新型犬气味结合蛋白
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及分子生物学领域。
更准确地,本发明涉及鉴定新型犬气味结合蛋白(OBP),其能够结合疏水化合物,尤其是气味化合物。这些新鉴定的OBP对于检测可以用于工业的气味化合物尤其有用。
背景技术
脂质运载蛋白形成一个蛋白质家族,尤其是在昆虫和脊椎动物中发现,它们在小疏水分子(如类固醇、胆盐、类视黄醇和脂质)的转运中发挥功能。脂质运载蛋白与许多生物过程相关,如免疫反应、信息素转运、前列腺素合成、类视黄醇结合和癌细胞相互作用。
该家族由含有疏水口袋的小蛋白质(160-190个氨基酸)组成,其通常是分泌的,尽管在一些情况下蛋白质保持与膜结合。在结构上,它们共享共同的三级结构,其由9条链的反平行β-桶组成,通过转角与螺旋结构域连接,然后是桶的一条链和C-末端尾巴。配体结合位点(即结合口袋)位于β-桶中间的空腔内。然而,尽管这种结构有同源性,但是脊椎动物脂质运载蛋白之间的序列同一性仍然很低(大约20%)。
气味结合蛋白(通常称为“OBP”)属于脂质运载蛋白家族。它们呈现15-22kDa的分子质量,在嗅粘液中分泌,嗅觉受体神经元沐浴在嗅粘液中。已在许多脊椎动物物种中鉴定了OBP。与其他脂质运载蛋白一样,OBP通常结合疏水化合物,优选气味化合物,并充当转运体,从而将这些化合物递送至位于嗅觉神经元细胞膜中的嗅觉受体。脊椎动物OBP属于脂质运载蛋白家族,呈现相同的折叠。基本上,脊椎动物OBP在物种间和物种内共享低同一性百分比。已显示物种之间的这一保守残基百分比低至8%(Tegoni,Campanacci等人2004)。
在许多脊椎动物(爪蟾、牛、猪、兔、小鼠、大鼠、猪、象、人)中大量研究了OBP,但尚未在狗中表征OBP。本发明人首次鉴定并表征了4种犬OBP。
本文描述的一些序列先前已被鉴定为脂质运载蛋白,但以前从未证明过或甚至从未描述过它们作为OBP的非常独特的功能。
发明内容
在第一方面,本发明涉及选自以下的序列作为OBP的用途:Seq ID No 3、Seq IDNo 1、Seq ID No 2、Seq ID No 4、Seq ID No 5、Seq ID No 6、Seq ID No 7、Seq ID No 8及其功能变体。
在进一步的方面,本发明涉及一种鉴定配体的方法,其至少包括以下步骤:
(i)将至少一种候选化合物暴露于如上所定义的OBP;
(ii)检测候选化合物是否与所述OBP结合;和
(iii)如果候选化合物与所述OBP结合,则化合物被鉴定为所述OBP的配体。
在另一方面,本发明还涉及一种试剂盒,其在单个包装中的一个或多个容器中包含:
(i)如本发明中所定义的OBP,和
(ii)一种或多种候选化合物。
特别是,这种试剂盒可以用于鉴定气味化合物,如使用根据本发明所述的方法进行鉴定。
附图说明
图1
图2
图3
图4
图5
图6
具体实施方式
除非另有特别说明,否则本文中的百分比以参考产品的重量表示。在本公开中,用速记形式陈述范围,以避免必须详细列出并描述范围内的每一个值。在合适的情况下,可以选择范围内的任何合适的值作为范围的上限值、下限值或终点。例如,范围0.1-1.0表示终点值0.1和1.0,以及中间值0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9,和0.1-1.0内涵盖的所有中间范围,如0.2-0.5、0.2-0.8、0.7-1.0等。
如通篇所用,除非上下文另有明确规定,否则词语的单数形式包括复数形式,反之亦然。因此,提及“一种(a)”、“一种(an)”和“所述(the)”一般包括各自术语的复数形式。例如,提及“一种方法”包括多种此类“方法”。类似地,词语“包含”也应作包容性解释。同样,术语“包括”和“或”均应解释为具有包容性。然而,所有这些术语都必须被视为涵盖排他性实施方案,也可以使用诸如“由……组成”的词语来指代这些实施方案。
在此举例说明的方法和组合物以及其他实施方案不限于本文描述的具体方法、方案和试剂,因为如本领域技术人员将理解的那样,它们可以变化。
除非特别定义,否则本文使用的所有技术和科学术语具有与化学、生物化学、细胞生物学、分子生物学和农学领域的技术人员通常理解的相同含义。
如本文所用的术语“约”在指可测量值(如量、持续时间等)时,意在涵盖从指定值变化±20%,更优选±10%,甚至更优选±5%,因为此类变化适合于再现所公开的方法和产品。
“分离的”是指从其自然环境中提取(即,从与其自然联合的至少一种其他组分分离)的分子,包括蛋白质、多肽、肽、核酸分子、质粒载体、病毒载体或重组细胞。
“适合于……的条件”、“对于……的适合条件”是指实施根据本发明的方法的条件,其在说明书中描述,特别是在实施例中说明,或本领域技术人员公知。
本文的“犬科动物(canine)”是指作为犬科成员的动物,包括狼、豺、狐、郊狼和家犬(domestic dog,以下称“狗”)。例如,犬科动物可以是家犬(domestic dog)、狼或具有来自犬科的多于一种物种的一些遗传属性的动物。优选地,术语“犬科动物”是指家犬,尤其是家犬(Canis lupus familiaris)亚种的那些犬。
在以下描述中,实施方案可以由本领域技术人员以合适的方式单独或组合采取。
在研究狗的嗅粘液时,本发明人令人惊讶地发现,该粘液中存在的在数据库中被引用为脂质运载蛋白的一些蛋白质可以用作OBP。这些蛋白质已被重新命名为CfamOBP1、CfamOBP2、CfamOBP3和CfamOBP4。在本发明的上下文中,分别通过提及其序列Seq ID No 1、Seq ID No 2、Seq ID No3和Seq ID No 4来鉴定和指明这些蛋白质。
A-
在第一方面,本发明涉及选自以下的序列作为OBP的用途:Seq ID No 3、Seq IDNo 1、Seq ID No 2、Seq ID No 4、Seq ID No 5、Seq ID No 6、Seq ID No 7、Seq ID No 8及其功能变体。为了简洁明了起见,本发明中描述并使用的序列称为“OBP”。
本发明人现在已经鉴定了本文描述的蛋白质和多肽可以用作OBP,其能够结合疏水化合物,更特别地是气味化合物,包括信息素。
“蛋白质”是指氨基酸残基的聚合物,其包含通过肽键连接的至少九个氨基酸。所述聚合物可以是直链的、支链的或环状的。所述聚合物可以包含天然存在的氨基酸和/或氨基酸类似物,并且可以被非氨基酸残基中断。在本申请中作为一般指示并且不与其链接,如果氨基酸聚合物含有多于50个氨基酸残基,则优选将其称为“多肽”或“蛋白质”,而如果该聚合物由50个或更少的氨基酸组成,则优选将其称为“肽”。因此,在本申请的意义上,术语“蛋白质”和“多肽”具有相似的含义并且可以可互换使用。
“结合”是指用作OBP的蛋白质和多肽与结合配偶体形成复合物,所述结合配偶体如疏水化合物,并且优选气味化合物。通常,根据本发明的用作OBP的蛋白质和多肽结合至少一种气味物质,其包含化合物如吡嗪、吡咯、醛、酮、酯、醇、酸、烷烃、烯烃、苯、硫化物、苯酚、噻唑、硫磺、碳氢化合物、萜烯或萜类化合物、呋喃、呋喃酮、内酯以及信息素。用于检测两个分子是否结合的方法在本领域中是公知的,包括例如平衡透析、表面等离子体共振、配体竞争性结合测定等。
“疏水分子”或“疏水化合物”是指倾向于非极化并因此偏好其他中性分子和非极性溶剂的分子。通常,疏水分子被大量水排斥,不溶于水,并且与水没有极性亲和力。
“气味物质”、“气味化合物”或“气味分子”包括化合物如吡嗪、吡咯、醛、酮、酯、醇、酸、烷烃、烯烃、苯、硫化物、苯酚、噻唑、硫磺、碳氢化合物、萜烯或萜类化合物、呋喃、呋喃酮、内酯以及信息素。通常,气味物质提供气味(smell,odor)、风味或香气,并且具有足够的挥发性以被转运至嗅觉系统,尤其是通过气味结合蛋白转运至位于感觉神经元细胞膜中的嗅觉受体。例如,DMO(3,7-二甲基-1-辛醇)、β-紫罗兰酮、香茅醛和IBMP(2-异丁基-3-甲氧基吡嗪)被认为是气味分子。
用作OBP的多肽
本发明提供了多肽作为OBP的用途。在本发明的上下文中用作OBP的肽序列如下:
Seq ID No 1:CfamOBP1
Seq ID No 2:CfamOBP2
Seq ID No 3:CfamOBP3
Seq ID No 4:CfamOBP4
在以上鉴定的蛋白质序列中,粗体字符表示信号肽;带下划线的字符表示共有序列,并且斜体字符表示α螺旋。
在实施方案中,本发明涉及选自Seq ID No 3、Seq ID No 2、Seq ID No 1和SeqID No 4的序列作为OBP的用途。
在优选的实施方案中,本发明涉及选自Seq ID No 3、Seq ID No 1和Seq ID No2的序列作为OBP的用途。仍优选地,本发明涉及选自Seq ID No 3和Seq ID No 2的序列作为OBP的用途。
用作OBP的变体
本发明还涉及上述多肽的功能变体作为OBP的用途。
“功能变体”或“其功能变体”是指源自根据本发明的OBP并且保留用于附接至疏水化合物(优选气味物质)的至少一个结构域的蛋白质。与参考OBP相比,功能变体可以具有相似或不同的结合谱。换言之,根据本发明的功能变体可以结合与其源自的OBP相同的化合物,但它也可以仅结合这些化合物中的一些,或不结合这些化合物中的任何一种,并且还可以结合参考OBP原本不结合的其他化合物。特别是,根据本发明使用的功能变体可以结合以下化合物:
(1)仅与其源自的OBP(参考OBP)相同的化合物;
(2)与其源自的OBP相同的化合物以及所述参考OBP原本不结合的其他化合物;
(3)仅其源自的OBP结合的化合物中的一些;
(4)其源自的OBP结合的一些化合物以及所述参考OBP原本不结合的其他化合物;或
(5)仅参考OBP原本不结合的一些化合物。
根据本发明使用的功能变体包括突变多肽,其可以天然存在,特别是在犬科动物(如狗)中。修饰可以是至少一个氨基酸的缺失、添加或替换,截短、延长和/或嵌合融合。作为示例,将提及能够在不导致由此获得的多肽的生物活性发生变化的情况下进行替换的可能性。这些类型的替换通常称为保守替换。它们对应于用具有相似生物化学特性(例如电荷、疏水性和/或大小)的不同氨基酸替换氨基酸。例如,可以用缬氨酸或异亮氨酸替换亮氨酸;可以用谷氨酸替换天冬氨酸;用天冬酰胺替换谷氨酰胺,或用赖氨酸替换精氨酸等。也可以在相同的条件下进行反向替换。特别是,可以在蛋白质的α螺旋水平上引入一种或多种修饰,如缺失、添加或替换至少一个氨基酸,而不影响由β-片层结构形成的杯(chalice)。类似地,可以引入等同氨基酸,其可以用于保持小叶β(leaflet beta)的疏水特征。本领域还普遍知晓,位于结合口袋入口处的一个保守酪氨酸残基构成空腔的门。结构和分子动力学研究与诱变实验相结合,已揭示了该残基在气味物质摄入中的关键作用。
特别是,OBP的N-末端部分对应于信号肽,在以上序列Seq ID No 1至4中以粗体字符表示,其功能是将蛋白质输出至合成它的细胞之外。尽管信号肽在OBP中具有重要功能,但它在所述蛋白质的结合能力中没有功能,因此它不参与其特异性。因此清楚的是,根据本发明使用的分离蛋白质的信号肽是任选的。因此,所述信号肽可以不在变体中,或者它可以被任何其他信号肽取代,如具有相似输出功能的信号肽或具有将所述变体导向细胞特定隔室的功能的信号肽。
根据本发明,OBP的功能变体可以是其片段。在具体的实施方案中,片段至少包含其源自的OBP的共有序列。在具体的实施方案中,片段至少包含参与所述OBP的结合口袋的氨基酸。如上所解释,根据本发明的功能变体必须结合疏水化合物,并且更优选气味化合物。然而,所述化合物可以不同于参考OBP(即,所述变体源自的OBP)结合的那些化合物。
有利地,根据本发明的分离蛋白质的功能变体包含与选自Seq ID No 3、Seq IDNo 2、Seq ID No 1和Seq ID No 4的序列具有至少70%同一性的氨基酸序列。更优选地,根据本发明的功能变体包含与选自Seq ID No 1、Seq ID No 2、Seq ID No 3和Seq ID No 4的序列具有至少以下同一性的氨基酸序列:至少75%的同一性,更优选至少80%的同一性,更优选至少85%的同一性,更优选至少90%的同一性,仍更优选至少91%的同一性,仍更优选至少92%的同一性,仍更优选至少93%的同一性,仍更优选至少94%的同一性,仍更优选至少95%的同一性,仍更优选至少96%的同一性,仍更优选至少97%的同一性,仍更优选至少98%的同一性,仍更优选至少99%的同一性,并且仍更优选100%的同一性。
“同一性”是指两个多肽之间、两个蛋白质之间、两个肽之间或两个氨基酸分子之间的精确序列匹配。两个序列之间的“同一性百分比”或“ID%”是两个序列共有的相同残基数量的函数,考虑为最佳比对而必须引入的间隙数和每个间隙的长度。技术领域中可获得各种计算机程序和数学算法以确定氨基酸序列之间的同一性百分比,如NCBI或ALIGN数据库上可获得的Blast程序(Atlas of Protein Sequence and Structure,Dayhoff(编辑),1981,Suppl.3 482-489)。例如,如此处所用,“至少80%的序列同一性”表示80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%。
用作OBP的共有序列
为了清楚起见,CfamOBP1的共有序列由Seq ID No 5指定,CfamOBP2的共有序列由Seq ID No 6指定,CfamOBP3的共有序列由Seq ID No 7指定,并且CfamOBP4的共有序列由Seq ID No 8指定。
“共有序列”是指蛋白质的一部分,其负责蛋白质的功能和结合特异性,并从而允许其在本发明的上下文中作为OBP的用途。尤其是,共有序列包含参与所述蛋白质的结合口袋形成的氨基酸。“结合口袋”是指OBP表面上或内部的空腔,其具有结合配体的适合特性,所述配体特别是疏水化合物,优选气味化合物。在这方面,结合口袋的3D结构构象至关重要,因为它是多肽结合特异性的关键,因此是其作为OBP的用途的关键。事实上,其独特的配置允许适应其个体分子结合配偶体并促进结合过程。
因此,根据本发明,OBP优选包含选自Seq ID No 7、Seq ID No 6、Seq ID No5和Seq ID No 8的序列。
在优选的实施方案中,本发明涉及选自Seq ID No 7、Seq ID No 6和Seq ID No5的序列作为OBP的用途。仍优选地,本发明涉及选自Seq ID No 7和Seq ID No 6的序列作为OBP的用途。
根据一些实施方案,所述OBP进一步包含信号肽和α螺旋肽。
“信号肽”是指用于将蛋白质导向特定位置的肽。该位置可以是细胞隔室,如细胞核、内体、高尔基体或其他,它可以是膜,如细胞膜或细胞器膜,或者它可以在细胞外部,尤其是对于被分泌的蛋白质。信号肽是短肽,通常包含15至30个氨基酸,并且位于N-末端或C-末端位置。特别是,所有分泌的蛋白质均含有信号肽,其是氨基酸的疏水序列。在本发明的上下文中,信号肽的存在是任选的。
“α螺旋”是指显示出特定的二级结构的肽,所述结构由右手螺旋构象组成,其中每个主链N-H基团氢与位于沿蛋白质序列向前三个或四个残基的氨基酸的主链C=O基团结合。OBP的C-末端序列(包括α-螺旋)的修饰对OBP结合特性没有影响(Ramoni,Bellucci等人2007)。因此,在本发明的上下文中,α螺旋的存在是任选的。
在优选的实施方案中,本发明涉及选自Seq ID No 7、Seq ID No 6、Seq ID No5和Seq ID No 8的序列作为OBP的用途,其中所述序列进一步包含合适的信号肽,特别是允许将蛋白质分泌到合成蛋白质的细胞外的信号肽。
在优选的实施方案中,本发明涉及选自Seq ID No 7、Seq ID No 6、Seq ID No5和Seq ID No 8的序列作为OBP的用途,其中所述序列进一步包含合适的α螺旋肽。
在另一个优选的实施方案中,本发明涉及根据本发明的多肽作为OBP的用途,所述多肽包含:
(i)选自Seq ID No 7、Seq ID No 6、Seq ID No 5和Seq ID No 8的序列,和
(ii)合适的信号肽,特别是允许将蛋白质分泌到合成蛋白质的细胞外的信号肽,和
(iii)合适的α螺旋肽。
在另一个优选的实施方案中,本发明涉及根据本发明的多肽作为OBP的用途,所述多肽由以下组成:
(i)选自Seq ID No 7、Seq ID No 6、Seq ID No 5和Seq ID No 8的序列,和
