一种基于历史数据库的数据服务方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明属于数据库技术领域,具体涉及一种基于历史数据库的数据服务方法。
背景技术
历史数据库在核电全范围模拟机中具有重要的地位。全范围模拟素有“虚拟核电站”之称。市场上常见的历史数据库包括Mysql、Sql Server、Oracle以及WonderwareHistorian等都发展的比较成熟。这些数据库在性能和可靠性上都具有一定的优势。核电全范围模拟机系统中需要存储大量的标记点数据,在存储上要求效率高,速度快,在存储时长和安全性上要求不高。更为重要的一点是,核电全范围模拟机系统运行时,具有启动、运行、暂停以及复位的功能,并且核电全范围模拟机具有自己的一套时间系统。核电全范围模拟机的特殊需求导致数据库需要解决两套时间系统之间的差异问题。
发明内容
本发明的目的是提供一种基于历史数据库的数据服务方法,在存储性能和检索性能上,满足核电仿真系统的要求,同时还有效解决核电全范围模拟机的特殊需求导致数据库需要解决两套时间系统之间的差异问题。
本发明的技术方案如下:一种基于历史数据库的数据服务方法,包括如下步骤:
第一步:客户端通过通信服务发送带有包头和请求的数据包给历史数据库服务端;
第二步:历史数据库通信服务接收到客户端发送的消息后,然后进行消息的处理操纵;
第三步:历史数据库将消息处理的结果通过通信服务程序发送给该消息的发送端。
所述的第二步包括:
S1获取并解析客户端发送的数据报文,所述数据报文中包括测点名称、开始时间、结束时间、以及取样频率信息;
S2将所述开始时间与所述结束时间转换为对应的仿真时段;
S3依据所述仿真时段从历史数据库已存储的文件中查找所述测点名称对应的文件,其中所述历史数据库中,所述文件基于仿真时间进行存储;
S4依据所述取样频率进行数值拟合,获取所述仿真时段中各时刻的对应数值。
步骤S3中,数据库系统建立二叉树,然后通过二叉树查找算法实现快速定位,二叉树的插入和查找的时间复杂度均为O(log
步骤S4包括:
S41获取标签点数据类型;
S42若为浮点型及整数型标签点,则采用直线拟合的方式计算某一时刻的数值,若为开关量,则某一时刻的为上一时刻的值的方法。
对于浮点型及整数型标签点数据拟,采用直线拟合的方式计算某一时刻的数值,某标签点的时刻t
本发明的有益效果在于:本发明从多线程并行运行角度出发,通过将数据的采集和存储进行分离,开辟内存数据缓冲区,在保证数据不丢的情况下,实现了高频率大量标签点的数据的采集及存储。通过优化数据在文件中的存储结构,降低数据检索复杂度。本发明中的历史数据库,在存储性能和检索性能上,满足核电仿真系统的要求。同时,由于数据存储时,基于仿真时间进行,数据查询时,将北京时间转换为仿真时间后,在进行数据查询,可方便的解决两套时间系统之间的差异问题。
附图说明
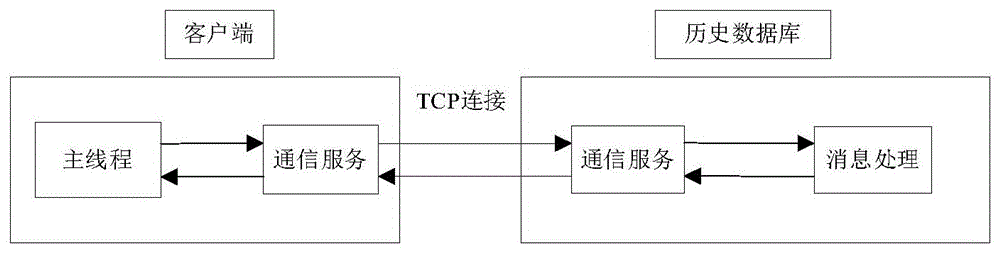
图1为客户端与历史数据库工作流程图;
图2为本发明所提供的一种基于历史数据库的数据服务方法中应用的系统主要结构图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步详细说明。
历史数据库数据服务主要包括服务器与客户端间的通信以及服务器的数据检索功能。本实施例中,客户端通过与历史数据库建立TCP通信连接,发送请求消息给服务器。服务器接收到消息后进行消息处理。当客户端发送数据查询请求时,服务端接收到请求后会到历史库中检索数据并将结果通过TCP信道返回给客户端。
本实施例中,如图1所示,一种基于历史数据库的数据服务方法,具体包括如下步骤:
第一步:客户端通过通信服务发送带有包头和请求的数据包给历史数据库服务端;
第二步:历史数据库通信服务接收到客户端发送的消息后,然后进行消息的处理操纵;具体包括如下步骤:
S1获取并解析客户端发送的数据报文,所述数据报文中包括测点名称、开始时间、结束时间、以及取样频率信息;
S2将所述开始时间与所述结束时间转换为对应的仿真时段;
S3依据所述仿真时段从历史数据库已存储的文件中查找所述测点名称对应的文件,其中所述历史数据库中,所述文件基于仿真时间进行存储;
S4依据所述取样频率进行数值拟合,获取所述仿真时段中各时刻的对应数值;
第三步:历史数据库将消息处理的结果通过通信服务程序发送给该消息的发送端。
此外,为了保证数据信道传输的稳定性,在客户端与历史库的TCP信道连接上增加了重连机制。当客户端与服务器之间断开时,客户端会在短时间内重新向服务器发出连接请求。这样有效保证了客户端可以随时快速访问数据库。
