表示车辆的朝向、v表示车辆的行驶速度,w1为Δx_k^2对应的权重系数,w2为Δy_k^2对应的权重系数,w3为Δphi_k^2对应的权重系数,w4为Δv_k^2对应的权重系数;
S5-2:所述无碰撞约束要求车辆始终在可行驶区域内,利用可行驶区域建立人工势场h,设定可行驶区域的势场值为0,越远离可行驶区域,势场值越大;则无碰撞约束公式为:
S5-3:所述动力学约束要求车辆的行驶轨迹需满足车辆的动力学要求,记车辆的状态转移函数为f,则动力学约束公式为:
其中f(x)=(x,y,phi,v)为车辆的状态量,f(u)=(u,a)为车辆的控制量;其中,u表示车辆的角速度,a表示车辆的加速度,f(w)=(w5,w6,w7,w8);w5,w6,w7,w8分别对应f(x)的取值为x,y,phi,v各项时的权重系数;
S5-4:所述平滑性约束要求各路径点的控制量及其变化量要小,以避免车辆行驶时来回晃动,平滑性约束公式为:
其中,u_′k为车辆角速度的导数,表示车辆角速度的变化量;a_′k为车辆加速度的导数,表示车辆加速度的变化量;w9为u_k^2对应的权重系数,w10为a_k^2对应的权重系数,w11为{u_′k}^2对应的权重系数,w12为{a_′k}^2对应的权重系数;
S5-5:综合上述,最终的路径优化目标函数为:
l=wr*lr+wc*lc+wd*ld+ws*ls
其中,wr为lr对应的权重系数,wc为lc对应的权重系数,wd为ld对应的权重系数,ws为ls对应的权重系数。
与现有技术相比,本发明所达到的有益效果是:本发明采用混合A*算法能够有效解决动态场景下的路径规划问题,考虑了障碍物的动态变化情况,从而生成更准确合理的离线路径;通过离线路径规划并对其获得的数据进行模型训练,提高路径规划的准确性和效率,使其更智能和适应动态环境的变化;利用训练后的策略模型,通过自回归方式实现在线路径规划,结合实时环境信息和模型预测,快速生成适应当前动态场景的路径方案;通过集束搜索方法生成多条候选可行路径,增加了路径规划的多样性和灵活性,满足了不同场景需求;在多条候选路径生成后,对这些路径进行评估并选取一条进行优化,得到最优路径。这样确保了路径的质量和实用性。本发明的路径规划方法能够提供更准确、智能、多样且优化的路径,为路径规划领域带来了重要的创新和进步,为动态场景下的路径规划问题提供了更好的解决方案。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是本发明一种结合离线采样学习与在线优化的无人车路径规划方法流程示意图;
图2是本发明一种结合离线采样学习与在线优化的无人车路径规划方法的路径规划整体框架示意图;
图3是本发明一种结合离线采样学习与在线优化的无人车路径规划方法中A*中使用的代价函数示意图;
图4是本发明一种结合离线采样学习与在线优化的无人车路径规划方法的Transformer模型工作内容示意图;
图5是本发明一种结合离线采样学习与在线优化的无人车路径规划方法的自回归路径生成过程示意图;
图6是本发明一种结合离线采样学习与在线优化的无人车路径规划方法的集束搜索示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-图6,本发明提供技术方案:一种结合离线采样学习与在线优化的无人车路径规划方法,方法包括:步骤S1:采用混合A*算法实现动态场景下的离线路径规划;步骤S2:通过离线路径规划所获得的数据,对规划策略模型pi和环境预测模型p进行模型训练;步骤S3:利用训练后的模型,通过自回归方式实现在线路径规划;步骤S4:通过集束搜索的方法实现多条候选可行路径的生成;步骤S5:对多条候选可行路径进行评估,选取一条路径作为路径规划的结果,并对选取的该路径进行优化,得到最优路径。
混合A*算法的工作过程包括如下步骤:
S1-1:混合A*算法在车辆的运动空间上进行采样,选取不同的速度v以及方向盘转角phi,以固定时间间隔Δt生成平滑、符合车辆运动学的行驶路径;
S1-2:混合A*算法中引入了Reeds-Shepp曲线来衔接当前位姿和终点位姿,Reeds-Shepp曲线由三部分组成,包括一段向左的圆弧、一段线段和一段向右的圆弧;
S1-3:由于Reeds-Shepp曲线生成较快,在车辆接近终点时,若生成的Reeds-Shepp曲线符合碰撞条件,各时刻车身均完全落在可行驶区域内,则混合A*算法对可行路径的搜索完成;若生成的Reeds-Shepp曲线不符合碰撞条件,即车辆与障碍物相交或碰撞,混合A*算法继续搜索可行路径,直到找到满足碰撞条件的路径为止;所述碰撞条件指车辆在沿着生成的路径行驶时,不与任何障碍物相交或碰撞。
混合A*算法对已发代价函数g(x)和启发代价函数h(x)进行设定;已发代价函数g(x)包含两个参数,第一个参数是起点到当前节点的距离,通过车辆的行驶速度与时间的乘积获得;第二个参数是路径的平滑程度,对频繁变化的行驶速度和行驶方向进行惩罚,其数值通过当前节点与父节点的控制量(v,phi)的差值得到;启发代价函数h(x)设定两种代价计算方式,最后取其中较大的值作为最终代价;第一种代价计算符合车辆运动学,但不考虑路径是否发生碰撞,第一种代价计算使用Reeds-Shepp曲线来实现,首先生成从当前位姿到目标位姿的Reeds-Shepp曲线,使用Reeds-Shepp曲线的长度作为第一种代价;第二种代价计算考虑碰撞检测,但不考虑车辆运动学;第二种代价计算将搜索空间划分为二维网格,使用Dijkstra算法计算当前点到目标点的网格数,以此得到估计的路径长度,作为第二种启发代价。