(ii)合适的信号肽,特别是允许将蛋白质分泌到合成蛋白质的细胞外的信号肽,和
(iii)合适的α螺旋肽。
用作OBP的共有序列的变体
本发明进一步涉及使用以上鉴定的共有序列的功能变体作为OBP的用途。根据本发明的“共有序列的功能变体”保留了用于附接至疏水化合物(优选气味物质)的至少一个结构域,并且与参考共有序列相比可以具有相似的或不同的结合谱。以上给出的“功能变体”的定义比照适用。
因此,在优选的实施方案中,根据本发明的用作OBP的共有序列的功能变体包含与选自Seq ID No 7、Seq ID No 6、Seq ID No 5和Seq ID No 8的序列具有至少90%同一性的氨基酸序列。更优选地,共有序列的功能变体包含与选自Seq ID No7、Seq ID No 6、SeqID No 5和Seq ID No 8的序列具有至少以下同一性的氨基酸序列:至少91%的同一性,仍更优选至少92%的同一性,仍更优选至少93%的同一性,仍更优选至少94%的同一性,仍更优选至少95%的同一性,仍更优选至少96%的同一性,仍更优选至少97%的同一性,仍更优选至少98%的同一性,仍更优选至少99%的同一性,并且仍更优选100%的同一性。
在一些实施方案中,本发明涉及与Seq ID No 3、Seq ID No 2、Seq ID No 1和SeqID No 4中任一个的共有序列具有至少90%同一性的序列的功能变体用作OBP的用途。
在优选的实施方案中,用作OBP的功能变体(1)保留用于附接至疏水化合物(优选气味物质)的至少一个结构域,并且与参考OBP相比可以具有相似的或不同的结合谱,和/或(2)与选自Seq ID No 3、Seq ID No 2、Seq ID No 1和Seq ID No4的序列具有的氨基酸序列同一性为至少70%的同一性,优选至少75%的同一性,更优选至少80%的同一性,更优选至少85%的同一性,更优选至少90%的同一性,仍更优选至少91%的同一性,仍更优选至少92%的同一性,仍更优选至少93%的同一性,仍更优选至少94%的同一性,仍更优选至少95%的同一性,仍更优选至少96%的同一性,仍更优选至少97%的同一性,仍更优选至少98%的同一性,仍更优选至少99%的同一性,并且仍更优选100%的同一性,和/或(3)与选自Seq ID No 5、Seq ID No 6、Seq ID No 7和Seq ID No 8的序列具有的序列同一性为至少90%的同一性,优选至少91%的同一性,仍更优选至少92%的同一性,仍更优选至少93%的同一性,仍更优选至少94%的同一性,仍更优选至少95%的同一性,仍更优选至少96%的同一性,仍更优选至少97%的同一性,仍更优选至少98%的同一性,仍更优选至少99%的同一性,并且仍更优选100%的同一性。
用作OBP的优选变体
根据一些实施方案,Seq ID No 1的功能变体选自Seq ID No 13和Seq ID No 14。
根据实施方案,Seq ID No 2的功能变体是Seq ID No 15。
根据实施方案,Seq ID No 3的功能变体选自Seq ID No 27和Seq ID No 35。
根据实施方案,Seq ID No 4的功能变体选自Seq ID No 16和Seq ID No 28。
在优选的实施方案中,根据本发明的用作OBP的多肽的功能变体包含选自Seq IDNo 13、Seq ID No 14、Seq ID No 15、Seq ID No 27、Seq ID No 35、Seq ID No 16和SeqID No 28的序列,特别是选自Seq ID No 13、Seq ID No 14、Seq ID No 15、Seq ID No 27和Seq ID No 35的序列,并且仍优选选自Seq ID No 15、Seq ID No 27和Seq ID No 35的序列。在另一个实施方案中,根据本发明的用作OBP的多肽的功能变体由以下组成:选自SeqID No 13、Seq ID No 14、Seq ID No 15、Seq ID No27、Seq ID No 35、Seq ID No 16和SeqID No 28的序列,特别是选自Seq ID No 13、Seq ID No 14、Seq ID No 15、Seq ID No 27和Seq ID No 35的序列,并且仍优选选自Seq ID No 15、Seq ID No 27和Seq ID No 35的序列。
标签
根据一些实施方案,根据本发明的用作OBP的分离蛋白质和多肽进一步包含至少一个标签。“标签”是指移植于重组多肽的C-末端或N-末端的肽序列。标签尤其是在分子生物学中用于蛋白质纯化、定位、溶解或其他应用。标签数量众多,并且在本领域是公知的。它们尤其包括GST标签、His标签、Flag标签、荧光标签和其他标签。
在另一方面,本发明涉及一种方法,其至少包括以下步骤:
(i)提供选自Seq ID No 3、Seq ID No 1、Seq ID No 2、Seq ID No 4、Seq ID No5、Seq ID No 6、Seq ID No 7、Seq ID No 8及其功能变体的至少一个序列;和
(ii)使用所述序列作为OBP。
在本发明的这一方面,步骤(i)的功能变体是上述那些功能变体,并且优选选自Seq ID No 13、Seq ID No 14、Seq ID No 15、Seq ID No 27、Seq ID No 35、Seq ID No 16和Seq ID No 28。
B-
在另一方面,本发明还涉及一种鉴定配体的方法。
“配体”是指与如本发明所定义的OBP结合和/或与其形成复合物的化合物。优选地,所述配体是疏水化合物,并且最优选气味化合物,其中“疏水化合物”和“气味化合物”的含义在说明书中如上所定义。
在实施方案中,所述鉴定配体的方法至少包括以下步骤:
(i)将至少一种候选化合物暴露于如上所定义的OBP或根据下述方法(参见第I节“产生OBP的方法”)产生的OBP;
(ii)检测候选化合物是否与所述OBP结合;和
(iii)如果候选化合物与所述OBP结合,则化合物被鉴定为所述OBP的配体。
在可替选步骤(iii)中,如果候选化合物不与所述OBP结合,则化合物被鉴定为不是配体。
在具体的实施方案中,所述方法在所述步骤(i)之前至少包括以下步骤:
-提供选自Seq ID No 3、Seq ID No 1、Seq ID No 2、Seq ID No 4、Seq ID No 5、Seq ID No 6、Seq ID No 7、Seq ID No 8及其功能变体的至少一个序列,其中所述序列用作步骤(i)中的OBP。
在该实施方案中,功能变体是上述那些功能变体,并且优选选自Seq ID No 13、Seq ID No 14、Seq ID No 15、Seq ID No 27、Seq ID No 35、Seq ID No 16和Seq ID No28。
如本文所用,术语“候选化合物”应当理解为其结合OBP的能力尚未知道并待测试以首次证明的化合物,或者其结合OBP的能力是推定的并且待测试以确认性证明的化合物。
候选化合物可以是气味化合物。在具体的实施方案中,包含至少一种候选化合物的组合物可以用于步骤(i)中。例如,所述组合物可以是食品、宠物食品、宠物食品适口性增强剂、香料或香水。
在步骤(ii)中,必须采用检测方法。检测方法的选择完全在技术人员能力范围内,例如荧光或量热法。
关于具体的实施方案,检测配体是否与所述OBP结合的步骤(ii)可以通过测量荧光来实施。用于测量荧光的装置是本领域公知的,并且尤其可以通过使用分光荧光计来实施。
在该最有利的实施方案中,所述方法包括使所述OBP与荧光探针接触的预备步骤(i-1),其中所述荧光探针结合OBP。
优选地,所述荧光探针选自:1-N-苯基萘胺(NPN)、1-氨基蒽(1-AMA)、8-苯胺萘-1-磺酸(1,8-ANS)和SYPRO
优选地,检测所述荧光发射并进行量化,以便确定荧光的标准水平,对应于其中所述OBP与所述荧光探针结合的状态。
有利地,荧光探针以可逆的方式与OBP结合,使得当OBP在步骤(i)中暴露于配体时,所述候选配体可以驱逐荧光化合物并与所述OBP结合。
优选地,荧光化合物对OBP的亲和力范围从低于K
根据该实施方案,当配体驱逐荧光探针并与OBP结合时,检测到荧光的降低。
“荧光的降低”是指荧光与参考情况相比降低。这种降低可以比所述参考情况下的荧光标准水平少约-1%,优选-2.5%,优选-5%、-7.5%、-10%、-15%、-20%、-25%、-30%、-35%、-40%、-45%、-50%、-55%、-60%、-65%、-70%、-75%、-80%、-85%、-90%、-95%、-100%。
尤其是,如果在步骤(ii-2)中观察到荧光的偏移,则可以在步骤(iii)中得出结论称步骤(i-3)的候选化合物是配体。可替选地,如果在步骤(ii-2)中未观察到荧光的偏移,则可以在步骤(iii)中得出结论称步骤(i-3)的候选化合物不是配体。
因此,在优选的实施方案中,所述鉴定配体的方法至少包括以下步骤:
(i-1)将至少一种荧光探针暴露于OBP;
(i-2)测量荧光发射以确定荧光的标准水平,对应于OBP与所述荧光探针结合的状态;
(i-3)将至少一种产品暴露于步骤(i-1)的所述OBP;
(ii-1)测量荧光发射以确定荧光的第二水平;
(ii-2)将步骤(i-2)中获得的荧光的标准水平与步骤(ii-1)中获得的荧光的第二水平相比较;和
(iii)如果荧光的第二水平低于荧光的标准水平,则得出结论称候选化合物是配体。
优选地,为了在步骤(iii)中得出结论称候选化合物是配体,则在步骤(ii-2)中确定的荧光的第二水平比步骤(vi)中确定的荧光的标准水平低至少-10%,优选至少-15%,如例如-20%、-25%、-30%、-35%、-40%、-45%、-50%、-55%、-60%、-65%、-70%、-75%、-80%、-85%、-90%、-95%,并且更优选-100%。
本发明还涉及如上所定义的OBP或根据下述方法(参见第I节“产生OBP的方法”)产生的OBP用于鉴定所述OBP的配体(如气味化合物)的用途。上述步骤也适用于本文。
在另一方面,本发明涉及通过以上方法鉴定的配体,优选气味化合物。
该方法可以用于鉴定OBP的OBP结合谱。
C-试剂盒
本发明还涉及一种试剂盒,其在单个包装中的一个或多个容器中包含:
(i)如本发明所定义的OBP或通过下述方法(参见第I节“产生OBP的方法”)获得的OBP,或下述多核苷酸(参见第E节“分离的多核苷酸”),或下述载体(参见第F节“载体”),或下述重组细胞(参见第G节“宿主细胞”),和
(ii)一种或多种候选化合物,如气味化合物。
根据本发明的“容器”包括但不限于袋、盒、箱、瓶、任何类型或设计或材料的包装。
术语“单个包装”是指所述试剂盒的元件在一个或多个容器中物理结合或与一个或多个容器物理结合,并被视为制造、分发、销售或使用的单元。单个包装可以是物理结合的个体元件的容器,使得它们被视为制造、分发、销售或使用的单元。
在根据本发明该方面的具体实施方案中,试剂盒进一步包含用于传达信息或说明的装置,以帮助使用试剂盒的元件。
如本文所用,“用于传达信息或说明的装置”是适合于提供信息、说明、建议和/或保证书等的任何形式的试剂盒元件。这种装置可以包括含有信息的文档、数字存储介质、光存储介质、音频演示、可视显示。传达装置可以是显示的网站、手册、产品标签、包装说明书、广告、视觉展示等。
特别是,这种试剂盒可以用于鉴定气味化合物,如使用根据本发明的方法进行鉴定。
有利地,根据本发明的试剂盒可以进一步包含已知结合所述OBP的气味化合物,并将在所述用于鉴定气味化合物的方法中用作阳性对照。有利地,它还可以进一步包含已知不结合所述OBP的化合物,以在所述方法中用作阴性对照。
D-OBP的进一步方法和用途
本发明还公开了如上所述的多肽的其他方法和用途,尤其是如上所述的选自CfamOBP1、CfamOBP2、CfamOBP3、CfamOBP4及其片段的多肽。
上述多肽或其片段也可以用于筛选化合物的方法,所述化合物优选疏水化合物,最优选气味化合物。
因此,本发明还涉及一种检测组合物中气味化合物的存在的方法。所述方法至少包括以下步骤:
(i)将所述组合物暴露于如上所定义的OBP或根据下述方法产生的OBP,已知所述OBP与气味化合物结合;
(ii)检测所述OBP是否结合气味化合物;和
(iii)如果OBP结合气味化合物,则得出结论称所述组合物中存在气味化合物。
组合物可以是可以在任何种类的工业(包括农业)中制造或使用的任何组合物,特别是包含气味化合物的任何组合物,包括食品、宠物食品、宠物食品适口性增强剂或香水。
在步骤(ii)中,必须采用检测方法。检测方法的选择再次完全在技术人员能力范围内,例如荧光或量热法。第B节中描述的技术实施方案适用于本文。有利地,当组合物包含多种易受所述OBP结合的气味化合物时也可以使用鉴定方法,如质谱法。
在具体的实施方案中,如上所定义的OBP可以用于鉴定组合物中至少一种气味化合物的方法,所述方法包括以下步骤:
(i)将所述组合物暴露于如上所定义的OBP或根据下述方法产生的OBP;
(ii)检测所述OBP是否结合气味化合物;和
(iii)鉴定所述气味化合物。
如上所述,组合物可以是包含气味化合物的任何组合物,包括食品、宠物食品、宠物食品适口性增强剂或香水。
在步骤(ii)中,必须采用检测方法。检测方法的选择再次完全在技术人员能力范围内,例如荧光或量热法。第B节中描述的技术实施方案适用于本文。
在步骤(iii)中,可以采用任何鉴定方法,如质谱法。
上述所述多肽或其片段可以用作竞争性抑制剂,用作细胞嗅觉受体的激动剂或拮抗剂。
有利地,OBP与其特异性嗅觉受体结合的抑制剂可以用于抗癌策略。事实上,已知一些肿瘤(如乳腺肿瘤)是激素依赖性的,并且对类固醇敏感。已知类固醇由某些类型的脂质运载蛋白转运。因此,在本发明的保护范围内提供一种抑制剂,其防止类固醇与如上所述的多肽结合,特别是防止类固醇与肿瘤细胞嗅觉受体结合。
本发明还涉及一种药物组合物,其包含与如上所述的至少一种多肽连接的药物化合物和药学上可接受的载体。通过根据本发明的多肽的诱变来增加结合能力也在本发明的范围内。
在另一个实施方案中,如上所述的多肽或其片段可以用于制备单克隆或多克隆抗体。可以有利地根据由(
因此,本发明还涉及单克隆或多克隆抗体及其片段,其特征在于它们特异性结合如上所述的多肽。嵌合抗体、人源化抗体和单链抗体也是本发明的一部分。根据本发明的抗体片段优选为Fab或F(ab)2片段。
本发明还涉及对如上所述的多肽具有特异性的单克隆抗体,并且其能够抑制所述多肽和与所述多肽特异性结合的细胞嗅觉受体之间的相互作用。根据另一个实施方案,根据本发明的单克隆抗体能够抑制所述多肽与其疏水配体之间的相互作用,所述疏水配体优选与所述多肽结合的气味分子或信息素。
本发明的抗体可以用酶标记、荧光标记或放射性标记进行标记。此类标记抗体可以用于检测生物样品中的这些多肽。优选地,所述生物样品是液体,如血清、血液或人活组织样品。它们因此构成了根据本发明的多肽表达的分析手段,例如通过免疫荧光、金标记、酶免疫缀合物进行。
更一般地,本发明的抗体可以有利地用于必须观察如上所述的多肽表达的任何情况,更特别地用于免疫细胞化学、免疫组织化学或蛋白质印迹实验、ELISA和RIA技术中。因此,在本发明的范围内提供一种检测和/或测定生物样品中如上所述的多肽的方法,其特征在于它包括以下步骤:(i)使生物样品与根据本发明的抗体接触,然后(ii)揭示形成的抗原-抗体复合物。
本发明的范围中还包括一种检测和/或测定生物样品中如上所述的多肽的试剂盒,其特征在于它包括以下元件:(i)如上所述的单克隆或多克隆抗体;(ii)在合适的情况下,用于构成免疫反应的介质的试剂;(iii)用于检测由免疫反应产生的抗原-抗体复合物的试剂。该试剂盒对于蛋白质印迹实验和免疫沉淀的性能特别有用。
在又一个实施方案中,上述多肽或其片段可以用于控制气味物质挥发的方法。
所述方法的特征在于,它包括使所述气味物质与如上所述的多肽或其片段结合的第一步骤。
也可以使用附接至固体载体的如上所述的多肽使气味物质与所述载体结合,这种结合既可以是共价的也可以是非共价的,如有需要时例如通过吸附或通过亲和素-生物素型粘合剂。在这些条件下,可以获得带香水的(perfumed)载体,其保留气味时间更长,逐渐释放气味,并且可以用于化妆品领域以及一般清洁产品领域。所述载体可以是例如板型或球型载体。当然,如上所述的多肽将更特别地可用于香水和化妆品工业,其中多肽可以以液体混合物的形式使用,旨在控制组合物涂敷于人皮肤上之后气味的挥发。这使得可以延长香水的持久力或特别是将包含于身体除臭剂的组成成分中。术语“香水”在本文中以其通常含义使用,并且以一般方式包括香水制造业中已知的混合物,其基于酒精或为水性形式,并且特别是含有精油。如上所述的多肽也可以作为视黄醇转运和保护剂用于基于视黄醇的霜剂组合物中,用于化妆品应用,特别是预防、消除和治疗皮肤的皱纹和细纹,以及对抗皮肤和/或皮下松垂。