本实施例中,历史数据库系统基于Linux操纵系统。提供大量标签点的实时数据的采集、存储以及查询功能。为了达到数据库的性能设计指标,该系统采用多线程并行处理技术,即将数据采集、数据存储以及数据查询设为三个并行线程。系统主要结构如图2所示。其中,数据的采集和存储分成两个并行的线程,这样设置,可以有效避免数据在写入本地文件的过程中实时数据的丢失情况。
数据采集时,数据采集线程周期性的取出需要存储的标签点的实时值,然后对应写入到系统内存建立的数据块中;当所述数据块存储满时,所述数据存储线程负责将所述数据块的数据按预设存储结构写入到本地文件中。其中,按照预设数据结构进行存储,可有效节省存储空间。在进行数据查询时,先访问数据块,判断数据块中是否存在仿真时段对应的文件,若有,则直接执行步骤S4,将相关数据发送至客户端;若判断数据块中没有存储相关数据,则访问本地文件,从本地文件中查找对应的数据并回传;若判断数据块只存在部分数据,则分别从数据块以及本地文件中调取对应数据并拼接后回传。
更进一步的,本实施例中,单个文件在内存中的存储结构如表1所示。
表1文件数据在内存中的存储结构
在核电DCS仿真系统中,单个标签点需要记录的数据有标签点名称、时间、当前值以及当前质量。在存储文件中,还需要写入的信息有数据的起始时间、结束时间、单个文件标签点数量、每个标签点数记录的数据数量以及文件的大小。
为了方便存储和查询,标签点的名称的存储长度设置成统一的一个定值L。在核电DCS仿真系统中,系统运行时间是从0开始的,同时,为了节省存储空间,将时间转换成以毫秒数进行存储,即以仿真时间进行存储,这样在32位操作系统中,一个4个字节的长度能够记录的时间为(2
假设单个文件中存储的标签点数量为N,每个标签点记录的数据数量为M,那么单个文件所占内存大小为(4+4+4+4+4)+(4*M)+N*L+M*N*(4+1)字节。如果数据采集周期为F,那么单个文件所能记录的数据时长为F*M。
如前所述,为了方便存储和查询,同时节省存储空间,历史数据库中,是将时间转换成以毫秒数进行存储,即以仿真时间进行存储,步骤S2中,对应的,通过预设映射表的方式,也将所述开始时间与所述结束时间转换为对应的仿真时段,这样设置,一方面可提高检索效率,另外一方面,还可实现数据的复位。
全范围模拟机主要用来进行操作员培训教学的仿真系统,故对应的历史数据库必须具备运行、暂停、复位功能。模拟机有自己定义的时间系统,时间格式为yyyy-MM-dd hh:mm:ss(年-月-日时:分:秒),yyyy-MM-dd代表的是模拟机启动的日期,hh:mm:ss代表的是模拟机运行了多长时间。全范围模拟机每次启动时候,时分秒均为0,显示为yyyy-MM-dd 00:00:00,暂停时模拟机时间也暂停,系统运行状态处于暂停状态,所有的系统都停止计算,同样的,历史数据也必须暂停存储,当切换到运行状态时系统恢复运行,继续存储历史数据。在复位时会输入一个时间点,所有的系统会恢复到指定时间时的状态,历史数据库也必须恢复到那一时刻。
本实施例中,通过预设映射表,将客户端输入的开始时间与结束时间(均为北京时间)转换为对应的仿真时间段,然后通过检索历史数据库中对应的仿真时间,可方便的找到对应文件位置;此外,还可通过调整映射表的规则,实现历史数据库的复位,以满足模拟机的复位功能。
步骤S3中,为了提高检索效率,快速定位查询时段所对应的文件,数据库系统建立二叉树,然后通过二叉树查找算法实现快速定位。二叉树的插入和查找的时间复杂度均为O(log
数据的准确性与历史数据库的数据采样频率有关,采样频率越高,数据检索时检索数据就越接近真实值,误差越小,但对系统性能要求就相对越高。通常历史数据库在按照预设的固定采样频率进行数据采集与存储,而客户端传入的取样频率又是使用者根据实际使用需要设置的,采样频率与取样频率往往并不相同,如存在采样频率为间隔2s采样一次,而取样频率需要为每间隔1s取样一次,假设客户端需要13:00至14:00的历史数据,此时,受限于采样频率,部分时刻的数值在历史数据库中并不存在,为了提高数据的精确度,故步骤S4中,对于所有的客户端需求,均依据所述取样频率进行数据拟合,获取所述仿真时段中各时刻的对应数值后进行回传。
具体而言包括如下步骤:
S41获取标签点数据类型;
S42若为浮点型及整数型标签点,则采用直线拟合的方式计算某一时刻的数值,若为开关量,则某一时刻的为上一时刻的值的方法。
对于浮点型及整数型标签点数据拟,采用直线拟合的方式计算某一时刻的数值。假设某标签点的时刻t
- 针对胰腺区域的四维锥束CT成像方法和装置
- 针对胰腺区域的四维CT配准方法和装置