对于动态障碍物,混合A*算法设定离线数据中相邻两帧数据的时间间隔为Δt,设定搜索中相邻节点的时间间隔为Δt;在进行路径探索时,在每一节点下,车辆位于其对应时刻的场景可行驶区域内,以实现动态场景下的离线路径规划。
通过离线路径规划所获得的数据对规划策略模型pi和环境预测模型p进行模型训练的工作过程包括:
S2-1:离线路径规划所获得的数据包括:给定历史状态动作序列fau(t)=(fs{t-n},fa{t-n},...,fs{t-1},fa{t-1},fs(t)),该序列包含当前时刻的环境状态fs(t)以及过去n个时刻下的环境状态与车辆动作;
S2-2:通过监督学习的方法,定义历史状态动作序列fau(t)作为输入数据,将对应的车辆动作fa(t)和下一时刻的环境状态fs(t+1)作为目标数据,来训练模型;规划策略模型pi的训练目标是根据当前环境状态fs(t)生成当前时刻下的车辆动作fa(t);环境预测模型p的训练目标是根据历史状态动作序列fau(t)和当前动作fa(t),预测下一时刻的环境状态fs(t+1);其中,环境状态fs为已知的车辆可行驶区域,车辆动作fa则为车辆行驶时的速度与方向盘角度(v,phi)。
在模型训练上,使用Transformer模型来处理序列数据;使用二维图像来表示场景的可行驶区域;引入两个卷积神经网络作为图像的编码器和解码器;编码器将图像编码为一个一维向量,解码器则将一维向量还原为图像。
利用训练后的策略模型,通过自回归方式实现在线路径规划的工作过程包括:
S3-1:在线规划时,将规划策略模型与环境预测模型结合在一起,利用当前时刻下的历史状态动作序列fau(t)预测当前时刻的车辆动作fa(t)和下一时刻的环境状态fs(t+1);规划策略模型pi利用fau(t)生成当前时刻下的车辆动作fa(t),环境预测模型p则使用fau(t)和fa(t)预测下一时刻的环境状态fs(t+1);
S3-2:将fau(t)与fa(t)、fs(t+1)组合为fau(t+1),在线规划模型继续预测未来的动作和环境状态,从而通过自回归的方式实现对车辆的路径规划。
通过集束搜索的方法将动作空间进行离散化,解决模型训练时的多解问题,实现多条候选可行路径的生成;集束搜索过程中,记长度为l的路径为L=(fa(t),fa(t+1),...,fa(t+1-1)),定义其概率为P(L)=prod{i=0}^{l-1}P(fa(t+i)),在每一步搜索过程中保留概率最大的k条路径,最终得到k条候选可行路径。
利用离线路径规划中的代价函数,对k条候选可行路径进行评估,从中选取代价函数值最小的路径作为路径规划的结果,并对选取的该路径进行优化,得到最优路径;最优路径的设定过程中,涉及到参考线约束(lr)、无碰撞约束(lc)、动力学约束(ld)和平滑性约束(ls);实现最终路径优化目标的工作过程包括:
S5-1:所述参考线约束(lr)使得优化后的路径尽可能靠近原始路径,设定规划策略模型的路径包含N个点,以规划策略模型的路径作为参考线,则参考线约束公式为:
其中,k表示车辆行驶路径中的第k个点,x表示车辆位置的横坐标,y表示车辆位置的纵坐标、phi表示车辆的朝向、v表示车辆的行驶速度,w1为Δx_k^2对应的权重系数,w2为Δy_k^2对应的权重系数,w3为Δphi_k^2对应的权重系数,w4为Δv_k^2对应的权重系数;
S5-2:所述无碰撞约束要求车辆始终在可行驶区域内,利用可行驶区域建立人工势场h,设定可行驶区域的势场值为0,越远离可行驶区域,势场值越大;则无碰撞约束公式为:
S5-3:所述动力学约束要求车辆的行驶轨迹需满足车辆的动力学要求,记车辆的状态转移函数为f,则动力学约束公式为:
其中f(x)=(x,y,phi,v)为车辆的状态量,f(u)=(u,a)为车辆的控制量;其中,u表示车辆的角速度,a表示车辆的加速度,f(w)=(w5,w6,w7,w8);w5,w6,w7,w8分别对应f(x)的取值为x,y,phi,v各项时的权重系数;
S5-4:所述平滑性约束要求各路径点的控制量及其变化量要小,以避免车辆行驶时来回晃动,平滑性约束公式为:
其中,u_′k为车辆角速度的导数,表示车辆角速度的变化量;a_′k为车辆加速度的导数,表示车辆加速度的变化量;w9为u_k^2对应的权重系数,w10为a_k^2对应的权重系数,w11为{u_′k}^2对应的权重系数,w12为{a_′k}^2对应的权重系数;
S5-5:综合上述,最终的路径优化目标函数为:
l=wr*lr+wc*lc+wd*ld+ws*ls
其中,wr为lr对应的权重系数,wc为lc对应的权重系数,wd为ld对应的权重系数,ws为ls对应的权重系数。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
最后应说明的是:以上仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种无人电动车的路径规划方法
- 一种将离线训练和在线学习相结合的单目标追踪方法
- 离线在线相结合的开关磁阻电机功率调节与效率优化方法