在涉及集体卫生的应用中,根据本发明的方法可以用于目标为对例如宠物店和马厩等场所进行除臭的装置。这种装置还以可用于对进入空调单元的气流进行除臭;这种装置将在受污染的地理区域非常有用。
在另一个实施方案中,如上所述的多肽或其片段可以用于溶解亲脂分子的方法,其特征在于它包括使所述亲脂分子与如上所述的多肽结合。
事实上,由于如上所述的OBP可以结合亲脂分子,从而溶解所述亲脂分子。因此,如上所述的多肽或其片段可以与膳食脂肪酸组合用作食品添加剂。
此外,如上所述的多肽可能参与脂肪酸的转运和允许检测食物定量配给的脂肪酸负荷的生物学机制,特别是在口服水平上。因此,本发明还涉及如上所述的多肽与脂肪酸联合的用途,以减少脂肪酸的消耗,特别是在高脂血症或肥胖症中。如上所述的多肽可以因此用于治疗高脂血症和肥胖症。事实上,这些蛋白质参与检测食物摄入中的脂肪酸含量(Gilbertson 1998),这些蛋白质的过量应当导致引诱生理系统检测食物定量配给的脂肪负荷。因此,低脂肪但补充有装载脂肪酸的如上所定义的OBP的食物部分将被错误地鉴定为高脂肪。
在又一个实施方案中,如上所述的多肽或其片段可以用于预防性和治疗性疗法。特别是,使用根据本发明的抗体、引物、探针检测生物样品中不存在该类型的蛋白质可以是诊断嗅觉缺失症的一个要素。
在另一个实施方案中,如上所述的多肽或其片段也可以用于药物组合物中,特别是以便为某些活性药物提供载体(vectorize)。事实上,哺乳动物使用OBP在生物液体内转运疏水分子。它们甚至似乎是异源物质(包括气味物质)的体内天然转运体。例如,异源物质的实验超载在雄性大鼠的肾单位近端旁路小管(TCP)处产生肿瘤(S J Borghoff,B GShort等人1990)。事实上,仅在雄性大鼠中产生的MUP蛋白被TCP细胞重吸收;溶酶体降解后,MUP蛋白释放它们携带的异源物质。这些积聚在这些细胞中,并通过诱变将其引导至肿瘤途径。脂质运载蛋白因此似乎是在其杯状部(calyx)中捕捉用作药物的分子的理想结构,从而避免其一般分布。因此,(Beste,Schmidt等人1999)和申请WO 99 16873描述了一种诱变和筛选策略,以鉴定对给定配体具有最佳亲和力的脂质运载蛋白的变体。因此可以产生具有高度特异性的药物笼(drug cage),所述笼对应于如上所述的OBP的结合口袋。
本发明因此涉及如上所述的多肽作为药物化合物靶向剂。“靶向剂”是指如上所述的多肽能够向某些靶组织或细胞转运并释放它们结合的配体,所述靶组织或细胞在其表面上具有所述多肽的受体。因此,本发明涉及如上所述的多肽的结合口袋内的药物转运,以及通过如上所述的多肽与特定嗅觉受体结合的能力来靶向细胞。
开发融合蛋白或嵌合蛋白也在本发明的范围内,所述融合蛋白或嵌合蛋白包含如上所述的多肽的结合口袋,其与允许特定细胞导向的蛋白质结合,所述特定细胞导向一般不同于如上所定义的OBP一般所导向的细胞。本发明因此涉及一种多肽,其特征在于所述多肽与允许特定细胞导向的蛋白质以融合蛋白的形式表达。
在允许特定细胞导向的蛋白质中,白细胞介素、细胞因子、淋巴因子、趋化因子、生长因子、激素、单克隆或多克隆抗体是优选的。白细胞介素、细胞因子和淋巴因子优选选自白细胞介素Il-1至Il-20、干扰素a-IFN、ss-IFN和y-IFN。生长因子优选为集落刺激因子G-CSF、GM-CSF和促红细胞生成素。激素优选选自类固醇激素。
根据另一个实施方案,用作药物化合物靶向剂的如上所述的多肽与允许特定细胞导向的分子结合。此类分子可以选自类固醇、白细胞介素、细胞因子、淋巴因子、干扰素、生长因子、激素和抗体。优选地,所述分子为类固醇。如上所述的多肽与所述分子之间的结合是通过非共价键或共价键实现的,非共价键使用例如亲和素-生物素系统实现,共价键使用例如化学桥接剂实现。
在由如上所述的多肽转运并靶向的药物化合物中有药物,并且特别是抗癌剂。抗癌剂选自抗增殖剂、抗肿瘤剂或细胞毒性剂,并用于阻止癌症的发展并诱导肿瘤肿块的消退和/或消除。这些抗癌剂优选为放射性同位素,甚至更优选为γ放射性同位素,如碘l3l、钇90.1'Or199、钯'00、铜67、铋2l7和锑2ll。β放射性同位素和α放射性同位素也可以用于疗法。与如上所述的多肽连接的非同位素抗癌剂是多种多样的。它们包括:(i)抗代谢物,如抗叶酸剂、甲氨蝶呤,(ii)嘌呤和嘧啶类似物(巯嘌呤、氟尿嘧啶、5-氮杂胞苷),(iii)抗生素,(iv)凝集素(蓖麻毒素、相思豆毒素)和(iv)细菌毒素(白喉毒素);所述毒素优选选自假单胞菌外毒素A、白喉毒素、霍乱毒素、炭疽芽孢杆菌(Bacillus anthrox)毒素、百日咳毒素、来自志贺氏菌的志贺毒素、志贺毒素样毒素、大肠杆菌(Escherichia coli)毒素、大肠杆菌素A(colicin A)、d-内毒素、嗜血杆菌A血凝素。
本发明还涉及如上所述的多肽作为药物化合物转运体。“转运体”是指如上所述的多肽能够在生物体中转运药物化合物,而不在生物体中的特权位置释放所述化合物。这种多肽构成将所述药物化合物递送至生物体中的装置。
本发明还涉及根据本发明的药物组合物,其特征在于所述多肽构成将所述药物化合物递送至体内的延迟形式。
E-
编码OBP的多核苷酸
还描述了分离的多核苷酸,其编码至少一种OBP,优选一种犬OBP,更特别地为上面提及的那些。
“多核苷酸”、“核酸”或“核酸分子”是指任何长度的脱氧核糖核酸的聚合物(DNA)或多聚脱氧核糖核苷酸,包括但不限于互补DNA或cDNA、基因组DNA、质粒、载体、病毒基因组、分离的DNA、探针、引物及其任何混合物;或任何长度的核糖核酸的聚合物(RNA)或多聚核糖核苷酸,特别是包括信使RNA或mRNA、反义RNA;或混合的多聚核糖-多聚脱氧核糖核苷酸。它们包括单链或双链、直链或环形、天然或合成多核苷酸。此外,多核苷酸可以包括非天然核苷酸,并且可以被非核苷酸组分中断。
术语“核酸”、“核酸分子”、“多核苷酸”和“核苷酸序列”在本文中可互换使用。
本文描述了一种多核苷酸,其编码至少一种以上提及的分离的多肽(即,如第A节(分离的蛋白质和多肽作为OBP的用途)中所述的OBP及其功能变体)。
还描述了一种分离的多核苷酸,其至少包含选自Seq ID No 9、Seq ID No 10、SeqID No 11和Seq ID No 12的序列。在实施方案中,分离的多核苷酸至少具有与选自Seq IDNo 9、Seq ID No 10、Seq ID No 11和Seq ID No 12的序列具有至少70%同一性的核苷酸序列。更优选地,分离的多核苷酸至少包含与选自Seq ID No 9、Seq ID No 10、Seq ID No11和Seq ID No 12的序列具有至少以下同一性的核苷酸序列:至少75%的同一性,更优选至少80%的同一性,更优选至少85%的同一性,更优选至少90%的同一性,仍更优选至少91%的同一性,仍更优选至少92%的同一性,仍更优选至少93%的同一性,仍更优选至少94%的同一性,仍更优选至少95%的同一性,仍更优选至少96%的同一性,仍更优选至少97%的同一性,仍更优选至少98%的同一性,仍更优选至少99%的同一性,并且仍更优选100%的同一性,以及其互补序列。
“同一性”还指两个多核苷酸之间、两个核苷酸序列之间或两个核酸分子之间的精确序列匹配。两个序列之间的“同一性百分比”或“ID%”是两个序列共有的相同残基数量的函数,考虑为最佳比对而必须引入的间隙数和每个间隙的长度。确定核苷酸序列之间同一性的程序可获自专业数据库(例如Genbank,Wisconsin序列分析包,BESTFIT、FASTA和GAP程序)。例如,如此处所用,“至少80%的序列同一性”表示80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%。
在一个实施方案中,分离的多核苷酸由选自Seq ID No 9、Seq ID No 10、Seq IDNo 11和Seq ID No 12的序列组成。
在一些具体的实施方案中,分离的多核苷酸至少包含选自以下的序列:Seq ID No17、Seq ID No 18、Seq ID No 19、Seq ID No 20、Seq ID No 21、Seq ID No 22、Seq ID No23、Seq ID No 24、Seq ID No 25、Seq ID No 26、Seq ID No 29、Seq ID No 30、Seq ID No31、Seq ID No 32、Seq ID No 33、Seq ID No 34和Seq ID No 36。
启动子和终止子
根据一些实施方案,分离的多核苷酸进一步包含至少一个转录促进序列。“转录启动序列”、“转录启动子”或“启动子”是指位于基因附近并对于将DNA转录为RNA至关重要的核苷酸序列。启动子允许在开始RNA合成之前结合RNA聚合酶。启动序列一般位于转录起始位点的上游。有许多不同的转录启动序列,技术人员知晓在给定的环境中如何确定哪种启动子最合适。
根据一些实施方案,分离的多核苷酸进一步包含至少一个转录终止子。“转录终止子”或“终止子”是指标志着基因通过RNA聚合酶转录为信使RNA的终点的核苷酸序列。存在不同的转录终止子序列,技术人员知晓在给定的环境中如何确定哪种启动子最合适。
根据优选的实施方案,分离的多核苷酸至少包含如上所定义的分离的多核苷酸(在段落“编码OBP的多核苷酸”中),优选至少包含编码选自CfamOBP1、CfamOBP2、CfamOBP3、CfamOBP4及其功能变体的多肽或蛋白质的核苷酸序列,并且进一步包含转录启动序列和转录终止子。
根据另一个优选的实施方案,分离的多核苷酸至少包含编码与选自Seq ID No3、Seq ID No 2、Seq ID No 1和Seq ID No 4的序列具有至少70%同一性的多肽的核苷酸序列,并且进一步包含转录启动序列和转录终止子。
根据又一个优选的实施方案,分离的多核苷酸至少包含与选自Seq ID No 9、SeqID No 10、Seq ID No 11和Seq ID No 12的序列具有至少70%同一性的核苷酸序列,并且进一步包含转录启动序列和转录终止子。
标签
根据一些实施方案,分离的多核苷酸进一步包含编码至少一个标签的核酸序列。编码所述标签的序列是众多的并且是本领域公知的,并且可以位于分离的多核苷酸的任一端(5'端和/或3'端)。
多核苷酸的类型
在实施方案中,多核苷酸分离自哺乳动物细胞,特别是分离自犬科动物细胞,并且优选分离自狗细胞。
在实施方案中,多核苷酸分离自包含所述多核苷酸的载体或宿主细胞,所述载体或宿主细胞如以下第G节和第F节“宿主细胞”或“载体”中所定义和描述。
分离的多核苷酸可以通过本领域技术人员公知的核酸合成技术在体外合成,或者可以由他或她的常识毫不费力地确定。
根据产生方法,分离的核酸分子是重组的。
表1:Seq ID对应总结
/>
F-
“载体”是指一种载体(vehicle),优选核酸分子或病毒颗粒,其含有使得能够在宿主细胞或生物体中施用、传播和/或表达一个或多个核酸分子的必要元件。
功能上,该术语包括用于维持的载体(克隆载体)、用于在各种宿主细胞或生物体中表达的载体(表达载体)、染色体外载体(例如,多拷贝质粒)或整合载体(例如,设计用于整合至宿主细胞的基因组中并在宿主细胞复制时产生其中所含的核酸分子的额外拷贝)。该术语还包括穿梭载体(例如,在原核和/或真核宿主中操作)和转移载体(例如,用于将核酸分子转移至宿主细胞的基因组中)。
结构上,载体可以是天然的、合成的,或天然和人工遗传元件的组合。
如本文所用的术语“载体”将广义地理解为包括质粒和病毒载体。
如本文所用,“质粒”是指可复制的DNA构建体。通常,质粒载体含有选择标记基因,其允许在对应于选择标记的化合物存在的情况下将携带质粒的宿主细胞鉴定和/或选择为阳性或阴性。本领域已知多种阳性选择标记基因和阴性选择标记基因。例如,抗生素抗性基因可以用作阳性选择标记基因,以在相应抗生素存在的情况下选择宿主细胞。
如本文所用,术语“病毒载体”是指包含病毒基因组的至少一个元件,并可以包装在病毒颗粒中的核酸载体。病毒载体可以具有复制能力或复制选择性(例如,设计为在特定宿主细胞中更好或选择性地复制),或者可以遗传失活以致复制缺陷或复制缺乏。
有利地,所述载体是质粒。
适合于本上下文的载体包括但不限于:用于在原核宿主细胞如细菌(例如大肠杆菌、芽孢杆菌或假单胞菌属的细菌)中表达的噬菌体、质粒或粘粒载体;用于在酵母(例如酿酒酵母(Saccharomyces cerevisiae)、粟酒裂殖酵母(Schyzosaccharomyces pombe)、毕赤酵母(Pichia pastoris))中表达的载体;用于在昆虫细胞系统(例如Sf 9细胞)中表达的杆状病毒载体;用于在植物细胞系统(例如Ti质粒、花椰菜花叶病毒CaMV、烟草花叶病毒TMV)中表达的病毒载体和质粒载体;以及用于在细胞或高等真核生物中表达的病毒载体和质粒载体。
“细菌”是指存在于给定介质中的微观原核生物体。本文使用的优选细菌属于大肠杆菌物种。
“酵母”是指微观真核生物体,其中一些物种能够引起有机物的发酵。本文使用的优选酵母属于毕赤酵母属。
适合于本上下文的载体可以是整合型或复制型。整合型载体没有称为“复制起点”的序列,因此必须直接整合至宿主细胞的基因组中才能表达。可以使用业内公知的专用遗传工具来完成该整合。例如,可以通过同源重组或经由CRE-LOX重组系统来进行该整合。复制载体具有自主复制起点。这些载体因此独立于宿主细胞基因组进行复制。因此,与整合载体不同,复制载体不需要整合至宿主细胞基因组中。
这些载体一般可商业获得(例如,获自供应商如Invitrogen、Promega等),可获自保藏机构如美国模式培养物保藏所(ATCC,Rockville,Md.),或者已成为众多出版物的主题,所述出版物描述其序列、结构和产生方法,使得本领域人员可以毫无困难地应用它们。
适合的细菌质粒载体的代表性例子包括pQE-30、pQE-31、pET载体。
适合的酵母质粒载体的代表性例子包括pPIC9和pPIC3.5K。
G-
本文还描述了一种重组细胞,其表达(优选过表达)如上所述的OBP。
“重组细胞”或“宿主细胞”是指含有至少一个外源核酸分子的细胞。根据本发明,重组细胞可以是原核细胞,如细菌,或真核细胞,如酵母、昆虫细胞或哺乳动物细胞。有利地,重组细胞表达(优选过表达)至少一种气味结合蛋白或其功能变体。
因此,重组细胞不是天然存在的细胞,而是通过遗传操作技术获得的分子生物学工具。
“外源”遗传物质或序列是指所述遗传物质或序列起源于另一生物体,其可以属于或不属于同一细胞系。
“过表达”是指与参考情况相比,基因或蛋白质(但尤其是OBP基因或蛋白)的细胞表达增加。这种过表达可以比所述参考情况下的表达标准水平高约+1%,优选+2.5%,优选+5%、+7.5%、+10%、+15%、+20%、+25%、+30%、+35%、+40%、+45%、+50%、+55%、+60%、+65%、+70%、+75%、+80%、+85%、+90%、+95%、+100%。本领域普通技术人员知晓合适的方法和技术以评估与标准表达水平相比增加的表达水平。“过表达”还指通常不表达基因或蛋白质(特别是OBP基因或蛋白)的细胞现在表达所述基因或蛋白质。
根据各种实施方案,所述宿主细胞可以是原核细胞,或真核细胞,如酵母细胞,或另一真核细胞,如昆虫、植物或哺乳动物细胞(例如,人细胞或非人细胞,优选非人细胞)。有利地,宿主细胞是细菌,尤其属于大肠杆菌物种,或是酵母,尤其是毕赤酵母属的酵母。
重组细胞优选包含如上所定义的至少一种多核苷酸或至少一种载体。优选地,用如上所定义的载体稳定转化所述重组细胞。
“转化的”或“转化”是指将外源遗传物质引入原核细胞中,特别是本文使用的那些原核细胞。为了简化起见,在本说明书中,术语“转染的”或“转染”和“转化的”或“转化”可互换使用。
当外源遗传物质稳定地引入重组细胞或宿主细胞中,使得所述外源遗传物质可以持续表达,并且也可以在所述细胞的后代中表达时,所述细胞是“稳定转化的”。本领域存在并且已知获得稳定转化的数种方法。尤其是,可以通过整合载体将外源遗传物质直接整合至宿主细胞基因组中。可替选地,可以将外源物质整合至将独立于宿主细胞基因组进行复制的复制载体中。优选地,使用选择标记并与外源遗传物质一起转染,以保持对转化细胞的选择压力并避免外源遗传物质的丢失。
因此,进一步描述了一种用多核苷酸的至少一个拷贝稳定转化的宿主细胞,所述多核苷酸至少编码如上所提及的多肽(即,如第A节“分离的蛋白质和多肽作为OBP的用途”中所述的OBP及其功能变体),特别是至少编码选自CfamOBP1、CfamOBP2、CfamOBP3、CfamOBP4及其功能变体的多肽。
优选地,用如上所定义的多核苷酸(在段落“编码OBP的多核苷酸”中)的至少一个拷贝稳定转化宿主细胞,所述多核苷酸特别是至少具有选自Seq ID No 9、Seq ID No 10、Seq ID No 11和Seq ID No 12的序列的多核苷酸。
在一些实施方案中,用多核苷酸的至少一个拷贝稳定转化宿主细胞,所述多核苷酸至少具有选自以下的序列:Seq ID No 17、Seq ID No 18、Seq ID No 19、Seq ID No 20、Seq ID No 21、Seq ID No 22、Seq ID No 23、Seq ID No 24、Seq ID No 25、Seq ID No26、Seq ID No 29、Seq ID No 30、Seq ID No 31、Seq ID No 32、Seq ID No 33、Seq ID No34和Seq ID No 36。
H-获得表达OBP的重组细胞的方法
本文还描述了一种获得如上所述的重组细胞的方法,所述重组细胞表达(优选过表达OBP)。
在优选的实施方案中,所述获得重组细胞的方法至少包括以下步骤:
(i)提供如上所定义的多核苷酸;
(ii)在能够在细胞中表达步骤(i)中提供的所述多核苷酸的载体中克隆所述分子;
(iii)在合适的条件下使所述细胞和在步骤(ii)中获得的所述载体接触,使得前者被所述载体转化,优选稳定转化,并且使得所述细胞表达所述多核苷酸,所述细胞因此是重组的。
步骤(i)的所述多核苷酸至少编码如上所提及的多肽(即,如第A节“分离的蛋白质和多肽作为OBP的用途”中所述的OBP及其功能变体),特别是至少编码选自CfamOBP1、CfamOBP2、CfamOBP3、CfamOBP4及其功能变体的多肽。
在实施方案中,步骤(i)的所述多核苷酸编码多肽,所述多肽至少具有选自Seq IDNo 13、Seq ID No 14、Seq ID No 15、Seq ID No 16、Seq ID No 27、Seq ID No 35和SeqID No 28的氨基酸序列。
在又一个优选的实施方案中,所述多核苷酸如上所定义(在段落“编码OBP的多核苷酸”中),特别是所述多核苷酸具有选自Seq ID No 9、Seq ID No 10、Seq ID No 11和SeqID No 12的序列。
在实施方案中,步骤(i)的所述多核苷酸至少具有选自以下的序列:Seq ID No17、Seq ID No 18、Seq ID No 19、Seq ID No 20、Seq ID No 21、Seq ID No 22、Seq ID No23、Seq ID No 24、Seq ID No 25、Seq ID No 26、Seq ID No 29、Seq ID No 30、Seq ID No31、Seq ID No 32、Seq ID No 33、Seq ID No 34和Seq ID No 36。优选地,步骤(i)中的所述多核苷酸进一步包含如上所定义的启动序列和转录终止子。
根据实施方案,所述多核苷酸在步骤(iii)中被直接整合至宿主细胞基因组中。在可替选的实施方案中,多核苷酸被整合至独立于宿主细胞基因组进行复制的复制载体中。
根据各种实施方案并且如上所述,所述宿主细胞可以是原核细胞,或真核细胞,如低等真核细胞,尤其是酵母细胞,或另一真核细胞,如昆虫、植物或哺乳动物细胞(例如,人细胞或非人细胞,优选非人细胞)。优选地,所述宿主细胞是细菌,尤其是大肠杆菌菌株。
I-产生OBP的方法
本说明书还涉及产生OBP的方法,尤其是如上所定义的OBP。
在优选的实施方案中,所述产生OBP的方法至少包括以下步骤:
(i)提供如上所定义的重组细胞或通过进行上述方法来获得重组细胞;
(ii)在适合的条件下,在合适的培养基中培养所述重组细胞以产生OBP;
(iii)在所述重组细胞或在步骤(ii)之后获得的培养基中回收所述OBP,并任选地纯化所述OBP。
有利地,重组细胞如上所述。特别是,它优选为细菌细胞,尤其是属于大肠杆菌物种。根据其他实施方案,所述重组细胞是酵母,尤其是毕赤酵母属的酵母。
基于他或她的常识,技术人员将能够根据步骤(ii)鉴定适合于产生OBP的培养条件。特别是,他或她将知晓如何调节温度、pH、O
根据信号肽的存在或不存在,所述OBP将在细胞内或细胞外(在培养基中)产生。在一些实施方案中,当使用细菌时,它在周质中产生。优选地,通过上述方法产生的OBP被移植有标签,其有助于步骤(iii)的任选蛋白质纯化。蛋白质纯化的方法在本领域是公知的;它们尤其包括亲和色谱法、空间排阻色谱法、离子交换色谱法。
以下实施例旨在说明本发明,没有任何限制。
实施例
实施例1:材料和方法
1.1.鼻粘液样品的采集
兽医在全身麻醉下从六只狗采集了嗅粘液。研究的品种是美国斯塔福梗(American Staff,1只雄性、1只雌性)、比利时牧羊犬(Belgian Shepherd,2只雄性、1只雌性)和塞特种猎犬(Setter,1只雄性)。
根据方案,出于戒断以外的其他目的在麻醉期间采集样品,并且未对动物造成不适。
在两个鼻孔中,用浸有生理浆液的棉花采集嗅粘液。
样品采集是在Diana Petfood的伦理委员会的批准下进行的。
1.2.通过LC/MS进行嗅粘液分析
使用十二烷基硫酸钠聚丙烯酰胺凝胶电泳(12%丙烯酰胺)(SDS-PAGE)分离蛋白质,并使用胰蛋白酶消化。使用UltiMate 300快速分离液相色谱(RSLC)Nano System(美国Thermo Fisher Scientific)完成蛋白质消化物的分离。在商用C18反相色谱柱(75μm×250mm,2μm颗粒,PepMap100 RSLC色谱柱,Thermo Fisher Scientific(美国),在35℃)上自动完成肽分级分离。使用含有98% H
1.3.菌株和材料
从Uniprot数据库(https://www.uniprot.org/)提取了四个CfamOBP的编码序列。识别号为O18873(CfamOBP1)、O18874(CfamOBP2)、H2B3G5(CfamOBP3)和E2R1I1(CfamOBP4)。CfamOBP编码序列对于在大肠杆菌中表达进行了优化,由Genewiz(德国)合成,并克隆至来自Qiagen(荷兰)的质粒pQE31中。通过CfamOBP3上的定点诱变由Genewiz(德国)合成编码Seq ID No 35突变体的质粒。将编码序列插入pQE31质粒中所含的BamHI和HindIII限制性位点之间。然后通过热激用质粒转化大肠杆菌M15。
1.4.蛋白质产生和纯化
LB培养基用于产生CfamOBP1及其变体(Seq ID No 14)和CfamOBP3及其变体(SeqID No 35),而Terrific Broth(TB)培养基用于产生CfamOBP2及其变体(Seq ID No 15)和CfamOBP4。除了CfamOBP1在29℃产生以外,所有蛋白质在37℃产生。所有培养均在0.1mg/mL氨苄西林和0.025mg/mL卡那霉素存在的情况下完成。当DO
然后在4次连续浴中透析蛋白质,所述浴含有pH 7.5的100mM磷酸盐缓冲液,前两次加入5%乙腈中。
然后通过紫外光谱法对纯化蛋白质浓度进行定量,对于CfamOBP1、CfamOBP2、CfamOBP3和CfamOBP4分别使用的280nm处的摩尔消光系数为13075M
1.5.重组OBP表征
使用Mini-Protean II系统(法国Bio-Rad)进行考马斯蓝染色的SDS-PAGE。Precision Plus Protein Dual Xtra Standards(法国Bio-rad)在凝胶上用作分子质量的参考。
1.6荧光结合测定
在20℃,在配备磁力搅拌器和Peltier控制温度单元的分光荧光计(Cary-Eclipse(美国Agilent))上进行结合实验。荧光探针:1-N-苯基萘胺(NPN)(美国Sigma)、8-苯胺萘-1-磺酸(1,8-ANS)(美国Sigma)和SYPRO
在比色皿中进行配体竞争性结合实验,所述比色皿在pH 7.5的50mM磷酸钾缓冲液中含有2μM OBP,对于CfamOBP1及其变体(Seq ID No 14)和CfamOBP3为10μM荧光探针,对于CfamOBP2及其变体(Seq ID No 15)为4μM荧光探针,并且对于CfamOBP4为1.25×荧光探针。
在100% MeOH中制备气味物质,并加入等分试样至终浓度为0.5-20μM。实验一式三份进行。然后使用SigmaPlot 12.5软件追踪并分析获得的数据。
1.7等温滴定量热法
在25℃使用等温滴定微量热仪VP-ITC系统(英国Malvern,Malvern Instruments)进行滴定实验。将100mM气味物质的MeOH溶液在pH 7.5的100mM磷酸钾缓冲液中稀释至250μM,并加载至注射器中。在磷酸盐缓冲液中制备25μM的蛋白质溶液,并在实验前直接脱气并注入测量单元中。将10μL配体溶液注入含有蛋白质的单元中,时间间隔为210s,共注入25次。使用Origin 5.0程序(英国Malvern,Malvern Instruments)对实验数据进行分析,并通过一个结合位点的模型进行拟合。通过该拟合确定结合参数如化学计量(n)和缔合常数(KA)。
实施例2:结果
2.1.狗气味结合蛋白的鉴定
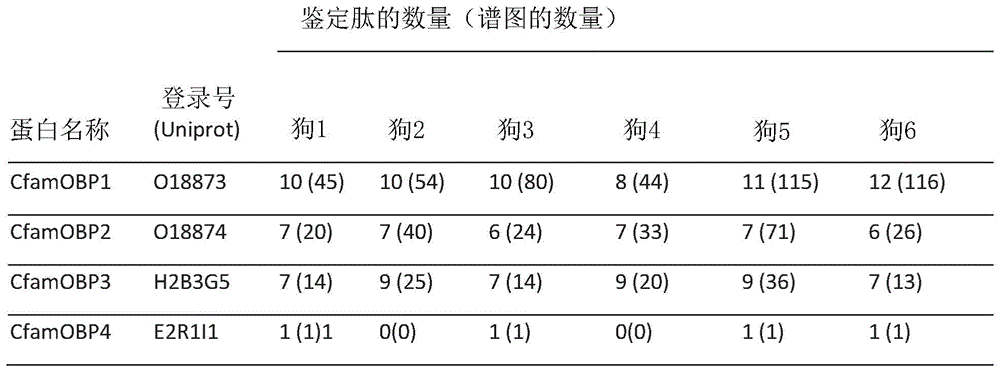
在GC/MS上分析了来自六只狗的鼻粘液样品,允许鉴定出总共2245种不同的蛋白质,每只狗分别计为1195、1184、1537、1235、1234和1285种蛋白质。在鉴定的蛋白质中,有四种在Uniprot数据库中被引用为脂质运载蛋白。如所预期的,这些蛋白质通常很小(160-180个氨基酸残基),并且含有脂质运载蛋白典型的GxW基序(Flower 1996,Pelosi 1998)。基于我们的生物化学表征,鉴定出的脂质运载蛋白中的四种蛋白质已被重新命名为CfamOBP1(O18873)、CfamOBP2(O18874)和CfamOBP3(H2B3G5)、CfamOBP4(E2R1I1)(图1)。已使用Signal P 5.0(http://www.cbs.dtu.dk/services/SignalP/)提取并分析了它们的氨基酸序列,以预测对应于肽信号的序列(图2)。已由先前解析的CfamOBP2和CfamOBP3结构预测了二级结构。关于CfamOBP1和CfamOBP4,已使用Jpred4软件(http://www.compbio.dundee.ac.uk/jpred/)预测了二级结构。四种蛋白质呈现出先前描述的脂质运载蛋白中的八个特征性β-片层。
2.2.狗气味结合蛋白的产生和纯化
在用相应质粒转化、在29或37℃培养并诱导后,CfamOBP在大肠杆菌M15菌株中异源表达。然后使用固定化金属亲和色谱法和咪唑线性梯度纯化重组蛋白。对于CfamOBP1、CfamOBP3及其Seq ID No 35的变体,每升细菌培养物平均获得10mg纯化蛋白。对于CfamOBP2及其变体(Seq ID No 15),每升细菌培养物获得较高量的30mg纯化蛋白。Seq IDNo 14的变体和CfamOBP4以较低的水平产生,每升细菌培养物含有4mg纯化蛋白。四种OBP的SDS-PAGE分析(图3)显示单个条带,对于CfamOBP1、CfamOBP2、CfamOBP3和CfamOBP4分别对应于19、20、21和19kDa的估计质量。
2.3.荧光结合研究
在蛋白质存在的情况下,探针的最大发射偏移至较小的波长和较高的强度水平,这将随着加入OBP配体而降低。
对于每种蛋白质,确定了显示最高发射荧光强度的荧光探针。因此,选择了三种不同探针:1,8-ANS用于CfamOBP1和Seq ID No 14的变体,NPN用于CfamOBP2、CfamOBP3和SeqID No 15的变体,并且SYPRO橙用于CfamOBP4。对于CfamOBP1/Seq ID No 14的变体、CfamOBP2/Seq ID No 15的变体、CfamOBP3和CfamOBP4,分别在470nm、400nm、420nm和600nm处记录了最大荧光强度。
测试的气味物质3,7-二甲基辛醇(DMO)先前用于对狗鼻粘液进行的一项先前研究(D′Auria,Staiano等人2006),而2-异丁基-3-甲氧基吡嗪(IBMP)是先前描述的OBP上的气味剂(Briand,Eloit等人2002,Lobel,Strotmann等人2001,Pelosi,Baldaccini等人1982)。
有趣地,香茅醛、DMO和IBMP分别能够置换针对CfamOBP1/Seq ID No 14的变体、CfamOBP2/Seq ID No 15和CfamOBP3的探针(图4和图5)。
这些结果支持在嗅粘液中鉴定的这些不同脂质运载蛋白作为OBP的功能。
2.4.等温滴定量热法
CfamOBP3具有在结合空腔入口处具有组氨酸残基而不是保守的酪氨酸残基的特殊性,使用CfamOBP3的突变体(Seq ID No 35)分析了该残基替换对OBP结合特性的影响。使用ITC用先前鉴定的配体IBMP研究了结合特性。Seq ID No 35的突变体表现出对IBMP的亲和力大幅增加,其Ka值增加了八倍。这一结果支持组氨酸残基在CfamOBP3的结合特性中的关键作用。
参考书目
Beste,G.,et al.(1999).″Small antibody-like proteins with prescribedligand specificities derived from the lipocalin fold.″
Briand,L.,et al.(2002).″Evidence of an odorant-binding protein in thehuman olfactory mucus:location,structural characterization,and odorant-binding properties.″
Brule,M.,et al.(2020).″Bacterial expression and purification ofvertebrate odorant-binding proteins.″
D′Auria,S.,et al.(2006).″The odorant-binding protein from Canisfamiliaris:purification,characterization and new perspectives in biohazardassessment.″
Flower,D.R.(1996).″The lipocalin protein family:structure andfunction.″
Gilbertson,T.A.(1998).″Gustatory mechanisms for the detection offat.″
G.and C.Milstein(1975).″Continuous cultures of fused cellssecreting antibody of predefined specificity.″
Lobel,D.,et al.(2001).″ldentification of a third rat odorant-bindingprotein(OBP3).″
Mastrogiacomo,R.,et al.(2014).″An odorant-binding protein isabundantly expressed in the nose and in the seminal fluid of the rabbit.″
Pelosi,P.(1998).″Odorant-binding proteins:structural aspects.″
Pelosi,P.,et al.(1982).″Identification of a specific olfactoryreceptor for 2isobutyl-3-methoxypyrazine.″
Ramoni,R.,et al.(2007).″The protein scaffold of the lipocalinodorant-binding protein is suitable for the design of new biosensors for thedetection of explosive components.″
S J Borghoff,et al.(1990).″Biochemical Mechanisms and Patho biologyof α2u-Globulin Nephropathy.″
Tegoni,M.,et al.(2004).″Structural aspects of sexual attraction andchemical communication in insects.″
Zhu,J.,et al.(2017).″Reverse chemical ecology:Olfactory proteins fromthe giant panda and their interactions with putative pheromones and bamboovolatiles.″
序列表
<110>特种宠物食品公司
法国国家农业食品与环境研究院
勃艮第大学
国家科学研究中心
国家农业科学食品与环境高等研究所
<120>新型犬气味结合蛋白
<130>B380982PCT D40594 - LUL
<150>EP 21305218.6
<151>2021-02-23
<160>36
<170>PatentIn version 3.5
<210>1
<211>174
<212>PRT
<213>人工序列
<220>
<223>CfamOBP1
<400>1
Met Lys Thr Leu Leu Leu Thr Ile Gly Phe Ser Leu Ile Ala Ile Leu
1 5 1015
Gln Ala Gln Asp Thr Pro Ala Leu Gly Lys Asp Thr Val Ala Val Ser
202530
Gly Lys Trp Tyr Leu Lys Ala Met Thr Ala Asp Gln Glu Val Pro Glu
354045
Lys Pro Asp Ser Val Thr Pro Met Ile Leu Lys Ala Gln Lys Gly Gly
505560
Asn Leu Glu Ala Lys Ile Thr Met Leu Thr Asn Gly Gln Cys Gln Asn
65707580
Ile Thr Val Val Leu His Lys Thr Ser Glu Pro Gly Lys Tyr Thr Ala
859095
Tyr Glu Gly Gln Arg Val Val Phe Ile Gln Pro Ser Pro Val Arg Asp
100 105 110
His Tyr Ile Leu Tyr Cys Glu Gly Glu Leu His Gly Arg Gln Ile Arg
115 120 125
Met Ala Lys Leu Leu Gly Arg Asp Pro Glu Gln Ser Gln Glu Ala Leu
130 135 140
Glu Asp Phe Arg Glu Phe Ser Arg Ala Lys Gly Leu Asn Gln Glu Ile
145 150 155 160
Leu Glu Leu Ala Gln Ser Glu Thr Cys Ser Pro Gly Gly Gln
165 170
<210>2
<211>180
<212>PRT
<213>人工序列
<220>
<223>CfamOBP2
<400>2
Met Gln Leu Leu Leu Leu Thr Val Gly Leu Ala Leu Ile Cys Gly Leu
1 5 1015
Gln Ala Gln Glu Gly Asn His Glu Glu Pro Gln Gly Gly Leu Glu Glu
202530
Leu Ser Gly Arg Trp His Ser Val Ala Leu Ala Ser Asn Lys Ser Asp
354045
Leu Ile Lys Pro Trp Gly His Phe Arg Val Phe Ile His Ser Met Ser
505560
Ala Lys Asp Gly Asn Leu His Gly Asp Ile Leu Ile Pro Gln Asp Gly
65707580
Gln Cys Glu Lys Val Ser Leu Thr Ala Phe Lys Thr Ala Thr Ser Asn
859095
Lys Phe Asp Leu Glu Tyr Trp Gly His Asn Asp Leu Tyr Leu Ala Glu
100 105 110
Val Asp Pro Lys Ser Tyr Leu Ile Leu Tyr Met Ile Asn Gln Tyr Asn
115 120 125
Asp Asp Thr Ser Leu Val Ala His Leu Met Val Arg Asp Leu Ser Arg
130 135 140
Gln Gln Asp Phe Leu Pro Ala Phe Glu Ser Val Cys Glu Asp Ile Gly
145 150 155 160
Leu His Lys Asp Gln Ile Val Val Leu Ser Asp Asp Asp Arg Cys Gln
165 170 175
Gly Ser Arg Asp
180
<210>3
<211>190
<212>PRT
<213>人工序列
<220>
<223>CfamOBP3
<400>3
Met Lys Leu Leu Leu Leu Cys Leu Gly Leu Ile Leu Val His Ala His
1 5 1015
Glu Glu Glu Asn Asp Val Val Lys Gly Asn Phe Asp Ile Ser Lys Ile
202530
Ser Gly Asp Trp Tyr Ser Ile Leu Leu Ala Ser Asp Ile Lys Glu Lys
354045
Ile Glu Glu Asn Gly Ser Met Arg Val Phe Val Lys Asp Ile Glu Val
505560
Leu Ser Asn Ser Ser Leu Ile Phe Thr Met His Thr Lys Val Asn Gly
65707580
Lys Cys Thr Lys Ile Ser Leu Ile Cys Asn Lys Thr Glu Lys Asp Gly
859095
Glu Tyr Asp Val Val His Asp Gly Tyr Asn Leu Phe Arg Ile Ile Glu
100 105 110
Thr Ala Tyr Glu Asp Tyr Ile Ile Phe His Leu Asn Asn Val Asn Gln
115 120 125
Glu Gln Glu Phe Gln Leu Met Glu Leu Tyr Gly Arg Lys Pro Asp Val
130 135 140
Ser Pro Lys Val Lys Glu Lys Phe Val Arg Tyr Cys Gln Gly Met Glu
145 150 155 160
Ile Pro Lys Glu Asn Ile Leu Asp Leu Thr Gln Val Asp Arg Cys Leu
165 170 175
Gln Ala Arg Gln Ser Glu Ala Ala Gln Val Ser Ser Ala Glu
180 185 190
<210>4
<211>184
<212>PRT
<213>人工序列
<220>
<223>CfamOBP4
<400>4
Met Arg Cys Val Leu Leu Gly Gln Val Leu Val Leu Leu Trp Leu Ser
1 5 1015
Gly Ala Trp Ala Glu Val Leu Val Gln Pro Asp Phe Asp Ala Lys Lys
202530
Phe Ser Gly Leu Trp Tyr Val Val Ser Met Val Ser Asp Cys Lys Val
354045
Phe Leu Gly Lys Lys Asp His Leu Leu Met Ser Ser Arg Thr Ile Arg
505560
Ala Met Pro Gly Gly Asn Leu Ser Val His Met Glu Phe Pro Arg Ala
65707580
Asp Gly Cys His Gln Leu Asp Ala Glu Tyr Leu Arg Val Gly Ser Glu
859095
Gly His Phe Arg Val Pro Ala Leu Gly Tyr Leu Asp Val Arg Val Ala
100 105 110
Asp Thr Asp Tyr Asp Thr Phe Ala Val Leu Tyr Ile Tyr Lys Glu Leu
115 120 125
Glu Gly Ala Leu Ser Thr Met Val Gln Leu Tyr Ser Arg Thr Gln Glu
130 135 140
Ala Ser Pro Gln Ala Thr Lys Ala Phe Gln Asp Phe Tyr Pro Thr Val
145 150 155 160
Gly Leu Pro Asn Asp Met Met Val Met Leu Pro Lys Ser Asp Val Cys
165 170 175
Ser Ser Ala Gly Lys Glu Ala Ser
180
<210>5
<211>115
<212>PRT
<213>人工序列
<220>
<223>CfamOBP1共有序列
<400>5
Gln Asp Thr Pro Ala Leu Gly Lys Asp Thr Val Ala Val Ser Gly Lys
1 5 1015
Trp Tyr Leu Lys Ala Met Thr Ala Asp Gln Glu Val Pro Glu Lys Pro
202530
Asp Ser Val Thr Pro Met Ile Leu Lys Ala Gln Lys Gly Gly Asn Leu
354045
Glu Ala Lys Ile Thr Met Leu Thr Asn Gly Gln Cys Gln Asn Ile Thr
505560
Val Val Leu His Lys Thr Ser Glu Pro Gly Lys Tyr Thr Ala Tyr Glu
65707580
Gly Gln Arg Val Val Phe Ile Gln Pro Ser Pro Val Arg Asp His Tyr
859095
Ile Leu Tyr Cys Glu Gly Glu Leu His Gly Arg Gln Ile Arg Met Ala
100 105 110
Lys Leu Leu
115
<210>6
<211>121
<212>PRT
<213>人工序列
<220>
<223>CfamOBP2共有序列
<400>6
Gln Glu Gly Asn His Glu Glu Pro Gln Gly Gly Leu Glu Glu Leu Ser
1 5 1015
Gly Arg Trp His Ser Val Ala Leu Ala Ser Asn Lys Ser Asp Leu Ile
202530
Lys Pro Trp Gly His Phe Arg Val Phe Ile His Ser Met Ser Ala Lys
354045
Asp Gly Asn Leu His Gly Asp Ile Leu Ile Pro Gln Asp Gly Gln Cys
505560
Glu Lys Val Ser Leu Thr Ala Phe Lys Thr Ala Thr Ser Asn Lys Phe
65707580
Asp Leu Glu Tyr Trp Gly His Asn Asp Leu Tyr Leu Ala Glu Val Asp
859095
Pro Lys Ser Tyr Leu Ile Leu Tyr Met Ile Asn Gln Tyr Asn Asp Asp
100 105 110
Thr Ser Leu Val Ala His Leu Met Val
115 120
<210>7
<211>124
<212>PRT
<213>人工序列
<220>
<223>CfamOBP3共有序列
<400>7
His Glu Glu Glu Asn Asp Val Val Lys Gly Asn Phe Asp Ile Ser Lys
1 5 1015
Ile Ser Gly Asp Trp Tyr Ser Ile Leu Leu Ala Ser Asp Ile Lys Glu
202530
Lys Ile Glu Glu Asn Gly Ser Met Arg Val Phe Val Lys Asp Ile Glu
354045
Val Leu Ser Asn Ser Ser Leu Ile Phe Thr Met His Thr Lys Val Asn
505560
Gly Lys Cys Thr Lys Ile Ser Leu Ile Cys Asn Lys Thr Glu Lys Asp
65707580
Gly Glu Tyr Asp Val Val His Asp Gly Tyr Asn Leu Phe Arg Ile Ile
859095
Glu Thr Ala Tyr Glu Asp Tyr Ile Ile Phe His Leu Asn Asn Val Asn
100 105 110
Gln Glu Gln Glu Phe Gln Leu Met Glu Leu Tyr Gly
115 120
<210>8
<211>121
<212>PRT
<213>人工序列
<220>
<223>CfamOBP4共有序列
<400>8
Glu Val Leu Val Gln Pro Asp Phe Asp Ala Lys Lys Phe Ser Gly Leu
1 5 1015
Trp Tyr Val Val Ser Met Val Ser Asp Cys Lys Val Phe Leu Gly Lys
202530
Lys Asp His Leu Leu Met Ser Ser Arg Thr Ile Arg Ala Met Pro Gly
354045
Gly Asn Leu Ser Val His Met Glu Phe Pro Arg Ala Asp Gly Cys His
505560
Gln Leu Asp Ala Glu Tyr Leu Arg Val Gly Ser Glu Gly His Phe Arg
65707580
Val Pro Ala Leu Gly Tyr Leu Asp Val Arg Val Ala Asp Thr Asp Tyr
859095
Asp Thr Phe Ala Val Leu Tyr Ile Tyr Lys Glu Leu Glu Gly Ala Leu
100 105 110
Ser Thr Met Val Gln Leu Tyr Ser Arg
115 120
<210>9
<211>525
<212>DNA
<213>人工序列
<220>
<223>CfamOBP1 DNA序列 >NM_001003190.1 家犬气味结合蛋白2B (OBP2B), mRNA
<400>9
atgaagaccc tgctcctcac catcggcttc agcctcattg cgatcctgca ggcccaggat60
accccagcct tgggaaagga cactgtggct gtgtcaggga aatggtatct gaaggccatg 120
acagcagacc aggaggtgcc tgagaagcct gactcagtga ctcccatgat cctcaaagcc 180
cagaaggggg gcaacctgga agccaagatc accatgctga caaatggtca gtgccagaac 240
atcacggtgg tcctgcacaa aacctctgag cctggcaaat acacggcata cgagggccag 300
cgtgtcgtgt tcatccagcc gtccccggtg agggaccact acattctcta ctgcgagggc 360
gagctccatg ggaggcagat ccgaatggcc aagcttctgg gaagggatcc tgagcagagc 420
caagaggcct tggaggattt tcgggaattc tcaagagcca aaggattgaa ccaggagatt 480
ttggaactcg cgcagagcga aacctgctct ccaggaggac agtag 525
<210>10
<211>543
<212>DNA
<213>人工序列
<220>
<223>CfamOBP2 DNA序列 >NM_001003189.2 家犬次要变应原Can f 2 (CANF2),mRNA
<400>10
atgcagctcc tactgctgac cgtgggcctg gcactgatct gtggcctcca ggctcaggag60
ggaaaccatg aggagcccca gggaggccta gaggagctgt ctgggaggtg gcactccgtt 120
gccctggcct ccaacaagtc cgatctgatc aaaccctggg ggcacttcag ggttttcatc 180
cacagcatga gcgcaaagga cggcaacctg cacggggata tccttatacc gcaggacggc 240
cagtgcgaga aagtctccct cactgcgttc aagactgcca ccagcaacaa atttgacctg 300
gagtactggg gacacaatga cctgtacctg gcagaggtag accccaagag ctacctgatt 360
ctctacatga tcaaccagta caacgatgac accagcctgg tggctcactt gatggtccgg 420
gacctcagca ggcagcagga cttcctgccg gcattcgaat ctgtatgtga agacatcggt 480
ctgcacaagg accagattgt ggttctgagc gatgacgatc gctgccaggg ttccagagac 540
tag 543
<210>11
<211>573
<212>DNA
<213>人工序列
<220>
<223>CfamOBP3 DNA序列 >NM_001284461.1 家犬变应原Fel d 4-样 (LOC481674),mRNA
<400>11
atgaagctgc tgttgctgtg tctggggctg attctagtcc atgcccacga ggaagaaaac60
gatgttgtga aaggaaactt cgatatttca aagatttcgg gagattggta ttccattctc 120
ttggcctcag atatcaagga aaagatagaa gaaaatggca gcatgagggt ttttgtgaaa 180
gacattgaag tcctgagcaa ctcttctctg atctttacaa tgcatacaaa ggtgaatggg 240
aagtgtacta aaatttctct gatttgtaac aaaacagaaa aggatggtga atatgatgtt 300
gtgcatgatg gatacaattt atttagaata attgaaacag cctatgagga ctatattata 360
tttcatctta ataatgtcaa ccaggaacag gaattccaac tgatggagct ctatggccga 420
aaaccagatg tgagtccaaa agtcaaggaa aagtttgtga gatattgcca aggaatggaa 480
attcctaagg aaaacatact tgacctgacc caagttgatc gctgtctcca ggcccgacag 540
agcgaagcag cccaggtctc cagtgctgag tga573
<210>12
<211>555
<212>DNA
<213>人工序列
<220>
<223>CfamOBP4DNA序列 >XM_843825.5 预测: 家犬脂质运载蛋白15 (LCN15),
转录变体X3, mRNA
<400>12
atgaggtgtg tcctgctggg ccaggtcctg gtgctgctct ggctgtccgg ggcttgggct60
gaggtcctgg tacagccaga ttttgatgcc aaaaagttct caggtctttg gtacgtggtc 120
tccatggtct ccgactgcaa ggtcttcctg ggcaagaagg accacttgct catgtccagc 180
aggactatca gggccatgcc agggggcaac ctcagtgtcc acatggagtt ccctcgggct 240
gacggctgtc accagctgga tgctgagtac ctgagggtgg gctctgaggg gcacttcaga 300
gtcccagccc tgggctacct ggacgtgcgc gtggcagaca cagactatga caccttcgcc 360
gtgctctaca tctataagga gctggagggg gcgctcagca ccatggtcca gctctacagc 420
cggacccagg aagcaagtcc ccaagccaca aaggccttcc aggacttcta ccccaccgtg 480
gggctcccca atgacatgat ggtcatgctg cccaagtcag atgtgtgctc ctctgcaggc 540
aaggaggctt cctga555
<210>13
<211>174
<212>PRT
<213>人工序列
<220>
<223>CfamOBP1变体Pro21Thr
<400>13
Met Lys Thr Leu Leu Leu Thr Ile Gly Phe Ser Leu Ile Ala Ile Leu
1 5 1015
Gln Ala Gln Asp Pro Pro Ala Leu Gly Lys Asp Thr Val Ala Val Ser
202530
Gly Lys Trp Tyr Leu Lys Ala Met Thr Ala Asp Gln Glu Val Pro Glu
354045
Lys Pro Asp Ser Val Thr Pro Met Ile Leu Lys Ala Gln Lys Gly Gly
505560
Asn Leu Glu Ala Lys Ile Thr Met Leu Thr Asn Gly Gln Cys Gln Asn
65707580
Ile Thr Val Val Leu His Lys Thr Ser Glu Pro Gly Lys Tyr Thr Ala
859095
Tyr Glu Gly Gln Arg Val Val Phe Ile Gln Pro Ser Pro Val Arg Asp
100 105 110
His Tyr Ile Leu Tyr Cys Glu Gly Glu Leu His Gly Arg Gln Ile Arg
115 120 125
Met Ala Lys Leu Leu Gly Arg Asp Pro Glu Gln Ser Gln Glu Ala Leu
130 135 140
Glu Asp Phe Arg Glu Phe Ser Arg Ala Lys Gly Leu Asn Gln Glu Ile
145 150 155 160
Leu Glu Leu Ala Gln Ser Glu Thr Cys Ser Pro Gly Gly Gln
165 170
<210>14
<211>174
<212>PRT
<213>人工序列
<220>
<223> CfamOBP1变体Ser52Leu
<400>14
Met Lys Thr Leu Leu Leu Thr Ile Gly Phe Ser Leu Ile Ala Ile Leu
1 5 1015
Gln Ala Gln Asp Thr Pro Ala Leu Gly Lys Asp Thr Val Ala Val Ser
202530
Gly Lys Trp Tyr Leu Lys Ala Met Thr Ala Asp Gln Glu Val Pro Glu
354045
Lys Pro Asp Leu Val Thr Pro Met Ile Leu Lys Ala Gln Lys Gly Gly
505560
Asn Leu Glu Ala Lys Ile Thr Met Leu Thr Asn Gly Gln Cys Gln Asn
65707580
Ile Thr Val Val Leu His Lys Thr Ser Glu Pro Gly Lys Tyr Thr Ala
859095
Tyr Glu Gly Gln Arg Val Val Phe Ile Gln Pro Ser Pro Val Arg Asp
100 105 110
His Tyr Ile Leu Tyr Cys Glu Gly Glu Leu His Gly Arg Gln Ile Arg
115 120 125
Met Ala Lys Leu Leu Gly Arg Asp Pro Glu Gln Ser Gln Glu Ala Leu
130 135 140
Glu Asp Phe Arg Glu Phe Ser Arg Ala Lys Gly Leu Asn Gln Glu Ile
145 150 155 160
Leu Glu Leu Ala Gln Ser Glu Thr Cys Ser Pro Gly Gly Gln
165 170
<210>15
<211>180
<212>PRT
<213>人工序列
<220>
<223>CfamOBP2变体Glu83Lys
<400>15
Met Gln Leu Leu Leu Leu Thr Val Gly Leu Ala Leu Ile Cys Gly Leu
1 5 1015
Gln Ala Gln Glu Gly Asn His Glu Glu Pro Gln Gly Gly Leu Glu Glu
202530
Leu Ser Gly Arg Trp His Ser Val Ala Leu Ala Ser Asn Lys Ser Asp
354045
Leu Ile Lys Pro Trp Gly His Phe Arg Val Phe Ile His Ser Met Ser
505560
Ala Lys Asp Gly Asn Leu His Gly Asp Ile Leu Ile Pro Gln Asp Gly
65707580
Gln Cys Lys Lys Val Ser Leu Thr Ala Phe Lys Thr Ala Thr Ser Asn
859095
Lys Phe Asp Leu Glu Tyr Trp Gly His Asn Asp Leu Tyr Leu Ala Glu
100 105 110
Val Asp Pro Lys Ser Tyr Leu Ile Leu Tyr Met Ile Asn Gln Tyr Asn
115 120 125
Asp Asp Thr Ser Leu Val Ala His Leu Met Val Arg Asp Leu Ser Arg
130 135 140
Gln Gln Asp Phe Leu Pro Ala Phe Glu Ser Val Cys Glu Asp Ile Gly
145 150 155 160
Leu His Lys Asp Gln Ile Val Val Leu Ser Asp Asp Asp Arg Cys Gln
165 170 175
Gly Ser Arg Asp
180
<210>16
<211>184
<212>PRT
<213>人工序列
<220>
<223>CfamOBP4变体Ser140Gly
<400>16
Met Arg Cys Val Leu Leu Gly Gln Val Leu Val Leu Leu Trp Leu Ser
1 5 1015
Gly Ala Trp Ala Glu Val Leu Val Gln Pro Asp Phe Asp Ala Lys Lys
202530
Phe Ser Gly Leu Trp Tyr Val Val Ser Met Val Ser Asp Cys Lys Val
354045
Phe Leu Gly Lys Lys Asp His Leu Leu Met Ser Ser Arg Thr Ile Arg
505560
Ala Met Pro Gly Gly Asn Leu Ser Val His Met Glu Phe Pro Arg Ala
65707580
Asp Gly Cys His Gln Leu Asp Ala Glu Tyr Leu Arg Val Gly Ser Glu
859095
Gly His Phe Arg Val Pro Ala Leu Gly Tyr Leu Asp Val Arg Val Ala
100 105 110
Asp Thr Asp Tyr Asp Thr Phe Ala Val Leu Tyr Ile Tyr Lys Glu Leu
115 120 125
Glu Gly Ala Leu Ser Thr Met Val Gln Leu Tyr Gly Arg Thr Gln Glu
130 135 140
Ala Ser Pro Gln Ala Thr Lys Ala Phe Gln Asp Phe Tyr Pro Thr Val
145 150 155 160
Gly Leu Pro Asn Asp Met Met Val Met Leu Pro Lys Ser Asp Val Cys
165 170 175
Ser Ser Ala Gly Lys Glu Ala Ser
180
<210>17
<211>525
<212>DNA
<213>人工序列
<220>
<223>CfamOBP1变体A61C
<400>17
atgaagaccc tgctcctcac catcggcttc agcctcattg cgatcctgca ggcccaggat60
cccccagcct tgggaaagga cactgtggct gtgtcaggga aatggtatct gaaggccatg 120
acagcagacc aggaggtgcc tgagaagcct gactcagtga ctcccatgat cctcaaagcc 180
cagaaggggg gcaacctgga agccaagatc accatgctga caaatggtca gtgccagaac 240
atcacggtgg tcctgcacaa aacctctgag cctggcaaat acacggcata cgagggccag 300
cgtgtcgtgt tcatccagcc gtccccggtg agggaccact acattctcta ctgcgagggc 360
gagctccatg ggaggcagat ccgaatggcc aagcttctgg gaagggatcc tgagcagagc 420
caagaggcct tggaggattt tcgggaattc tcaagagcca aaggattgaa ccaggagatt 480
ttggaactcg cgcagagcga aacctgctct ccaggaggac agtag 525
<210>18
<211>525
<212>DNA
<213>人工序列
<220>
<223>CfamOBP1变体C155T
<400>18
atgaagaccc tgctcctcac catcggcttc agcctcattg cgatcctgca ggcccaggat60
accccagcct tgggaaagga cactgtggct gtgtcaggga aatggtatct gaaggccatg 120
acagcagacc aggaggtgcc tgagaagcct gacttagtga ctcccatgat cctcaaagcc 180
cagaaggggg gcaacctgga agccaagatc accatgctga caaatggtca gtgccagaac 240
atcacggtgg tcctgcacaa aacctctgag cctggcaaat acacggcata cgagggccag 300
cgtgtcgtgt tcatccagcc gtccccggtg agggaccact acattctcta ctgcgagggc 360
gagctccatg ggaggcagat ccgaatggcc aagcttctgg gaagggatcc tgagcagagc 420
caagaggcct tggaggattt tcgggaattc tcaagagcca aaggattgaa ccaggagatt 480
ttggaactcg cgcagagcga aacctgctct ccaggaggac agtag 525
<210>19
<211>525
<212>DNA
<213>人工序列
<220>
<223>CfamOBP1变体G399A
<400>19
atgaagaccc tgctcctcac catcggcttc agcctcattg cgatcctgca ggcccaggat60
accccagcct tgggaaagga cactgtggct gtgtcaggga aatggtatct gaaggccatg 120
acagcagacc aggaggtgcc tgagaagcct gactcagtga ctcccatgat cctcaaagcc 180
cagaaggggg gcaacctgga agccaagatc accatgctga caaatggtca gtgccagaac 240
atcacggtgg tcctgcacaa aacctctgag cctggcaaat acacggcata cgagggccag 300
cgtgtcgtgt tcatccagcc gtccccggtg agggaccact acattctcta ctgcgagggc 360
gagctccatg ggaggcagat ccgaatggcc aagcttctag gaagggatcc tgagcagagc 420
caagaggcct tggaggattt tcgggaattc tcaagagcca aaggattgaa ccaggagatt 480
ttggaactcg cgcagagcga aacctgctct ccaggaggac agtag 525
<210>20
<211>543
<212>DNA
<213>人工序列
<220>
<223>CfamOBP2变体G51A
<400>20
atgcagctcc tactgctgac cgtgggcctg gcactgatct gtggcctcca agctcaggag60
ggaaaccatg aggagcccca gggaggccta gaggagctgt ctgggaggtg gcactccgtt 120
gccctggcct ccaacaagtc cgatctgatc aaaccctggg ggcacttcag ggttttcatc 180
cacagcatga gcgcaaagga cggcaacctg cacggggata tccttatacc gcaggacggc 240
cagtgcgaga aagtctccct cactgcgttc aagactgcca ccagcaacaa atttgacctg 300
gagtactggg gacacaatga cctgtacctg gcagaggtag accccaagag ctacctgatt 360
ctctacatga tcaaccagta caacgatgac accagcctgg tggctcactt gatggtccgg 420
gacctcagca ggcagcagga cttcctgccg gcattcgaat ctgtatgtga agacatcggt 480
ctgcacaagg accagattgt ggttctgagc gatgacgatc gctgccaggg ttccagagac 540
tag 543
<210>21
<211>543
<212>DNA
<213>人工序列
<220>
<223>CfamOBP2变体T225C
<400>21
atgcagctcc tactgctgac cgtgggcctg gcactgatct gtggcctcca ggctcaggag60
ggaaaccatg aggagcccca gggaggccta gaggagctgt ctgggaggtg gcactccgtt 120
gccctggcct ccaacaagtc cgatctgatc aaaccctggg ggcacttcag ggttttcatc 180
cacagcatga gcgcaaagga cggcaacctg cacggggata tcctcatacc gcaggacggc 240
cagtgcgaga aagtctccct cactgcgttc aagactgcca ccagcaacaa atttgacctg 300
gagtactggg gacacaatga cctgtacctg gcagaggtag accccaagag ctacctgatt 360
ctctacatga tcaaccagta caacgatgac accagcctgg tggctcactt gatggtccgg 420
gacctcagca ggcagcagga cttcctgccg gcattcgaat ctgtatgtga agacatcggt 480
ctgcacaagg accagattgt ggttctgagc gatgacgatc gctgccaggg ttccagagac 540
tag 543
<210>22
<211>543
<212>DNA
<213>人工序列
<220>
<223>CfamOBP2变体G247A
<400>22
atgcagctcc tactgctgac cgtgggcctg gcactgatct gtggcctcca ggctcaggag60
ggaaaccatg aggagcccca gggaggccta gaggagctgt ctgggaggtg gcactccgtt 120
gccctggcct ccaacaagtc cgatctgatc aaaccctggg ggcacttcag ggttttcatc 180
cacagcatga gcgcaaagga cggcaacctg cacggggata tccttatacc gcaggacggc 240
cagtgcaaga aagtctccct cactgcgttc aagactgcca ccagcaacaa atttgacctg 300
gagtactggg gacacaatga cctgtacctg gcagaggtag accccaagag ctacctgatt 360
ctctacatga tcaaccagta caacgatgac accagcctgg tggctcactt gatggtccgg 420
gacctcagca ggcagcagga cttcctgccg gcattcgaat ctgtatgtga agacatcggt 480
ctgcacaagg accagattgt ggttctgagc gatgacgatc gctgccaggg ttccagagac 540
tag 543
<210>23
<211>543
<212>DNA
<213>人工序列
<220>
<223>Cfam OBP2变体T409C
<400>23
atgcagctcc tactgctgac cgtgggcctg gcactgatct gtggcctcca ggctcaggag60
ggaaaccatg aggagcccca gggaggccta gaggagctgt ctgggaggtg gcactccgtt 120
gccctggcct ccaacaagtc cgatctgatc aaaccctggg ggcacttcag ggttttcatc 180
cacagcatga gcgcaaagga cggcaacctg cacggggata tccttatacc gcaggacggc 240
cagtgcgaga aagtctccct cactgcgttc aagactgcca ccagcaacaa atttgacctg 300
gagtactggg gacacaatga cctgtacctg gcagaggtag accccaagag ctacctgatt 360
ctctacatga tcaaccagta caacgatgac accagcctgg tggctcacct gatggtccgg 420
gacctcagca ggcagcagga cttcctgccg gcattcgaat ctgtatgtga agacatcggt 480
ctgcacaagg accagattgt ggttctgagc gatgacgatc gctgccaggg ttccagagac 540
tag 543
<210>24
<211>543
<212>DNA
<213>人工序列
<220>
<223>CfamOBP2变体T462C
<400>24
atgcagctcc tactgctgac cgtgggcctg gcactgatct gtggcctcca ggctcaggag60
ggaaaccatg aggagcccca gggaggccta gaggagctgt ctgggaggtg gcactccgtt 120
gccctggcct ccaacaagtc cgatctgatc aaaccctggg ggcacttcag ggttttcatc 180
cacagcatga gcgcaaagga cggcaacctg cacggggata tccttatacc gcaggacggc 240
cagtgcgaga aagtctccct cactgcgttc aagactgcca ccagcaacaa atttgacctg 300
gagtactggg gacacaatga cctgtacctg gcagaggtag accccaagag ctacctgatt 360
ctctacatga tcaaccagta caacgatgac accagcctgg tggctcactt gatggtccgg 420
gacctcagca ggcagcagga cttcctgccg gcattcgaat ccgtatgtga agacatcggt 480
ctgcacaagg accagattgt ggttctgagc gatgacgatc gctgccaggg ttccagagac 540
tag 543
<210>25
<211>573
<212>DNA
<213>人工序列
<220>
<223>CfamOBP3变体G231A
<400>25
atgaagctgc tgttgctgtg tctggggctg attctagtcc atgcccacga ggaagaaaac60
gatgttgtga aaggaaactt cgatatttca aagatttcgg gagattggta ttccattctc 120
ttggcctcag atatcaagga aaagatagaa gaaaatggca gcatgagggt ttttgtgaaa 180
gacattgaag tcctgagcaa ctcttctctg atctttacaa tgcatacaaa agtgaatggg 240
aagtgtacta aaatttctct gatttgtaac aaaacagaaa aggatggtga atatgatgtt 300
gtgcatgatg gatacaattt atttagaata attgaaacag cctatgagga ctatattata 360
tttcatctta ataatgtcaa ccaggaacag gaattccaac tgatggagct ctatggccga 420
aaaccagatg tgagtccaaa agtcaaggaa aagtttgtga gatattgcca aggaatggaa 480
attcctaagg aaaacatact tgacctgacc caagttgatc gctgtctcca ggcccgacag 540
agcgaagcag cccaggtctc cagtgctgag tga573
<210>26
<211>555
<212>DNA
<213>人工序列
<220>
<223>CfamOBP4变体A418G
<400>26
atgaggtgtg tcctgctggg ccaggtcctg gtgctgctct ggctgtccgg ggcttgggct60
gaggtcctgg tacagccaga ttttgatgcc aaaaagttct caggtctttg gtacgtggtc 120
tccatggtct ccgactgcaa ggtcttcctg ggcaagaagg accacttgct catgtccagc 180
aggactatca gggccatgcc agggggcaac ctcagtgtcc acatggagtt ccctcgggct 240
gacggctgtc accagctgga tgctgagtac ctgagggtgg gctctgaggg gcacttcaga 300
gtcccagccc tgggctacct ggacgtgcgc gtggcagaca cagactatga caccttcgcc 360
gtgctctaca tctataagga gctggagggg gcgctcagca ccatggtcca gctctacggc 420
cggacccagg aagcaagtcc ccaagccaca aaggccttcc aggacttcta ccccaccgtg 480
gggctcccca atgacatgat ggtcatgctg cccaagtcag atgtgtgctc ctctgcaggc 540
aaggaggctt cctga555
<210>27
<211>190
<212>PRT
<213>人工序列
<220>
<223>CfamOBP3变体Ile71Val
<400>27
Met Lys Leu Leu Leu Leu Cys Leu Gly Leu Ile Leu Val His Ala His
1 5 1015
Glu Glu Glu Asn Asp Val Val Lys Gly Asn Phe Asp Ile Ser Lys Ile
202530
Ser Gly Asp Trp Tyr Ser Ile Leu Leu Ala Ser Asp Ile Lys Glu Lys
354045
Ile Glu Glu Asn Gly Ser Met Arg Val Phe Val Lys Asp Ile Glu Val
505560
Leu Ser Asn Ser Ser Leu Val Phe Thr Met His Thr Lys Val Asn Gly
65707580
Lys Cys Thr Lys Ile Ser Leu Ile Cys Asn Lys Thr Glu Lys Asp Gly
859095
Glu Tyr Asp Val Val His Asp Gly Tyr Asn Leu Phe Arg Ile Ile Glu
100 105 110
Thr Ala Tyr Glu Asp Tyr Ile Ile Phe His Leu Asn Asn Val Asn Gln
115 120 125
Glu Gln Glu Phe Gln Leu Met Glu Leu Tyr Gly Arg Lys Pro Asp Val
130 135 140
Ser Pro Lys Val Lys Glu Lys Phe Val Arg Tyr Cys Gln Gly Met Glu
145 150 155 160
Ile Pro Lys Glu Asn Ile Leu Asp Leu Thr Gln Val Asp Arg Cys Leu
165 170 175
Gln Ala Arg Gln Ser Glu Ala Ala Gln Val Ser Ser Ala Glu
180 185 190
<210>28
<211>184
<212>PRT
<213>人工序列
<220>
<223>CfamOBP4变体Asn164Asp
<400>28
Met Arg Cys Val Leu Leu Gly Gln Val Leu Val Leu Leu Trp Leu Ser
1 5 1015
Gly Ala Trp Ala Glu Val Leu Val Gln Pro Asp Phe Asp Ala Lys Lys
202530
Phe Ser Gly Leu Trp Tyr Val Val Ser Met Val Ser Asp Cys Lys Val
354045
Phe Leu Gly Lys Lys Asp His Leu Leu Met Ser Ser Arg Thr Ile Arg
505560
Ala Met Pro Gly Gly Asn Leu Ser Val His Met Glu Phe Pro Arg Ala
65707580
Asp Gly Cys His Gln Leu Asp Ala Glu Tyr Leu Arg Val Gly Ser Glu
859095
Gly His Phe Arg Val Pro Ala Leu Gly Tyr Leu Asp Val Arg Val Ala
100 105 110
Asp Thr Asp Tyr Asp Thr Phe Ala Val Leu Tyr Ile Tyr Lys Glu Leu
115 120 125
Glu Gly Ala Leu Ser Thr Met Val Gln Leu Tyr Ser Arg Thr Gln Glu
130 135 140
Ala Ser Pro Gln Ala Thr Lys Ala Phe Gln Asp Phe Tyr Pro Thr Val
145 150 155 160
Gly Leu Pro Asp Asp Met Met Val Met Leu Pro Lys Ser Asp Val Cys
165 170 175
Ser Ser Ala Gly Lys Glu Ala Ser
180
<210>29
<211>525
<212>DNA
<213>人工序列
<220>
<223>CfamOBP1变体G363A
<400>29
atgaagaccc tgctcctcac catcggcttc agcctcattg cgatcctgca ggcccaggat60
accccagcct tgggaaagga cactgtggct gtgtcaggga aatggtatct gaaggccatg 120
acagcagacc aggaggtgcc tgagaagcct gactcagtga ctcccatgat cctcaaagcc 180
cagaaggggg gcaacctgga agccaagatc accatgctga caaatggtca gtgccagaac 240
atcacggtgg tcctgcacaa aacctctgag cctggcaaat acacggcata cgagggccag 300
cgtgtcgtgt tcatccagcc gtccccggtg agggaccact acattctcta ctgcgagggc 360
gaactccatg ggaggcagat ccgaatggcc aagcttctgg gaagggatcc tgagcagagc 420
caagaggcct tggaggattt tcgggaattc tcaagagcca aaggattgaa ccaggagatt 480
ttggaactcg cgcagagcga aacctgctct ccaggaggac agtag 525
<210>30
<211>573
<212>DNA
<213>人工序列
<220>
<223>CfamOBP3变体G99A
<400>30
atgaagctgc tgttgctgtg tctggggctg attctagtcc atgcccacga ggaagaaaac60
gatgttgtga aaggaaactt cgatatttca aagatttcag gagattggta ttccattctc 120
ttggcctcag atatcaagga aaagatagaa gaaaatggca gcatgagggt ttttgtgaaa 180
gacattgaag tcctgagcaa ctcttctctg atctttacaa tgcatacaaa ggtgaatggg 240
aagtgtacta aaatttctct gatttgtaac aaaacagaaa aggatggtga atatgatgtt 300
gtgcatgatg gatacaattt atttagaata attgaaacag cctatgagga ctatattata 360
tttcatctta ataatgtcaa ccaggaacag gaattccaac tgatggagct ctatggccga 420
aaaccagatg tgagtccaaa agtcaaggaa aagtttgtga gatattgcca aggaatggaa 480
attcctaagg aaaacatact tgacctgacc caagttgatc gctgtctcca ggcccgacag 540
agcgaagcag cccaggtctc cagtgctgag tga573
<210>31
<211>573
<212>DNA
<213>人工序列
<220>
<223>CfamOBP3变体A211G
<400>31
atgaagctgc tgttgctgtg tctggggctg attctagtcc atgcccacga ggaagaaaac60
gatgttgtga aaggaaactt cgatatttca aagatttcgg gagattggta ttccattctc 120
ttggcctcag atatcaagga aaagatagaa gaaaatggca gcatgagggt ttttgtgaaa 180
gacattgaag tcctgagcaa ctcttctctg gtctttacaa tgcatacaaa ggtgaatggg 240
aagtgtacta aaatttctct gatttgtaac aaaacagaaa aggatggtga atatgatgtt 300
gtgcatgatg gatacaattt atttagaata attgaaacag cctatgagga ctatattata 360
tttcatctta ataatgtcaa ccaggaacag gaattccaac tgatggagct ctatggccga 420
aaaccagatg tgagtccaaa agtcaaggaa aagtttgtga gatattgcca aggaatggaa 480
attcctaagg aaaacatact tgacctgacc caagttgatc gctgtctcca ggcccgacag 540
agcgaagcag cccaggtctc cagtgctgag tga573
<210>32
<211>555
<212>DNA
<213>人工序列
<220>
<223>CfamOBP4变体C12T
<400>32
atgaggtgtg ttctgctggg ccaggtcctg gtgctgctct ggctgtccgg ggcttgggct60
gaggtcctgg tacagccaga ttttgatgcc aaaaagttct caggtctttg gtacgtggtc 120
tccatggtct ccgactgcaa ggtcttcctg ggcaagaagg accacttgct catgtccagc 180
aggactatca gggccatgcc agggggcaac ctcagtgtcc acatggagtt ccctcgggct 240
gacggctgtc accagctgga tgctgagtac ctgagggtgg gctctgaggg gcacttcaga 300
gtcccagccc tgggctacct ggacgtgcgc gtggcagaca cagactatga caccttcgcc 360
gtgctctaca tctataagga gctggagggg gcgctcagca ccatggtcca gctctacagc 420
cggacccagg aagcaagtcc ccaagccaca aaggccttcc aggacttcta ccccaccgtg 480
gggctcccca atgacatgat ggtcatgctg cccaagtcag atgtgtgctc ctctgcaggc 540
aaggaggctt cctga555
<210>33
<211>555
<212>DNA
<213>人工序列
<220>
<223>CfamOBP4变体C177T
<400>33
atgaggtgtg tcctgctggg ccaggtcctg gtgctgctct ggctgtccgg ggcttgggct60
gaggtcctgg tacagccaga ttttgatgcc aaaaagttct caggtctttg gtacgtggtc 120
tccatggtct ccgactgcaa ggtcttcctg ggcaagaagg accacttgct catgtctagc 180
aggactatca gggccatgcc agggggcaac ctcagtgtcc acatggagtt ccctcgggct 240
gacggctgtc accagctgga tgctgagtac ctgagggtgg gctctgaggg gcacttcaga 300
gtcccagccc tgggctacct ggacgtgcgc gtggcagaca cagactatga caccttcgcc 360
gtgctctaca tctataagga gctggagggg gcgctcagca ccatggtcca gctctacagc 420
cggacccagg aagcaagtcc ccaagccaca aaggccttcc aggacttcta ccccaccgtg 480
gggctcccca atgacatgat ggtcatgctg cccaagtcag atgtgtgctc ctctgcaggc 540
aaggaggctt cctga555
<210>34
<211>555
<212>DNA
<213>人工序列
<220>
<223>CfamOBP4变体A490G
<400>34
atgaggtgtg tcctgctggg ccaggtcctg gtgctgctct ggctgtccgg ggcttgggct60
gaggtcctgg tacagccaga ttttgatgcc aaaaagttct caggtctttg gtacgtggtc 120
tccatggtct ccgactgcaa ggtcttcctg ggcaagaagg accacttgct catgtccagc 180
aggactatca gggccatgcc agggggcaac ctcagtgtcc acatggagtt ccctcgggct 240
gacggctgtc accagctgga tgctgagtac ctgagggtgg gctctgaggg gcacttcaga 300
gtcccagccc tgggctacct ggacgtgcgc gtggcagaca cagactatga caccttcgcc 360
gtgctctaca tctataagga gctggagggg gcgctcagca ccatggtcca gctctacagc 420
cggacccagg aagcaagtcc ccaagccaca aaggccttcc aggacttcta ccccaccgtg 480
gggctccccg atgacatgat ggtcatgctg cccaagtcag atgtgtgctc ctctgcaggc 540
aaggaggctt cctga555
<210>35
<211>190
<212>PRT
<213>人工序列
<220>
<223>CfamOBP3突变体102Y
<400>35
Met Lys Leu Leu Leu Leu Cys Leu Gly Leu Ile Leu Val His Ala His
1 5 1015
Glu Glu Glu Asn Asp Val Val Lys Gly Asn Phe Asp Ile Ser Lys Ile
202530
Ser Gly Asp Trp Tyr Ser Ile Leu Leu Ala Ser Asp Ile Lys Glu Lys
354045
Ile Glu Glu Asn Gly Ser Met Arg Val Phe Val Lys Asp Ile Glu Val
505560
Leu Ser Asn Ser Ser Leu Ile Phe Thr Met His Thr Lys Val Asn Gly
65707580
Lys Cys Thr Lys Ile Ser Leu Ile Cys Asn Lys Thr Glu Lys Asp Gly
859095
Glu Tyr Asp Val Val Tyr Asp Gly Tyr Asn Leu Phe Arg Ile Ile Glu
100 105 110
Thr Ala Tyr Glu Asp Tyr Ile Ile Phe His Leu Asn Asn Val Asn Gln
115 120 125
Glu Gln Glu Phe Gln Leu Met Glu Leu Tyr Gly Arg Lys Pro Asp Val
130 135 140
Ser Pro Lys Val Lys Glu Lys Phe Val Arg Tyr Cys Gln Gly Met Glu
145 150 155 160
Ile Pro Lys Glu Asn Ile Leu Asp Leu Thr Gln Val Asp Arg Cys Leu
165 170 175
Gln Ala Arg Gln Ser Glu Ala Ala Gln Val Ser Ser Ala Glu
180 185 190
<210>36
<211>564
<212>DNA
<213>人工序列
<220>
<223>CfamOBP3突变体102Y
<400>36
atgagaggat ctcaccatca ccatcaccat acggatccgc atgaggagga aaacgacgtt60
gtgaagggca acttcgacat cagcaagatc agcggcgatt ggtacagcat tctgctggcg 120
agcgacatca aggagaagat cgaggagaat ggcagcatgc gcgtgttcgt gaaggacatc 180
gaagtgctca gcaacagcag tctgatcttc acgatgcaca ccaaggtgaa cggcaaatgc 240
accaaaatca gcctcatttg caacaagacc gagaaggacg gcgagtacga tgtggtgtat 300
gatggttaca acctcttccg catcatcgag acggcctacg aagactacat catcttccat 360
ctcaacaacg tgaatcaaga acaagaattc cagctgatgg agctgtacgg ccgcaaaccg 420
gatgtgagcc caaaggtgaa ggagaagttc gtgcgctact gtcaaggcat ggagatcccg 480
aaagagaaca ttctggatct gacgcaagtt gaccgctgtc tgcaagcccg ccaaagcgaa 540
gccgcgcaag tgagcagcgc cgaa564
- 一种检测气味结合蛋白与信息素结合过程的装置及方法
- 一种检测气味结合蛋白与信息素结合过程的装置及方法